13 dic 2025·8 min
Dalla startup grafica al colosso dell'IA: la storia di Nvidia
Esplora il percorso di Nvidia dal 1993, da startup grafica a potenza globale dell'IA, seguendo prodotti chiave, svolte, leader e scelte strategiche.
Esplora il percorso di Nvidia dal 1993, da startup grafica a potenza globale dell'IA, seguendo prodotti chiave, svolte, leader e scelte strategiche.
Nvidia è diventata un nome noto per motivi molto diversi, a seconda di chi chiedi. I giocatori su PC pensano alle schede GeForce e ai frame rate fluidi. I ricercatori di IA pensano alle GPU che addestrano modelli all'avanguardia in giorni invece che in mesi. Gli investitori vedono una delle società di semiconduttori più preziose della storia, un titolo che è diventato un proxy per l'intero boom dell'IA.
Eppure tutto questo non era inevitabile. Quando Nvidia fu fondata nel 1993, era una piccola startup che puntava su un'idea di nicchia: che i chip grafici avrebbero rimodellato il personal computing. In oltre tre decenni è passata da produttore di schede grafiche a fornitore centrale di hardware e software per l'IA moderna, alimentando tutto, dai sistemi di raccomandazione ai prototipi per la guida autonoma fino ai grandi modelli di linguaggio.
Capire la storia di Nvidia è uno dei modi più chiari per comprendere l'hardware dell'IA moderna e i modelli di business che si stanno formando attorno a esso. L'azienda siede all'incrocio di diverse forze:
Lungo la strada, Nvidia ha ripetutamente fatto scommesse ad alto rischio: puntare sulle GPU programmabili prima che esistesse un mercato chiaro, costruire uno stack software completo per il deep learning e spendere miliardi in acquisizioni come Mellanox per controllare meglio il data center.
Questo articolo traccia il percorso di Nvidia dal 1993 a oggi, con attenzione a:
L'articolo è pensato per lettori interessati a tecnologia, business e investimenti che vogliono una visione narrativa chiara di come Nvidia sia diventata un gigante dell'IA — e cosa potrebbe succedere dopo.
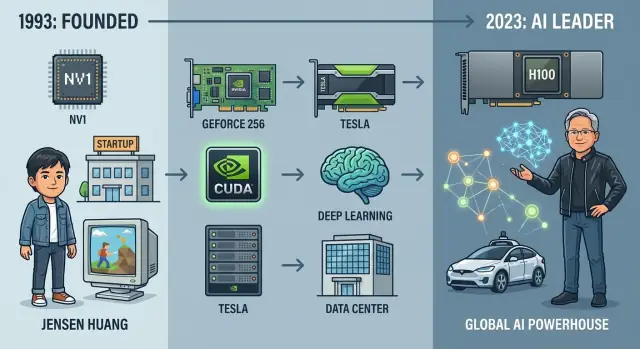
Nel 1993 tre ingegneri con personalità diverse ma la stessa convinzione sulla grafica 3D fondarono Nvidia in una cabina di un Denny's nella Silicon Valley. Jensen Huang, ingegnere taiwanese‑americano ed ex progettista di chip alla LSI Logic, portava grande ambizione e abilità nello storytelling con clienti e investitori. Chris Malachowsky arrivava da Sun Microsystems con esperienza in workstation ad alte prestazioni. Curtis Priem, ex IBM e Sun, era l'architetto di sistema ossessionato da come hardware e software si integrassero.
All'epoca la Valley ruotava intorno a workstation, minicomputer e ai nascente produttori di PC. La grafica 3D era potente ma costosa, per lo più legata a Silicon Graphics (SGI) e a fornitori di workstation rivolti a CAD, cinema e visualizzazione scientifica.
Huang e i co‑fondatori videro un'opportunità: portare quel tipo di potenza visiva in PC accessibili. Se milioni di persone avessero potuto avere grafica 3D di alta qualità per giochi e multimedia, il mercato sarebbe stato molto più grande del mondo di nicchia delle workstation.
L'idea fondante di Nvidia non era creare semiconduttori generici, ma offrire grafica accelerata per il mercato di massa. Invece di lasciare tutto alla CPU, un processore grafico specializzato avrebbe gestito i calcoli pesanti del rendering 3D.
Il team credeva che questo richiedesse:
Huang raccolse capitale iniziale da venture come Sequoia, ma i soldi non abbondavano mai. Il primo chip, NV1, era ambizioso ma non allineato con lo standard DirectX emergente e con le API di gioco dominanti. Vendette poco e rischiò di mandare l'azienda in rovina.
