26 lug 2025·8 min
Come costruire una web app per monitorare le eccezioni dei processi aziendali
Scopri i passaggi per progettare, costruire e lanciare una web app che registra, instrada e risolve le eccezioni di processo aziendale con workflow chiari e report.
Cosa sono le eccezioni dei processi aziendali (e perché tracciarle)
Un'eccezione del processo aziendale è qualsiasi cosa interrompa il “percorso felice” di un flusso di lavoro di routine: un evento che richiede attenzione umana perché le regole standard non lo coprono o perché qualcosa è andato storto.
Considera le eccezioni come l'equivalente operativo degli “edge case”, ma per il lavoro quotidiano.
Esempi concreti
Le eccezioni compaiono in quasi tutti i reparti:
- Differenza sulla fattura: il totale della fattura non corrisponde all'ordine d'acquisto, le quantità differiscono o manca una riga.
- Approvazione mancante: un contratto è eseguito senza la firma corretta, o una spesa è inviata oltre il limite senza approvazione.
- Spedizione in ritardo: la consegna non ha rispettato la data promessa, è arrivata una spedizione parziale, o è stato inviato l'SKU sbagliato.
Questi non sono rari. Sono comuni — e creano ritardi, rifacimenti e frustrazione quando non hai un modo chiaro per catturarli e risolverli.
Perché fogli di calcolo e thread email falliscono
Molte squadre iniziano con un foglio condiviso più email o chat. Funziona — finché non smette di funzionare.
Una riga di foglio può dirti cosa è successo, ma spesso perde il resto:
- Contesto perso: dettagli chiave sono nelle caselle di posta (screenshot, risposte dei fornitori, approvazioni), non collegati al record.
- Nessuna proprietà chiara: la gente presume che qualcun altro se ne stia occupando, specialmente quando le eccezioni attraversano team.
- Storia debole: è difficile vedere chi ha cambiato cosa e perché, cosa importante quando sorgono domande in seguito.
Col tempo il foglio diventa un miscuglio di aggiornamenti parziali, voci duplicate e campi “stato” di cui nessuno si fida.
Cosa ottieni tracciando le eccezioni correttamente
Una semplice app per tracciare eccezioni (un registro incidenti/problemi adattato al tuo processo) crea valore operativo immediato:
- Risoluzione più rapida: la persona giusta viene notificata, le informazioni di supporto restano con l'eccezione e lo stato è visibile.
- Meno ripetizioni: emergono pattern (stesso fornitore, stesso step, stesso gap di approvazione) così puoi risolvere le cause alla radice.
- Responsabilità chiara: ogni eccezione ha un proprietario, scadenze (SLA/obiettivi) e un risultato documentato.
Imposta aspettative: parti semplice e iterare
Non ti serve un workflow perfetto dal primo giorno. Inizia catturando il minimo indispensabile: cosa è successo, chi ne è responsabile, stato corrente e passo successivo — poi fatti evolvere campi, instradamento e report man mano che capisci quali eccezioni si ripetono e quali dati guidano davvero le decisioni.
Definisci utenti, ambito e metriche di successo
Prima di disegnare schermate o scegliere strumenti, chiarisci a chi serve l'app, cosa coprirà nella versione 1 e come capirai che sta funzionando. Questo evita che un “tracker di eccezioni” diventi un generico sistema di ticketing.
Identifica i ruoli principali
La maggior parte dei workflow di eccezione richiede pochi attori chiari:
- Requester: registra l'eccezione e fornisce il contesto (cosa è successo, quando, impatto).
- Approver: decide se l'eccezione è accettabile e a quali condizioni.
- Resolver: risolve il problema, esegue la soluzione alternativa o aggiorna i dati.
- Process owner: responsabile del processo sottostante e delle azioni di prevenzione.
- Auditor/viewer: accesso in sola lettura per supervisione e controlli di conformità.
Per ogni ruolo, annota 2–3 permessi chiave (creare, approvare, riassegnare, chiudere, esportare) e le decisioni di cui sono responsabili.
Chiarisci gli obiettivi
Mantieni gli obiettivi pratici e osservabili. Obiettivi comuni includono:
- Catturare le eccezioni in modo coerente (stesso minimo di dati ogni volta).
- Assegnare responsabilità chiare in modo che nulla resti fermo.
