Chiarisci l'obiettivo e l'ambito dell'app
Prima di progettare schermate o scegliere la tecnologia, definisci esplicitamente cosa significa “rischio operativo” nella tua organizzazione. Alcuni team lo usano per coprire guasti di processo e errori umani; altri includono interruzioni IT, problemi con fornitori, frodi o eventi esterni. Se la definizione è vaga, la tua app diventerà una discarica e i report risulteranno inaffidabili.
Definisci cosa traccerai
Scrivi una dichiarazione chiara su cosa conta come rischio operativo e cosa no. Puoi inquadrare il tutto in quattro contenitori (processi, persone, sistemi, eventi esterni) e aggiungere 3–5 esempi per ciascuno. Questo riduce le discussioni successive e mantiene i dati coerenti.
Concorda gli obiettivi
Sii specifico su cosa l'app deve raggiungere. Obiettivi comuni includono:
- Visibilità: un unico luogo per vedere rischi, controlli, incidenti e azioni
- Responsabilità: ogni elemento ha un owner nominato e una scadenza
- Tracciamento della remediazione: le azioni passano da “aperte” a “verificate” con evidenze
- Reporting e prontezza all'audit: puoi spiegare cosa è cambiato, quando e perché
Se non riesci a descrivere l'obiettivo, probabilmente è una richiesta di funzionalità, non un requisito.
Identifica gli utenti principali
Elenca i ruoli che useranno l'app e cosa necessitano maggiormente:
- Proprietari del rischio (identificano e aggiornano i rischi)
- Proprietari dei controlli (attestano i controlli, allegano evidenze)
- Revisori (approvano modifiche, richiedono aggiornamenti)
- Auditor (accesso in sola lettura, tracciabilità)
- Admin (accesso utenti, configurazione)
Questo evita di costruire per “tutti” e non soddisfare nessuno.
Definisci un ambito v1 realistico
Un v1 pratico per il monitoraggio del rischio operativo di solito si concentra su: un registro dei rischi, scoring base, tracciamento delle azioni e report semplici. Lascia per fasi successive funzionalità più profonde (integrazioni avanzate, gestione tassonomia complessa, builder di workflow personalizzati).
Definisci metriche di successo
Scegli segnali misurabili come: percentuale di rischi con owner, completezza del registro, tempo per chiudere le azioni, tasso di azioni scadute e completamento delle revisioni in tempo. Queste metriche rendono più facile valutare se l'app funziona e cosa migliorare.
Raccogli i requisiti dagli stakeholder
Una web app per il registro dei rischi funziona solo se rispecchia come le persone effettivamente identificano, valutano e seguono i rischi operativi. Prima di parlare di funzionalità, parla con chi userà (o sarà giudicato dai) risultati.
Chi coinvolgere (e perché)
Inizia con un gruppo piccolo e rappresentativo:
- Proprietari delle unità di business che sollevano e gestiscono rischi quotidianamente
- Risk/Compliance che definiscono terminologia, aspettative di scoring e bisogni di report
- Internal audit che tengono all'evidenza, alle approvazioni e alla completezza del registro audit
- IT/Security che controlleranno accessi, retention dati e integrazioni
- Esecutivi/collegamenti al board che consumano sommari e report di trend
Mappa il processo corrente end-to-end
In workshop, mappa il flusso reale passo dopo passo: identificazione del rischio → valutazione → trattamento → monitoraggio → revisione. Cattura dove avvengono le decisioni (chi approva cosa), cosa significa “fatto” e cosa provoca una revisione (basata sul tempo, su un incidente o su una soglia).
Raccogli i punti dolenti da risolvere
Chiedi agli stakeholder di mostrare il foglio di calcolo o la catena di email attuale. Documenta problemi concreti come:
- Mancanza di ownership (confusione tra proprietario rischio, proprietario controllo, proprietario azione)
- Scoring incoerente (i team interpretano probabilità/impatti in modo diverso)
- Debole tracciatura audit (nessuna traccia di chi ha cambiato cosa e perché)
- Confusione delle versioni (più copie della presunta “ultima” versione del registro)
Documenta i workflow e gli eventi richiesti
Scrivi i workflow minimi che l'app deve supportare:
- Creare un nuovo rischio (con campi obbligatori e regole di approvazione)
- Aggiornare un rischio (ri-valutazione, cambio stato, aggiunta note)
- Registrare incidenti e collegarli a rischi/controlli
- Registrare risultati di test sui controlli e relative evidenze
- Creare e tracciare piani d'azione (date di scadenza, promemoria, escalation)
Definisci i report di cui si ha bisogno
Concorda gli output presto per evitare rifacimenti. Necessità comuni includono sintesi per il board, viste per unità di business, azioni scadute e principali rischi per punteggio o trend.
