29 nov 2025·8 min
Come costruire un'app web per gestire i feedback dei clienti
Scopri come progettare e costruire un'app web che raccolga, instradi, tracci e chiuda i feedback clienti con workflow, ruoli e metriche chiari.
Scopri come progettare e costruire un'app web che raccolga, instradi, tracci e chiuda i feedback clienti con workflow, ruoli e metriche chiari.
Un'app per la gestione dei feedback non è “un posto dove conservare messaggi”. È un sistema che aiuta il tuo team a passare in modo affidabile da input a azione a follow-up visibile al cliente, e poi a imparare da ciò che è successo.
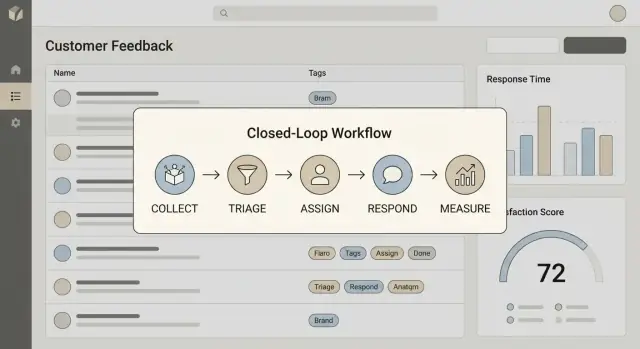
Scrivete una definizione in una frase che il team possa ripetere. Per la maggior parte dei team, chiudere il loop comprende quattro passi:
Se uno di questi passaggi manca, la tua app diventerà una fossa di backlog.
La prima versione dovrebbe servire ruoli reali, giorno per giorno:
Siate specifici sui “decisions per click”:
Scegliete un piccolo set di metriche che riflettano velocità e qualità, come tempo alla prima risposta, tasso di risoluzione, e variazione CSAT dopo il follow‑up. Queste diventano la vostra stella polare per scelte di design successive.
Prima di progettare schermate o scegliere un database, mappate cosa succede al feedback dal momento in cui viene creato fino alla risposta. Una mappa del journey semplice mantiene i team allineati su cosa significhi “fatto” e vi evita di costruire funzionalità che non si adattano al lavoro reale.
Elencate le fonti di feedback e annotate quali dati ciascuna fornisce in modo affidabile:
Anche se gli input differiscono, la vostra app dovrebbe normalizzarli in una forma consistente di “feedback item” così i team possono triagare tutto in un unico posto.
Un modello pratico di partenza include solitamente:
Status con cui iniziare: New → Triaged → Planned → In Progress → Shipped → Closed. Tenete i significati degli status scritti in modo che “Planned” non significhi “Forse” per un team e “Committed” per un altro.
I duplicati sono inevitabili. Definite le regole presto:
Un approccio comune è mantenere un feedback item canonico e collegare gli altri come duplicati, preservando l'attribuzione (chi lo ha chiesto) senza frammentare il lavoro.
Un'app per il feedback ha successo o fallisce dal giorno uno in base a quanto le persone riescono a processare il feedback rapidamente. Puntate a un flusso che sembri: “scorri → decidi → vai avanti”, pur preservando il contesto per decisioni successive.
La vostra inbox è la coda condivisa del team. Deve supportare un triage rapido tramite un piccolo insieme di filtri potenti:
Aggiungete presto “Saved views” (anche se basiche), perché i team scansionano in modo diverso: Support vuole “urgent + paying”, Product vuole “feature requests + high ARR”.
Quando un utente apre un elemento, dovrebbe vedere:
L'obiettivo è evitare di cambiare tab solo per rispondere: “Chi è, cosa voleva dire e abbiamo già risposto?”.
Dalla vista dettaglio, il triage dovrebbe richiedere un click per decisione:
Probabilmente vi serviranno due modalità:
Qualunque sia la scelta, rendete “rispondere con il contesto” il passo finale—così chiudere il loop è parte del workflow, non un ripensamento.
Un'app di feedback diventa in fretta un sistema condiviso di record: product vuole temi, support risposte rapide, leadership esportazioni. Se non definite chi può fare cosa (e non dimostrate cosa è successo), la fiducia si rompe.
Se servirete più aziende, trattate ogni workspace/org come un confine rigido fin dal primo giorno. Ogni record core (feedback item, customer, conversation, tag, report) dovrebbe includere un workspace_id, e ogni query dovrebbe essere scansionata su di esso.
Questo non è solo un dettaglio di DB—influenza URL, inviti e analytics. Un default sicuro: gli utenti appartengono a uno o più workspace e i permessi vengono valutati per workspace.