Nvidia sopravvisse pivotando rapidamente verso NV3 (RIVA 128), riposizionando l'architettura attorno agli standard di settore e imparando a collaborare molto più strettamente con sviluppatori di giochi e Microsoft. La lezione: la tecnologia da sola non bastava; l'allineamento con l'ecosistema determinava la sopravvivenza.
Fin dall'inizio, Nvidia coltivò una cultura in cui gli ingegneri avevano un'influenza sproporzionata e il time‑to‑market era trattato come esistenziale. I team si muovevano velocemente, iteravano i progetti aggressivamente e accettavano che alcune scommesse potessero fallire.
I vincoli di cassa generarono parsimonia: mobili d'ufficio riutilizzati, lunghe ore e la propensione a assumere un piccolo numero di ingegneri molto capaci invece di costruire grandi gerarchie. Quella cultura iniziale — intensità tecnica, urgenza e spesa attenta — avrebbe poi plasmato come Nvidia avrebbe affrontato opportunità molto più grandi oltre la grafica PC.
Nei primi‑metà anni '90 la grafica PC era basilare e frammentata. Molti giochi usavano ancora il rendering software, con la CPU che faceva la maggior parte del lavoro. Esistevano acceleratori 2D dedicati per Windows e prime schede 3D come la Voodoo di 3dfx, ma non c'era un modo standard per programmare l'hardware 3D. API come Direct3D e OpenGL erano ancora in evoluzione, e gli sviluppatori spesso dovevano mirare a schede specifiche.
Questo era l'ambiente in cui Nvidia entrò: rapido, disordinato e pieno di opportunità per chi fosse capace di combinare prestazioni con un modello di programmazione chiaro.
Il primo prodotto importante di Nvidia, NV1, uscì nel 1995. Cercava di fare tutto insieme: 2D, 3D, audio e persino supporto per il gamepad Sega Saturn su un'unica scheda. Tecnicamente puntava su superfici quadratiche invece che su triangoli, proprio mentre Microsoft e gran parte dell'industria standardizzavano le API 3D attorno ai poligoni triangolari.
Il disallineamento con DirectX e il supporto software limitato resero NV1 un insuccesso commerciale. Ma insegnò due lezioni cruciali: seguire l'API dominante (DirectX) e concentrarsi nettamente sulle prestazioni 3D piuttosto che su funzionalità esotiche.
Nvidia si riorganizzò con RIVA 128 nel 1997. Abbracciò i triangoli e Direct3D, offrì solide prestazioni 3D e integrò 2D e 3D in una singola scheda. I recensori notarono il cambiamento e gli OEM cominciarono a vedere Nvidia come un partner serio.
RIVA TNT e TNT2 affinarono la formula: migliore qualità d'immagine, risoluzioni più elevate e driver migliorati. Mentre 3dfx manteneva una forte presenza nella mente dei consumatori, Nvidia recuperava rapidamente spedendo aggiornamenti frequenti dei driver e corteggiando gli sviluppatori di giochi.
Nel 1999 Nvidia introdusse la GeForce 256 e la definì la "prima GPU al mondo" — una Graphics Processing Unit. Non era solo marketing. GeForce 256 integrò hardware per transform and lighting (T&L), scaricando i calcoli di geometria dalla CPU al chip grafico.
Questo spostamento liberò le CPU per la logica di gioco e la fisica, mentre la GPU gestiva scene 3D sempre più complesse. I giochi poterono disegnare più poligoni, usare un'illuminazione più realistica e girare più fluidamente a risoluzioni più alte.
Allo stesso tempo, il gaming su PC stava esplodendo, guidato da titoli come Quake III Arena e Unreal Tournament, e dall'adozione rapida di Windows e DirectX. Nvidia si allineò strettamente a questa crescita.
La compagnia ottenne design win con OEM come Dell e Compaq, assicurandosi che milioni di PC mainstream venissero spediti con grafica Nvidia di default. Programmi di marketing congiunti con studi di gioco e il branding “The Way It’s Meant to Be Played” rafforzarono l'immagine di Nvidia come scelta di riferimento per i giocatori seri.
All'inizio degli anni 2000 Nvidia era passata da startup in difficoltà con un prodotto iniziale mal allineato a forza dominante nella grafica PC, preparando il terreno per tutto ciò che sarebbe venuto dopo nel calcolo GPU e, infine, nell'IA.
