08 mag 2025·8 min
Come costruire un'app web per la valutazione e le recensioni dei fornitori
Scopri come pianificare, progettare e costruire un'app web per schede valutazione e recensioni fornitori: modelli dati, workflow, permessi e suggerimenti per il reporting.
Prima di abbozzare schermate o scegliere un database, chiarisci a cosa serve l'app, chi ci farà affidamento e cosa significa “buono”. Le app per la valutazione dei fornitori falliscono più spesso quando cercano di accontentare tutti contemporaneamente—o quando non riescono a rispondere a domande basilari come “Quale fornitore stiamo effettivamente valutando?”
Obiettivi, utenti e ambito
Chi la usa (e cosa gli serve)
Inizia nominando i gruppi di utenti principali e le decisioni quotidiane che prendono:
- Procurement ha bisogno di una scheda fornitore coerente, viste comparative tra fornitori e una traccia di audit difendibile per le decisioni di sourcing.
- Finance si interessa delle variazioni di costo, dell'aderenza alle condizioni di pagamento e dei segnali di rischio che influenzano le previsioni.
- Operations vuole risolvere i problemi rapidamente: tracciare incidenti, documentare azioni correttive e vedere se le prestazioni migliorano.
- Fornitori (portale opzionale) vogliono visibilità sul feedback, la possibilità di rispondere e chiarezza su come sono calcolati i punteggi.
Un trucco utile: scegli un “utente core” (spesso procurement) e progetta la prima release attorno al suo workflow. Aggiungi il gruppo successivo solo quando puoi spiegare quale nuova capacità abilita.
Risultati chiave a cui puntare
Scrivi i risultati come cambiamenti misurabili, non come funzionalità. Risultati comuni includono:
- Decisioni sui fornitori migliori (es. liste di fornitori preferiti basate su evidenze, non su aneddoti)
- Risoluzione più rapida dei problemi (proprietà chiara, scadenze e follow-up)
- Valutazione più coerente (meno variazioni tra revisori o siti)
Questi risultati guideranno successivamente le scelte di monitoraggio KPI e reporting.
Definisci cosa significa “fornitore” nel tuo sistema
“Fornitore” può significare cose diverse a seconda della struttura dell’organizzazione e dei contratti. Decidi presto se un fornitore è:
- una entità legale (società madre)
- un sito/ubicazione (utile quando la qualità varia per impianto o regione)
- una linea di servizio (es. logistica vs imballaggio dallo stesso fornitore)
La tua scelta influenza tutto: aggregazioni dei punteggi, permessi e persino se una singola struttura con problemi debba impattare il rapporto complessivo.
Scegli l’approccio di scoring
Ci sono tre pattern comuni:
- KPI ponderati: input numerici (es. % consegne puntuali, tasso di difetti) moltiplicati per pesi. Ottimo per trasparenza e automazione.
- Rubriche: i revisori scelgono livelli (es. “Eccellente/Buono/Discreto/Povero”) con testo guida. Ottimo quando i dati sono qualitativi.
- Ibrido: KPI per aree misurabili + rubrica per collaborazione, reattività o fit strategico.
Rendi il metodo di scoring sufficientemente comprensibile perché un fornitore (e un revisore interno) possa seguirlo.
Definisci metriche di successo per l’app
Infine, scegli alcune metriche a livello app per convalidare adozione e valore:
- Adozione: % di fornitori attivi con almeno una recensione nell’ultimo trimestre
- Completezza delle recensioni: campi obbligatori compilati, evidenze allegate, KPI forniti
- Tempo di ciclo: tempo dall’apertura della review → approvazione → condivisione con il fornitore (se applicabile)
Con obiettivi, utenti e ambito definiti, avrai una base stabile per il modello di scoring e il design del workflow che seguono.
Modello di scoring e progettazione dei KPI
Un'app di scoring fornitore vive o muore in base a quanto il punteggio rispecchi l’esperienza reale. Prima di costruire schermate, annota esattamente KPI, scale e regole in modo che procurement, operations e finance interpretino i risultati allo stesso modo.
