Cosa stai costruendo: l'app web IDP in parole semplici
Un'app web IDP è la “porta d'ingresso” interna al tuo sistema di ingegneria. È il posto dove gli sviluppatori vanno per scoprire cosa esiste già (servizi, librerie, ambienti), seguire il modo preferito per costruire ed eseguire il software e richiedere modifiche senza cercare tra una dozzina di strumenti.
Non meno importante, non è un altro sostituto tutto-in-uno di Git, CI, console cloud o ticketing. L'obiettivo è ridurre l'attrito orchestrando ciò che già usi—rendendo il percorso giusto il percorso più semplice.
I problemi che dovrebbe risolvere
La maggior parte dei team costruisce un'app web IDP perché il lavoro quotidiano è rallentato da:
- Proliferazione di strumenti: la conoscenza di “dove cliccare” vive nella memoria tribale.
- Onboarding lento: i nuovi ingegneri impiegano settimane a imparare i processi invece di consegnare.
- Standard incoerenti: i servizi vengono creati e gestiti in modi diversi, rendendo più difficile affidabilità e sicurezza.
L'app web dovrebbe trasformare questi aspetti in workflow ripetibili e informazioni chiare e ricercabili.
Componenti fondamentali
Un'app web IDP pratica di solito ha tre parti:
- Portal UI: un catalogo servizi, punti di ingresso alla documentazione e form self-service (es., “crea un servizio”, “richiedi accesso”, “provisiona un database”).
- Backend API: la logica di business che valida le richieste, applica le policy e registra le azioni.
- Integrazioni: connettori alla tua toolchain (hosting Git, CI/CD, tool infrastrutturali, secret manager, gestione incidenti) così le azioni avvengono nei sistemi di record.
Chi lo possiede (e chi no)
Il platform team tipicamente possiede il prodotto portale: l'esperienza, le API, i template e i guardrail.
I product team possiedono i loro servizi: mantenere metadata accurati, documentazione/runbook e adottare i template forniti. Un modello sano è la responsabilità condivisa: il platform team costruisce la strada asfaltata; i product team la percorrono e contribuiscono a migliorarla.
Utenti, casi d'uso e metriche di successo
Un'app web IDP ha successo o fallisce in base a quanto serve le persone giuste con i giusti “percorsi felici”. Prima di scegliere strumenti o disegnare diagrammi architetturali, chiarisci chi userà il portale, cosa vuole ottenere e come misurerai i progressi.
Utenti principali (e cosa li interessa)
La maggior parte dei portali IDP ha quattro pubblici principali:
- Sviluppatori applicativi: vogliono default rapidi e sicuri per creare ed eseguire servizi senza aspettare ticket.
- SRE / ops: vogliono standardizzazione, meno cambi improvvisi e chiara ownership durante gli incidenti.
- Security / compliance: vogliono controlli coerenti (revisioni accessi, gestione segreti, tracce di audit) senza bloccare la delivery.
- Engineering manager / product lead: vogliono visibilità—cosa esiste, chi lo possiede e se i team rilasciano in modo affidabile.
Se non riesci a descrivere come ogni gruppo beneficia in una frase, stai probabilmente costruendo un portale che sembra opzionale.
Mappa 5–10 journey chiave
Scegli i percorsi che accadono settimanalmente (non annualmente) e rendili davvero end-to-end:
- Crea un nuovo servizio da un template (repo + CI + ownership + tag).
- Richiedi un ambiente (dev/stage) con guardrail.
- Visualizza lo stato di salute del servizio (stato deploy, alert, dipendenze).
- Ruota chiavi / segreti con un workflow auditabile.
- Richiedi accesso a un sistema o dataset con approvazioni.
Scrivi ogni journey come: trigger → passi → sistemi coinvolti → risultato atteso → modalità di errore. Questo diventa il tuo backlog prodotto e i criteri di accettazione.
