Cos'è una pagina di stato SaaS (e perché conta)
Una pagina di stato SaaS è un sito pubblico (o riservato ai clienti) che mostra se il tuo prodotto sta funzionando in questo momento — e cosa stai facendo se non lo è. Diventa la fonte unica di verità durante gli incidenti, separata dai social, dai ticket di supporto e dai rumor.
Aiuta più persone di quanto potresti aspettarti:
- I clienti possono rapidamente capire “È solo un problema mio?” e decidere se aspettare, riprovare o usare una soluzione alternativa.
- I team di supporto possono linkare un unico aggiornamento canonico invece di ripetere spiegazioni in decine di ticket.
- Sales e Customer Success possono gestire preventivamente rinnovi e account chiave con informazioni accurate e datate.
Stato in tempo reale vs. cronologia degli incidenti vs. postmortem
Un buon sito di stato di servizio di solito contiene tre livelli correlati (ma diversi):
- Stato in tempo reale: cosa è su, giù o degradato in questo momento nei tuoi componenti (API, dashboard, billing, ecc.).
- Pagina cronologia degli incidenti: una timeline di incidenti e manutenzioni passate, così i clienti possono capire i pattern e vedere che i problemi sono stati affrontati.
- Revisioni post-incidente (postmortem): resoconti più approfonditi che spiegano causa radice, fix e passi di prevenzione. Possono essere pubblici o condivisi privatamente con i clienti interessati.
L'obiettivo è chiarezza: lo stato in tempo reale risponde a “Posso usare il prodotto?” mentre la cronologia risponde a “Quanto spesso succede?” e i postmortem rispondono a “Perché è successo e cosa è cambiato?”.
Gestire le aspettative: trasparenza, rapidità e chiarezza
Una pagina di stato funziona quando gli aggiornamenti sono veloci, in linguaggio semplice e onesti sull'impatto. Non serve una diagnosi perfetta per comunicare. Ti servono invece timestamp, ambito (chi è interessato) e l'ora del prossimo aggiornamento.
Momenti comuni in cui la userai
Ti servirà durante interruzioni, prestazioni degradate (login lenti, webhook ritardati) e manutenzioni programmate che possono causare brevi interruzioni o rischi.
Se tratti la pagina di stato come una superficie di prodotto (non come una pagina operativa fatta al volo), il resto della configurazione diventa molto più semplice: puoi definire owner, costruire template e connettere il monitoring senza reinventare il processo a ogni incidente.
Definisci obiettivi, pubblico e responsabilità
Prima di scegliere uno strumento o progettare un layout, decidi cosa deve fare la tua pagina di stato. Un obiettivo chiaro e un owner esplicito sono ciò che mantiene la pagina utile durante un incidente — quando tutti sono occupati e l'informazione è confusa.
Definisci l'obiettivo (come appare il “successo”)
La maggior parte dei team SaaS crea una pagina di stato per tre risultati pratici:
- Ridurre i ticket di supporto rispondendo a “È giù?” in un unico posto pubblico
- Costruire fiducia condividendo aggiornamenti tempestivi in linguaggio semplice
- Accelerare la comunicazione tra Support, Engineering, Sales e Customer Success
Annota 2–3 segnali misurabili che puoi monitorare dopo il lancio: meno ticket duplicati durante gli incidenti, tempo più veloce al primo aggiornamento, o più clienti che usano le iscrizioni.
Identifica il pubblico e il livello di lettura
Il tuo lettore principale è solitamente un cliente non tecnico che vuole sapere:
- Il prodotto funziona ora?
- Cosa è impattato (login, API, billing, ecc.)?
- Cosa devo fare dopo?
- Quando sarà sistemato?
Questo significa minimizzare il gergo. Preferisci “Alcuni clienti non riescono ad accedere” a “Tassi 5xx elevati su auth.” Se servono dettagli tecnici, mettili come una frase secondaria e breve.
