Quale problema cercava di risolvere NoSQL?
NoSQL è nato quando molti team si sono trovati di fronte a una discrepanza tra ciò di cui avevano bisogno nelle loro applicazioni e ciò per cui i database relazionali tradizionali (database SQL) erano ottimizzati. SQL non ha “fallito” — ma alla scala del web, alcuni team hanno cominciato a dare priorità a obiettivi diversi.
Le due pressioni: scala e cambiamento
Prima di tutto, la scala. Le app consumer popolari hanno iniziato a vedere picchi di traffico, scritture continue e volumi massicci di dati generati dagli utenti. Per questi carichi di lavoro, “comprare un server più grande” è diventato costoso, lento da mettere in pratica e, alla fine, limitato dalla dimensione massima della macchina che fosse ragionevole gestire.
Secondo, il cambiamento. Le funzionalità di prodotto evolvono rapidamente e i dati sottostanti non sempre si adattano bene a un set fisso di tabelle. Aggiungere nuovi attributi ai profili utente, memorizzare più tipi di eventi o ingerire JSON semi-strutturati da fonti diverse spesso significava migrazioni di schema ripetute e coordinamento tra team.
Perché i database relazionali faticavano in certi casi
I database relazionali sono eccellenti nell'applicare struttura e nel permettere query complesse su tabelle normalizzate. Ma alcuni carichi a larga scala rendevano più difficile sfruttare quei punti di forza:
- Molte scritture concorrenti su molte tabelle possono creare contesa.
- Query pesanti che usano join possono diventare costose man mano che i dati crescono rapidamente.
- Scalare orizzontalmente su molte macchine è possibile, ma mantenerlo operativo mantenendo la consistenza rigorosa ovunque può essere complicato.
Il risultato: alcuni team hanno cercato sistemi che scambiassero certe garanzie e capacità per una scalabilità più semplice e iterazioni più rapide.
NoSQL: una famiglia di approcci, non una singola cosa
NoSQL non è un singolo database o design. È un termine ombrello per sistemi che enfatizzano una combinazione di:
- Scalabilità orizzontale (aggiungere più macchine)
- Modelli di dati flessibili
- Pattern di accesso ottimizzati per specifiche esigenze applicative
Un azzeramento delle aspettative
NoSQL non è mai stato pensato come sostituto universale di SQL. È un insieme di compromessi: si può guadagnare scalabilità o flessibilità dello schema, ma si può accettare garanzie di consistenza più deboli, meno opzioni per query ad-hoc o più responsabilità nel modellare i dati a livello applicativo.
Perché la scalabilità tradizionale ha iniziato a cedere
Per anni, la risposta standard a un database lento era semplice: comprare un server più grande. Aggiungi CPU, più RAM, dischi più veloci e mantieni lo stesso schema e modello operativo. Questo approccio di “scale up” ha funzionato — finché non è diventato poco pratico.
Lo scaling verticale ha incontrato limiti difficili
Le macchine di fascia alta diventano costose rapidamente e la curva prezzo/prestazioni alla fine diventa sfavorevole. Gli upgrade spesso richiedono approvazioni di budget importanti e finestre di manutenzione per spostare i dati e fare il cutover. Anche se puoi permetterti hardware più grande, un singolo server ha comunque un tetto: un bus di memoria, un sottosistema di storage e un nodo primario che assorbe il carico di scrittura.
Con la crescita dei prodotti, i database si sono trovati sotto una pressione costante di letture/scritture invece che picchi occasionali. Il traffico è diventato veramente 24/7 e alcune funzionalità hanno creato pattern di accesso disomogenei. Un piccolo numero di righe o partizioni molto accessate poteva dominare il traffico, causando tabelle “calde” (o chiavi calde) che rallentavano tutto il resto.
I colli di bottiglia operativi sono diventati comuni:
- Crescita degli indici quando nuove funzionalità richiedevano indici secondari
- Contesa dovuta a molte scritture concorrenti sulle stesse tabelle
- Attese di lock che rendevano la latenza imprevedibile sotto carico
- Lag nella replica e failover più lenti man mano che i dataset crescevano
I server più grandi non risolvevano la disponibilità globale
Molte applicazioni avevano bisogno di essere disponibili in più regioni, non solo veloci in un singolo data center. Un database “principale” in un'unica posizione aumenta la latenza per utenti distanti e rende le interruzioni più catastrofiche. La domanda è passata da “Come compriamo una macchina più grande?” a “Come eseguiamo il database su molte macchine e location?”
