Dal prototipo al SaaS: dove nasce la confusione
Un prototipo dimostra un'idea. Un SaaS deve sopravvivere all'uso reale: picchi di traffico, dati sporchi, retry e clienti che notano ogni intoppo. Qui le cose diventano complicate, perché la domanda cambia da “funziona?” a “continua a funzionare?”.
Con utenti reali, “funzionava ieri” fallisce per motivi noiosi. Un job in background parte più tardi del solito. Un cliente carica un file 10x più grande dei tuoi test. Un provider di pagamenti resta bloccato per 30 secondi. Niente di esotico, ma gli effetti a catena si sentono quando le parti del sistema dipendono l'una dall'altra.
La maggior parte della complessità appare in quattro luoghi: dati (la stessa informazione esiste in posti diversi e deriva), latenza (chiamate da 50 ms talvolta impiegano 5 secondi), guasti (timeout, aggiornamenti parziali, retry) e team (persone diverse rilasciano servizi diversi con schedule diversi).
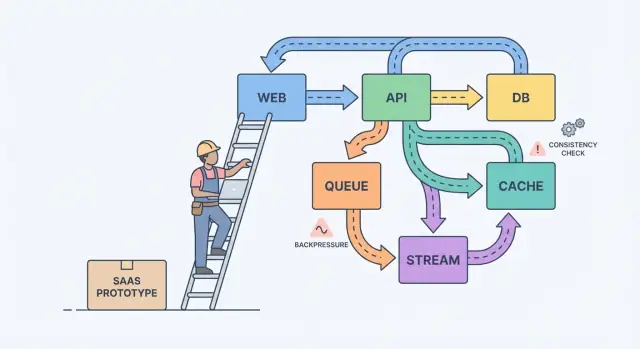
Un modello mentale semplice aiuta: componenti, messaggi e stato.
I componenti fanno lavoro (web app, API, worker, database). I messaggi spostano lavoro tra componenti (request, eventi, job). Lo stato è ciò che ricordi (ordini, impostazioni utente, stato del billing). Il dolore della scalabilità è di solito uno sbilanciamento: mandi messaggi più velocemente di quanto un componente possa gestire, o aggiorni lo stato in due posti senza una sorgente di verità chiara.
Un esempio classico è il billing. Un prototipo potrebbe creare una fattura, inviare un'email e aggiornare il piano dell'utente in una sola richiesta. Sotto carico, l'email rallenta, la richiesta va in timeout, il client riprova e ora hai due fatture e un solo cambiamento di piano. Il lavoro di affidabilità è soprattutto evitare che questi fallimenti quotidiani diventino bug visibili ai clienti.
Molti sistemi si complicano perché crescono senza accordo su cosa deve essere corretto, cosa deve solo essere veloce e cosa dovrebbe succedere quando qualcosa fallisce.
Inizia disegnando un confine attorno a ciò che prometti agli utenti. All'interno di quel confine, nomina le azioni che devono essere corrette ogni volta (movimento di denaro, controllo accessi, proprietà degli account). Poi nomina le aree dove “eventualmente corretto” va bene (conteggi di analytics, indici di ricerca, raccomandazioni). Questa divisione trasforma la teoria sfumata in priorità.
Poi scrivi la tua fonte di verità. È dove i fatti vengono registrati una sola volta, in modo durevole, con regole chiare. Tutto il resto è dato derivato costruito per velocità o comodità. Se una vista derivata è corrotta, devi poterla ricostruire dalla fonte di verità.
Quando i team si bloccano, queste domande di solito fanno emergere ciò che conta:
- Quali dati non devono mai andare persi, anche se rallentano le cose?\n- Cosa può essere ricreato da altri dati, anche se ci vuole ore?\n- Cosa può essere obsoleto, e per quanto tempo, dal punto di vista dell'utente?\n- Quale fallimento è peggiore per voi: duplicati, eventi mancanti o ritardi?
Se un utente aggiorna il piano di billing, una dashboard può essere lenta. Ma non puoi tollerare una discrepanza tra stato di pagamento e accesso reale.
Se un utente clicca un pulsante e deve vedere il risultato subito (salva profilo, carica dashboard, controlla permessi), una normale API request-response di solito basta. Mantienila diretta.
