Perché i framework backend contano oltre il “scegliere uno stack”
Un framework backend è più di un insieme di librerie. Le librerie ti aiutano a svolgere compiti specifici (routing, validazione, ORM, logging). Un framework aggiunge un “modo di lavorare” opinabile: una struttura di progetto predefinita, pattern comuni, tooling integrato e regole su come i pezzi si collegano.
I framework influenzano le decisioni quotidiane
Una volta scelto un framework, esso guida centinaia di piccole scelte:
- Dove deve risiedere il nuovo codice (feature, moduli, servizi)
- Come le richieste attraversano l’app (controller, middleware, handler)
- Come gestire preoccupazioni cross-cutting come auth, validazione ed errori
- Come i team nominano le cose, scrivono test e revisionano le pull request
Per questo due team che costruiscono “la stessa API” possono avere codebase molto diverse—anche usando lo stesso linguaggio e database. Le convenzioni del framework diventano la risposta predefinita a “come lo facciamo qui?”.
Velocità e coerenza vs flessibilità
I framework spesso scambiano flessibilità con una struttura prevedibile. Il vantaggio è onboarding più rapido, meno discussioni e pattern riutilizzabili che riducono la complessità accidentale. Lo svantaggio è che le convenzioni del framework possono sembrare vincolanti quando il prodotto necessita di workflow non convenzionali, tuning delle performance o architetture non standard.
Una buona decisione non è “framework o no”, ma quanta convenzione vuoi—e se il team è disposto a sostenere il costo della personalizzazione nel tempo.
Chi dovrebbe interessarsene
- Ingegneri: meno tempo a reinventare pattern, più tempo per consegnare funzionalità
- Tech lead: standard più chiari per architettura, testing e code review
- Product team: delivery più prevedibile e meno regressioni di qualità man mano che il codice cresce
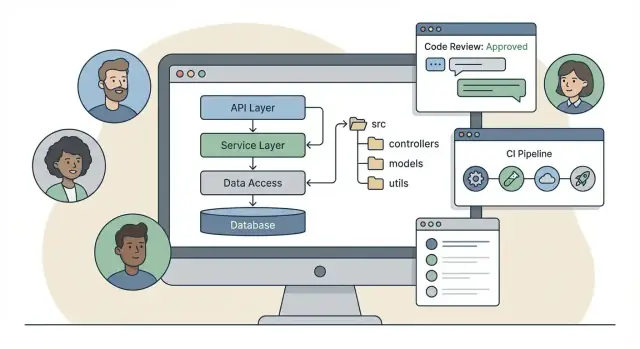
I default del framework che definiscono la struttura del progetto
La maggior parte dei team non parte da una cartella vuota—parte dal layout “raccomandato” del framework. Quei default decidono dove mettere il codice, come chiamare le cose e cosa sembra “normale” nelle review.
Due mentalità predefinite comuni
Alcuni framework spingono per una classica struttura a layer: controllers / services / models. È facile da imparare e si mappa bene alla gestione delle richieste:
/src
/controllers
/services
/models
/repositories
Altri framework tendono ai moduli per feature: raggruppare tutto ciò che riguarda una funzionalità (handler HTTP, regole di dominio, persistenza). Questo favorisce il ragionamento locale—quando lavori su “Billing”, apri una sola cartella:
/src
/modules
/billing
/http
/domain
/data
Nessuna delle due è automaticamente migliore, ma ciascuna forma abitudini diverse. Le strutture a layer possono rendere più semplice centralizzare standard cross-cutting (logging, validazione, gestione errori). Le strutture modulari possono ridurre lo “scroll orizzontale” nel codice man mano che cresce.
Gli strumenti di scaffolding creano pattern duraturi
I generatori CLI (scaffolding) sono appiccicosi. Se il generatore crea per ogni endpoint una coppia controller + service, la gente continuerà a farlo—anche quando sarebbe sufficiente una funzione più semplice. Se genera un modulo con confini chiari, i team sono più inclini a rispettare quei confini anche sotto pressione di scadenze.
