Definire l'impatto di un incidente e le decisioni che deve supportare
Prima di costruire calcoli o dashboard, decidete cosa significa “impatto” nella vostra organizzazione. Se saltate questo passaggio otterrete uno score che sembra scientifico ma non aiuta nessuno a decidere.
Cosa conta come “impatto” (e cosa non conta)
L'impatto è la conseguenza misurabile di un incidente su qualcosa che il business considera importante. Dimensioni comuni includono:
- Utenti: numero di utenti che non riescono ad accedere, picchi di error-rate su flussi chiave, latenza degradata per una regione.
- Ricavi: checkout che falliscono, rinnovi bloccati, impression pubblicitarie in calo.
- Rischio SLA/SLO: minuti di downtime rispetto a un obiettivo di uptime, consumo del budget di errori.
- Team interni: volume di ticket di supporto, carico on-call, deploy bloccati.
Scegliete 2–4 dimensioni principali e definitele esplicitamente. Per esempio: “Impatto = clienti paganti interessati + minuti di SLA a rischio”, non “Impatto = tutto ciò che sembra brutto nei grafici”.
Chi usa l'app e cosa gli serve nei primi 10 minuti
Ruoli diversi prendono decisioni diverse:
- Incident commander ha bisogno di un riepilogo rapido e difendibile: cosa si è rotto, chi è impattato e come evolve.
- Support ha bisogno della portata verso i clienti: quali account, regioni o piani sono coinvolti.
- Engineering ha bisogno di un'ipotesi sul blast radius per guidare debug e mitigazione.
- Executive ha bisogno di una sintesi business: gravità, impatto sui clienti e confidenza nell'ETA.
Progettate gli output di “impatto” in modo che ogni pubblico possa rispondere alla propria domanda principale senza dover tradurre metriche.
Tempo reale vs quasi in tempo reale: fissate le aspettative subito
Decidete quale latenza è accettabile. “Tempo reale” è costoso e spesso non necessario; quasi in tempo reale (es. 1–5 minuti) può essere sufficiente per le decisioni.
Documentatelo come requisito di prodotto perché influisce su ingestione, caching e UI.
Decisioni che l'app dovrebbe abilitare durante un incidente
Il vostro MVP dovrebbe supportare direttamente azioni come:
- Dichiarare gravità e livello di escalation
- Attivare comunicazioni ai clienti (status page, macro di supporto)
- Prioritizzare il lavoro di mitigazione (quale servizio/team prima)
- Decidere rollback, feature flag o spostamenti di traffico
- Identificare quali clienti contattare proattivamente
Se una metrica non cambia una decisione, probabilmente non è “impatto” ma solo telemetria.
Prima di progettare schermate o scegliere un database, scrivete cosa deve rispondere l'analisi d'impatto durante un incidente reale. L'obiettivo non è la precisione perfetta dal primo giorno, ma risultati coerenti e spiegabili di cui i responder possano fidarsi.
Iniziate con i dati che dovete ingerire o consultare per calcolare l'impatto:
- Incidenti: ID, orari di inizio/fine, stato, team responsabile, sommario, link al canale/ticket dell'incidente.
- Servizi: lista canonica dei servizi (nome, owner, tier/criticità, link al runbook).
- Dipendenze: quali servizi dipendono da quali altri (anche se la prima versione è approssimativa).
- Segnali di telemetria: alert, consumo SLO, error rate/latency, eventi di deploy—qualunque cosa indichi degrado.
- Clienti: ID account, piano/SLA, regione, contatti chiave, e come gli account mappano ai servizi (direttamente o tramite workload).
Opzionale al lancio (pianificatelo, non richiederlo)
La maggior parte dei team non ha mappature perfette di dipendenze o clienti dal primo giorno. Decidete cosa permetterete di inserire manualmente per mantenere utile l'app:
- Selezione manuale di servizi/clienti impattati quando mancano i dati
- Stima dell'orario d'inizio o della portata quando la telemetria è ritardata
- Override con motivazione (es. “falso positivo”, “impatto solo interno”)
Progettate questi campi come campi espliciti (non note libere) in modo che siano interrogabili in seguito.
