22 set 2025·8 min
Cos'è Kafka e come viene usato nei sistemi moderni?
Scopri cos'è Apache Kafka, come funzionano topic e partizioni e dove si colloca Kafka nei sistemi moderni per eventi in tempo reale, log e pipeline di dati.
Scopri cos'è Apache Kafka, come funzionano topic e partizioni e dove si colloca Kafka nei sistemi moderni per eventi in tempo reale, log e pipeline di dati.
Apache Kafka è una piattaforma distribuita di event streaming. In termini semplici, è una “tubo” condiviso e durevole che permette a molti sistemi di pubblicare fatti su ciò che è successo e ad altri sistemi di leggere quei fatti—velocemente, a scala e in ordine.
I team usano Kafka quando i dati devono muoversi in modo affidabile tra sistemi senza un forte accoppiamento. Invece di far sì che un'applicazione chiami direttamente un'altra (e fallisca se è giù o lenta), i producer scrivono eventi in Kafka. I consumer li leggono quando sono pronti. Kafka conserva gli eventi per un periodo configurabile, così i sistemi possono riprendersi da interruzioni e persino riprocessare la storia.
Questa guida è per ingegneri orientati al prodotto, persone dei dati e leader tecnici che vogliono un modello mentale pratico di Kafka.
Imparerai i blocchi fondamentali (producer, consumer, topic, broker), come Kafka scala con le partizioni, come memorizza e riproduce gli eventi e dove si inserisce nell'architettura event-driven. Copriremo anche casi d'uso comuni, garanzie di consegna, nozioni di sicurezza, pianificazione operativa e quando Kafka è (o non è) lo strumento giusto.
Kafka è più semplice da capire come un log di eventi condiviso: le applicazioni scrivono eventi su di esso e altre applicazioni leggono quegli eventi dopo—spesso in tempo reale, a volte ore o giorni dopo.
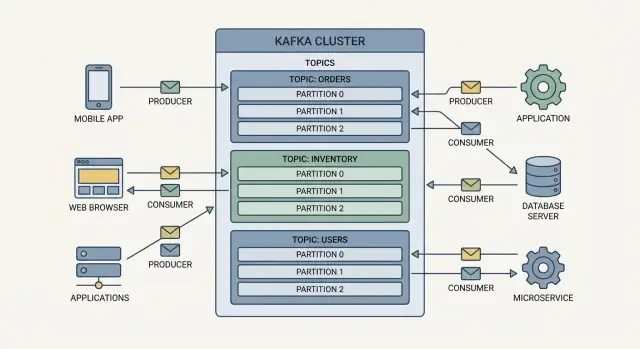
Producer sono gli scrittori. Un producer potrebbe pubblicare un evento come “order placed”, “payment confirmed” o “temperature reading”. I producer non inviano eventi direttamente ad app specifiche—invece li inviano a Kafka.
Consumer sono i lettori. Un consumer potrebbe alimentare una dashboard, attivare un workflow di spedizione o caricare dati per analytics. I consumer decidono cosa fare con gli eventi e possono leggerli al proprio ritmo.
Gli eventi in Kafka sono raggruppati in topic, che sono fondamentalmente categorie nominate. Per esempio:
orders per eventi legati agli ordinipayments per eventi di pagamentoinventory per variazioni di stockUn topic diventa lo stream “source of truth” per quel tipo di evento, facilitando il riuso dei dati da parte di più team senza integrare soluzioni ad hoc.
Un broker è un server Kafka che memorizza eventi e li serve ai consumer. In pratica, Kafka gira come un cluster (più broker che lavorano insieme) così può gestire più traffico e rimanere operativo anche se una macchina fallisce.
I consumer spesso girano in un consumer group. Kafka suddivide il lavoro di lettura tra i membri del gruppo, così puoi aggiungere istanze consumer per scalare il processing—senza che ogni istanza esegua lo stesso lavoro.
Kafka scala dividendo il lavoro in topic (stream di eventi correlati) e poi spezzando ogni topic in partizioni (fette più piccole e indipendenti di quello stream).
Un topic con una sola partizione può essere letto da un solo consumer alla volta all'interno di un consumer group. Aggiungi più partizioni e puoi aggiungere più consumer per processare gli eventi in parallelo. È così che Kafka supporta l'event streaming ad alto volume e le pipeline di dati in tempo reale senza trasformare ogni sistema in un collo di bottiglia.
Le partizioni aiutano anche a distribuire il carico tra i broker. Invece che una sola macchina gestisca tutte le scritture e letture per un topic, più broker possono ospitare partizioni diverse e condividere il traffico.