All'inizio le GPU erano macchine a funzione fissa: pipeline cablate che prendevano vertici e texture e restituivano pixel. Erano incredibilmente veloci, ma quasi completamente rigide.
Verso i primi anni 2000 gli shader programmabili (vertex e pixel/fragment shader in DirectX e OpenGL) cambiarono le regole. Con chip come la GeForce 3, e poi GeForce FX e GeForce 6, Nvidia iniziò a esporre piccole unità programmabili che permettevano agli sviluppatori di scrivere effetti personalizzati invece di fare affidamento su una pipeline rigida.
Questi shader erano ancora pensati per la grafica, ma piantarono un'idea cruciale dentro Nvidia: se una GPU poteva essere programmata per molti effetti visivi diversi, perché non programmarla per il calcolo in senso più ampio?
Il calcolo generale su GPU (GPGPU) era una scommessa contraria. Internamente molti si chiedevano se valesse la pena spendere transistor, tempo di ingegneria e sforzi software su carichi di lavoro diversi dal gaming. Esternamente, gli scettici liquidavano le GPU come giocattoli per la grafica, e i primi esperimenti di GPGPU — sfruttare shader di frammento per algebra lineare — erano notoriamente faticosi.
La risposta di Nvidia fu CUDA, annunciata nel 2006: un modello di programmazione simile a C/C++, runtime e toolchain pensati per far sentire la GPU come un coprocessore massicciamente parallelo. Invece di costringere gli scienziati a pensare in termini di triangoli e pixel, CUDA espose thread, block, grid e gerarchie di memoria esplicite.
Fu un enorme rischio strategico: Nvidia dovette costruire compilatori, debugger, librerie, documentazione e programmi di formazione — investimenti software più tipici di una piattaforma che di un venditore di chip.
I primi successi arrivarono dall'high‑performance computing:
I ricercatori poterono improvvisamente eseguire simulazioni di settimane in giorni o ore, spesso su una singola GPU in una workstation invece che su un intero cluster di CPU.
CUDA fece più che accelerare il codice; creò un ecosistema di sviluppatori attorno all'hardware Nvidia. L'azienda investì in SDK, librerie matematiche (come cuBLAS e cuFFT), programmi universitari e nella propria conferenza (GTC) per insegnare la programmazione parallela su GPU.
Ogni applicazione e libreria CUDA approfondiva il fossato: gli sviluppatori ottimizzavano per le GPU Nvidia, i toolchain maturavano attorno a CUDA e nuovi progetti cominciavano con Nvidia come acceleratore predefinito. Molto prima che l'addestramento AI riempisse i data center di GPU, quell'ecosistema aveva già trasformato la programmabilità in uno degli asset strategici più potenti di Nvidia.
Metà anni 2000 il business gaming di Nvidia prosperava, ma Jensen Huang e il suo team videro un limite nell'affidarsi solo alle GPU consumer. La stessa potenza di elaborazione parallela che rendeva i giochi più fluidi poteva accelerare simulazioni scientifiche, finanza e, in seguito, l'IA.
Nvidia iniziò a posizionare le GPU come acceleratori generici per workstation e server. Le schede professionali per designer e ingegneri (linea Quadro) furono un passo iniziale, ma la scommessa più grande era entrare direttamente nel cuore del data center.
Nel 2007 Nvidia introdusse la famiglia Tesla, le prime GPU costruite specificamente per HPC e workload server piuttosto che per display.
Le schede Tesla enfatizzavano prestazioni in doppia precisione, memoria con correzione degli errori e efficienza energetica in rack densi — caratteristiche che i data center e i centri di supercalcolo apprezzavano molto più dei frame rate.
HPC e laboratori nazionali divennero adottatori chiave. Sistemi come il supercomputer “Titan” dell'Oak Ridge National Laboratory dimostrarono che cluster di GPU programmabili con CUDA potevano offrire enormi accelerazioni per fisica, modellazione climatica e dinamica molecolare. Quella credibilità nell'HPC avrebbe poi aiutato a convincere enterprise e cloud che le GPU erano infrastruttura seria, non solo hardware da gaming.
Nvidia investì molto nelle relazioni con università e istituti di ricerca, dotando laboratori di hardware e strumenti CUDA. Molti ricercatori che sperimentarono il calcolo GPU in ambito accademico poi guidarono l'adozione dentro aziende e startup.
Allo stesso tempo, i primi cloud provider cominciarono a offrire istanze con GPU Nvidia, rendendo le Tesla accessibili on‑demand a chiunque avesse una carta di credito, essenziale per il deep learning su GPU.
