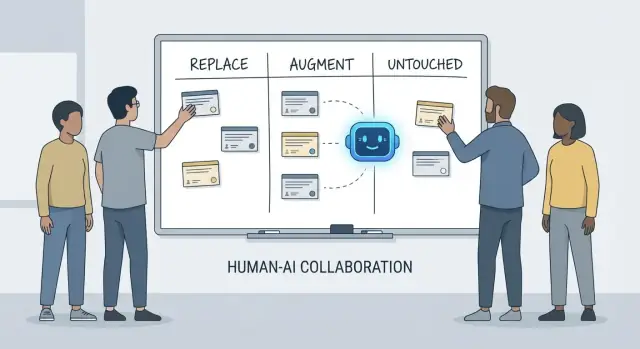
Sostituire, Potenziare, Intatto: Un framework semplice
Le conversazioni su cosa “l'IA farà agli sviluppatori” diventano rapidamente confuse perché spesso confondiamo strumenti e responsabilità. Uno strumento può generare codice, riassumere un ticket o suggerire test. Una responsabilità è ciò di cui il team è ancora responsabile quando il suggerimento è sbagliato.
Questo articolo usa un framework semplice—sostituire, potenziare, intatto—per descrivere il lavoro quotidiano in team reali con scadenze, codice legacy, incidenti di produzione e stakeholder che si aspettano risultati affidabili.
Cosa significa “sostituire” (e cosa non significa)
Sostituire significa che l'IA può completare il compito end-to-end nella maggior parte dei casi con chiari guardrail, e il ruolo umano si sposta verso supervisione e controlli a campione.
Gli esempi tendono ad essere lavori ben delimitati: generare boilerplate, tradurre codice tra linguaggi, redigere casi di test ripetitivi o produrre documentazione di primo passaggio.
Sostituire non vuol dire assenza di responsabilità umana. Se l'output rompe la produzione, perde dati o viola standard, resta responsabilità del team.
Cosa significa “potenziare”
Potenziare significa che l'IA rende uno sviluppatore più veloce o più completo, ma non finisce affidabilmente il lavoro senza giudizio umano.
Questo è il caso comune nell'ingegneria professionale: otterrai bozze utili, approcci alternativi, spiegazioni rapide o una short‑list di bug probabili—ma uno sviluppatore decide ancora cosa è corretto, sicuro e adatto al prodotto.
Cosa resta “intatto”
Intatto significa che la responsabilità principale resta guidata da umani perché richiede contesto, compromessi e accountability che non si comprimono bene in prompt.
Pensa a: negoziare requisiti, scegliere vincoli a livello di sistema, gestire incidenti, stabilire soglie di qualità e prendere decisioni dove non esiste una sola risposta “giusta”.
Perché le responsabilità sono l'unità di analisi
Gli strumenti cambiano rapidamente. Le responsabilità cambiano lentamente.
Quindi invece di chiedersi “Può un'IA scrivere questo codice?”, chiediti “Chi si assume la responsabilità del risultato?” Questa inquadratura mantiene le aspettative ancorate a accuratezza, affidabilità e responsabilità—cose che contano più delle demo impressionanti.
Cosa intendiamo per “responsabilità degli sviluppatori”
Quando la gente chiede cosa l'IA “sostituisce” nello sviluppo, spesso pensa ai compiti: scrivere una funzione, generare test, redigere documentazione. I team, però, non spediscono compiti: spediscono risultati. Qui è dove le responsabilità degli sviluppatori contano.
Il pacchetto usuale di responsabilità
Il lavoro di uno sviluppatore normalmente va oltre il tempo di scrivere codice:
- Delivery: trasformare un'idea vaga in software funzionante che viene rilasciato in tempo.
- Qualità: correttezza, manutenibilità e prevenzione delle regressioni.
- Sicurezza e privacy: impostazioni sicure di default, gestione dei dati e consapevolezza delle minacce.