Definisci metriche di successo realmente tracciabili
Buone metriche si collegano direttamente al tempo risparmiato e all'attrito rimosso:
- Time-to-first-deploy per un nuovo servizio (mediana, p90).
- Volume di ticket manuali per richieste comuni (e tempo di risoluzione).
- Tasso di adozione: % di servizi registrati, % di team che usano i template.
- Change failure rate e mean time to restore (se il portale standardizza la delivery).
Scrivi una dichiarazione di scope “versione 1”
Mantienila breve e visibile:
Scope V1: “Un portale che permette agli sviluppatori di creare un servizio da template approvati, registrarlo nel catalogo servizi con un owner e mostrare stato deploy + salute. Include RBAC base e log di audit. Esclude dashboard personalizzate, sostituzione completa del CMDB e workflow su misura.”
Quella dichiarazione è il filtro per il feature-creep e l'ancora della roadmap per ciò che viene dopo.
Scopo MVP e roadmap per un portale interno
Un portale interno ha successo quando risolve un problema doloroso end-to-end, poi guadagna il diritto di espandersi. La via più rapida è un MVP ristretto rilasciato a un team reale in settimane—non in trimestri.
Un MVP ristretto che risulti comunque “completo”
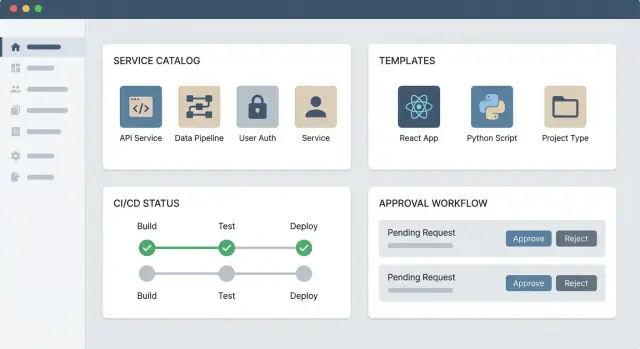
Inizia con tre blocchi fondamentali:
- Catalogo servizi: un posto per scoprire cosa esiste, chi lo possiede e dove si trovano i link operativi.
- Un workflow self-service: scegli una richiesta ad alta frequenza (es., “crea un nuovo repo servizio” o “provisiona un ambiente standard”) e automatizzala.
- Hub docs/link: non migrare tutto—collega le fonti di verità esistenti (CI/CD, strumenti incident, runbook) mentre impari cosa usano davvero le persone.
Questo MVP è piccolo, ma produce un risultato chiaro: “Posso trovare il mio servizio ed eseguire una azione importante senza chiedere su Slack.”
Se vuoi validare rapidamente l'UX e il happy path del workflow, una piattaforma di prototipazione come Koder.ai può essere utile per creare le schermate del portale e le schermate di orchestrazione a partire da uno spec scritto del workflow. Poiché Koder.ai può generare un'app React con backend Go + PostgreSQL e supporta l'export del codice sorgente, i team possono iterare velocemente mantenendo la proprietà a lungo termine del codice.
Struttura del backlog: discover, create, operate, govern
Per mantenere la roadmap organizzata, raggruppa il lavoro in quattro aree:
- Discover: ricerca, tag, ownership, pagine team, viste delle dipendenze.
- Create: template, scaffolding, provisioning ambienti, configurazioni standard.
- Operate: link a dashboard/runbook, info on-call, riepiloghi SLO, azioni comuni.
- Govern: RBAC, passi di approvazione, log di audit, controlli policy.
Questa struttura previene un portale che sia “solo catalogo” o “solo automazione” senza legami tra le parti.
Automatizzare ora vs. link esterni
Automatizza solo ciò che soddisfa almeno uno di questi criteri: (1) si ripete settimanalmente, (2) è soggetto a errori se fatto manualmente, (3) richiede coordinazione multi-team. Tutto il resto può essere un link ben curato allo strumento giusto, con istruzioni chiare e ownership.