Scegli un set di KPI piccolo e difendibile
Inizia con un nucleo che la maggior parte dei team riconosce:
- Consegna puntuale (es. % di spedizioni entro la finestra concordata)
- Qualità (tasso difetti, tasso resi o % superamento ispezione)
- Aderenza SLA (ticket risolti entro il tempo target, uptime se rilevante)
- Variazione di costo (variazione fattura vs PO, addebiti non previsti)
- Reattività (tempo alla prima risposta, tempo alla risoluzione per escalation)
Mantieni le definizioni misurabili e collega ogni KPI a una fonte dati o a una domanda di revisione.
Definisci scale di valutazione che le persone possano spiegare
Scegli o 1–5 (facile per le persone) o 0–100 (più granulare), quindi definisci cosa significa ogni livello. Per esempio, “Consegna puntuale: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%.” Soglie chiare riducono le discussioni e rendono le recensioni comparabili tra team.
Pesi, dati mancanti e regole di equità
Assegna pesi alle categorie (es. Consegna 30%, Qualità 30%, SLA 20%, Costo 10%, Reattività 10%) e documenta quando i pesi cambiano (diversi tipi di contratto possono dare priorità differenti).
Decidi come trattare i dati mancanti:
- Escludere il KPI dal denominatore per quel periodo, oppure
- Applicare un default neutro, oppure
- Segnalare “dati insufficienti” e bloccare il ranking.
Qualunque scelta tu faccia, applicala coerentemente e rendila visibile nelle viste di drill-down così i team non confondano “mancante” con “buono”.
Più schede di valutazione per fornitore
Supporta più di una scheda per fornitore così i team possono confrontare le performance per contratto, regione o periodo. Questo evita di mediamente attenuare problemi isolati a uno specifico sito o progetto.
Dispute e correzioni
Documenta come le dispute influenzano i punteggi: se una metrica può essere corretta retroattivamente, se una disputa flagga temporaneamente il punteggio e quale versione è considerata “ufficiale.” Anche una regola semplice come “i punteggi si ricalcolano quando una correzione è approvata, con una nota che spiega la modifica” evita confusione in seguito.
Modello dati e schema di base
Un modello dati pulito mantiene lo scoring equo, le recensioni tracciabili e i report credibili. Vuoi rispondere a domande semplici in modo affidabile—“Perché questo fornitore ha preso 72 questo mese?” e “Cosa è cambiato dall'ultimo trimestre?”—senza giustificazioni vaghe o fogli di calcolo.
Entità principali (cosa memorizzi)
Al minimo, definisci queste entità:
- Vendor: profilo fornitore (nome, stato, categoria, contatti)
- Contract: dettagli dell'accordo commerciale e finestre di validità
- Order/Invoice (o una Transaction unificata): fatti operativi che guidano i KPI
- KPI Metric: definizioni come % consegna puntuale, tasso difetti, tempo di risposta
- Score: risultato calcolato per un fornitore in un periodo (complessivo e/o per metrica)
- Review: feedback qualitativo, valutazioni e evidenze narrative
- Attachment: file collegati a recensioni o dispute (email, foto, PDF)
Questo set supporta sia performance “dure” misurate sia feedback “morbidi” degli utenti, che tipicamente richiedono workflow differenti.
Relazioni (come i dati si connettono)
Modella esplicitamente le relazioni:
- Vendor → Contracts: un vendor può avere più contratti nel tempo.\n- Vendor → Orders/Invoices: le transazioni sono solitamente molti-a-uno rispetto al vendor.\n- Score → Metric: i punteggi devono essere ricondotti alla definizione della metrica e alla versione di calcolo.\n- Review → Period: le recensioni hanno bisogno di un periodo temporale chiaro (mese/trimestre) così non galleggiano senza contesto.
Un approccio comune è:
scorecard_period(es. 2025-10)vendor_period_score(complessivo)vendor_period_metric_score(per metrica, include numeratore/denominatore se applicabile)
Campi che ti faranno comodo in seguito
Aggiungi campi di consistenza across tabelle:
- Timestamp:
created_at,updated_at, e per approvazionisubmitted_at,approved_at - Autore e attore:
created_by_user_id, piùapproved_by_user_iddove rilevante - Sistema sorgente:
source_systeme identificatori esterni comeerp_vendor_id,crm_account_id,erp_invoice_id - Confidenza/qualità: un campo
confidenceodata_quality_flagper segnalare feed incompleti o stime
Questi supportano tracce di audit, gestione dispute e analytics procurement affidabili.