Kafka garantisce l'ordinamento all'interno di una singola partizione. Se gli eventi A, B e C vengono scritti nella stessa partizione in quell'ordine, i consumer li leggeranno A → B → C.
L'ordinamento tra partizioni non è garantito. Se hai bisogno di un ordinamento rigoroso per una specifica entità (come un cliente o un ordine), di solito fai in modo che tutti gli eventi per quell'entità vadano nella stessa partizione.
Quando i producer inviano un evento, possono includere una key (ad esempio order_id). Kafka usa la key per instradare in modo coerente eventi correlati nella stessa partizione. Questo dà un ordinamento prevedibile per quella key pur permettendo al topic di scalare su molte partizioni.
Ogni partizione può essere replicata su altri broker. Se un broker fallisce, un altro broker con una replica può subentrare. La replica è una delle ragioni principali per cui Kafka è affidabile in sistemi critici: migliora la disponibilità e supporta la tolleranza ai guasti senza costringere ogni applicazione a implementare logiche di failover.
Un'idea chiave in Apache Kafka è che gli eventi non vengono solo passati e dimenticati. Vengono scritti su disco in un log ordinato, così i consumer possono leggerli ora—o dopo. Questo rende Kafka utile non solo per muovere dati, ma anche per mantenere una storia durevole di ciò che è successo.
Quando un producer invia un evento a un topic, Kafka lo appende allo storage sul broker. I consumer leggono poi da quel log memorizzato al proprio ritmo. Se un consumer è giù per un'ora, gli eventi esistono ancora e possono essere recuperati al suo riavvio.
Kafka conserva gli eventi secondo policy di retention:
La retention si configura per topic, così puoi trattare in modo diverso i topic di audit da quelli di telemetria ad alto volume.
Alcuni topic sono più simili a un changelog che a un archivio storico—per esempio, “impostazioni utente correnti”. La log compaction mantiene almeno l'evento più recente per ogni chiave, mentre i record più vecchi possono essere rimossi. In questo modo ottieni una fonte di verità duratura per lo stato più recente senza crescita illimitata.
Poiché gli eventi rimangono memorizzati, puoi riprodurli per ricostruire lo stato:
Nella pratica, il replay è controllato da dove un consumer “inizia a leggere” (il suo offset), dando ai team una rete di sicurezza potente quando i sistemi evolvono.
Kafka è progettato per mantenere il flusso di dati anche quando parti del sistema falliscono. Lo fa con replica, regole chiare su chi è “responsabile” di ogni partizione e acknowledgment di scrittura configurabili.
Ogni partizione ha un broker leader e uno o più replica follower su altri broker. Producer e consumer parlano con il leader di quella partizione.
I follower copiano continuamente i dati del leader. Se il leader va giù, Kafka può promuovere un follower aggiornato a nuovo leader, così la partizione rimane disponibile.
Se un broker fallisce, le partizioni per cui era leader diventano temporaneamente non disponibili. Il controller di Kafka rileva il problema e avvia l'election del leader per quelle partizioni.
Se almeno una replica è sufficientemente aggiornata, può prendere il posto del leader e i client riprendono a produrre/consumare. Se non ci sono repliche in-sync, Kafka potrebbe mettere in pausa le scritture (a seconda delle impostazioni) per evitare la perdita di dati già confermati.
Due principali leve influenzano la durabilità:
A livello concettuale:
Per ridurre duplicati durante i retry, i team spesso combinano acks più sicuri con producer idempotenti e una gestione robusta dei consumer.
Maggiore sicurezza tipicamente significa aspettare più conferme e mantenere più repliche in sync, il che può aggiungere latenza e ridurre il throughput massimo.
Impostazioni a bassa latenza possono andar bene per telemetria o clickstream dove la perdita occasionale è accettabile, ma pagamenti, inventario e log di audit solitamente giustificano la maggiore sicurezza.
L'architettura event-driven (EDA) è un modo di costruire sistemi in cui gli eventi di business—un ordine effettuato, un pagamento confermato, un pacco spedito—sono rappresentati come eventi a cui altre parti del sistema possono reagire.
Kafka spesso sta al centro di EDA come lo “stream di eventi” condiviso. Invece che il Servizio A chiami il Servizio B direttamente, il Servizio A pubblica un evento (ad esempio OrderCreated) su un topic Kafka. Un numero qualsiasi di servizi può consumare quell'evento e agire—inviare un'email, riservare inventario, avviare controlli antifrode—senza che il produttore debba conoscerli.