Mantenete la prima versione semplice:
Poi mappate i permessi alle azioni, non alle schermate: view vs edit feedback, merge duplicates, cambiare status, esportare dati e inviare risposte. Questo rende più facile aggiungere un ruolo “Read‑only” dopo senza riscrivere tutto.
Un audit log evita i dibattiti “chi ha cambiato questo?”. Loggate eventi chiave con actor, timestamp e before/after quando utile:
Applicate una policy password ragionevole, proteggete gli endpoint con rate limiting (soprattutto login e ingestion) e gestite le sessioni in modo sicuro.
Progettate pensando all'SSO (SAML/OIDC) anche se lo rilasciate dopo: conservate un ID provider e pianificate l'account linking. Questo evita che richieste enterprise forzino un refactor doloroso.
All'inizio, il rischio architetturale più grande non è “si scalerà?”—è “riusciremo a cambiarla rapidamente senza rompere tutto?”. Un'app di feedback evolve velocemente mentre imparate come i team triagano, instradano e rispondono.
Un monolite modulare è spesso la scelta migliore per partire. Avete un solo servizio deployabile, un set di log e debug più semplice—pur mantenendo il codice organizzato.
Una divisione modulare pratica:
Pensate “cartelle separate e interfacce” prima di “servizi separati”. Se un confine diventa doloroso più avanti (es. volume di ingest elevato), lo potete estrarre con meno drammi.
Preferite framework e librerie che il team conosce e con cui può consegnare con sicurezza. Uno stack “noioso” e noto vince spesso perché:
Strumenti nuovi possono aspettare finché non avrete limiti reali (alto ingest, latenze stringenti, permessi complessi). Fino ad allora, ottimizzate per chiarezza e consegne costanti.
La maggior parte delle entità core—feedback items, customers, accounts, tag, assignments—si adatta naturalmente a un database relazionale. Volete buone query, vincoli e transazioni per i cambi workflow.
Se la ricerca full‑text e i filtri diventano importanti, aggiungete un indice di ricerca dedicato più avanti (o usate capacità built‑in all'inizio). Evitate di costruire due fonti di verità troppo presto.
Un sistema di feedback accumula subito lavoro “da fare in seguito”: invio email, sync integrazioni, processare allegati, generare digest, inviare webhook. Mettete questi compiti in una coda/worker in background fin dall'inizio.
Questo mantiene l'UI reattiva, riduce timeout e rende i fallimenti retryable—senza costringervi ai microservizi dal giorno uno.
Se l'obiettivo è validare workflow e UI rapidamente (inbox → triage → risposte), considerate l'uso di una piattaforma di prototipazione come Koder.ai per generare la prima versione da uno spec strutturato in chat. Può aiutarvi a mettere su un front end React con backend Go + PostgreSQL, iterare in “planning mode” e comunque esportare il codice sorgente quando sarete pronti a passare a un workflow ingegneristico classico.
Il layer di storage decide se il vostro feedback loop sembra veloce e affidabile—o lento e confuso. Puntate a uno schema facile da interrogare per il lavoro quotidiano (triage, assegnazione, status), preservando abbastanza dettaglio raw per l'audit.
Per un MVP, potete coprire la maggior parte delle esigenze con poche tabelle/collection:
Una regola utile: mantenere feedback snello (ciò che interrogate costantemente) e spostare il “tutto il resto” in events e metadata specifici per canale.
Quando un ticket arriva via email, chat o webhook, conservate il payload raw esattamente com'è ricevuto (es. header email + body originali, o webhook JSON). Questo vi aiuta a:
Pattern comune: una tabella ingestions con source, received_at, raw_payload (JSON/text/blob) e un link al feedback_id creato/aggiornato.
La maggior parte delle schermate si riduce a pochi filtri prevedibili. Aggiungete indici presto per:
(workspace_id, status) per inbox/kanban view(workspace_id, assigned_to) per “my items”(workspace_id, created_at) per ordinamento e filtri per data(tag_id, feedback_id) sulla join table o un indice dedicato per lookup tagSe supportate la ricerca full‑text, considerate un indice di ricerca separato (o la ricerca testuale integrata del DB) invece di appesantire il production con complessi LIKE.
I feedback spesso contengono dati personali. Decidete da subito:
Implementate la retention come policy per workspace (es. 90/180/365 giorni) e applicatela con un job schedulato che scada prima gli ingestions raw, poi eventi/replies più vecchi se necessario.
L'ingest è il punto in cui il vostro feedback loop rimane pulito e utile—o diventa un groviglio. Mirate a “facile da inviare, coerente da processare.” Iniziate con pochi canali che i clienti già usano, poi espandete.