Conservazione, versioning e “cosa è cambiato?”
I punteggi cambiano perché i dati arrivano in ritardo, le formule evolvono o qualcuno corregge un mapping. Invece di sovrascrivere la storia, conserva versioni:
- Mantieni una versione del punteggio (o
calculation_run_id) su ogni riga di score.\n- Registra reason codes per i ricalcoli (fattura in ritardo, aggiornamento definizione KPI, correzione manuale).\n- Considera una traccia di audit append-only per tabelle importanti (scores, reviews, approvals) così puoi mostrare chi ha cambiato cosa e quando.
Per la retention, definisci quanto a lungo conservi le transazioni raw vs. i punteggi derivati. Spesso si conservano i punteggi derivati più a lungo (spazio minore, alto valore per il reporting) e gli estratti ERP per un periodo di policy più breve.
Strategia degli identificatori per matching ERP/CRM
Tratta gli ID esterni come campi di prima classe, non come note:
- Memorizza sia external ID che system name (ERP_A vs ERP_B).\n- Applica unicità per sistema sorgente (es.
unique(source_system, external_id)).\n- Aggiungi tabelle di mapping leggere quando i vendor si uniscono/dividono così i punteggi storici restano accurati.
Questa base facilita le sezioni successive—integrazioni, monitoraggio KPI, moderazione delle recensioni e auditabilità—da implementare e spiegare.
Ingestione dati e integrazioni
Un’app di scoring fornitore è valida quanto gli input che la alimentano. Pianifica più percorsi di ingest fin da subito, anche se parti con uno solo. La maggior parte dei team necessita di una combinazione di inserimento manuale per casi limite, upload bulk per storici e sync via API per aggiornamenti continui.
Fonti dati comuni
Inserimento manuale è utile per fornitori piccoli, incidenti isolati o quando un team deve registrare subito una recensione.
Upload CSV ti aiuta a bootstrapare il sistema con performance passate, fatture, ticket o record di consegna. Rendi gli upload prevedibili: pubblica un template e versionalo così i cambiamenti non rompono gli import silenziosamente.
API sync tipicamente si connette a ERP/strumenti procurement (PO, ricevute, fatture) e a sistemi di servizio come helpdesk (ticket, violazioni SLA). Preferisci sync incrementale (da ultimo cursore) per evitare di tirare sempre tutto.
Validazione che evita spazzatura in ingresso
Applica regole chiare in fase di import:
- Campi richiesti (vendor ID, data, nome/valore metrica)\n- Range numerici (es. 0–100, quantità non negative)\n- Rilevamento duplicati (stesso vendor + metrica + periodo + source record ID)
Conserva le righe invalide con messaggi di errore così gli admin possono correggere e ricaricare senza perdere contesto.
Correzioni, backfill e log dei ricalcoli
Gli import saranno a volte errati. Supporta re-run (idempotenti per source IDs), backfill (periodi storici) e log di ricalcolo che registrano cosa è cambiato, quando e perché. Questo è cruciale per la fiducia quando il punteggio di un fornitore si sposta.
Scheduling e trasparenza
La maggior parte dei team va bene con import giornalieri/settimanali per metriche finanziarie e di consegna, più eventi near-real-time per incidenti critici.
Espone una pagina admin-friendly di import (es. /admin/imports) che mostri stato, conteggi righe, warning e gli errori esatti—così i problemi sono visibili e correggibili senza aiuto degli sviluppatori.
Ruoli, permessi e workflow di approvazione
Reduce Your Build Cost
Riduci i costi di sviluppo ottenendo crediti creando contenuti su Koder.ai o invitando colleghi e partner.
Ruoli chiari e un percorso di approvazione prevedibile prevengono la “caos delle schede”: modifiche in conflitto, cambiamenti di valutazione a sorpresa e incertezza su cosa il fornitore può vedere. Definisci regole di accesso presto e poi applicale coerentemente in UI e API.
