25 lug 2025·8 min
Come gli LLM trasformano idee espresse in inglese semplice in app full‑stack
Come gli LLM trasformano idee espresse in inglese semplice in app web, mobile e backend: requisiti, flussi UI, modelli dati, API, test e deployment.
Come gli LLM trasformano idee espresse in inglese semplice in app web, mobile e backend: requisiti, flussi UI, modelli dati, API, test e deployment.
A “plain English product idea” usually starts as a mix of intent and hope: who it’s for, what problem it solves, and what success looks like. It might be a few sentences (“an app for scheduling dog walkers”), a rough workflow (“customer requests → walker accepts → payment”), and a couple of must-haves (“push notifications, ratings”). That’s enough to talk about an idea—but not enough to build consistently.
When people say an LLM can “translate” an idea into an app, the useful meaning is this: turning fuzzy goals into concrete, testable decisions. The “translation” isn’t just rewriting—it’s adding structure so you can review, challenge, and implement.
LLMs are good at producing a first draft of core building blocks:
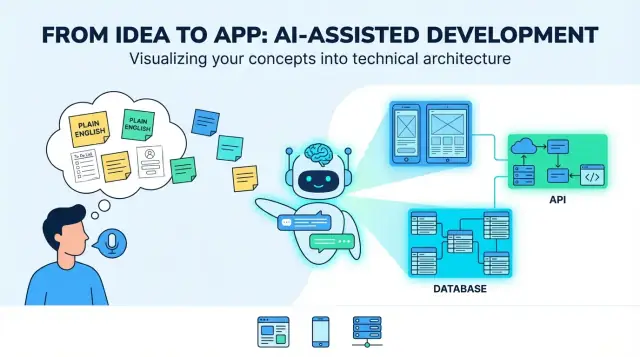
The typical “end result” looks like a blueprint for a full-stack product: a web UI (often for admins or desktop-heavy tasks), a mobile UI (for on-the-go users), backend services (auth, business logic, notifications), and data storage (database plus file/media storage).
LLMs can’t reliably choose your product’s trade-offs, because the right answers depend on context you may not have written down:
Treat the model as a system that proposes options and defaults, not final truth.
The biggest failure modes are predictable:
The real goal of “translation” is to make assumptions visible—so you can confirm, revise, or reject them before they harden into code.
Before an LLM can turn “Build me an app for X” into screens, APIs, and data models, you need a product brief that’s specific enough to design against. This step is about turning fuzzy intent into a shared target.
Write the problem statement in one or two sentences: who is struggling, with what, and why it matters. Then add success metrics that are observable.
For example: “Reduce the time it takes for a clinic to schedule follow-up appointments.” Metrics could include average scheduling time, no-show rate, or % of patients booking via self-serve.
List the primary user types (not everyone who might touch the system). Give each one a top task and a short scenario.
A useful prompt template is: “As a [role], I want to [do something] so that [benefit].” Aim for 3–7 core use cases that describe the MVP.
Constraints are the difference between a clean prototype and a shippable product. Include:
Be explicit about what’s in the first release and what’s postponed. A simple rule: MVP features must support the primary use cases end-to-end without manual workarounds.
If you want, capture this as a one-page brief and keep it as the “source of truth” for the next steps (requirements, UI flows, and architecture).
A plain-English idea is usually a mix of goals (“help people book classes”), assumptions (“users will log in”), and vague scope (“make it simple”). An LLM is useful here because it can turn messy input into requirements you can review, correct, and approve.
Start by rewriting each sentence as a user story. This forces clarity about who needs what and why:
If a story doesn’t name a user type or benefit, it’s probably still too vague.
Next, group stories into features, then label each as must-have or nice-to-have. This helps prevent scope drift before design and engineering begin.
Example: “push notifications” may be nice-to-have, while “cancel a booking” is usually must-have.
Add simple, testable rules under each story. Good acceptance criteria are specific and observable:
LLMs often default to the “happy path,” so explicitly request edge cases such as:
This requirements bundle becomes the source of truth you’ll use to evaluate later outputs (UI flows, APIs, and tests).
A plain-English idea becomes buildable when it turns into user journeys and screens connected by clear navigation. At this step, you’re not choosing colors—you’re defining what people can do, in what order, and what success looks like.
Start by listing the paths that matter most. For many products, you can structure them as:
The model can draft these flows as step-by-step sequences. Your job is to confirm what’s optional, what’s required, and where users can safely exit and resume.
Ask for two deliverables: a screen inventory and a navigation map.
A good output names screens consistently (e.g., “Order Details” vs “Order Detail”), defines entry points, and includes empty states (no results, no saved items).
Turn requirements into form fields with rules: required/optional, formats, limits, and friendly error messages. Example: password rules, payment address formats, or “date must be in the future.” Make sure validation happens both inline (as users type) and on submit.
Include readable text sizes, clear contrast, full keyboard support on web, and error messages that explain how to fix the problem (not just “Invalid input”). Also ensure every form field has a label and the focus order makes sense.
