09 ago 2025·8 min
Come le astrazioni dei framework perdono quando i sistemi scalano
Scopri perché le astrazioni ad alto livello si rompono alla scala, i pattern più comuni di perdita, i sintomi da monitorare e rimedi pratici di design e operazioni.
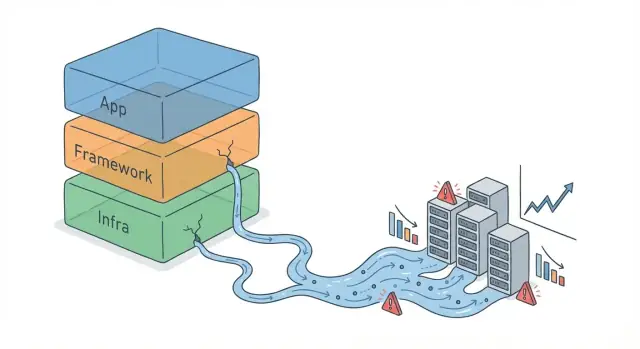
Scopri perché le astrazioni ad alto livello si rompono alla scala, i pattern più comuni di perdita, i sintomi da monitorare e rimedi pratici di design e operazioni.
Un'astrazione è uno strato che semplifica: un'API di framework, un ORM, un client di message queue, persino un helper di caching “in una riga”. Ti permette di ragionare in concetti di alto livello (“salva questo oggetto”, “invia questo evento”) senza gestire continuamente i dettagli a basso livello.
Una perdita di astrazione accade quando quei dettagli nascosti iniziano comunque a influenzare i risultati reali—e quindi sei costretto a capire e gestire ciò che l'astrazione voleva nascondere. Il codice continua a “funzionare”, ma il modello semplificato non predice più il comportamento reale.
La crescita iniziale è indulgente. Con poco traffico e dataset piccoli, le inefficienze si nascondono dietro CPU libere, cache calde e query veloci. Gli spike di latenza sono rari, i retry non si accumulano e una riga di log leggermente sprecona non pesa.
Con l'aumento del volume, le stesse scorciatoie possono amplificarsi:
Le astrazioni che perdono di solito emergono in tre aree:
Nelle sezioni seguenti ci concentreremo sui segnali pratici che indicano una perdita di astrazione, su come diagnosticare la causa sottostante (non solo i sintomi) e sulle opzioni di mitigazione—dalla semplice configurazione al deliberato “scendere di livello” quando l'astrazione non corrisponde più alla scala.
Molto software segue lo stesso arco: un prototipo dimostra l'idea, il prodotto viene rilasciato e poi l'uso cresce più velocemente dell'architettura originale. All'inizio, i framework sembrano magici perché i loro default ti permettono di muoverti in fretta—routing, accesso al DB, logging, retry e job in background “gratis”.
Alla scala, vuoi ancora quei benefici—ma i default e le API comode diventano assunzioni.
I default dei framework solitamente presumono:
Queste assunzioni reggono all'inizio, quindi l'astrazione sembra pulita. Ma la scala cambia cosa significa “normale”. Una query che va bene a 10.000 righe diventa lenta a 100 milioni. Un handler sincrono che sembrava semplice inizia a scadere quando il traffico picchia. Una policy di retry che mitigava fallimenti occasionali può amplificare outage quando migliaia di client ritentano contemporaneamente.
La scala non è solo “più utenti”. È volume dati maggiore, traffico a raffiche e più lavoro concorrente. Queste cose mettono pressione sulle parti che le astrazioni nascondono: pool di connessioni, scheduling dei thread, profondità delle code, pressione sulla memoria, limiti I/O e limiti di rate imposti dalle dipendenze.
I framework spesso scelgono impostazioni generiche sicure (dimensione pool, timeout, comportamento di batching). Sotto carico, queste impostazioni possono tradursi in contendibilità, latenza long-tail e failure a cascata—problemi non visibili quando tutto sta comodamente dentro i margini.
Gli ambienti di staging raramente riflettono le condizioni di produzione: dataset più piccoli, meno servizi, comportamento di cache differente e attività utenti meno “disordinata”. In produzione hai anche variabilità reale di rete, noisy neighbors, deploy rolling e failure parziali. Ecco perché astrazioni che sembravano ermetiche nei test possono iniziare a perdere quando le condizioni reali applicano pressione.