Tipi di ruolo (e a cosa servono)
Un set pratico iniziale di ruoli:
- Admin: gestisce impostazioni organizzazione, assegnazioni ruoli, template di scoring e regole di moderazione.
- Internal Reviewer: invia recensioni, evidenze e bozze di aggiornamento dei punteggi.
- Approver: valida azioni sensibili (pubblicazione recensioni, blocco periodi, approvazione modifiche punteggi).
- Vendor User: visualizza la propria scheda, risponde alle recensioni, carica chiarimenti (se permesso).
- Read-only: può vedere dashboard e profili fornitore ma non modificare.
Permessi che mappano azioni reali
Evita permessi vaghi come “può gestire fornitori”. Controlla capacità specifiche:
- Visualizzazione: chi può vedere recensioni, nomi dei revisori, allegati e punteggi storici.\n- Modifica: chi può creare/modificare bozze, cambiare valori KPI o aggiustare pesi.\n- Pubblicazione: chi può muovere contenuto da bozza a visibile.\n- Esportazione: chi può scaricare report (CSV/PDF) e con quale ambito (singolo fornitore vs tutti i fornitori).
Considera di dividere “export” in “export propri fornitori” vs “export tutti” specialmente per analytics procurement.
Regole di visibilità per i fornitori
I Vendor Users dovrebbero tipicamente vedere solo i propri dati: i loro punteggi, recensioni pubblicate e lo stato degli elementi aperti. Limita i dettagli sull’identità dei revisori per default (es. mostra reparto o ruolo invece del nome completo) per ridurre attriti interpersonali. Se permetti risposte del fornitore, mantienile threadate e chiaramente etichettate come fornite dal fornitore.
Flussi di approvazione per fiducia e coerenza
Tratta recensioni e modifiche dei punteggi come proposte fino all’approvazione:
- L’Internal Reviewer invia una bozza di recensione/aggiornamento punteggio.\n- L’Approver controlla le evidenze, verifica la policy e approva, richiede modifiche o rifiuta.\n- Solo gli elementi approvati influenzano il punteggio “corrente” e diventano visibili ai Vendor Users.
I workflow con vincoli temporali aiutano: per esempio, le modifiche ai punteggi possono richiedere approvazione solo durante la chiusura mensile/trimestrale.
Requisiti per la traccia di audit
Per compliance e responsabilità, registra ogni evento significativo: chi ha fatto cosa, quando, da dove e cosa è cambiato (valori prima/dopo). Le voci di audit dovrebbero coprire cambi permessi, modifiche recensioni, approvazioni, pubblicazioni, esportazioni ed eliminazioni. Rendi la traccia ricercabile, esportabile per audit e protetta da manomissione (append-only o log immutabili).
UX e schermate core
Iterate Without Fear
Testa i cambi di scoring in sicurezza con snapshot e rollback quando pesi o KPI cambiano.
Un’app di scoring fornitore ha successo o fallisce in base a se gli utenti occupati riescono a trovare il fornitore giusto rapidamente, capire il punteggio a colpo d’occhio e lasciare feedback affidabili senza attrito. Inizia con un piccolo set di schermate “home base” e rendi ogni numero spiegabile.
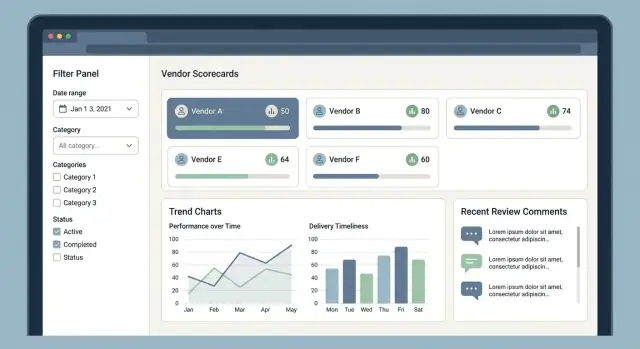
1) Lista fornitori (il centro di comando)
Qui iniziano la maggior parte delle sessioni. Mantieni layout semplice: nome fornitore, categoria, regione, fascia di punteggio corrente, stato e ultima attività.