La necessità di modelli di dati flessibili
I database relazionali brillano quando la forma dei dati è stabile. Ma molti prodotti moderni non restano fermi. Lo schema di una tabella è intenzionalmente rigido: ogni riga segue lo stesso insieme di colonne, tipi e vincoli. Quella prevedibilità è preziosa — fino a quando si itera rapidamente.
Schemi rigidi e il costo reale del cambiamento
Nella pratica, cambi frequenti di schema possono essere costosi. Un aggiornamento apparentemente piccolo può richiedere migrazioni, backfill, aggiornamenti di indici, tempistiche di deployment coordinate e pianificazione della compatibilità in modo che i vecchi percorsi di codice non si rompano. Su tabelle grandi, anche aggiungere una colonna o cambiare un tipo può diventare un'operazione che richiede tempo con rischio operativo reale.
Questa frizione spinge i team a rimandare cambiamenti, accumulare soluzioni alternative o memorizzare blob disordinati in campi di testo — nessuna di queste è ideale per iterare rapidamente.
I dati semi-strutturati si adattano all'evoluzione dei prodotti
Molti dati applicativi sono naturalmente semi-strutturati: oggetti nidificati, campi opzionali e attributi che evolvono nel tempo.
Per esempio, un “profilo utente” può partire con nome e email, poi crescere includendo preferenze, account collegati, indirizzi di spedizione, impostazioni di notifica e flag di esperimenti. Non tutti gli utenti hanno ogni campo e nuovi campi arrivano gradualmente. I modelli documentali possono memorizzare forme nidificate e irregolari direttamente senza costringere ogni record nello stesso template rigido.
Iterazione più rapida, meno join imbarazzanti
La flessibilità riduce anche la necessità di join complessi per certe forme di dati. Quando una singola schermata necessita di un oggetto composto (un ordine con articoli, informazioni di spedizione e cronologia di stato), i design relazionali possono richiedere più tabelle e join — più layer ORM che tentano di nascondere quella complessità ma spesso aggiungono attrito.
Le opzioni NoSQL hanno reso più facile modellare i dati più vicino a come l'applicazione li legge e scrive, aiutando i team a rilasciare cambiamenti più velocemente.
Lo shift web-scale che ha cambiato i requisiti dei database
Le applicazioni web non si sono solo ingrandite — hanno cambiato forma. Invece di servire un numero prevedibile di utenti interni durante l'orario lavorativo, i prodotti hanno iniziato a servire milioni di utenti globali 24 ore su 24, con picchi improvvisi causati da lanci, notizie o condivisioni social.
Le aspettative “always-on” hanno alzato l'asticella: i downtime sono diventati una notizia, non un inconveniente. Allo stesso tempo, i team dovevano rilasciare funzionalità più velocemente — spesso prima di sapere quale sarebbe stato il modello dati “finale”.
Distribuito è diventato il percorso predefinito per crescere
Per tenere il passo, scalare una singola macchina non è bastato. Più traffico gestivi, più volevi capacità che si potesse aggiungere incrementando: aggiungi un nodo, distribuisci il carico, isola i guasti.
Questo ha spinto l'architettura verso flotte di macchine invece di una singola “main box”, e ha cambiato ciò che i team si aspettavano dai database: non solo correttezza, ma prestazioni prevedibili sotto alta concorrenza e comportamento degradato quando parti del sistema sono unhealthy.
Pattern adottati dai team prima che i database si aggiornassero
Prima che “NoSQL” diventasse categoria mainstream, molti team avevano già piegato i sistemi verso le realtà web-scale:
- Layer di cache (spesso in-memory) per ridurre letture ripetute
- Denormalizzazione per evitare join costosi e ridurre i round-trip
- View precomputate e rollup materializzati per feed, timeline e dashboard
Queste tecniche funzionavano, ma spostavano la complessità nel codice applicativo: invalidazione della cache, mantenere dati duplicati coerenti e costruire pipeline per record “ready-to-serve”.
Come questo ha costretto l'evoluzione dei database
Man mano che questi pattern sono diventati standard, i database hanno dovuto supportare la distribuzione dei dati su più macchine, tollerare fallimenti parziali, gestire alti volumi di scrittura e rappresentare dati in evoluzione in modo pulito. I database NoSQL sono emersi in parte per rendere strategie comuni di web-scale prima classe invece che workaround continui.
Compromessi distribuiti e il teorema CAP
Try a hybrid setup
Stand up a hybrid baseline with Postgres as system of record, then iterate safely.