Output chiave (cosa l'app deve produrre)
La prima release dovrebbe generare in modo affidabile:
- Servizi impattati e un chiaro “perché” (segnali + dipendenze)
- Lista clienti con conteggi per piano/regione e una vista dei “top account”
- Score di gravità/impatto spiegabile in linguaggio semplice
- Timeline di quando l'impatto è iniziato, ha raggiunto il picco e si è risolto
- Opzionale ma utile: una stima dei costi (crediti SLA, carico supporto, rischio di ricavo) con range di confidenza
Vincoli non funzionali (ciò che lo rende affidabile)
L'analisi d'impatto è uno strumento decisionale, quindi i vincoli contano:
- Latenza: le dashboard devono caricarsi in secondi durante un incidente
- Disponibilità: trattatela come uno strumento interno critico; definite un target di disponibilità
- Auditabilità: loggate chi ha cambiato un override, quando e quale fosse il valore precedente
- Controllo accessi: limitate dati sensibili dei clienti; separate permessi di lettura e scrittura
Scrivete questi requisiti come affermazioni testabili. Se non potete verificarli, non potete farvi affidamento durante un outage.
Modello dati: incidenti, servizi, dipendenze e clienti
Il vostro modello dati è il contratto tra ingestione, calcolo e UI. Se lo fate bene, potete sostituire sorgenti strumenti, rifinire lo scoring e continuare a rispondere alle stesse domande: “Cosa si è rotto?”, “Chi è impattato?” e “Per quanto tempo?”.
Entità core (mantenerle piccole e collegabili)
Al minimo, modellate questi record come entità di prima classe:
- Incident: contenitore narrativo (titolo, gravità, stato, owner), più puntatori alle prove.
- Service: unità per cui mappate dipendenze (API, DB, queue, provider terzi).
- Dependency: un arco direzionale servizio A → servizio B con metadata (tipo, criticità).
- Signal: un'osservazione timestampata (alert, consumo SLO, picco di errori, check sintetico fallito).
- Customer: un account o organizzazione che consuma servizi.
- Subscription/SLA: cosa spetta al cliente (piano, target SLA/SLO, regole di reporting).
Mantenete gli ID stabili e coerenti tra le sorgenti. Se avete già un catalogo servizi, trattatelo come fonte di verità e mappate gli identificatori esterni in esso.
Modellazione del tempo (l'impatto è una finestra temporale)
Conservate più timestamp sull'incidente per supportare report e analisi:
- start_time / end_time: finestra di impatto effettiva (può essere raffinata dopo)
- detection_time: quando lo abbiamo scoperto
- mitigation_time: quando le azioni hanno iniziato a ridurre l'impatto
Conservate anche finestre temporali calcolate per lo scoring dell'impatto (es. bucket da 5 minuti). Questo rende semplici replay e confronti.
Relazioni che alimentano “chi è impattato?”
Modellate due grafi chiave:
- Dipendenze servizio→servizio (blast radius)
- Uso cliente→servizio (scope impattato)
Un pattern semplice è customer_service_usage(customer_id, service_id, weight, last_seen_at) così potete ordinare l'impatto per “quanto il cliente dipende dal servizio”.
Versioning e cronologia (le dipendenze cambiano)
Le dipendenze evolvono e i calcoli d'impatto dovrebbero riflettere ciò che era vero al momento. Aggiungete dating efficace agli archi:
dependency(valid_from, valid_to)
Fatelo anche per le sottoscrizioni dei clienti e gli snapshot di utilizzo. Con versioni storiche potete rieseguire incidenti passati durante il post-incident review e produrre reporting SLA coerente.
Raccogliere e normalizzare i dati dagli strumenti
L'analisi d'impatto è valida quanto gli input che la alimentano. L'obiettivo è semplice: prelevare segnali dagli strumenti che già usate e convertirli in uno stream di eventi coerente che l'app possa interpretare.
Cosa ingerire (e perché)
Partite da una lista corta di sorgenti che descrivono in modo affidabile “qualcosa è cambiato” durante un incidente:
- Alert di monitoring (PagerDuty, Opsgenie, CloudWatch alarms): indicatori rapidi di sintomi e gravità
- Log e trace (ELK, Datadog, backend OpenTelemetry): prove della portata (quali endpoint, quali clienti)
- Aggiornamenti di status page (Statuspage, Cachet): la narrativa ufficiale e i timestamp verso i clienti
- Ticketing/strumenti incidente (Jira, ServiceNow): ownership, timestamp e dati post-incident
Non provate a ingerire tutto in una volta. Scegliete sorgenti che coprano detection, escalation e conferma.
