15 nov 2025·8 min
Crea un'app web che monitora la salute dell'app e i KPI di business
Scopri come costruire un'app web che unifica uptime, latenza e errori con ricavi, conversioni e churn—con dashboard, alert e progettazione dei dati.
Scopri come costruire un'app web che unifica uptime, latenza e errori con ricavi, conversioni e churn—con dashboard, alert e progettazione dei dati.
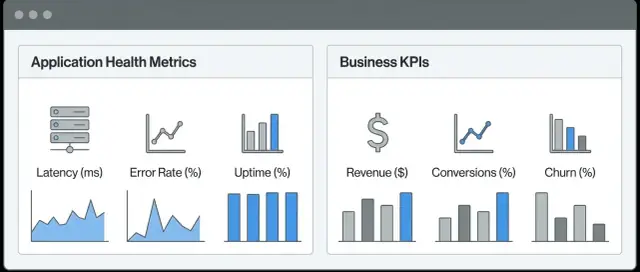
Una vista combinata “Salute dell'app + KPI di business” è un unico posto dove i team possono vedere se il sistema funziona e se il prodotto sta producendo i risultati che contano per l'azienda. Invece di saltare tra uno strumento di osservabilità per gli incidenti e uno strumento di analytics per le performance, colleghi i punti in un solo flusso di lavoro.
Metriche tecniche descrivono il comportamento del software e dell'infrastruttura. Rispondono a domande come: l'app risponde? Ci sono errori? È lenta? Esempi comuni includono latenza, tasso di errori, throughput, uso CPU/memoria, profondità delle code e disponibilità delle dipendenze.
Metriche di business (KPI) descrivono i risultati degli utenti e dei ricavi. Rispondono a domande come: gli utenti raggiungono i loro obiettivi? Stiamo generando ricavi? Esempi: iscrizioni, tasso di attivazione, conversione, completamento del checkout, valore medio ordine, churn, rimborsi e volume ticket di supporto.
L'obiettivo non è sostituire una categoria con l'altra, ma collegarle, così un picco di errori 500 non è solo “rosso su un grafico”, ma è chiaramente connesso a “la conversione del checkout è calata del 12%”.
Quando i segnali di salute e i KPI condividono la stessa interfaccia e finestra temporale, i team di solito ottengono:
Questa guida si concentra su struttura e decisioni: come definire metriche, collegare identificatori, archiviare e interrogare dati, e presentare dashboard e alert. Non è legata a un vendor specifico, così puoi applicare l'approccio sia che tu usi strumenti pronti, costruisca internamente o faccia entrambe le cose.
Se provi a tracciare tutto, finirai con una dashboard di cui nessuno si fida. Inizia decidendo cosa deve aiutare l'app di monitoraggio a fare sotto pressione: prendere decisioni rapide e corrette durante un incidente e tracciare i progressi settimana dopo settimana.
Quando qualcosa va storto, le tue dashboard dovrebbero rispondere velocemente:
Se un grafico non aiuta a rispondere a una di queste, è candidato alla rimozione.
Mantieni il set di base piccolo e coerente tra i team. Una lista di partenza utile:
Queste mappano bene ai comuni failure mode e sono facili da alertare dopo.
Scegli metriche che rappresentano il funnel cliente e la realtà dei ricavi:
Per ogni metrica, definisci un owner, una definizione/fonte di verità e una cadenza di revisione (settimanale o mensile). Se nessuno possiede una metrica, diventerà fuorviante e le decisioni sugli incidenti ne risentiranno.
Se i grafici di salute vivono in uno strumento e la dashboard dei KPI in un altro, è facile litigare su “cosa è successo” durante un incidente. Ancorare il monitoraggio attorno a pochi customer journey in cui le performance influenzano chiaramente gli esiti.
Scegli flussi che guidano direttamente ricavi o retention, come onboarding, ricerca, checkout/pagamento, login account o pubblicazione contenuti. Per ogni journey definisci i passi chiave e cosa significa “successo”.
Esempio (checkout):
Mappa i segnali tecnici che influenzano maggiormente ogni passo. Qui il monitoraggio diventa rilevante per il business.
Per il checkout, un indicatore anticipatorio potrebbe essere “p95 di latenza dell'API di pagamento”, mentre un indicatore ritardato è “tasso di conversione del checkout”. Vederli entrambi sulla stessa timeline rende più chiara la catena causale.
Un dizionario evita confusione e dibattiti “stesso KPI, matematica diversa”. Per ogni metrica documenta:
Page view, iscrizioni grezze o “sessioni totali” possono essere rumorose senza contesto. Preferisci metriche legate a decisioni (completion rate, burn dell'error budget, revenue per visita). Deduplica anche i KPI: una definizione ufficiale batte tre dashboard concorrenti che differiscono del 2%.
