Cos'è lo sharding (e cosa non è)
Lo sharding (detto anche partizionamento orizzontale) significa presentare alla tua applicazione quello che sembra un database unico e invece suddividere i suoi dati su più macchine, chiamate shard. Ogni shard contiene solo un sottoinsieme delle righe, ma insieme rappresentano l'intero dataset.
Una tabella logica, molti posti fisici
Un modello mentale utile è la differenza tra struttura logica e posizionamento fisico.
- Logico: hai ancora una tabella “Users” unica (stesse colonne, stesso significato).
- Fisico: le righe di quella tabella sono memorizzate in posti diversi—per esempio gli utenti con ID 1–1.000.000 su shard A e il successivo milione su shard B.
Dal punto di vista dell'app vuoi eseguire query come se fosse una tabella sola. Sotto il cofano, il sistema deve decidere a quale shard(i) parlare.
Non è replica, non è “compra una macchina più grande”
Lo sharding è diverso dalla replica. La replica crea copie degli stessi dati su più nodi, principalmente per alta disponibilità e scalabilità in lettura. Lo sharding divide i dati in modo che ogni nodo contenga record diversi.
È diverso anche dallo scaling verticale, dove mantieni un solo database ma lo sposti su una macchina più potente (più CPU/RAM/dischi più veloci). Lo scaling verticale può essere più semplice, ma ha limiti pratici e può diventare rapidamente costoso.
Cosa lo sharding non risolve magicamente
Lo sharding aumenta la capacità, ma non rende automaticamente il database “facile” o ogni query più veloce.
- Join possono diventare costose se righe correlate vivono su shard diversi.
- Transazioni cross-shard sono più complicate; aggiornamenti “tutto o niente” richiedono coordinazione.
- Complessità operativa aumenta: routing, ribilanciamento, debugging e gestione dei fallimenti diventano parte del sistema.
Quindi lo sharding è meglio inteso come un modo per scalare storage e throughput—non un aggiornamento gratuito a tutti gli aspetti del comportamento del database.
Perché i team shardano: i problemi che cerca di risolvere
Lo sharding raramente è la prima scelta. I team di solito ci ricorrono dopo che un sistema di successo raggiunge limiti fisici—or dopo che i dolori operativi diventano troppo frequenti per essere ignorati. La motivazione è meno “vogliamo lo sharding” e più “dobbiamo continuare a crescere senza che un database diventi punto singolo di fallimento e costo”.
I punti dolenti che spingono verso lo sharding
Un singolo nodo di database può esaurire risorse in vari modi:
- Limiti di storage: tabelle e indici crescono, il disco diventa scarso, i backup rallentano e le operazioni di manutenzione diventano rischiose.
- Limiti di throughput in scrittura: CPU, WAL/redo o contesa di lock limitano quante scritture al secondo puoi sostenere.
- Limiti di throughput in lettura: anche con cache e repliche, alcuni carichi sovraccaricano il primario (o le repliche diventano costose da scalare).
- Noisy neighbors: un tenant, cliente o pattern di workload monopolizza le risorse e degrada gli altri.
Quando questi problemi si presentano regolarmente, spesso non è una singola query pessima—è che una macchina sta portando troppa responsabilità.
Gli obiettivi: scalare, isolare e controllare i costi
Lo sharding del database distribuisce dati e traffico su più nodi così la capacità cresce aggiungendo macchine invece di potenziare una sola. Ben fatto, può anche isolare i workload (così il picco di un tenant non rovina la latenza per gli altri) e controllare i costi evitando istanze premium sempre più grosse.
Segnali premonitori che stai per raggiungere il tetto
Pattern ricorrenti includono latenza p95/p99 in aumento durante i picchi, lag di replica più lungo, backup/restore che superano la finestra accettabile e piccole modifiche allo schema che diventano eventi importanti.
