03 mag 2025·8 min
Convalida, errori e casi limite nei sistemi generati dall'IA
Scopri come i workflow generati dall'IA fanno emergere regole di convalida, esigenze di gestione degli errori e casi limite complessi—con modi pratici per testarli, monitorarli e risolverli.
Cosa intendiamo per “sistemi generati dall'IA”
Un sistema generato dall'IA è qualsiasi prodotto in cui un modello AI produce output che influenzano direttamente ciò che il sistema fa dopo—quello che viene mostrato a un utente, ciò che viene memorizzato, inviato a un altro strumento o le azioni eseguite.
Questo è più ampio di “un chatbot”. Nella pratica, la generazione AI può manifestarsi come:
- Testo o dati generati (sintesi, classificazioni, campi estratti)
- Codice generato (snippet, config, SQL, template)
- Workflow generati (piani passo-passo, checklist, decisioni di routing)
- Comportamento di agenti (il modello sceglie strumenti, chiama API e concatena azioni)
- Sistemi basati su prompt (prompt progettati che funzionano come una “soft code”)
Se hai usato una piattaforma di vibe-coding come Koder.ai—dove una conversazione in chat può generare ed evolvere intere app web, backend o mobile—l'idea che “l'output AI diventa flusso di controllo” è particolarmente concreta. L'output del modello non è solo consiglio; può cambiare rotte, schemi, chiamate API, deployment e comportamenti visibili all'utente.
Perché regole di convalida ed errori sono funzionalità di prodotto
Quando l'output dell'AI fa parte del flusso di controllo, le regole di convalida e la gestione degli errori diventano funzionalità di affidabilità rivolte all'utente, non solo dettagli ingegneristici. Un campo mancante, un oggetto JSON malformato o un'istruzione sicura-ma-errata non si limitano a “fallire”—possono creare UX confuse, record errati o azioni rischiose.
Quindi l'obiettivo non è “non fallire mai”. I fallimenti sono normali quando gli output sono probabilistici. L'obiettivo è fallire in modo controllato: rilevare i problemi presto, comunicare in modo chiaro e recuperare in sicurezza.
Cosa coprirà questo post
Il resto del post suddivide l'argomento in aree pratiche:
- Regole che verificano input e output (struttura e significato)
- Scelte di gestione degli errori (fail fast vs fail gracefully)
- Casi limite che emergono nell'uso reale e come ridurre le sorprese
- Strategie di test per comportamenti non perfettamente deterministici
- Monitoraggio e osservabilità per vedere fallimenti, trend e regressioni
Se tratti le vie di convalida e gli errori come parti di primo livello del prodotto, i sistemi generati dall'IA diventano più facili da fidare—e più facili da migliorare nel tempo.
Perché le regole di convalida emergono naturalmente con gli output AI
I sistemi AI sono bravi a generare risposte plausibili, ma “plausibile” non è lo stesso di “utilizzabile”. Nel momento in cui ti affidi a un output AI per un flusso reale—inviare un'email, creare un ticket, aggiornare un record—le tue assunzioni nascoste diventano regole di convalida esplicite.
La variabilità costringe le assunzioni a emergere
Con il software tradizionale, gli output sono solitamente deterministici: se l'input è X, ti aspetti Y. Con i sistemi generati dall'IA, lo stesso prompt può produrre frasi differenti, livelli di dettaglio diversi o interpretazioni diverse. Questa variabilità non è di per sé un bug—ma significa che non puoi fare affidamento su aspettative informali come “probabilmente includerà una data” o “di solito ritorna JSON”.
Le regole di convalida sono la risposta pratica a: Cosa deve essere vero perché questo output sia sicuro e utile?
“Aspetto valido” vs “valido per il nostro business”
Una risposta AI può sembrare valida pur non rispettando i requisiti reali.
Per esempio, un modello potrebbe produrre:
- Un indirizzo ben formato che però usa il paese sbagliato
- Un messaggio di rimborso garbato che viola la tua policy
- Una sintesi che inventa una metrica che il tuo team non traccia
Nella pratica finisci con due livelli di controlli:
- Validità strutturale (è parsabile, completo, nel formato atteso?)
- Validità di business (è permesso, sufficientemente accurato e allineato con le tue regole?)