Quando un'astrazione perde, i sintomi raramente si presentano come un messaggio d'errore chiaro. Piuttosto, vedi pattern: comportamenti che andavano bene a basso traffico diventano imprevedibili o costosi con volumi maggiori.
Un'astrazione che perde spesso si manifesta attraverso latenza visibile agli utenti:
Questi sono segnali classici che l'astrazione nasconde un collo di bottiglia che non puoi risolvere senza scendere di livello (es.: ispezionare query reali, uso delle connessioni o comportamento I/O).
Alcune perdite si vedono prima nelle fatture anziché nelle dashboard:
Se scalare l'infrastruttura non ripristina le prestazioni in modo proporzionale, spesso non è pura capacità bruta—è overhead che non avevi realizzato di pagare.
Le perdite diventano problemi di affidabilità quando interagiscono con retry e catene di dipendenze:
Usa questo per un controllo rapido prima di comprare più capacità:
Se i sintomi si concentrano in una dipendenza (DB, cache, rete) e non rispondono in modo prevedibile a “più server”, è un forte indicatore che devi guardare sotto l'astrazione.
Gli ORM sono ottimi per eliminare boilerplate, ma rendono facile dimenticare che ogni oggetto prima o poi diventa una query SQL. A piccola scala, questo compromesso è invisibile. A volumi maggiori, il database è spesso il primo luogo dove un'astrazione “pulita” inizia a chiedere interessi.
L'N+1 accade quando carichi una lista di record parent (1 query) e poi, dentro un ciclo, carichi i record correlati per ciascun parent (N query in più). In locale sembra ok—magari N è 20. In produzione N diventa 2.000 e la tua app trasforma silenziosamente una richiesta in migliaia di round trip.
La parte insidiosa è che nulla “si rompe” immediatamente; la latenza aumenta gradualmente, i pool di connessioni si riempiono e i retry moltiplicano il carico.
Le astrazioni spesso incoraggiano a prendere oggetti completi di default, anche quando servono solo due campi. Questo aumenta I/O, memoria e trasferimento di rete.
Allo stesso tempo, gli ORM possono generare query che non usano gli indici che pensavi venissero usati (o che non esistono). Un indice mancante può trasformare una lookup selettiva in una scansione di tabella.
I join sono un altro costo nascosto: ciò che appare come “includi la relazione” può diventare una query multi-join con risultati intermedi enormi.
Sotto carico, le connessioni al database sono una risorsa scarsa. Se ogni richiesta scaturisce molte query, il pool colpisce il limite rapidamente e la tua app comincia ad accodare.
Transazioni lunghe (a volte accidentali) possono anche causare contendibilità—i lock durano più a lungo e la concorrenza crolla.
EXPLAIN e tratta gli indici come parte del design dell'app, non come un pensiero secondario al DBA.La concorrenza è dove le astrazioni possono sembrare “sicure” in sviluppo e poi fallire rumorosamente sotto carico. Il modello di default di un framework spesso nasconde il vero vincolo: non stai solo servendo richieste—stai gestendo contendibilità per CPU, thread, socket e capacità a valle.
Thread-per-request (comune negli stack web classici) è semplice: ogni richiesta ottiene un thread lavoratore. Rompe quando l'I/O lento (DB, chiamate API) fa accumulare thread. Quando il pool di thread è esaurito, le nuove richieste si accodano, la latenza esplode e infine si raggiungono i timeout—mentre il server è “occupato” a non fare nulla ma ad aspettare.
I modelli async/event-loop gestiscono molte richieste in volo con meno thread, quindi vanno bene ad alta concorrenza. Rompono in modo diverso: una chiamata bloccante (una libreria sincrona, parsing JSON pesante, logging intensivo) può bloccare l'event loop, trasformando “una richiesta lenta” in “tutto lento”. L'async rende anche facile creare troppa concorrenza, sovrastando una dipendenza più rapidamente di quanto i limiti di thread farebbero.