Scegli tono, regole e ownership
Scegli un tono che puoi mantenere sotto pressione: calmo, fattuale e trasparente. Decidi in anticipo:
- Chi può pubblicare aggiornamenti (un singolo ruolo o una rotazione on-call)
- Chi approva gli aggiornamenti (se serve) e quanto può durare l'approvazione
- Frequenza minima degli aggiornamenti durante un incidente attivo (ad esempio, ogni 30 minuti)
Rendi l'ownership esplicita: la pagina di stato non dovrebbe essere “compito di tutti”, altrimenti diventa di nessuno.
Decidi dove risiede
Hai due opzioni comuni:
- Sito standalone (es. status.yourcompany.com): separazione più chiara e spesso più resistente alle interruzioni
- Sottopercorso (es. /status): branding e analytics più semplici
Se la tua app principale può cadere, un sito di status standalone è solitamente più sicuro. Puoi comunque linkarlo in modo prominente dall'app e dal centro assistenza (ad esempio, /help).
Mappa i tuoi servizi e il modello di stato dei componenti
Una pagina di stato è utile quanto la “mappa” che la sostiene. Prima di scegliere colori o scrivere copy, decidi su cosa stai effettivamente riportando. L'obiettivo è riflettere come i clienti vivono il prodotto — non come è organizzata la tua org.
Inizia con un inventario dei componenti
Elenca le parti che un cliente potrebbe descrivere quando dice “è rotto”. Per molti prodotti SaaS, un set pratico di partenza è:
- API
- Web app
- Dashboard / admin
- Autenticazione (login, SSO)
- Billing
- Integrazioni (Slack, Salesforce, webhook, ecc.)
Se offri più regioni o tier, cattura anche quelli (es. “API – US” e “API – EU”). Usa nomi comprensibili per i clienti: “Login” è più chiaro di “IdP Gateway”.
Decidi come raggruppare i componenti
Scegli un raggruppamento che corrisponda al modo in cui i clienti pensano al tuo servizio:
- Per prodotto: utile se hai offerte distinte (Prodotto A vs Prodotto B)
- Per regione: utile se la disponibilità varia significativamente per geografia
- Per funzionalità/workflow: utile se i clienti si affidano a job specifici (Reporting, Importazioni, Notifiche)
Evita liste infinite. Se hai decine di integrazioni, considera un componente genitore (“Integrazioni”) più alcuni figli ad alto impatto (es. “Salesforce”, “Webhooks”).
Definisci i livelli di stato (e cosa significano)
Un modello semplice e coerente evita confusione durante gli incidenti. Livelli comuni includono:
- Operational: funziona come previsto
- Degraded Performance: più lento del normale o errori intermittenti
- Partial Outage: una parte significativa di utenti/funzionalità non è disponibile
- Major Outage: il servizio è ampiamente non disponibile
Scrivi criteri interni per ogni livello (anche se non li pubblichi). Per esempio, “Partial Outage = una regione giù” o “Degraded = p95 latency sopra X per Y minuti.” La coerenza costruisce fiducia.
Documenta le dipendenze — e scegli cosa mostrare
La maggior parte delle interruzioni coinvolge terze parti: hosting cloud, delivery email, processori di pagamento o identity provider. Documenta queste dipendenze così i tuoi aggiornamenti possono essere accurati.
Se mostrarle pubblicamente dipende dal tuo pubblico. Se i clienti possono essere direttamente impattati (es. pagamenti), mostrare una dipendenza può essere utile. Se crea rumore o invita a giochi di colpe, mantieni le dipendenze interne ma riferiscile negli aggiornamenti quando rilevante (es. “Stiamo investigando errori elevati dal nostro provider di pagamenti”).
Una volta definito questo modello di componenti, il resto della configurazione della pagina di stato diventa molto più semplice: ogni incidente avrà subito un “dove” (componente) e “quanto è grave” (stato).
Progetta una pagina di stato semplice e orientata al cliente
Una pagina di stato è più utile quando risponde alle domande del cliente in pochi secondi. Le persone arrivano spesso stressate e vogliono chiarezza — non molta navigazione.
Metti prima ciò di cui i clienti hanno bisogno
Dai priorità all'essenziale in cima:
- Stato corrente: Tutto operativo, degradato o interruzione?