Filtri e ricerca dovrebbero essere istantanei e prevedibili:
- Categoria, regione, stato (attivo/in sospeso/bloccato)\n- Intervallo di date (es. ultima review, ultimo incidente di consegna)\n- Fascia di punteggio (A/B/C o intervalli 0–100)
Salva viste comuni (es. “Fornitori critici in EMEA sotto 70”) così i team non ricreano filtri ogni giorno.
2) Profilo fornitore (una pagina, molte risposte)
Il profilo dovrebbe riassumere “chi sono” e “come vanno”, senza costringere gli utenti a navigare troppi tab. Metti i contatti e i metadati contrattuali vicino a un riepilogo chiaro del punteggio.
3) Scheda valutazione con drill-down sul “perché”
Mostra il punteggio complessivo e la ripartizione KPI (qualità, consegna, costo, conformità). Ogni KPI necessita una fonte visibile: le recensioni, gli issue o le metriche che l’hanno prodotto.
Un buon pattern è:
- KPI → formula/peso → elementi contributivi → evidenze (commenti, allegati, timestamp)
4) Recensioni e issue (inserimento veloce, contesto forte)
Rendi l’inserimento delle recensioni mobile-friendly: target touch grandi, campi brevi e commenti rapidi. Collega sempre le recensioni a un intervallo temporale e (se rilevante) a un PO, sito o progetto così il feedback resta azionabile.
5) Report (pronti per decisioni)
I report dovrebbero rispondere a domande comuni: “Quali fornitori stanno peggiorando?” e “Cosa è cambiato questo mese?” Usa grafici leggibili, etichette chiare e navigazione da tastiera per accessibilità.
Recensioni, commenti e moderazione
Le recensioni sono dove l’app diventa davvero utile: catturano contesto, evidenze e il “perché” dietro i numeri. Per mantenerle coerenti (e difendibili), tratta le recensioni prima come record strutturati e poi come testo libero.
Tipi di recensione da supportare
Momenti diversi richiedono template diversi. Un set semplice di partenza:
- Recensioni periodiche (mensili/trimestrali): cadenza regolare per performance e trend.\n- Recensioni basate su incidenti: legate a una consegna in ritardo, un difetto qualità o un problema di compliance.\n- Recensioni di chiusura progetto: riepilogo di fine impegno con lezioni apprese.
Ogni tipo può condividere campi comuni ma permettere domande specifiche così i team non forzano un incidente in un modulo trimestrale.
Campi strutturati: rendi le recensioni ricercabili
Accanto al commento narrativo, includi input strutturati che guidano filtraggio e reporting:
- Tag e categorie (es. Logistica, Qualità, Comunicazione)\n- Punti di forza e gap (campi separati per evitare feedback unilaterale)\n- Azioni con proprietario, scadenza e stato
Questa struttura trasforma il feedback in lavoro tracciabile, non solo testo in una casella.
Gestione delle evidenze (senza renderla pesante)
Permetti di allegare prove nello stesso punto in cui si scrive la recensione:
- Allegati file (foto, PDF)\n- Link a documenti condivisi\n- Riferimenti a ticket / PO / ordini (idealmente selezionabili da una lista)
Memorizza metadata (chi ha caricato, quando, a cosa si riferisce) così gli audit non diventano una caccia al tesoro.
Moderazione e cronologia delle modifiche
Anche gli strumenti interni richiedono moderazione. Aggiungi:
- Controlli base su linguaggio offensivo/spam\n- Regole di escalation per accuse serie (es. sicurezza, frode)\n- Una cronologia modifiche che registra cosa è cambiato e da chi (incluse redazioni)
Evita modifiche silenziose—la trasparenza protegge sia revisori che fornitori.
Notifiche, promemoria e SLA di risposta
Definisci regole di notifica fin da subito:
- Avvisa i fornitori quando una recensione è pubblicata (o quando è richiesta una loro risposta)\n- Invia promemoria interni per azioni scadute\n- Imposta un SLA per le risposte (es. 5 giorni lavorativi) con escalation dopo scadenze mancate
Fatelo bene e le recensioni diventano un workflow a ciclo chiuso invece che un reclamo occasionale.