Quando i dati vivono su una sola macchina, le regole sembrano semplici: c'è una singola fonte di verità e ogni lettura o scrittura può essere verificata immediatamente. Quando distribuisci i dati su server (spesso tra regioni), appare una nuova realtà: i messaggi possono essere ritardati, i nodi possono fallire e parti del sistema possono temporaneamente smettere di comunicare.
Il compromesso distributivo chiave (in parole semplici)
Un database distribuito deve decidere cosa fare quando non può coordinarsi in modo sicuro. Deve continuare a servire richieste così l'app rimane “up”, anche se i risultati potrebbero essere leggermente non aggiornati? Oppure deve rifiutare alcune operazioni finché non può confermare che le repliche sono d'accordo, il che può assomigliare a downtime per gli utenti?
Queste situazioni avvengono durante guasti di router, reti sovraccariche, deploy rolling, misconfigurazioni di firewall e ritardi nella replica cross-region.
CAP in una frase: C, A e P
Il teorema CAP è una scorciatoia per tre proprietà che vorresti avere contemporaneamente:
- Coerenza (C): ogni lettura restituisce l'ultima scrittura (o un errore). In pratica, “tutti vedono la stessa risposta in questo momento”.
- Disponibilità (A): ogni richiesta riceve una risposta (non necessariamente il dato più recente).
- Tolleranza alla partizione (P): il sistema continua a funzionare anche se la rete si spezza in gruppi isolati.
Il punto chiave non è “scegli due per sempre.” È: quando succede una partizione di rete, devi scegliere tra coerenza e disponibilità. Nei sistemi web-scale, le partizioni sono trattate come inevitabili — specialmente in setup multi-regione.
Le partizioni si collegano direttamente ai guasti reali
Immagina che la tua app giri in due regioni per resilienza. Un taglio di fibra o un problema di instradamento impedisce la sincronizzazione.
- Se privilegi disponibilità, entrambe le regioni continuano ad accettare scritture e i dati possono divergere temporaneamente.
- Se privilegi coerenza, una regione può rifiutare scritture (o letture) finché non può confermare l'accordo.
Diversi sistemi NoSQL (e anche configurazioni diverse dello stesso sistema) fanno compromessi diversi a seconda di ciò che conta di più: esperienza utente durante i guasti, garanzie di correttezza, semplicità operativa o comportamento di recovery.
Scalare orizzontalmente: sharding e replica come idee fondamentali
Scalare out (scaling orizzontale) significa aumentare la capacità aggiungendo più macchine (nodi) invece di comprare un server più potente. Per molti team, questo è stato un cambiamento finanziario e operativo: nodi commodity potevano essere aggiunti incrementally, i fallimenti erano attesi e la crescita non richiedeva migrazioni rischiose su “big box”.
Sharding (partizionamento): distribuire il lavoro
Per rendere utili molti nodi, i sistemi NoSQL hanno fatto affidamento sullo sharding (chiamato anche partizionamento). Invece di un singolo database che gestisce ogni richiesta, i dati sono divisi in partizioni e distribuiti sui nodi.
Un esempio semplice è partizionare per chiave (come user_id):
- Nodo A memorizza utenti 1–1.000.000
- Nodo B memorizza utenti 1.000.001–2.000.000
Letture e scritture si distribuiscono, riducendo hotspot e permettendo al throughput di crescere aggiungendo nodi. La chiave di partizione diventa una decisione di progettazione: scegli una chiave allineata ai pattern di query, altrimenti potresti accidentalmente convogliare troppo traffico in un shard.
Replica: disponibilità e scalabilità delle letture
La replica significa mantenere più copie degli stessi dati su nodi diversi. Questo migliora:
- Disponibilità: se un nodo fallisce, un'altra replica può servire le richieste.
- Capacità di lettura: le letture possono essere servite da più repliche.
La replica permette anche di distribuire i dati su rack o regioni per sopravvivere a guasti localizzati.
Il costo nascosto: rebalancing e operazioni
Sharding e replica introducono lavoro operativo continuo. Man mano che i dati crescono o i nodi cambiano, il sistema deve ribilanciare — spostando partizioni rimanendo online. Se gestito male, il rebalancing può causare picchi di latenza, carico non uniforme o temporanee carenze di capacità.
Questo è un compromesso centrale: scaling più economico tramite più nodi, in cambio di una distribuzione più complessa, monitoraggio e gestione dei fallimenti.