Nota vincoli di compliance (senza promettere certificazioni)
Elenca regole che influenzano i requisiti—es. periodi di retention dei dati, vincoli di privacy per i dati degli incidenti, separazione dei compiti, evidenza di approvazione e restrizioni d'accesso per regione o entità. Mantieni la raccolta fattuale: stai raccogliendo vincoli, non affermando compliance di default.
Progetta il framework di rischio e la terminologia
Prima di costruire schermate o workflow, allinea il vocabolario che l'app implementerà. Terminologia chiara evita che lo stesso rischio venga descritto in modi diversi e rende il reporting affidabile.
Inizia con una tassonomia pratica
Definisci come i rischi saranno raggruppati e filtrati nel registro. Rendila utile sia per la gestione quotidiana che per cruscotti e report.
Livelli di tassonomia tipici: categoria → sottocategoria, mappati a unità di business e (quando utile) processi, prodotti o location. Evita una tassonomia troppo dettagliata che impedisca scelte coerenti; puoi raffinire più tardi quando emergono pattern.
Standardizza la descrizione del rischio e i campi richiesti
Concorda un formato coerente per la dichiarazione del rischio (es. “A causa di causa, può verificarsi evento, portando a impatto”). Poi decidi cosa è obbligatorio:
- Causa, evento, impatto (per analisi significative)
- Proprietario del rischio e team responsabile (per guidare l'azione)
- Stato (bozza, attivo, in revisione, ritirato)
- Date (data di identificazione, ultima valutazione, prossima revisione)
Questa struttura collega controlli e incidenti a una singola narrazione invece di note sparse.
Definisci le dimensioni di valutazione e lo scoring
Scegli le dimensioni di valutazione da supportare nel modello di scoring. Probabilità e impatto sono il minimo; velocità e rilevabilità possono aggiungere valore se i valutatori li useranno coerentemente.
Decidi come gestire rischio inerente vs residuo. Un approccio comune: il rischio inerente è valutato prima dei controlli; il rischio residuo è il punteggio post-controlli, con i controlli collegati esplicitamente in modo che la logica sia spiegabile durante revisioni e audit.
Infine, concorda una scala semplice (spesso 1–5) e scrivi definizioni in linguaggio comune per ogni livello. Se “3 = medio” significa cose diverse per team diversi, il workflow di valutazione genererà rumore invece di insight.
Crea il modello dati (registro rischi, controlli, azioni)
Un modello dati chiaro trasforma un registro tipo spreadsheet in un sistema di cui ci si può fidare. Punta a poche entità principali, relazioni nette e liste di riferimento coerenti così i report restano affidabili con l'aumentare dell'uso.
Entità core (schema minimo)
Inizia con alcune tabelle che mappano direttamente al lavoro delle persone:
- Users e Roles: chi è nel sistema e cosa può fare
- Risks: voce del registro dei rischi (titolo, descrizione, owner, area di business, rating inerente/residuo, stato)
- Assessments: valutazioni puntuali (data, valutatore, input di scoring, note). Tenere le valutazioni separate evita di sovrascrivere la “vista corrente”.
- Controls: salvaguardie legate ai rischi (efficacia di design/operativa, cadenza test, proprietario del controllo)
- Incidents/Events: cosa è successo (data, impatto, causa radice, rischi collegati, fallimenti di controllo collegati)
- Actions: task di remediazione collegati a un rischio, controllo o incidente
- Comments: discussioni e decisioni, idealmente con @mention e timestamp
Relazioni importanti per la tracciabilità
Modella esplicitamente collegamenti molti-a-molti chiave:
- Risk ↔ Controls (via tabella di join) per mostrare quali controlli mitigano quali rischi
- Risk ↔ Incidents per collegare perdite/near-miss al registro
- Actions → Risk/Control/Incident (link polimorfico o tre foreign key nullable) così la remediazione è sempre ancorata
Questa struttura risponde a domande tipo “Quali controlli riducono i nostri rischi principali?” e “Quali incidenti hanno causato un cambiamento del rating?”