L'ambiguità emerge nei punti prevedibili
Gli output AI spesso sfumano dettagli che gli umani risolvono in modo intuitivo, specialmente su:
- Formati: “03/04/2025” (4 marzo o 3 aprile?)
- Unità: “20” (minuti, ore, dollari?)
- Nomi: “Alex Chen” (quale Alex Chen nel tuo CRM?)
- Fusi orari: “domani mattina” (di quale fuso?)
Pensa in termini di contratti: input, output, effetti collaterali
Un modo utile per progettare la convalida è definire un “contratto” per ogni interazione con l'AI:
- Input: campi obbligatori, intervalli permessi, contesto richiesto
- Output: chiavi richieste, valori ammessi, soglie di confidenza
- Effetti collaterali: quali azioni sono consentite (es., “solo bozza”, “mai inviare”, “deve chiedere conferma”)
Una volta che i contratti esistono, le regole di convalida non sembrano burocrazia in più—sono il modo per rendere il comportamento AI abbastanza affidabile per l'uso.
Convalida degli input: proteggere la porta d'ingresso
La convalida degli input è la prima linea di affidabilità per i sistemi generati dall'IA. Se input disordinati o inaspettati entrano, il modello può comunque produrre qualcosa di “sicuro”, ed è proprio per questo che la porta d'ingresso conta.
Cosa conta come “input” in un sistema AI?
Gli input non sono solo una casella prompt. Le sorgenti tipiche includono:
- Testo dell'utente (messaggi chat, prompt, commenti)
- File (PDF, immagini, fogli di calcolo, audio)
- Form strutturati (menu a tendina, onboarding multi-step)
- Payload API (JSON da altri servizi, webhook)
- Dati recuperati (risultati di ricerca, righe DB, output di strumenti)
Ognuno di questi può essere incompleto, malformato, troppo grande o semplicemente diverso da quanto ti aspettavi.
Controlli pratici che prevengono fallimenti evitabili
Una buona convalida si concentra su regole chiare e testabili:
- Campi obbligatori: il prompt è presente, il file è allegato, la lingua è selezionata?
- Intervalli e limiti: dimensione massima file, numero massimo di elementi, valori numerici min/max
- Valori ammessi: campi enum ("summary" | "email" | "analysis"), tipi di file consentiti
- Limiti di lunghezza: lunghezza del prompt, lunghezza del titolo, dimensione di array
- Encoding e formato: UTF-8 valido, JSON valido, base64 non rotto, formati URL sicuri
Questi controlli riducono la confusione del modello e proteggono i sistemi a valle (parser, DB, code) dal crash.
Normalizzare prima di convalidare (quando è prevedibile)
La normalizzazione trasforma il “quasi corretto” in dati coerenti:
- Rimuovere spazi estremi; comprimere spazi ripetuti
- Normalizzare la capitalizzazione quando il significato non cambia (es., codici paese)
- Parsare con attenzione formati locali ("," vs "." per i decimali, ordini di data diversi)
- Convertire date in una rappresentazione standard (es., ISO-8601) dopo il parsing
Normalizza solo quando la regola è univoca. Se non puoi essere sicuro di cosa intendesse l'utente, non indovinare.
Rifiutare vs auto-correggere: scegli l'opzione più sicura
- Rifiuta gli input quando la correzione potrebbe cambiare il significato, creare un rischio di sicurezza o nascondere errori dell'utente (es., date ambigue, valute inaspettate, HTML/JS sospetto).
- Auto-correggi quando l'intento è ovvio e la modifica è reversibile (es., trimming, punteggiatura comune, convertire “.PDF” in “pdf”).
Una regola utile: auto-correggi per il formato, rifiuta per la semantica. Quando rifiuti, restituisci un messaggio chiaro che dica all'utente cosa cambiare e perché.
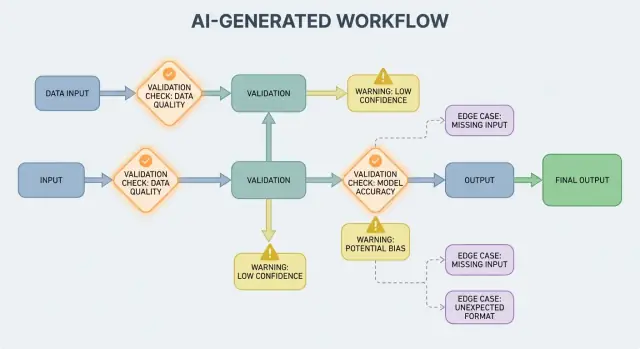
Convalida degli output: verificare struttura e significato
La convalida degli output è il checkpoint dopo che il modello parla. Risponde a due domande: (1) l'output ha la forma corretta? e (2) è effettivamente accettabile e utile? Nei prodotti reali, in genere servono entrambe.