Metodi di ingestione tra cui scegliere
Diversi strumenti supportano pattern di integrazione differenti:
- Webhooks per aggiornamenti quasi in tempo reale (ideali per alert e status page)
- Polling per API senza webhook (usate backoff e limiti di rate)
- Import batch per backfill storici (utile per la validazione iniziale)
- Inserimento manuale per correzioni dell'ultimo miglio (un analista può aggiustare un tag mancante)
Un approccio pratico: webhook per segnali critici, più import batch per colmare le lacune.
Normalizzare in uno schema comune
Normalizzate ogni elemento in una singola forma di “evento”, anche se la sorgente lo chiama alert, incident o annotazione. Al minimo, standardizzate:
- Timestamp(s): occurred_at, detected_at, resolved_at (quando disponibili)
- Identificatori di servizio: mappate tag/nome di sorgente agli ID canonici dei servizi
- Gravità/priorità: convertite i livelli specifici dello strumento nella vostra scala
- Sorgente e payload raw: tenete il JSON originale per audit e debugging
Igiene dei dati: duplicati, ordinamento, campi mancanti
Aspettatevi dati impolverati. Usate chiavi di idempotenza (source + external_id) per deduplicare, tollerate eventi fuori ordine ordinando su occurred_at (non sul tempo di arrivo) e applicate valori di default sicuri quando mancano campi (segnalandoli per revisione).
Una piccola coda “servizio non abbinato” nell'UI evita errori silenziosi e mantiene i risultati dell'impatto affidabili.
Mappare le dipendenze dei servizi per un blast radius accurato
Scala oltre il prototipo
Passa da un prototipo rapido a Pro o Business quando l'app per l'impatto diventa critica.
Se la mappa delle dipendenze è sbagliata, il blast radius sarà sbagliato—anche se segnali e scoring sono perfetti. L'obiettivo è costruire un grafo di dipendenze di cui ci si può fidare durante e dopo un incidente.
Iniziate da un catalogo servizi (la vostra “fonte di verità”)
Prima di mappare gli archi, definite i nodi. Create una voce nel catalogo per ogni sistema che potete citare in un incidente: API, worker, datastore, vendor terzi e componenti condivisi critici.
Ogni servizio dovrebbe includere almeno: owner/team, tier/criticità (es. customer-facing vs interno), target SLA/SLO e link a runbook e doc on-call (es. /runbooks/payments-timeouts).
Catturare le dipendenze: statiche vs apprese
Usate due fonti complementari:
- Statiche (dichiarate): ciò da cui i team dicono di dipendere (IaC, config, manifest di servizio, ADR). Stabili e facili da auditare.
- Apprese (osservate): ciò che i sistemi effettivamente chiamano (traces, telemetry del service mesh, log del gateway, audit DB). Catturano gli “unknown unknowns”.
Trattatele come tipi di arco separati così la gente capisce la confidenza: “dichiarato dal team” vs “osservato negli ultimi 7 giorni”.
Direzionalità e criticità contano
Le dipendenze devono essere direzionali: Checkout → Payments non è la stessa cosa di Payments → Checkout. La direzione guida il ragionamento (“se Payments è degradato, quali upstream potrebbero fallare?”).
Modellate anche dipendenze hard vs soft:
- Hard: il fallimento blocca la funzionalità core (es. auth per il login).
- Soft: il degrado riduce la qualità ma c'è fallback (raccomandazioni, arricchimenti opzionali).
Questa distinzione evita di sovrastimare l'impatto e aiuta a prioritizzare.
Snapshot del grafo per replay e analisi post-incident
L'architettura cambia settimanalmente. Se non memorizzate snapshot, non potete analizzare correttamente un incidente di due mesi fa.
Persistete versioni del grafo di dipendenze nel tempo (giornalmente, per deploy o quando cambiano). Quando calcolate il blast radius, risolvete il timestamp dell'incidente allo snapshot più vicino, così “chi era impattato” riflette la realtà di quel momento—non l'architettura di oggi.