Tabelle di storico e “perché è cambiato?”
Il monitoraggio del rischio operativo spesso richiede uno storico difendibile. Aggiungi tabelle di history/audit per Risks, Controls, Assessments, Incidents e Actions con:
- chi ha cambiato, quando e quali campi sono cambiati
- motivo della modifica opzionale (testo libero o codici selezionabili)
Evita di memorizzare solo “ultimo aggiornamento” se sono previste approvazioni e audit.
Tabelle di riferimento per coerenza
Usa tabelle di riferimento (non stringhe hard-coded) per tassonomia, stati, scale severità/probabilità, tipi di controllo e stati azione. Questo evita che i report si rompano per refusi (“High” vs “HIGH”).
Allegati (evidenze) con retention in mente
Tratta le evidenze come dati di prima classe: una tabella Attachments con metadati file (nome, tipo, dimensione, uploader, record collegato, data upload), più campi per data di retention/cancellazione e classificazione di accesso. Archivia i file in object storage, ma conserva le regole di governance nel database.
Pianifica workflow, approvazioni e ownership
Un'app per i rischi fallisce rapidamente quando “chi fa cosa” non è chiaro. Prima di costruire schermate, definisci stati di workflow, chi può muovere gli elementi tra stati e cosa deve essere catturato a ogni passo.
Ruoli e permessi (mantienili semplici)
Inizia con pochi ruoli e amplia solo se necessario:
- Creator: può creare bozze di rischi, controlli, incidenti e azioni
- Risk owner: responsabile dell'accuratezza e delle revisioni
- Approver: valida le voci e può marcarle come “ufficiali”
- Auditor / read-only: può visualizzare, esportare e (opzionalmente) commentare, ma non modificare
- Admin: gestisce configurazione, utenti e permessi
Rendi i permessi espliciti per tipo di oggetto (risk, control, action) e per capacità (creare, modificare, approvare, chiudere, riaprire).
Flusso di approvazione: draft → review → approved → re-review
Usa un ciclo di vita chiaro con gate prevedibili:
- Draft: modificabile; campi incompleti consentiti
- In review: modifiche limitate; richiedi commenti del revisore
- Approved: blocca campi core; le modifiche richiedono richiesta formale di aggiornamento
- Periodic re-review: checkpoint pianificati (es. trimestrali) per confermare che nulla sia cambiato
SLA, promemoria e logica per scaduti
Allega SLA ai cicli di revisione, ai test dei controlli e alle scadenze delle azioni. Invia promemoria prima delle scadenze, escale dopo SLA mancati e mostra gli elementi scaduti in modo evidente (per proprietari e loro manager).
Deleghe, riassegnazioni e accountability
Ogni elemento dovrebbe avere un owner responsabile più eventuali collaboratori. Supporta delega e riassegnazione, ma richiedi un motivo (e opzionalmente una data di efficacia) così i lettori capiscono perché la responsabilità è cambiata e quando.
Progetta l'esperienza utente e le schermate chiave
Allinea gli stakeholder in un unico posto
Porta proprietari dei rischi, revisori e auditor in uno spazio condiviso per testare permessi e flussi.
Un'app per i rischi funziona quando le persone la usano davvero. Per utenti non tecnici, la migliore UX è prevedibile, a basso attrito e coerente: etichette chiare, gergo minimo e abbastanza guida per evitare voci “varie” vaghe.
1) Intake del rischio: rendi i dati corretti il default
Il modulo di inserimento dovrebbe sembrare una conversazione guidata. Aggiungi brevi testi di aiuto sotto i campi (non istruzioni lunghe) e marca come obbligatori solo i campi davvero necessari.
Includi elementi essenziali: titolo, categoria, processo/area, owner, stato corrente, score iniziale e “perché è importante” (narrazione dell'impatto). Se usi lo scoring, integra tooltip accanto a ogni fattore così gli utenti capiscono le definizioni senza lasciare la pagina.
2) Vista elenco rischi: triage e follow-up in un posto
La maggior parte degli utenti vivrà nella vista elenco, quindi rendila veloce per rispondere a: “Cosa richiede attenzione?”