Architettura e scelta tech
Prepare for Real Data
Crea flussi admin preparati per l'import che validano CSV e dati API prima che arrivino al calcolo dei punteggi.
La prima decisione architetturale riguarda meno la “tecnologia più recente” e più quanto velocemente puoi consegnare una piattaforma affidabile per scoring e recensioni senza creare un onere di manutenzione.
Se l’obiettivo è muoversi in fretta, considera di prototipare il workflow (fornitori → schede → recensioni → approvazioni → report) su una piattaforma che genera un'app funzionante da una specifica chiara. Per esempio, Koder.ai è una piattaforma vibe-coding dove puoi costruire web, backend e app mobile tramite un'interfaccia chat, poi esportare il codice sorgente quando sei pronto. È un modo pratico per convalidare il modello di scoring e i ruoli/permessi prima di investire pesantemente in UI e integrazioni.
Monolite vs servizi modulari (mantienilo semplice)
Per la maggior parte dei team, un monolite modulare è il punto d’incontro ideale: un'app distribuibile, ma organizzata in moduli chiari (Vendors, Scorecards, Reviews, Reporting, Admin). Ottieni sviluppo e debug più semplici, oltre a deployment e sicurezza più lineari.
Muoviti verso servizi separati solo quando hai una ragione forte—es. carichi pesanti di reporting, più team di prodotto o requisiti di isolamento stretti. Un percorso comune è: monolite ora, poi estrai “imports/reporting” più tardi se necessario.
Design API (REST che rispecchia il lavoro reale)
Una REST API è generalmente la più semplice da ragionare e integrare con strumenti procurement. Punta a risorse prevedibili e pochi endpoint “task” dove il sistema fa lavoro reale.
Esempi:
/api/vendors(create/update vendor, status)\n-/api/vendors/{id}/scores(punteggio corrente, scomposizione storica)\n-/api/vendors/{id}/reviews(lista/crea recensioni)\n-/api/reviews/{id}(aggiorna, azioni di moderazione)\n-/api/exports(richiedi export; ritorna job id)
Tieni operazioni pesanti (export, ricalcoli bulk) asincrone così la UI resta reattiva.
Job in background (import, ricalcoli, notifiche)
Usa una coda di job per:
- importare dati fornitori (CSV/SFTP/API)\n- ricalcolare punteggi quando KPI, pesi o recensioni cambiano\n- inviare notifiche (richiesta review, cambio punteggio, approvazione necessaria)
Questo ti aiuta anche a ritentare fallimenti senza intervento manuale.
Caching per dashboard e report pesanti
I dashboard possono essere costosi. Cache le metriche aggregate (per intervallo data, categoria, unità di business) e invalida su cambiamenti significativi, o aggiorna su programma. Questo mantiene la dashboard veloce preservando dati di drill-down accurati.
Documentazione (per sviluppatori e admin)
Scrivi API docs (OpenAPI/Swagger va bene) e mantieni una guida interna per admin in formato blog—es. “Come funziona lo scoring”, “Come gestire dispute”, “Come eseguire export”—e linkala dall'app a /blog così è facile da trovare e aggiornare.
Domande frequenti
How do I define the scope so the vendor scoring app doesn’t try to satisfy everyone at once?
Inizia nominando un unico “utente core” e ottimizzando la prima release per il suo flusso di lavoro (spesso procurement). Scrivi:
- La decisione che prende (es. rinnovare vs sostituire un fornitore)
- Gli input di cui si fida (KPI, incidenti, fatture, recensioni)
- Gli output di cui ha bisogno (scheda valutazione, vista comparativa, traccia di audit)
Aggiungi funzionalità per finance/operations solo quando puoi spiegare chiaramente quale nuova decisione abilitano.
What should “vendor” mean in the system—company, site, or service line?
Scegli una definizione all'inizio e progetta il modello dei dati attorno a essa:
- Entità legale: migliore per decisioni a livello di contratto e report consolidati.
- Sito/ubicazione: migliore quando qualità o consegne variano per impianto/regione.