Con la crescita dei mercati data center e professionali, la base di ricavi di Nvidia si è ampliata. Il gaming rimase un pilastro, ma nuovi segmenti — HPC, AI enterprise e cloud — divennero un secondo motore di crescita, creando la base economica per la successiva dominanza nell'AI.
Il punto di svolta arrivò nel 2012, quando una rete neurale chiamata AlexNet stupì la comunità di computer vision dominando la sfida ImageNet. Crucialmente, girava su una coppia di GPU Nvidia. Ciò che era stato un'idea di nicchia — addestrare grandi reti neurali con chip grafici — sembrò all'improvviso il futuro dell'IA.
Le reti neurali profonde sono costruite da enormi quantità di operazioni identiche: moltiplicazioni di matrici e convoluzioni applicate a milioni di pesi e attivazioni. Le GPU sono progettate per eseguire migliaia di thread semplici in parallelo per lo shading grafico. Quella stessa parallelità si adattava quasi perfettamente alle reti neurali.
Invece di renderizzare pixel, le GPU potevano processare neuroni. Workload pesanti di calcolo che sulle CPU avrebbero impiegato tempi lunghissimi potevano essere accelerati di ordini di grandezza. I tempi di addestramento che prima richiedevano settimane crollarono a giorni o ore, permettendo ai ricercatori di iterare rapidamente e scalare i modelli.
Nvidia si mosse in fretta per trasformare questa curiosità da ricerca in una piattaforma. CUDA già offriva un modo per programmare le GPU, ma il deep learning richiedeva strumenti di livello più alto.
Nvidia costruì cuDNN, una libreria ottimizzata per GPU per i primiti delle reti neurali — convoluzioni, pooling, funzioni di attivazione. Framework come Caffe, Theano, Torch e poi TensorFlow e PyTorch integrarono cuDNN, così i ricercatori ottennero accelerazioni GPU senza dover ottimizzare manualmente i kernel.
Parallelamente, Nvidia adattò l'hardware: aggiungendo supporto per precisione mista, memoria ad alta larghezza di banda e poi Tensor Cores nelle architetture Volta e successive, progettati specificamente per l'algebra matriciale nel deep learning.
Nvidia coltivò relazioni strette con laboratori AI e ricercatori in istituzioni come University of Toronto, Stanford, Google, Facebook e startup precoci come DeepMind. L'azienda fornì hardware iniziale, supporto ingegneristico e driver custom, ottenendo in cambio feedback diretto sulle necessità dei carichi AI.
Per rendere il supercomputing AI più accessibile, Nvidia introdusse i sistemi DGX — server AI pre‑integrati con GPU di fascia alta, interconnessioni veloci e software ottimizzato. DGX‑1 e i successivi divennero l'appliance di riferimento per molti laboratori e imprese che costruivano capacità di deep learning serie.
Con GPU come Tesla K80, P100, V100 e infine A100 e H100, Nvidia smise di essere una “azienda di gaming che faceva anche compute” e divenne il motore predefinito per l'addestramento e il deployment dei modelli deep learning più avanzati. Il momento AlexNet aveva aperto una nuova era, e Nvidia si era posizionata al centro.
Nvidia non ha vinto l'IA vendendo solo chip più veloci. Ha costruito una piattaforma end‑to‑end che rende la creazione, il deployment e la scalabilità dell'IA molto più semplici su hardware Nvidia che altrove.
La base è CUDA, il modello di programmazione parallela di Nvidia introdotto nel 2006. CUDA permette agli sviluppatori di trattare la GPU come un acceleratore generale, con toolchain familiari in C/C++ e Python.
Sopra CUDA, Nvidia stratifica librerie e SDK specializzati:
Questo stack fa sì che un ricercatore o ingegnere scriva raramente codice GPU di basso livello; richiamano librerie Nvidia ottimizzate per ogni generazione di GPU.
Anni di investimento in tooling CUDA, documentazione e formazione hanno creato un fossato potente. Milioni di linee di codice in produzione, progetti accademici e framework open‑source sono ottimizzati per le GPU Nvidia.
Spostarsi su un'architettura rivale spesso significa riscrivere kernel, riconvalidare modelli e riqualificare ingegneri. Questo costo di switching tiene sviluppatori, startup e grandi imprese ancorati a Nvidia.
Nvidia collabora strettamente con hyperscaler, fornendo piattaforme di riferimento HGX e DGX, driver e stack software ottimizzati così che i clienti possano noleggiare GPU con il minimo attrito.