Questo stesso dinamismo appare anche nei workflow di “vibe-coding”: se i default della vostra piattaforma producono un layout prevedibile e cuciture di modulo chiare, i team tendono a mantenere coerente la codebase mentre cresce. Ad esempio, Koder.ai genera app full-stack da prompt in chat, e il beneficio pratico (oltre alla velocità) è che il team può standardizzare strutture e pattern coerenti presto—poi iterarci sopra come su qualsiasi altro codice (inclusa l’esportazione del codice sorgente quando vuoi il controllo completo).
Evitare "controller gonfi"
I framework che mettono i controller sotto i riflettori possono tentare i team a infilare regole di business negli handler delle richieste. Una regola pratica: i controller traducono HTTP → chiamata dell'applicazione, e nulla di più. Metti la logica di business in un livello service/use-case (o domain del modulo), così può essere testata senza HTTP e riutilizzata da job background o task CLI.
Un rapido controllo per la tua struttura
Se non riesci a rispondere in una frase a “Dove vive la logica di pricing?”, i default del framework potrebbero scontrarsi con il tuo dominio. Aggiusta presto—le cartelle si cambiano facilmente; le abitudini no.
Flusso della richiesta: routing, controller e convenzioni middleware
Un framework backend non è solo un set di librerie—definisce come una richiesta dovrebbe viaggiare nel tuo codice. Quando tutti seguono lo stesso percorso della richiesta, le feature si consegnano più velocemente e le review diventano meno sulle preferenze di stile e più sulla correttezza.
Routing: la mappa pubblica del tuo sistema
Le route dovrebbero leggere come un sommario per la tua API. I buoni framework incoraggiano route che siano:
- Dichiarative (si può scorrere e capire cosa è esposto)
- Coerenti (stessi pattern URL e verbi HTTP in tutta la codebase)
- Vicino al bordo (la configurazione di routing non dovrebbe contenere regole di business)
Una convenzione pratica è tenere i file di route focalizzati sul mapping: GET /orders/:id -> OrdersController.getById, non “se l'utente è VIP, fai X”.
Controller/handler: traduttori leggeri delle richieste
I controller (o handler) funzionano meglio come traduttori tra HTTP e la logica core:
- Leggono input (params, header, body)
- Chiamano un service/use-case
- Restituiscono una risposta
Quando i framework offrono helper per parsing, validazione e formattazione delle risposte, il team è portato ad ammassare logica nei controller. Il pattern più sano è “controller sottili, service spessi”: tieni le preoccupazioni request/response nel controller e le decisioni di business in un livello separato che non conosce HTTP.
Middleware/filtri: un unico posto per le preoccupazioni ripetute
Il middleware (o filtri/interceptor) decide dove mettere comportamenti ripetuti come autenticazione, logging, rate limiting e request ID. La convenzione chiave: il middleware deve arricchire o proteggere la richiesta, non implementare regole di prodotto.
Ad esempio, il middleware di auth può allegare req.user, e i controller possono passare quell'identità nella logica core. Un middleware di logging può standardizzare cosa viene loggato senza far reinventare la ruota a ogni controller.
Convenzioni di naming che rimuovono attrito nelle review
Accordatevi su nomi prevedibili:
OrdersController, OrdersService, CreateOrder (use-case)authMiddleware, requestIdMiddlewarevalidateCreateOrder (schema/validator)
Quando i nomi codificano l'intento, le review si concentrano sul comportamento, non su dove qualcosa “doveva andare”.
Layer e confini: dove vive la logica di business
Un framework backend non aiuta solo a pubblicare endpoint—spinge il team verso una certa “forma” del codice. Se non definite i confini presto, la gravità di default è spesso: i controller chiamano l'ORM, l'ORM parla al DB, e le regole di business vengono sparse ovunque.
Un'architettura a layer pratica
Una separazione semplice e duratura assomiglia a questa:
- Presentation layer: preoccupazioni HTTP (routing, controller, auth middleware). Converte le richieste in comandi dell'app e restituisce risposte.
- Application layer: use-case (es.
CreateInvoice, CancelSubscription). Orchestration del lavoro e transazioni, ma poco legato al framework.
- Domain layer: regole di business e concetti core (entità, policy, domain services). Dovrebbe leggere come il linguaggio del business, non come SQL.