- Impatto: cosa è interessato (chi/regioni/funzionalità) e cosa gli utenti potrebbero percepire
- ETA (se ne hai una): attenzione — condividi solo stime che puoi difendere
- Prossimo aggiornamento: una promessa specifica come “Prossimo aggiornamento entro le 14:30 UTC” riduce i ticket ripetuti
Scrivi in linguaggio semplice. “Tassi di errore elevati sulle richieste API” è più chiaro di “Partial outage in upstream dependency.” Se devi usare termini tecnici, aggiungi una breve traduzione (“Alcune richieste potrebbero non rispondere o andare in timeout”).
Usa un layout semplice e leggibile di scansione
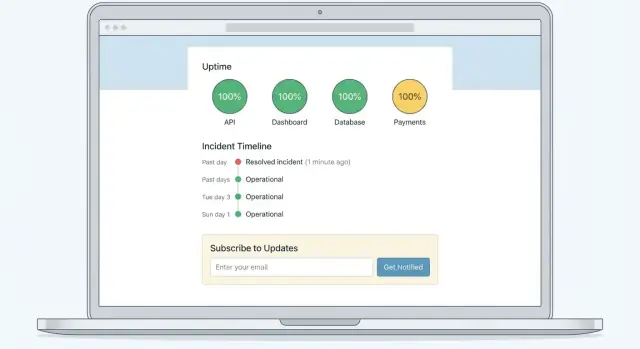
Un pattern affidabile è:
- Banner in cima per lo stato complessivo (All Systems Operational / Degraded Performance / Major Outage)
- Lista dei componenti con stati chiari (Web App, API, Billing, Integrations, ecc.)
- Incidenti attivi e manutenzioni programmate subito sotto, ordinati per aggiornamento più recente
Per la lista dei componenti, mantieni le etichette orientate al cliente. Se il tuo servizio interno si chiama “k8s-cluster-2”, i clienti probabilmente hanno bisogno di “API” o “Background Jobs”.
Accessibilità e basi mobile
Rendi la pagina leggibile sotto pressione:
- Forte contrasto colore e etichette testuali (non affidarti solo al colore)
- Icone chiare con significati coerenti (es. verde = operativo, giallo = degradato, rosso = interruzione)
- Spaziatura mobile-friendly e target di tocco grandi; molti utenti controlleranno lo stato dal telefono
Aggiungi link rapidi dove le persone se li aspettano
Posiziona un piccolo set di link in cima (header o subito sotto il banner):
- Iscriviti (per notifiche email/SMS/webhook)
- Cronologia incidenti (per incidenti passati e timeline)
- Contatta il supporto su /support
L'obiettivo è fiducia: i clienti devono capire subito cosa succede, cosa è impattato e quando riceveranno il prossimo aggiornamento.
Crea template per aggiornamenti di incidente e manutenzione
Quando scatta un incidente, il tuo team sta contemporaneamente diagnosticando, mitigando e rispondendo alle domande dei clienti. I template rimuovono l'incertezza così gli aggiornamenti restano coerenti, chiari e rapidi — soprattutto quando persone diverse potrebbero pubblicare.
Definisci i campi dell'incidente che pubblicherai sempre
Un buon aggiornamento inizia sempre con gli stessi fatti di base. Al minimo, standardizza questi campi così i clienti capiscono immediatamente cosa succede:
- Ora d'inizio dell'incidente (con timezone)
- Componenti/servizi interessati (mappati al tuo modello di stato)
- Impatto per i clienti (chi è interessato e in che modo)
- Stato corrente (Investigating, Identified, Monitoring, Resolved)
- Log degli aggiornamenti (voci con timestamp)
- Ora di risoluzione (quando il servizio è tornato normale)
Se pubblichi una pagina di cronologia degli incidenti, mantenere questi campi coerenti rende gli incidenti passati facili da scorrere e confrontare.