La suite Nvidia AI Enterprise, il catalogo software NGC e modelli pre‑addestrati offrono alle imprese un percorso supportato dal pilot alla produzione, on‑premise o in cloud.
Nvidia estende la sua piattaforma in soluzioni verticali complete:
Queste piattaforme verticali combinano GPU, SDK, applicazioni di riferimento e integrazioni partner, offrendo ai clienti soluzioni quasi turnkey.
Nutrendo ISV, partner cloud, laboratori di ricerca e system integrator attorno al proprio stack software, Nvidia trasformò le GPU nell'hardware predefinito per l'IA.
Ogni nuovo framework ottimizzato per CUDA, ogni startup che lancia su Nvidia e ogni servizio cloud tarato per le sue GPU rafforza un circolo virtuoso: più software su Nvidia attrae più utenti, giustificando nuovi investimenti e ampliando il divario con i concorrenti.
La crescita di Nvidia nell'IA riguarda tanto le scelte strategiche oltre la GPU quanto i chip stessi.
L'acquisizione di Mellanox nel 2019 fu una svolta. Mellanox portò InfiniBand e Ethernet di fascia alta, oltre a competenza in interconnessioni a bassa latenza e alta throughput.
Addestrare grandi modelli AI dipende dal collegare migliaia di GPU in un singolo computer logico. Senza networking veloce, le GPU restano inattive in attesa di dati o di sincronizzazione dei gradienti. Tecnologie come InfiniBand, RDMA, NVLink e NVSwitch riducono l'overhead di comunicazione e permettono a cluster massivi di scalare in modo efficiente. Perciò i sistemi più preziosi di Nvidia — DGX, HGX e riferimenti di data center completi — combinano GPU, CPU, NIC, switch e software in una piattaforma integrata. Mellanox ha dato a Nvidia un controllo critico su quel tessuto.
Nel 2020 Nvidia annunciò l'intenzione di acquisire Arm, con l'obiettivo di combinare la sua esperienza nell'accelerazione AI con un'architettura CPU largamente licenziata usata in telefoni, dispositivi embedded e sempre più nei server.
I regolatori in USA, UK, UE e Cina sollevarono forti preoccupazioni antitrust: Arm è un fornitore di IP neutrale per molti dei rivali di Nvidia, e la consolidazione minacciava quella neutralità. Dopo un lungo scrutinio e opposizione dell'industria, Nvidia abbandonò l'accordo nel 2022.
Anche senza Arm, Nvidia proseguì con il proprio CPU Grace, dimostrando l'intenzione di modellare il nodo di data center completo, non solo la scheda acceleratrice.
Omniverse estende Nvidia nella simulazione, nei digital twin e nella collaborazione 3D. Connette strumenti e dati attorno a OpenUSD, permettendo alle imprese di simulare fabbriche, città e robot prima di dispiegarli nel mondo reale. Omniverse è sia un carico di lavoro GPU pesante sia una piattaforma software che fidelizza gli sviluppatori.
Nell'automotive, la piattaforma DRIVE mira all'elaborazione centralizzata in auto, alla guida autonoma e all'assistenza avanzata alla guida. Fornendo hardware, SDK e strumenti di validazione ad automaker e fornitori tier‑1, Nvidia si inserisce in cicli di prodotto lunghi e ricavi software ricorrenti.
All'edge, i moduli Jetson e gli stack software associati alimentano robotica, telecamere intelligenti e AI industriale. Questi prodotti portano la piattaforma AI di Nvidia in retail, logistica, sanità e città, catturando workload che non possono vivere solo nel cloud.
Attraverso Mellanox e il networking, giocate fallite ma istruttive come Arm, ed espansioni in Omniverse, automotive e edge AI, Nvidia si è deliberatamente spostata oltre il ruolo di “venditore di GPU”.
Oggi vende:
Queste mosse rendono Nvidia più difficile da scalzare: i concorrenti devono eguagliare non solo un chip, ma uno stack integrato che spazia compute, networking, software e soluzioni specifiche di dominio.
L'ascesa di Nvidia ha attirato rivali potenti, regolatori più severi e nuovi rischi geopolitici che modellano ogni mossa strategica dell'azienda.
AMD resta il principale pari di Nvidia nelle GPU, spesso competendo testa a testa su gaming e acceleratori data center. Le GPU MI di AMD mirano gli stessi clienti cloud e hyperscale che Nvidia serve con H100 e parti successive.