Modelli di consistenza: dalla coerenza forte alla eventuale
Una volta che i dati sono distribuiti, un database deve definire cosa significa “corretto” quando gli aggiornamenti avvengono in concorrenza, le reti rallentano o i nodi non possono comunicare.
Coerenza forte
Con la coerenza forte, una volta che una scrittura è confermata, ogni lettore dovrebbe vederla immediatamente. Questo corrisponde all'esperienza della “singola fonte di verità” che molti associano ai database relazionali.
La sfida è la coordinazione: garanzie rigorose tra nodi richiedono più messaggi, attese per risposte sufficienti e gestione dei fallimenti a metà di un'operazione. Quanto più distanti sono i nodi (o quanto più sono occupati), tanto più latenza puoi introdurre — a volte su ogni scrittura.
Consistenza eventuale
La consistenza eventuale rilassa quella garanzia: dopo una scrittura, nodi diversi possono restituire risposte differenti per un breve periodo, ma il sistema converge nel tempo.
Esempi:
- Un contatore di “like” potrebbe mostrare 101 like su una replica mentre un'altra ancora mostra 100 per alcuni secondi.
- Un nuovo post può apparire in un feed per alcuni utenti prima che altri lo vedano, soprattutto tra regioni.
Per molte esperienze utente, quella discrepanza temporanea è accettabile se il sistema resta veloce e disponibile.
Conflitti e come vengono risolti
Se due repliche accettano aggiornamenti quasi nello stesso istante, il database ha bisogno di una regola di merge.
Approcci comuni includono:
- Timestamp (last-write-wins): mantenere l'aggiornamento con il timestamp più recente. Semplice, ma può perdere dati se gli orologi non sono sincronizzati o se “più nuovo” non è semanticamente corretto.
- Vettori di versione (concettualmente): tracciare quali repliche hanno visto quali aggiornamenti, rilevare scritture concorrenti e unire o esporre i conflitti.
Dove la coerenza forte conta ancora
La coerenza forte vale il costo per trasferimenti di denaro, limiti di inventario, username unici, permessi e qualsiasi workflow in cui avere “due verità per un momento” possa causare danni reali.
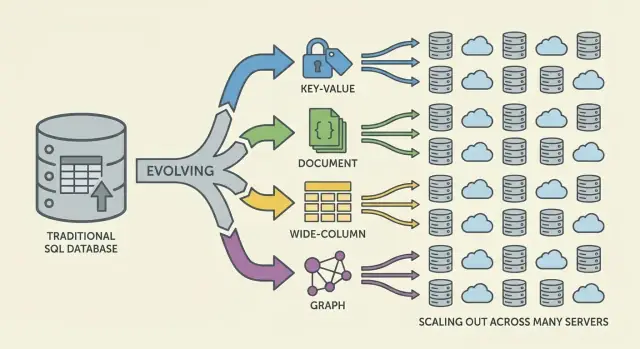
Le principali famiglie di database NoSQL (e cosa ottimizzavano)
Prototype your data strategy
Prototype a SQL vs NoSQL approach fast with a full-stack app generated from chat.
NoSQL è un insieme di modelli che fanno compromessi diversi attorno a scala, latenza e forma dei dati. Capire la “famiglia” aiuta a prevedere cosa sarà veloce, cosa sarà doloroso e perché.
Key-value store: velocità grazie alla semplicità
I database key-value memorizzano un valore dietro una chiave unica, come una gigantesca hashmap distribuita. Poiché il pattern di accesso è tipicamente “get by key” / “set by key”, possono essere estremamente veloci e scalabili orizzontalmente.
Sono ottimi quando conosci già la chiave di lookup (sessioni, caching, feature flag), ma limitati per query ad-hoc: filtrare su più campi spesso non è l'obiettivo del sistema.
I database documentali memorizzano documenti simili a JSON (spesso raggruppati in collection). Ogni documento può avere una struttura leggermente diversa, il che supporta la flessibilità dello schema man mano che i prodotti evolvono.
Ottimizzano le letture e le scritture di documenti interi e le query su campi al loro interno — senza costringere tabelle rigide. Il compromesso: modellare relazioni può diventare complesso e i join (se supportati) possono essere più limitati rispetto ai sistemi relazionali.
Wide-column: elevato throughput di scrittura su scala enorme
I database wide-column (ispirati a Bigtable) organizzano i dati per chiavi di riga, con molte colonne che possono variare per riga. Eccellono in tassi di scrittura massicci e storage distribuito, rendendoli adatti per serie temporali, eventi e workload di log.
