Definisci obiettivi e ambito per il monitoraggio dell'affidabilità
Prima di scegliere metriche o costruire dashboard, decidi di cosa si deve occupare l'app di monitoraggio—e di cosa non si occupa. Un ambito chiaro impedisce che lo strumento diventi un “portale ops” tuttofare di cui nessuno si fida.
Definisci cosa stai tracciando
Inizia elencando gli strumenti interni che l'app coprirà (per es., ticketing, payroll, integrazioni CRM, pipeline dati) e i team che li possiedono o li dipendono. Sii esplicito sui confini: “sito verso i clienti” potrebbe essere fuori ambito, mentre “console admin interna” è dentro.
Concorda cosa significa “affidabilità” qui
Organizzazioni diverse usano il termine in modo diverso. Scrivi la tua definizione operativa in linguaggio chiaro—di solito una combinazione di:
- Disponibilità: le persone possono accedervi quando serve?
- Latenza: è sufficientemente veloce da essere usabile?
- Errori: fallisce in modi che gli utenti notano (timeout, job che falliscono, risposte errate)?
Se i team non concordano, l'app finirà per confrontare mele con arance.
Decidi i risultati che vuoi ottenere
Scegli 1–3 risultati principali, come:
- Rilevazione più rapida dei problemi (ridurre il “time to notice”)
- Reportistica più chiara per manager e stakeholder
- Meno incidenti ripetuti grazie a follow-up migliori
Questi risultati guideranno poi cosa misuri e come lo presenti.
Identifica utenti e ruoli
Elenca chi userà l'app e quali decisioni prendono: ingegneri che indagano incidenti, supporto che scala problemi, manager che rivedono trend e stakeholder che vogliono aggiornamenti sullo stato. Questo influenzerà terminologia, permessi e livello di dettaglio che ogni vista deve mostrare.
Scegli le metriche di affidabilità che contano (SLI/SLO)
Il monitoraggio dell'affidabilità funziona solo se tutti concordano su cosa significa “buono”. Inizia separando tre termini che suonano simili.
SLIs vs SLOs vs SLAs (in parole semplici)
Un SLI (Service Level Indicator) è una misura: “Quale percentuale di richieste ha avuto successo?” o “Quanto tempo hanno impiegato le pagine a caricarsi?”
Un SLO (Service Level Objective) è l'obiettivo per quella misura: “99,9% di successi su 30 giorni.”
Un SLA (Service Level Agreement) è una promessa con conseguenze, di solito esterna (crediti, penali). Per gli strumenti interni, spesso imposti SLO senza SLA formali—sufficienti per allineare aspettative senza trasformare l'affidabilità in diritto contrattuale.
Scegli un set SLI piccolo e coerente per ogni strumento
Mantienilo confrontabile tra strumenti e facile da spiegare. Una baseline pratica è:
- Uptime/disponibilità: lo strumento era raggiungibile?
- Tempo di risposta: quanto velocemente rispondevano pagine o endpoint chiave?
- Tasso di errori: quale quota di check o richieste è fallita (5xx, timeout, stati di errore noti)?
Evita di aggiungere altro finché non puoi rispondere: “Quale decisione guiderà questa metrica?”
Scegli finestre temporali che rispecchiano come la gente pensa
Usa finestre scorrevoli così le scorecard si aggiornano continuamente:
- 7 giorni: cattura regressioni rapidamente
- 30 giorni: report mensile e trend
- 90 giorni: stabilità su base trimestrale
Definisci gli incidenti con livelli di severità chiari
La tua app dovrebbe trasformare le metriche in azione. Definisci livelli di severità (es. Sev1–Sev3) e trigger espliciti come:
- Sev1: servizio down o workflow critico bloccato per X minuti
- Sev2: degrado significativo (es. tasso di errori sopra Y% per Z minuti)
- Sev3: problemi minori o intermittenti
Queste definizioni rendono alerting, timeline di incidente e tracciamento del budget di errore coerenti tra i team.
