21 mag 2025·8 min
Crea un'app web per report SLA centralizzati per i clienti
Scopri come pianificare, costruire e lanciare un'app web multi-cliente che raccoglie dati SLA, normalizza le metriche e fornisce dashboard, avvisi e report esportabili.
Scopri come pianificare, costruire e lanciare un'app web multi-cliente che raccoglie dati SLA, normalizza le metriche e fornisce dashboard, avvisi e report esportabili.
La reportistica SLA centralizzata nasce perché le prove degli SLA raramente stanno in un solo posto. L'uptime può essere in uno strumento di monitoring, gli incidenti in una status page, i ticket in un helpdesk e le note di escalation in email o chat. Quando ogni cliente ha uno stack leggermente diverso (o convenzioni di nomenclatura differenti), il reporting mensile diventa lavoro manuale su fogli di calcolo—e le discussioni su “cosa è realmente successo” diventano comuni.
Una buona app di reportistica SLA serve più audience con obiettivi diversi:
L'app dovrebbe presentare la stessa verità di base a livelli di dettaglio diversi, a seconda del ruolo.
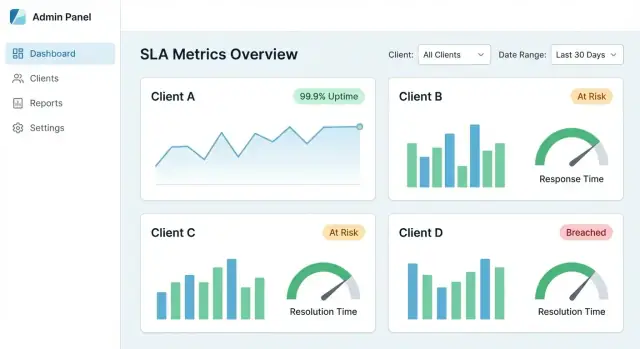
Una dashboard SLA centralizzata dovrebbe offrire:
Nella pratica, ogni numero SLA dovrebbe essere tracciabile fino agli eventi grezzi (alert, ticket, timeline degli incidenti) con timestamp e ownership.
Prima di costruire qualsiasi cosa, definisci cosa è in scope e cosa out of scope. Per esempio:
Confini chiari evitano discussioni successive e mantengono il reporting coerente tra i clienti.
Al minimo, la reportistica SLA centralizzata dovrebbe supportare cinque flussi:
Progetta attorno a questi flussi fin dal primo giorno e il resto del sistema (modello dati, integrazioni e UX) resterà allineato ai bisogni reali di reporting.
Prima di costruire schermate o pipeline, decidi cosa misurerà la tua app e come quei numeri devono essere interpretati. L'obiettivo è la coerenza: due persone che leggono lo stesso report dovrebbero arrivare alla stessa conclusione.
Parti con un set ristretto che la maggior parte dei clienti riconosce:
Sii esplicito su cosa misura ogni metrica e su cosa non misura. Un breve pannello di definizioni nell'UI (e un riferimento a /help/sla-definitions) previene malintesi successivi.
Le regole sono il punto in cui la reportistica SLA spesso fallisce. Documentale in frasi che il cliente possa convalidare, poi traducile in logica.
Copri l'essenziale:
Scegli periodi predefiniti (mensile e trimestrale sono comuni) e se supporterai intervalli personalizzati. Chiarisci il fuso orario usato per i cutoff.
Per i breach, definisci:
Per ogni metrica, elenca gli input richiesti (eventi di monitoring, record di incidenti, timestamp dei ticket, finestre di manutenzione). Questo diventerà la base per integrazioni e controlli di qualità dei dati.
Prima di progettare dashboard o KPI, chiarisci dove vivono davvero le prove SLA. La maggior parte dei team scopre che i loro “dati SLA” sono divisi tra strumenti, posseduti da gruppi differenti e registrati con significati leggermente diversi.
Inizia con una lista semplice per cliente (e per servizio):
Per ogni sistema, annota il proprietario, il periodo di retention, i limiti API, la risoluzione temporale (secondi vs minuti) e se i dati sono scoped per cliente o condivisi.
La maggior parte delle app di reportistica SLA usa una combinazione:
Una regola pratica: usa webhook quando la freschezza conta, e API pulls quando la completezza conta.
Strumenti diversi descrivono la stessa cosa in modi differenti. Normalizza in un piccolo set di eventi su cui l'app può fare affidamento, come:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedIncludi campi coerenti: client_id, service_id, source_system, external_id, severity, e timestamp.
Conserva tutti i timestamp in UTC, e converti per la visualizzazione in base al fuso orario preferito del cliente (soprattutto per i cutoff mensili).