- Data layer: repository, modelli/mappers ORM, query, migration.
I framework che generano “controller + service + repository” possono essere utili—se li trattate come flusso direttivo, non come obbligo che ogni feature debba avere ogni layer.
Come ORM e repository influenzano i confini
Un ORM rende tentante passare modelli del database ovunque perché sono comodi e “più o meno” già validati. I repository aiutano fornendo interfacce più strette (“get customer by id”, “save invoice”), così il codice application e domain non dipende dai dettagli dell'ORM.
Per evitare design in cui “tutto dipende dal database”:
- Non restituire entità ORM direttamente dai controller.
- Mantieni le forme delle query nel data layer; tieni le regole nel domain.
- Preferisci input/output amichevoli al dominio per gli use-case.
Quando introdurre un service layer (e quando no)
Aggiungi un livello service/use-case quando la logica è riutilizzata tra endpoint, richiede transazioni o deve far rispettare regole in modo coerente. Saltalo per CRUD semplici che non hanno comportamento di business—aggiungere layer lì può creare solo burocrazia senza chiarezza.
Dependency Injection e abitudini di design modulare
La Dependency Injection (DI) è uno di quei default di framework che formano tutto il team. Quando è integrata nel framework, si smette di istanziare servizi a caso e si comincia a trattare le dipendenze come qualcosa da dichiarare, collegare e sostituire intenzionalmente.
Cosa incentiva la DI (e cosa può complicare)
La DI spinge verso componenti piccoli e focalizzati: un controller dipende da un service, un service da un repository, e ogni parte ha un ruolo chiaro. Questo migliora la testabilità e facilita la sostituzione di implementazioni (per esempio, gateway di pagamento reale vs mock).
Lo svantaggio è che la DI può nascondere complessità. Se ogni classe dipende da cinque altre classi, diventa più difficile capire cosa viene effettivamente eseguito per una richiesta. Container mal configurati possono anche causare errori lontani dal codice che stavi modificando.
Constructor injection e design orientato alle interfacce
Molti framework favoriscono la constructor injection perché rende le dipendenze esplicite e previene pattern come il “service locator”.
Un'abitudine utile è affiancare la constructor injection al design guidato dalle interfacce: il codice dipende da un contratto stabile (es. EmailSender) invece che da un client vendor-specific. Questo mantiene le modifiche localizzate quando cambi provider o rifattorizzi.
Moduli coesi senza dipendenze circolari
La DI funziona meglio quando i moduli sono coesi: un modulo possiede una fetta di funzionalità (orders, billing, auth) ed espone una superficie pubblica ridotta.
Le dipendenze circolari sono un fallimento comune. Sono spesso un segno che i confini non sono chiari—due moduli condividono concetti che meriterebbero un modulo a sé, o un modulo sta facendo troppo.
Accordarsi su dove avviene il wiring
I team dovrebbero concordare dove registrare le dipendenze: una singola composition root (startup/bootstrap), più wiring a livello di modulo per gli interni del modulo.
Mantenere il wiring centralizzato semplifica le review: i revisori possono individuare nuove dipendenze, confermarne la giustificazione e prevenire lo “sprawl” del container che trasforma la DI da strumento a mistero.
Refactor senza paura
Sperimenta modifiche di struttura in modo sicuro usando snapshot e rollback mentre iteri.
Un framework backend influenza cosa il team considera “una buona API”. Se la validazione è una feature di prima classe (decoratori, schemi, pipe, request guard), le persone progettano endpoint attorno a input chiari e output prevedibili—perché è più facile fare la cosa giusta che saltarla.
Quando la validazione vive al confine (prima della logica di business), i team iniziano a trattare i payload delle richieste come contratti, non come “qualsiasi cosa invii il client”. Questo porta di solito a:
- Campi espliciti obbligatori vs opzionali (meno discussioni “null significa sconosciuto”)
- Regole chiare per formati (date, ID, enum) e vincoli (min/max, lunghezza)
- Rifiuto precoce delle richieste errate, mantenendo il codice di servizio focalizzato sulle regole di business
Qui i framework incoraggiano convenzioni condivise: dove definire la validazione, come esporre gli errori e se permettere campi sconosciuti.