- Documentare le decisioni (perché un'eccezione è stata approvata/respinta e da chi).
- Ridurre le ripetizioni tracciando causa radice e azioni preventive.
Decidi cosa è in scope per la v1
Scegli 1–2 workflow ad alto volume dove le eccezioni sono frequenti e il costo del ritardo è reale (es.: discrepanze di fatture, blocchi d'ordine, onboarding con documenti mancanti). Evita di partire con “tutti i processi aziendali”. Un ambito ristretto ti permette di standardizzare categorie, stati e regole di approvazione più rapidamente.
Scrivi 3–5 metriche di successo
Definisci metriche misurabili da subito:
- Tempo di risoluzione (mediana, e % entro SLA)
- Tasso di riapertura (qualità della chiusura)
- Volume di eccezioni per tipo (principali cause)
- Tempo ciclo approvazione (richiesta → decisione)
- Eccezioni ripetute collegate alla stessa causa radice
Queste metriche diventano la baseline per iterare e giustificare automazioni future.
Mappa il ciclo di vita dell'eccezione e gli stati
Un ciclo di vita chiaro mantiene tutti allineati su dove si trova un'eccezione, chi ne è responsabile e cosa dovrebbe succedere dopo. Mantieni pochi stati non ambigui e legali ad azioni reali.
Un ciclo pratico di default
Created → Triage → Review → Decision → Resolution → Closed
- Created: l'eccezione è registrata con i dettagli minimi.
- Triage: qualcuno la valida, assegna proprietà e imposta l'urgenza.
- Review: il team giusto raccoglie evidenze e valuta opzioni.
- Decision: approvare/negare l'eccezione (o richiedere modifiche) con razionale registrato.
- Resolution: l'azione correttiva viene eseguita e verificata.
- Closed: il record è finalizzato per report e audit.
Definisci il “done” con criteri di ingresso/uscita
Scrivi cosa deve essere vero per entrare ed uscire da ogni fase:
- Created (exit): campi richiesti completi; categoria selezionata; requester identificato.
- Triage (exit): owner assegnato; impatto + data di scadenza impostati; duplicati controllati.
- Review (exit): evidenze allegate; stakeholder consultati; raccomandazione documentata.
- Decision (exit): decisione registrata; approvatore identificato; condizioni (se presenti) catturate.
- Resolution (exit): azioni completate; risultato validato; SLA rispettato o motivo del breach registrato.
- Closed (exit): note finali aggiunte; nessuna attività aperta; audit trail completo.
Regole di escalation per evitare stallo
Aggiungi escalation automatica quando un'eccezione è scaduta (oltre data di scadenza/SLA), bloccata (dipendenza esterna troppo a lungo) o ad alto impatto (soglia di severità). L'escalation può notificare un manager, riallocare a un livello di approvazione superiore o aumentare la priorità.
Riapertura e gestione dei duplicati
- Riapri quando la stessa eccezione ricompare (es.: la soluzione non ha funzionato). Richiedi una motivazione e rimanda a Triage o Review.
- Duplicato quando due record descrivono lo stesso problema sottostante. Marca uno come “primario”, collega i duplicati e chiudi i duplicati con esito “Merged” così i report restano accurati.
Progetta il modello dati e i campi richiesti
Un buon tracker di eccezioni si regge sul modello dati. Se la struttura è troppo libera, il reporting diventa inaffidabile. Se è troppo rigida, gli utenti non inseriranno dati in modo coerente. Punta a pochi campi obbligatori e a un set più ampio di campi opzionali ben definiti.
Entità core da includere
Inizia con alcuni record fondamentali che coprono la maggior parte degli scenari:
- Exception: il record principale (cosa è successo, dove e cosa serve per risolverlo).
- Comment: discussioni, chiarimenti e aggiornamenti di progresso.
- Attachment: screenshot, PDF, email, esportazioni.
- Task: azioni discrete assegnate a proprietari specifici.
- Decision: approvazioni/respinti, eccezioni di policy o decisioni di chiusura.
- Category: lista controllata che mantiene pulito il reporting.
- User: reporter, assegnatari, approvatori e viewer.