Un set pratico iniziale include solitamente:
Non vi serve un filtering pesante dal giorno uno, ma servono protezioni di base:
Normalizzate ogni evento in un formato interno con campi consistenti:
Conservate sia il raw payload sia il record normalizzato così potete migliorare il parser senza perdere dati.
Inviate una conferma immediata (per email/API/widget quando possibile): ringraziate, spiegate cosa succede dopo e evitate promesse. Esempio: “Revisiamo ogni messaggio. Se servono dettagli, risponderemo. Non possiamo rispondere individualmente a tutte le richieste, ma il tuo feedback è tracciato.”
Un'inbox di feedback resta utile solo se i team possono rispondere rapidamente a tre domande: Cos'è questo? Chi lo possiede? Quanto è urgente? Il triage è la parte dell'app che trasforma messaggi grezzi in lavoro organizzato.
I tag freeform sembrano flessibili, ma si frammentano in fretta (“login”, “log-in”, “signin”). Partite con una tassonomia controllata e piccola che rispecchi come i team di prodotto già pensano:
Consentite agli utenti di suggerire nuovi tag, ma richiedete un owner (es. PM/Support lead) per approvarli. Questo mantiene i report significativi più avanti.
Costruite un semplice motore di regole che possa instradare automaticamente il feedback basandosi su segnali prevedibili:
Tenete le regole trasparenti: mostrate “Routed because: Enterprise plan + keyword ‘SSO’.” I team si fidano dell'automazione quando possono verificarla.
Aggiungete timer SLA a ogni item e a ogni coda:
Mostrate lo stato SLA nella lista (“2h left”) e nella pagina dettaglio, così l'urgenza è condivisa tra il team—non rinchiusa nella testa di qualcuno.
Create un percorso chiaro quando gli elementi stagnano: una coda overdue, digest giornalieri agli owner, e una ladder di escalation leggera (Support → Team lead → On‑call/Manager). L'obiettivo non è pressione—è evitare che feedback importanti scadano silenziosamente.
Chiudere il loop è il punto in cui un sistema di gestione dei feedback smette di essere una “cassetta di raccolta” e diventa uno strumento per costruire fiducia. L'obiettivo è semplice: ogni feedback può essere collegato a lavoro reale, e i clienti che lo hanno richiesto possono sapere cosa è successo—senza fogli di calcolo manuali.
Iniziate permettendo a un singolo feedback item di puntare a uno o più oggetti di lavoro interni (bug, task, feature). Non cercate di replicare tutto l'issue tracker—conservate riferimenti leggeri:
work_type (es. issue/task/feature)external_system (es. jira, linear, github)external_id e opzionalmente external_urlQuesto mantiene il vostro modello dati stabile anche se cambiate strumenti più avanti. Abilita anche viste come “mostrami tutti i feedback cliente legati a questo rilascio” senza scraping.
Quando il lavoro collegato passa a Shipped (o Done/Released), la vostra app dovrebbe poter notificare tutti i clienti attaccati agli item correlati.
Usate un messaggio template con placeholder sicuri (nome, product area, sommario, link note di rilascio). Mantenevelo editabile al momento dell'invio per evitare formulazioni imbarazzanti. Se avete note pubbliche, linkatele usando un percorso relativo come /releases.
Supportate risposte tramite il canale che potete inviare in modo affidabile:
Qualunque sia la scelta, tracciate le risposte per feedback item con una timeline auditabile: sent_at, channel, author, template_id e stato di delivery. Se un cliente risponde, conservate anche i messaggi inbound con timestamp, così il team può dimostrare che il loop è stato effettivamente chiuso—non solo “marcato come shipped”.
I report sono utili solo se cambiano ciò che i team fanno dopo. Puntate a poche viste che le persone possano controllare quotidianamente, poi espandete quando siete sicuri che i dati di workflow sottostanti (status, tag, owner, timestamp) siano coerenti.
Iniziate con dashboard operative che supportino routing e follow‑up:
Mantenete i grafici semplici e cliccabili così un manager può approfondire gli item che compongono un picco.
Aggiungete una pagina “customer 360” che aiuti support e success a rispondere con contesto:
Questa vista riduce domande duplicate e rende i follow‑up intenzionali.
I team chiederanno esportazioni presto. Fornite:
Fate in modo che i filtri siano coerenti ovunque (stessi nomi tag, range date, definizioni status). Questa coerenza evita “due versioni della verità”.
Saltate le dashboard che misurano solo attività (ticket creati, tag aggiunti). Preferite metriche di outcome legate ad azione e risposta: tempo alla prima reply, % di item che hanno raggiunto una decisione, e problemi ricorrenti effettivamente risolti.
Un feedback loop funziona solo se vive dove le persone già passano tempo. Le integrazioni riducono copia/incolla, mantengono il contesto vicino al lavoro e rendono “chiudere il loop” un'abitudine invece che un progetto speciale.