- Operazioni: mantenere i servizi in funzione, capire le modalità di fallimento e rispondere agli incidenti.
- Comunicazione: allinearsi con prodotto, design, supporto e altri ingegneri.
Queste responsabilità attraversano tutto il ciclo di vita—from “cosa dovremmo costruire?” a “è sicuro?” fino a “che succede alle 3 del mattino quando si rompe?”.
Perché non è una checklist
Ogni responsabilità è in realtà molte piccole decisioni: quali edge case contano, quali metriche indicano salute, quando tagliare il scope, se una correzione è sicura da rilasciare, come spiegare un compromesso agli stakeholder. L'IA può aiutare a eseguire parti di questo lavoro (bozze di codice, proporre test, riassumere log), ma la responsabilità riguarda possedere il risultato.
Dove falliscono i passaggi di consegna
I guasti spesso avvengono ai confini di handoff:
- “Lo QA lo troverà” (ma nessuno ha definito cosa significa qualità).
- “La security lo esaminerà” (ma il design ha già fissato scelte rischiose).
- “Ops lo gestirà” (ma il servizio non è stato costruito per essere operabile).
Quando la proprietà è poco chiara, il lavoro cade nelle fessure.
Diritti decisionali: chi decide vs chi esegue
Un modo utile per parlare di responsabilità è i diritti decisionali:
- Chi decide requisiti, compromessi e rischio accettabile?
- Chi esegue implementazione e verifica?
L'IA può accelerare l'esecuzione. I diritti decisionali—e l'accountability per i risultati—hanno ancora bisogno di un nome umano accanto.
Lavori che l'IA può spesso sostituire (con guardrail)
Gli assistenti di programmazione sono davvero utili quando il lavoro è prevedibile, a basso impatto e facile da verificare. Considerali come un compagno junior veloce: ottimo per una prima versione, ma sempre bisognoso di istruzioni chiare e controlli attenti.
Nella pratica, alcuni team usano sempre più piattaforme di “vibe-coding” (come Koder.ai) per accelerare questi pezzi sostituibili: generare scaffold, collegare flussi CRUD e produrre bozze iniziali di UI e codice backend dalla chat. La chiave resta la stessa: guardrail, revisione e proprietà chiara.
Boilerplate a basso rischio
Molto tempo degli sviluppatori va nello scaffolding di progetti e nell'incollare i pezzi. L'IA può spesso generare:
- file e cartelle starter (controller, route, DTO)
- “glue code” ripetitivo tra i layer
- endpoint CRUD semplici che seguono un pattern stabilito
Il guardrail qui è la coerenza: assicurati che si allinei alle convenzioni esistenti e non inventi nuovi pattern o dipendenze.
Refactor e migrazioni meccaniche
Quando una modifica è per lo più meccanica—rinominare un simbolo su tutto il codice, riformattare o aggiornare un'API in modo lineare—l'IA può accelerare il lavoro ripetitivo.
Trattalo comunque come una modifica massiva: esegui l'intera suite di test, esamina i diff per comportamenti non intenzionali ed evita che “migliori” oltre il refactor richiesto.
Bozze di documentazione (con revisione)
L'IA può redigere README, commenti inline e note di changelog basandosi su codice e messaggi di commit. Questo può accelerare la chiarezza, ma può anche produrre imprecisioni convincenti.
Buona pratica: usa l'IA per struttura e fraseggio, poi verifica ogni affermazione—soprattutto passaggi di setup, default di configurazione e casi limite.
Generazione base di test come punto di partenza
Per funzioni pure e ben specificate, test unitari generati dall'IA possono fornire copertura iniziale e ricordare edge case. Il guardrail è la proprietà: scegli tu cosa conta, aggiungi asserzioni che riflettano requisiti reali e assicurati che i test falliscano per le ragioni giuste.