Campi obbligatori (mantienili pochi)
Rendi obbligatori questi su ogni Exception:
- Title e description (linguaggio semplice: cosa è successo e perché conta)
- Category
- Impact (es.: finanziario, cliente, conformità, operativo)
- Process area (es.: fatturazione, fulfillment, resi)
- Due date (o data target di risoluzione)
Valori strutturati da standardizzare
Usa valori controllati invece di testo libero per:
- Status (Created, Triage, Review, Decision, Resolution, Closed)
- Priority (Low/Medium/High/Urgent)
- Root cause (Errore umano, difetto di sistema, dati mancanti, problema fornitore, policy non chiara)
- Resolution type (Dati corretti, rimborso emesso, workaround, processo aggiornato, formazione, nessuna azione)
Collegamenti e tracciabilità
Prevedi campi per connettere eccezioni a oggetti aziendali reali:
- Riferimenti record interessati (Order ID, invoice ID, customer ID)
- ID sistemi esterni (ticket ERP, case CRM)
- Eccezioni correlate (duplicati, pattern ricorrenti, parent/child)
Questi collegamenti rendono più semplice individuare problemi ripetuti e costruire report accurati in seguito.
Pianifica l'esperienza utente e le schermate core
Un buon tracker di eccezioni sembra una casella condivisa: tutti vedono rapidamente cosa richiede attenzione, cosa è bloccato e cosa è scaduto. Parti disegnando poche schermate che coprono il 90% del lavoro quotidiano, poi aggiungi funzionalità avanzate (reporting, integrazioni).
Schermate principali da progettare prima
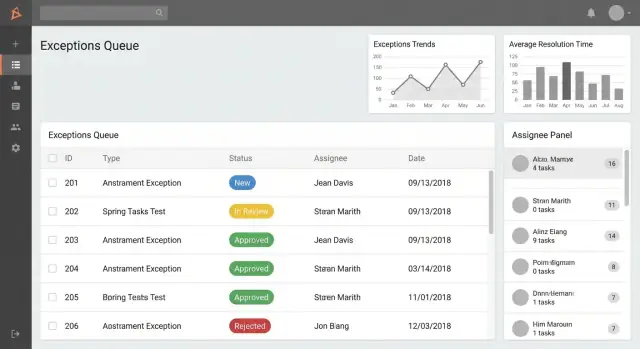
1) Elenco eccezioni / coda (home)
Qui gli utenti vivono. Rendila veloce, scansionabile e orientata all'azione.
Crea code basate sui ruoli come:
- Le mie eccezioni (create da me o assegnate a me)
- Richiede la mia approvazione (elementi in attesa di decisione)
- Scadute (oltre SLA o data target)
Aggiungi ricerca e filtri che rispecchiano il modo in cui la gente parla del lavoro:
- Stato, categoria, area di processo
- Intervallo di date (creato, scadenza, chiuso)
- Assegnatario / team
2) Form per creare eccezione
Mantieni il primo passo leggero: pochi campi obbligatori, con dettagli opzionali sotto “Altro”. Considera salvataggi come bozze e “assegnatario sconosciuto” per evitare scorciatoie.
3) Pagina dettaglio eccezione
Deve rispondere a “Cosa è successo? Cosa succede dopo? Chi è il proprietario?” Includi:
- Riepilogo, stato, proprietario/assegnatario, data di scadenza/SLA
- Azioni principali chiare (Assegna, Richiedi approvazione, Chiudi)
- Un pannello laterale per metadata chiave
Collaborazione essenziale (senza trasformare tutto in chat)
Includi:
- Commenti con @mention per chiamare le persone giuste
- Allegati per le evidenze (screenshot, PDF)
- Una timeline attività che registra cambiamenti (aggiornamenti di stato, riassegnazioni, approvazioni) così gli utenti non devono chiedere “chi ha cambiato questo?”
Impostazioni admin (minime ma necessarie)
Fornisci un'area admin per gestire categorie, aree di processo, target SLA e regole di notifica — così i team operativi possono evolvere l'app senza un redeploy.
Scegli approccio tecnico e architettura
Rendi le decisioni verificabili
Inizia con log delle attività, note decisionali e allegati così le revisioni diventano semplici.
Qui bilanci velocità, flessibilità e manutenibilità a lungo termine. La risposta “giusta” dipende dalla complessità del ciclo di vita delle eccezioni, da quanti team useranno lo strumento e da quanto rigorosi sono i requisiti di audit.