Usa un template semplice e ripetibile per gli aggiornamenti
Punta a aggiornamenti brevi che rispondono alle stesse domande ogni volta. Ecco un template pratico che puoi copiare nel tuo strumento di status:
Titolo: Sommario breve e specifico (es. “Errori API per la regione EU”)\n\nOra d'inizio: YYYY-MM-DD HH:MM (TZ)\n\nComponenti interessati: API, Dashboard, Payments\n\nImpatto: Cosa vedono gli utenti (errori, timeout, prestazioni degradate) e chi è interessato\n\nCosa sappiamo: Una frase sulla causa se confermata (evita speculazioni)\n\nCosa stiamo facendo: Azioni concrete (rollback, scalare, escalation al vendor)\n\nProssimo aggiornamento: Ora in cui pubblicherai di nuovo\n\nAggiornamenti:\n\n- HH:MM (TZ) — Investigating: …\n- HH:MM (TZ) — Identified: …\n- HH:MM (TZ) — Monitoring: …\n- HH:MM (TZ) — Resolved: …
Definisci regole chiare per la cadenza degli aggiornamenti
I clienti non vogliono solo informazioni — vogliono prevedibilità.
- Per incidenti gravi, impegnati a aggiornare ogni 30–60 minuti, anche se l'aggiornamento è “Stiamo ancora investigando; nessuna ETA; prossimo aggiornamento a X.”
- Per problemi minori, puoi pubblicare meno frequentemente, ma prometti sempre un “prossimo aggiornamento”.
- Se non puoi rispettare la cadenza, posta una breve nota che riconosce il ritardo e reimposta le aspettative.
Aggiungi template per annunci di manutenzione
La manutenzione programmata dovrebbe apparire calma e strutturata. Standardizza i post di manutenzione con:
- Finestra di manutenzione: ora d'inizio/fine (con timezone)
- Impatto previsto: none / degraded / intermittent / downtime
- Componenti interessati
- Azioni per i clienti (se necessarie): “Nessuna azione richiesta” o passi chiari
- Aggiornamento promemoria: un breve post quando la manutenzione inizia e un altro quando termina
Mantieni il linguaggio specifico (cosa cambia, cosa noteranno gli utenti) e evita promesse eccessive — i clienti apprezzano la precisione più dell'ottimismo.
Costruisci una cronologia degli incidenti facile da scorrere
Ricevi ricompense per la condivisione
Condividi ciò che hai creato con Koder.ai o invita un collega per guadagnare crediti sulla piattaforma.
Una pagina di cronologia degli incidenti è più di un log — è un modo per clienti (e il tuo team) di capire rapidamente quanto spesso succedono problemi, quali tipologie si ripetono e come rispondete.
Perché la cronologia degli incidenti vale lo sforzo
Una cronologia chiara costruisce fiducia tramite trasparenza. Crea anche visibilità sui trend: se vedi ricorrenti incidenti di “latency API” ogni poche settimane, è un segnale per investire in lavoro di performance (e per dare priorità al processo di post-incident review). Nel tempo, report coerenti possono ridurre i ticket perché i clienti trovano le risposte da soli.
Decidi la retention: quanto indietro conservarla?
Scegli una finestra di retention che corrisponda alle aspettative dei clienti e alla maturità del prodotto.
- 90 giorni: comune per SaaS early-stage, mantiene la pagina snella
- 6–12 mesi: migliore per buyer enterprise che valutano l'affidabilità
- Più a lungo: valuta di esportare i record più vecchi in una pagina di archivio separata se la timeline diventa rumorosa
Qualunque sia la scelta, dichiarala chiaramente (es. “La cronologia degli incidenti è conservata per 12 mesi”).
Rendi ogni entry immediatamente comprensibile
La coerenza rende la scansione facile. Usa un formato di nome prevedibile come:
YYYY-MM-DD — Breve sommario (es. “2025-10-14 — Consegna email ritardata”)
Per ogni incidente mostra almeno:
- componenti interessati
- ora d'inizio/fine (con timezone)
- livello d'impatto (minor/major)
- breve nota di risoluzione
Collega a contesto più profondo quando disponibile
Se pubblichi postmortem, collega dalla pagina di dettaglio dell'incidente al resoconto (per esempio: “Leggi il postmortem” collegato a /blog/postmortems/2025-10-14-email-delays). Questo mantiene la timeline pulita offrendo comunque dettaglio a chi lo desidera.