Riepiloghi di thread e log
Con thread lunghi su Slack, ticket o log di incidenti, l'IA può trasformarli in note concise e azioni. Mantienilo ancorato fornendo il contesto completo e verificando fatti chiave, timestamp e decisioni prima di condividerli.
Lavori che l'IA soprattutto potenzia: più veloce, non finito
Gli assistenti di programmazione sono al meglio quando sai già cosa vuoi e hai bisogno di aiuto per avanzare più velocemente. Possono ridurre il tempo di “digitazione” e portare contesto utile, ma non eliminano la necessità di proprietà, verifica e giudizio.
Accelerare l'implementazione (una solida prima bozza)
Con una specifica chiara—input, output, casi limite e vincoli—l'IA può mettere giù un'implementazione di partenza: boilerplate, mapping dati, handler API, migrazioni o un refactor semplice. Il vantaggio è lo slancio: ottieni qualcosa di eseguibile rapidamente.
Il rovescio è che il codice di prima bozza spesso manca requisiti sottili (semantiche di errore, vincoli di performance, compatibilità a ritroso). Trattalo come la bozza di un intern: utile, ma non autorevole.
Proporre opzioni—with trade-off da convalidare
Quando scegli tra approcci (caching vs batching, locking ottimistico vs pessimistico), l'IA può proporre alternative e elencare compromessi. È utile per il brainstorming, ma i compromessi devono essere verificati rispetto alla realtà del tuo sistema: forma del traffico, necessità di consistenza dei dati, vincoli operativi e convenzioni del team.
Comprensione del codice e navigazione del codebase
L'IA è valida anche per spiegare codice poco familiare, evidenziare pattern e tradurre “cosa fa questo?” in linguaggio semplice. Accoppiata a strumenti di ricerca, può aiutare a rispondere “Dove viene usato X?” e generare una lista di impatto di siti chiamanti, config e test da riesaminare.
Ergonomia dello sviluppatore: cicli di feedback migliori
Aspettati miglioramenti pratici di qualità della vita: messaggi di errore più chiari, piccoli esempi e snippet pronti da incollare. Riduce l'attrito, ma non sostituisce revisioni attente, esecuzioni locali e test mirati—specialmente per cambiamenti che toccano utenti o sistemi di produzione.
Comprensione del prodotto e requisiti: ancora guidati da umani
L'IA può aiutare a scrivere e raffinare requisiti, ma non può decidere affidabilmente cosa dovremmo costruire o perché è importante. La comprensione del prodotto è radicata nel contesto: obiettivi di business, dolore utente, vincoli organizzativi, casi limite e costo di sbagliare. Quegli input vivono in conversazioni, storici e accountability—cose che un modello può riassumere, ma non possedere.
Le richieste iniziali spesso suonano come “Rendi l'onboarding più fluido” o “Riduci ticket di supporto.” Il lavoro dello sviluppatore è tradurre questo in requisiti chiari e criteri di accettazione.
Quella traduzione è per lo più lavoro umano perché dipende da domande esplorative e giudizio:
- Quale segmento di utenti stiamo ottimizzando e quale comportamento dovrebbe cambiare?
- Quando si può dire “fatto” e come lo misuriamo?
- Quali vincoli sono non negoziabili (privacy, performance, scadenze)?
L'IA può suggerire metriche o bozzare criteri di accettazione, ma non saprà quali vincoli sono reali a meno che qualcuno non li fornisca—e non farà obiezioni quando una richiesta è auto-contraddittoria.
Compromessi e gestione delle aspettative
Il lavoro sui requisiti è dove emergono compromessi scomodi: tempo vs qualità, velocità vs manutenibilità, nuove funzionalità vs stabilità. I team hanno bisogno di una persona che renda espliciti i rischi, proponga opzioni e allinei gli stakeholder sulle conseguenze.
Una buona specifica non è solo testo; è un registro decisionale. Deve essere testabile e implementabile, con definizioni nette (input, output, casi limite e modalità di fallimento). L'IA può aiutare a strutturare il documento, ma la responsabilità della correttezza—e del dire “questo è ambiguo, serve una decisione”—resta agli umani.