Pianifica le sorgenti dati e l'approccio di ingestione
Un'app di monitoraggio dell'affidabilità è credibile quanto i dati che la alimentano. Prima di costruire pipeline di ingestione, mappa ogni segnale che tratterai come “verità” e scrivi quale domanda risponde (disponibilità, latenza, errori, impatto dei deploy, risposta agli incidenti).
Mappa le sorgenti dati che hai già
La maggior parte dei team può coprire il necessario usando una combinazione di:
- Status check / probe sintetiche (uptime e tempo di risposta di base)
- Metriche (percentili di latenza, tassi di errore, saturazione)
- Log (conteggi di errore, endpoint che falliscono più spesso)
- Tracce (dove viene spesa la latenza tra dipendenze)
- Strumenti di ticketing/incidenti (inizio/fine incidente, severità, owner, link al postmortem)
Sii esplicito su quali sistemi sono autorevoli. Per esempio, il tuo “SLI di uptime” potrebbe provenire solo dalle probe sintetiche, non dai log del server.
Decidi push vs pull (e con quale frequenza)
- Pull funziona bene per API (Prometheus, monitoring cloud, ticketing): la tua app interroga a intervalli.
- Push è meglio per eventi ad alto volume (deploy, incidenti, alert): i sistemi inviano webhook/eventi alla tua app.
Imposta la frequenza di aggiornamento in base al caso d'uso: le dashboard possono aggiornarsi ogni 1–5 minuti, mentre le scorecard possono essere calcolate ogni ora/giorno.
Normalizza identificatori e ownership
Crea ID coerenti per tool/service, ambienti (prod/stage) e owner. Concorda regole di naming presto così “Payments-API”, “payments_api” e “payments” non diventano tre entità separate.
Retention e privacy
Pianifica cosa conservare e per quanto (es. eventi raw 30–90 giorni, aggregati giornalieri 12–24 mesi). Evita di ingerire payload sensibili; conserva solo i metadati necessari per l'analisi di affidabilità (timestamp, codici di stato, bucket di latenza, tag di incidente).
Progetta il modello dati e lo schema del database
Il tuo schema dovrebbe rendere semplici due cose: rispondere a domande quotidiane (“questo strumento è sano?”) e ricostruire cosa è successo durante un incidente (“quando sono iniziati i sintomi, chi ha cambiato cosa, quali alert sono scattati?”). Parti da un piccolo set di entità core e rendi esplicite le relazioni.
Entità core (parti minime)
- Tool/Service: lo strumento interno tracciato (nome, descrizione, ambiente, criticità).
- Check: un check di uptime o sintetico legato a un tool (tipo, target URL, schedule, abilitato).
- Metric: datapoint di serie temporali (latenza, tasso di successo, conteggio errori) associati a tool o check.
- SLO: obiettivo e finestra di valutazione (es. 99,9% su 30 giorni) più impostazioni di error budget.
- Incident: evento che impatta l'affidabilità (severità, stato, inizio/fine, riassunto).
- Event: record di timeline per incidenti (cambi di stato, note, alert ricevuto, mitigazione applicata).
- Owner: team o individuo responsabile dello strumento.
Relazioni che semplificano le query
Una baseline pratica è:
- Tool ha molti Check (e può avere molti SLO).
- Check ha molte Metriche (o stream metrici).
- Incident appartiene a Tool, e Incident ha molti Event per la timeline.
- Tool appartiene a Owner (o molti-a-molti se la ownership è condivisa).
Questa struttura supporta dashboard (“tool → stato attuale → incidenti recenti”) e drill-down (“incidente → eventi → check e metriche correlate”).
Campi di audit e tagging
Aggiungi campi di audit dove serve responsabilità e storia:
created_by, created_at, updated_atstatus più tracciamento cambi di status (o nella tabella Event o in una history dedicata)
Infine, includi tag flessibili per filtrare e fare report (es. team, criticità, sistema, compliance). Una tabella di join tool_tags (tool_id, key, value) mantiene il tagging coerente e semplifica scorecard e rollup più avanti.