Il backpressure è il sistema che dice ai chiamanti “rallenta; non posso accettare altro in sicurezza”. Senza di esso, una dipendenza lenta (DB, provider di pagamento) non solo rallenta le risposte—ma aumenta il lavoro in volo, l'uso della memoria e la lunghezza delle code. Quel lavoro extra rende la dipendenza ancora più lenta, creando un loop di retroazione.
I timeout devono essere espliciti e stratificati: client, servizio e dipendenza. Se i timeout sono troppo lunghi, le code crescono e il recupero impiega più tempo. Se i retry sono automatici e aggressivi, puoi innescare una tempesta di retry: la dipendenza rallenta, le chiamate scadono, i chiamanti ritentano, il carico si moltiplica e la dipendenza collassa.
I framework rendono la rete come “chiamare semplicemente un endpoint”. Sotto carico, quell'astrazione spesso perde attraverso il lavoro invisibile fatto dallo stack dei middleware, dalla serializzazione e dalla gestione dei payload.
Ogni layer—API gateway, middleware auth, rate limiting, validazione request, hook di osservabilità, retry—aggiunge un po' di tempo. Un millisecondo in più raramente conta in sviluppo; a scala, una manciata di hop di middleware può trasformare una richiesta da 20 ms a 60–100 ms, specialmente quando si formano code.
La chiave è che la latenza non solo si somma—si amplifica. Piccoli ritardi aumentano la concorrenza (più richieste in volo), che aumenta la contendibilità (pool di thread, pool di connessioni), che a sua volta aumenta ancora i ritardi.
JSON è comodo, ma codificare/decodificare payload grandi può dominare la CPU. La perdita si manifesta come “rete” lenta che è in realtà tempo CPU applicativo, più un churn di memoria dovuto all'allocazione di buffer.
I payload grandi rallentano anche tutto attorno:
Gli header possono gonfiare silenziosamente le richieste (cookie, token auth, header di tracing). Quel gonfiore si moltiplica su ogni chiamata e ogni hop.
La compressione è un altro compromesso. Può risparmiare banda, ma costa CPU e può aggiungere latenza—soprattutto se comprimi payload piccoli o li comprimi più volte attraverso proxy.
Infine, streaming vs buffering è importante. Molti framework bufferano interi corpi di request/response per default (per abilitare retry, logging o il calcolo del content-length). Questo è comodo, ma ad alto volume aumenta l'uso di memoria e crea head-of-line blocking. Lo streaming aiuta a mantenere la memoria prevedibile e riduce il time-to-first-byte, ma richiede gestione degli errori più attenta.
Tratta dimensione del payload e profondità dei middleware come budget, non come dopo-pensieri:
Quando la scala espone overhead di rete, la soluzione spesso non è “ottimizza la rete” ma “smetti di fare lavoro nascosto su ogni richiesta”.
Il caching è spesso trattato come un interruttore semplice: aggiungi Redis (o una CDN), la latenza cala e passi oltre. Sotto carico reale, il caching è un'astrazione che può perdere pesantemente—perché cambia dove il lavoro avviene, quando avviene e come i failure si propagano.
Una cache aggiunge ulteriori hop di rete, serializzazione e complessità operativa. Introduce anche una seconda “fonte della verità” che può essere obsoleta, parzialmente popolata o non disponibile. Quando qualcosa va storto, il sistema non diventa solo più lento—può comportarsi diversamente (servendo dati vecchi, amplificando retry o sovraccaricando il DB).
Gli cache stampede avvengono quando molte richieste mancano la cache allo stesso tempo (spesso dopo una scadenza) e tutte ricostruiscono lo stesso valore. A scala questo può trasformare una piccola miss rate in uno spike al database.
Design delle chiavi povero è un altro problema silenzioso. Se le chiavi sono troppo ampie (es., user:feed senza parametri) servi dati sbagliati. Se le chiavi sono troppo specifiche (includendo timestamp, ID casuali o parametri di query non ordinati), ottieni hit rate quasi nullo e paghi l'overhead senza benefici.
Invalidazione è la trappola classica: aggiornare il DB è facile; assicurarsi che ogni vista cache correlata venga aggiornata non lo è. L'invalidazione parziale porta a bug confusi del tipo “a me funziona” e letture incoerenti.