Miglioramenti progressivi senza redesign
Progetta il portale in modo che nuovi workflow si colleghino come azioni aggiuntive su una pagina servizio o ambiente. Se ogni nuovo workflow richiede di ripensare la navigazione, l'adozione si bloccherà. Tratta i workflow come moduli: input coerenti, stato coerente, cronologia coerente—in modo da poter aggiungere altro senza cambiare il modello mentale.
Architettura di riferimento: UI, API e integrazioni
Un'architettura pratica mantiene l'esperienza utente semplice mentre gestisce il lavoro “sporco” delle integrazioni dietro le quinte. L'obiettivo è dare agli sviluppatori un'unica app web, anche se le azioni spesso attraversano Git, CI/CD, account cloud, ticketing e Kubernetes.
Scegli un modello di deployment
Ci sono tre pattern comuni, e la scelta giusta dipende dalla velocità di rilascio e da quanti team estenderanno il portale:
- App singola (monolite): MVP più veloce. UI, API e logica integrazione vanno insieme. Buono quando il platform team possiede la maggior parte delle funzionalità.
- Servizi modulari: UI separata, API core e alcuni servizi d'integrazione. Più semplice scalare e chiarire ownership man mano che il portale cresce.
- Basato su plugin: un “core” stabile più plugin per sorgenti catalogo, scaffolding, docs e workflow. Ideale quando molti team contribuiscono funzionalità.
Componenti core (dove girano)
Al minimo, aspettati questi blocchi:
- Web UI (developer portal): navigazione catalogo, golden path, form, pagine di stato.
- Backend API (spesso dietro un API gateway): auth, controlli RBAC, validazione, orchestrazione.
- Integration workers: task lunghi (creazione repo, provisioning) eseguiti in modo asincrono.
- Database: configurazione del portale, viste catalog cache, cronologia dei workflow, eventi di audit.
Dove deve risiedere lo stato
Decidi presto cosa il portale “possiede” rispetto a ciò che mostra soltanto:
- Mantieni la source-of-truth nei sistemi esistenti (Git, cloud IAM, CI/CD, Kubernetes, ticketing).
- Memorizza nel DB del portale: richieste di workflow, stato, approvazioni, log di audit e indici cache che rendono l'UI veloce.
Affidabilità delle integrazioni
Le integrazioni falliscono per motivi normali (rate limit, outage transitori, successi parziali). Progetta per:
- Retry con backoff e messaggi d'errore chiari
- Idempotenza (rilanciare una richiesta non deve creare duplicati)
- Timeout e cancellazione
- Cronologia duratura del workflow così gli utenti vedono cosa è successo e possono recuperare in sicurezza
Modello dati: catalogo servizi e ownership
Il tuo catalogo servizi è la fonte di verità su cosa esiste, chi lo possiede e come si integra nel resto del sistema. Un modello dati chiaro previene “servizi misteriosi”, voci duplicate e automazioni rotte.
Definisci l'entità core “Service”
Inizia concordando cosa significa “service” nella tua organizzazione. Per la maggior parte dei team è un'unità deployabile (API, worker, sito) con un ciclo di vita.
Al minimo, modella questi campi:
- Nome + descrizione (leggibile da umani)
- Owners: team primario, più contatti secondari opzionali (gruppo on-call, tech lead)
- Repository di origine: uno o più link/ID repo
- Ambienti di runtime: dev/stage/prod, o varianti specifiche per regione
- Dipendenze: servizi upstream/downstream e librerie condivise
Aggiungi metadata pratici che alimentano il portale:
- Lifecycle (experimental, active, deprecated)
- Criticality/tier (per aspettative di supporto e governance)
- Link (runbook, dashboard, SLO, canale incident)
Modella le relazioni in modo esplicito
Tratta le relazioni come first-class, non solo campi di testo:
- Services ↔ teams: molti servizi per team; a volte ownership condivisa (usa
primary_owner_team_id più additional_owner_team_ids).