Calcolo dell'impatto: dai segnali agli score e alla portata impattata
Quando state già ingerendo segnali (alert, consumo SLO, check sintetici, ticket clienti), l'app ha bisogno di un modo coerente per trasformare input disordinati in una dichiarazione chiara: cosa è rotto, quanto è grave e chi ne è colpito?
Scegliete un approccio di scoring (partite semplici)
Potete arrivare a un MVP utile con uno di questi pattern:
- Rule-based: “Se errore checkout > 5% per 10 minuti, impatto = Alto.” Facile da spiegare e debuggare.
- Formula pesata: Combinate metriche normalizzate in un singolo score (es. 0–100). Utile quando avete molti segnali e volete una curva continua.
- Mappatura per tier: Mappate sistemi a tier business (Tier 0–3) e limitate o aumentate la gravità in base al tier. Mantiene i risultati allineati alle priorità di business.
Qualunque approccio scegliate, conservate i valori intermedi (soglie raggiunte, pesi, tier) così la gente può capire perché lo score è quello.
Definite dimensioni d'impatto
Evitare di comprimere tutto in un unico numero troppo presto. Tracciate separatamente alcune dimensioni, poi derivate una gravità complessiva:
- Disponibilità: downtime, richieste fallite, endpoint irraggiungibili
- Latenza: degrado p95/p99 rispetto a baseline o SLO
- Errori: picchi di error rate, job falliti, timeout
- Correttezza dei dati: record mancanti/errati, elaborazioni in ritardo
- Rischio di sicurezza: accessi sospetti, indicatori di esposizione dati
Questo aiuta a comunicare con precisione (es. “disponibile ma lento” vs “risultati errati”).
Calcolare la portata impattata (clienti/utenti)
L'impatto non è solo salute dei servizi—è chi l'ha percepito.
Usate la mappatura di utilizzo (tenant → servizio, piano cliente → funzionalità, traffico utente → endpoint) e calcolate i clienti impattati entro una finestra temporale allineata all'incidente (start, mitigation, eventuale backfill).
Siate espliciti sulle assunzioni: log campionati, stime di traffico o telemetria parziale.
Regolazioni manuali—con responsabilità
Gli operatori dovranno sovrascrivere: falso positivo, rollout parziale, subset noto di tenant.
Permettete modifiche manuali a gravità, dimensioni e clienti impattati, ma richiedete:
- Chi ha modificato cosa
- Quando
- Perché (breve motivo + link opzionale a ticket/runbook)
Questa traccia di audit mantiene la fiducia nella dashboard e accelera il post-incident review.
UX e dashboard: rendere l'impatto comprensibile in pochi minuti
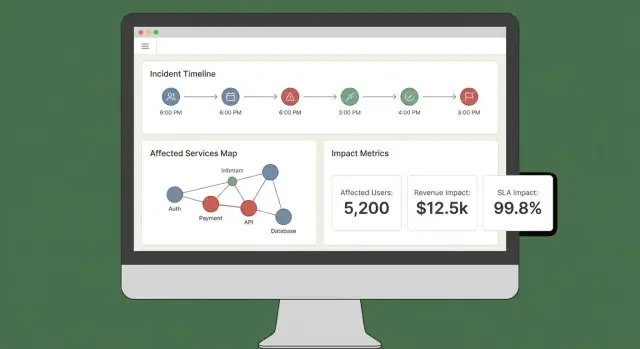
Una buona dashboard d'impatto risponde a tre domande rapidamente: Cosa è impattato? Chi è impattato? Quanto ne siamo sicuri? Se gli utenti devono aprire cinque tab per raccogliere queste info, non si fidano dell'output e non agiranno.
Viste core da includere nell'MVP
Partite con un piccolo set di viste “sempre presenti” che mappano ai workflow reali degli incidenti:
- Panoramica dell'incidente: stato, ora d'inizio, score attuale, servizi/clienti più impattati e le prove più recenti.
- Servizi impattati: lista ordinata che mostra gravità, regione e percorso di dipendenza (così gli ingegneri vedono dove intervenire).
- Clienti impattati: conteggi e account nominativi per tier/piano, più stima di utenti impattati se la tracciate.