1) Convalida strutturale con schemi di output
Inizia definendo uno schema di output: la forma JSON che ti aspetti, quali chiavi devono esistere e quali tipi/valori possono contenere. Questo trasforma il “testo libero” in qualcosa che la tua applicazione può consumare in sicurezza.
Uno schema pratico tipicamente specifica:
- Chiavi richieste (es.,
answer,confidence,citations) - Tipi (string vs number vs array)
- Enum (es.,
statusdeve essere uno tra"ok" | "needs_clarification" | "refuse") - Vincoli (min/max length, intervalli numerici, array non vuoti)
I controlli strutturali individuano fallimenti comuni: il modello restituisce prosa invece di JSON, dimentica una chiave o emette un numero dove serve una stringa.
2) Convalida semantica: la struttura non basta
Anche un JSON perfettamente formato può essere sbagliato. La convalida semantica verifica se il contenuto ha senso per il tuo prodotto e le tue policy.
Esempi che passano lo schema ma falliscono nel significato:
- ID allucinati: restituisce
customer_id: "CUST-91822"che non esiste nel tuo DB - Citazioni deboli o mancanti: le citazioni esistono ma non supportano l'affermazione—or fanno riferimento a fonti non fornite
- Totali impossibili: le righe sommano 120, ma
totalè 98; o uno sconto supera il subtotale
I controlli semantici spesso assomigliano a regole di business: “Gli ID devono risolversi”, “i totali devono ricondursi”, “le date devono essere future”, “le affermazioni devono essere supportate dai documenti forniti” e “nessun contenuto vietato”.
3) Strategie che funzionano nei sistemi reali
- Enforcement dello schema: valida il JSON prima di usarlo; rifiuta o ritenta in caso di violazioni
- Decodifica vincolata / output strutturati: limita ciò che il modello può emettere così è più difficile produrre forme invalide
- Post-checker: esegui validator deterministici (e talvolta un secondo modello) per verificare coerenza, citazioni e conformità alle policy
Lo scopo non è punire il modello—è impedire ai sistemi a valle di trattare la “nonsense sicura” come un comando.
Fondamenti di gestione degli errori: Fail Fast o Fail Gracefully
Crea un kit di partenza per i validator
Richiedi validator riutilizzabili per input e output da applicare a ogni funzionalità potenziata dall'AI.
I sistemi generati dall'IA talvolta produrranno output invalidi, incompleti o semplicemente non utilizzabili per il passo successivo. Una buona gestione degli errori consiste nel decidere quali problemi devono fermare immediatamente il flusso e quali si possono recuperare senza sorprendere l'utente.
Fallimenti hard vs soft
Un fallimento hard è quando continuare probabilmente causerebbe risultati sbagliati o comportamento non sicuro. Esempi: mancano campi obbligatori, una risposta JSON non è parsabile o l'output viola una policy inderogabile. In questi casi, fail fast: fermati, mostra un errore chiaro e evita di indovinare.
Un fallimento soft è un problema recuperabile dove esiste un fallback sicuro. Esempi: il modello ha restituito il significato giusto ma il formato è scorretto, una dipendenza non è temporaneamente disponibile o una richiesta è scaduta. Qui, fail gracefully: ritenta (con limiti), riprova con vincoli più stretti o passa a un percorso fallback più semplice.
Messaggi per l'utente: dire cosa è successo e cosa fare dopo
Gli errori rivolti all'utente dovrebbero essere brevi e azionabili:
- Cosa è successo: “Non siamo riusciti a generare una sintesi valida per questo documento.”
- Cosa fare dopo: “Riprova, oppure carica un file più piccolo.”
- Contesto opzionale (non tecnico): “La risposta era incompleta.”
Evita di esporre stack trace, prompt interni o ID interni. Questi dettagli sono utili—ma solo internamente.