Non appena il lavoro può avvenire dopo, spostalo in asincrono. Pensa a invio email, addebito carte, generazione report, ridimensionamento upload o sincronizzazione con la ricerca. L'utente non dovrebbe aspettare queste operazioni, e la tua API non dovrebbe restare bloccata mentre vengono eseguite.
Una coda è una lista di cose da fare: ogni task dovrebbe essere gestito una volta da un worker. Uno stream (o log) è un registro: gli eventi vengono tenuti in ordine così più lettori possono riprodurli, aggiornarsi o costruire nuove funzionalità in seguito senza cambiare il produttore.
Un modo pratico per scegliere:\n
- Usa request-response quando l'utente necessita di una risposta immediata e il lavoro è piccolo.\n- Usa una coda per lavoro in background con retry dove un solo worker dovrebbe eseguire ogni job.\n- Usa uno stream/log quando hai bisogno di replay, di una traccia di audit o di consumatori multipli non accoppiati a un solo servizio.
Esempio: il tuo SaaS ha un pulsante “Create invoice”. L'API valida l'input e memorizza la fattura in Postgres. Poi una coda gestisce “invia email fattura” e “addebita carta”. Se poi aggiungi analytics, notifiche e controlli antifrode, uno stream di InvoiceCreated permette a ogni funzionalità di sottoscriversi senza trasformare il servizio core in un labirinto.
Progettazione degli eventi: cosa pubblichi e cosa conservi
Man mano che un prodotto cresce, gli eventi smettono di essere “carini da avere” e diventano una rete di sicurezza. Un buon design degli eventi si riduce a due domande: quali fatti registri e come possono le altre parti reagire senza indovinare?
Inizia con un piccolo set di eventi di business. Scegli i momenti che contano per gli utenti e per i soldi: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
I nomi sopravvivono al codice. Usa il passato per fatti completati, mantienili specifici ed evita wording legato alla UI. PaymentSucceeded resta significativo anche se poi aggiungi coupon, retry o più provider di pagamento.
Tratta gli eventi come contratti. Evita un catch-all tipo “UserUpdated” con un insieme di campi che cambiano ogni sprint. Preferisci il fatto più piccolo su cui puoi contare per anni.
Per evolvere in sicurezza, favorisci cambiamenti additivi (nuovi campi opzionali). Se serve un cambiamento breaking, pubblica un nuovo nome evento (o una versione esplicita) e mantieni entrambi finché i vecchi consumer non sono migrati.
Cosa dovresti memorizzare? Se tieni solo le righe attuali in un database, perdi la storia di come ci sei arrivato.
Gli eventi raw sono ottimi per audit, replay e debugging. Gli snapshot sono ottimi per letture veloci e recuperi rapidi. Molti prodotti SaaS usano entrambi: conservano eventi raw per workflow chiave (billing, permessi) e mantengono snapshot per le schermate rivolte all'utente.
Compromessi di consistenza che gli utenti percepiscono
La consistenza si manifesta in momenti come: “Ho cambiato piano, perché dice ancora Free?” o “Ho inviato un invito, perché il mio collega non riesce ancora ad accedere?”.
La consistenza forte significa che una volta che ottieni un messaggio di successo, ogni schermata dovrebbe riflettere immediatamente il nuovo stato. La consistenza eventuale significa che il cambiamento si propaga col tempo, e per una finestra breve diverse parti dell'app possono non essere d'accordo. Nessuna è “migliore” in assoluto. Si sceglie in base al danno che una discrepanza può causare.
La consistenza forte si adatta solitamente a denaro, accesso e sicurezza: addebitare una carta, cambiare una password, revocare API key, far rispettare limiti di posti. La consistenza eventuale spesso si adatta a feed di attività, ricerca, analytics, “ultimo accesso” e notifiche.
Se accetti staleness, progetta per esso invece di nasconderlo. Mantieni l'interfaccia onesta: mostra uno stato “Aggiornamento in corso…” dopo una scrittura finché non arriva la conferma, offri un refresh manuale per le liste e usa UI ottimistiche solo quando puoi rollbackare pulitamente.