- Services ↔ resources: collega a risorse cloud (namespace Kubernetes, code, DB) così le persone possono rispondere a “cosa usa questo servizio?”
- Service tiers: memorizza il tier come enum strutturato e collegalo a policy (es., tier-0 richiede on-call e log di audit).
Questa struttura relazionale abilita pagine come “tutto ciò che è posseduto dal Team X” o “tutti i servizi che toccano questo database”.
Identificatori e regole di naming
Decidi presto l'ID canonico così i duplicati non compaiono dopo importazioni. Pattern comuni:
- Uno slug stabile unico (es.,
payments-api)
- Un UUID immutabile più uno slug leggibile
- Opzionale: una chiave derivata dal repo (
github_org/repo) se i repo sono 1:1 con i servizi
Documenta le regole di naming (caratteri ammessi, unicità, politica di rinomina) e vali dale alla creazione.
Pianifica come i dati restano freschi
Un catalogo fallisce quando diventa obsoleto. Scegli o combina:
- Import programmati (sync notturno da Git, CI/CD, inventario cloud)
- Webhooks (aggiorna su cambi repo, deploy, cambi ownership)
- Stream di eventi (pubblica eventi come “service.created” o “dependency.updated”)
Mantieni un campo last_seen_at e data_source per record così puoi mostrare freschezza e debugare conflitti.
Autenticazione, autorizzazione e auditabilità
Distribuisci un pilot a team reali
Ospita il prototipo del tuo portale interno e condividilo rapidamente con un team pilota.
Se il tuo portale IDP deve essere affidabile, ha bisogno di tre cose che funzionano insieme: autenticazione (chi sei?), autorizzazione (cosa puoi fare?) e auditabilità (cosa è successo e chi l'ha fatto?). Fallo bene presto e eviterai rifacimenti—soprattutto quando il portale inizierà a gestire cambi in produzione.
Default su SSO con mappatura dei gruppi
La maggior parte delle aziende ha già infrastruttura d'identità. Usala.
Rendi SSO via OIDC o SAML il percorso di accesso predefinito e importa la membership dei gruppi dal tuo IdP (Okta, Azure AD, Google Workspace, ecc.). Poi mappa i gruppi ai ruoli del portale e alla membership dei team.
Questo semplifica l'onboarding (“accedi ed sei già nei team giusti”), evita la memorizzazione di password e permette a IT di applicare policy globali come MFA e timeout di sessione.
Definisci ruoli chiari (e cosa possono fare)
Evita un modello vago “admin vs tutti”. Un set pratico di ruoli per un IDP è:
- Developer: naviga il portale, usa template e workflow self-service entro scope permessi.
- Service Owner: gestisce la voce del catalogo servizio (metadata, on-call, link, lifecycle), vede la cronologia specifica del servizio.
- Approver: approva o rifiuta richieste sensibili (accesso prod, nuovi ambienti, risorse a costo significativo).
- Platform Admin: gestisce template, integrazioni, impostazioni globali e default di policy.
- Auditor: accesso in sola lettura a log di audit, approvazioni e cronologia di configurazione.
Mantieni i ruoli piccoli e comprensibili. Puoi estenderli dopo, ma un modello confuso riduce l'adozione.
RBAC più permessi a livello di risorsa
Il controllo basato sui ruoli è necessario, ma non sufficiente. Il portale ha anche bisogno di permessi a livello risorsa: l'accesso dovrebbe essere limitato a un team, un servizio o un ambiente.
Esempi:
- Uno sviluppatore può attivare un workflow “crea sandbox” per i servizi del proprio team, ma non per altri.
- Un service owner può modificare la voce del catalogo per i servizi che possiede.
- Un approver può approvare richieste solo per specifici cost center o namespace di produzione.
Implementa questo con un pattern di policy semplice: (principale) può (azione) su (risorsa) se (condizione). Parti con lo scoping team/service e amplia dopo.