Poiché i servizi comunicano tramite eventi, non devono coordinare API request/response per ogni interazione. Questo riduce dipendenze strette tra team e rende più facile aggiungere nuove funzionalità: puoi introdurre un nuovo consumer per un evento esistente senza cambiare il producer.
EDA è naturalmente asincrona: i producer scrivono eventi rapidamente e i consumer li processano al proprio ritmo. Durante picchi di traffico, Kafka aiuta a smorzare l'ondata così i sistemi downstream non crollano immediatamente. I consumer possono scalare per recuperare, e se un consumer va giù temporaneamente può riprendere da dove aveva lasciato.
Pensa a Kafka come al “feed di attività” del sistema. I producer pubblicano fatti; i consumer si iscrivono ai fatti che gli interessano. Questo pattern abilita pipeline di dati in tempo reale e workflow event-driven mantenendo i servizi più semplici e indipendenti.
Kafka tende a comparire dove i team devono muovere molti piccoli “fatti che sono accaduti” (eventi) tra sistemi—velocemente, in modo affidabile e in modo che più consumer possano riutilizzare gli stessi dati.
Le applicazioni spesso hanno bisogno di una storia append-only: accessi utente, cambi di permessi, aggiornamenti di record o azioni amministrative. Kafka funziona bene come stream centrale di questi eventi, così strumenti di sicurezza, report e esportazioni per compliance possono leggere la stessa fonte senza gravare sul DB di produzione. Poiché gli eventi sono trattenuti per un periodo, puoi anche riprodurli per ricostruire una vista di audit dopo un bug o un cambiamento di schema.
Invece di chiamate dirette, i servizi possono pubblicare eventi come “order created” o “payment received”. Altri servizi si iscrivono e reagiscono a loro tempo. Questo riduce l'accoppiamento, aiuta i sistemi a restare operativi durante outage parziali e facilita l'aggiunta di nuove capacità (ad esempio controlli antifrode) semplicemente consumando lo stream esistente.
Kafka è una spina dorsale comune per spostare dati dai sistemi operazionali verso piattaforme analitiche. I team possono streamare cambiamenti dai database applicativi e portarli in un warehouse o data lake con bassa latenza, mantenendo l'app di produzione separata dalle query analitiche pesanti.
Sensori, dispositivi e telemetria app arrivano spesso a raffica. Kafka può assorbire gli spike, bufferizzarli in sicurezza e permettere al processing downstream di recuperare—utile per monitoring, alerting e analisi a lungo termine.
Kafka è più dei broker e dei topic. La maggior parte dei team si affida a strumenti complementari che rendono Kafka pratico per il movimento quotidiano dei dati, il processing degli stream e le operazioni.
Kafka Connect è il framework di integrazione di Kafka per portare dati in Kafka (source) e fuori Kafka (sink). Invece di costruire e mantenere pipeline one-off, esegui Connect e configuri i connector.
Esempi comuni includono estrarre cambiamenti dai database, ingerire eventi SaaS o consegnare dati Kafka a un data warehouse o object storage. Connect standardizza anche preoccupazioni operative come retry, offset e parallelismo.
Se Connect è per l'integrazione, Kafka Streams è per il calcolo. È una libreria che aggiungi alla tua applicazione per trasformare stream in tempo reale—filtrare eventi, arricchirli, unire stream e costruire aggregati (come “ordini al minuto”).
Poiché le app Streams leggono da topic e scrivono su topic, si integrano naturalmente in sistemi event-driven e possono scalare aggiungendo istanze.
Quando più team pubblicano eventi, la coerenza conta. La gestione degli schemi (spesso tramite uno schema registry) definisce quali campi un evento dovrebbe avere e come evolvono nel tempo. Questo aiuta a prevenire rotture come la rinominazione di un campo usato da un consumer.
Kafka è sensibile dal punto di vista operativo, quindi il monitoraggio di base è essenziale:
La maggior parte dei team usa anche UI di gestione e automazioni per deploy, configurazione dei topic e policy di accesso.
Kafka è spesso descritto come “log duraturo + consumer”, ma ciò che interessa davvero alla maggior parte dei team è: processerò ogni evento una volta e cosa succede quando qualcosa fallisce? Kafka offre i mattoni di base e tu scegli i compromessi.
At-most-once significa che potresti perdere eventi, ma non processerai duplicati. Succede se un consumer commette la posizione prima di completare il lavoro e poi si blocca.
At-least-once significa che non perderai eventi, ma i duplicati sono possibili (ad esempio, il consumer processa un evento, poi crasha e lo rielabora al restart). Questo è il comportamento più comune.