Fornisci filtri e ordinamenti per stato, owner, categoria, punteggio, data ultima revisione e azioni scadute. Evidenzia le eccezioni (revisioni scadute, azioni oltre la scadenza) con badge discreti—non colori allarmanti ovunque—per concentrare l'attenzione sugli elementi giusti.
3) Pagina dettaglio rischio: una storia unica, record connessi
La schermata dettaglio deve leggere come un sommario prima e poi dettaglio di supporto. Mantieni la parte superiore focalizzata: descrizione, punteggio corrente, ultima revisione, prossima revisione e owner.
Sotto, mostra controlli collegati, incidenti e azioni in sezioni separate. Aggiungi commenti per contesto (“perché abbiamo cambiato lo score”) e allegati per le evidenze.
Le azioni necessitano di assegnazione, date di scadenza, progresso, upload di evidenze e criteri chiari di chiusura. Rendi esplicita la chiusura: chi approva la chiusura e quale prova è richiesta.
Se ti serve un layout di riferimento, mantieni la navigazione semplice e coerente tra le schermate (es. /risks, /risks/new, /risks/{id}, /actions).
Implementa lo scoring e la logica di revisione
Lo scoring è dove l'app di monitoraggio del rischio operativo diventa azionabile. L'obiettivo non è “bocciare” i team, ma standardizzare come confrontare i rischi, decidere cosa priorizzare e impedire che gli elementi diventino obsoleti.
Scegli (e documenta) un modello di scoring
Inizia con un modello semplice e spiegabile che funzioni trasversalmente. Un default comune è una scala 1–5 per Probabilità e Impatto, con punteggio calcolato:
- Punteggio = Probabilità × Impatto
Scrivi definizioni chiare per ogni valore (cosa significa “3”, non solo il numero). Metti questa documentazione vicino ai campi nell'interfaccia (tooltip o pannello “Come funziona lo scoring”) così gli utenti non devono cercarla.
Rendi significative le soglie e collegale ad azioni
I numeri da soli non guidano il comportamento—lo fanno le soglie. Definisci i confini per Basso / Medio / Alto (e opzionalmente Critico) e stabilisci cosa attiva ciascun livello.
Esempi:
- Alto: richiede owner, data target e approvazione di management prima della chiusura
- Medio: richiede un piano di mitigazione ma può non necessitare approvazione
- Basso: tracciare e rivedere; nessuna azione immediata richiesta
Mantieni le soglie configurabili, perché ciò che conta come “Alto” varia per unità di business.
Traccia rischio inerente vs residuo
Le discussioni spesso si bloccano quando le persone parlano di cose diverse. Risolvilo separando:
- Rischio inerente: prima dei controlli
- Rischio residuo: dopo aver considerato i controlli
Nell'interfaccia mostra entrambi i punteggi affiancati e mostra come i controlli influenzano il rischio residuo (ad esempio, un controllo può ridurre Probabilità o Impatto di 1). Evita di nascondere la logica dietro aggiustamenti automatici che gli utenti non possono spiegare.
Costruisci regole di revisione configurabili
Aggiungi logica di revisione basata sul tempo così i rischi non invecchino. Una base pratica:
- Rischi alti: revisione trimestrale
- Rischi medi: revisione semestrale
- Rischi bassi: revisione annuale
Rendi la frequenza configurabile per unità di business e consenti override per singolo rischio. Automatizza promemoria e stato “revisione scaduta” basato su data ultima revisione.
Evita scoring in “scatole nere”
Rendi visibile il calcolo: mostra Probabilità, Impatto, eventuali aggiustamenti dei controlli e il punteggio residuo finale. Gli utenti dovrebbero poter rispondere “Perché questo è Alto?” con un colpo d'occhio.
Costruisci audit trail, versioning e gestione delle evidenze
Itera senza rompere la fiducia
Sperimenta con tassonomie e aggiornamenti di scoring, poi effettua rollback rapidamente se serve.
Un tool di rischio è credibile quanto la sua storia. Se uno score cambia, un controllo viene marcato “testato” o un incidente viene riclassificato, serve un record che risponda: chi ha fatto cosa, quando e perché.