Progettazione di sistema e decisioni architetturali
La progettazione di sistema è dove “cosa dobbiamo costruire?” diventa “su cosa lo costruiamo, e come si comporterà quando qualcosa va storto?” L'IA può aiutare a esplorare opzioni, ma non può assumersi le conseguenze.
Scegliere un'architettura che si adatti alla realtà
Scegliere tra monolite, modular monolith, microservizi, serverless o piattaforme gestite non è un quiz con una sola risposta giusta. È un problema di adattamento: scala prevista, limiti di budget, time-to-market e competenze del team.
Un assistente può riassumere pattern e suggerire architetture di riferimento, ma non saprà che il tuo team fa on-call settimanale, che l'assunzione è lenta o che il contratto del tuo vendor DB scade il prossimo trimestre. Sono quei dettagli che spesso decidono il successo di un'architettura.
Esplicitare i compromessi
La buona architettura è per lo più compromessi: semplicità vs flessibilità, performance vs costo, velocità oggi vs manutenibilità dopo. L'IA può produrre rapidamente elenchi pro/contro, il che è utile—soprattutto per documentare decisioni.
Quel che non può fare è fissare priorità quando i compromessi danneggiano. Per esempio, “accettiamo risposte leggermente più lente per mantenere il sistema più semplice e operativo” è una scelta di business, non solo tecnica.
Confini, proprietà dei dati e modalità di fallimento
Definire confini di servizio, chi possiede quali dati e cosa succede durante outage parziali richiede profondo contesto di prodotto e operativo. L'IA può aiutare a pensare ai failure mode (“cosa succede se il provider di pagamenti è giù?”), ma servono umani per decidere comportamento atteso, messaggistica ai clienti e piani di rollback.
API che rimangono usabili
Progettare API è progettare un contratto. L'IA può aiutare a generare esempi e individuare incoerenze, ma devi decidere tu versioning, retrocompatibilità e cosa supportare a lungo termine.
Decidere di non costruire (o di eliminare)
Forse la decisione architetturale più difficile è dire “no”—o cancellare una funzionalità. L'IA non può misurare il costo opportunità o il rischio politico. I team possono e devono farlo.
Debugging e analisi delle cause radice in pratica
Il debugging è dove l'IA spesso sembra impressionante—e dove può sprecare più tempo in silenzio. Un assistente può analizzare log, indicare percorsi di codice sospetti o suggerire una correzione che “sembra giusta.” Ma l'analisi delle cause radice non è solo generare spiegazioni; è dimostrarne una.
L'IA può suggerire; tu confermi la causa radice
Tratta l'output dell'IA come ipotesi, non conclusione. Molti bug hanno cause plausibili multiple, e l'IA tende a scegliere una storia semplice che si adatta allo snippet che hai incollato, non alla realtà del sistema in esecuzione.
Un flusso pratico è:
- Chiedi all'IA possibili cause e quale evidenza le distinguerebbe.
- Riproduci il problema e raccogli quell'evidenza.
- Solo allora accetta una correzione (e verifica che rimuova davvero la condizione di falla).
Riproduzione e raccolta di evidenze restano guidate dall'umano
Riprodurre in modo affidabile è un superpotere del debugging perché trasforma un mistero in un test. L'IA può aiutarti a scrivere un repro minimale, uno script diagnostico o suggerire logging aggiuntivo, ma sei tu a decidere quali segnali contano: request ID, tempistiche, differenze d'ambiente, feature flag, forma dei dati o concorrenza.
Quando gli utenti segnalano sintomi (“l'app si blocca”), devi ancora tradurli in comportamento di sistema: quale endpoint si è fermato, quali timeout sono scattati, quali segnali di error budget sono cambiati. Ciò richiede contesto: come viene usato il prodotto e cosa è “normale”.