Seleziona stack tecnologico e modello di deployment
Il tuo tracker di affidabilità dovrebbe essere “noioso” nel senso migliore: facile da eseguire, da modificare e da supportare. Lo stack “giusto” è di solito quello che il tuo team può mantenere senza eroismi.
Parti da ciò che il team già conosce
Scegli un framework web mainstream che il team conosce bene—Node/Express, Django o Rails sono tutte opzioni solide. Prioritizza:
- Convenzioni chiare (così i nuovi contributori non si perdono)
- Buone librerie per auth, job in background e chart
- Percorsi di upgrade prevedibili
Se integri sistemi interni (SSO, ticketing, chat), scegli l'ecosistema dove queste integrazioni sono più semplici.
Se vuoi accelerare la prima iterazione, una piattaforma di vibe-coding come Koder.ai può essere un punto di partenza pratico: descrivi le tue entità (tool, check, SLO, incidenti), i workflow (alert → incidente → postmortem) e le dashboard in chat, poi genera rapidamente uno scaffold di web app funzionante. Perché Koder.ai comunemente mira a React sul frontend e Go + PostgreSQL sul backend, si mappa bene allo stack di default “noioso e manutenibile” che molti team preferiscono—e puoi esportare il codice sorgente se poi vuoi passare a una pipeline completamente manuale.
Database prima, poi pezzi di supporto
Per la maggior parte delle app interne, PostgreSQL è il default giusto: gestisce bene reporting relazionale, query basate sul tempo e auditing.
Aggiungi componenti extra solo se risolvono un problema reale:
- Cache (es. Redis) se le dashboard sono lente o sei limitato da API upstream
- Coda/job in background (Redis + worker, Sidekiq, Celery, BullMQ) per polling uptime, invio notifiche e generazione report
Hosting e modello di deployment
Decidi tra:
- Cloud interno / Kubernetes quando serve accesso di rete più stretto ai servizi interni
- PaaS quando vuoi operazioni più semplici e iterazione veloce
Qualunque scelta, standardizza dev/staging/prod e automatizza i deployment (CI/CD), così i cambiamenti non alterano silenziosamente i numeri di affidabilità. Se usi un approccio piattaforma (incluso Koder.ai), cerca funzionalità come separazione degli ambienti, hosting, e rollback rapido (snapshot) per poter iterare senza rompere il tracker stesso.
Gestione della configurazione affidabile
Documenta la configurazione in un unico posto: environment variable, segreti e feature flag. Mantieni una guida minima “come eseguire localmente” e un runbook ridotto (cosa fare se l'ingestione si ferma, la coda si accumula o il DB raggiunge i limiti). Una pagina breve in /docs è spesso sufficiente.
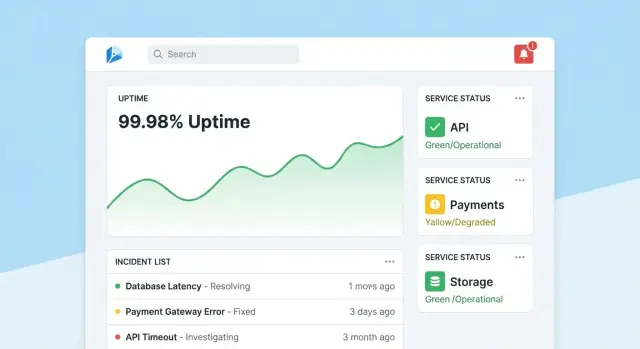
Progetta l'UX: dashboard, drill-down e workflow
Itera con rollback sicuri
Usa snapshot e rollback per iterare su ingestione e alert senza perdere una versione stabile.
Un'app di monitoraggio dell'affidabilità funziona quando le persone possono rispondere a due domande in pochi secondi: “Stiamo bene?” e “Cosa faccio adesso?” Progetta le schermate attorno a queste decisioni, con navigazione chiara da overview → tool specifico → incidente specifico.
Homepage: lettura veloce dello stato
Rendi la homepage un centro di comando compatto. Metti in evidenza un sommario di salute generale (es. numero di tool che rispettano gli SLO, incidenti attivi, principali rischi attuali), poi mostra incidenti e alert recenti con badge di stato.
