Definire obiettivi e segnali di adozione
Prima di costruire un punteggio di adozione cliente, decidi cosa vuoi che il punteggio faccia per il business. Un punteggio pensato per attivare avvisi di rischio churn sarà diverso da uno pensato per guidare l'onboarding, l'educazione del cliente o il miglioramento del prodotto.
Definisci cosa significa “adozione” per il tuo prodotto
L'adozione non è solo “ha effettuato l'accesso di recente”. Scrivi i pochi comportamenti che indicano veramente che i clienti raggiungono valore:
- Attivazione: il primo momento in cui un utente raggiunge un risultato significativo (es. “ha invitato un collega”, “ha collegato una fonte dati”, “ha pubblicato un report”).
- Azioni fondamentali: comportamenti ripetibili e ad alto segnale che si correlano con account di successo (es. esportazioni settimanali, esecuzioni di automazioni, dashboard visualizzate da più utenti).
- Retention: uso continuativo alla cadenza giusta per il tuo prodotto (giornaliero, settimanale, mensile), idealmente su più utenti nell'account.
Questi diventano i tuoi segnali iniziali di adozione per l'analisi delle funzionalità e per le cohort in seguito.
Elenca le decisioni che la tua app dovrebbe abilitare
Sii esplicito su cosa succede quando il punteggio cambia:
- Chi viene notificato quando un account scende sotto una soglia?
- Quali playbook devono essere lanciati (outreach, formazione, controllo supporto)?
- Quali insights dovrebbero informare il monitoraggio dell'adozione prodotto (punti di frizione, funzionalità sottoutilizzate, time-to-value)?
Se non riesci a nominare una decisione, non tracciare ancora la metrica.
Identifica utenti, ruoli e finestre temporali
Chiarisci chi userà la dashboard di Customer Success:
- Manager CS hanno bisogno di priorizzazione e contesto account.
- Product ha bisogno di pattern, cohort e movimento a livello di feature.
- Support ha bisogno dell'attività recente intorno a ticket e incidenti.
- Leadership necessita di un roll-up comprensibile e delle tendenze.
Scegli finestre standard—ultimi 7/30/90 giorni—e considera le fasi del ciclo di vita (trial, onboarding, steady-state, rinnovo). Questo evita di confrontare un account nuovissimo con uno maturo.
Definisci i criteri di successo
Definisci il “fatto” per il tuo modello di health score:
- Accuratezza: predice il rischio e i segnali di espansione meglio dell'approccio attuale?
- Spiegabilità: un CSM può spiegare perché il punteggio è alto/basso in un minuto?
- Facilità d'uso: fa risparmiare tempo e guida azioni coerenti?
Questi obiettivi modellano tutto ciò che segue: tracciamento eventi, logica di scoring e i workflow costruiti attorno al punteggio.
Selezionare le metriche per il tuo health score
La scelta delle metriche è il punto in cui il tuo health score diventa un segnale utile o un numero rumoroso. Punta a un piccolo set di indicatori che riflettano la reale adozione—non solo attività.
Parti dai segnali di adozione del prodotto
Scegli metriche che mostrino se gli utenti ottengono ripetutamente valore:
- Logins / utenti attivi: es. weekly active users (WAU) e il trend nelle ultime 4–8 settimane.
- Giorni attivi: quanti giorni distinti l'account è stato attivo in una settimana/mese (aiuta ad evitare falsi positivi di “una grande sessione”).
- Profondità delle feature: uso delle tue “feature di valore” (le azioni che si correlano al successo), non ogni clic su un pulsante.
- Integrazioni connesse: soprattutto se le integrazioni aumentano i costi di switching o sbloccano workflow chiave.
- Utilizzo delle seat: percentuale delle seat acquistate che sono invitate, attivate e realmente attive.
Mantieni la lista focalizzata. Se non puoi spiegare in una frase perché una metrica conta, probabilmente non è un input fondamentale.
Aggiungi contesto di business (per evitare punteggi ingiusti)
L'adozione va interpretata nel contesto. Un team da 3 seat si comporterà diversamente rispetto a un rollout da 500 seat.