Errori centralizzati per aspettative coerenti dei client
I framework che supportano filtri/handler di eccezioni globali rendono la consistenza raggiungibile. Invece di lasciare che ogni controller inventi le proprie risposte, puoi standardizzare:
- Involucro d'errore (es.
code, message, details, traceId)
- Mappatura degli status HTTP (validation → 400, auth → 401/403, not found → 404)
- Logging e correlation ID così il supporto può investigare una singola richiesta fallita
Una forma d'errore coerente riduce la logica condizionale sul front-end e rende la documentazione API più affidabile.
DTO e view model proteggono i tuoi interni
Molti framework spingono verso DTO (input) e view model (output). Questa separazione è salutare: impedisce di esporre accidentalmente campi interni, evita il coupling dei client agli schemi del DB e rende i refactor più sicuri. Una regola pratica: i controller parlano in DTO; i service parlano in modelli di dominio.
Versioning e compatibilità indietro
Anche piccole API evolvono. Le convenzioni di routing spesso determinano se il versioning è via URL (/v1/...) o via header. Qualunque sia la scelta, fissate le basi presto: non rimuovete campi senza una finestra di deprecazione, aggiungete campi in modo backward-compatible e documentate i cambiamenti in un unico posto (per esempio, /docs o /changelog).
Un framework backend non aiuta solo a spedire feature; detta anche come testarle. Il test runner integrato, le utility di bootstrap e il container DI spesso determinano cosa è facile—e ciò che è facile diventa ciò che il team realmente fa.
Helper del framework: unit vs integrazione vs end-to-end
Molti framework forniscono un "test app" bootstrapper che può avviare il container, registrare le route ed eseguire richieste in memoria. Questo spinge i team verso test di integrazione presto—perché sono solo poche righe in più rispetto a un unit test.
Una divisione pratica è:
- Unit test per logica pura di business (no boot del framework, no DB).
- Integration test per moduli/service collegati attraverso il container DI.
- End-to-end test per il comportamento HTTP reale (routing, middleware, auth, mapping errori).
Una piramide di test che si adatta ai servizi backend
Per la maggior parte dei servizi la velocità conta più della pura osservanza della piramide. Una buona regola: molti piccoli unit test, un set mirato di integration test attorno ai confini (DB, code), e una sottile suite E2E che prova il contratto.
Se il tuo framework rende economica la simulazione di richieste, puoi appoggiarti un po' di più sugli integration test—pur isolando la logica di dominio così che gli unit test restino stabili.
Mocking che rispecchia DI e runtime
La strategia di mocking dovrebbe seguire come il framework risolve le dipendenze:
- Preferisci override dei binding DI (sostituisci un client email reale con un fake) invece di monkey-patch degli import.
- Usa adapter in-memory dove possibile (es. repository in-memory) per evitare mock fragili.
- Mocka al confine del modulo, non dentro la logica di business, così i refactor non rompono i test.
Test veloci e affidabili per la CI
Il tempo di boot del framework può dominare la CI. Mantieni i test rapidi memorizzando setup costosi, eseguendo migrazioni una volta per suite e usando parallelizzazione solo dove l'isolamento è garantito. Rendi i fallimenti facili da diagnosticare: seeding coerente, orologi deterministici e hook di cleanup stretti battono il “retry on fail”.
Scalare la codebase: moduli, pacchetti e codice condiviso
Pianifica prima l'architettura
Mappa moduli, confini e flusso delle richieste prima di generare codice con Koder.ai Planning Mode.
I framework non solo aiutano a pubblicare la prima API—modelano come il codice cresce quando il “servizio singolo” diventa decine di feature, team e integrazioni. Le meccaniche di modulo e package che il framework rende semplici diventeranno spesso la tua architettura a lungo termine.
Pattern di modularità che i framework incoraggiano
La maggior parte dei backend framework spinge verso la modularità per design: app, plugin, blueprint, module, feature folder o package. Quando questo è il default, i team tendono ad aggiungere capacità come “un altro modulo” invece di spargere file nuovi ovunque.