An “architecture” is the app’s blueprint: what parts exist, what each part is responsible for, and how they talk to each other. When an LLM proposes an architecture, your job is to make sure it’s simple enough to build now and clear enough to evolve later.
For most new products, a single backend (a monolith) is the right starting point: one codebase, one deployment, one database. It’s faster to build, easier to debug, and cheaper to operate.
A modular monolith is often the sweet spot: still one deploy, but organized into modules (Auth, Billing, Projects, etc.) with clean boundaries. You delay a service split until there’s real pressure—like heavy traffic, a team that needs independent deploys, or a part of the system that scales differently.
If the LLM immediately suggests “microservices,” ask it to justify that choice with concrete needs, not future hypotheticals.
A good architecture outline names the essentials:
The model should also specify where each piece lives (backend vs mobile vs web) and define how clients interact with the backend (usually REST or GraphQL).
Architecture stays ambiguous unless you pin down basics: backend framework, database, hosting, and mobile approach (native vs cross-platform). Ask the model to write these as “Assumptions” so everyone knows what’s being designed.
Instead of big rewrites, prefer small “escape hatches”: caching for hot reads, a queue for background jobs, and stateless app servers so you can add more instances later. The best architecture proposals explain these options while keeping v1 straightforward.
A product idea is usually full of nouns: “users,” “projects,” “tasks,” “payments,” “messages.” Data modeling is the step where an LLM turns those nouns into a shared picture of what the app must store—and how different things connect.
Start by listing the key entities and asking: what belongs to what?
For example:
Then define relationships and constraints: can a task exist without a project, can comments be edited, can projects be archived, and what happens to tasks when a project is deleted.
Next, the model proposes a first-pass schema (SQL tables or NoSQL collections). Keep it simple and focused on decisions that affect behavior.
A typical draft might include:
Important: capture “status” fields, timestamps, and unique constraints early (like unique email). Those details drive UI filters, notifications, and reporting later.
Most real apps need clear rules for who can see what. An LLM should make ownership explicit (owner_user_id) and model access (memberships/roles). For multi-tenant products (many companies in one system), introduce a tenant/organization entity and attach tenant_id to everything that must be isolated.
Also define how permissions are enforced: by role (admin/member/viewer), by ownership, or by both.
Finally, decide what must be logged and what must be deleted. Examples:
These choices prevent unpleasant surprises when compliance, support, or billing questions show up later.
Backend APIs are where your app’s promises become real actions: “save my profile,” “show my orders,” “search listings.” A good output starts from user actions and turns them into a small set of clear endpoints.
List the main things users interact with (e.g., Projects, Tasks, Messages). For each, define what the user can do:
That usually maps neatly to endpoints like:
POST /api/v1/tasks (create)GET /api/v1/tasks?status=open&q=invoice (list/search)GET /api/v1/tasks/{taskId} (read)PATCH /api/v1/tasks/{taskId} (update)DELETE /api/v1/tasks/{taskId} (delete)Create a task: user submits title and due date.
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
Response returns the saved record (including server-generated fields):
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
Have the model produce consistent errors:
For retries, prefer idempotency keys on POST and clear guidance like “retry after 5 seconds.”
Mobile clients update slowly. Use a versioned base path (/api/v1/...) and avoid breaking changes:
GET /api/version)Security isn’t a “later” task. When an LLM turns your idea into app specs, you want safe defaults to be explicit—so the first generated version isn’t accidentally open to abuse.
Ask the model to recommend a primary login method and a fallback, plus what happens when things go wrong (lost access, suspicious login, etc.). Common choices include:
Have it specify session handling (short-lived access tokens, refresh tokens, device logout) and whether you support multi-factor authentication.
Authentication identifies the user; authorization limits access. Encourage the model to choose one clear pattern:
project:edit, invoice:export) for flexible productsA good output includes sample rules like: “Only project owners can delete a project; collaborators can edit; viewers can comment.”
Make the model list concrete safeguards, not generic promises:
Also request a baseline threat checklist: CSRF/XSS protections, secure cookies, and safe file uploads if applicable.
Default to minimal data collection: only what the feature truly needs, for as short a time as possible.
Have the LLM draft plain-language copy for:
If you add analytics, insist on an opt-out (or opt-in where required) and document it clearly in your settings and policy pages.
A good LLM can turn your requirements into a test plan that’s surprisingly usable—if you force it to anchor everything to acceptance criteria, not generic “should work” statements.
Start by giving the model your feature list and acceptance criteria, then ask it to generate tests per criterion. A solid output includes:
If a test can’t point back to a specific criterion, it’s probably noise.
LLMs can also propose fixtures that mirror how people actually use the app: messy names, missing fields, time zones, long text, flaky networks, and “almost duplicate” records.
Ask for:
Have the model add a dedicated mobile checklist:
LLMs are great at drafting test skeletons, but you should review:
Treat the model as a fast test author, not the final QA sign-off.