Mantieni la vista predefinita calma: evidenzia solo ciò che richiede attenzione. Dai a ogni riquadro un drill-down diretto sul tool o sull'incidente interessato.
Ogni pagina di tool dovrebbe rispondere a “Questo strumento è abbastanza affidabile?” e “Perché/no?”. Includi:
- Stato SLO corrente con pass/fail semplice e budget di errore rimanente
- Grafici per uptime, latenza o tasso di errori su intervalli selezionabili
- Cambi recenti (deploy, modifiche config, aggiornamenti check) così i pattern risultano evidenti
- Runbook e owner: una sezione “Cosa fare” ben visibile con link e contatti
Progetta i grafici per non esperti: etichetta le unità, segna le soglie SLO e aggiungi brevi spiegazioni (tooltip) invece di controlli tecnici densi.
Pagina dell'incidente: contesto condiviso e timeline
Una pagina incidente è un record vivo. Includi una timeline (eventi auto-catturati come alert scattato, acknowledged, mitigato), aggiornamenti umani, utenti impattati e azioni intraprese.
Rendi le aggiornamenti facili da pubblicare: una sola casella di testo, stati predefiniti (Investigating/Identified/Monitoring/Resolved) e note interne opzionali. Quando l'incidente viene chiuso, un'azione “Avvia postmortem” dovrebbe precompilare fatti dalla timeline.
Pagine admin: ownership e coerenza
Gli admin hanno bisogno di schermate semplici per gestire tool, check, target SLO e owner. Ottimizza per correttezza: valori predefiniti sensati, validazione e avvisi quando le modifiche impattano i report. Aggiungi una traccia “ultima modifica” visibile così le persone si fidano dei numeri.
Implementa autenticazione, permessi e audit trail
I dati di affidabilità restano utili solo se le persone si fidano. Ciò significa collegare ogni modifica a un'identità, limitare chi può fare edit ad alto impatto e mantenere una storia chiara consultabile durante le review.
Autenticazione: usa quello che la tua azienda già usa
Per uno strumento interno, punta all'SSO (SAML) o OAuth/OIDC tramite il tuo identity provider (Okta, Azure AD, Google Workspace). Questo riduce la gestione password e rende onboarding/offboarding automatico.
Dettagli pratici:
- Applica MFA tramite l'IdP (non reimplementarla)
- Mappa i gruppi IdP ai ruoli dell'app al login
- Imposta sessioni di breve durata e supporta logout manuale
Permessi: ruolo-based con azioni protette
Inizia con ruoli semplici e aggiungi regole più fini solo quando necessario:
- Viewer: dashboard e scorecard in sola lettura per gli stakeholder.
- Editor: creare/aggiornare check, incidenti e note.
- Admin: gestire definizioni SLO, soglie, integrazioni e mappature utenti/ruoli.
Proteggi le azioni che possono cambiare esiti di affidabilità o narrazioni di reportistica:
- Solo Admin può cambiare target SLO, soglie di alert o mapping delle sorgenti dati.
- Restringi chi può chiudere incidenti o marcarli “resolved” e richiedi un riepilogo di risoluzione.
Tracce di audit: storia immutabile delle modifiche
Logga ogni edit a SLO, check e campi di incidente con:
- chi l'ha fatto (utente + ruolo)
- quando è successo (timestamp)
- cosa è cambiato (valori prima/dopo)
- da dove è venuto (UI, API, automazione)
Rendi i log di audit ricercabili e visibili dalle pagine di dettaglio pertinenti (es. la pagina incidente mostra tutta la storia dei cambi). Questo mantiene le review fattuali e riduce i confronti durante i postmortem.
Costruisci check di monitoring e raccolta uptime
Il monitoring è lo “strato sensoriale” della tua app: trasforma il comportamento reale in dati affidabili. Per gli strumenti interni, i check sintetici sono spesso la via più veloce perché tu puoi controllare cosa significa “sano”.