Aggiungi iscrizioni e notifiche
Una pagina di stato è utile quando i clienti pensano di verificarla. Le iscrizioni ribaltano il paradigma: i clienti ricevono aggiornamenti automaticamente, senza ricaricare la pagina o scrivere al supporto per conferma.
Offri i canali che i clienti già usano
La maggior parte dei team offre almeno alcune opzioni:
- Email (default per molti clienti)
- SMS (migliore per alert urgenti ad alto segnale)
- Slack o Microsoft Teams (ideale per clienti business e team ops)
- RSS/Atom (ancora usato da utenti tecnici e per tool interni)
Se supporti più canali, mantieni il flusso di iscrizione coerente così i clienti non avranno l'impressione di doversi iscrivere quattro volte.
Rendi l'opt-in e le preferenze cristalline
Le iscrizioni devono essere sempre opt-in. Sii esplicito su cosa riceveranno prima della conferma — specialmente per gli SMS.
Dai ai sottoscrittori controllo su:
- Ambito: tutti gli incidenti vs solo componenti selezionati (es. “API” ma non “Marketing site”)\n- Tipo: solo incidenti, solo manutenzioni, o entrambi\n- Severità (opzionale): solo “Major outage” vs “Tutti gli aggiornamenti”
Queste preferenze riducono l'alert fatigue e mantengono le tue notifiche affidabili. Se non hai ancora subscriptions per componente, inizia con “Tutti gli aggiornamenti” e aggiungi filtri dopo.
Evita che le notifiche falliscano proprio quando servono
Durante un incidente, il volume di messaggi schizza e i provider terzi possono limitare il traffico. Verifica:
- Deliverability: SPF/DKIM/DMARC per email; domini di invio verificati; indirizzi "from" riconoscibili dai clienti
- Rate limits e throttling: limiti del provider email/SMS, limiti webhook Slack/Teams e comportamento di retry
- Fallback: se i post su Slack falliscono, mandi comunque email? Se gli SMS sono ritardati, mostri un banner chiaro sulla homepage di status?
Vale la pena eseguire un test programmato (anche trimestrale) per assicurarsi che le iscrizioni funzionino ancora come previsto.
Metti “Iscriviti agli aggiornamenti” dove non si può non vederlo
Aggiungi un callout chiaro nella homepage di status — sopra la piega se possibile — così i clienti possono iscriversi prima del prossimo incidente. Rendilo visibile su mobile e includilo nei posti dove i clienti cercano aiuto (come un link dal tuo portale di supporto o dal /help).
Spedisci template per gli incidenti
Trasforma il tuo modello di aggiornamento per gli incidenti in un'interfaccia editabile e un backend in Koder.ai.
Scegliere come costruire la pagina di status riguarda meno il “possiamo farlo?” e più il cosa vuoi ottimizzare: rapidità di lancio, affidabilità durante gli incidenti e sforzo di manutenzione.
Opzione 1: Usa uno strumento hosted per le pagine di stato
Uno strumento hosted è di solito il percorso più veloce. Ottieni una pagina di status pronta, iscrizioni, timeline degli incidenti e spesso integrazioni con sistemi di monitoring comuni.
Cosa cercare in uno strumento hosted:
- Affidabilità e indipendenza: la pagina di status deve restare raggiungibile anche se la tua app principale è giù
- API e automazione: creare incidenti, aggiornare componenti e pubblicare avanzamenti via API o webhook
- Controllo accessi: ruoli su chi può pubblicare vs chi può solo preparare bozze; SSO è un plus
- Branding e dominio personalizzato: logo/colori, e dominio tipo status.yourcompany.com
- Analytics: numero di iscritti, visualizzazioni degli aggiornamenti e metriche di delivery email (utili per migliorare la comunicazione)
- Requisiti di compliance: audit log e retention se operi in ambienti regolamentati
Opzione 2: Costruirla internamente (DIY)
Il DIY può essere ottimo se vuoi controllo totale su design, retention dei dati e presentazione della cronologia degli incidenti. Il compromesso è che tu possiedi affidabilità e operazioni.