A model can generate a lot of code, but users only benefit once it’s shipped safely and you can see what happens after launch. This step is about repeatable releases: the same steps every time, with the least surprise.
Set up a simple CI pipeline that runs on every pull request and on merges to your main branch:
Even if the LLM wrote the code, CI is what tells you whether it still works after a change.
Use three environments with clear purposes:
Configuration should be handled via environment variables and secrets (not hard-coded). A good rule: if changing a value requires a code change, it’s probably misconfigured.
For a typical full-stack app:
Plan for three signals:
This is where AI-assisted development becomes operational: you’re not just generating code—you’re running a product.
LLMs can turn a vague idea into something that looks like a full plan—but polished prose can hide gaps. The most common failures are predictable, and you can prevent them with a few repeatable habits.
Most weak outputs trace back to four issues:
Give the model concrete material to work with:
Ask for checklists per deliverable. For instance, requirements aren’t “done” until they include acceptance criteria, error states, roles/permissions, and measurable success metrics.
LLM outputs drift when specs, API notes, and UI ideas live in separate threads. Maintain one living doc (even a simple markdown file) that links:
When you prompt again, paste the latest excerpt and say: “Update only sections X and Y; keep everything else unchanged.”
If you’re implementing as you go, it also helps to use a workflow that supports quick iteration without losing traceability. For example, Koder.ai’s “planning mode” fits naturally here: you can lock down the spec (assumptions, open questions, acceptance criteria), generate the web/mobile/backend scaffolding from a single chat thread, and rely on snapshots/rollback if a change introduces regressions. Source code export is especially useful when you want your generated architecture and your repo to stay aligned.
Here’s what “LLM translation” can look like end to end—plus the checkpoints where a human should slow down and make real decisions.
Plain-English idea: “A pet-sitting marketplace where owners post requests, sitters apply, and payments are released after the job.”
An LLM can turn that into a first draft like:
POST /requests, GET /requests/{id}, POST /requests/{id}/apply, GET /requests/{id}/applications, POST /messages, POST /checkout/session, POST /jobs/{id}/complete, POST /reviews.That’s useful—but it’s not “done.” It’s a structured proposal that needs validation.
Product decisions: What makes an “application” valid? Can an owner invite a sitter directly? When is a request considered “filled”? These rules affect every screen and API.
Security & privacy review: Confirm role-based access (owners can’t read other owners’ chats), protect payments, and define data retention (e.g., delete chat after X months). Add abuse controls: rate limits, spam prevention, audit logs.
Performance tradeoffs: Decide what must be fast and scalable (search/filter requests, chat). This influences caching, pagination, indexing, and background jobs.
After a pilot, users might ask for “repeat a request” or “cancel with partial refund.” Feed that back as updated requirements, regenerate or patch affected flows, then re-run tests and security checks.
Capture the “why,” not just the “what”: key business rules, permission matrix, API contracts, error codes, database migrations, and a short runbook for releases and incident response. This is what keeps generated code understandable six months later.
In questo contesto, “traduzione” significa convertire un'idea vaga in decisioni specifiche e verificabili: ruoli, percorsi utente, requisiti, dati, API e criteri di successo.
Non è solo parafrasare: è rendere esplicite le assunzioni così puoi confermarle o rigettarle prima di costruire.
Un primo pass pratico include:
Consideralo un project blueprint provvisorio da rivedere, non una specifica finale.
Perché un LLM non può conoscere in modo affidabile i vincoli e i compromessi del mondo reale se non glieli fornisci. Gli esseri umani devono comunque decidere:
Usa il modello per proporre opzioni, poi scegli con intenzione.
Forniscigli abbastanza contesto da progettare:
Se non puoi consegnare questo a un collega e ottenere la stessa interpretazione, non è pronto.
Trasforma gli obiettivi in user story + criteri di accettazione.
Un buon bundle contiene:
Questo diventa la tua “fonte di verità” per UI, API e test.
Chiedi due deliverable:
Poi verifica:
Per la maggior parte dei prodotti v1, monolite o modular monolith è la scelta giusta.
Contrasta una proposta immediata di microservizi: chiedi motivazioni concrete (traffico, esigenze di deploy indipendenti, differenze di scalabilità). Preferisci “vie di fuga” come:
Mantieni il v1 semplice da rilasciare e da debuggare.
Fai in modo che il modello espliciti:
Le decisioni sui dati guidano filtri UI, notifiche, report e sicurezza.
Pretendi coerenza e comportamento adatto al mobile:
/api/v1/...)POST ritentatiEvita breaking changes: aggiungi campi opzionali e mantieni una finestra di deprecazione.
Usa il modello per abbozzare il piano, poi mettilo a confronto con i criteri di accettazione:
Richiedi anche fixture realistiche: fusi orari, testi lunghi, quasi-duplicati, reti instabili. Considera i test generati come punto di partenza, non come QA finale.
Stai progettando il comportamento, non l'aspetto visivo.