Tre approcci pratici per costruire
1) Custom build (controllo totale). Costruisci UI, API, database e integrazioni da zero. Funziona quando servono workflow su misura (routing, SLA, audit trail, integrazioni ERP/ticketing) e prevedi di far evolvere il processo. Contro: costo iniziale più alto e necessità di supporto ingegneristico continuo.
2) Low-code (più rapido da lanciare). Builder interni creano form, tabelle e approvazioni di base rapidamente. Ideale per un pilot o rollout in un singolo dipartimento. Contro: limiti su permessi complessi, reporting personalizzato, performance a scala o portabilità dei dati.
3) Vibe-coding / build assistita da agenti (iterazione rapida con codice reale). Se vuoi velocità senza rinunciare a una base di codice mantenibile, una piattaforma come Koder.ai può aiutare a creare una web app funzionante da una specifica conversazionale — poi esportare il codice sorgente quando serve controllo completo. Team comuni la usano per generare rapidamente l'interfaccia React e un backend Go + PostgreSQL, iterare in “planning mode” e usare snapshot/rollback mentre il workflow si stabilizza.
Un'architettura semplice e scalabile
Punta a una chiara separazione delle responsabilità:
- Web UI per inviare, revisionare e risolvere eccezioni
- API che applica validazioni, permessi e regole di workflow
- Database che conserva eccezioni, commenti, metadati allegati, decisioni, task e eventi di audit
- Background jobs per notifiche, escalation, timer SLA e report pianificati
Questa struttura resta comprensibile con la crescita e facilita l'aggiunta di integrazioni.
Hosting e ambienti
Pianifica almeno dev → staging → prod. Lo staging dovrebbe rispecchiare prod (soprattutto auth e email) per testare routing, SLA e report in sicurezza prima del rilascio.
Se vuoi ridurre l'operatività iniziale, considera una piattaforma che include deployment e hosting (Koder.ai, per esempio, offre deployment/hosting, domini personalizzati e regioni AWS globali) — poi valuta una soluzione su misura una volta provato il workflow.
Costi e compromessi di complessità
Low-code riduce il time-to-first-version, ma esigenze di personalizzazione e conformità possono aumentare i costi dopo (soluzioni alternative, add-on, vincoli del fornitore). I custom build costano di più all'inizio, ma possono risultare più economici sul lungo periodo se la gestione delle eccezioni è centrale per le operazioni. Un percorso intermedio — lanciare velocemente, validare il workflow e mantenere una chiara via di migrazione (es.: esportazione del codice) — spesso offre il miglior rapporto costo/controllo.
Configura autenticazione, ruoli e controllo accessi
I record di eccezione spesso contengono dettagli sensibili (nomi clienti, rettifiche finanziarie, violazioni di policy). Se l'accesso è troppo permissivo rischi problemi di privacy e “modifiche in ombra” che indeboliscono la fiducia nel sistema.
Accesso e sessioni sicure
Parti da soluzioni di autenticazione consolidate invece di costruire password da zero. Se l'organizzazione ha già un identity provider, usa SSO (SAML/OIDC) così gli utenti usano l'account di lavoro e erediti controlli come MFA e offboarding degli account.
Indipendentemente dall'SSO o dal login email, gestisci le sessioni con cura: sessioni a vita breve, cookie sicuri, protezione CSRF per le app browser e logout automatico dopo inattività per ruoli a rischio. Registra eventi di autenticazione (login, logout, tentativi falliti) per poter investigare attività insolite.
Ruoli e permessi (cosa può fare ciascuno)
Definisci i ruoli in termini aziendali e legali alle azioni nell'app. Un punto di partenza:
- Reporter: crea eccezioni, aggiunge note/allegati, vede i propri elementi
- Assignee/Resolver: modifica campi, propone soluzioni, aggiorna stato
- Approver/Manager: approva o respinge, richiede più info, chiude elementi
- Admin: configura il sistema (non elabora operativamente)
Sii esplicito su chi può cancellare. Molte squadre disabilitano le cancellazioni hard e permettono solo agli admin di archiviare, preservando la storia.