Segnali di contesto comuni:
- Tier del piano e entitlements delle feature
- Dimensione del contratto / fascia ARR
- Fase del ciclo di vita: trial vs appena pagato vs finestra di rinnovo
Questi non devono necessariamente “aggiungere punti”, ma aiutano a impostare aspettative e soglie realistiche per segmento.
Decidi indicatori leading vs lagging
Un punteggio utile miscela:
- Indicatori leading (predicono il successo futuro): aumento dei giorni attivi, completamento onboarding, prima integrazione connessa.
- Indicatori lagging (confermano esiti): rinnovo, espansione, retention a lungo termine.
Evita di sovrappesare i lagging metric; dicono cosa è già successo.
Se li hai, NPS/CSAT, volume ticket di supporto e note CSM possono aggiungere sfumature. Usali come modificatori o flag—non come base—perché i dati qualitativi possono essere scarsi e soggettivi.
Crea un semplice data dictionary
Prima di costruire grafici, allineate nomi e definizioni. Un data dictionary leggero dovrebbe includere:
- Nome della metrica (es.
active_days_28d)
- Definizione chiara (cosa conta, cosa no)
- Finestra temporale e cadenza di refresh
- Sistema di origine (eventi prodotto, CRM, support)
Questo evita confusione da “stessa metrica, significato diverso” quando implementerai dashboard e avvisi.
Progettare un modello di health score spiegabile
Un punteggio di adozione funziona solo se il team gli si fida. Punta a un modello che puoi spiegare in un minuto a un CSM e in cinque minuti a un cliente.
Parti semplice: punti ponderati (prima del ML)
Inizia con un punteggio rules-based e trasparente. Scegli un piccolo set di segnali di adozione (es. utenti attivi, uso di feature chiave, integrazioni abilitate) e assegna pesi che riflettano gli “aha” del tuo prodotto.
Esempio di pesi:
- Weekly active users per seat: 0–40 punti
- Frequenza d'uso delle feature chiave: 0–35 punti
- Ampiezza delle feature usate: 0–15 punti
- Tempo dall'ultima attività significativa: 0–10 punti
Mantieni i pesi facilmente difendibili. Puoi rivederli più tardi—non aspettare il modello perfetto.
Normalizza per ridurre i bias
I conteggi grezzi penalizzano gli account piccoli e appiattiscono quelli grandi. Normalizza le metriche dove serve:
- Per seat (uso / seat licenziate)
- Per età dell'account (nuovo vs maturo)
- Per tier di piano (disponibilità delle feature)
Questo aiuta il tuo punteggio a riflettere il comportamento, non solo la dimensione.
Definisci verde/giallo/rosso con ragionamenti chiari
Imposta soglie (es. Green ≥ 75, Yellow 50–74, Red < 50) e documenta perché ogni cutoff esiste. Collega le soglie agli esiti attesi (rischio di rinnovo, completamento onboarding, prontezza all'espansione) e tieni le note nei tuoi documenti interni o in /blog/health-score-playbook.
Rendilo spiegabile: contributori e trend
Ogni punteggio dovrebbe mostrare:
- I top 3 contributori (cosa ha aiutato/o penalizzato)
- Il cambiamento nel tempo (ultimi 7/30 giorni)
- Un sommario in linguaggio semplice (“L'uso della Feature X è diminuito del 35% week-over-week”)
Pianifica l'iterazione: versiona il modello
Tratta lo scoring come un prodotto. Versionalo (v1, v2) e traccia l'impatto: gli avvisi di rischio churn sono diventati più accurati? I CSM agiscono più velocemente? Memorizza la versione del punteggio con ogni calcolo per confrontare i risultati nel tempo.
Strumentare eventi prodotto e sorgenti dati
Un health score è affidabile quanto i dati di attività che lo alimentano. Prima di costruire la logica di scoring, conferma che i segnali giusti siano catturati in modo coerente tra i sistemi.
Scegli le sorgenti eventi
La maggior parte dei programmi di adozione attinge da un mix di:
- Eventi frontend (page view, click, interazioni con le feature)
- Azioni backend (chiamate API, job completati, record creati)
- Billing (piano, rinnovi, stato pagamenti, conteggio seat)
- Support e strumenti di success (ticket, CSAT, milestone onboarding)
Una regola pratica: traccia le azioni critiche server-side (più difficili da falsificare, meno influenzate da ad-blocker) e usa gli eventi frontend per engagement UI e discovery.