- Timeline: un flusso cronologico unico che combina rilevazioni, deploy, alert, mitigazioni e cambi di impatto.
- Azioni: passi consigliati, owner e link a playbook o ticket.
Rendete il “perché” visibile
Gli score senza spiegazione sembrano arbitrari. Ogni score dovrebbe essere ricondotto agli input e alle regole:
- Mostrate quali segnali hanno contribuito (errori, latency, health check, volume supporto) e i loro valori attuali.
- Visualizzate regole e soglie usate (es. “latency p95 > 2s per 10 min = degradato”).
- Aggiungete un indicatore leggero di confidenza (es. “Alta confidenza: confermato da 3 sorgenti”).
Un pannello “Spiega l'impatto” può fare questo senza appesantire la vista principale.
Filtri e drilldown che rispondono a domande reali
Consentite slicing per servizio, regione, tier cliente e range temporale. Permettete di cliccare su un punto del grafico o una riga per approfondire le prove raw (i monitor, i log o gli eventi che hanno generato il cambiamento).
Condivisione ed esportazioni
Durante un incidente attivo, servono aggiornamenti portabili. Include:
- Link condivisibili alla vista dell'incidente (rispettando i permessi)
- Esportazione CSV per liste servizi/clienti
- Esportazione PDF per aggiornamenti di stato e sommari post-incident
Se già avete una status page, fate riferimento ad essa tramite una rotta relativa come /status in modo che il team comunicazioni possa incrociare rapidamente.
Sicurezza, permessi e audit logging
Pianifica il tuo strumento per incidenti
Mappa ruoli, permessi e requisiti di audit prima di scrivere codice di implementazione.
L'analisi d'impatto è utile solo se ci si può fidare—e fiducia significa controllare chi vede cosa e avere una traccia chiara delle modifiche.
Ruoli e permessi (partite semplici)
Definite un piccolo set di ruoli che rispecchino come gli incidenti vengono gestiti:
- Viewer: accesso in sola lettura a riepiloghi e impatto alto livello.
- Responder: può aggiungere note, confermare servizi impattati e aggiornare campi operativi.
- Incident commander: può approvare override, impostare lo status verso i clienti e chiudere incidenti.
- Admin: gestisce integrazioni, assegnazioni di ruolo e retention dei dati.
Allineate i permessi alle azioni, non ai titoli. Per esempio, “può esportare report d'impatto clienti” è un permesso che potete assegnare a commander e alcuni admin.
Proteggete i dati sensibili dei clienti
L'analisi d'impatto spesso tocca identificatori cliente, tier contrattuali e dettagli di contatto. Applicate il principio del least privilege per default:
- Mascherate campi sensibili (es. ultimi 4 caratteri di un account ID) a meno che l'utente non abbia accesso esplicito.
- Separate “chi è impattato” da “cosa si è rotto”. Molti utenti hanno bisogno solo dell'impatto a livello di servizio, non delle liste clienti.
- Proteggete le esportazioni: watermark su PDF/CSV, includete l'utente richiedente e limitate le esportazioni a ruoli approvati. Preferite link di download firmati e a breve scadenza.
Audit logging che risponde a “chi ha cambiato cosa?”
Loggate azioni chiave con contesto sufficiente per le revisioni:
- Modifiche manuali a input di impatto (servizi/clienti impattati)
- Override dello score d'impatto (valore vecchio, nuovo, motivo)
- Acknowledgment e transizioni di stato
- Generazione report ed esportazioni
Conservate i log di audit append-only, con timestamp e identità dell'attore. Rendeteli ricercabili per incidente così siano utili nel post-incident review.
Pianificate esigenze di compliance (senza promettere troppo)
Documentate cosa potete supportare ora—periodo di retention, controlli d'accesso, cifratura e copertura di audit—e cosa è in roadmap.
Una breve pagina “Security & Audit” nell'app (es. /security) aiuta a fissare aspettative e riduce domande ad hoc durante incidenti critici.
Workflow e notifiche durante un incidente attivo
L'analisi d'impatto conta solo se guida l'azione. L'app dovrebbe comportarsi come un “co-pilota” nel canale incident: trasforma segnali in aggiornamenti chiari e sollecita le persone quando l'impatto cambia in modo significativo.