Una regola pratica: tratta ogni modulo come un mini-prodotto con la propria superficie pubblica (route/handler, interfacce dei service), internals privati e test. Se il framework supporta l'auto-discovery (es. module scanning), usalo con prudenza—import espliciti spesso rendono le dipendenze più facili da capire.
Moduli core di dominio vs infrastruttura
Man mano che la codebase cresce, mescolare regole di business con adapter diventa costoso. Una suddivisione utile è:
- Core domain modules: regole di business, policy, domain services e modelli di dominio (cose che dovrebbero sopravvivere a uno swap del database)
- Infrastructure modules: client DB, modelli ORM, broker di messaggi, client HTTP, cache, provider di auth
Le convenzioni del framework influenzano questo: se il framework incoraggia “service class”, metti i domain service nei moduli core e lascia il wiring specifico del framework (controller, middleware, provider) ai bordi.
Librerie condivise vs copy-paste: regole decisionali
I team spesso condividono troppo presto. Preferisci copiare codice piccolo fino a quando non è stabile, poi estrailo quando:
- due o più team mantengono la stessa logica
- una correzione di bug deve essere applicata in più posti
- puoi definire una API chiara e versionarla
Se estrai, pubblica package interni (o workspace library) con ownership stretta e disciplina sul changelog.
Prepararsi dal monolite modulare alle microservizi (in futuro)
Un monolite modulare è spesso il miglior “punto medio”. Se i moduli hanno confini chiari e poche importazioni incrociate, puoi più facilmente estrarre un modulo in un servizio. Progetta i moduli intorno a capability di business, non a layer tecnici. Per una strategia più approfondita, vedi /blog/modular-monolith.
Configurazione, ambienti e readiness operativa
Il modello di configurazione di un framework definisce quanto coerenti (o caotiche) saranno le tue deployment. Quando la config è sparsa in file ad-hoc, variabili d'ambiente random e “solo questa costante”, i team finiscono a debugare differenze invece che costruire funzionalità.
Stile di configurazione = coerenza
La maggior parte dei framework ti spinge verso una fonte di verità primaria: file di configurazione, variabili d'ambiente o configurazione basata su codice (moduli/plugin). Qualunque sia la strada scelta, standardizzala presto:
- File funzionano bene per sviluppo locale e default chiari (es.
config/default.yml).
- Variabili d'ambiente sono ottime per differenze a deployment-time e piattaforme container.
- Config basata su codice può essere potente, ma è facile nascondere impostazioni importanti dietro logica.
Una buona convenzione è: default nel file di config versionato, variabili d'ambiente per override per ambiente, e il codice legge da un unico oggetto di config tipizzato. Questo mantiene ovvio “dove cambiare un valore” durante gli incidenti.
Segreti: trattali come categoria separata
I framework spesso forniscono helper per leggere env var, integrare secret store o validare la config all'avvio. Usa questi strumenti per rendere difficile un uso sbagliato dei segreti:
- Mai committare segreti nel repo (inclusi chiavi “temporanee”).
- Tieni i segreti fuori dai log e dalle pagine di errore.
- Preferisci l'iniezione a runtime (CI/CD, orchestratore container, o secret manager) rispetto alla proliferazione di
.env locali.
L'abitudine operativa da mirare è semplice: gli sviluppatori possono eseguire localmente con placeholder sicuri, mentre le credenziali reali esistono solo nell'ambiente che ne ha bisogno.
Parità degli ambienti: dev, staging, production
I default del framework possono incoraggiare la parità (stesso processo di avvio ovunque) o creare casi speciali (“in produzione si usa un entrypoint server diverso”). Punta allo stesso comando di avvio e allo stesso schema di config in tutti gli ambienti, cambiando solo i valori.
Lo staging dovrebbe essere considerato una prova generale: stesse feature flag, stesso percorso di migration, stessi job in background—solo a scala ridotta.