Definisci uno schema evento chiaro
Mantieni un contratto consistente così gli eventi sono facili da joinare, interrogare e spiegare agli stakeholder. Una baseline comune:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id, ecc.)
Usa un vocabolario controllato per event_name (per esempio, project_created, report_exported) e documentalo in un tracking plan semplice.
Decidi SDK vs server-side (o entrambi)
- SDK tracking è veloce da rilasciare ed ottimo per eventi UI.
- Server-side tracking è migliore per azioni system-of-record.
Molti team fanno entrambi, ma assicurati di non conteggiare due volte la stessa azione del mondo reale.
Gestisci correttamente l'identità
I punteggi di salute solitamente vengono aggregati a livello account, quindi serve una mappatura user→account affidabile. Pianifica per:
- Utenti appartenenti a più account
- Merge di account (acquisizioni, consolidamento workspace)
- ID anonimizzati per comportamento pre-login (con una fusione sicura dopo la registrazione)
Inserisci controlli di qualità dati
Al minimo, monitora eventi mancanti, esplosioni di duplicati e coerenza dei fusi orari (memorizza in UTC; converti per la visualizzazione). Segnala anomalie presto così i tuoi avvisi di rischio churn non scattino perché il tracciamento si è rotto.
Modellare i dati e lo storage
Un'app per health score cliente vive o muore in base a quanto bene modellate sono le informazioni su “chi ha fatto cosa e quando”. L'obiettivo è rendere veloci le domande comuni: Come sta questo account questa settimana? Quali feature sono in crescita o decrescita? Una buona modellazione semplifica scoring, dashboard e avvisi.
Entità core da modellare
Inizia con un piccolo set di tabelle “source of truth”:
- Accounts: account_id, piano, segmento, lifecycle stage, CSM owner
- Users: user_id, account_id, ruolo/persona, created_at, status
- Subscriptions (o contratti): account_id, start/end, seats, MRR, renewal date
- Features: feature_id, name, category (activation, collaboration, admin, ecc.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (o computed_at), overall_score, component scores, campi di spiegazione
Mantieni queste entità coerenti usando ID stabili (account_id, user_id) ovunque.
Separare lo storage: relazionale + analytics
Usa un database relazionale (es. Postgres) per accounts/users/subscriptions/scores—cose che aggiorni e joini frequentemente.
Conserva gli eventi ad alto volume in un warehouse/analytics (es. BigQuery/Snowflake/ClickHouse). Questo mantiene reattive le dashboard e l'analisi di cohort senza sovraccaricare il DB transazionale.
Conserva aggregati per velocità
Invece di ricalcolare tutto dagli eventi raw, mantieni:
- Riepiloghi giornalieri account (una riga per account per giorno): utenti attivi, conteggi eventi chiave, ultima attività, milestone di adozione
- Contatori per feature: per account/giorno/feature conteggi d'uso, utenti unici, tempo speso (se disponibile)
Queste tabelle alimentano i grafici di trend, gli insight su “cosa è cambiato” e i componenti del punteggio.
Per grandi tabelle eventi, pianifica retention (es. 13 mesi raw, più a lungo per gli aggregati) e partiziona per data. Cluster/index su account_id e timestamp/date per accelerare le query “account over time”.
Nelle tabelle relazionali, indicizza i filtri e i join comuni: account_id, (account_id, date) sui summary, e chiavi esterne per mantenere i dati puliti.
Pianificare l'architettura della web app
Costruisci la pipeline di scoring
Prototipa account, eventi, aggregati e job di scoring velocemente così il team può iterare precocemente.
La tua architettura dovrebbe rendere semplice il rilascio di un v1 affidabile, poi crescere senza riscritture. Inizia decidendo quanti componenti ti servono davvero.
Monolite vs servizi (mantieni semplice il v1)
Per la maggior parte dei team, un monolite modulare è la strada più veloce: un codice unico con confini chiari (ingest, scoring, API, UI), un singolo deployable e meno sorprese operative.