Perché lo sharding è di solito l'ultima scelta
Prima di impegnarsi, i team esauriscono opzioni più semplici: indicizzazione e fix delle query, caching, repliche di lettura, partizionamento dentro un singolo database, archiviazione dati vecchi e aggiornamenti hardware. Lo sharding può risolvere la scala, ma introduce anche coordinazione, complessità operativa e nuovi modi di fallire—quindi la soglia dovrebbe essere alta.
Un database sharded non è una singola cosa—è un piccolo sistema di parti che collaborano. Il motivo per cui lo sharding può sembrare “difficile da razionalizzare” è che correttezza e prestazioni dipendono da come queste parti interagiscono, non solo dal motore del database.
Shard: partizioni indipendenti (con i propri indici)
Uno shard è un sottoinsieme dei dati, di solito memorizzato su un proprio server o cluster. Ogni shard tipicamente ha il suo:
- storage (file di dati)
- indici (così le query possono essere veloci all'interno di quello shard)
- limiti locali (CPU, memoria, disco, connessioni)
Dal punto di vista dell'app, un setup sharded spesso cerca di apparire come un database logico unico. Ma sotto il cofano, una query che sarebbe “una sola ricerca per indice” in un database single-node potrebbe diventare “trova lo shard giusto, poi fai la ricerca”.
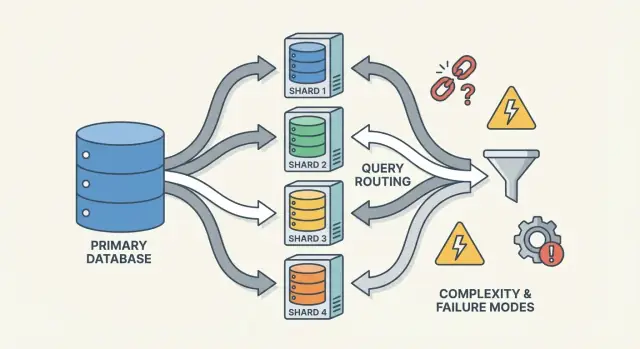
Router/coordinator: come le richieste raggiungono lo shard giusto
Un router (a volte chiamato coordinator, query router o proxy) è il vigile del traffico. Risponde alla domanda pratica: data questa richiesta, quale shard deve gestirla?
Ci sono due pattern comuni:
- Routing lato client: la libreria dell'app conosce la mappa degli shard e si connette direttamente allo shard giusto.
- Proxy routing: l'app si collega a un servizio router, che inoltra la richiesta.
I router riducono la complessità nell'app, ma possono anche diventare un collo di bottiglia o un nuovo punto di fallimento se non progettati con cura.
Lo sharding si basa su metadata—una fonte di verità che descrive:
- la mappa degli shard (quale shard possiede quale range/bucket/hash/ID)
- ownership (soprattutto durante le migrazioni, quando l'ownership può temporaneamente sovrapporsi)
- health e membership (quali nodi sono su, ruoli primary/replica, stato di draining)
Queste informazioni spesso risiedono in un servizio di config (o un piccolo database del “control plane”). Se i metadata sono vecchi o inconsistenti, i router possono inviare traffico nel posto sbagliato—anche se ogni shard è perfettamente sano.
Job in background: bilanciamento, migrazioni e backup
Infine, lo sharding dipende da processi in background che mantengono il sistema gestibile nel tempo:
- ribilanciamento dei dati quando uno shard cresce più velocemente degli altri
- migrazioni quando si sposta ownership tra shard
- backup/restore che funzionano su più shard (e rispettano i tuoi obiettivi di recovery)
Questi job sono facili da ignorare all'inizio, ma sono dove succedono molte sorprese in produzione—perché cambiano la forma del sistema mentre è ancora sotto carico.
Scegliere la chiave di shard: il primo grande compromesso
Una chiave di shard è il campo (o combinazione di campi) che il sistema usa per decidere in quale shard memorizzare una riga/documento. Quella scelta singola determina silenziosamente prestazioni, costi e anche quali funzionalità sembreranno “facili” in futuro—perché controlla se le richieste possono essere instradate a uno shard o devono essere diffuse su molti.