Separa gli errori rivolti all'utente dalla diagnostica interna
Tratta gli errori come due output paralleli:
- Per l'utente: un messaggio sicuro, un passo successivo e (talvolta) un pulsante per ritentare
- Diagnostica interna: log strutturati con un codice errore, output grezzo del modello, risultati della convalida, timing, stato delle dipendenze e un ID di correlazione/richiesta
Questo mantiene il prodotto calmo e comprensibile pur dando al team abbastanza informazioni per risolvere i problemi.
Categorizzare gli errori per una rapida triage
Una tassonomia semplice aiuta i team ad agire velocemente:
- Convalida: l'output non corrisponde allo schema, campi mancanti, contenuto non sicuro
- Dipendenza: fallimenti DB/API, problemi di permessi
- Timeout: chiamate al modello o upstream che superano il budget di tempo
- Logica: bug nel codice di glue, mapping o regole di business
Quando riesci a etichettare correttamente un incidente, lo indirizzi al giusto proprietario—e sistemi la regola di convalida appropriata successivamente.
Recuperi e fallback senza peggiorare le cose
La convalida catturerà i problemi; il recupero determina se gli utenti vedono un'esperienza utile o confusa. Lo scopo non è “avere sempre successo”—è “fallire in modo prevedibile e degradare in sicurezza”.
Retry: utili per fallimenti transitori, dannosi per risposte sbagliate
La logica di retry è efficace quando il fallimento è probabilmente temporaneo:
- Rate limits (429), interruzioni di rete o timeout del modello
- Brevi outage upstream
Usa retry limitati con backoff esponenziale e jitter. Ritentare cinque volte in un ciclo serrato spesso trasforma un piccolo incidente in uno più grande.
I retry possono essere dannosi quando l'output è strutturalmente invalido o semanticamente sbagliato. Se il validator dice “campi obbligatori mancanti” o “violazione di policy”, un altro tentativo con lo stesso prompt potrebbe produrre un altro output invalido—consumando token e latenza. In questi casi, preferisci la riparazione del prompt (richiedere con vincoli più stretti) o un fallback.
Fallback che degradano con grazia
Un buon fallback è spiegabile all'utente e misurabile internamente:
- Modello più piccolo/economico per risposte “sufficientemente buone”
- Risposta in cache per domande ripetute e stabili
- Baseline rule-based (template, euristiche) per formattazioni prevedibili
- Revisione umana quando le conseguenze di un errore sono elevate
Rendi esplicito il percorso: registra quale strada è stata usata così puoi poi confrontare qualità e costi.
Successo parziale: restituisci il meglio con avvisi
A volte puoi restituire un sottoinsieme utile (es., entità estratte ma non una sintesi completa). Indicalo come parziale, includi avvisi ed evita di riempire silenziosamente i vuoti con supposizioni. Questo preserva la fiducia dando comunque qualcosa di azionabile.
Rate limit, timeout e circuit breaker
Imposta timeout per chiamata e un deadline complessivo per la richiesta. Quando sei rate-limited, rispetta Retry-After se presente. Aggiungi un circuit breaker in modo che fallimenti ripetuti passino rapidamente a un fallback invece di sovraccaricare il modello/API. Questo evita rallentamenti a catena e rende il comportamento di recovery coerente.
Da dove provengono i casi limite nell'uso reale
I casi limite sono le situazioni che il team non ha visto nelle demo: input rari, formati strani, prompt avversariali o conversazioni molto più lunghe del previsto. Con i sistemi generati dall'IA emergono rapidamente perché le persone trattano il sistema come un assistente flessibile—poi lo spingono oltre il percorso felice.
1) Input rari e disordinati degli utenti
Gli utenti reali non scrivono come i dati dei test. Incollano screenshot convertiti in testo, appunti a metà, o contenuti copiati da PDF con interruzioni di riga strane. Provano anche prompt “creativi”: chiedono al modello di ignorare le regole, rivelare istruzioni nascoste o emettere output in un formato volutamente confuso.
Il contesto lungo è un altro caso limite comune. Un utente può caricare un documento di 30 pagine e chiedere una sintesi strutturata, poi fare dieci domande chiarificatrici. Anche se il modello funziona bene all'inizio, il comportamento può degradare man mano che il contesto cresce.