Passa a servizi solo quando hai una ragione chiara—necessità di scalare indipendentemente, isolamento dati rigoroso o team separati che gestiscono componenti. Altrimenti, servizi prematuri aumentano i punti di guasto e rallentano l'iterazione.
Definisci i componenti core
Al minimo, prevedi queste responsabilità (anche se risiedono in un'unica app inizialmente):
- Ingestion: riceve eventi prodotto (SDK, Segment, webhook, import batch).
- Aggregation: trasforma eventi raw in fatti di utilizzo giornalieri/settimanali per account/utente.
- Scoring: calcola il customer adoption health score e le spiegazioni correlate.
- API: serve score, trend e insight “perché” all'UI e alle integrazioni.
- UI: dashboard Customer Success con viste account, cohort e drill-down.
Se vuoi prototipare velocemente, un approccio “vibe-coding” può aiutare a ottenere una dashboard funzionante senza investire troppo nello scaffolding. Per esempio, Koder.ai può generare una UI React e un backend Go a partire da una semplice descrizione delle tue entità (accounts, events, scores), endpoint e schermate—utile per produrre un v1 su cui il team CS può reagire presto.
Job schedulati vs streaming
Lo scoring batch (es. orario/notturno) è di solito sufficiente per il monitoraggio dell'adozione e molto più semplice da gestire. Lo streaming ha senso se servono avvisi quasi in tempo reale (es. calo improvviso d'uso) o volumi di evento molto alti.
Un ibrido pratico: ingest degli eventi continuo, aggregate/scoring schedulati, e streaming riservato a pochi segnali urgenti.
Ambienti, segreti e requisiti non funzionali
Imposta dev/stage/prod presto, con account di esempio in stage per validare le dashboard. Usa un secrets store gestito e ruota le credenziali.
Documenta i requisiti in anticipo: volume atteso di eventi, freschezza del punteggio (SLA), target di latenza API, disponibilità, retention dei dati e vincoli di privacy (gestione PII e controlli di accesso). Questo evita decisioni architetturali fatte troppo tardi sotto pressione.
Costruire la data pipeline e i job di scoring
Il tuo health score è affidabile quanto la pipeline che lo produce. Tratta lo scoring come un sistema di produzione: riproducibile, osservabile e facile da spiegare quando qualcuno chiede “Perché questo account è sceso oggi?”.
Una pipeline semplice: raw → validated → aggregates
Inizia con un flusso staged che riduce i dati in qualcosa che puoi valutare in sicurezza:
- Raw events: ingest append-only dalla tua app, mobile, integrazioni e export billing/CRM.
- Validated events: eventi che passano controlli di schema (campi richiesti, tipi corretti), controlli di identità (mappatura user → account) e deduplica.
- Daily aggregates: rollup per account (e opzionalmente workspace/team) come utenti attivi, conteggi eventi chiave, milestone time-to-value e delta di trend.
Questa struttura mantiene i job di scoring veloci e stabili, perché operano su tabelle compatte e pulite invece che su miliardi di righe raw.
Schedule di ricalcolo e backfill
Decidi quanto “fresco” deve essere il punteggio:
- Orario per motion ad alta interazione dove i CSM agiscono rapidamente.
- Giornaliero spesso è sufficiente per SMB/self-serve e mantiene bassi i costi.
Costruisci lo scheduler in modo che supporti backfill (es. ricalcolo degli ultimi 30/90 giorni) quando sistemate il tracking, cambiate pesi o aggiungete segnali. I backfill dovrebbero essere una feature di prima classe, non uno script d'emergenza.
Idempotenza: evita il doppio conteggio
I job di scoring verranno ritentati. Gli import verranno rilanciati. I webhook saranno consegnati due volte. Progetta di conseguenza.
Usa una chiave di idempotenza per gli eventi (event_id o un hash stabile di timestamp + user_id + event_name + properties) e impone unicità al layer validated. Per gli aggregati, esegui upsert per (account_id, date) così la ricalcolazione sostituisce i risultati precedenti anziché aggiungerli.