Prima di scrivere codice UI, decidi cosa stai effettivamente costruendo. Un'app “salute + KPI” solitamente ha cinque componenti core: collector (metriche/log/trace ed eventi prodotto), ingestione (code/ETL/streaming), storage (time-series + warehouse), una API dati (per query e permessi coerenti) e una UI (dashboard + drill-down). Alerting può far parte della UI o essere delegato a un sistema on-call esistente.
Se stai prototipando la UI e il workflow velocemente, una piattaforma vibe-coding come Koder.ai può aiutarti a mettere in piedi una shell dashboard React con backend Go + PostgreSQL partendo da una specifica guidata via chat, poi iterare su navigazione e filtri prima di impegnarti in una riscrittura della piattaforma dati.
Pianifica ambienti separati presto: i dati di produzione non devono essere mescolati con staging/dev. Mantieni project ID, API key e bucket/tabelle di storage distinti. Se vuoi “confrontare prod vs staging”, fallo tramite una vista controllata nell'API, non condividendo pipeline raw.
Una vista unica non significa reimplementare ogni visualizzazione. Puoi:
Se scegli l'embedding, definisci uno standard di navigazione chiaro (es.: “da card KPI a vista trace”) così gli utenti non sembrino rimbalzati tra strumenti.
Le tue dashboard saranno affidabili quanto i dati sottostanti. Prima di costruire pipeline, elenca i sistemi che già “sanno” cosa succede e decidi ogni quanto ciascuno va aggiornato.
Inizia con le sorgenti che spiegano affidabilità e performance:
Una regola pratica: tratta i segnali di salute come near-real-time per default, perché guidano alert e risposta agli incidenti.
I KPI di business spesso vivono in strumenti posseduti da team diversi:
Non tutti i KPI necessitano aggiornamenti ogni secondo. I ricavi giornalieri possono essere batch; la conversione al checkout potrebbe richiedere dati più freschi.
Per ogni KPI annota un'aspettativa di latenza semplice: “Aggiornamenti ogni 1 minuto”, “Ogni ora”, o “Il giorno lavorativo successivo”. Riflettilo direttamente nella UI (es.: “Dati aggiornati alle 10:35 UTC”). Questo evita falsi allarmi e discussioni su numeri “sbagliati” che sono semplicemente in ritardo.
Per collegare un picco di errori a ricavi persi, servono ID coerenti:
Definisci una “fonte di verità” per ogni identificatore e assicurati che ogni sistema lo trasporti (eventi analytics, log, record di billing). Se i sistemi usano chiavi diverse, aggiungi presto una tabella di mapping: ricucire a posteriori è costoso e rischioso.
Se cerchi di mettere tutto in un unico DB, di solito otterrai dashboard lente, query costose o entrambi. Un approccio più pulito tratta telemetria di salute e KPI di business come forme di dati diverse con pattern di lettura diversi.
Le metriche di salute (latenza, tasso di errori, CPU, profondità code) sono ad alto volume e interrogate per intervalli temporali: “ultimi 15 minuti”, “confronta con ieri”, “p95 per servizio”. Un DB time-series è ottimizzato per rollup rapidi e scansioni su intervalli.
Mantieni tag/label limitati e coerenti (service, env, region, endpoint group). Troppe label uniche esplodono la cardinalità e i costi.
I KPI di business (iscrizioni, conversioni a pagamento, churn, ricavi, ordini) spesso necessitano di join, backfill e reporting “as-of”. Un warehouse/lake è meglio per:
La tua web app non dovrebbe parlare direttamente a entrambi gli store dal browser. Costruisci una API backend che interroga ogni store, applica permessi e restituisce uno schema coerente. Pattern tipico: i pannelli di salute interrogano il time-series; i pannelli KPI il warehouse; gli endpoint di drill-down possono prendere da entrambi e fondere per finestra temporale.
Stabilisci tier chiari:
Pre-aggregare le viste dashboard comuni (orario/giornaliero) così la maggior parte degli utenti non innesca query costose “scan everything”.
La tua UI sarà usabile quanto l'API sottostante. Una buona API rende le viste comuni della dashboard rapide e prevedibili, permettendo comunque di cliccare nei dettagli senza caricare un prodotto totalmente diverso.