Decidi cosa audittare (ed esplicitalo)
Inizia con una lista di eventi chiave per non perdere azioni importanti né inondare il log di rumore. Eventi comuni:
- Create/update/delete su oggetti core (risks, controls, incidents, actions)
- Decisioni di approvazione (inviato, approvato, respinto) e riassegnazione di ownership
- Esportazioni (CSV/PDF), specialmente per team regolamentati
- Eventi di autenticazione (tentativi di login, reset password) e cambi permessi
Cattura “chi/quando/cosa” più contesto
Al minimo, memorizza attore, timestamp, tipo/ID oggetto e i campi cambiati (vecchio valore → nuovo valore). Aggiungi una nota opzionale “motivo della modifica”—previene confusione successiva (“cambiato punteggio residuo dopo revisione trimestrale”).
Tieni il log append-only. Evita modifiche, anche da admin; se serve una correzione crea un nuovo evento che faccia riferimento al precedente.
Fornisci una vista read-only del log di audit
Auditor e admin di solito necessitano di una vista dedicata e filtrabile: per intervallo di date, oggetto, utente e tipo di evento. Rendi semplice l'export da questa schermata pur loggando l'evento di export stesso. Se hai un'area admin, collega la vista da /admin/audit-log.
Versiona le evidenze ed evita sovrascritture silenziose
I file di evidenza (screenshot, risultati di test, policy) devono essere versionati. Tratta ogni upload come una nuova versione con timestamp e uploader, e conserva le versioni precedenti. Se sono consentiti i rimpiazzi, richiedi una nota motivo e mantieni entrambe le versioni.
Definisci retention e accesso per evidenze sensibili
Imposta regole di retention (es. mantenere eventi audit per X anni; eliminare evidenze dopo Y salvo legal hold). Restringi l'accesso alle evidenze con permessi più stretti rispetto al record del rischio quando contengono dati personali o dettagli di sicurezza.
Affronta sicurezza, privacy e controllo accessi
Sicurezza e privacy non sono “extra”—modellano la fiducia necessaria per segnalare incidenti, allegare evidenze e assegnare responsabilità. Inizia mappando chi ha bisogno di accesso, cosa deve vedere e cosa va limitato.
Autenticazione: SSO vs email/password
Se la tua organizzazione usa già un identity provider (Okta, Azure AD, Google Workspace), dai priorità al Single Sign-On tramite SAML o OIDC. Riduce i rischi delle password, semplifica onboarding/offboarding e si allinea alle policy corporate.
Se costruisci per team più piccoli o utenti esterni, email/password può funzionare—ma abbina a regole forti per le password, recupero sicuro e, dove possibile, MFA.
RBAC che rispecchia come si lavora
Definisci ruoli che riflettono responsabilità reali: admin, risk owner, revisore/approvatore, collaboratore, lettore, auditor.
Il rischio operativo richiede spesso confini più rigidi di un tool interno tipico. Considera RBAC che possa limitare accesso:
- Per unità di business/departimento (es. Finance non vede incidenti HR)
- Per record (es. solo il team investigativo può accedere a un incidente sensibile)
Mantieni i permessi comprensibili—le persone devono capire rapidamente perché possono o non possono vedere un record.
Protezioni base dei dati da considerare non negoziabili
Usa crittografia in transito (HTTPS/TLS) ovunque e applica il principio del least privilege per servizi applicativi e database. Le sessioni dovrebbero essere protette con cookie sicuri, timeout di inattività brevi e invalidazione server-side al logout.
Sensibilità a livello di campo e redazione
Non tutti i campi hanno lo stesso rischio. Narrazioni degli incidenti, note sull'impatto cliente o dettagli dei dipendenti possono richiedere controlli più stretti. Supporta visibilità a livello di campo (o almeno redazione) così gli utenti possono collaborare senza esporre contenuti sensibili ampiamente.
Salvaguardie amministrative
Aggiungi alcuni guardrail pratici:
- Log attività admin (chi cambia permessi, esportazioni, configurazioni)
- IP allowlist opzionale per ambienti ad alto rischio
- MFA per admin (anche se altri non la usano)
Fatti bene, questi controlli proteggono i dati mantenendo comunque fluide le attività di reporting e remediazione.