Monitoring e controlli di anomalia
Aggiungi monitoring operativo per:
- Successo/fallimento dei job e conteggi di retry
- Data lag (quanto è indietro rispetto a “ora” il tuo ultimo aggregato)
- Anomalie di volume (calo/improvviso picco di eventi, utenti attivi, azioni chiave)
Anche soglie leggere (es. “eventi giù del 40% vs media 7 giorni”) prevengono rotture silenziose che ingannerebbero la dashboard CS.
Audit trail per ogni punteggio
Memorizza un record di audit per account per ogni esecuzione di scoring: metriche input, feature derivate (es. variazione week-over-week), versione del modello e punteggio finale. Quando un CSM clicca “Perché?”, puoi mostrare esattamente cosa è cambiato e quando—senza doverlo ricostruire dai log.
Creare un'API sicura per health e insight
Possiedi il codice
Mantieni il controllo completo esportando il codice sorgente quando sei pronto a personalizzare.
La tua web app vive o muore per la sua API. È il contratto tra i job di scoring, l'interfaccia e gli strumenti downstream (piattaforme CS, BI, export dati). Punta a un'API veloce, prevedibile e sicura per default.
Endpoint core per supportare workflow reali
Progetta endpoint attorno a come Customer Success esplora realmente l'adozione:
- Account health:
GET /api/accounts/{id}/health restituisce l'ultimo punteggio, la banda di stato (es. Green/Yellow/Red) e il timestamp dell'ultimo calcolo.
- Trends:
GET /api/accounts/{id}/health/trends?from=&to= per il punteggio nel tempo e i delta delle metriche chiave.
- Drivers (“why”):
GET /api/accounts/{id}/health/drivers per mostrare i principali fattori positivi/negativi (es. “weekly active seats giù 35%”).
- Cohorts:
GET /api/cohorts/health?definition= per analisi di cohort e benchmark tra pari.
- Exports:
POST /api/exports/health per generare CSV/Parquet con schemi coerenti.
Filtri, paginazione e caching
Rendi gli endpoint lista facili da sezionare:
- Filtri:
plan, segment, csm_owner, lifecycle_stage e date_range sono essenziali.
- Paginazione: usa cursor-based (
cursor, limit) per stabilità mentre i dati cambiano.
- Caching: cache le query pesanti (cohort rollup, serie di trend) e ritorna
ETag/If-None-Match per ridurre i carichi ripetuti. I key di cache devono essere consapevoli di filtri e permessi.
Sicurezza con controllo degli accessi basato sui ruoli
Proteggi i dati a livello account. Implementa RBAC (es. Admin, CSM, Read-only) e applicalo server-side su ogni endpoint. Un CSM deve vedere solo gli account che possiede; ruoli finanziari possono vedere aggregati a livello piano ma non dettagli utente.
Restituisci sempre spiegazioni
Oltre al numero del customer adoption health score, restituisci campi “perché”: principali driver, metriche colpite e baseline di confronto (periodo precedente, mediana della cohort). Questo trasforma il monitoraggio dell'adozione in azione, non solo in reporting, e rende la tua dashboard più affidabile.
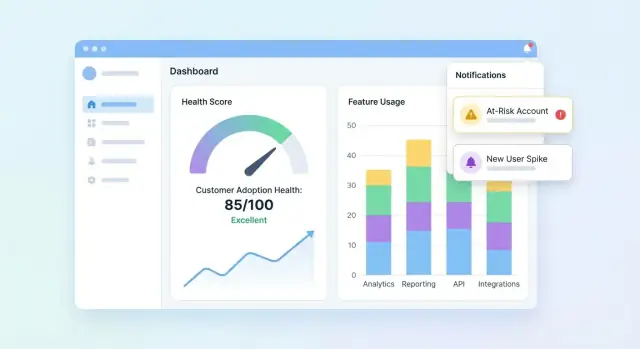
Progettare dashboard e viste account
La UI deve rispondere rapidamente a tre domande: Chi è sano? Chi sta peggiorando? Perché? Parti da una dashboard che riassume il portfolio, poi consenti agli utenti di approfondire un account per capirne la storia dietro il punteggio.