Documenta la config come un'API
Quando la configurazione non è documentata, i colleghi indovinano—e gli indovinelli diventano outage. Mantieni un riferimento breve e aggiornato nel repo (per esempio, /docs/configuration) che elenchi:
- ogni chiave di config e cosa controlla
- tipo/formato atteso (stringa, URL, intero)
- valore di default ed esempi sicuri
- quali ambienti devono impostarla
Molti framework possono validare la config all'avvio. Abbinalo alla documentazione e ridurrai i casi “funziona sulla mia macchina” da ricorrenza a rara eccezione.
Standard di osservabilità imposti dal framework
Un framework backend stabilisce la base per come capisci il sistema in produzione. Quando l'osservabilità è integrata (o fortemente consigliata), i team smettono di considerare log e metriche come lavoro “da fare dopo” e iniziano a progettarle come parte dell'API.
Logging, tracing e metriche: cosa ottieni “gratis”
Molti framework si integrano con tool comuni per logging strutturato, distributed tracing e raccolta metriche. Quell'integrazione influenza l'organizzazione del codice: tende a centralizzare le preoccupazioni cross-cutting (middleware di logging, interceptor di tracing, collector di metriche) invece di spargere print statement nei controller.
Uno standard utile è definire un piccolo set di campi richiesti che ogni riga di log relativa a una richiesta includa:
correlation_id (o request_id) per collegare i log tra serviziroute e method per capire quale endpoint è coinvoltouser_id o account_id (quando disponibile) per investigazioni di supportoduration_ms e status_code per performance e affidabilità
Le convenzioni del framework (come oggetti di request context o pipeline middleware) rendono più semplice generare e propagare correlation ID in modo coerente, evitando che gli sviluppatori reinventino il pattern per ogni feature.
Health check e readiness endpoint
I default del framework spesso determinano se health check sono first-class o un ripensamento. Endpoint standard come /health (liveness) e /ready (readiness) diventano parte della definizione di “done” del team e ti spingono verso confini più puliti:
- liveness: “il processo è in esecuzione?”
- readiness: “può servire traffico?” (es. connessione al DB, migrazioni applicate)
Quando questi endpoint sono standardizzati presto, i requisiti operativi smettono di filtrare nel codice delle feature.
Usare l'osservabilità per guidare i refactor
I dati di osservabilità sono anche uno strumento decisionale. Se le trace mostrano che un endpoint passa ripetutamente tempo nella stessa dipendenza, è un segnale per estrarre un modulo, aggiungere caching o ridisegnare una query. Se i log rivelano forme d'errore incoerenti, è un invito a centralizzare la gestione degli errori. In altre parole: gli hook di osservabilità del framework non servono solo per il debug—ti aiutano a riorganizzare la codebase con fiducia.
Costruisci un backend rapidamente
Trasforma le convenzioni del tuo framework in un vero codice generando un backend da una singola chat.
Un framework backend non organizza solo il codice—stabilisce le “regole di casa” per come il team lavora. Quando tutti seguono le stesse convenzioni (posizione dei file, naming, come si collegano le dipendenze), le review diventano più veloci e l'onboarding più semplice.
Generazione di codice e scaffold: usali ma non venerateli
Gli scaffold possono standardizzare nuovi endpoint, moduli e test in pochi minuti. La trappola è lasciare che i generatori dettino il modello di dominio.
Usa gli scaffold per creare shell coerenti (route/controller, DTO, stub di test), poi modifica subito l'output per aderire alle regole architetturali del team. Una buona policy: i generatori sono ammessi, ma il codice finale deve comunque sembrare una progettazione ponderata—non un dump di template.
Se usi flussi assistiti da AI, applica la stessa disciplina: tratta il codice generato come scaffolding. Su piattaforme come Koder.ai puoi iterare rapidamente via chat mantenendo comunque le convenzioni del team (confini dei moduli, pattern DI, forme d'errore) tramite le review—perché velocità aiuta solo se la struttura resta prevedibile.
Style guide allineate con gli idiomi del framework
I framework spesso implicano uno stile idiomatico: dove sta la validazione, come si sollevano errori, come si nominano i service. Cattura queste aspettative in una breve style guide del team che includa:
- Convenzioni di naming che corrispondono ai primitivi del framework (es. Controller, Service, Module)
- Confini delle cartelle (cosa è permesso in un controller vs in domain/service)
- Esempi di un endpoint “buono"
Tienila leggera e pratica; linkala da /contributing.