Prioritizzate i sistemi che il team usa per comunicare, costruire e tracciare i clienti:
Tenete la prima versione semplice: notifiche one‑way + deep link alla vostra app, poi aggiungete azioni write‑back (es. “Assign owner” da Slack) più tardi.
Anche se rilasciate poche integrazioni native, i webhooks permettono a clienti e team interni di connettere qualsiasi altra cosa.
Offrite un set piccolo e stabile di eventi:
feedback.createdfeedback.updatedfeedback.closedIncludete una idempotency key, timestamp, tenant/workspace id e un payload minimo più un URL per recuperare i dettagli completi. Questo evita di rompere i consumer quando evolve il modello dati.
Le integrazioni falliscono per motivi normali: token revocati, rate limit, problemi di rete, mismatch di schema.
Progettate per questo:
Se vendete questo come prodotto, le integrazioni sono anche un trigger d'acquisto. Aggiungete passi chiari dall'app (e dal sito marketing) a /pricing e /contact per team che vogliono demo o aiuto a connettere lo stack.
Un'app di feedback efficace non è “finta” subito dopo il lancio—viene modellata da come i team triagano, agiscono e rispondono. L'obiettivo della prima release è semplice: provare il workflow, ridurre il lavoro manuale e catturare dati puliti e affidabili.
Tenete lo scope ristretto per riuscire a spedire e imparare. Un MVP pratico include di solito:
Se una feature non aiuta un team a processare feedback end‑to‑end, può aspettare.
Gli early users perdonano funzionalità mancanti, ma non feedback persi o routing errato. Focalizzate i test dove gli errori costano:
Puntate a fiducia nel workflow, non a coverage perfetta.
Anche un MVP ha bisogno di alcuni elementi “noiosi” essenziali:
Partite con un pilot: un team, un set limitato di canali e una metrica di successo chiara (es. “rispondere al 90% dei feedback high‑priority entro 2 giorni”). Raccogliete punti di attrito settimanalmente, poi iterate il workflow prima di invitare altri team.
Trattate i dati d'uso come roadmap: dove cliccano le persone, dove abbandonano, quali tag non vengono usati e quali “workaround” rivelano i requisiti reali.
"Chiudere il loop" significa poter passare in modo affidabile da Collect → Act → Reply → Learn. In pratica, ogni elemento di feedback dovrebbe concludersi con un risultato visibile (shipped, declined, explained o queued) e—quando appropriato—una risposta rivolta al cliente con una tempistica.
Inizia con metriche che riflettano velocità e qualità:
Scegli un piccolo set per evitare che i team ottimizzino per metriche di vanità.
Normalizza tutto in un unico formato interno “feedback item”, mantenendo però i dati originali.
Approccio pratico:
Così il triage resta coerente e puoi riprocessare messaggi vecchi quando migliori il parser.
Mantieni il modello core semplice e ottimizzato per le query:
Annotate una breve definizione condivisa degli status e iniziate con una sequenza lineare:
Assicuratevi che ogni stato risponda a “che succede dopo?” e “chi è responsabile del prossimo passo?”. Se “Planned” varia di significato, dividetelo o rinominatelo per mantenere report affidabili.
Definite duplicati come “stesso problema/ richiesta sottostante”, non solo testi simili.
Workflow comune:
Questo evita il lavoro frammentato mantenendo un record completo della domanda.
Mantieni l'automazione semplice e auditabile:
Mostra sempre “Routed because…” così gli umani possono fidarsi e correggere. Parti con suggerimenti o predefiniti prima di applicare routing rigido.
Trattate ogni workspace come un confine rigoroso:
workspace_id a ogni record coreworkspace_idPoi definite ruoli per azioni (view/edit/merge/export/send replies), non per schermate. Aggiungete un audit log fin da subito per cambi di stato, merge, assegnazioni e risposte.
Partite con un monolite modulare e confini chiari (auth/orgs, feedback, workflow, messaging, analytics). Usate un DB relazionale per i dati transazionali del workflow.
Aggiungete job in background presto per:
Questo mantiene l'UI veloce e gli errori retryable senza impegnarsi subito nei microservizi.
Conserva riferimenti leggeri invece di replicare tutto il tuo issue tracker:
external_system (jira/linear/github)work_type (bug/task/feature)external_id (e opzionalmente external_url)Poi, quando il lavoro collegato è , avvia un workflow per notificare tutti i clienti collegati usando template con placeholder sicuri. Se hai note pubbliche, collegale relativamente (es. ).
Usa la timeline di eventi per auditabilità e per non sovraccaricare il record principale di feedback.
/releases