Inizia con un piccolo set di tipi di check che coprono la maggior parte delle app interne:
- HTTP ping: conferma che il servizio risponde (status code, TLS, header di base).
- Validazione endpoint: colpisci un URL noto e valida qualcosa di significativo (forma JSON attesa, una stringa chiave nell'HTML, o il payload di un health endpoint).
- Percorso “smoke” senza login: se possibile, testa un flusso read-only che rifletta l'esperienza utente (es. carica la pagina della dashboard e verifica che si renderizzi).
Mantieni i check deterministici. Se una validazione può fallire a causa di contenuto variabile, creerai rumore e la fiducia scenderà.
Raccogli uptime e latenza (e conservali saggiamente)
Per ogni esecuzione del check, cattura:
- Timestamp (inizio e fine)
- Risultato: up/down/unknown
- Latenza: durata totale (e opzionalmente DNS/connect/TTFB se lo misuri)
- Motivo: codice di errore, timeout, fallimento di validazione o messaggio di eccezione
Conserva i dati come eventi di serie temporali (una riga per ogni run) o come rollup aggregati (es. rollup per minuto con conteggi e p95 di latenza). I dati eventi sono ottimi per debug; i rollup sono ottimi per dashboard veloci. Molti team fanno entrambe le cose: mantengono eventi raw per 7–30 giorni e rollup per report a lungo termine.
Tratta outage vs dati mancanti in modo esplicito
Un risultato mancante di un check non dovrebbe automaticamente significare “down.” Aggiungi uno stato unknown esplicito per casi come:
- il worker del checker è fermo
- partizione di rete tra checker e target
- configurazione rimossa a metà run
Questo evita downtime gonfiato e rende i “gap di monitoring” visibili come problema operativo a sé.
Esegui check su schedule con job in background
Usa worker in background (scheduling tipo cron, code) per eseguire check a intervalli fissi (es. ogni 30–60 secondi per tool critici). Inserisci timeout, retry con backoff e limiti di concorrenza così il tuo checker non sovraccarica i servizi interni. Persiste ogni risultato di run—anche i fallimenti—così la dashboard di uptime mostra sia lo stato corrente sia una cronologia affidabile.
Crea flussi di alerting e notifica
Distribuisci e condividi internamente
Ospita la tua app con deployment integrato, poi aggiungi un dominio personalizzato quando sei pronto.
Gli alert sono il punto in cui il monitoraggio diventa azione. L'obiettivo è semplice: notificare le persone giuste, con il contesto giusto, al momento giusto—senza sommergere tutti.
Collega gli alert agli SLO (non solo a soglie)
Inizia definendo regole di alert che mappano direttamente ai tuoi SLIs/SLOs. Due pattern pratici:
- Burn-rate alert: chiamare quando il budget di errore viene consumato abbastanza velocemente da far mancare l'SLO se non cambia qualcosa.
- Soglie: avvisa quando una metrica supera un confine chiaro (es. disponibilità sotto 99,5% su 15 minuti).
Per ogni regola, memorizza il “perché” insieme al “cosa”: quale SLO è impattato, la finestra di valutazione e la severità prevista.
Rendi le notifiche azionabili
Invia notifiche nei canali dove i team sono già presenti (email, Slack, Microsoft Teams). Ogni messaggio dovrebbe includere:
- Una riga di sintesi (servizio + sintomo + severità)
- Un link diretto alla vista dashboard rilevante (es. /services/payments?window=1h)
- Un link alla pagina incidente se ne è stata creata una (es. /incidents/123)
Evita di scaricare metriche raw. Fornisci un breve “prossimo passo” come “Controlla i deploy recenti” o “Apri i log.”
Riduci il rumore con dedupe, raggruppamento e quiet hours
Implementa:
- Deduplificazione (stessa fingerprint → aggiorna il thread esistente)
- Raggruppamento (un incidente può raccogliere più alert correlati)
- Quiet hours e regole di routing in modo che alert a bassa severità non sveglino l'on-call
Supporta escalation e routing on-call
Anche in uno strumento interno, le persone hanno bisogno di controllo. Aggiungi escalation manuale (pulsante sulla pagina alert/incidente) e integra con tool on-call se disponibili (PagerDuty/Opsgenie equivalenti), o almeno una lista di rotazione configurabile memorizzata nell'app.