Un'architettura DIY pratica è:
- Sito statico (veloce, cache-friendly) per l'interfaccia di status e le pagine di cronologia
- Fonte di dati con API (o un CMS leggero) che conserva incidenti, componenti e aggiornamenti
- Caching aggressivo + CDN così la pagina di status resta veloce sotto picchi di traffico durante un outage
Se ti autohosti, pianifica i failure mode: cosa succede se il tuo database primario non è disponibile o la pipeline di deploy è giù? Molti team tengono la pagina di status su infrastruttura separata (o anche un provider diverso) rispetto al prodotto principale.
Se vuoi il controllo del DIY senza ricostruire tutto, una piattaforma vibe-coding come Koder.ai può aiutarti a mettere su un sito di status personalizzato (UI web più una piccola API per gli incidenti) rapidamente da una specifica generata in chat. Questo è particolarmente utile per team che vogliono modelli di componenti su misura, una UX di cronologia incidenti custom o workflow amministrativi interni — pur potendo esportare il codice, deployare e iterare velocemente.
Pianificazione dei costi
Gli strumenti hosted hanno prezzi mensili prevedibili; il DIY richiede tempo ingegneristico, costi di hosting/CDN e manutenzione continua. Se stai confrontando opzioni, delinea la spesa mensile prevista e il tempo interno richiesto — poi verifica con il budget (vedi /pricing).
Connetti monitoring e workflow degli incidenti
Una pagina di stato è utile solo se riflette la realtà rapidamente. Il modo più semplice è collegare i sistemi che rilevano i problemi (monitoring) con quelli che coordinano la risposta (incident workflow), così gli aggiornamenti sono coerenti e tempestivi.
Da dove dovrebbero venire gli aggiornamenti di stato
La maggior parte dei team combina tre fonti di dati:
- Alert di monitoring (health check, synthetic test, tassi di errore, latenza, profondità delle code). Sono ottimi per la rilevazione, ma non sempre descrivono l'impatto cliente.
- Aggiornamenti manuali dall'on-call o dal team di supporto. Gli umani aggiungono contesto: chi è impattato, qual è la soluzione alternativa, cosa è cambiato.
- Tool di incident management (PagerDuty, Opsgenie, Jira Service Management, ecc.). Forniscono la timeline, i ruoli e le note di risoluzione che la pagina di status può riassumere.
Una regola pratica: il monitoring rileva; l'incident workflow coordina; la pagina di stato comunica.
Automazione utile (senza promettere troppo)
L'automazione può risparmiare minuti quando conta:
- Crea un incidente da un alert quando un monitor high-severity scatta (es. “tasso errori API > 5% per 5 minuti”). Precompila titolo, componenti interessati e severità iniziale.
- Aggiorna componenti da health check per segnali oggettivi (es. “Web app: Degraded Performance” quando soglie di latenza sono superate).
- Sincronizza i cambi di stato con il canale incident (Slack/Teams) così i responder vedono ciò che vedono i clienti.
Mantieni il primo messaggio pubblico conservativo. “Investigating elevated errors” è più sicuro di “Outage confirmed” quando stai ancora validando.
Non andare completamente automatico senza revisione umana
La messaggistica totalmente automatica può ritorcersi contro:
- Un alert rumoroso può pubblicare incidenti falsi.
- Un guasto parziale può sembrare “down” a un monitor ma non impattare i clienti.
- Aggiornamenti auto-risolti possono chiudere un incidente mentre gli utenti sono ancora impattati.
Usa l'automazione per bozzare e suggerire aggiornamenti, ma richiedi una review umana per il linguaggio rivolto ai clienti — specialmente per gli stati Identified, Mitigated e Resolved.