Pianifica anche per lacune: alcuni clienti potrebbero non avere status page, alcuni servizi potrebbero non essere monitorati 24/7 e alcuni strumenti potrebbero perdere eventi. Rendi la “copertura parziale” visibile nei report (es. “dati di monitoring non disponibili per 3 ore”) così i risultati SLA non risultino fuorvianti.
Se la tua app riporta SLA per più clienti, le decisioni architetturali determinano se puoi scalare in sicurezza senza fughe di dati tra clienti.
Comincia nominando i livelli che devi supportare. Un “cliente” potrebbe essere:
Scrivi questi elementi presto, perché influenzano permessi, filtri e come memorizzi le configurazioni.
La maggior parte delle app di reportistica SLA sceglie uno di questi:
tenant_id. È economico e più semplice da gestire, ma richiede disciplina stretta nelle query.Un compromesso comune è DB condiviso per la maggior parte dei tenant e DB dedicati per clienti “enterprise”.
L'isolamento deve valere per:
tenant_id così i risultati non finiscano nel tenant sbagliatoUsa guardrail come row-level security, scope di query obbligatori e test automatizzati per i confini tenant.
Clienti diversi avranno obiettivi e definizioni diverse. Pianifica impostazioni per tenant come:
Gli utenti interni spesso devono “impersonare” la vista di un cliente. Implementa uno switch deliberato (non un filtro libero), mostra il tenant attivo in modo prominente, registra gli switch per audit e previeni link che possano bypassare i controlli di tenant.
Un'app di reportistica SLA centralizzata vive o muore sul suo modello dati. Se modelli solo “% SLA per mese”, faticherai a spiegare risultati, gestire dispute o aggiornare calcoli in futuro. Se modelli solo eventi grezzi, il reporting diventa lento e costoso. L'obiettivo è supportare entrambi: prove grezze tracciabili e rollup veloci pronti per il cliente.
Mantieni una separazione chiara tra chi viene riportato, cosa viene misurato e come è calcolato:
Progetta tabelle (o collection) per:
La logica SLA cambia: orari lavorativi aggiornati, esclusioni chiarite, regole di arrotondamento che evolvono. Aggiungi un calculation_version (e idealmente un riferimento al “rule set”) a ogni risultato calcolato. In questo modo i report vecchi possono essere riprodotti esattamente anche dopo miglioramenti.
Includi campi di audit dove contano:
I clienti spesso chiedono “dimostrami perché”. Pianifica uno schema per le prove:
Questa struttura mantiene l'app spiegabile, riproducibile e veloce—senza perdere le prove sottostanti.
Se gli input sono disordinati, anche la tua dashboard SLA lo sarà. Una pipeline affidabile trasforma dati di incidenti e ticket da più strumenti in risultati SLA coerenti e auditabili—senza doppio conteggio, gap o errori silenziosi.
Tratta ingestione, normalizzazione e rollup come fasi separate. Esegui come job in background così l'UI resta reattiva e puoi riprovare in sicurezza.
Questa separazione aiuta anche quando la sorgente di un cliente è down: l'ingestione può fallire senza corrompere i calcoli esistenti.
Le API esterne timeoutano. I webhook possono essere consegnati due volte. La pipeline deve essere idempotente: processare lo stesso input più volte non dovrebbe cambiare il risultato.
Approcci comuni:
Tra clienti e strumenti, “P1”, “Critical” e “Urgent” possono significare la stessa cosa—o no. Costruisci uno strato di normalizzazione che standardizzi:
Conserva sia il valore originale sia quello normalizzato per tracciabilità.
Aggiungi regole di validazione (timestamp mancanti, durate negative, transizioni di stato impossibili). Non scartare i dati errati silenziosamente—instradali in una coda di quarantena con una ragione e un workflow “fix or map”.
Per ogni cliente e sorgente, calcola “ultimo sync riuscito”, “evento non processato più vecchio” e “rollup aggiornato fino a”. Mostralo come semplice indicatore di freschezza dei dati così i clienti si fidano dei numeri e il tuo team individua problemi presto.
Se i clienti usano il tuo portale per rivedere le performance SLA, autenticazione e permessi devono essere progettati con la stessa cura della matematica SLA. L'obiettivo è semplice: ogni utente vede solo ciò che deve—e puoi dimostrarlo in seguito.
Inizia con un set piccolo e chiaro di ruoli ed espandi solo quando serve:
Applica il principio del minimo privilegio: gli account nuovi dovrebbero essere viewer salvo promozioni esplicite.
Per team interni, SSO riduce lo sprawl di account e il rischio di offboarding incompleto. Supporta OIDC (Google Workspace/Azure AD/Okta) e, dove richiesto, SAML.