Progetta endpoint che corrispondono alla navigazione principale, non ai DB sottostanti:
GET /api/dashboards e GET /api/dashboards/{id} per recuperare layout salvati, definizioni dei grafici e filtri predefiniti.GET /api/metrics/timeseries per grafici di salute e KPI con from, to, interval, timezone e filters.GET /api/drilldowns (o /api/events/search) per “mostrami le richieste/ordini/utenti sottostanti” dietro a un segmento di grafico.GET /api/filters per enumerazioni (regioni, piani, environment) e per alimentare typeahead.Le dashboard raramente necessitano dati raw; richiedono riassunti:
Aggiungi caching per richieste ripetute (stessa dashboard, stessa finestra) e applica rate limit per query ampie. Considera limiti separati per drill-down interattivi vs refresh schedulati.
Rendi i grafici comparabili restituendo sempre gli stessi confini di bucket e unità: timestamp allineati all'intervallo scelto, campi unit espliciti (ms, %, USD) e regole di arrotondamento stabili. La coerenza evita salti confusi quando si cambiano filtri o ambienti.
Una dashboard funziona quando risponde rapidamente a: “Stiamo bene?” e “Se no, dove guardo dopo?” Progetta attorno alle decisioni, non a tutto ciò che puoi misurare.
La maggior parte dei team va meglio con poche viste intenzionali piuttosto che una mega-dashboard:
Metti un time picker unico in cima a ogni pagina e mantienilo coerente. Aggiungi filtri globali realmente usati—regione, piano, piattaforma, e magari segmento cliente. L'obiettivo è confrontare “US + iOS + Pro” con “EU + Web + Free” senza ricostruire i grafici.
Includi almeno un pannello di correlazione per pagina che sovrappone segnali tecnici e business sulla stessa asse temporale. Per esempio:
Questo aiuta stakeholder non tecnici a vedere l'impatto e gli ingegneri a dare priorità a fix che proteggono gli esiti.
Evita il disordine: meno grafici, font più grandi, etichette chiare. Ogni grafico chiave dovrebbe mostrare soglie (buono / attenzione / critico) e lo stato corrente dovrebbe essere leggibile senza hover. Se una metrica non ha un intervallo buono/cattivo concordato, di solito non è pronta per la homepage.
Il monitoraggio è utile solo se guida l'azione corretta. Gli SLO ti aiutano a definire il “sufficiente” in modo che corrisponda all'esperienza utente—e gli alert ti aiutano a reagire prima che i clienti lo notino.
Scegli SLI che gli utenti percepiscono: errori, latenza e disponibilità su journey chiave come login, ricerca e pagamento—non metriche interne.
Quando possibile, allerta sui sintomi di impatto utente prima che sulle cause probabili:
Gli alert sulle cause rimangono utili, ma quelli basati sui sintomi riducono il rumore e focalizzano il team su cosa vedono i clienti.
Per collegare salute e KPI, aggiungi pochi alert che rappresentano rischio reale di ricavo o crescita, come:
Collega ogni alert a un’“azione attesa”: investigare, rollbackare, cambiare provider o avvisare support.
Definisci livelli di severità e regole di routing:
Ogni alert deve rispondere: cosa è impattato, quanto è grave e cosa deve fare qualcuno dopo?
Mescolare monitoraggio di salute applicativa e dashboard KPI aumenta la posta in gioco: una schermata potrebbe mostrare tassi di errore accanto a ricavi, churn o nomi clienti. Se i permessi e la privacy vengono aggiunti tardi, finirai o per sovra-restringere il prodotto (nessuno lo usa) o per sovra-esporre dati (rischio reale).
Inizia definendo ruoli attorno alle decisioni, non all'organigramma. Per esempio:
Applica il principio del minimo privilegio: gli utenti vedono il minimo necessario e richiedono accesso più ampio quando giustificato.
Tratta la PII come classe separata con regole più severe:
Se devi unire segnali di osservabilità ai record cliente, fallo con identificatori non-PII stabili (tenant_id, account_id) e mantieni il mapping sotto controlli d'accesso più rigidi.
I team perdono fiducia quando le formule KPI cambiano di nascosto. Traccia:
Esponi questo come log di audit e allegalo ai widget chiave.
Se più team o clienti useranno l'app, progetta la tenancy presto: token con scope, query tenant-aware e isolamento stringente di default. È molto più semplice che retrofit dopo l'integrazione analytics e la risposta agli incidenti.
Testare un prodotto “salute + KPI” non riguarda solo il caricamento dei grafici. Riguarda la fiducia nei numeri e la capacità di agire rapidamente. Prima che qualcuno esterno veda il prodotto, valida correttezza e velocità in condizioni realistiche.