Tracce di audit per azioni sensibili
Tratta i log di audit come una feature di prima classe, non un dettaglio backend. Il portale dovrebbe registrare:
- Chi ha inizialmente avviato un workflow self-service (e da dove)
- I valori dei parametri inviati (redigi i segreti)
- Chi ha approvato/respinto e eventuali commenti
- Cambiamenti risultanti (link a CI/CD run, ticket o cambi infrastrutturali)
- Modifiche a template, permessi e integrazioni
Rendi le tracce di audit facilmente accessibili nei punti dove le persone lavorano: una pagina servizio nel portale, una tab “Cronologia” del workflow e una vista admin per compliance. Questo accelera anche le revisioni post-incident quando qualcosa si rompe.
UX Design per sviluppatori: rendi semplice il percorso giusto
Una buona UX per l'IDP non è questione di estetica—è ridurre l'attrito quando qualcuno cerca di consegnare. Gli sviluppatori dovrebbero poter rispondere a tre domande rapidamente: Cosa esiste? Cosa posso creare? Cosa richiede attenzione adesso?
Progetta la navigazione attorno a compiti reali
Invece di organizzare i menu per sistemi backend (“Kubernetes”, “Jira”, “Terraform”), struttura il portale attorno al lavoro reale degli sviluppatori:
- Discover: trova servizi, API, doc, owner, runbook
- Create: avvia un nuovo servizio, aggiungi un endpoint, richiedi un database
- Operate: visualizza salute, incidenti, stato deploy, cambi recenti
- Govern: permessi, controlli di conformità, eccezioni policy
Questa navigazione basata sui compiti rende anche l'onboarding più semplice: i nuovi membri non devono conoscere la tua toolchain per iniziare.
Rendi l'ownership impossibile da perdere
Ogni pagina servizio dovrebbe mostrare chiaramente:
- Team proprietario e canale del team
- Rotazione on-call e percorso di escalation
- Repo primario(i) e target di deployment
Metti questo pannello “Chi lo possiede?” vicino alla cima, non nascosto in una tab. Quando ci sono incidenti, i secondi contano.
Ricerca, filtri e stato che rispecchiano il pensiero delle persone
Una ricerca veloce è la caratteristica potente del portale. Supporta filtri che gli sviluppatori usano naturalmente: team, lifecycle (experimental/production), tier, linguaggio, piattaforma e “di mia proprietà”. Aggiungi indicatori di stato netti (healthy/degraded, SLO a rischio, bloccato da approvazione) così gli utenti possono scansionare una lista e decidere cosa fare.
Quando crei risorse, chiedi solo ciò che serve davvero ora. Usa template (“golden path”) e default per prevenire errori evitabili—convenzioni di naming, hook per logging/metrics e impostazioni CI precompilate. Se un campo è opzionale, nascondilo sotto “Opzioni avanzate” così il percorso felice resta veloce.
Workflow self-service: template, approvazioni e cronologia
Riduci i costi mentre impari
Guadagna crediti condividendo ciò che hai costruito o invitando altri a provare Koder.ai.
Il self-service è il punto dove un IDP guadagna fiducia: gli sviluppatori dovrebbero completare compiti comuni end-to-end senza aprire ticket, mentre i platform team mantengono il controllo su sicurezza, compliance e costi.
Scegli prima i tipi di workflow che contano
Inizia con un set ridotto di workflow che mappano a richieste frequenti e ad alto attrito. I tipici “quattro iniziali”:
- Crea servizio: scaffold di un repo, registrazione nel catalogo, configurazione ownership e bootstrap CI/CD.
- Provisiona ambiente: avvia un ambiente dev/stage con networking standard, logging e budget.
- Richiedi accesso: concedi accesso least-privilege a un sistema (DB, queue, API di terze parti) con opzione di scadenza.
- Ruota segreti: avvia la rotazione, aggiorna le configurazioni downstream e verifica che le applicazioni siano sane dopo.
Questi workflow dovrebbero essere opinionated e riflettere il tuo golden path, pur permettendo scelte controllate (linguaggio/runtime, regione, tier, classificazione dati).