Intel attacca su più fronti: CPU x86 che dominano ancora i server, proprie GPU discrete e acceleratori AI dedicati. Allo stesso tempo, hyperscaler come Google (TPU), Amazon (Trainium/Inferentia) e una ondata di startup (es. Graphcore, Cerebras) progettano chip propri per ridurre la dipendenza da Nvidia.
La difesa chiave di Nvidia rimane una combinazione di leadership nelle prestazioni e software. CUDA, cuDNN, TensorRT e un profondo stack di SDK ancorano sviluppatori ed enterprise. Il solo hardware non basta; portare modelli e tooling fuori dall'ecosistema Nvidia comporta costi reali di switching.
I governi considerano ora le GPU avanzate come asset strategici. I controlli alle esportazioni USA hanno ripetutamente limitato la spedizione di chip AI di fascia alta verso la Cina e altri mercati sensibili, costringendo Nvidia a progettare varianti “compliant” con prestazioni ridotte. Questi controlli proteggono la sicurezza nazionale ma limitano l'accesso a una grande regione di crescita.
I regolatori osservano anche il potere di mercato di Nvidia. L'acquisizione bloccata di Arm ha evidenziato preoccupazioni sul controllo di IP fondamentale. Con la crescita della quota di Nvidia negli acceleratori AI, i regolatori in USA, UE e altrove sono più inclini a esaminare esclusività, bundling e possibili discriminazioni nell'accesso ad hardware e software.
Nvidia è fabless e dipende fortemente da TSMC per la produzione all'avanguardia. Qualsiasi disruption a Taiwan — che sia disastro naturale, tensione politica o conflitto — colpirebbe direttamente la capacità di Nvidia di fornire GPU top‑tier.
La carenza globale di capacità di packaging avanzato (CoWoS, integrazione HBM) crea già colli di bottiglia, dando a Nvidia meno flessibilità per rispondere a una domanda in impennata. L'azienda deve negoziare capacità, navigare le frizioni tecnologiche tra USA e Cina e coprire il rischio di regole di esportazione che possono cambiare più velocemente delle roadmap dei semiconduttori.
Bilanciare queste pressioni mantenendo il vantaggio tecnologico è ormai tanto un compito geopolitico e regolatorio quanto ingegneristico.
Jensen Huang è un founder‑CEO che si comporta ancora da ingegnere pratico. È profondamente coinvolto nella strategia di prodotto, partecipa a review tecniche e sessioni alla lavagna, non solo alle conference call sugli utili.
La sua immagine pubblica coniuga showmanship e chiarezza. Le presentazioni con la giacca di pelle sono deliberate: usa metafore semplici per spiegare architetture complesse, posizionando Nvidia come azienda che capisce sia la fisica sia il business. Internamente è noto per feedback diretti, aspettative alte e la volontà di prendere decisioni scomode quando tecnologia o mercati cambiano.
La cultura di Nvidia ruota attorno a pochi temi ricorrenti:
Questa combinazione fa coesistere loop di feedback lunghi (progettazione chip) con loop rapidi (software e ricerca), e richiede collaborazione stretta tra hardware, software e ricerca.
Nvidia investe regolarmente in piattaforme pluriennali — nuove architetture GPU, interconnessioni, CUDA, framework AI — pur gestendo le aspettative trimestrali.
Organizzativamente significa:
Huang spesso inquadra le call sugli utili attorno a tendenze secolari (IA, calcolo accelerato) per mantenere gli investitori allineati con l'orizzonte temporale dell'azienda, anche quando la domanda a breve può oscillare.
Nvidia tratta gli sviluppatori come un cliente primario. CUDA, cuDNN, TensorRT e decine di SDK di dominio sono supportati da:
Gli ecosistemi partner — OEM, cloud provider, system integrator — vengono coltivati con design di riferimento, marketing congiunto e accesso anticipato alle roadmap. Questo tessuto stretto rende la piattaforma Nvidia collosa e difficile da rimpiazzare.
Con la crescita da vendor di schede grafiche a piattaforma AI globale, la cultura di Nvidia si è evoluta:
Nonostante la scala, Nvidia ha cercato di preservare una mentalità guidata dal founder e incentrata sull'ingegneria, dove scommesse tecniche ambiziose sono incoraggiate e i team devono muoversi rapidamente per raggiungere breakthrough.
L'arco finanziario di Nvidia è tra i più impressionanti in tecnologia: da fornitore di grafica PC a società da trilioni di dollari al centro del boom dell'IA.