Per i clienti, offri SSO come opzione avanzata, ma lascia email/password con MFA per organizzazioni più piccole.
Imponi confini tenant a ogni livello:
Registra accessi a pagine sensibili e download: chi ha visto cosa, quando e da dove. Questo aiuta conformità e fiducia del cliente.
Costruisci un flusso di onboarding dove admin o editor cliente possono invitare utenti, impostare ruoli, richiedere verifica email e revocare l'accesso immediatamente quando qualcuno lascia.
Una dashboard SLA centralizzata funziona quando un cliente può rispondere a tre domande in meno di un minuto: Stiamo rispettando gli SLA? Cosa è cambiato? Cosa ha causato i fallimenti? La UX dovrebbe guidare dall'overview alla prova—senza costringere a conoscere il tuo modello dati interno.
Inizia con poche card e grafici che corrispondono alle conversazioni SLA comuni:
Rendi ogni card cliccabile così diventa una porta verso i dettagli, non un elemento morto.
I filtri dovrebbero essere coerenti su tutte le pagine e rimanere attivi durante la navigazione.
Default consigliati:
Mostra le filter chip attive in alto così gli utenti comprendono sempre cosa stanno visualizzando.
Ogni metrica dovrebbe avere un percorso verso il “perché”. Un buon flusso di drill-down:
Se un numero non può essere spiegato con prove, sarà messo in discussione—soprattutto durante i QBR.
Aggiungi tooltip o un pannello “info” per ogni KPI: come è calcolato, esclusioni, fuso orario e freschezza dei dati. Includi esempi tipo “Finestre di manutenzione escluse” o “Uptime misurato al gateway API”.
Rendi le viste filtrate condivisibili tramite URL stabili (es. /reports/sla?client=acme&service=api&range=30d). Questo trasforma la dashboard SLA centralizzata in un portale report pronto per il cliente che supporta check-in ricorrenti e audit trail.
Una dashboard SLA è utile giorno per giorno, ma i clienti spesso vogliono qualcosa che possano inoltrare internamente: un PDF per i leader, un CSV per gli analisti e un link da salvare.
Supporta tre output dagli stessi risultati SLA sottostanti:
Per i report basati su link, rendi i filtri espliciti (intervallo, servizio, severità) così il cliente sa esattamente cosa rappresentano i numeri.
Aggiungi scheduling così ogni cliente può ricevere report automaticamente—settimanali, mensili e trimestrali—inviati a una lista client-specific o a una inbox condivisa. Mantieni gli schedule scoped al tenant e auditabili (chi lo ha creato, ultimo invio, prossima esecuzione).
Se vuoi partire semplice, lancia con un “sommario mensile” più un download one-click da /reports.
Costruisci template che leggono come slide QBR/MBR in forma scritta:
Gli SLA reali includono eccezioni (manutenzioni, outage terze parti). Permetti agli utenti di allegare note di conformità e segnalare eccezioni che richiedono approvazione, con una traccia di approvazione.
Gli export devono rispettare isolamento tenant e permessi di ruolo. Un utente dovrebbe poter esportare solo i clienti, servizi e periodi che è autorizzato a vedere—e l'export deve riflettere esattamente la vista del portale (nessuna colonna in più che perda dati nascosti).
Gli alert sono il punto in cui un'app SLA passa da “dashboard interessante” a strumento operativo. L'obiettivo non è inviare più messaggi—ma aiutare le persone giuste a reagire presto, documentare cosa è successo e informare i clienti.
Parti con tre categorie:
Collega ogni alert a una definizione chiara (metrica, finestra temporale, soglia, ambito cliente) così i destinatari possano fidarsi.
Offri più opzioni di delivery così i team incontrano i clienti dove già lavorano:
Per report multi-cliente, instrada le notifiche usando regole tenant (es. “Client A -> Canale A; breach interni -> on-call”). Evita di mandare dettagli specifici cliente in canali condivisi.
L'alert fatigue uccide l'adozione. Implementa:
Ogni alert dovrebbe supportare:
Questo crea una traccia leggera riutilizzabile nei report cliente.
Fornisci un editor di regole base per soglie e routing per cliente (senza esporre logica di query complessa). I guardrail aiutano: default, validazione e anteprima (“questa regola avrebbe triggerato 3 volte il mese scorso”).
Un'app di reportistica SLA centralizzata diventa rapidamente mission-critical perché i clienti la usano per giudicare la qualità del servizio. Questo rende velocità, sicurezza e evidenza (per audit) importanti quanto i grafici.