Evita spiegazioni “plausibili ma sbagliate”
Se un suggerimento non è convalidabile, assumilo sbagliato finché non dimostrato il contrario. Preferisci spiegazioni che formulino una previsione testabile (es., “accade solo con payload grandi” o “solo dopo il warm-up della cache”).
Patch, revert o riprogettare?
Anche dopo aver trovato la causa, resta la decisione difficile. L'IA può delineare i compromessi, ma gli umani scelgono la risposta:
- Patch veloce per fermare il sanguinamento.
- Revert per ripristinare un comportamento noto e funzionante.
- Riprogettare se il fallimento rivela un mismatch più profondo (performance, modello dati o assunzioni).
L'analisi delle cause radice è infine accountability: possedere la spiegazione, la correzione e la fiducia che non tornerà.
Code review: giudizio e standard non si automatizzano
La code review non è solo una checklist per stile. È il momento in cui un team decide ciò che è disposto a mantenere, supportare e di cui essere responsabile. L'IA può aiutarti a vedere di più, ma non può decidere cosa conta, cosa si adatta all'intento del prodotto o quali compromessi il team accetta.
Cosa l'IA fa bene nelle review
Gli assistenti di programmazione possono comportarsi come un paio d'occhi instancabili. Possono rapidamente:
- Segnalare bug probabili, pattern sospetti, mancanze di null check o gestione non sicura delle stringhe.
- Suggerire nomi più chiari, refactor o flussi di controllo più semplici.
- Evidenziare formattazione incoerente o duplicazioni ovvie.
- Generare domande di revisione (“Cosa succede se questa API restituisce una lista vuota?”).
Usata così, l'IA accorcia il tempo tra “ho aperto la PR” e “ho notato il rischio.”
Ciò che richiede ancora giudizio umano
Revisionare per correttezza non riguarda solo se il codice compila. Gli umani collegano le modifiche al comportamento reale degli utenti, ai vincoli di produzione e alla manutenzione a lungo termine.
Un revisore deve ancora decidere:
- Cosa rilasciare: l'IA può elencare problemi, ma non può scegliere quali sono bloccanti per il rilascio.
- Leggibilità e manutenibilità: il codice “tecnicamente corretto” può essere comunque confuso, fragile o difficile da estendere.
- Casi limite e gap d'ambiente: molti fallimenti sono “funziona sulla mia macchina”—configurazione, dati, concorrenza o timing di deploy. L'IA non può inferire affidabilmente la tua realtà di runtime.
- Standard e intento: solo il team conosce convenzioni, tolleranza al rischio e obiettivi di prodotto. Una modifica può essere codice pulito e comunque comportamento sbagliato.
Un flusso pratico: l'IA come co‑revisore
Tratta l'IA come un secondo revisore, non come approvatore finale. Chiedile un passaggio mirato (controlli di sicurezza, casi limite, retrocompatibilità), poi prendi la decisione umana su scope, priorità e allineamento con gli standard del team.
Strategia di test e proprietà della qualità
Gli assistenti di programmazione possono generare test rapidamente, ma non possiedono la qualità. Una suite di test è un insieme di scommesse su cosa può rompersi, cosa non deve mai rompersi e su cosa sei disposto a spedire senza provare ogni caso. Quelle scommesse sono decisioni di prodotto e ingegneria—ancora prese da persone.
L'IA può bozzare test; gli umani fissano gli obiettivi
Gli assistenti sono bravi a produrre scaffolding per test unitari, mocking e coprire i percorsi “happy path” dalla implementazione. Ciò che non può fare in modo affidabile è decidere quale copertura conta.
Gli umani definiscono:
- quali moduli richiedono copertura profonda perché critici o frequentemente modificati;
- cosa significa “fatto” per un refactor rischioso vs. una piccola correzione;
- quando investire in test di regressione vs. monitoraggio e piani di rollback.