Cosa rende una chiave di shard “buona”
Una buona chiave tende ad avere:
- Alta cardinalità: molti valori possibili (per es.,
user_id invece di paese).
- Distribuzione uniforme: i valori distribuiscono scritture e letture evitando accumuli su uno shard.
- Pattern di accesso stabili: corrisponde a come interroghi più spesso i dati oggi e come prevedi di interrogarli il prossimo trimestre.
Un esempio comune è sharding per tenant_id in un'app multi-tenant: la maggior parte delle letture e scritture per un tenant rimane su uno shard, e i tenant sono abbastanza numerosi da distribuire il carico.
Cosa rende una chiave di shard “cattiva” (e perché fa male)
Alcune chiavi quasi garantiscono problemi:
- Chiavi monotone legate al tempo (timestamp, ID auto-increment): i nuovi dati si accumulano sullo shard “più recente”, creando uno hotspot in scrittura.
- Campi a bassa cardinalità (status, plan_tier, country): pochi valori distinti significano che pochi shard fanno la maggior parte del lavoro.
- Identificatori che cambiano (email, username modificabile): se la chiave cambia, spostare i dati tra shard diventa costoso e rischioso.
Anche se una chiave a bassa cardinalità sembra comoda per filtrare, spesso trasforma query di routine in scatter-gather, perché le righe corrispondenti vivono dappertutto.
Il compromesso reale: comodità delle query vs qualità della distribuzione
La migliore chiave di shard per bilanciare il carico non è sempre la migliore per le query prodotto.
- Scegli una chiave allineata al tuo pattern di accesso principale (per es.,
user_id) e alcune query “globali” (reporting admin) diventano più lente o richiedono pipeline separate.
- Scegli una chiave allineata al reporting (per es.,
region) e rischi hotspot e capacità diseguale.
La maggior parte dei team progetta attorno a questo compromesso: ottimizza la chiave di shard per le operazioni più frequenti e sensibili alla latenza—e gestisce il resto con indici, denormalizzazione, repliche o tabelle analitiche dedicate.
Strategie comuni di sharding (Range, Hash, Directory)
Non esiste un modo “migliore” assoluto per shardare un database. La strategia scelta determina quanto è facile instradare le query, quanto uniformemente si distribuiscono i dati e quali pattern di accesso saranno problematici.
Range sharding
Con il range sharding, ogni shard possiede una fetta contigua dello spazio di chiavi—for example:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
Il routing è diretto: guarda la chiave, scegli lo shard.
Il problema sono gli hotspot. Se i nuovi utenti ottengono sempre ID crescenti, lo shard “ultimo” diventa il collo di bottiglia in scrittura. Il range sharding è anche sensibile alla crescita disomogenea (un range diventa popolare, un altro resta quieto). Il vantaggio: le query per intervallo (“tutti gli ordini dal 1° al 31 ottobre”) possono essere efficienti perché i dati sono fisicamente raggruppati.
Hash sharding
Il hash sharding manda la chiave di shard in una funzione di hash e usa il risultato per scegliere uno shard. Questo di solito distribuisce i dati più uniformemente, aiutando a evitare il problema dello shard “più nuovo”.
Contro: le query per intervallo diventano difficili. Una query come “clienti con ID tra X e Y” non mappa più a pochi shard; può coinvolgerne molti.
Un dettaglio pratico sottovalutato è il consistent hashing. Invece di mappare direttamente sul conteggio di shard (che rimappa tutto quando aggiungi shard), molti sistemi usano un hash ring con “nodi virtuali” così aggiungere capacità sposta solo una parte delle chiavi.
Directory (lookup) sharding
Il directory sharding conserva una mappatura esplicita (una tabella/servizio di lookup) da chiave → posizione shard. È il più flessibile: puoi mettere tenant specifici su shard dedicati, spostare un cliente senza muovere tutti gli altri e supportare shard di dimensioni non uniformi.