Aggiungi gestione incidenti e funzionalità postmortem
La gestione degli incidenti trasforma “abbiamo ricevuto un alert” in una risposta condivisa e tracciabile. Costruiscila nell'app così le persone possono passare dal segnale alla coordinazione senza saltare tra strumenti.
Creazione incidente con un clic
Rendi possibile creare un incidente direttamente da un alert, da una pagina servizio o da un grafico uptime. Precompila campi chiave (servizio, ambiente, fonte dell'alert, primo istante rilevato) e assegna un ID incidente univoco.
Un set di campi predefinito mantiene il flusso leggero: severità, impatto sui “clienti” (team interni coinvolti), owner corrente e link all'alert che ha scatenato tutto.
Ciclo di vita dello stato e collaborazione
Usa un ciclo semplice che rispecchi il modo in cui i team lavorano veramente:
- Open → Investigating → Mitigated → Resolved
Ogni cambio di stato dovrebbe registrare chi lo ha fatto e quando. Aggiungi aggiornamenti a timeline (note brevi con timestamp), supporto per allegati e link a runbook e ticket (es. /runbooks/payments-retries o /tickets/INC-1234). Questo diventa il thread unico per “cosa è successo e cosa abbiamo fatto”.
Postmortem con azioni
I postmortem devono essere veloci da avviare e coerenti da revisionare. Fornisci template con:
- Riassunto, impatto, rilevazione e causa radice
- Fattori che hanno contribuito (inclusi gap di processo)
- Cosa ha funzionato / cosa no
- Azioni con owner e date di scadenza
Collega gli action item all'incidente, traccia il completamento e metti in evidenza gli item scaduti nelle dashboard del team. Se supporti le review di apprendimento, abilita una modalità “blameless” che si concentri su sistemi e processi invece che su errori individuali.
Reporting e scorecard di affidabilità
Esporta il sorgente in qualsiasi momento
Mantieni il controllo completo esportando il codice quando vuoi spostarti sulla tua pipeline.
Il reporting è dove il monitoraggio diventa decisione. Le dashboard aiutano gli operatori; le scorecard aiutano i leader a capire se gli strumenti interni stanno migliorando, dove investire e cosa significa “bene”.
Cosa includere in una scorecard
Costruisci una vista coerente e ripetibile per ogni tool (e opzionalmente per team) che risponda velocemente a poche domande:
- Conformità SLO nel tempo: mostra il periodo corrente (settimana/mese/trimestre) e una linea di trend contro l'obiettivo SLO.
- Tool meno affidabili: classifica per SLO mancato, minuti di downtime più alti o burn di error-budget peggiori.
- MTTR: median e p90 del tempo di ripristino, così un singolo incidente lungo non nasconde un pattern.
- Conteggio incidenti: totale incidenti più suddivisione per severità (Sev1–Sev3), con confronto al periodo precedente.
Dove possibile, aggiungi contesto leggero: “SLO mancato a causa di 2 deploy” o “La maggior parte del downtime dal dipendente X”, senza trasformare il report in una review completa di incidente.
Filtri che rendono il reporting dei leader utilizzabile
I leader raramente vogliono “tutto”. Aggiungi filtri per team, criticità del tool (es. Tier 0–3) e finestra temporale. Assicurati che lo stesso tool possa apparire in più rollup (il team platform lo possiede, finance lo usa).
Riepiloghi ed esportazioni
Fornisci riepiloghi settimanali e mensili che si possono condividere fuori dall'app:
- Esportazione CSV con un clic per fogli di calcolo
- Esportazione PDF pulita per review di stato
Mantieni la narrativa coerente (“Cosa è cambiato rispetto al periodo precedente?” “Dove siamo oltre budget?”). Se serve un primer per gli stakeholder, linka una breve guida come /blog/sli-slo-basics.