Elementi essenziali della dashboard portfolio
Includi un set compatto di riquadri e grafici che il team CS possa scansionare in pochi secondi:
- Distribuzione dei punteggi (istogramma o bucket Healthy / Watch / At-risk)
- Lista At-risk con i pochi campi necessari per agire (account, owner, punteggio, ultima attività, top driver)
- Trend del punteggio (chart a linee) con opzione di filtro per segmento
Rendi cliccabile la lista at-risk così un utente può aprire un account e vedere subito cosa è cambiato.
Vista account: spiega il punteggio
La pagina dell'account dovrebbe leggere come una timeline di adozione:
- Timeline di eventi chiave (passaggi onboarding completati, integrazioni connesse, cambi amministrativi, primo utilizzo di feature maggiori)
- Metriche chiave (utenti attivi, azioni feature chiave, tempo dall'ultima attività significativa)
- Breakdown dell'adozione delle feature che mostra quali feature sono adottate, ignorate o in regressione
Aggiungi un pannello “Perché questo punteggio?”: cliccando sul punteggio si rivelano i segnali contributori (positivi e negativi) con spiegazioni in linguaggio semplice.
Viste cohort e di segmento
Fornisci filtri di cohort che rispecchino come i team gestiscono gli account: cohort di onboarding, tier di piano, settori. Abbina ogni cohort con linee di trend e una piccola tabella dei top movers così i team possono confrontare esiti e individuare pattern.
Visualizzazioni accessibili e affidabili
Usa etichette chiare e unità, evita icone ambigue e offri indicatori di stato accessibili (es. etichette testuali + forme). Tratta i grafici come strumenti decisionali: annota i picchi, mostra gli intervalli di date e rendi il comportamento di drill-down consistente su tutte le pagine.
Aggiungere avvisi, task e workflow
Un health score è utile solo se genera azione. Avvisi e workflow trasformano “dati interessanti” in outreach tempestivi, correzioni di onboarding o nudges di prodotto—senza costringere il team a fissare dashboard tutto il giorno.
Definisci regole di avviso che mappano a rischi reali
Inizia con pochi trigger ad alto segnale:
- Calo del punteggio (es. giù 15 punti week-over-week)
- Stato Red (superamento di una soglia critica)
- Calo improvviso di utilizzo (uso di feature chiave sotto una baseline)
- Passaggio onboarding fallito (checklist bloccata, integrazione non completata)
Rendi ogni regola esplicita e spiegabile. Invece di “Cattiva salute”, avvisa su “Nessuna attività in Feature X per 7 giorni + onboarding incompleto.”
Scegli canali e rendili configurabili
Team diversi lavorano in modi diversi, quindi costruisci supporto canali e preferenze:
- Email per owner e manager
- Slack per visibilità del team e risposta rapida
- Task in-app dentro la dashboard CS così il lavoro non si perde
Permetti a ogni team di configurare: chi viene notificato, quali regole sono attive e cosa significa “urgente”.
Riduci il rumore con guardrail
La fatica da avvisi uccide il monitoraggio. Aggiungi controlli come:
- Finestre di cooldown (non riavvisare per lo stesso account per N ore/giorni)
- Soglie minime di dati (salta avvisi se l'account ha dati recenti insufficienti)
- Batching/digest per segnali non urgenti (sintesi giornaliere/settimanali)
Aggiungi contesto e prossimi passi
Ogni avviso dovrebbe rispondere: cosa è cambiato, perché conta e cosa fare dopo. Includi i driver recenti del punteggio, una breve timeline (es. ultimi 14 giorni) e task suggeriti come “Pianifica chiamata di onboarding” o “Invia guida integrazione”. Mostra la vista account (es. /accounts/{id}).
Traccia gli esiti per chiudere il ciclo
Tratta gli avvisi come work item con stati: acknowledged, contacted, recovered, churned. Il reporting sugli esiti aiuta a perfezionare le regole, migliorare i playbook e dimostrare che il punteggio guida impatti misurabili sulla retention.
Assicurare qualità dei dati, privacy e governance
Lancia la tua dashboard
Distribuisci e ospita la tua app di monitoraggio dell'adozione senza configurare l'infrastruttura a mano.
Se il tuo health score si basa su dati inaffidabili, i team smetteranno di fidarsi e di agire. Tratta qualità, privacy e governance come funzionalità prodotto, non come un ripensamento.