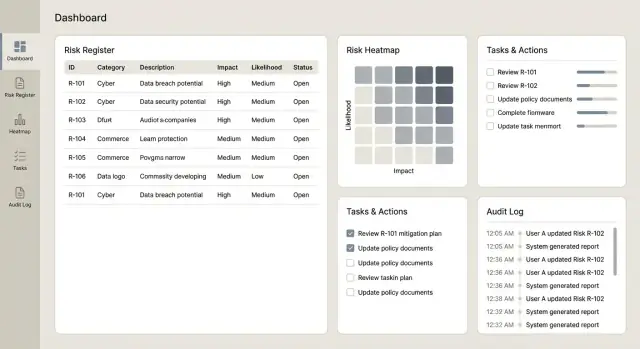
Fornisci dashboard, report e export
Dashboard e report sono dove l'app dimostra valore: trasformano un lungo registro in decisioni chiare per owner, manager e comitati. La chiave è rendere i numeri tracciabili fino alle regole di scoring e ai record sottostanti.
Cruscotti che le persone useranno davvero
Inizia con poche viste ad alto segnale che rispondono rapidamente a domande comuni:
- Rischi principali per punteggio residuo (con possibilità di passare a inerente)
- Trend nel tempo (es. trend del rischio residuo per mese/trimestre)
- Distribuzione residuo vs inerente, incluso un semplice confronto “prima vs dopo controlli”
- Una heatmap del rischio (probabilità × impatto) che colleghi ogni cella ai rischi sottostanti
Rendi ogni riquadro cliccabile così gli utenti possono approfondire la lista di rischi, controlli, incidenti e azioni dietro il grafico.
Viste operative per la gestione quotidiana
I cruscotti decisionali sono diversi dalle viste operative. Aggiungi schermate focalizzate su cosa serve questa settimana:
- Azioni scadute (per owner/team, con giorni di ritardo)
- Revisioni imminenti (rischi o controlli da rivedere)
- Test controlli falliti (fallimenti recenti, severità e remediazione aperta)
- Frequenza incidenti (conteggi e tassi nel tempo, con filtri per processo/categoria)
Queste viste funzionano bene con promemoria e ownership così l'app sembra un vero strumento di workflow, non solo un database.
Export utili per comitati e audit
Pianifica gli export presto, perché i comitati spesso usano pacchetti offline. Supporta CSV per analisi e PDF per distribuzione in sola lettura, con:
- Filtri (unità di business, categoria, owner, stato)
- Intervalli di date (incidenti nel periodo, azioni create/chiuse nel periodo)
- Etichette chiare (inerente vs residuo, date versione e filtri applicati)
Se hai già un template per il pack di governance, rispecchialo così l'adozione è più semplice.
Assicurati che ogni definizione di report corrisponda alle regole di scoring. Per esempio, se il cruscotto indica “rischi top” per punteggio residuo, deve allinearsi allo stesso calcolo usato nel record e negli export.
Per registri grandi, progetta per performance: paginazione nelle liste, caching per aggregati comuni e generazione report async (genera in background e notifica quando pronto). Se aggiungi report schedulati, conserva link interni (es. salva configurazione report riapribile da /reports).
Pianifica integrazioni e migrazione dati
Valida l'UX con UI reale
Avvia pagine di intake, elenco e dettaglio così gli utenti possono testare il flusso invece di discuterlo.
Integrazioni e migrazione determinano se l'app diventerà il sistema di record o solo un altro posto da dimenticare. Pianificale presto, ma implementale in modo incrementale per mantenere il core stabile.
Parti dai workflow che le persone già usano
La maggior parte dei team non vuole “un'altra lista di task”. Vogliono che l'app si connetta ai luoghi dove il lavoro avviene:
- Jira o ServiceNow per creare e tracciare azioni di remediazione (e sincronizzare lo stato)
- Slack o Microsoft Teams per avvisi quando un rischio è escalato, una revisione è dovuta o si richiede evidenza
- Email per promemoria periodici e approvazioni (utile per utenti occasionali)
Un approccio pratico è mantenere l'app dei rischi come owner dei dati di rischio, mentre strumenti esterni gestiscono i dettagli di esecuzione (ticket, assegnatari, scadenze) e inviano aggiornamenti di progresso.
Popola il registro da spreadsheet—in sicurezza
Molte organizzazioni partono da Excel. Fornisci un'importazione che accetti formati comuni, ma aggiungi guardrail:
- Regole di validazione (campi obbligatori, formati date, range numerici)
- Rilevamento duplicati (es. stesso titolo rischio + processo + owner) con opzione “merge/skip”
- Forzatura tassonomia (unità di business, processo, categoria rischio) per evitare report sporchi dopo
Mostra un'anteprima di cosa verrà creato, cosa verrà rifiutato e perché. Quella schermata può far risparmiare ore di chiarimenti.