Collegarsi a chat e canali incident
Iniziate integrando il posto dove i responder già lavorano (spesso Slack, Microsoft Teams o uno strumento incidente dedicato). L'obiettivo non è sostituire il canale ma postare aggiornamenti contestuali e mantenere un registro condiviso.
Un pattern pratico tratta il canale come input e output:
- Input: i responder taggano l'app (es. “/impact summarize”, “/impact add affected customer Acme”) per correggere o arricchire la portata.
- Output: l'app pubblica aggiornamenti concisi e coerenti (score corrente, servizi/clienti impattati, trend rispetto all'ultimo update).
Se prototipate rapidamente, considerate di costruire prima il flusso end-to-end (vista incidente → sintetizza → notifica) prima di perfezionare lo scoring. Piattaforme come Koder.ai possono aiutare: potete iterare su una dashboard React e un backend Go/PostgreSQL tramite un workflow guidato in chat, poi esportare il codice sorgente quando il team approva l'UX.
Notifiche basate su soglia (non rumore)
Evitare lo spam: triggerate notifiche solo quando l'impatto supera soglie esplicite. Trigger comuni:
- Scope: il numero di clienti impattati cresce molto (es. da 10 a 100)
- Tier: un servizio Tier 1 diventa impattato
- Ricavo / SLA: proiezione di violazione SLA o coinvolgimento di alto valore contrattuale
- Espansione del blast radius: nuovi servizi dipendenti entrano nell'insieme impattato
Quando scatta una soglia, inviate un messaggio che spiega perché (cosa è cambiato), chi dovrebbe agire e cosa fare.
Collegamento a runbook e workflow
Ogni notifica dovrebbe includere link “prossimo passo” per permettere azioni rapide:
- Runbook: /blog/incident-runbook-template
- Policy di escalation: /pricing
- Pagina ownership servizio: /services/payments
Mantenete questi riferimenti stabili e relativi così funzionino in tutti gli ambienti.
Aggiornamenti agli stakeholder: interno e verso i clienti
Generate due formati di sommario dagli stessi dati:
- Aggiornamento interno: dettagli tecnici, causa sospetta, progresso mitigazione, confidenza ETA.
- Aggiornamento per i clienti: linguaggio semplice, impatto corrente sugli utenti, workaround, orario del prossimo aggiornamento.
Supportate sommari pianificati (es. ogni 15–30 minuti) e azioni “genera update” on-demand, con uno step di approvazione prima dell'invio esterno.
Validazione: test, replay e controlli di accuratezza
Pubblica una pagina di overview
Crea una vista di overview dell'incidente che mostri cosa si è rotto, chi è impattato e perché.
L'analisi d'impatto è utile solo se la gente si fida dei risultati durante e dopo l'incidente. La validazione dovrebbe dimostrare due cose: (1) il sistema produce risultati stabili e spiegabili, e (2) quei risultati corrispondono a quanto l'organizzazione concorda sia successo in seguito.
Strategia di testing: regole e pipeline
Partite con test automatici che coprano le due aree più soggette a errori: logica di scoring e ingestione dati.
- Unit test per regole di scoring: trattate ogni regola come un contratto. Dati segnali specifici (error rate, latency, check sintetici, volume ticket), il test dovrebbe asserire lo score d'impatto e la portata impattata attesi. Includete test ai bordi (sotto/sopra soglia) così l'instabilità dei metrici non inverte gli esiti.
- Integration test per ingestione: verificate il percorso completo da webhook/input evento a record normalizzato e impatto calcolato. Usate payload registrati dai vostri strumenti di osservabilità e incident per catturare early schema drift.
Tenete i fixture leggibili: quando qualcuno cambia una regola deve poter capire perché uno score è cambiato.
Replay di incidenti passati per validare gli output
Una modalità di replay è una via rapida per guadagnare confidenza. Eseguite incidenti storici attraverso l'app e confrontate cosa avrebbe mostrato “all'istante” rispetto a quanto i responder hanno concluso dopo.
Suggerimenti pratici:
- Ricostruite timeline usando timestamp degli eventi (non tempo di ingestione) per riflettere la realtà.