Grandi clienti possono generare milioni di ticket, incidenti ed eventi di monitoring. Per mantenere le pagine reattive:
Gli eventi grezzi sono preziosi per indagini, ma conservarli per sempre aumenta costi e rischi.
Stabilisci regole chiare come:
Per un portale di report, considera contenuti sensibili: nomi clienti, timestamp, note ticket e talvolta PII.
Anche se non miri a uno standard specifico, una buona evidenza operativa genera fiducia.
Mantieni:
Lanciare un’app SLA è meno un rilascio big-bang e più la dimostrazione di accuratezza, poi scala ripetibile. Un piano di lancio solido riduce le dispute rendendo i risultati facili da verificare e riprodurre.
Scegli un cliente con un set gestibile di servizi e sorgenti dati. Esegui i calcoli SLA dell'app in parallelo con i loro spreadsheet, export ticket o report vendor.
Concentrati sulle differenze comuni:
Documenta le discrepanze e decidi se l'app deve aderire all'approccio corrente del cliente o sostituirlo con uno standard più chiaro.
Crea una checklist ripetibile così ogni nuovo cliente ha un'esperienza prevedibile:
Una checklist aiuta anche a stimare sforzo e supporto nelle conversazioni su /pricing.
Le dashboard SLA sono credibili solo se fresche e complete. Aggiungi monitoring per:
Invia prima alert interni; quando stabile, puoi introdurre note di status visibili ai clienti.
Raccogli feedback su dove avviene confusione: definizioni, dispute (“perché questo è un breach?”) e “cosa è cambiato” dall'ultimo mese. Prioritizza piccoli miglioramenti UX come tooltip, change log e note chiare su esclusioni.
Se vuoi rilasciare un MVP interno rapidamente (modello tenant, integrazioni, dashboard, export) senza settimane di boilerplate, un approccio di sviluppo guidato può aiutare. Ad esempio, Koder.ai permette ai team di progettare e iterare su un'app multi-tenant via chat—poi esportare il codice e deployare. È una scelta pratica per prodotti SLA, dove la complessità principale sono le regole di dominio e la normalizzazione dati più che lo scaffolding UI.
Puoi usare la modalità planning di Koder.ai per definire entità (tenant, servizi, SLA definition, eventi, rollup), quindi generare una UI React e una base backend Go/PostgreSQL che puoi estendere con integrazioni specifiche e logica di calcolo.
Mantieni un doc living con i prossimi passi: nuove integrazioni, formati export e tracce di audit. Collega guide correlate su /blog così clienti e colleghi possono auto-istruirsi.
La reportistica SLA centralizzata dovrebbe creare una fonte unica di verità raccogliendo uptime, incidenti e timeline dei ticket in una vista unica e tracciabile.
Praticamente, dovrebbe:
Inizia con un piccolo set che la maggior parte dei clienti riconosce, poi espandi solo quando puoi spiegarli e verificarli.
Metriche di partenza comuni:
Per ogni metrica, documenta cosa misura, cosa esclude e le fonti dati necessarie.
Scrivi le regole in linguaggio semplice prima, poi trasformale in logica applicativa.
Di solito devi definire:
Se due persone non riescono a mettersi d'accordo sulla versione in linguaggio naturale, la versione in codice sarà contestata più avanti.
Conserva tutti i timestamp in UTC, poi converti per la visualizzazione usando il fuso orario di reporting del tenant.
Decidi anche in anticipo:
Mostralo chiaramente nell'interfaccia (es. “I cutoff dei periodi di reporting sono in America/New_York”).
Usa una combinazione di metodi basata su freschezza vs completezza:
Una regola pratica: webhooks dove la freschezza conta, API pulls dove conta la completezza.
Definisci un piccolo set canonico di eventi normalizzati così strumenti diversi mappano agli stessi concetti.
Esempi:
incident_opened / incident_closedScegli un modello multi-tenant e applica l'isolamento oltre l'interfaccia utente.
Protezioni chiave:
tenant_idConsidera export e job in background come i punti più a rischio per fughe di dati se non progetti il contesto tenant correttamente.
Conserva sia eventi grezzi sia risultati derivati così puoi essere veloce e spiegabile.
Una separazione pratica:
Aggiungi un così i report passati possono essere riprodotti esattamente dopo cambi nelle regole.
Rendi la pipeline a fasi e idempotente:
Per affidabilità:
Includi tre categorie di alert così il sistema è operativo, non solo una dashboard:
Riduci il rumore con deduplica, ore silenziose ed escalation, e rendi ogni alert azionabile con riconoscimento e note di risoluzione.
downtime_started / downtime_endedticket_created / first_response / resolvedIncludi campi coerenti come tenant_id, service_id, source_system, external_id, severity e timestamp in UTC.
calculation_version