Premiano spesso un'attenta progettazione attorno ai pattern di accesso: si interroga efficientemente per chiave primaria e regole di clustering, non tramite filtri arbitrari.
Database a grafo: interrogazioni incentrate sulle relazioni
I database a grafo trattano le relazioni come dati di prima classe. Invece di ripetere join tra tabelle, attraversano archi tra nodi, rendendo naturali e veloci query del tipo “come sono connessi questi elementi?” (ring di frodi, raccomandazioni, grafi di dipendenza).
Guida rapida: quando conviene ogni modello
- Key-value: lookup più veloci per ID; caching, sessioni, contatori
- Document: dati di prodotto in evoluzione; profili, cataloghi, contenuti
- Wide-column: pesante ingestione su larga scala; telemetria, log, serie temporali
- Graph: query profonde sulle relazioni; grafi sociali, routing, analisi delle frodi
Cambiamenti nel data modeling: meno join, design più intenzionale
I database relazionali incoraggiano la normalizzazione: dividere i dati in molte tabelle e riassemblarli con join al momento della query. Molti sistemi NoSQL ti spingono a progettare attorno ai pattern di accesso più importanti — a volte a costo di duplicazione — per mantenere la latenza prevedibile tra i nodi.
Perché la denormalizzazione è così comune
In database distribuiti, un join può richiedere il recupero di dati da più partizioni o macchine. Questo aggiunge hop di rete, coordinazione e latenza imprevedibile. La denormalizzazione (memorizzare i dati correlati insieme) riduce i round-trip e mantiene spesso una lettura “locale”.
Una conseguenza pratica: potresti memorizzare lo stesso nome cliente in un record orders anche se esiste anche in customers, perché “mostrami gli ultimi 20 ordini” è una query primaria.
Vincoli sulle query: meno join, più modellazione nell'app
Molti database NoSQL supportano join limitati (o nessuno), quindi l'app prende più responsabilità:
- Recupera un documento/riga per chiave e renderizza direttamente
- Leggi due dataset separati e uniscili in codice
- Precalcola modelli di lettura (count, riassunti) per evitare scansioni costose
Ecco perché il modeling NoSQL spesso inizia con: “Quali schermate dobbiamo caricare?” e “Quali sono le query principali che devono essere veloci?”
Indici secondari — e i loro costi nascosti
Gli indici secondari possono abilitare nuove query (“trova utenti per email”), ma non sono gratuiti. Nei sistemi distribuiti, ogni scrittura può aggiornare più strutture di indice, portando a:
- Amplificazione delle scritture: una scrittura logica diventa più scritture fisiche
- Storage extra: le voci d'indice possono avvicinarsi alla dimensione dei dati
- Complessità operativa: gli indici possono andare indietro rispetto ai dati o richiedere tuning
Esempi di scelte di modellazione che migliorano le prestazioni
- Embed invece di reference: memorizzare gli articoli di un ordine dentro il documento dell'ordine per leggere un ordine in una richiesta
- Bucket per dati time-series: mantenere eventi per dispositivo per giorno per evitare partizioni non limitate
- Materializzare modelli di lettura: mantenere un record
user_profile_summary per servire una pagina profilo senza scansionare post, like e follow
Benefici e compromessi che i team hanno accettato
Keep full control
Generate the app, then export source code to extend it your way.
NoSQL non è stato adottato perché fosse “migliore” in ogni aspetto. È stato adottato perché i team erano disposti a scambiare alcune comodità dei database relazionali per velocità, scala e flessibilità sotto pressione web-scale.
Cosa hanno guadagnato i team
Scalare out per design. Molti sistemi NoSQL hanno reso pratico aggiungere macchine (scalabilità orizzontale) invece di aggiornare continuamente un singolo server. Sharding e replica sono diventati capacità core, non ripensamenti.
Schemi flessibili. I sistemi documentali e key-value permettono alle applicazioni di evolvere senza far passare ogni modifica di campo attraverso una definizione di tabella rigida, riducendo l'attrito quando i requisiti cambiano settimanalmente.
Pattern di alta disponibilità. La replica tra nodi e regioni ha reso più semplice mantenere i servizi attivi durante guasti hardware o manutenzioni.
Cosa i team hanno pagato
Duplicazione dei dati e denormalizzazione. Evitare i join spesso significa duplicare i dati. Questo migliora le prestazioni di lettura ma aumenta lo storage e introduce la complessità di “aggiornalo ovunque”.