Accesso a livello di record (chi vede cosa)
Oltre ai ruoli, aggiungi regole che limitano la visibilità per reparto, team, sede o area di processo. Pattern comuni:
- Gli utenti vedono gli elementi che hanno creato e quelli assegnati al loro team
- I manager vedono tutti gli elementi nella loro unità organizzativa
- Ruoli compliance/audit vedono trasversalmente in sola lettura
Questo evita "browsing" indiscriminato mantenendo la collaborazione.
Capacità admin necessarie
Gli admin dovrebbero poter gestire categorie e sottocategorie, regole SLA (date di scadenza, soglie di escalation), template di notifica e assegnazioni ruoli. Mantieni le azioni admin tracciabili e richiedi conferme elevate per modifiche ad alto impatto (es.: editing SLA), dato che influenzano report e responsabilità.
Costruisci workflow, instradamento e notifiche
Imposta escalation SLA
Prototipa regole e notifiche per gli scaduti, poi raffinane l'uso mano a mano che emergono i pattern di eccezione.
I workflow trasformano un semplice registro in un'app di cui ci si può fidare. L'obiettivo è movimento prevedibile: ogni eccezione deve avere un proprietario chiaro, il passo successivo e una scadenza.
Regole di instradamento: chi riceve cosa e quando
Inizia con poche regole di instradamento facili da spiegare. Puoi instradare per:
- Categoria (es.: qualità dati, deviazione policy, outage di sistema)
- Impatto (importo finanziario, numero clienti, severità)
- Area di processo (AP/AR, onboarding, fulfillment)
- Soglie (es.: “Importo > $10.000” o “Alta severità”)
Mantieni le regole determinate: se più regole corrispondono, definisci un ordine di priorità. Prevedi anche un fallback sicuro (es.: instrada alla coda “Exception Triage”) così nulla resta senza assegnazione.
Approvazioni: semplice, multi-step e override
Molte eccezioni necessitano di approvazione prima di essere accettate, rimediate o chiuse.
Progetta per due pattern comuni:
- Singolo approvatore: una persona approva/rigetta (più veloce da implementare).
- Approvazione multi-step: sequenza come Manager → Compliance → Finance.
Sii chiaro su chi può override (e in quali condizioni). Se sono permessi override, richiedi una motivazione e registrala nell'audit trail (es.: “Approvato per override a causa di rischio SLA”).
Notifiche che non generano rumore
Aggiungi notifiche email e in-app per i momenti che cambiano proprietà o urgenza:
- Assegnazione e riassegnazione
- Nuovi commenti o menzioni
- Richiesta approvazione / approvato / respinto
- Elementi scaduti e promemoria “in scadenza"
Lascia che gli utenti controllino notifiche opzionali, ma mantieni attive per default quelle critiche (assegnazione, scaduto).
Rendi il lavoro di risoluzione visibile con task/checklist
Le eccezioni spesso falliscono perché il lavoro avviene “a lato”. Aggiungi task o checklist leggeri legati all'eccezione: ogni task ha un proprietario, data di scadenza e stato. Questo rende il progresso tracciabile, migliora i passaggi di consegna e dà ai manager una vista in tempo reale di cosa blocca la chiusura.
Aggiungi reporting e dashboard operativi
Il reporting è dove un tracker di eccezioni smette di essere un “registro” e diventa uno strumento operativo. L'obiettivo è aiutare i leader a individuare pattern precocemente e aiutare i team a decidere cosa affrontare dopo — senza aprire ogni singolo record.
Report standard da includere
Inizia con pochi report che rispondono a domande comuni in modo affidabile:
- Volume nel tempo (giornaliero/settimanale/mensile): le eccezioni aumentano, diminuiscono o sono stagionali?
- Per categoria/causa: quali tipi di eccezioni creano più disturbo?
- Per team/owner: dove è concentrato il carico di lavoro?
- Per stato: quanto è in ciascuna fase (Created, Triage, Review, Decision, Resolution, Closed)?
Mantieni i grafici semplici (linee per trend, barre per suddivisioni). Il valore principale è la coerenza: gli utenti devono fidarsi che il report corrisponda alla lista eccezioni.