Lo svantaggio è una dipendenza in più. Se la directory è lenta, stale o non disponibile, il routing soffre—anche se gli shard sono sani.
Chiavi composite e sub-sharding
I sistemi reali spesso mescolano approcci. Una chiave composite (es., tenant_id + user_id) mantiene isolati i tenant mentre distribuisce il carico all'interno di un tenant. Il sub-sharding è simile: prima instradi per tenant, poi fai hash all'interno del gruppo di shard del tenant per evitare che un tenant grande domini uno shard.
Come funzionano le query: routing vs scatter-gather
Un database sharded ha due percorsi di query molto diversi. Capire quale percorso stai usando spiega la maggior parte delle sorprese nelle prestazioni—e perché lo sharding può sembrare imprevedibile.
Query single-shard: il percorso veloce
Il risultato ideale è instradare una query a esattamente uno shard. Se la richiesta include la chiave di shard (o qualcosa che il router può mappare allo shard), il sistema può inviarla direttamente al posto giusto.
Per questo motivo i team insicuriscono di rendere le letture comuni “consapevoli della chiave di shard”. Uno shard significa meno hop di rete, esecuzione più semplice, meno lock e molta meno coordinazione. La latenza è soprattutto il database che fa il lavoro, non il cluster che discute chi debba farlo.
Letture scatter-gather: fan-out e tail latency
Quando una query non può essere instradata precisamente (per esempio filtra su un campo non della chiave di shard), il sistema può broadcastarla a molti o tutti gli shard. Ogni shard esegue la query localmente, poi il router (o un coordinator) unisce i risultati—ordinando, deduplicando, applicando limiti e combinando aggregati parziali.
Questo fan-out amplifica la tail latency: anche se 9 shard rispondono rapidamente, uno shard lento può tenere in ostaggio l'intera richiesta. Moltiplica anche il carico: una richiesta utente può diventare N richieste agli shard.
Join e aggregazioni cross-shard
Le join tra shard sono costose perché dati che una volta si sarebbero incontrati “dentro” il database devono ora viaggiare tra shard (o verso un coordinator). Anche aggregazioni semplici (COUNT, SUM, GROUP BY) possono richiedere un piano in due fasi: calcola risultati parziali su ogni shard, poi uniscili.
Limiti di indicizzazione: locali vs globali
La maggior parte dei sistemi usa indici locali per default: ogni shard indicizza solo i suoi dati. Sono economici da mantenere, ma non aiutano il routing—quindi le query possono comunque scatterare.
Gli indici globali possono abilitare il routing mirato su campi non chiave di shard, ma aggiungono overhead in scrittura, coordinazione extra e problemi di scalabilità/consistenza.
Scritture e transazioni attraverso gli shard
Le scritture sono il punto in cui lo sharding smette di sembrare “solo scalare” e inizia a cambiare come progetti le funzionalità. Una scrittura che tocca uno shard può essere veloce e semplice. Una scrittura che attraversa shard può essere lenta, soggetta a errori e sorprendentemente difficile da rendere corretta.
Scritture single-shard: il percorso felice
Se ogni richiesta può essere instradata a esattamente uno shard (tipicamente tramite la chiave di shard), il database può usare la sua normale macchina di transazioni. Ottieni atomicità e isolamento all'interno di quello shard, e molti problemi operativi appaiono familiari—solo ripetuti N volte.
Scritture multi-shard: dove la complessità cresce
Nel momento in cui devi aggiornare dati su due shard in una singola “azione logica” (per es., trasferire denaro, spostare un ordine tra clienti, aggiornare un aggregato memorizzato altrove), sei nel territorio delle transazioni distribuite.
Le transazioni distribuite sono difficili perché richiedono coordinazione tra macchine che possono essere lente, partizionate o riavviate in qualsiasi momento. I protocolli in stile two-phase commit aggiungono round trip, possono bloccare su timeout e rendono i fallimenti ambigui: lo shard B ha applicato la modifica prima che il coordinatore morisse? Se il client ritenta, applichi due volte la scrittura? Se non ritenti, la perdi?