Dopo l'IPO del 1999, Nvidia passò anni valutata in poche decine di miliardi, legata ai mercati ciclici di PC e gaming. Negli anni 2000 i ricavi crebbero costantemente fino ai primi miliardi, ma l'azienda era ancora vista come un vendor specialistico, non come leader di piattaforma.
L'inflessione arrivò a metà anni 2010 quando i ricavi del data center e dell'IA cominciarono a comporre. Verso il 2017 la capitalizzazione superò i 100 miliardi; nel 2021 divenne una delle società di semiconduttori più preziose al mondo. Nel 2023 entrò brevemente nel club del trilione e nel 2024 spesso venne scambiata ampiamente sopra tale livello, riflettendo la convinzione degli investitori che Nvidia sia infrastruttura fondamentale per l'IA.
Per gran parte della sua storia le GPU gaming furono il core business. Le grafiche consumer e le schede workstation guidavano gran parte dei ricavi e dei profitti.
Quel mix si è invertito con l'esplosione dell'IA e del calcolo accelerato nel cloud:
L'economia dell'hardware AI ha trasformato il profilo finanziario di Nvidia. Le piattaforme acceleratrici di fascia alta, insieme al networking e al software, hanno prezzi premium e margini elevati. Con la crescita del data center i margini complessivi si sono ampliati, trasformando Nvidia in una macchina di cassa con leva operativa straordinaria.
La domanda AI non ha solo aggiunto una linea di prodotto; ha ridefinito come gli investitori valutano Nvidia. L'azienda è passata dall'essere modellata come nome ciclico dei semiconduttori a essere trattata più come infrastruttura critica e piattaforma software.
I margini lordi, sostenuti dagli acceleratori AI e dal software di piattaforma, sono saliti stabilmente oltre il 70% in alcune metriche. Con costi fissi che scalano molto più lentamente dei ricavi, i margini incrementali sulla crescita AI sono stati estremamente alti, guidando accelerazioni significative degli utili per azione. Questo ha innescato ondate di riallineamenti dalle stime degli analisti e ricalibrature della valutazione del titolo.
La storia del prezzo delle azioni di Nvidia è punteggiata da rally spettacolari e forti ritracciamenti.
L'azienda ha effettuato split azionari per mantenere il prezzo per azione accessibile: diversi split 2‑per‑1 nei primi anni 2000, uno 4‑per‑1 nel 2021 e uno 10‑per‑1 nel 2024. Gli azionisti di lungo periodo che hanno mantenuto le posizioni hanno visto rendimenti composti straordinari.
La volatilità è stata altrettanto notevole. Il titolo ha subìto forti ribassi durante:
Ogni volta, preoccupazioni sulla ciclicità o correzioni di domanda hanno colpito le azioni. Eppure il successivo boom dell'IA ha più volte portato Nvidia a nuovi massimi mentre le aspettative venivano ricalibrate.
Nonostante il successo, Nvidia non è priva di rischi. Gli investitori discutono vari temi chiave:
D'altro canto, il caso rialzista a lungo termine è che il calcolo accelerato e l'IA diventino standard nei data center, nelle imprese e nei dispositivi edge per decenni. In tale visione, la combinazione di GPU, networking, software ed ecosystem lock‑in di Nvidia potrebbe giustificare anni di crescita elevata e margini robusti, sostenendo la transizione da produttore di chip di nicchia a gigante di mercato duraturo.
Il prossimo capitolo di Nvidia riguarda trasformare le GPU da strumento per l'addestramento di modelli a tessuto sottostante dei sistemi intelligenti: AI generativa, macchine autonome e mondi simulati.
L'IA generativa è il focus immediato. Nvidia vuole che ogni grande modello — testo, immagine, video, codice — venga addestrato, messo a punto e servito sulla sua piattaforma. Ciò richiede GPU data center più potenti, networking più veloce e stack software che rendano semplice per le imprese costruire copiloti personalizzati e modelli specifici per dominio.
Oltre il cloud, Nvidia punta sui sistemi autonomi: auto self‑driving, robot per consegne, bracci di fabbrica e droni. L'obiettivo è riutilizzare lo stesso stack CUDA, AI e simulazione across automotive (Drive), robotica (Isaac) e piattaforme embedded (Jetson).
I digital twin uniscono il tutto. Con Omniverse e strumenti correlati, Nvidia scommette che le aziende simuleranno fabbriche, città, reti 5G e persino reti elettriche prima di costruirle o riconfigurarle. Questo crea ricavi software e servizi duraturi oltre l'hardware.