Sorpresi dalla coerenza. La consistenza eventuale può essere accettabile — finché non lo è. Gli utenti possono vedere dati obsoleti o casi limite confusi se l'app non è progettata per tollerare o risolvere i conflitti.
Analisi più difficili (a volte). Alcuni store NoSQL eccellono alle letture/scritture operative ma rendono le query ad-hoc, i report o aggregazioni complesse più macchinose rispetto ai sistemi SQL-first.
Perché operazioni e strumenti contavano
L'adozione iniziale di NoSQL spesso ha spostato lo sforzo dalle funzionalità del database alla disciplina ingegneristica: monitorare la replica, gestire le partizioni, eseguire compaction, pianificare backup/restore e testare scenari di failure. I team con maturità operativa elevata ne hanno beneficiato di più.
Come valutare i compromessi
Scegli in base alle realtà del workload: latenza attesa, throughput di picco, pattern di query dominanti, tolleranza per letture stale e requisiti di recovery (RPO/RTO). La scelta “giusta” NoSQL è spesso quella che corrisponde a come la tua applicazione fallisce, scala e deve essere interrogata — non quella con la checklist più impressionante.
Come decidere se NoSQL è adatto oggi
Scegliere NoSQL non dovrebbe partire dai brand o dall'hype — dovrebbe partire da ciò che la tua applicazione deve fare, come crescerà e cosa significa “corretto” per i tuoi utenti.
Parti dai requisiti e dai pattern di accesso
Prima di scegliere un datastore, scrivi:
- Le 5–10 query/operazioni principali che devi supportare (letture, scritture, ricerca, aggregazioni)
- Traffico previsto ora vs. 12–24 mesi
- Tolleranza per dati obsoleti (millisecondi, secondi, mai)
- Aspettative di failure (cosa succede se un nodo o una regione cade?)
Se non riesci a descrivere chiaramente i pattern di accesso, qualsiasi scelta sarà un colpo di fortuna — specialmente con NoSQL, dove il modellamento è spesso plasmato attorno a come leggi e scrivi.
Una checklist semplice (SQL vs NoSQL vs ibrido)
Usala come filtro rapido:
- Scegli SQL se hai bisogno di coerenza forte di default, query ad-hoc complesse e molte relazioni che traggono beneficio dai join.
- Scegli NoSQL se hai bisogno di scalare orizzontalmente facilmente per pattern di accesso specifici, puoi progettare i dati attorno a quei pattern e puoi accettare consistenza rilassata per alcuni workflow.
- Scegli ibrido se diverse parti dell'app hanno esigenze diverse (comune nei prodotti reali).
Un segnale pratico: se la tua “verità fondamentale” (ordini, pagamenti, inventario) deve essere corretta sempre, tienila in SQL o in un altro store con forte consistenza. Se servi contenuti ad alto volume, sessioni, caching, feed di attività o dati generati dagli utenti flessibili, NoSQL può adattarsi bene.
Considera la persistenza poliglotta (volontaria)
Molti team hanno successo con più store: per esempio, SQL per transazioni, un database documentale per profili/contenuti e uno store key-value per sessioni. Lo scopo non è complessità fine a sé stessa — è abbinare ogni workload a uno strumento che lo gestisca in modo pulito.
Questo è anche il punto dove il workflow dello sviluppatore conta. Se stai iterando sull'architettura (SQL vs NoSQL vs ibrido), essere in grado di creare rapidamente un prototipo funzionante — API, modello dati e UI — può ridurre il rischio. Piattaforme come Koder.ai aiutano i team a farlo generando app full-stack dalla chat, tipicamente con frontend React e backend Go + PostgreSQL, permettendo poi di esportare il codice sorgente. Anche se in seguito introduci uno store NoSQL per workload specifici, avere un forte sistema SQL “system of record” più prototipazione rapida, snapshot e rollback può rendere gli esperimenti più sicuri e veloci.
Valida con test, non con opinioni
Qualunque sia la tua scelta, provaci con dati reali:
- Esegui load test con query realistiche e dimensioni dei dati realistiche.
- Fai failure drill (uccidi nodi, simula problemi di rete, testa restore).
- Crea un piano di evoluzione dello schema: come aggiungerai campi, migrerai record e manterrai le vecchie/nuove versioni compatibili durante il rollout.
Se non puoi testare questi scenari, la decisione sul database resta teorica — e la produzione finirà per fare i test al tuo posto.