Exactly-once mira a evitare sia perdita che duplicati end-to-end. In Kafka ciò coinvolge tipicamente producer transazionali e processing compatibile (spesso con Kafka Streams). È potente, ma più vincolante e richiede una configurazione attenta.
Nella pratica molti sistemi accettano at-least-once e aggiungono salvaguardie:
Un offset consumer è la posizione dell'ultimo record processato in una partizione. Quando commetti offset, dici “ho finito fino a qui”. Commit troppo presto e rischi perdita; troppo tardi e aumenti i duplicati dopo un fallimento.
I retry dovrebbero essere limitati e visibili. Un pattern comune è:
Questo evita che un singolo “poison message” blocchi un intero consumer group mantenendo i dati disponibili per correzioni future.
Kafka spesso trasporta eventi business-critical (ordini, pagamenti, attività utente). Questo rende sicurezza e governance parte del design, non un ripensamento.
L'autenticazione risponde a “chi sei?” L'autorizzazione risponde a “cosa puoi fare?” In Kafka, l'autenticazione è comunemente fatta con SASL (ad es. SCRAM o Kerberos), mentre l'autorizzazione è applicata con ACL a livello di topic, consumer group e cluster.
Un pattern pratico è least privilege: i producer possono scrivere solo sui topic di loro pertinenza e i consumer possono leggere solo ciò di cui hanno bisogno. Questo riduce l'esposizione accidentale dei dati e limita l'impatto se le credenziali vengono compromesse.
TLS cripta i dati mentre si muovono tra app, broker e strumenti. Senza TLS, gli eventi possono essere intercettati anche su reti interne. TLS aiuta anche a prevenire attacchi man-in-the-middle validando l'identità dei broker.
Quando più team condividono un cluster, servono guardrail. Convenzioni chiare per i nomi dei topic (ad esempio <team>.<dominio>.<evento>.<versione>) rendono evidente la proprietà e aiutano gli strumenti ad applicare policy in modo coerente.
Abbina naming a quote e template di ACL così un carico rumoroso non prosciuga gli altri e i nuovi servizi partono con impostazioni sicure.
Tratta Kafka come sistema di record per la storia degli eventi solo se intendi farlo. Se gli eventi includono PII, usa minimizzazione dati (invia ID invece di profili completi), considera la crittografia a livello di campo e documenta quali topic sono sensibili.
Le impostazioni di retention dovrebbero rispecchiare requisiti legali e aziendali. Se la policy dice “elimina dopo 30 giorni”, non conservare 6 mesi “nel caso”. Revisioni e audit regolari mantengono le configurazioni allineate con l'evoluzione dei sistemi.
Gestire Apache Kafka non è “installalo e dimenticalo”. Si comporta come un servizio condiviso: molti team dipendono da esso e piccoli errori possono propagarsi alle app downstream.
La capacità di Kafka è soprattutto un problema di matematica da rivedere regolarmente. Le leve principali sono partizioni (parallelismo), throughput (MB/s in ingresso e in uscita) e crescita dello storage (quanto a lungo conservi i dati).
Se il traffico raddoppia, potresti aver bisogno di più partizioni per distribuire il carico tra i broker, più disco per la retention e più banda per la replica. Un'abitudine pratica è prevedere il tasso di scrittura di picco e moltiplicarlo per la retention per stimare la crescita del disco, poi aggiungere un buffer per replica e “successo inaspettato”.
Aspettati lavoro routinario oltre a mantenere i server in piedi:
I costi sono guidati da dischi, egress di rete e dal numero/dimensione dei broker. Kafka gestito può ridurre il carico operativo e semplificare gli upgrade, mentre l'auto-gestione può essere più economica a scala se hai operatori esperti. Il trade-off è tempo di recupero e on-call.
I team tipicamente monitorano:
Buone dashboard e alert trasformano Kafka da “scatola nera” a servizio comprensibile.
Kafka è adatto quando devi muovere molti eventi in modo affidabile, conservarli per un periodo e permettere a più sistemi di reagire agli stessi dati al proprio ritmo. È particolarmente utile quando i dati devono essere riproducibili (backfill, audit, ricostruzione di servizi) e quando prevedi di aggiungere producer/consumer nel tempo.
Kafka brilla quando hai:
Kafka può essere sovradimensionato se i tuoi bisogni sono semplici:
In questi casi l'overhead operativo (sizing del cluster, upgrade, monitoraggio, on-call) può superare i benefici.
Kafka completa—non sostituisce—database (system of record), cache (letture veloci) e strumenti di ETL batch (trasformazioni periodiche su larga scala).