Il traffico reale non è distribuito uniformemente. Un profilo di celebrità, un prodotto popolare o un endpoint di config condivisa può diventare una hot key, concentrando carico su una singola voce di cache e sul suo backing store. Anche se le prestazioni medie sembrano ok, la latenza tail e la pressione a livello di nodo possono esplodere.
I framework spesso fanno sembrare la memoria “gestita”, il che è rassicurante—fino a che il traffico cresce e la latenza inizia a scattare in modi che non corrispondono ai grafici CPU. Molti default sono tarati per comodità dello sviluppatore, non per processi long-running sotto carico sostenuto.
I framework di alto livello allocano spesso oggetti a vita corta per richiesta: wrapper request/response, oggetti di contesto middleware, alberi JSON, matcher regex e stringhe temporanee. Singolarmente sono piccoli. A scala, creano pressione di allocazione costante che spinge il runtime a eseguire più spesso la garbage collection (GC).
Le pause di GC possono diventare visibili come spike di latenza brevi ma frequenti. Man mano che gli heap crescono, le pause spesso si allungano—non necessariamente perché hai un leak, ma perché il runtime ha bisogno di più tempo per scandire e compattare la memoria.
Sotto carico, un servizio può promuovere oggetti in generazioni più vecchie (o regioni a vita più lunga) semplicemente perché sopravvivono a qualche ciclo di GC mentre restano nelle code, buffer, pool di connessioni o richieste in volo. Questo può gonfiare l'heap anche se l'applicazione è “corretta”.
La frammentazione è un altro costo nascosto: la memoria può essere libera ma non riutilizzabile per le dimensioni di cui hai bisogno, così il processo continua a chiedere più memoria al sistema operativo.
Un vero leak è una crescita illimitata nel tempo: la memoria sale, non ritorna e alla fine causa OOM o thrash di GC estremo. Un uso alto ma stabile è diverso: la memoria sale durante il warm-up e poi resta approssimativamente piatta.
Inizia con il profiling (snapshot dell'heap, flame graph di allocazione) per trovare i path di allocazione caldi e gli oggetti trattenuti.
Sii cauto con il pooling: può ridurre le allocazioni, ma un pool mal dimensionato può fissare memoria e peggiorare la frammentazione. Preferisci ridurre le allocazioni prima (streaming invece di buffering, evitare creazione inutile di oggetti, limitare cache per richiesta), poi aggiungi pooling solo dove le misure mostrano benefici chiari.
Gli strumenti di osservabilità spesso sembrano “gratis” perché il framework ti dà default comodi: log di richiesta, metriche auto-instrumentate e tracing con una riga. Sotto traffico reale, quei default possono diventare parte del carico che stai cercando di osservare.
Il logging per richiesta è l'esempio classico. Una singola riga per richiesta sembra innocua—fino a quando non arrivi a migliaia di richieste al secondo. Allora paghi per formattazione di stringhe, encoding JSON, scrittura su disco o rete e ingest downstream. La perdita si manifesta come maggiore latenza tail, spike CPU, pipeline di log che restano indietro e a volte timeout dovuti a flush sincronizzati dei log.
Le metriche possono sovraccaricare i sistemi in modo più silenzioso. Contatori e istogrammi sono economici quando hai poche serie temporali. Ma i framework spesso incoraggiano l'aggiunta di tag/label come user_id, email, path o order_id. Questo porta a esplosioni di cardinalità: invece di una metrica hai milioni di serie uniche. Il risultato è memoria gonfia nel client metriche e nel backend, query lente nelle dashboard, campioni persi e bollette inattese.
Il tracing distribuito aggiunge storage e overhead di calcolo che crescono con il traffico e con il numero di span per richiesta. Se tracci tutto di default, puoi pagare due volte: una nell'overhead dell'app (creazione di span, propagazione del contesto) e un'altra nel backend di tracing (ingest, indicizzazione, retention).
Il sampling è il modo in cui i team riprendono il controllo—ma è facile farlo male. Campionare troppo nasconde failure rari; campionare troppo poco rende il tracing proibitivo in termini di costo. Un approccio pratico è campionare di più per errori e richieste ad alta latenza, e meno per i percorsi sani e veloci.
Se vuoi una baseline su cosa raccogliere (e cosa evitare), vedi /blog/observability-basics.