- Linea di servizio: migliore quando lo stesso fornitore fornisce servizi diversi con risultati differenti.
Se non sei sicuro, modella il fornitore come un genitore con “unità fornitore” figlie (siti/linee di servizio) così puoi consolidare o approfondire in seguito.
Should we use weighted KPIs, rubric scoring, or a hybrid model?
Usa KPI ponderati quando hai dati operativi affidabili e vuoi automazione e trasparenza. Usa rubriche quando la performance è per lo più qualitativa o incoerente tra team.
Un default pratico è ibrido:
- KPI per consegna/qualità/costo/SLA
- Domande a rubrica per collaborazione, reattività e fit strategico
Qualunque sia la scelta, rendi il metodo spiegabile a revisori e fornitori.
What’s a good “starter” KPI set for vendor performance scoring?
Inizia con un set ridotto che la maggior parte degli stakeholder riconosce e può misurare in modo coerente:
- Consegna puntuale
- Qualità (difetti/resi/percentuale superamento ispezione)
- Aderenza SLA (ticket nei tempi target)
- Variazione di costo (fattura vs PO)
- Reattività (tempo alla prima risposta/risoluzione)
Per ogni KPI, documenta definizione, scala e fonte dati prima di costruire UI o report.
How do we design rating scales that different teams interpret the same way?
Scegli una scala che le persone possano spiegare a voce (comunemente 1–5 o 0–100) e definisci le soglie in linguaggio chiaro.
Esempio:
- On-time delivery: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%
Evita numeri basati su “sensazioni”. Soglie chiare riducono i disaccordi tra revisori e rendono le comparazioni più eque.
How should we handle missing KPI data without making scoring unfair?
Scegli e documenta una policy per KPI (applicala coerentemente):
- Escludere dal denominatore per quel periodo (comune quando i dati non sono disponibili)
- Valore neutro predefinito (usalo con cautela—può nascondere lacune reali)
- Segnalazione insufficiente e blocco del ranking/benchmarking
Conserva anche un indicatore di qualità dei dati (es. ) così i report possono distinguere “scarsa performance” da “prestazione sconosciuta”.
What’s the best way to handle disputes and score corrections?
Tratta le dispute come un workflow con esiti tracciabili:
- Marca la metrica/recensione come disputed senza cambiare la storia in modo silente
- Consenti di proporre una correzione con evidenza
- Ricalcola solo dopo l’approvazione e conserva una nota che spiega la modifica
Mantieni un identificatore di versione (es. calculation_run_id) così puoi rispondere in modo affidabile a “cosa è cambiato dall’ultimo trimestre?”.
What core entities should the database include for a vendor scoring app?
Uno schema minimo solido tipicamente include:
- Vendor, Contract, Transaction (ordini/fatture), definizione KPI
- Review (qualitativa), Score (complessivo), Metric Score (per KPI)
- Attachment (evidenza)
Aggiungi campi per tracciabilità: timestamp, ID attore, sistema di origine + ID esterni, e un riferimento versione/punteggio così ogni numero può essere spiegato e riprodotto.
How do we prevent “garbage in” when importing from ERP/CSV/API sources?
Prevedi più vie di ingest anche se inizi da una sola:
- Inserimento manuale per edge case
- Upload CSV per bootstrap storico
- Sync via API per aggiornamenti continui
Durante l’import, applica campi obbligatori, range numerici e rilevamento duplicati. Conserva le righe non valide con messaggi di errore chiari così gli amministratori possano correggere e rieseguire senza perdere contesto.
What roles, permissions, and audit trail features are essential—especially with a vendor portal?
Usa accesso basato sui ruoli e tratta le modifiche come proposte:
- I reviewer creano bozze (recensioni, aggiornamenti KPI)
- Gli approver pubblicano/bloccano i periodi così i punteggi restano stabili
- I Vendor users vedono solo le proprie schede pubblicate e le risposte threadate
Registra ogni evento significativo (modifiche, approvazioni, esportazioni, cambi permessi) con valori prima/dopo. Questo protegge la fiducia e semplifica le verifiche—soprattutto quando i fornitori possono visualizzare o rispondere.