Tratta la tua app di monitoraggio come un prodotto a sé con target propri. Definisci obiettivi di performance come:
Esegui questi test anche nei “giorni peggiori” realistici—metriche ad alta cardinalità, range temporali ampi e picchi di traffico.
Una dashboard può sembrare a posto mentre la pipeline fallisce silenziosamente. Aggiungi controlli automatici e rendili visibili in una vista interna:
Questi controlli devono fallire rumorosamente in staging così non scopri problemi in produzione.
Crea dataset sintetici che includano edge case: zeri, spike, rimborsi, eventi duplicati e confini di fuso orario. Poi riproduci pattern di traffico reali (con identificatori anonimizzati) in staging per validare dashboard e alert senza rischiare impatto sui clienti.
Per ogni KPI core definisci una routine ripetibile di verifica:
Se non sai spiegare un numero a uno stakeholder non tecnico in un minuto, non è pronto per il rilascio.
Una app combinata funziona solo se le persone le si fidano, la usano e la mantengono aggiornata. Tratta il rollout come il lancio di un prodotto: parti piccolo, dimostra valore e costruisci abitudini.
Scegli un singolo customer journey che interessa a tutti (es.: checkout) e un servizio backend principale che lo supporta. Per quella fetta, rilascia:
Questo approccio rende chiaro lo scopo dell'app e mantiene gestibile il dibattito iniziale su “quali metriche contano”.
Imposta una review ricorrente di 30–45 minuti con product, support e engineering. Mantienila pratica:
Tratta le dashboard inutilizzate come segnale per semplificare. Tratta gli alert rumorosi come bug.
Assegna ownership (anche condivisa) e esegui una checklist leggera mensile:
Una volta stabile la prima slice, espandi al prossimo journey o servizio seguendo lo stesso schema.
Se vuoi idee di implementazione ed esempi, sfoglia /blog. Se stai valutando build vs buy, confronta opzioni e scope su /pricing.
Se vuoi accelerare la prima versione funzionante (UI dashboard + layer API + auth), Koder.ai può essere un punto pragmatico di partenza—soprattutto per team che vogliono un frontend React con backend Go + PostgreSQL, più l'opzione di esportare il codice sorgente quando sei pronto a integrarlo nel flusso di ingegneria standard.
È un unico flusso di lavoro (di solito una dashboard con drill-down) dove vedi insieme i segnali di salute tecnica (latenza, errori, saturazione) e gli esiti di business (conversione, ricavi, churn) sulla stessa linea temporale.
L'obiettivo è la correlazione: non solo “qualcosa è rotto”, ma “gli errori nel checkout sono aumentati e la conversione è scesa”, così puoi dare priorità alle correzioni in base all'impatto.
Perché è molto più semplice gestire gli incidenti quando puoi confermare subito l'impatto sul cliente.
Invece di indovinare se un picco di latenza è rilevante, lo convalidi con KPI come acquisti/minuto o tasso di attivazione e decidi se allertare, rollbackare o monitorare.
Inizia dalle domande di incidente:
Poi scegli 5–10 metriche di salute (availability, latency, error rate, saturation, traffic) e 5–10 KPI (signups, activation, conversion, revenue, retention). Mantieni la homepage minimale.
Scegli 3–5 journey critici che mappano direttamente a ricavi o retention (checkout/payment, login, onboarding, ricerca, publishing).
Per ogni journey definisci:
Questo mantiene le dashboard allineate agli esiti invece che ai dettagli infrastrutturali.
Un dizionario di metriche evita i problemi di “stesso KPI, calcoli diversi”. Per ogni metrica documenta:
Considera le metriche senza owner come deprecate finché qualcuno non le mantiene.
Se i sistemi non condividono identificatori coerenti non puoi collegare in modo affidabile errori e esiti.
Standardizza e porta ovunque:
user_idaccount_id / org_idorder_id / invoice_idUna divisione pratica è:
Aggiungi un'API dati backend che interroga entrambi, applica permessi e restituisce bucket/unità coerenti alla UI.
Usa questa regola:
“Single pane” non richiede di reimplementare ogni cosa.
Allerta prima sui sintomi dell'impatto utente, poi sui possibili cause.
Buoni alert di sintomo:
Aggiungi un piccolo set di alert a impatto business (calo di conversione, errori di pagamento, calo degli ordini/minuto) con azioni attese chiare (investigare, rollback, cambiare provider, avvisare support).
Mescolare monitoraggio operativo e KPI aumenta i rischi di privacy e fiducia.
Implementa:
Preferisci ID non-PII stabili (come ) per le join.
Se le chiavi differiscono tra gli strumenti, crea presto una tabella di mapping; ricucire a posteriori è costoso e spesso inaccurato.
account_id