Basi API per ridurre problemi futuri
Anche se inizi con una sola integrazione, progetta l'API come se ne avessi diverse:
- Mantieni endpoint coerenti e naming (es. /risks, /controls, /actions)
- Assicura audit logging sulle scritture (chi ha cambiato cosa, quando e da dove)
- Aggiungi rate limiting e codici errore chiari così le integrazioni falliscono in modo gestibile
Gestisci i fallimenti con retry e stato visibile
Le integrazioni falliscono per motivi normali: cambi permessi, timeout di rete, ticket cancellati. Progetta per questo:
- Accoda richieste outbound e ritenta con backoff
- Registra uno stato integrazione su ogni elemento collegato (“Synced”, “Pending”, “Failed”)
- Fornisci messaggi azionabili (“ServiceNow token scaduto—riconnetti”) e un pulsante manuale “Retry now”
Questo mantiene alta la fiducia e previene derive silenziose tra registro e strumenti di esecuzione.
Testa, lancia e migliora nel tempo
Un'app di rischio diventa preziosa quando le persone si fidano e la usano costantemente. Tratta test e rollout come parte del prodotto, non come l'ultimo step.
Costruisci una strategia di test pratica
Inizia con test automatizzati per le parti che devono comportarsi sempre allo stesso modo—soprattutto scoring e permessi:
- Unit tests per lo scoring: verifica calcoli probabilità/impatti, soglie, arrotondamenti e edge case (es. “N/A”, campi mancanti, override)
- Workflow tests per approvazioni: assicurati che i cambi di stato seguano le regole (draft → submitted → approved), incluse riassegnazioni e percorsi di rifiuto
- Permission tests: conferma che i lettori non possano modificare, che gli owner non possano approvare le proprie submission (se questa è la policy) e che gli admin possano auditare senza rompere la segregazione dei compiti
Esegui UAT con scenari reali
L'UAT funziona meglio quando rispecchia il lavoro reale. Chiedi a ogni unità di business un piccolo set di rischi, controlli, incidenti e azioni campione, poi esegui scenari tipici:
- crea un rischio, collega controlli e invia per approvazione
- aggiorna dopo un incidente e allega evidenze
- completa un'azione e verifica i cambi nel reporting
Raccogli non solo bug, ma etichette confuse, stati mancanti e campi che non rispecchiano il linguaggio dei team.
Rollout pilota prima di andare company-wide
Lancia prima a un team (o a una regione) per 2–4 settimane. Mantieni lo scope controllato: un singolo workflow, pochi campi e una metrica di successo chiara (es. % rischi rivisti in tempo). Usa il feedback per aggiustare:
- nomi dei campi e obbligatorietà
- passi di approvazione e regole di ownership
- tempistiche dei promemoria ed escalation
Fornisci guide pratiche e un glossario di una pagina: cosa significa ogni score, quando usare ogni stato e come allegare evidenze. Una sessione live di 30 minuti più clip registrate spesso è più efficace di un manuale lungo.
Costruisci più velocemente con Koder.ai (opzionale)
Se vuoi arrivare a una v1 credibile rapidamente, una piattaforma vibe-coding come Koder.ai può aiutare a prototipare e iterare i workflow senza una lunga fase di setup. Puoi descrivere schermate e regole (intake rischio, approvazioni, scoring, promemoria, viste audit) in chat e poi raffinare l'app generata man mano che gli stakeholder provano l'interfaccia.
Koder.ai è progettata per la delivery end-to-end: supporta la costruzione di web app (comunemente React), servizi backend (Go + PostgreSQL) e include funzionalità pratiche come export del codice sorgente, deployment/hosting, domini custom e snapshot con rollback—utile quando cambi tassonomie, scale di scoring o flussi di approvazione e hai bisogno di iterare in sicurezza. I team possono iniziare con un piano free e salire a pro, business o enterprise a seconda dei requisiti di governance e scala.
Mantieni l'app sana dopo il lancio
Pianifica operazioni continue: backup automatici, monitoraggio uptime/errori e un processo leggero per cambi di tassonomia e scale di scoring così gli aggiornamenti restino coerenti e tracciabili nel tempo.