Monitoraggio performance e SLA
Aggiungi metriche operative che riflettono la salute del servizio:
- Tempo medio di risoluzione (e mediana, se possibile)
- Tasso di breach SLA (% di eccezioni oltre il target)
- Dimensione backlog (eccezioni aperte) e aging (da quanto tempo sono aperte)
Se memorizzi timestamp come created_at, assigned_at e resolved_at, queste metriche diventano semplici e spiegabili.
Drill-down, esportazioni e riepiloghi programmati
Ogni grafico dovrebbe consentire il drill-down: cliccare su una barra o segmento porta alla lista filtrata di eccezioni (es.: “Category = Shipping, Status = Open”). Questo mantiene le dashboard azionabili.
Per condivisione e analisi offline, fornisci esportazione CSV sia dalla lista che dai report chiave. Per stakeholder che vogliono visibilità regolare, aggiungi sommari programmati (email settimanali o digest in-app) che evidenziano cambi di trend, categorie principali e breach SLA, con riferimenti alle viste filtrate (es.: /exceptions?status=open&category=shipping).
Garantire auditabilità e basi di conformità
Se l'app influenza approvazioni, pagamenti, esiti per i clienti o report regolatori, dovrai rispondere a “Chi ha fatto cosa, quando e perché?”. Costruire auditabilità fin da subito evita retrofit costosi e dà fiducia che il record sia attendibile.
Cattura un log di attività incontestabile
Crea un log completo per ogni record di eccezione. Registra l'attore (utente o sistema), timestamp (con timezone), tipo di azione (creato, campo cambiato, transizione di stato) e i valori prima/dopo.
Mantieni il log append-only. Le modifiche devono aggiungere eventi invece di sovrascrivere la storia. Se devi correggere un errore, registra un evento di “correzione” con spiegazione.
Conserva decisioni con ragioni e prove
Approvazioni e rifiuti devono essere eventi di prima classe, non solo un cambio di stato. Cattura:
- Decisione (approved/denied/returned)
- Codice motivo + nota in testo libero (richiesta per decisioni chiave)
- Allegati (screenshot, PDF, email) e chi li ha caricati
Questo accelera le revisioni e riduce i ping-pong quando qualcuno chiede perché un'eccezione è stata accettata.
Regole di retention e cancellazione (definiscile intenzionalmente)
Definisci per quanto tempo sono conservati eccezioni, allegati e log. Per molte organizzazioni, un default prudente è:
- Conservare record e eventi di audit per un periodo fisso (es.: 3–7 anni)
- Limitare la cancellazione a un piccolo gruppo admin, con giustificazione obbligatoria
- Preferire la “soft delete” (nascondere dalle viste normali) mantenendo l'audit trail
Allinea la policy con governance interna e requisiti legali.
Progetta per revisioni e audit
Auditor e revisori hanno bisogno di velocità e chiarezza. Aggiungi filtri specifici per i controlli: per intervallo di date, owner/team, stato, codici motivo, breach SLA e esiti delle approvazioni.
Fornisci sommari stampabili ed esportabili che includano la storia immutabile (timeline eventi, note decisionali e lista allegati). Una buona regola: se non riesci a ricostruire tutta la storia dal record e dal suo log, il sistema non è pronto per l'audit.
Test, pilot e rollout
Collega eccezioni ai record
Mantieni la tracciabilità catturando ID di ordine, fattura e sistemi esterni su ogni eccezione.
Il testing e il rollout sono il momento in cui un tracker di eccezioni smette di essere “una bella idea” e diventa uno strumento affidabile. Concentrati sui flussi che avvengono ogni giorno, poi allarga il raggio.
Testa i flussi chiave end-to-end
Crea uno script di test semplice (anche un foglio è OK) che percorra l'intero ciclo di vita:
- Crea un'eccezione, allega un file e conferma che i campi richiesti sono obbligatori.
- Assegna alla persona/team giusto e verifica che possano visualizzarla subito.
- Percorsi di approvazione e rigetto: assicurati che ogni decisione catturi un motivo e timestamp.
- Chiudi l'eccezione e conferma che diventi di sola lettura (o con editing limitato) come previsto.
- Riaprila e verifica che la storia/audit mostri chiaramente cosa è cambiato.
Includi variazioni “reali”: cambio priorità, riassegnazioni ed elementi scaduti per verificare calcoli SLA e tempi di risoluzione.