Mantieni una traccia di audit
Tratta la pagina di stato come un registro pubblico. Assicurati di poter rispondere a:
- Chi ha cambiato lo stato dell'incidente?
- Cosa è stato modificato (testo, componenti, timestamp)?
- Quando è stato cambiato?
Questa traccia aiuta la post-incident review, riduce la confusione durante i passaggi di consegne e costruisce fiducia quando i clienti chiedono chiarimenti.
Rendi tutto affidabile: hosting, DNS e protezioni contro i blackout
Una pagina di stato serve solo se è raggiungibile quando il tuo prodotto non lo è. Il difetto più comune è costruire la pagina di status sulla stessa infrastruttura dell'app — così quando l'app cade, sparisce anche la pagina di status, lasciando i clienti senza fonte di verità.
Isolala dal tuo stack principale
Quando possibile, ospita la pagina di status su un provider diverso rispetto all'app di produzione (o almeno in una regione/account differente). L'obiettivo è separare il raggio d'azione: un outage nella piattaforma dell'app non dovrebbe portare giù anche le comunicazioni sugli incidenti.
Considera anche di separare il DNS. Se il DNS del dominio principale è gestito nello stesso posto dell'edge/CDN dell'app, un problema DNS o di certificato può bloccare entrambi. Molti team usano un sottodominio dedicato (per esempio, status.yourcompany.com) con DNS ospitato indipendentemente.
Rendi la pagina veloce e resistente
Mantieni le risorse leggere: JavaScript minimo, CSS compresso e nessuna dipendenza che richieda le API della tua app per il rendering. Metti una CDN davanti alla pagina di status e abilita caching per le risorse statiche così si carica anche sotto traffico elevato durante gli incidenti.
Un buon piano di sicurezza è una modalità statica di fallback:
- prerender dell'ultimo stato noto e del banner dell'incidente
- servilo da object storage o hosting statico
- aggiorna dinamicamente quando i sistemi sono sani, ma degrada in modo elegante quando non lo sono
Pubblica per default, con accesso admin sicuro
I clienti non dovrebbero dover effettuare il login per vedere lo stato del servizio. Mantieni la pagina pubblica, ma metti gli strumenti di amministrazione/editor dietro autenticazione (SSO se disponibile), con controlli di accesso forti e audit log.
Infine, testa gli scenari di failure: blocca temporaneamente l'origine dell'app in un ambiente di staging e conferma che la pagina di status si risolve, si carica velocemente e può essere aggiornata quando serve di più.
Processo operativo: chi aggiorna e quando
Progetta per lettori sotto stress
Prototipa un sito di status che rimane semplice su mobile e chiaro sotto pressione.
Una pagina di stato costruisce fiducia solo se aggiornata consistentemente durante incidenti reali. Quella coerenza non accade per caso — ti servono ownership chiara, regole semplici e una cadenza prevedibile.
Definisci i ruoli (prima che qualcosa si rompa)
Tieni il team centrale piccolo ed esplicito:
- Incident Commander (IC): dirige la risposta, decide la priorità e conferma quando siete stabili
- Communications Lead: pubblica aggiornamenti sulla pagina di stato e mantiene il linguaggio cliente-friendly
- Engineer on call: investigano, mitigano e forniscono fatti confermati all'IC
Se siete un team piccolo, una persona può ricoprire due ruoli — l'importante è decidere in anticipo. Documenta i passaggi di responsabilità e i percorsi di escalation nel tuo manuale on-call (vedi /docs/on-call).
Una checklist semplice da seguire ogni volta
Quando un alert diventa un incidente con impatto cliente, segui un flusso ripetibile:
- Riconosci: posta rapidamente un aggiornamento “Investigating” (anche se i dettagli sono limitati)
- Valuta l'impatto: conferma quali componenti, regioni o segmenti di clienti sono interessati
- Pubblica aggiornamento: spiega cosa potrebbero notare gli utenti, workaround (se presenti) e quando aggiornerai di nuovo
- Risolvere: conferma il ripristino del servizio e cosa stai monitorando
- Ricapitola: aggiungi un breve sommario e collega alla review completa quando disponibile
Una regola pratica: posta il primo aggiornamento entro 10–15 minuti, poi ogni 30–60 minuti finché l'impatto continua — anche se il messaggio è “Nessun cambiamento, ancora in investigazione.”