I retry sono il punto in cui la consistenza diventa insidiosa. Le reti cadono, i client cliccano due volte e i worker si riavviano. Per operazioni importanti, rendi le richieste idempotenti così ripetere la stessa azione non crea due fatture, due inviti o due rimborsi. Un approccio comune è una chiave di idempotenza per azione più una regola server-side che restituisce il risultato originale per le ripetizioni.
Backpressure: evitare che il sistema si sciolga
Il backpressure è ciò che serve quando le richieste o gli eventi arrivano più velocemente di quanto il sistema possa gestire. Senza di esso, il lavoro si accumula in memoria, le code crescono e la dipendenza più lenta (spesso il database) decide quando tutto fallisce.
In termini semplici: il produttore continua a parlare mentre il consumatore si sta annegando. Se continui ad accettare lavoro, non solo rallenti. Scateni una reazione a catena di timeout e retry che moltiplica il carico.
I segnali di avvertimento sono spesso visibili prima di un outage: backlog che cresce, latenza che salta dopo picchi o deploy, retry in aumento, endpoint non correlati che falliscono quando una dipendenza rallenta e connessioni al database al limite.
Quando arrivi a quel punto, scegli una regola chiara per cosa succede quando sei pieno. L'obiettivo non è processare tutto a qualsiasi costo. È restare vivi e recuperare velocemente. I team partono tipicamente con uno o due controlli: rate limit (per utente o API key), code con limiti e policy chiare di drop/ritardo, circuit breaker per dipendenze in errore e priorità in modo che le richieste interattive vincano sui job in background.
Proteggi il database prima di tutto. Mantieni i pool di connessioni piccoli e prevedibili, imposta timeout sulle query e metti limiti netti su endpoint costosi come report ad-hoc.
Un percorso passo-passo per l'affidabilità (senza riscrivere tutto)
L'affidabilità raramente richiede una grande riscrittura. Spesso deriva da poche decisioni che rendono i guasti visibili, contenuti e recuperabili.
Inizia con i flussi che guadagnano o perdono fiducia, poi aggiungi sponde di sicurezza prima di aggiungere funzionalità:
-
Mappa i percorsi critici. Scrivi i passaggi esatti per signup, login, reset password e qualsiasi flusso di pagamento. Per ogni passo, elenca le dipendenze (database, provider email, worker). Questo forza chiarezza su cosa deve essere immediato e cosa può essere risolto “eventualmente”.
-
Aggiungi osservabilità di base. Dai a ogni richiesta un ID che appaia nei log. Traccia un piccolo set di metriche che rispecchiano il dolore dell'utente: error rate, latenza, profondità delle code e query lente. Aggiungi tracing solo dove le richieste attraversano servizi.
-
Isola lavoro lento o instabile. Qualsiasi cosa che parla a un servizio esterno o impiega regolarmente più di un secondo dovrebbe diventare job e worker.
-
Progetta per retry e fallimenti parziali. Assumi che i timeout succedano. Rendi le operazioni idempotenti, usa backoff, imposta limiti di tempo e mantieni brevi le azioni rivolte all'utente.
-
Esercita il recupero. I backup contano solo se sai ripristinarli. Usa release piccole e tieni un percorso di rollback veloce.
Se il tuo tooling supporta snapshot e rollback (Koder.ai lo fa), integralo nelle abitudini di deployment invece di tenerlo come trucco d'emergenza.
Immagina un piccolo SaaS che aiuta i team a onboardare nuovi clienti. Il flusso è semplice: un utente si registra, sceglie un piano, paga e riceve una email di benvenuto più alcuni passaggi di onboarding.
Nel prototipo tutto succede in una richiesta: crea account, addebita carta, imposta “paid” sull'utente, invia email. Funziona finché il traffico cresce, i retry capitano e i servizi esterni rallentano.
Per renderlo affidabile, il team trasforma azioni chiave in eventi e mantiene una cronologia append-only. Introducono alcuni eventi: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Questo dà una traccia di audit, facilita l'analytics e permette al lavoro lento di avvenire in background senza bloccare la registrazione.
Alcune scelte fanno la maggior parte del lavoro:
- Tratta i pagamenti come fonte di verità per l'accesso, non un singolo flag “paid”.\n- Concedi entitlements da
PaymentSucceeded con una chiave di idempotenza chiara così i retry non raddoppiano le concessioni.\n- Invia le email da una coda/worker, non dalla richiesta di checkout.\n- Registra gli eventi anche se un handler fallisce, così puoi replayare e recuperare.\n- Aggiungi timeout e circuit breaker attorno ai provider esterni.