Aggiungi validazione e gestione degli errori per evitare dati sporchi
La maggior parte dei problemi di reporting nasce da input incoerenti. Metti dei guardrail presto:
- Campi obbligatori (es.: area di processo, tipo eccezione, owner, data di scadenza)
- Limiti upload file (dimensione/tipo) con messaggi chiari
- Rilevamento duplicati (es.: stesso cliente/ordine/data) con opzione “collega a esistente”
- Gestione sicura di casi limite: assignee mancante, date invalide, utenti cancellati
Testa anche percorsi “sfortunati”: interruzioni di rete, sessioni scadute ed errori di permessi.
Esegui un pilot con un team alla volta
Scegli un team con volume sufficiente per imparare rapidamente, ma abbastanza piccolo da adattarsi in fretta. Pilot per 2–4 settimane, poi rivedi:
- I campi catturano ciò di cui la gente ha realmente bisogno?
- Gli stati corrispondono al modo in cui il lavoro avviene?
- Le notifiche sono utili o rumorose?
Apporta modifiche settimanali, ma blocca il workflow nell'ultima settimana per stabilizzarlo.
Rollout con un kit di lancio leggero
Mantieni il rollout semplice:
- Una pagina “Come usiamo l'app” (stati, regole di proprietà, SLA)
- Una breve sessione di formazione (15–30 minuti) più una registrazione
- Una checklist di lancio: accessi/ruoli, instradamento di default, template e contatto di supporto
Dopo il lancio, monitora adozione e salute del backlog giornalmente nella prima settimana, poi settimanalmente.
Mantieni, migliora e scala nel tempo
Rilasciare l'app è l'inizio del lavoro reale: mantenere il registro delle eccezioni accurato, veloce e allineato a come l'azienda opera.
Monitora uso e colli di bottiglia
Tratta il flusso di eccezioni come una pipeline operativa. Rivedi dove gli elementi si bloccano (per stato, team e owner), quali categorie dominano il volume e se gli SLA sono realistici.
Un controllo mensile semplice spesso basta:
- Tempo di risoluzione mediano e 90° percentile per categoria
- Conteggi “aging” (es.: aperti > 7/30/60 giorni)
- Tassi di riapertura e loop “rimandato indietro”
- Campi più spesso vuoti (segnale di frizione UX)
Usa questi risultati per ritarare definizioni di stato, campi obbligatori e regole di instradamento — senza aggiungere complessità continua.
Mantieni un backlog di iterazione
Crea un backlog leggero che catturi richieste da operatori, approvatori e compliance. Elementi tipici:
- Nuovi campi (solo quando servono davvero per report o decisioni)
- Automazioni (assegnazione automatica per categoria, default date di scadenza)
- Template per tipi comuni di eccezione
- Piccole correzioni UI che riducono la classificazione errata
Prioritizza cambiamenti che riducono il ciclo o prevengono eccezioni ricorrenti.
Integrazioni: parti in sicurezza, poi approfondisci
Le integrazioni possono moltiplicare il valore, ma aumentano anche rischi e manutenzione. Parti con link in sola lettura:
- Conserva ID record esterni (ERP/CRM/ticketing)
- Deep-link alla sorgente (es.: ordine, cliente, fattura)
Una volta stabile, passa a write-back selettivi (aggiornamenti di stato, commenti) e sincronizzazioni basate su eventi.
Assegna chiare responsabilità
Nomina proprietari per le parti che cambiano più spesso:
- Tassonomia delle categorie (e quando unire/ritirare categorie)
- Definizioni SLA e regole di escalation
- Regole workflow/instradamento e policy di notifica
Quando la proprietà è esplicita, l'app resta affidabile mentre il volume cresce e i team si riorganizzano.
Nota sulla velocità di sviluppo
Il tracking delle eccezioni raramente è “finito” — evolve mentre i team imparano cosa va prevenuto, automatizzato o scalato. Se prevedi frequenti cambi di workflow, scegli un approccio che renda l'iterazione sicura (feature flag, staging, rollback) e mantenga il controllo su codice e dati. Piattaforme come Koder.ai sono spesso usate per spedire una versione iniziale rapidamente (i piani Free/Pro bastano per i pilot), poi crescere verso Business/Enterprise man mano che governance, controllo accessi e requisiti di deployment diventano più stringenti.