Dopo la risoluzione: revisione e miglioramento
Entro 1–3 giorni lavorativi, fai una post-incident review leggera:
- Timeline: eventi chiave da rilevamento a recovery
- Causa radice (miglior conoscenza): spiega in linguaggio semplice
- Azioni: fix specifici, owner e scadenze
Poi aggiorna l'entry dell'incidente con il sommario finale così la cronologia rimane utile — non solo un registro di messaggi “risolto”.
Checklist di lancio e miglioramenti continui
Una pagina di stato è utile solo se è facile da trovare, da fidarsi e aggiornata con costanza. Prima di annunciarla, fai un rapido controllo “production-ready” — e poi stabilisci una cadenza leggera per migliorarla nel tempo.
Checklist di lancio (versione pratica)
Copy e struttura
- Conferma che i nomi dei componenti corrispondano a come i clienti li riconoscono (es. “Dashboard” vs nomi interni).\n- Aggiungi una breve introduzione “Cosa mostra questa pagina” e un link chiaro al supporto (es. /support) per problemi legati ad account specifici.\n- Assicurati che gli aggiornamenti spieghino l'impatto cliente (“pagamenti non riusciti”) e forniscano i passi successivi (“riprovare dopo 10 minuti”).
Branding e fiducia
- Aggiungi il logo, favicon e un semplice sistema di colori per gli stati (evita sfumature troppo sottili).\n- Includi un formato timestamp chiaro e il fuso orario.
Accessi e permessi
- Verifica chi può pubblicare incidenti, pianificare manutenzioni e modificare le impostazioni della pagina.\n- Imposta un “backup on-call” così gli aggiornamenti non rimangano bloccati da una sola persona.
Test del workflow completo
- Esegui un incidente di test (marcalo come test e risolvilo).\n- Iscriviti via email/SMS e conferma che le notifiche arrivano e includono i link corretti.
Annuncio
- Aggiungi il link della pagina di status nel footer della tua app, nel centro assistenza e nelle risposte automatiche del supporto.\n- Invia un breve annuncio ai clienti spiegando cosa aspettarsi e come iscriversi.
Se stai costruendo il tuo sito di status, considera di eseguire la stessa checklist in staging prima. Strumenti come Koder.ai possono accelerare questo ciclo di iterazione generando UI web, schermate admin e endpoint backend da una singola specifica — poi permettendoti di esportare il codice e deployare dove preferisci.
Misura cosa significa “migliorare”
Monitora pochi risultati semplici e rivedili mensilmente:
- Riduzione dei ticket: confronta il volume di ticket legati agli incidenti prima/dopo il lancio.
- Tempo al primo aggiornamento: misura il tempo da rilevamento al primo aggiornamento pubblico.
- Crescita degli iscritti: traccia gli iscritti per canale e quali componenti seguono.
Impara dai pattern degli incidenti
Tieni una tassonomia di base così la cronologia diventa azionabile:
- Tagga gli incidenti per categoria (performance, partial outage, terze parti, manutenzione, sicurezza).\n- Nota componenti ricorrenti e colpevoli abituali.\n- Usa queste informazioni per dare priorità ai fix e informare il processo di post-incident review.
Nozioni SEO di base (così i clienti trovano la pagina giusta)
- Usa titoli di pagina chiari come “Service Status” e “Incident History.”\n- Mantieni le intestazioni strutturate (H2/H3) così le pagine di cronologia sono facili da scansionare.\n- Preferisci pagine di cronologia incidenti indicizzabili (a meno che non ci siano ragioni di sicurezza/privacy) e assicurati che i link tra la pagina principale di stato e ogni incidente siano crawlable.
Col tempo, piccoli miglioramenti — wording più chiaro, aggiornamenti più rapidi, migliore categorizzazione — si sommano in meno interruzioni, meno ticket e più fiducia dei clienti.