Pattern per evitare scritture cross-shard
Alcune tattiche comuni riducono la frequenza di transazioni multi-shard:
- Località dei dati: co-loca record correlati sullo stesso shard (per es., tutto ciò che riguarda un cliente).
- Routing delle richieste: assicurati che un'operazione sia “owned” da uno shard e tratta gli altri come input in sola lettura.
- Denormalizzazione: duplica piccoli pezzi di dati così gli aggiornamenti non devono propagarsi.
Idempotenza e sicurezza nei retry
Nei sistemi sharded i retry non sono opzionali—sono inevitabili. Rendi le scritture idempotenti usando ID di operazione stabili (per es., una idempotency key) e facendo in modo che il database memorizzi i marker di “già applicato”. Così, se c'è un timeout e il client ritenta, il secondo tentativo diventa no-op invece di un doppio addebito, ordine duplicato o contatore incoerente.
Consistenza e replica: mantenere i dati corretti
Lo sharding divide i dati su macchine, ma non elimina la necessità di ridondanza. La replica è ciò che mantiene uno shard disponibile quando un nodo muore—e rende anche più difficile rispondere a “cos'è vero adesso?”.
Replica all'interno di ogni shard
La maggior parte dei sistemi replica all'interno di ogni shard: un primario (leader) accetta scritture e una o più repliche copiano quei cambiamenti. Se il primario fallisce, il sistema promuove una replica (failover). Le repliche possono anche servire letture per ridurre il carico.
Il compromesso è temporale. Una replica di lettura può essere indietro di qualche millisecondo—o secondi. Quel gap è normale, ma conta quando gli utenti si aspettano “ho appena aggiornato, quindi dovrei vederlo”.
Modelli di consistenza in termini semplici
- Consistenza forte: dopo che una scrittura ha successo, le letture la rifletteranno (dal punto di vista garantito dal sistema). Questo di solito significa leggere dal leader o aspettare conferme dalle repliche.
- Consistenza eventuale: il sistema converge, ma una lettura può temporaneamente restituire dati più vecchi.
Negli setup sharded spesso finisci con consistenza forte dentro uno shard e garanzie più deboli tra shard, specialmente quando sono coinvolte operazioni multi-shard.
“Fonte unica di verità” quando i dati sono divisi
Con lo sharding, “fonte unica di verità” tipicamente significa: per ogni pezzo di dati, c'è un posto autorevole dove scriverlo (di solito il leader dello shard). Ma a livello globale non esiste una macchina che può confermare istantaneamente lo stato più aggiornato di tutto. Hai molte verità locali che devono essere tenute in sync tramite replica.
Vincoli globali: unicità, foreign key, contatori
I vincoli sono difficili quando i dati da verificare vivono su shard diversi:
- Unicità (es., username): imporre “nessun duplicato ovunque” può richiedere un indice centralizzato, uno “shard” dedicato ai vincoli o un workflow di prenotazione a livello applicativo.
- Foreign key: se righe padre e figlio sono su shard diversi, il database non può facilmente far rispettare l'integrità referenziale senza coordinazione cross-shard.
- Contatori (totali globali, ID sequenziali): approcci ingenui creano un collo di bottiglia. Soluzioni comuni includono range per shard, batching o accettare conteggi approssimati.
Queste scelte non sono solo dettagli di implementazione—definiscono cosa significa “corretto” per il tuo prodotto.
Ribilanciamento e resharding senza downtime
Il ribilanciamento è ciò che mantiene un database sharded utilizzabile man mano che la realtà cambia. I dati crescono in modo non uniforme, una chiave di shard bilanciata deriva verso lo skew, aggiungi nuovi nodi per capacità o devi ritirare hardware. Qualsiasi di queste cose può trasformare uno shard nel collo di bottiglia—anche se il progetto iniziale sembrava perfetto.