Scegliere il giusto mix di tipi di test
La maggior parte dei team ha bisogno di una strategia stratificata, non di “più test”. L'IA può aiutare a scriverne molti, ma la selezione e i confini restano guidati dagli umani:
- Unit test per regole di business e casi limite intricati.
- Integration test per interazioni DB/code/queue/service.
- End-to-end per percorsi utente critici (pochi, stabili, ad alto valore).
- Contract test per mantenere compatibilità tra team/servizi.
- Performance test per proteggere latenza e costo sotto carico.
Evitare test fragili e falsa fiducia
I test generati dall'IA spesso rispecchiano troppo il codice, creando asserzioni brittle o setup eccessivamente mockato che passano anche quando il comportamento reale fallisce. Gli sviluppatori lo prevengono:
- testando comportamento osservabile, non dettagli interni di implementazione;
- mantenendo dati deterministici e controllando tempo, casualità e chiamate di rete;
- esaminando i fallimenti per decidere: bug reale, bug del test o problema d'ambiente.
Allineare la strategia a rischio e cadenza di rilascio
Una buona strategia si adatta a come rilasci. Rilasci più rapidi richiedono controlli automatizzati più forti e chiare vie di rollback; rilasci lenti possono permettersi validazioni più pesanti prima del merge. Il proprietario della qualità è il team, non lo strumento.
Misurare gli esiti che contano
La qualità non è una percentuale di coverage. Monitora se i test migliorano i risultati: meno incidenti in produzione, recupero più veloce e cambiamenti più sicuri (rollback più piccoli, deploy più fiduciosi). L'IA può velocizzare il lavoro, ma la responsabilità resta agli sviluppatori.
Sicurezza, privacy e compliance
Il lavoro di sicurezza riguarda meno la generazione di codice e più il prendere compromessi sotto vincoli reali. L'IA può far emergere checklist e errori comuni, ma la decisione sul rischio resta del team.
Threat modeling richiede contesto
Il threat modeling non è un esercizio generico—ciò che conta dipende dalle priorità di business, dagli utenti e dalle modalità di fallimento. Un assistente può suggerire minacce tipiche (injection, auth rotta, default insicuri), ma non saprà quale tipo di incidente è davvero costoso per il tuo prodotto: takeover di account vs perdita di dati vs interruzione del servizio, né quali asset sono legalmente sensibili.
I rischi specifici dell'app non sono pattern riconoscibili
L'IA individua anti-pattern noti, ma molti incidenti nascono da dettagli applicativi: un edge case di permessi, un endpoint admin “temporaneo” o un workflow che aggira approvazioni. Questi rischi richiedono di leggere l'intento del sistema, non solo il codice.
Segreti, permessi e retention sono scelte intenzionali
Gli strumenti possono ricordare di non hardcodare chiavi, ma non possono possedere la policy completa:
- dove risiedono i segreti (vault, CI, runtime) e come ruotano;
- ruoli a least-privilege e revisioni di accesso;
- retention dei dati: cosa conservi, per quanto e chi può esportarlo.
Dipendenze e rischio della supply chain
L'IA può segnalare librerie obsolete, ma i team devono mantenere pratiche: fissare versioni, verificare provenienza, rivedere dipendenze transitive e decidere quando accettare il rischio o investire nella mitigazione.
Compliance e audit richiedono evidenza
La compliance non è “aggiungi cifratura.” Sono controlli, documentazione e responsabilità: log di accesso, tracce di approvazione, procedure per incidenti e prove che le hai seguite. L'IA può redigere template, ma gli umani devono convalidare le evidenze e firmare—perché auditor e clienti si basano su quelle firme.
Operazioni, affidabilità e risposta agli incidenti
L'IA può rendere il lavoro operativo più veloce, ma non ne prende possesso. L'affidabilità è una catena di decisioni sotto incertezza, e il costo di una scelta sbagliata è spesso più alto del costo di una scelta lenta.