Definisci un contratto di workflow (per mantenere prevedibilità dei template)
Tratta ogni workflow come un'API prodotto. Un contratto chiaro rende i workflow riutilizzabili, testabili e facili da integrare con la toolchain.
Un contratto pratico include:
- Input: campi tipizzati con default (es., nome servizio, team owner, ambiente, sensibilità dati).
- Validazione: regole di naming, regioni permesse, controlli quote e check “esiste già?”.
- Passi: sequenza di azioni (esegui un template, chiama CI/CD, crea risorse cloud, aggiorna catalogo servizi).
- Output: artefatti e link necessari agli sviluppatori (URL repo, URL di deploy, link al runbook, risorse create).
Mantieni l'UX focalizzata: mostra solo gli input che lo sviluppatore può realmente decidere e deduci il resto dal catalogo servizi e dalle policy.
Approvazioni rapide, chiare e applicabili
Le approvazioni sono inevitabili per certe azioni (accesso in produzione, dati sensibili, aumento dei costi). Il portale dovrebbe rendere le approvazioni prevedibili:
- Chi approva cosa: definisci approvatori basati su regole (team owner, owner del sistema, security) invece di ping ad-hoc.
- Limiti temporali: imposta SLA per l'approvazione e scadi automaticamente le richieste invecchiate.
- Escalation: se l'approvatore primario non è disponibile, instrada a un gruppo di backup o alla rotazione on-call.
Fondamentale: le approvazioni devono far parte del motore del workflow, non di un canale manuale esterno. Lo sviluppatore deve vedere stato, prossimi passi e perché è richiesta un'approvazione.
Memorizza cronologia e risultati per l'auto-diagnosi
Ogni esecuzione di workflow dovrebbe produrre un registro permanente:
- Input usati, risultati delle validazioni e decisioni degli approvatori
- Log passo-passo (con segreti redatti)
- Output finali, risorse create e eventuali azioni di rollback
Questa cronologia diventa la tua “traccia cartacea” e il tuo sistema di supporto: quando qualcosa fallisce, gli sviluppatori vedono esattamente dove e perché—spesso risolvendo il problema senza aprire un ticket. Fornisce anche ai platform team i dati per migliorare i template e individuare fallimenti ricorrenti.
Un portale IDP sembra “reale” solo quando può leggere e agire sui sistemi che gli sviluppatori già usano. Le integrazioni trasformano una voce del catalogo in qualcosa che puoi deployare, osservare e supportare.
Inizia con una checklist d'integrazione chiara
La maggior parte dei portali ha bisogno di un set di connessioni di base:
- Git (repo, branch predefinito, CODEOWNERS, pull request)
- CI/CD (pipeline, stato build, artifact, promozioni)
- Kubernetes (cluster, namespace, workload, rollout)
- Cloud (account/progetti, networking, servizi gestiti)
- IAM (team, gruppi, SSO, mappature ruoli)
- Secrets (vault, riferimenti a segreti, stato rotazione)
Sii esplicito su cosa è read-only (es., stato pipeline) vs write (es., trigger di deployment).
Preferisci API-first; usa webhooks o sync quando necessario
Le integrazioni API-first sono più facili da ragionare e testare: puoi validare auth, schemi e gestione errori.
Usa webhook per eventi near-real-time (PR merged, pipeline finita). Usa sync programmati per sistemi che non possono pushare eventi o dove la consistenza eventuale è accettabile (es., import notturno degli account cloud).
Costruisci uno strato connector (non incorporare vendor nel core)
Crea un sottile servizio “connector” o “integration service” che normalizzi i dettagli specifici del vendor in un contratto interno stabile (es., Repository, PipelineRun, Cluster). Questo isola le modifiche quando cambi tool e mantiene pulita l'API/UI del portale.