Perché è difficile
A differenza di un database singolo, lo sharding incorpora la posizione dei dati nella logica di routing. Quando muovi i dati, non stai solo copiando byte—stai cambiando dove le query devono andare. Questo significa che il ribilanciamento riguarda tanto metadata e client quanto storage.
Il pattern di migrazione online (copia → overlap → cutover)
La maggior parte dei team mira a un workflow online che eviti una grande finestra di “stop the world”:
- Copia: backfill degli shard target dallo shard sorgente mentre il sistema è live.
- Dual-write (a volte dual-read): durante la transizione, scrivi le modifiche nuove sia nella vecchia sia nella nuova posizione. Le letture possono consultare entrambe (o usare una regola “vince la nuova”) finché non sei sicuro.
- Cutover: aggiorna la mappa degli shard così router/client inviano il traffico alla nuova posizione.
- Cleanup: ferma i dual-write, rimuovi la copia vecchia e compatta/recupera spazio.
Mappe degli shard e comportamento client
Un cambiamento nella mappa degli shard è un evento che rompe se i client cachano decisioni di routing. I buoni sistemi trattano i metadata di routing come configurazione: versionali, aggiornali frequentemente e sii esplicito su cosa succede quando un client incontra una chiave spostata (redirect, retry o proxy).
Rischi operativi da pianificare
Il ribilanciamento spesso causa cali temporanei di prestazione (scritture extra, churn di cache, carico di copia in background). I movimenti parziali sono comuni—alcuni range migrano prima di altri—quindi hai bisogno di buona osservabilità e di un piano di rollback (per esempio, ribaltare la mappa e svuotare i dual-write) prima di fare il cutover.
Lo sharding presume che il lavoro si distribuisca. La sorpresa è che un cluster può sembrare “bilanciato” sulla carta (stesso numero di righe per shard) mentre in produzione si comporta in modo molto disomogeneo.
Partizioni calde (hot key)
Uno hotspot succede quando una piccola fetta del tuo spazio di chiavi riceve la maggior parte del traffico—pensa a un account celebre, un prodotto popolare, un tenant che esegue un job pesante o una chiave temporale dove “oggi” attira tutte le scritture. Se quelle chiavi mappano a uno shard, quello shard diventa il collo di bottiglia anche se gli altri shard sono inattivi.
Skew: dimensione dati vs traffico
“Skew” non è una cosa sola:
- Skew dei dati: uno shard contiene più byte/righe (pressione di storage, backup più lunghi, scansioni rallentate).
- Skew del traffico: uno shard gestisce più QPS o query più pesanti (saturazione CPU, code, spike di latenza).
Non sempre coincidono. Uno shard con meno dati può comunque essere il più caldo se possiede le chiavi più richieste.
Come rilevarlo rapidamente
Non servono trace sofisticati per individuare lo skew. Parti con dashboard per-shard:
- p95 per shard (se il p95 di uno shard diverge è un segnale)
- QPS (e write QPS) per shard
- Storage usato / dimensione tabelle per shard
Se la latenza di uno shard cresce con la sua QPS mentre gli altri restano piatti, probabilmente hai uno hotspot.
Mitigazioni
Le soluzioni generalmente scambiano semplicità con bilanciamento:
- Scegli una chiave di shard che distribuisca traffico, non solo record.
- Aggiungi bucketing/salting per chiavi calde (splitta una chiave logica su più bucket fisici).
- Usa cache per elementi hot-read.
- Applica rate limit o quote per-tenant per proteggere il cluster.
- Dividi shard caldi (o sposta range caldi) quando uno shard non si riesce più a raffreddare.
Modalità di guasto e debugging in un sistema sharded
Lo sharding non aggiunge solo più server—aggiunge più modi in cui le cose possono andare male e più posti da ispezionare quando succede. Molti incidenti non sono “il database è giù”, ma “uno shard è giù” o “il sistema non si mette d'accordo su dove vivono i dati”.