Dove l'IA aiuta nella quotidianità
L'IA è utile per redigere e mantenere artefatti operativi—runbook, checklist e playbook “se X allora prova Y”. Può anche riassumere log, raggruppare alert simili e proporre ipotesi di primo livello.
Per l'affidabilità, questo si traduce in iterazioni più veloci su:
- dashboard di monitoraggio e descrizioni degli alert;
- note di capacità e euristiche di scaling;
- template per report sull'error budget.
Sono acceleratori eccellenti, ma non sono il lavoro stesso.
Le parti che restano possedute dagli umani
Gli incidenti raramente seguono lo script. Gli ingegneri on-call si confrontano con segnali poco chiari, guasti parziali e compromessi disordinati mentre il tempo scorre. L'IA può suggerire cause probabili, ma non può decidere con affidabilità se chiamare un altro team, disabilitare una funzionalità o accettare impatto cliente a breve termine per preservare l'integrità dei dati.
La sicurezza del deploy è un'altra responsabilità umana. Gli strumenti possono raccomandare rollback, feature flag o rilasci graduali, ma i team devono scegliere il percorso più sicuro dato il contesto aziendale e il blast radius.
Postmortem: l'apprendimento è l'obiettivo
L'IA può redigere timeline e estrarre eventi chiave da chat, ticket e monitoraggio. Gli umani fanno ancora le parti critiche: decidere cosa è “buono”, prioritizzare le correzioni e applicare cambiamenti che prevengano il ripetersi (non solo lo stesso sintomo).
Se tratti l'IA come copilota per la documentazione operativa e il finding di pattern—not un comandante d'incidente—otterrai velocità senza cedere accountability.
Comunicazione del team, mentoring e proprietà
L'IA può spiegare concetti in modo chiaro e on demand: “Cos'è CQRS?”, “Perché avviene questo deadlock?”, “Riassumi questa PR.” Questo aiuta i team a muoversi più velocemente. Ma la comunicazione sul lavoro non è solo trasferire informazioni—serve costruire fiducia, stabilire abitudini condivise e prendere impegni sui quali le persone possono contare.
Onboarding: più della documentazione
I nuovi sviluppatori non hanno bisogno solo di risposte; hanno bisogno di contesto e relazioni. L'IA può aiutare riassumendo moduli, suggerendo percorsi di lettura e traducendo gergo. Gli umani devono insegnare cosa conta qui: quali compromessi il team preferisce, cosa significa “buono” in questo codebase e con chi parlare quando qualcosa sembra fuori posto.
Allineamento tra ruoli
La maggior parte delle frizioni di progetto appare tra ruoli: prodotto, design, QA, security, support. L'IA può redigere note di riunione, proporre criteri di accettazione o riformulare feedback in modo più neutro. Le persone devono però negoziare priorità, risolvere ambiguità e notare quando uno stakeholder “accetta” senza aver realmente accettato.
Definizione di fatto e confini di proprietà
I team falliscono quando la responsabilità è sfocata. L'IA può generare checklist, ma non può imporre accountability. Gli umani devono definire cosa significa “fatto” (test? docs? piano di rollout? monitoraggio?) e chi possiede cosa dopo il merge—specialmente quando il codice generato dall'IA nasconde complessità.
Checklist: uso responsabile dell'IA nei workflow di team
- Dichiara l'uso dell'IA quando influisce su decisioni, stime o codice generato.
- Verifica i fatti: link, API, affermazioni di sicurezza e “best practice” prima di condividere.
- Tieni i prompt liberi da segreti (chiavi, dati cliente, dettagli di incidenti).
- Tratta gli output dell'IA come bozze; assegna un proprietario umano per ogni decisione.
- Documenta le norme di team: quando l'IA è permessa, quando no, e rivedi le aspettative.
- Preferisci cambiamenti piccoli e revisionabili—evita refactor “big bang” generati dall'IA.