Un pattern pratico è:
- Il portale chiama il connector
- Il connector gestisce auth, rate limit, retry e mapping
- Il connector ritorna dati normalizzati + link azionabili (es.,
/deployments/123)
Documenta modalità di errore e cosa devono fare gli utenti
Ogni integrazione dovrebbe avere un piccolo runbook: come si manifesta il degrado, come viene mostrato in UI e cosa fare.
Esempi:
- API Git rate-limited: il portale mostra dati repo cache; l'utente può ancora sfogliare il catalogo, ma “Crea da template” è disabilitato.
- CI/CD down: il portale offre fallback manuale (link all'interfaccia pipeline) e spiega i tempi di retry.
- Secret manager non disponibile: blocca i cambi che richiedono nuovi segreti; permetti solo accesso in sola lettura ai metadata servizio.
Mantieni questi documenti vicini al prodotto (es., /docs/integrations) così gli sviluppatori non devono indovinare.
Osservabilità: monitorare il portale e le sue automazioni
Il tuo portale IDP non è solo una UI—è un livello di orchestrazione che avvia job CI/CD, crea risorse cloud, aggiorna un catalogo servizi e applica approvazioni. L'osservabilità ti permette di rispondere, rapidamente e con fiducia: “Cosa è successo?”, “Dove è fallito?” e “Chi deve agire dopo?”
Traccia ogni richiesta attraverso i passaggi
Strumenta ogni run di workflow con un correlation ID che segue la richiesta dalla UI del portale attraverso API backend, controlli approvazione e tool esterni (Git, CI, cloud, ticketing). Aggiungi tracing delle richieste così una singola vista mostra il percorso completo e i tempi di ogni passo.
Complementa i trace con log strutturati (JSON) che includano: nome workflow, run ID, nome passo, servizio target, ambiente, attore e risultato. Questo rende facile filtrare per “tutti i run falliti di deploy-template” o “tutto ciò che riguarda il Service X.”
Metriche che riflettono il dolore degli sviluppatori
Le metriche di infra di base non bastano. Aggiungi metriche di workflow che si collegano a risultati reali:
- Conteggi dei run, tasso di successo e durata per workflow e passo
- Tempo di attesa approvazione vs tempo di esecuzione (aiuta a individuare colli di bottiglia)
- Retry, timeout e rate limit dai connector
Viste operative dentro il portale
Dai ai platform team pagine “a colpo d'occhio”:
- Coda dei workflow: in esecuzione, in coda, falliti, in attesa di approvazione
- Salute dei connector: validità token, ultima chiamata riuscita, tasso errori
- Stato sync: ultimo sync catalogo, drift rilevato, dimensione backlog
Collega ogni stato ai dettagli drill-down e ai log/tracce esatti per quel run.
Alert, retention e audit
Imposta alert per integrazioni rotte (es., 401/403 ripetuti), approvazioni bloccate (nessuna azione per N ore) e fallimenti di sync. Pianifica la retenzione dei dati: conserva i log ad alto volume per meno tempo, ma tieni gli eventi di audit più a lungo per compliance e indagini, con controlli di accesso e opzioni di esportazione chiare.
Sicurezza e governance senza rallentare i team
Allestisci un catalogo servizi
Genera un'interfaccia catalogo servizi con campi di ownership, tag e liste ricercabili.
La sicurezza in un portale IDP funziona meglio quando si percepisce come “guardrail”, non come portone. L'obiettivo è ridurre le scelte rischiose rendendo la strada sicura la più semplice—pur dando ai team autonomia per consegnare.
La maggior parte della governance può avvenire al momento in cui lo sviluppatore richiede qualcosa (nuovo servizio, repository, ambiente o risorsa cloud). Tratta ogni form e chiamata API come input non fidato.
Applica gli standard in codice, non solo in documentazione:
- Richiedi ownership (team, on-call e contatto escalation) e blocca la creazione se manca.
- Valida convenzioni di naming (nomi servizio, repo, ambienti) per evitare collisioni e confusione.
- Richiedi tag/metadata usati per allocazione costi, compliance e discovery.