Modalità di guasto comuni
Alcuni pattern ricorrono spesso:
- Uno shard non è disponibile (crash, disco pieno, pause di GC lunghe), causando outage parziali: alcuni clienti funzionano, altri falliscono.
- Router che instrada male il traffico, spesso dopo un cambiamento di config o un deploy fallato. Le letture possono restituire risultati vuoti se inviate allo shard sbagliato.
- Metadata stale o inconsistenti (es., mappa shard, tabella directory). Durante move o split, componenti diversi possono instradare la stessa chiave in modo diverso.
- Problemi di rete parziali: timeout tra router e un sottoinsieme di shard possono sembrare errori “a caso” e generare retry che amplificano il carico.
Come cambia il debugging
In un database single-node esegui il tail di un log e guardi un set di metriche. In un sistema sharded hai bisogno di osservabilità che segua una richiesta attraverso gli shard.
Usa correlation ID in ogni richiesta e propagali dal livello API attraverso router a ogni shard. Abbina questo con distributed tracing così una query scatter-gather mostra quale shard è stato lento o è fallito. Le metriche devono essere suddivise per shard (latenza, profondità delle code, tasso di errori), altrimenti uno shard caldo si nasconde nelle medie del fleet.
Incidenti di correttezza dei dati
I fallimenti di sharding spesso emergono come bug di correttezza:
- Duplicati dopo retry o scritture non idempotenti.
- Righe mancanti quando una migrazione ha spostato dati ma il routing punta ancora alla vecchia posizione.
- Split-brain writes se due viste metadata accettano scritture per lo stesso range.
Backup, restore e disaster recovery
“Ripristina il database” diventa “ripristina molte parti nell'ordine giusto”. Potresti dover ripristinare prima i metadata, poi ogni shard, quindi verificare che i confini degli shard e le regole di routing corrispondano al punto nel tempo ripristinato. I piani di DR dovrebbero includere prove che dimostrino la capacità di ricomporre un cluster consistente—non solo recuperare macchine singole.
Quando non shardare: alternative pratiche e una checklist decisionale
Lo sharding viene spesso trattato come l'interruttore della scala, ma è anche un aumento permanente della complessità del sistema. Se puoi raggiungere i tuoi obiettivi di performance e affidabilità senza dividere i dati su nodi, di solito ottieni un'architettura più semplice, debugging più facile e meno edge case operativi.
Alternative pratiche che spesso comprano molto headroom
Prima di decidere lo sharding, prova opzioni che preservano un database logico unico:
- Migliore indicizzazione + tuning delle query: risolvi prima i percorsi lenti—indici mancanti, query non limitate, join costose e pattern N+1.
- Caching: metti risposte read-heavy e stabili dietro una cache (cache a livello app, CDN per contenuti pubblici, o una cache in-memory per chiavi hot).
- Repliche di lettura: scarica il traffico di lettura senza cambiare il percorso di scrittura (accettando il lag delle repliche dove va bene).
- Partizionamento di tabelle su un nodo: molti database supportano il partitioning che migliora manutenzione e performance senza routing cross-node.
Dove gli strumenti aiutano: prototipare servizi shard-aware senza impegno
Un modo pratico per ridurre i rischi è prototipare il plumbing (confini di routing, idempotenza, workflow di migrazione e osservabilità) prima di impegnare il database di produzione.
Per esempio, con Koder.ai puoi rapidamente avviare un piccolo servizio realistico dalla chat—spesso una UI admin React più un backend Go con PostgreSQL—e sperimentare API consapevoli della chiave di shard, chiavi di idempotenza e comportamenti di “cutover” in un sandbox sicuro. Perché Koder.ai supporta planning mode, snapshot/rollback ed esportazione del codice sorgente, puoi iterare decisioni di design legate allo sharding (come routing e forma dei metadata) e poi portare il codice e le runbook nel tuo stack principale quando sei sicuro.