Sicurezza, qualità dei dati e hardening operativo
Un tracker di affidabilità diventa rapidamente fonte di verità. Trattalo come un sistema di produzione: sicuro per default, resistente ai dati sporchi e facile da recuperare quando qualcosa va storto.
Proteggi la superficie dell'app
Blocca ogni endpoint—anche quelli “solo interni”.
- Valida gli input al confine (tipi, range, enum ammessi, dimensione massima payload) e rifiuta campi sconosciuti.
- Aggiungi rate limiting per utente/token di servizio per evitare client rumorosi che sovraccaricano ingestione o dashboard.
- Usa query parametrizzate e pattern ORM sicuri per evitare injection.
Segreti e controllo accessi
Tieni le credenziali fuori dal codice e fuori dai log.
Conserva i segreti in un secret manager e ruotali. Dai all'app web accesso al DB con il minimo privilegio: ruoli lettura/scrittura separati, restrizioni solo alle tabelle necessarie e credenziali a vita breve se possibile. Cripta i dati in transito (TLS) tra browser↔app e app↔database.
Guardrail per la qualità dei dati
Le metriche sono utili solo se gli eventi sottostanti sono affidabili.
Aggiungi controlli server-side per timestamp (timezone/clock skew), campi obbligatori e chiavi di idempotenza per deduplicare i retry. Traccia errori di ingestione in una dead-letter queue o tabella di “quarantena” così eventi corrotti non inquinano le dashboard.
Basi operative (non saltarle)
Automatizza migrazioni DB e testa rollback. Pianifica backup, verifica regolarmente i restore e documenta un piano di disaster recovery minimo (chi, cosa, quanto tempo).
Infine, rendi affidabile anche l'app di affidabilità: aggiungi health check, monitoraggio base per lag delle code e latenza DB, e alert quando l'ingestione scende silenziosamente a zero.
Piano di rollout e roadmap di iterazione
Un'app di monitoraggio ha successo quando la gente si fida e la usa. Considera la prima release come un loop di apprendimento, non un lancio “big bang”.
Parti con un pilot focalizzato
Scegli 2–3 strumenti interni largamente usati e con owner chiari. Implementa un set minimo di check (per esempio: disponibilità homepage, successo login e un endpoint API chiave) e pubblica una dashboard che risponda: “È su? Se no, cosa è cambiato e chi lo possiede?”
Mantieni il pilot visibile ma contenuto: un team o un piccolo gruppo di power user basta per convalidare il flusso.
Raccogli feedback dove fa più male
Nelle prime 1–2 settimane, raccogli attivamente feedback su:
- Cosa risulta confuso (nomi metriche, grafici, filtri, definizioni)
- Cosa è rumoroso (alert che non mappano a impatto utente)
- Cosa manca (ownership, runbook, link a incidenti)
Trasforma il feedback in backlog concreto. Un semplice pulsante “Segnala un problema con questa metrica” su ogni grafico spesso fa emergere le intuizioni più rapide.
Itera con integrazioni e automazioni
Aggiungi valore a strati: connetti lo strumento di chat per notifiche, poi lo strumento incidente per creazione ticket automatica, poi CI/CD per marker dei deploy. Ogni integrazione dovrebbe ridurre lavoro manuale o abbreviare il tempo di diagnosi—altrimenti è solo complessità.
Se stai prototipando velocemente, considera l'uso della planning mode di Koder.ai per mappare l'ambito iniziale (entità, ruoli e workflow) prima di generare la prima build. È un modo semplice per mantenere l'MVP compatto—e poiché puoi snapshot e rollback, puoi iterare su dashboard e ingestione in sicurezza mentre i team rifiniscono le definizioni.
Definisci metriche di successo ed espandi
Prima di estendere ad altri team, definisci metriche di successo come utenti attivi settimanali della dashboard, riduzione del time-to-detect, meno alert duplicati o revisioni SLO coerenti. Pubblica una roadmap leggera in /blog/reliability-tracking-roadmap ed espandi strumento per strumento con owner chiari e sessioni di training.