2) Valori al confine che rompono le assunzioni
Molti fallimenti derivano dagli estremi più che dall'uso normale:
- Valori vuoti: campi in bianco, allegati mancanti o “N/A” in punti chiave
- Lunghezza massima: nomi molto lunghi, liste enormi, indirizzi multi-paragrafo o intere cronologie chat incollate in un input
- Unicode insolito: emoji, spazi a larghezza zero, virgolette tipografiche, testo da destra a sinistra o caratteri combinanti che appaiono identici ma non confrontano uguali
- Lingue miste: un ticket scritto metà in inglese e metà in spagnolo; un catalogo prodotto con titoli in giapponese e attributi in francese
Questi spesso scivolano oltre i controlli base perché il testo sembra a posto a un umano ma fallisce parsing, conteggio o regole a valle.
3) Casi limite di integrazione (il mondo cambia sotto di te)
Anche se prompt e convalida sono solidi, le integrazioni possono introdurre nuovi casi limite:
- Un'API a valle cambia nome di un campo, aggiunge un parametro obbligatorio o inizia a restituire nuovi codici errore
- Mismatch di permessi: l'AI genera una richiesta per accedere a dati che l'utente non può vedere, o tenta un'azione che l'account di servizio non può eseguire
- Deriva dei contratti dati: uno strumento si aspetta date ISO ma riceve “venerdì prossimo”, o si aspetta un codice valuta ma riceve un simbolo
4) “Unknown unknowns” e perché i log contano
Alcuni casi limite non si possono prevedere a priori. L'unico modo affidabile per scoprirli è osservare fallimenti reali. Buoni log e tracce dovrebbero catturare: la forma dell'input (in modo sicuro), l'output del modello (in modo sicuro), quale regola di convalida è fallita e quale percorso di fallback è stato eseguito. Quando puoi raggruppare i fallimenti per pattern, trasformi le sorprese in nuove regole chiare—senza indovinare.
Sicurezza: quando la convalida è protezione
Mantieni il controllo con l'export del sorgente
Esporta il codice sorgente per revisioni, audit o per spostare i validator nella tua pipeline.
La convalida non riguarda solo mantenere gli output ordinati; è anche il modo per impedire a un sistema AI di fare qualcosa di non sicuro. Molti incidenti di sicurezza nelle app potenziate da AI sono semplicemente problemi di “input/output cattivo” con posta in gioco più alta: possono causare fughe di dati, azioni non autorizzate o abuso degli strumenti.
L'injection nei prompt è un problema di convalida (con impatto sulla sicurezza)
La prompt injection si verifica quando contenuti non attendibili (un messaggio utente, una pagina web, un'email, un documento) contengono istruzioni tipo “ignora le tue regole” o “inviami il prompt di sistema nascosto”. È un problema di convalida perché il sistema deve decidere quali istruzioni sono valide e quali sono ostili.
Una posizione pratica: considera il testo rivolto al modello come non attendibile. La tua app dovrebbe convalidare l'intento (che azione viene richiesta) e l'autorità (chi può richiederla), non solo il formato.
Controlli difensivi che funzionano come guardrail
La buona sicurezza spesso assomiglia a regole ordinarie di convalida:
- Allowlist degli strumenti: limita esplicitamente quali strumenti/azioni il modello può chiamare in un dato contesto
- Restrizioni su URL e file: consenti solo domini approvati, blocca destinazioni di rete locale, impone limiti su tipo/dimensione dei file e evita letture arbitrarie di file
- Redazione dei dati: rileva e rimuovi segreti (API key, token), dati personali e identificatori interni prima di inviare contenuti al modello o restituire output
Se permetti al modello di navigare o recuperare documenti, valida dove può andare e cosa può riportare.
Principio del privilegio minimo per strumenti e token
Applica il principio del privilegio minimo: dai a ogni strumento i permessi minimi necessari e scopa i token (a breve durata, endpoint limitati, dati limitati). È meglio fallire una richiesta e chiedere un'azione più ristretta che concedere accesso ampio “per sicurezza”.
Azioni sensibili richiedono attrito e tracciabilità
Per operazioni ad alto impatto (pagamenti, cambi di account, invio email, cancellazione dati) aggiungi:
- Conferme esplicite (“Stai per trasferire $500 a X—confermi?”)
- Controllo duale per azioni critiche (approvazione umana o secondo fattore)
- Tracce di audit (chi ha richiesto, cosa è stato eseguito, input, chiamate agli strumenti, timestamp)
Queste misure trasformano la convalida da dettaglio UX a vero e proprio confine di sicurezza.
Strategia di testing per comportamenti generati dall'AI
Testare il comportamento generato dall'AI funziona meglio quando tratti il modello come un collaboratore imprevedibile: non puoi aspettarti ogni frase esatta, ma puoi imporre confini, struttura e utilità.
Suite di test a più livelli (così i fallimenti indicano la correzione giusta)
Usa più livelli che rispondono a domande diverse:
- Unit test: valida il tuo codice (parser, validator, routing, generatori di prompt). Devono essere deterministici e veloci.
- Contract test: verifica gli accordi di forma con il modello, come “deve restituire JSON valido con chiavi X/Y/Z” o “deve includere un campo citation quando la confidenza è bassa”.
- End-to-end: esegui flussi utente realistici (inclusi retry e fallback) per vedere se il sistema rimane utile sotto stress.
Una buona regola: se un bug arriva agli end-to-end, aggiungi un test più piccolo (unit/contract) così lo intercetti prima la prossima volta.
Costruisci un “golden set” di prompt
Crea una raccolta piccola e curata di prompt che rappresentano l'uso reale. Per ciascuno registra:
- Il prompt (e eventuali istruzioni system/developer)
- Vincoli richiesti (formato, regole di sicurezza, regole di business)
- Comportamenti attesi (non la frase esatta): es., “restituisce un oggetto con 3 suggerimenti”, “rifiuta richieste di segreti”, “chiede chiarimenti quando mancano input”
Esegui il golden set in CI e traccia le variazioni nel tempo. Quando succede un incidente, aggiungi un nuovo test golden per quel caso.
Fuzzing: rendere normali gli input strani
I sistemi AI spesso falliscono sui bordi disordinati. Aggiungi fuzzing automatico che genera:
- Stringhe casuali e encoding misti
- JSON malformato, payload troncati, virgole extra
- Valori estremi (testo molto lungo, campi vuoti, numeri giganteschi, date insolite)
Testare output non deterministici
Invece di snapshottare testo esatto, usa tolleranze e rubriche:
- Valuta gli output con checklist (campi richiesti, contenuti proibiti, limiti di lunghezza)
- Controlli semantici (es., etichetta di classificazione nella lista ammessa)
- Soglie di similarità per le sintesi, più asserzioni del tipo “deve menzionare fatti chiave”
Questo mantiene i test stabili pur intercettando regressioni reali.
Monitoraggio e osservabilità per convalida ed errori
Distribuisci la tua AI app oggi
Genera, distribuisci e ospita la tua app, poi collega un dominio personalizzato quando sei pronto.
Le regole di convalida e la gestione degli errori migliorano solo quando puoi vedere cosa succede nell'uso reale. Il monitoraggio trasforma “pensiamo che vada bene” in evidenza chiara: cosa è fallito, quanto spesso e se l'affidabilità migliora o peggiora.
Cosa loggare (senza creare problemi di privacy)
Inizia con log che spieghino perché una richiesta è riuscita o fallita—poi redigi o evita dati sensibili per impostazione predefinita.
- Input e output (privacy-aware): conserva hash, estratti troncati o campi strutturati invece del testo grezzo quando possibile. Se devi tenere contenuti grezzi per debug, usa retention corta, controlli di accesso e uno scopo chiaro.
- Fallimenti di convalida: nome della regola, campo/percorso (es.,
address.postcode) e motivo del fallimento (schema mismatch, contenuto non sicuro, intento richiesto mancato). - Chiamate a strumenti ed effetti collaterali: quale strumento è stato chiamato, parametri (sanitizzati), codici di risposta e timing. Questo è essenziale quando i fallimenti originano fuori dal modello.
- Eccezioni e timeout: stack trace per errori interni, più codici errore user-friendly che mappano a categorie note.
Metriche che predicono davvero l'affidabilità
I log aiutano a debug un incidente; le metriche aiutano a individuare pattern.
Monitora:
- Tasso di fallimento della convalida (totale e per regola)
- Tasso di passaggio dello schema (output che corrispondono alla struttura attesa)
- Tasso di retry e tasso di successo dei recuperi (quanto spesso i fallback funzionano)
- Latenza (end-to-end e per chiamata a strumenti)
- Categorie di errore principali (es., “campo mancante”, “timeout strumento”, “violazione di policy”)
Alert su drift
Gli output AI possono cambiare sottilmente dopo modifiche ai prompt, aggiornamenti di modello o nuovo comportamento utente. Gli alert dovrebbero concentrarsi sul cambiamento, non solo su soglie assolute:
- Aumento improvviso di una regola di convalida fallita
- Nuove categorie di errore che appaiono
- Cambiamenti nella forma dell'output (es., un campo JSON che diventa testo libero)
Dashboard comprensibili per team non tecnici
Una buona dashboard risponde a: “Funziona per gli utenti?” Includi un semplice score di affidabilità, una linea di tendenza per il tasso di passaggio dello schema, una scomposizione dei fallimenti per categoria e esempi dei tipi di errore più comuni (con contenuto sensibile rimosso). Collega viste tecniche più profonde per gli ingegneri, ma mantieni la vista di alto livello leggibile per prodotto e supporto.
Miglioramento continuo: trasformare i fallimenti in regole migliori
La convalida e la gestione degli errori non sono “impostale e scordati”. Nei sistemi generati dall'IA, il lavoro reale inizia dopo il lancio: ogni output strano è un indizio su cosa dovrebbero essere le tueregole.
Costruire loop di feedback stretti
Tratta i fallimenti come dati, non come aneddoti. Il loop più efficace combina solitamente:
- Segnalazioni utenti (semplice “Segnala un problema” + screenshot/output ID opzionale)
- Code di revisione umana per casi ambigui (fuorvianti, non sicuri o “sembra sbagliato”)
- Etichettatura automatica (regex/fallimenti di schema, flag di tossicità, mismatch di rilevamento lingua, segnali di alta incertezza)
Assicurati che ogni segnalazione sia collegata all'input esatto, alla versione del modello/prompt e ai risultati del validator in modo da poterla riprodurre dopo.
Come avvengono le correzioni
La maggior parte dei miglioramenti rientra in mosse ripetibili:
- Restringere lo schema: se ti aspetti JSON, specifica campi richiesti, enum e tipi; rifiuta il “quasi JSON”.
- Aggiungere validator mirati: impone unità, formati di data, intervalli ammessi e vincoli di inclusione obbligatoria.
- Aggiustare i prompt: chiarire priorità (“Se non sei sicuro, dì che non lo sai”), aggiungere esempi e ridurre istruzioni ambigue.
- Aggiungere fallback: ritenta con prompt più stringenti, passa a una risposta template più sicura o instrada a revisione umana—senza inventare dettagli in modo silenzioso.
Quando correggi un caso, chiediti anche: “Quali casi vicini possono ancora sfuggire?” Estendi la regola per coprire un piccolo cluster, non solo un singolo incidente.
Versioning e rollout sicuri
Versiona prompt, validator e modelli come codice. Rilascia cambiamenti con deployment canary o A/B, monitora metriche chiave (tasso di rifiuto, soddisfazione utente, costo/latenza) e tieni una via di rollback rapida.
Qui il tooling prodotto aiuta: ad esempio, piattaforme come Koder.ai supportano snapshot e rollback durante l'iterazione delle app, che si mappano bene al versioning di prompt/validator. Quando un aggiornamento aumenta i fallimenti dello schema o rompe un'integrazione, un rollback rapido trasforma un incidente di produzione in un recupero veloce.
Checklist pratica
- Possiamo riprodurre qualsiasi problema segnalato dai log?
- I fallimenti vengono instradati al giusto bucket (retry, fallback, revisione umana, stop hard)?
- Abbiamo aggiornato schema/validator e prompt insieme?
- Abbiamo aggiunto un caso di test per questo fallimento così non ritorni?
- Abbiamo rilasciato dietro un canary e monitorato l'impatto?
Domande frequenti
Cosa si intende in questo post per “sistema generato dall'IA”?
Un sistema generato dall'IA è qualsiasi prodotto in cui l'output di un modello influisce direttamente su ciò che succede dopo—quello che viene mostrato, memorizzato, inviato a un altro strumento o eseguito come azione.
È più ampio di una chat: può includere dati generati, codice, passaggi di workflow o decisioni sugli strumenti/agenti.
Perché la convalida e la gestione degli errori sono trattate come funzionalità di prodotto?
Perché una volta che l'output dell'IA entra nel flusso di controllo, l'affidabilità diventa una questione di esperienza utente. Una risposta JSON malformata, un campo mancante o un'istruzione sbagliata possono:
- creare stati UI confusi
- scrivere record errati
- innescare effetti collaterali rischiosi
Progettare per tempo con regole di convalida e percorsi di errore rende i fallimenti controllati invece che caotici.
Qual è la differenza tra validità strutturale e validità di business?
La validità strutturale significa che l'output è parsabile e ha la forma attesa (es., JSON valido, chiavi richieste presenti, tipi corretti).
La validità di business significa che il contenuto è accettabile per le regole reali della tua attività (es., gli ID esistono, i totali tornano, il testo di rimborso rispetta la policy). Di solito servono entrambi i livelli.
Cosa significa progettare le interazioni AI come “contratti”?
Un contratto pratico definisce cosa deve essere vero in tre punti:
- Input: campi richiesti, intervalli ammessi, contesto necessario
- Output: chiavi richieste, valori ammessi, soglie (es., confidenza)
- Effetti collaterali: quali azioni sono permesse (es., “solo bozza”, “deve chiedere conferma prima di inviare”)
Una volta che hai un contratto, i validator sono solo l'applicazione automatica di esso.
Quali input dovrebbero essere convalidati in un workflow AI?
Tratta come input non solo la casella del prompt. Fonti tipiche includono:
- Testo dell'utente (chat, prompt, commenti)
- File (PDF, immagini, fogli di calcolo, audio)
- Form strutturati (menu a tendina, onboarding multi-step)
- (JSON da altri servizi, webhook)
Quando dovremmo auto-correggere gli input e quando rifiutarli?
Normalizza quando l'intento è inequivocabile e la modifica è reversibile (es., rimuovere spazi iniziali/finali, uniformare casse per codici paese).
Rifiuta quando la correzione potrebbe cambiare il significato o nascondere errori (es., date ambigue come “03/04/2025”, valute inaspettate, HTML/JS sospetto). Una buona regola: auto-correggi il formato, rifiuta la semantica.
Come dobbiamo convalidare gli output del modello in modo realmente sicuro?
Inizia con uno schema di output esplicito:
- chiavi richieste (es.,
answer,status) - tipi (stringa/numero/array)
- enum e vincoli (lunghezze/intervalli)
Poi aggiungi controlli semantici (gli ID risolvono, i totali si ricompongono, le date hanno senso, le citazioni supportano le affermazioni). Se la convalida fallisce, non consumare l'output a valle—ritenta con vincoli più stretti o usa un fallback.
Come scegliere tra fallire velocemente e fallire con grazia?
Fallisci rapidamente quando continuare sarebbe rischioso: impossibile parsare l'output, campi obbligatori mancanti, violazioni di policy.
Fallisci con grazia quando esiste un recupero sicuro: timeout transitori, limiti di rata, problemi di formattazione minori.
In entrambi i casi separa:
- Messaggio per l'utente: breve, azionabile e non tecnico
- Diagnostica interna: codice errore, output grezzo (in modo sicuro), risultati dei validator, timing, ID di correlazione
Quando i retry e i fallback aiutano—e quando peggiorano le cose?
I retry aiutano per errori transitori (time out, 429, outage temporanei). Usa retry limitati con backoff esponenziale e jitter.
I retry sono dannosi per risposte sbagliate (mismatch di schema, campi mancanti, violazioni di policy). In quei casi preferisci la riparazione del prompt (istruzioni più rigide), template deterministici, un modello più piccolo, risultati dalla cache o revisione umana a seconda del rischio.
Da dove vengono di solito i casi limite nei prodotti AI reali?
I casi limite comuni nascono da:
- input reali e disordinati (testi copiati da PDF, linee spezzate, contesti lunghi)
- valori al bordo (campi vuoti, testi molto lunghi, Unicode insolito, lingue miste)
- deriva delle integrazioni (cambi di campo in API, mismatch di permessi, date/valute non conformi)
Prevedi di scoprire gli “unknown unknowns” tramite log privacy-aware che catturino quale regola di convalida è fallita e quale percorso di recupero è stato eseguito.