Automatizza gli standard. Configura formatter e linter per riflettere le convenzioni del framework (import, decorator/annotation, pattern async). Poi applicali via pre-commit e CI, così le review si concentrano sul design e non su spaziature o naming.
Template PR e checklists di review legati all'architettura
Una checklist basata sul framework previene la deriva lenta verso l'incoerenza. Aggiungi un template PR che chieda ai revisori di confermare cose come:
- I nuovi endpoint seguono le convenzioni routing/controller
- Validazione e risposte d'errore corrispondono allo standard del team
- I confini delle dipendenze sono rispettati (niente chiamate dirette al DB dai controller, ecc.)
- I test seguono i pattern raccomandati dal framework
Col tempo, questi piccoli guardrail di workflow sono ciò che mantiene una codebase manutenibile mentre il team cresce.
Scegliere ed evolvere un framework senza riscritture dolorose
Le scelte di framework tendono a fissare pattern—layout delle directory, stile dei controller, DI e persino come la gente scrive i test. L'obiettivo non è scegliere il framework perfetto; è scegliere quello che si adatta a come il tuo team consegna software, e mantenere la possibilità di cambiare quando i requisiti evolvono.
Valutare l'adattamento alle dimensioni e agli obiettivi del team
Parti dai vincoli di delivery, non da checklist di feature. Un team piccolo di solito beneficia di forti convenzioni, tooling “batteries-included” e onboarding veloce. Team più grandi spesso hanno bisogno di confini di modulo più netti, punti di estensione stabili e pattern che rendano difficile creare accoppiamenti nascosti.
Fai domande pratiche:
- Riuscite a far rispettare una struttura coerente con poca polizia nelle code review?
- Il framework rende la cosa giusta facile (validazione, error handling, logging), o ogni team inventa la propria strada?
- Gli aggiornamenti sono prevedibili (changelog chiari, percorsi di deprecazione), e l'ecosistema è maturo per le vostre esigenze?
Segnali d'allarme che prevedono riscritture
Una riscrittura è spesso il risultato di piccoli dolori ignorati. Fai attenzione a:
- Confini poco chiari: logica di business che migra in controller, middleware o modelli ORM
- Test lenti: integration test che richiedono minuti, spingendo i team a saltarli
- Upgrade fragili: cambiamenti breaking frequenti, dipendenza da API interne o workaround della community che diventano la norma
Pattern di refactor incrementale che mantengono la delivery
Puoi evolvere senza fermare il lavoro di feature introducendo cuciture:
- Approccio strangler: instrada un piccolo set di endpoint attraverso un nuovo modulo mantenendo il vecchio sistema attivo
- Layer adapter: avvolgi primitive specifiche del framework dietro interfacce tue (request context, logger, repository)
- Confini “ports and adapters”: sposta la logica di dominio in moduli plain con import minimi del framework, poi collegali ai bordi
Checklist di adozione e prossimi passi
Prima di impegnarti (o prima del prossimo major upgrade), fai una breve prova:
- Costruisci un endpoint reale end-to-end: auth, validazione, risposte d'errore e logging.
- Scrivi due test: un unit veloce per la logica di dominio, un integration per lo strato HTTP.
- Simula un cambiamento: aggiungi un campo, versiona una risposta e rifattorizza un modulo.
- Revisiona le note di upgrade dell'ultima major release—avrebbe causato problemi a voi?
Se vuoi un modo strutturato per valutare le opzioni, crea un RFC leggero e conservalo con la codebase (per esempio, /docs/decisions) così i team futuri capiranno perché avete scelto e come cambiare in sicurezza.
Una lente in più da considerare: se il tuo team sperimenta cicli di build più rapidi (incluso sviluppo guidato dalla chat), valuta se il tuo workflow continua a produrre gli stessi artefatti architetturali—moduli chiari, contratti applicabili e default operativi. I migliori speedup (sia dal CLI di un framework che da una piattaforma come Koder.ai) sono quelli che riducono il tempo di ciclo senza erodere le convenzioni che mantengono un backend manutenibile.