Automotive, automazione industriale e edge computing sono premi enormi. Le auto stanno diventando data center mobili, le fabbriche sistemi guidati dall'IA e ospedali e retail spazi ricchi di sensori. Ognuno richiede inferenza a bassa latenza, software safety‑critical e ecosistemi di sviluppatori robusti — aree in cui Nvidia investe pesantemente.
Ma i rischi sono concreti:
Per founder e ingegneri, la storia di Nvidia mostra il potere di possedere uno stack completo: hardware, software di sistema e strumenti per sviluppatori, puntando sempre al prossimo collo di bottiglia del calcolo prima che sia ovvio.
Per i decisori politici, è un caso di studio su come piattaforme di calcolo critiche diventino infrastruttura strategica. Le scelte su controlli alle esportazioni, politiche di concorrenza e finanziamenti per alternative aperte modelleranno se Nvidia resti la porta dominante all'IA o uno dei principali attori in un ecosistema più diversificato.
Nvidia è stata fondata su un'ipotesi molto specifica: che la grafica 3D sarebbe passata da workstation costose a PC di massa e che questo cambiamento avrebbe richiesto un processore grafico dedicato strettamente integrato con il software.
Invece di puntare a essere un'azienda di semiconduttori generica, Nvidia:
Questo focus stretto ma profondo su un singolo problema—la grafica in tempo reale—ha creato la base tecnica e culturale che poi si è tradotta nel calcolo GPU e nell'accelerazione dell'IA.
CUDA ha trasformato le GPU di Nvidia da hardware grafico a piattaforma di calcolo parallelo generale.
I punti chiave che hanno permesso la sua diffusione nell'IA:
Mellanox ha dato a Nvidia il controllo sul tessuto di rete che collega migliaia di GPU nei supercomputer AI.
Per i modelli di grandi dimensioni, le prestazioni dipendono non solo da chip veloci ma anche da quanto rapidamente possono scambiarsi dati e gradienti. Mellanox ha portato:
Il mix di ricavi di Nvidia si è spostato da prevalenza gaming a predominanza data center.
A grandi linee:
Nvidia affronta pressioni da rivali tradizionali e da acceleratori personalizzati:
Le GPU avanzate sono ora trattate come tecnologie strategiche, soprattutto per l'IA.
Impatto sul business di Nvidia:
Lo stack AI di Nvidia è un insieme stratificato di strumenti che nascondono la complessità GPU alla maggior parte degli sviluppatori:
La guida per auto autonome e la robotica sono estensioni della piattaforma centrale AI e di simulazione di Nvidia nei sistemi fisici.
Dal punto di vista strategico:
La traiettoria di Nvidia offre diverse lezioni pratiche:
Se i futuri carichi di lavoro si allontanano dai pattern favorevoli alle GPU, Nvidia dovrà adattare rapidamente hardware e software.
Possibili evoluzioni:
La risposta probabile di Nvidia includerà:
Quando il deep learning è esploso, gli strumenti, la documentazione e le abitudini legate a CUDA erano già maturi, dando a Nvidia un enorme vantaggio iniziale.
Questo ha permesso a Nvidia di vendere piattaforme integrate (DGX, HGX, progetti di data center completi) dove GPU, rete e software sono co‑ottimizzati, invece di limitarsi a vendere schede acceleratrici standalone.
Le piattaforme AI di fascia alta e il networking hanno prezzi e margini premium, per questo la crescita del data center ha trasformato la redditività complessiva di Nvidia.
Le principali difese di Nvidia sono la leadership nelle prestazioni, il lock‑in software di CUDA e gli ecosistemi integrati. Tuttavia, se le alternative diventano “sufficientemente buone” e più semplici da programmare, la quota e il potere di prezzo di Nvidia potrebbero essere messi sotto pressione.
Perciò, la strategia di Nvidia deve tenere conto non solo di ingegneria e mercati, ma anche di politica, regole commerciali e piani industriali regionali.
La maggior parte dei team chiama queste librerie tramite framework come PyTorch o TensorFlow, quindi raramente scrivono codice GPU a basso livello.
Questi mercati possono essere più piccoli rispetto al cloud AI oggi, ma possono generare ricavi duraturi e margini elevati, oltre ad approfondire l'ecosistema di Nvidia in più settori.
Per i fondatori, il messaggio è di unire approfondimento tecnico con pensiero di ecosistema, non solo prestazioni grezze.
La storia dell'azienda suggerisce che può pivotare, ma tali cambiamenti metterebbero alla prova la sua capacità di adattamento.