- Congelate i grafi di dipendenza alla data dell'incidente se il catalogo servizi è cambiato.
- Salvate i risultati di replay per poter confrontare versioni dopo modifiche alle regole.
Gestire i casi limite che rompono scoring naive
Gli incidenti reali raramente sono outage puliti. La suite di validazione dovrebbe includere scenari come:
- Outage parziali (alcuni endpoint o segmenti clienti falliscono)
- Prestazioni degradate (lentezza ma non fallimento) dove l'impatto business può essere alto
- Fail multi-regione dove lo stesso servizio ha salute diversa per regione
Per ognuno, asserite non solo lo score ma anche la spiegazione: quali segnali e quali dipendenze/clienti hanno guidato il risultato.
Misurare l'accuratezza rispetto ai riscontri post-incident
Definite l'accuratezza in termini operativi e tracciatela.
Confrontate l'impatto calcolato con i risultati del post-incident review: servizi impattati, durata, numero clienti, breach SLA e gravità. Registrate le discrepanze come issue di validazione con una categoria (dati mancanti, dipendenza sbagliata, soglia errata, segnale in ritardo).
Col tempo, l'obiettivo non è la perfezione ma meno sorprese e più velocità di accordo durante gli incidenti.
Deploy, scalabilità e iterazioni dopo l'MVP
Rilasciare un MVP per l'analisi d'impatto riguarda soprattutto affidabilità e cicli di feedback. La prima scelta di deployment dovrebbe ottimizzare la velocità di cambiamento, non la scala teorica futura.
Scegliete uno stile di deployment che potete evolvere
Partite con un monolite modulare a meno che non abbiate già un team platform forte e confini di servizio netti. Un'unità distribuibile semplifica migrazioni, debugging e test end-to-end.
Spezziate in servizi solo quando sentite un dolore reale:
- la pipeline di ingestione necessita di scalare indipendentemente
- più team devono deployare indipendentemente
- i domini di failure sono difficili da ragionare in un'unica app
Un compromesso pragmatico è un'app + worker di background (code) + un edge di ingestione separato se necessario.
Se volete muovervi velocemente senza costruire subito una grande piattaforma su misura, Koder.ai può accelerare l'MVP: il suo workflow “vibe-coding” guidato in chat si presta a costruire una UI React, una API Go e un modello PostgreSQL, con snapshot/rollback mentre iterate su regole di scoring e workflow.
Scegliere lo storage in base ai pattern d'accesso
Usate storage relazionale (Postgres/MySQL) per entità core: incidenti, servizi, clienti, ownership e snapshot calcolati d'impatto. È facile da interrogare, auditare ed evolvere.
Per segnali ad alto volume (metriche, eventi derivati dai log), aggiungete uno store time-series (o columnar) quando la retention raw e i rollup diventano costosi in SQL.
Considerate un graph database solo se le query sulle dipendenze diventano un collo di bottiglia o il modello è altamente dinamico. Molte squadre arrivano lontano con tabelle di adiacenza più caching.
Aggiungere osservabilità all'app stessa
La vostra app d'impatto entra nella toolchain degli incidenti, quindi strumentatela come software di produzione:
- rate di errori ed endpoint lenti (soprattutto “ricalcola impatto”)
- profondità/lag delle code worker e tassi di retry
- throughput di ingestione e conteggi di failure per sorgente
- freschezza dati (tempo dall'ultimo pull/push riuscito)
- durata dei calcoli e hit rate della cache
Esponete una vista “health + freshness” nella UI così i responder possono fidarsi (o mettere in dubbio) i numeri.
Pianificate iterazioni e refactor deliberatamente
Definite in modo ristretto l'ambito dell'MVP: pochi strumenti per ingerire, uno score chiaro e una dashboard che risponda “chi è impattato e quanto”. Poi iterate:
- Funzionalità successive: maggiore accuratezza delle dipendenze, pesi specifici per cliente, esportazioni reporting SLA, replay per incidenti passati
- Trigger di refactor: aggiungete eccezioni ogni settimana, il ricalcolo è troppo lento o il modello dati non esprime la realtà senza hack
Trattate il modello come un prodotto: versionatelo, migrate in sicurezza e documentate i cambiamenti per il post-incident review.