Inserisci controlli automatici dei dati
Inizia con validazioni leggere a ogni passaggio (ingest → warehouse → output scoring). Alcuni test ad alto segnale catturano la maggior parte dei problemi presto:
- Schema checks: colonne aspettate, tipi non cambiati, enum validi.
- Range checks: valori impossibili (sessioni negative, timestamp futuri) falliscono subito.
- Null checks: campi richiesti (
account_id, event_name, occurred_at) non possono essere vuoti.
Quando i test falliscono, blocca il job di scoring (o marca i risultati come “stale”) così una pipeline rotta non genera silenziosamente avvisi fuorvianti.
Gestisci esplicitamente i casi limite comuni
Lo scoring si rompe su scenari “strani ma normali”. Definisci regole per:
- Account nuovi con pochi dati: mostra “dati insufficienti” o usa una baseline di ramp-up invece di un punteggio basso.
- Uso stagionale: confronta con il periodo precedente dell'account o benchmark di cohort anziché una soglia universale.
- Outage e gap di tracciamento: flagga le finestre interessate e evita di penalizzare i clienti per i downtime tuoi.
Aggiungi permessi e controlli di privacy
Limita i PII per default: conserva solo ciò che serve per il monitoraggio dell'adozione. Applica RBAC nella web app, logga chi ha visualizzato/esportato i dati e oscurare gli export quando i campi non sono necessari (es. nascondi email nei CSV).
Crea runbook e abitudini di governance
Scrivi runbook brevi per la risposta agli incidenti: come mettere in pausa lo scoring, backfill dei dati e rilanciare job storici. Rivedi metriche di Customer Success e pesi del punteggio regolarmente—mensilmente o trimestralmente—per evitare drift mentre il prodotto evolve. Per l'allineamento di processo, collega la tua checklist interna da /blog/health-score-governance.
Validare, iterare e scalare il health score
La validazione è dove un health score smette di essere un “bel grafico” e diventa affidabile per guidare l'azione. Tratta la prima versione come un'ipotesi, non come la risposta finale.
Esegui un pilot e calibra con il giudizio umano
Inizia con un gruppo pilota di account (es. 20–50 attraverso i segmenti). Per ogni account, confronta il punteggio e le ragioni di rischio con la valutazione del CSM.
Cerca pattern:
- Punteggi costantemente più alti/bassi rispetto al giudizio del CSM (calibrazione)
- “Falsi allarmi” (alto rischio ma account a posto) vs “miss” (punteggio sano ma account che churna)
- Motivi che non rispecchiano la realtà (gap di spiegabilità)
Misura se è effettivamente utile
L'accuratezza è utile, ma l'utilità è ciò che paga. Monitora outcome operativi come:
- Time-to-detect risk (quanto presto segnali un problema)
- Tasso di successo degli outreach (percentuale di account a rischio che migliorano dopo l'intervento)
- Proxy di riduzione churn (movimenti di likelihood di rinnovo, segnali di espansione, cambiamento del carico support)
Testa i cambiamenti in sicurezza con versioning
Quando modifichi soglie, pesi o aggiungi segnali, trattali come una nuova versione del modello. Fai A/B test delle versioni su cohort comparabili e conserva le versioni storiche per spiegare perché i punteggi sono cambiati nel tempo.
Raccogli feedback dall'interno dell'UI
Aggiungi un controllo leggero come “Il punteggio sembra sbagliato” più una ragione (es. “completamento onboarding recente non riflesso”, “uso stagionale”, “mappatura account errata”). Inoltra questo feedback al backlog e taggalo con account e versione del punteggio per debug più rapido.
Scala con una roadmap
Una volta che il pilot è stabile, pianifica il lavoro di scalabilità: integrazioni più profonde (CRM, billing, support), segmentazione (per piano, industry, lifecycle), automazioni (task e playbook) e setup self-serve così i team possono personalizzare viste senza engineering.
Mentre scala, mantieni corto il loop build/iterate. I team spesso usano Koder.ai per creare nuove pagine di dashboard, rifinire shape API o aggiungere funzionalità workflow (task, export e release rollback-ready) direttamente dalla chat—utile quando versioni il modello di health score e devi spedire cambi UI + backend insieme senza rallentare il feedback CS.