Tratta l'osservabilità come traffico di produzione: imposta budget (volume dei log, numero di serie metriche, ingest dei trace), rivedi i tag per rischio di cardinalità e fai load test con l'instrumentation abilitata. L'obiettivo non è “meno osservabilità” ma osservabilità che funzioni ancora quando il sistema è sotto pressione.
I framework spesso fanno sembrare chiamare un altro servizio come chiamare una funzione locale: userService.getUser(id) ritorna velocemente, gli errori sono “solo eccezioni” e i retry sembrano innocui. A bassa scala questa illusione regge. A larga scala l'astrazione perde perché ogni chiamata “semplice” porta accoppiamenti nascosti: latenza, limiti di capacità, failure parziali e mismatch di versione.
Una chiamata remota accoppia i cicli di rilascio, i modelli di dati e l'uptime di due team. Se il Servizio A presume che il Servizio B sia sempre disponibile e veloce, il comportamento di A non è più definito dal suo codice ma dal giorno peggiore di B. È così che i sistemi diventano strettamente legati anche quando il codice sembra modulare.
Le transazioni distribuite sono una trappola comune: ciò che sembrava “salva utente, poi addebita carta” diventa un workflow multi-step su DB e servizi diversi. Two-phase commit raramente rimane semplice in produzione, quindi molti sistemi passano a consistenza eventuale (es., “il pagamento sarà confermato a breve”). Questo spostamento ti costringe a progettare per retry, duplicati e eventi fuori ordine.
L'idempotenza diventa essenziale: se una richiesta viene ritentata per un timeout, non deve creare un secondo addebito o una seconda spedizione. Gli helper di retry a livello di framework possono amplificare i problemi se gli endpoint non sono esplicitamente sicuri da ripetere.
Una dipendenza lenta può esaurire pool di thread, pool di connessioni o code, creando un effetto a catena: i timeout scatenano retry, i retry aumentano il carico e presto endpoint non correlati degradano. “Basta aggiungere più istanze” può aggravare la tempesta se tutti ritentano insieme.
Definisci contratti chiari (schemi, codici di errore e versioning), imposta timeout e budget per chiamata e implementa fallback (letture cached, risposte degradate) dove opportuno.
Infine, imposta SLO per dipendenza e fallo rispettare: se il Servizio B non può rispettare il suo SLO, il Servizio A dovrebbe fallire velocemente o degradare con grazia anziché trascinare silenziosamente tutto il sistema giù.
Quando un'astrazione perde a scala, spesso si manifesta con un sintomo vago (timeout, spike CPU, query lente) che tenta i team a riscrivere prematuramente. Un approccio migliore è trasformare l'ipotesi in evidenza.
1) Riproduci (fallire su richiesta).
Cattura lo scenario più piccolo che ancora genera il problema: l'endpoint, il job in background o il flusso utente. Riproducilo in locale o in staging con configurazione simile a produzione (feature flag, timeout, pool di connessioni).
2) Misura (scegli due o tre segnali).
Scegli poche metriche che ti dicano dove vanno tempo e risorse: p95/p99 latency, tasso di errore, CPU, memoria, tempo GC, tempo query DB, profondità delle code. Evita di aggiungere dozzine di grafici a metà incidente.
3) Isola (restringi il sospetto).
Usa gli strumenti per separare “overhead del framework” dal “tuo codice”:
4) Conferma (prova causa ed effetto).
Cambia una variabile alla volta: aggira l'ORM per una query, disabilita un middleware, riduci il volume di log, limita la concorrenza o modifica le dimensioni dei pool. Se il sintomo si muove in modo prevedibile, hai trovato la perdita.
Usa dimensioni dati realistiche (numero di righe, dimensione dei payload) e concorrenza realistica (burst, long-tail, client lenti). Molte perdite appaiono solo quando le cache sono fredde, le tabelle sono grandi o i retry amplificano il carico.
Le perdite di astrazione non sono un fallimento morale del framework—sono un segnale che i bisogni del sistema hanno superato il “percorso di default”. L'obiettivo non è abbandonare i framework, ma essere deliberati su quando tararli e quando aggirarli.