Se il pagamento riesce ma l'accesso non è ancora concesso, gli utenti si sentono truffati. La soluzione non è “coerenza perfetta ovunque”. È decidere cosa deve essere consistente ora e riflettere quella decisione nell'interfaccia con uno stato come “Attivazione del piano” finché EntitlementGranted non arriva.
In una giornata negativa, il backpressure fa la differenza. Se l'API email si blocca durante una campagna marketing, il design vecchio manda in timeout i checkout e gli utenti riprovano, creando addebiti duplicati e duplicate email. Nel design migliore, il checkout ha successo, le richieste email si mettono in coda e un job di replay svuota il backlog quando il provider si riprende.
Trappole comuni quando i sistemi crescono
La maggior parte degli outage non sono causati da un singolo bug eroico. Nascono da piccole decisioni che avevano senso in un prototipo e poi sono diventate abitudini.
Una trappola comune è split in microservizi troppo presto. Finisci con servizi che si chiamano molto tra loro, ownership poco chiara e modifiche che richiedono cinque deploy invece di uno.
Un'altra trappola è usare “consistenza eventuale” come scusa. Gli utenti non si preoccupano del termine: vogliono che, dopo aver cliccato Salva, la pagina non mostri dati vecchi o che uno stato di fattura non salti avanti e indietro. Se accetti delay, serve comunque feedback all'utente, timeout e una definizione di “abbastanza buono” per ogni schermata.
Altri colpevoli ricorrenti: pubblicare eventi senza un piano di reprocessing, retry senza limiti che moltiplicano il carico durante incidenti e lasciare ogni servizio a parlare direttamente allo stesso schema del database così una modifica rompe molte squadre.
Controlli rapidi prima di dichiarare “pronto per la produzione”
“Pronto per la produzione” è un insieme di decisioni che puoi indicare alle 2 di notte. La chiarezza batte l'ingegnosità.
Inizia nominando le tue fonti di verità. Per ogni tipo di dato chiave (clienti, sottoscrizioni, fatture, permessi), decidi dove vive il record finale. Se la tua app legge la “verità” da due posti, finirai per mostrare risposte diverse a utenti diversi.
Poi guarda i retry. Assumi che ogni azione importante verrà eseguita due volte a un certo punto. Se la stessa richiesta arriva due volte, puoi evitare doppi addebiti, doppi invii o doppie creazioni?
Una piccola checklist che cattura la maggior parte dei fallimenti dolorosi:\n
- Per ogni tipo di dato, puoi indicare una fonte di verità e dire cosa è derivato.\n- Ogni scrittura importante è sicura da ripetere (chiave di idempotenza o vincolo unico).\n- Il lavoro asincrono non può crescere senza limiti (monitori lag, età del messaggio più vecchio e alert prima che gli utenti notino).\n- Hai un piano per il cambiamento (migrazioni reversibili, versioning degli eventi).\n- Puoi rollbackare e ripristinare con fiducia perché hai provato.
Passi successivi: prendi una decisione alla volta
Scalare diventa più facile quando consideri il design del sistema come una breve lista di scelte, non un mucchio di teoria.
Scrivi 3–5 decisioni che prevedi di affrontare nel prossimo mese, in linguaggio semplice: “Spostiamo l'invio email in un job background?” “Accettiamo analytics leggermente obsolete?” “Quali azioni devono essere immediatamente consistenti?” Usa quella lista per allineare prodotto e engineering.
Poi scegli un workflow attualmente sincrono e convertilo solo in asincrono. Ricevute, notifiche, report e elaborazione file sono mosse comuni. Misura due cose prima e dopo: latenza percepita dall'utente (la pagina è più veloce?) e comportamento nei fallimenti (i retry hanno creato duplicati o confusione?).
Se vuoi prototipare questi cambiamenti rapidamente, Koder.ai (koder.ai) può essere utile per iterare su un SaaS React + Go + PostgreSQL mantenendo snapshot e rollback a portata di mano. La regola rimane semplice: rilascia un miglioramento, impara dal traffico reale, poi decidi il prossimo.