- Rifiuta richieste che non soddisfano policy minime (es., “esposizione pubblica” richiede review extra).
Questo mantiene il catalogo pulito e semplifica gli audit.
Proteggi i segreti by design
Un portale spesso tocca credenziali (token CI, accesso cloud, API key). Tratta i segreti come radioattivi:
- Non loggare mai i segreti né includerli nei messaggi d'errore.
- Preferisci token a breve vita (OIDC, federated access, credenziali time-bound) a chiavi a lunga durata.
- Conserva i segreti solo in un secret manager dedicato; il portale dovrebbe farne riferimento, non copiarli.
Assicurati che i log di audit catturino chi ha fatto cosa e quando—senza includere i valori dei segreti.
Modella le minacce sui fallimenti “normali”
Concentrati sui rischi realistici:
- Escalation di privilegi tramite RBAC mal configurato e permessi troppo ampi.
- Webhook o callback spoofati che attivano azioni senza verifica.
- Fughe di dati tramite endpoint di debug, log verbosi o ricerca troppo permissiva.
Mitiga con verifica firmata dei webhook, ruoli least-privilege e separazione netta tra operazioni di lettura e modifica.
Sposta i controlli a sinistra con CI e revisioni permessi
Esegui controlli di sicurezza in CI per il codice del portale e per i template generati (linting, policy check, scansione dipendenze). Poi programma revisioni regolari di:
- Ruoli RBAC e mappature dei gruppi
- Permessi dei template (chi può creare cosa)
- Accesso admin “break-glass” e procedure di rotazione
La governance è sostenibile quando è routine, automatizzata e visibile—non un progetto una tantum.
Rollout, adozione e manutenzione a lungo termine
Un portale per sviluppatori consegna valore solo se i team lo usano. Tratta il rollout come un lancio prodotto: parti piccolo, impara velocemente, poi scala basandoti sulle evidenze.
Parti con un pilot focalizzato
Pilota con 1–3 team motivati e rappresentativi (un team “greenfield”, uno con legacy pesante, uno con esigenze di compliance più rigide). Osserva come completano task reali—registrare un servizio, richiedere infrastruttura, triggerare un deploy—and correggi gli attriti immediatamente. L'obiettivo non è la completezza delle feature, ma dimostrare che il portale risparmia tempo e riduce errori.
Rendi la migrazione noiosa e prevedibile
Fornisci passi di migrazione che si inseriscano nello sprint normale. Per esempio:
- registra un servizio esistente nel catalogo,\n2) associa ownership e info on-call,\n3) collega CI/CD,\n4) adotta un template (repo, pipeline o infra) per il prossimo componente.
Mantieni gli upgrade “day 2” semplici: permetti ai team di aggiungere metadata gradualmente e sostituire script su misura con workflow del portale.
Documentazione e help in-product che le persone leggeranno
Scrivi doc concise per i workflow importanti: “Registra un servizio”, “Richiedi un database”, “Rollback di un deploy”. Aggiungi help in-product accanto ai campi dei form e rimanda a /docs/portal e /support per contesto più profondo. Tratta la documentazione come codice: versionala, rivedila e puliscila.
L'ownership è un impegno a lungo termine
Pianifica la proprietà continua fin dall'inizio: qualcuno deve triage il backlog, mantenere i connector agli strumenti esterni e supportare gli utenti quando le automazioni falliscono. Definisci SLA per gli incident del portale, una cadenza regolare per aggiornare i connector e revisiona i log di audit per individuare punti di dolore ricorrenti e gap di policy.
Man mano che il portale matura, vorrai probabilmente funzionalità come snapshot/rollback per la configurazione del portale, deployment prevedibili e promozione degli ambienti across-region. Se stai sperimentando o costruendo velocemente, Koder.ai può aiutare i team a mettere in piedi app interne con modalità di planning, hosting e export del codice—utile per pilotare funzionalità del portale prima di consolidarle in componenti di piattaforma a lungo termine.