Chiediti:
Se rispondi “sì” a gran parte di queste, Kafka è di solito una scelta sensata.
Kafka funziona meglio quando serve una “fonte di verità” condivisa per stream di eventi in tempo reale: molti sistemi che producono fatti (ordini creati, pagamenti autorizzati, inventario modificato) e molti sistemi che consumano quei fatti per pipeline, analytics e funzionalità reattive.
Inizia con un flusso ristretto e ad alto valore—come pubblicare eventi “OrderPlaced” per servizi downstream (email, antifrode, fulfillment). Evita di trasformare Kafka in una coda universale dal giorno zero.
Annota:
Mantieni gli schemi iniziali semplici e coerenti (timestamp, ID e un nome evento chiaro). Decidi se imporre schemi subito o evolverli con cautela.
Kafka ha successo quando qualcuno possiede:
Aggiungi subito monitoring (consumer lag, salute broker, throughput, errori). Se non hai ancora un team piattaforma, parti con un'offerta gestita e limiti chiari.
Produci eventi da un sistema, consumali in un posto, e dimostra il loop end-to-end. Solo dopo espandi a più consumer, partizioni e integrazioni.
Se vuoi muoverti velocemente dall'idea a un servizio event-driven funzionante, strumenti come Koder.ai possono aiutarti a prototipare l'app circostante rapidamente (UI React, backend Go, PostgreSQL) e aggiungere producer/consumer Kafka tramite un flusso di lavoro guidato in chat. È particolarmente utile per costruire dashboard interne e servizi leggeri che consumano topic, con funzionalità come modalità di pianificazione, esportazione del codice sorgente, deploy/hosting e snapshot con rollback.
Se stai mappando questo in un approccio event-driven, vedi il post sul blog sull'architettura event-driven. Per pianificare costi e ambienti, consulta la pagina dei prezzi.
Kafka è una piattaforma distribuita di event streaming che memorizza eventi in log duraturi e append-only.
I producer scrivono eventi nei topic e i consumer li leggono in modo indipendente (spesso in tempo reale, ma anche in seguito) perché Kafka trattiene i dati per un periodo configurabile.
Usa Kafka quando più sistemi hanno bisogno dello stesso flusso di eventi, vuoi disaccoppiare i servizi e potrebbe essere necessario riprodurre la storia.
È particolarmente utile per:
Un topic è una categoria nominata di eventi (come orders o payments).
Una partizione è una fetta di un topic che consente:
Kafka garantisce l'ordinamento solo all'interno di una singola partizione.
Kafka usa la chiave del record (ad esempio order_id) per instradare in modo coerente eventi correlati alla stessa partizione.
Regola pratica: se serve l'ordinamento per entità (tutti gli eventi di un ordine/cliente in sequenza), scegli una chiave che rappresenti quell'entità così gli eventi finiscono nella stessa partizione.
Un consumer group è un insieme di istanze consumer che si dividono il lavoro per un topic.
All'interno di un gruppo:
Se due applicazioni diverse devono ricevere ogni evento, devono usare gruppi di consumer diversi.
Kafka trattiene gli eventi su disco in base alle policy del topic, così i consumer possono recuperare dopo un downtime o riprocessare la storia.
Tipi comuni di retention:
La retention è per topic, quindi stream di audit a valore elevato possono essere conservati più a lungo rispetto alla telemetria ad alto volume.
La compattazione del log mantiene almeno l'ultimo record per chiave, rimuovendo progressivamente i record superseduti.
È utile per stream che rappresentano lo “stato corrente” (come impostazioni o profili), dove interessa il valore più recente per ogni chiave anziché ogni cambiamento storico, pur mantenendo una fonte di verità duratura per lo stato attuale.
Il pattern end-to-end più comune con Kafka è at-least-once: non perdi eventi, ma possono verificarsi duplicati.
Per gestirlo in sicurezza:
Gli offset sono il “segnalibro” del consumer per ogni partizione.
Se committi gli offset troppo presto puoi perdere lavoro in caso di crash; troppo tardi e ri-processerai record causando duplicati.
Un pattern operativo comune è retry con backoff limitato, poi pubblicare i record falliti in un dead-letter topic così un messaggio malato non blocca tutto il consumer group.
Kafka Connect sposta i dati dentro/fuori Kafka tramite connector (source e sink) invece di scrivere pipeline custom.
Kafka Streams è una libreria per trasformare e aggregare stream in tempo reale dentro le tue applicazioni (filtrare, unire, arricchire, aggregare), leggendo topic e scrivendo i risultati su topic.
Connect è tipicamente per integrazione; Streams è per calcolo/processing.