Rimani all'interno del framework quando il problema è configurazione o uso e non un mismatch fondamentale. Buoni candidati:
Se puoi risolverlo stringendo impostazioni e aggiungendo guardrail, mantieni le upgrade facili e riduci i casi speciali.
La maggior parte dei framework maturi fornisce modi per uscire dall'astrazione senza riscrivere tutto. Pattern comuni:
Questo mantiene il framework come strumento, non come una dipendenza che detta l'architettura.
La mitigazione è tanto operativa quanto codice:
Per pratiche di rollout correlate, vedi /blog/canary-releases.
Scendi di livello quando (1) il problema è su un path critico, (2) puoi misurare il guadagno e (3) la modifica non creerà un costo di manutenzione a lungo termine che il team non può permettersi. Se solo una persona capisce la soluzione alternativa, non è “fixata”—è fragile.
Quando cerchi leak, la velocità conta—ma conta anche rendere le modifiche reversibili. I team spesso usano Koder.ai per avviare piccole riproduzioni isolate dei problemi di produzione (una UI React minima, un servizio Go, uno schema PostgreSQL e un harness di load test) senza bruciare giorni su scaffolding. La sua modalità di pianificazione aiuta a documentare cosa stai cambiando e perché, mentre snapshot e rollback rendono più sicuro provare esperimenti di “scendere di livello” (come sostituire una query ORM con SQL grezzo) e poi tornare indietro se i dati non lo supportano.
Se lavori su questo attraverso ambienti, il deployment/hosting integrato di Koder.ai e il codice sorgente esportabile possono anche aiutare a mantenere gli artefatti di diagnosi (benchmark, app di riproduzione, dashboard interne) come software reale—versionato, condivisibile e non bloccato nella cartella locale di qualcuno.
Un'astrazione che perde è uno strato che prova a nascondere la complessità (ORM, helper per i retry, wrapper di caching, middleware), ma sotto carico i dettagli nascosti iniziano a cambiare i risultati.
Praticamente, è quando il tuo “modello mentale semplice” smette di prevedere il comportamento reale e sei costretto a capire cose come piani di query, pool di connessioni, profondità delle code, GC, timeout e retry.
I sistemi iniziali hanno capacità di riserva: tabelle piccole, bassa concorrenza, cache calde e poche interazioni di failure.
Con l'aumentare del volume, piccoli overhead diventano colli di bottiglia costanti e casi limite rari (timeout, failure parziali) diventano normali. È allora che i costi e i limiti nascosti dell'astrazione emergono in produzione.
Cerca pattern che non migliorano in modo prevedibile quando aggiungi risorse:
L'underprovisioning di solito migliora più o meno linearmente quando aggiungi capacità.
Un leak spesso mostra:
Usa la checklist nel post: se raddoppiare le risorse non risolve proporzionalmente, sospetta una perdita di astrazione.
Gli ORM possono nascondere il fatto che ogni operazione su un oggetto diventa SQL. Perdite comuni:
Mitiga con eager loading mirato, selezionando solo le colonne necessarie, paginazione, batching e validando l'SQL generato con EXPLAIN.
I pool di connessioni limitano la concorrenza per proteggere il DB, ma la proliferazione nascosta di query può esaurire il pool.
Quando il pool è pieno, le richieste si accodano nell'app, aumentando la latenza e trattenendo risorse più a lungo. Le transazioni lunghe aggravano la situazione mantenendo lock e riducendo la concorrenza effettiva.
Fix pratici:
Thread-per-request fallisce quando finiscono i thread durante I/O lento; tutto si accoda e i timeout esplodono.
Async/event-loop fallisce quando:
In entrambi i casi, l'astrazione "il framework gestisce la concorrenza" perde e servono limiti espliciti, timeout e backpressure.
Il backpressure è il meccanismo che dice “rallenta” quando un componente non può accettare altro lavoro in sicurezza.
Senza di esso, dipendenze lente aumentano le richieste in volo, l'uso della memoria e la lunghezza delle code—rendendo la dipendenza ancora più lenta (loop di feedback).
Strumenti comuni:
I retry automatici possono trasformare un rallentamento in un outage:
Mitiga con:
L'instrumentation compie lavoro reale ad alto traffico:
user_id, email, order_id) esplodono il numero di serie temporali e i costiControlli pratici: