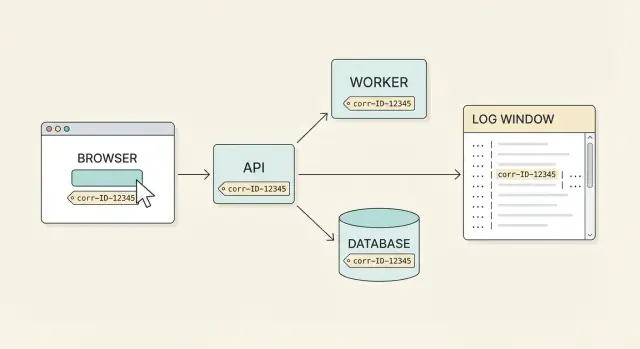
Perché i correlation ID sono importanti per il supporto
Il supporto raramente riceve un report di bug pulito. Un utente dice: "Ho cliccato Pay e ha fallito", ma quel singolo click può coinvolgere il browser, un API gateway, un servizio pagamenti, un database e un job in background. Ogni parte registra il suo pezzo della storia in momenti diversi, su macchine diverse. Senza un'etichetta condivisa, si finisce per indovinare quali righe di log appartengono insieme.
Un correlation ID è quell'etichetta condivisa. È un unico ID collegato a una singola azione utente (o a un workflow logico) e trasportato attraverso ogni richiesta, retry e hop di servizio. Con una copertura end-to-end reale, puoi partire da un reclamo utente e ottenere la timeline completa attraverso i sistemi.
Spesso si confondono alcuni ID simili. Ecco la separazione chiara:
- Correlation ID: raggruppa tutto ciò che riguarda un'azione (per esempio, "Salva impostazioni").
- Request ID: identifica una singola richiesta HTTP. I retry creano nuovi request ID.
- Trace ID: usato dagli strumenti di distributed tracing; obiettivo simile, spesso generato dalle librerie di tracing.
- Session ID: identifica una sessione utente attraverso molte azioni; troppo ampio per il debug di un singolo incidente.
Un buon processo è semplice: un utente segnala un problema, gli chiedi il correlation ID mostrato nella UI (o trovato in una schermata di supporto), e chiunque del team può trovare la storia completa in pochi minuti. Vedi la richiesta frontend, la risposta API, i passaggi backend e il risultato del database, tutti collegati insieme.
Decidi le convenzioni per i correlation ID
Prima di generare qualsiasi cosa, concorda poche regole. Se ogni team sceglie un nome di header o un campo di log diverso, il supporto resterà comunque a indovinare.
Parti da un nome canonico e usalo ovunque. Una scelta comune è un header HTTP come X-Correlation-Id, più un campo di log strutturato come correlation_id. Scegli una sola grafia e un solo casing, documentalo e assicurati che il reverse proxy o il gateway non rinominino o scartino l'header.
Scegli un formato facile da creare e sicuro da condividere nei ticket e nelle chat. Gli UUID funzionano bene perché sono unici e anonimi. Mantieni l'ID abbastanza corto da poterlo copiare, ma non così corto da rischiare collisioni. La coerenza batte la genialità.
Decidi anche dove l'ID deve comparire perché gli esseri umani possano effettivamente usarlo. In pratica significa che è presente nelle richieste, nei log e nelle uscite d'errore, ed è ricercabile nello strumento che il tuo team usa.
Definisci quanto deve durare un singolo ID. Un buon default è la durata di una singola azione utente, come "cliccato Pay" o "profilo salvato". Per workflow più lunghi che attraversano servizi e code, mantieni lo stesso ID fino alla fine del workflow, poi aprine uno nuovo per l'azione successiva. Evita "un ID per tutta la sessione" perché le ricerche diventano rapidamente troppo rumorose.
Una regola ferrea: non inserire mai dati personali nell'ID. Niente email, numeri di telefono, user ID o numeri d'ordine. Se ti serve quel contesto, registralo in campi separati con i giusti controlli di privacy.
Generare l'ID nel frontend (approccio pratico)
Il posto più semplice per iniziare un correlation ID è il momento in cui l'utente avvia un'azione che ti interessa: clic su "Salva", submit di un form o avvio di un flusso che scatena più richieste. Se aspetti che il backend lo crei, spesso perdi la prima parte della storia (errori UI, retry, richieste cancellate).
Usa un formato casuale e unico. UUID v4 è una scelta comune perché è facile da generare e ha bassa probabilità di collisione. Mantienilo opaco (niente username, email o timestamp) così non esponi dati personali in header e log.
Crea e conserva l'ID per un workflow
Considera un "workflow" come una singola azione utente che può attivare più richieste: validazione, upload, creazione record, poi refresh delle liste. Crea un ID quando il workflow inizia e mantienilo fino alla fine (successo, errore o cancellazione da parte dell'utente). Un pattern semplice è conservarlo nello stato del componente o in un oggetto di contesto delle richieste leggero.
Se l'utente avvia la stessa azione due volte, genera un nuovo correlation ID per il secondo tentativo. Questo permette al supporto di distinguere "stesso click ritentato" da "due invii separati".
Allegalo a ogni richiesta del workflow
Aggiungi l'ID a ogni chiamata API attivata dal workflow, di solito tramite un header come X-Correlation-ID. Se usi un client API condiviso (wrapper fetch, istanza Axios, ecc.), passa l'ID una volta e lascia che il client lo inietti in tutte le chiamate.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Se la UI esegue richieste di background non correlate all'azione (polling, analytics, auto-refresh), non riutilizzare l'ID del workflow per quelle. Mantieni i correlation ID focalizzati in modo che un ID racconti una sola storia.
Trasmettere l'ID attraverso le API in modo affidabile
Una volta generato il correlation ID nel browser, il compito è semplice: deve lasciare il frontend con ogni richiesta e arrivare invariato ad ogni confine API. Questo è ciò che si rompe più spesso quando i team aggiungono nuovi endpoint, nuovi client o nuovo middleware.
Il default più sicuro è un header HTTP su ogni chiamata (per esempio X-Correlation-Id). Gli header sono facili da aggiungere in un solo punto (wrapper fetch, interceptor Axios, layer di networking mobile) e non richiedono di cambiare i payload.
Se hai richieste cross-origin, assicurati che la tua API permetta quell'header. Altrimenti il browser potrebbe bloccarlo silenziosamente e penserai di inviarlo quando non è così.
Se devi mettere l'ID nella query string o nel body della richiesta (alcuni tool di terze parti o upload di file lo richiedono), mantieni la coerenza e documentalo. Scegli un solo nome di campo e usalo ovunque. Non mescolare correlationId, requestId e cid a seconda dell'endpoint.
I retry sono un'altra trappola comune. Un retry dovrebbe mantenere lo stesso correlation ID se è ancora la stessa azione utente. Esempio: l'utente clicca "Salva", la rete cade, il client ritenta la POST. Il supporto dovrebbe vedere un'unica traccia collegata, non tre tracce scollegate. Un nuovo click utente (o un nuovo job in background) dovrebbe ottenere un nuovo ID.
Per i WebSocket, includi l'ID nell'envelope del messaggio, non solo nell'handshake iniziale. Una connessione può trasportare molte azioni utente.
Se vuoi un controllo rapido sull'affidabilità, tienilo semplice:
- Un helper client condiviso aggiunge l'header a ogni richiesta.
- I retry riutilizzano lo stesso ID per la stessa azione.
- Qualsiasi fallback su body/query usa un unico nome di campo documentato.
- I messaggi WebSocket includono un campo esplicito
correlationId.
Comportamento all'entry point API
Crea una console di supporto semplice
Crea una schermata interna per cercare incidenti per correlation ID in pochi secondi.
Il tuo edge API (gateway, load balancer o il primo servizio che riceve il traffico) è dove i correlation ID diventano affidabili o si trasformano in indovinelli. Tratta questo punto d'ingresso come fonte di verità.
Accetta un ID in ingresso se il client lo invia, ma non dare per scontato che sia sempre presente. Se manca, generane uno nuovo immediatamente e usalo per il resto della richiesta. Questo mantiene il sistema funzionante anche quando alcuni client sono vecchi o mal configurati.
Esegui una validazione leggera in modo che valori brutti non inquinino i log. Mantienila permissiva: controlla lunghezza e caratteri consentiti, ma evita formati rigidi che rifiuterebbero traffico reale. Per esempio, consenti 16-64 caratteri e lettere, numeri, trattino e underscore. Se il valore fallisce la validazione, sostituiscilo con un ID nuovo e continua.
Rendi l'ID visibile al chiamante. Restituiscilo sempre negli header di risposta e includilo nei corpi di errore. In questo modo un utente può copiarlo dalla UI, o un agente di supporto può chiederlo e trovare la traccia esatta nei log.
Una policy edge pratica è così:
- Leggi
X-Correlation-ID (o l'header scelto) dalla richiesta.
- Se manca o è invalido, crea un nuovo ID e allegalo al contesto della richiesta.
- Aggiungi
X-Correlation-ID a ogni risposta, inclusi gli errori.
- Quando ritorni errori JSON, fai eco dell'ID nel payload.
Esempio di payload di errore (ciò che il supporto dovrebbe vedere nei ticket e negli screenshot):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Propagare l'ID tra i servizi backend
Una volta che una richiesta arriva al backend, tratta il correlation ID come parte del contesto della richiesta, non come qualcosa da mettere in una variabile globale. Le globali si rompono non appena gestisci due richieste contemporaneamente, o quando lavoro asincrono continua dopo la risposta.
Una regola scalabile: ogni funzione che può loggare o chiamare un altro servizio dovrebbe ricevere il contesto che contiene l'ID. Nei servizi Go, questo di solito significa passare context.Context attraverso handler, logica di business e codice client.
Quando il Servizio A chiama il Servizio B, copia lo stesso ID nella richiesta uscente. Non generarne uno nuovo in volo a meno che non mantieni anche l'originale come campo separato (per esempio parent_correlation_id). Se cambi gli ID, il supporto perde il filo unico che lega la storia.
La propagazione viene spesso dimenticata in luoghi prevedibili: job di background avviati durante la richiesta, retry dentro librerie client, webhook triggerati più tardi e chiamate in fan-out. Qualsiasi messaggio asincrono (coda/job) dovrebbe portare l'ID, e qualsiasi logica di retry dovrebbe preservarlo.
I log dovrebbero essere strutturati con un nome di campo stabile come correlation_id. Scegli una sola grafia e mantienila ovunque. Evita di mischiare requestId, req_id e traceId a meno che non definisci anche una mappatura chiara.
Se possibile, includi l'ID anche nella visibilità del database. Un approccio pratico è aggiungerlo ai commenti delle query o ai metadati della sessione in modo che i log delle query lente possano mostrarlo. Quando qualcuno segnala "il pulsante Salva è rimasto appeso per 10 secondi", il supporto può cercare correlation_id=abc123 e vedere il log API, la chiamata al servizio downstream e la singola query SQL lenta che ha causato il ritardo.
Includi l'ID nei log che gli umani possono usare
Un correlation ID aiuta solo se le persone possono trovarlo e seguirlo. Rendilo un campo di log di prima classe (non sepolto dentro la stringa del messaggio) e mantieni il resto della voce di log consistente tra i servizi.
Campi di log che rendono l'ID utilizzabile
Abbina il correlation ID a un piccolo insieme di campi che rispondono: quando, dove, cosa e chi (in modo sicuro per l'utente). Per la maggior parte dei team, significa:
timestamp (con timezone)service e env (api, worker, prod, staging)route (o nome dell'operazione) e methodstatus e duration_ms- un identificatore utente sicuro (per esempio
account_id o un user id hashed, non un'email)
Con questo, il supporto può cercare per ID, confermare di guardare la richiesta giusta e vedere quale servizio l'ha gestita.
Cosa loggare all'inizio, al successo e all'errore
Punta a poche briciole significative per richiesta, non a una trascrizione completa.
- Start: correlation ID, route, identificatore utente sicuro e input chiave (sommari).
- Success: correlation ID, status, durata e un breve outcome (per esempio
rows=12).
- Failure: correlation ID, tipo di errore, contesto sicuro e dove è successo (handler, dipendenza).
Per evitare log rumorosi, tieni i dettagli di debug fuori per default e promuovi solo gli eventi che aiutano a rispondere a "Dove è fallito?". Se una riga non aiuta a localizzare il problema o misurarne l'impatto, probabilmente non dovrebbe stare nei log di livello info.
La redazione è importante quanto la struttura. Non mettere mai PII nel correlation ID o nei log: niente email, nomi, numeri di telefono, indirizzi completi o token raw. Se devi identificare un utente, registra un ID interno o un hash one-way.
Esempio: tracciare un report utente dall'UI al database
Imposta una policy affidabile all'entry API
Genera la logica del gateway che accetta, valida ed echoa automaticamente X-Correlation-ID.
Un utente scrive al supporto: "Checkout fallito quando ho cliccato Pay." La domanda migliore di follow-up è semplice: "Puoi incollare il correlation ID mostrato nella schermata d'errore?" Lui risponde con cid=9f3c2b1f6a7a4c2f.
Il supporto ha ora una maniglia che collega UI, API e lavoro su database. L'obiettivo è che ogni riga di log per quell'azione porti lo stesso ID.
Il supporto cerca i log per 9f3c2b1f6a7a4c2f e vede il flusso:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Da lì, un ingegnere segue lo stesso ID nel passo successivo. L'importante è che le chiamate backend (e qualsiasi job in coda) inoltrino anche l'ID.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Ora il problema è concreto: il servizio pagamenti ha avuto un timeout dopo 3 secondi e viene scritto un record di fallimento. L'ingegnere può controllare deploy recenti, verificare se le impostazioni di timeout sono cambiate e vedere se avvengono retry.
Per chiudere il cerchio, fai quattro verifiche:
- Risolvi la causa (per esempio, aggiusta il timeout e aggiungi un retry sicuro).
- Assicurati che gli errori visibili all'utente includano il correlation ID.
- Monitora nuovi log con lo stesso pattern di errore e ID differenti.
- Conferma che l'ID sopravvive a ogni hop (inclusi worker e messaggi in coda).
Errori comuni e come evitarli
Il modo più rapido per rendere inutili i correlation ID è spezzare la catena. La maggior parte dei problemi nasce da piccole decisioni che sembrano innocue durante lo sviluppo, ma che poi ostacolano il supporto.
Un errore classico è generare un ID nuovo a ogni hop. Se il browser invia un ID, il tuo API gateway dovrebbe mantenerlo, non sostituirlo. Se davvero ti serve un ID interno (per un messaggio in coda o un job), conserva l'originale come campo parent in modo che la storia rimanga collegata.
Un altro gap comune è il logging parziale. I team aggiungono l'ID al primo API, ma lo dimenticano nei processi worker, nei job schedulati o nel layer di accesso al database. Il risultato è un vicolo cieco: vedi la richiesta entrare nel sistema, ma non dove è andata dopo.
Evita il problema del "caos di naming"
Anche quando l'ID esiste ovunque, può essere difficile cercarlo se ogni servizio usa un nome di campo o un formato diverso. Scegli un nome e mantienilo su frontend, API e log (per esempio, correlation_id). Scegli anche un formato (spesso un UUID) e trattalo come case-sensitive così il copia-incolla funziona.
Non perdere l'ID quando qualcosa va storto. Se un'API restituisce 500 o un errore di validazione, includi il correlation ID nella risposta d'errore (e idealmente anche in un header di risposta). Così un utente può incollarlo in una chat di supporto e il team può tracciare immediatamente il percorso completo.
Un test rapido: può una persona del support iniziare con un ID e seguirlo attraverso ogni riga di log coinvolta, inclusi i fallimenti?
Checklist rapida per verificare la copertura end-to-end
Distribuisci un'app tracciabile più velocemente
Vai da piano ad app funzionante senza configurare server manualmente.
Usa questo come controllo di sanità prima di dire al support "cercate pure nei log". Funziona solo quando ogni hop segue le stesse regole.
Controlli obbligatori
- Hai un unico formato di ID e un unico nome di header, usati ovunque (frontend, gateway, API, worker).
- Il frontend crea (o riceve) l'ID all'inizio di un'azione utente e lo mantiene fino al termine dell'azione.
- Il punto d'ingresso API crea un ID se manca e lo restituisce sempre negli header di risposta.
- Ogni servizio backend include
correlation_id nei log relativi alle richieste come campo strutturato.
- Il personale on-call può incollare un ID nella ricerca dei log e vedere tutto il percorso in pochi minuti: richiesta edge, auth, chiamate di servizio, operazione DB e retry.
Se un controllo fallisce, risolvilo così
Scegli la modifica più piccola che mantiene la catena ininterrotta.
- Se gli ID cambiano in volo, smetti di generarne di nuovi nei servizi interni. Mantieni l'originale
correlation_id e aggiungi un span_id separato se ti serve più dettaglio.
- Se i log mancano del campo, aggiungi middleware di logging così gli ingegneri non devono ricordarsi di includerlo.
- Se il support non riesce a ottenere l'ID, assicurati che la UI lo mostri sulle schermate d'errore e che il gateway lo echoi sempre nelle risposte.
Un test rapido che cattura le lacune: apri devtools, esegui un'azione, copia il correlation ID dalla prima richiesta e poi conferma di vedere lo stesso valore in ogni richiesta API correlata e in ogni riga di log corrispondente.
Prossimi passi: inseriscilo nel tuo processo di sviluppo
I correlation ID aiutano solo quando tutti li usano nello stesso modo, ogni volta. Tratta il comportamento dei correlation ID come parte richiesta della consegna, non come una modifica opzionale ai log.
Aggiungi un piccolo passo di tracciabilità alla tua definition of done per ogni nuovo endpoint o azione UI. Copri come l'ID viene creato (o riutilizzato), dove vive durante il flusso, quale header lo trasporta e cosa fa ogni servizio quando l'header manca.
Una checklist leggera è spesso sufficiente:
- Frontend: genera o riusa un ID per ogni azione utente e allegalo a tutte le chiamate API di quell'azione.
- Entry API: accetta l'header, valida o genera, poi lo echoa nella risposta.
- Backend: passalo ai servizi downstream e ai job, e includilo nei log.
- Logging: mantieni il nome del campo coerente (per esempio
correlation_id) tra app e servizi.
- Review: rifiuta PR che aggiungono endpoint senza test che provino che l'ID compare nei log.
Il support ha anche bisogno di uno script semplice per rendere il debug rapido e ripetibile. Decidi dove l'ID compare per gli utenti (per esempio un pulsante "Copia debug ID" nelle dialog d'errore) e scrivi cosa il support deve chiedere e dove cercare.
Prima di affidarti a questo in produzione, esegui un flusso stagging che riproduca l'uso reale: clicca un bottone, scatena un errore di validazione, poi completa l'azione. Conferma di poter seguire lo stesso ID dalla richiesta del browser, attraverso i log API, in ogni worker di background e fino ai log delle chiamate al database se li registri.
Se stai costruendo app su Koder.ai, aiuta inserire le convenzioni di header e logging per i correlation ID in Planning Mode così i frontend React e i servizi Go generati partono coerenti di default.