12 giu 2025·8 min
Dalle user story allo schema di database: un metodo guidato dall’AI
Impara un metodo pratico per trasformare user story, entità e workflow in uno schema di database chiaro, e come il ragionamento AI può aiutare a trovare gap e regole.
Che cosa stai costruendo: uno schema che rispecchia il lavoro reale
Uno schema di database è il progetto di come la tua app ricorderà le cose. In termini pratici, è:
- Tabelle: i “contenitori” di informazioni (Customers, Orders, Tickets)
- Campi (colonne): i dettagli che salvi su ogni cosa (customer_name, order_date)
- Relazioni: come i contenitori si connettono (un Order appartiene a un Customer; un Customer può avere molti Orders)
Quando lo schema rispecchia il lavoro reale, riflette ciò che le persone fanno davvero—creare, revisionare, approvare, programmare, assegnare, cancellare—invece di quello che sembra ordinato sulla lavagna.
Perché partire dalle user story?
Le user story e i criteri di accettazione descrivono bisogni reali in linguaggio semplice: chi fa cosa e cosa significa “fatto”. Se le usi come fonte, lo schema è meno soggetto a perdere dettagli chiave (tipo “dobbiamo tracciare chi ha approvato il rimborso” o “una prenotazione può essere riprogrammata più volte”).
Partire dalle story ti mantiene onesto sullo scope. Se non è nelle story (o nel workflow), trattalo come opzionale invece di costruire di nascosto un modello complicato “nel caso serva”.
Cosa può e non può fare l’AI
L’AI può aiutarti ad andare più veloce facendo cose come:
- estrarre candidate entità (le cose importanti dalle story)
- suggerire campi impliciti nei criteri di accettazione (timestamp, status, riferimenti)
- individuare probabili relazioni e gap (“si parla di approvazioni ma non salviamo l’approvatore”)
L’AI non può invece affidabilmente:
- conoscere regole aziendali nascoste o casi limite che non hai scritto
- scegliere il livello di dettaglio “giusto” senza bilanciamenti (semplice vs flessibile)
- garantire che lo schema soddisfi reporting, sicurezza o compliance
Considera l’AI un forte assistente, non il decisore finale.
Se vuoi trasformare quell’assistente in momentum, una piattaforma vibe-coding come Koder.ai può aiutarti ad andare dalle decisioni sullo schema a un’app funzionante (React + Go + PostgreSQL) più rapidamente—mentre rimani comunque padrone del modello, dei vincoli e delle migrazioni.
Impostare le aspettative: iterativo, non one-shot
La progettazione dello schema è un loop: bozza → test contro le story → trova i dati mancanti → rifinisci. L’obiettivo non è un output perfetto la prima volta; è un modello che puoi ricondurre a ogni user story e dire con sicurezza: “Sì, possiamo memorizzare tutto ciò che questo workflow richiede—e possiamo spiegare perché ogni tabella esiste.”
Input: user story, criteri di accettazione ed esempi reali
Prima di trasformare i requisiti in tabelle, chiarisci cosa stai modellando. Un buon schema raramente parte da zero—parte da lavori concreti che le persone fanno e dalla prova di cui avrai bisogno dopo (schermate, output e casi limite).
Gli input tipici da avere insieme
Le user story sono il titolo, ma non bastano da sole. Raccogli:
- User story + ruoli (chi fa cosa e perché)
- Acceptance criteria (le regole “deve essere vero”)
- Form/schermate (i campi che gli utenti digitano, scelgono o vedono)
- Report/export (cosa va riepilogato, raggruppato, filtrato)
- Esempi reali (ordini di esempio, fatture, ticket, calendari—qualsiasi cosa rappresentativa)
Se usi l’AI, questi input tengono il modello ancorato. L’AI può proporre entità e campi velocemente, ma ha bisogno di artefatti concreti per evitare di inventare strutture che non corrispondono al prodotto.
I criteri di accettazione: la fonte nascosta dei vincoli
I criteri di accettazione spesso contengono le regole più importanti per il database, anche quando non menzionano i dati esplicitamente. Cerca frasi come:
- “Email must be unique” (unicità)
- “Status can be Draft, Submitted, Approved” (valori ammessi)
- “Only managers can approve” (permessi, possibilmente campi di audit)
- “Can’t delete an invoice with payments” (regole referenziali)
Errori comuni da correggere presto
Story vaghe (“As a user, I can manage projects”) nascondono più entità e workflow. Un altro gap frequente sono i casi limite mancanti come cancellazioni, retry, rimborsi parziali o riassegnazioni.
Checklist rapida per la qualità della story (prima del modeling)
- L’attore/ruolo è esplicito.
- L’oggetto è specifico (non “dati” o “cose”).
- Esiste almeno un esempio reale.
- I criteri di accettazione includono validazioni e limiti.
- I casi di errore e i “what if” sono menzionati (o esplicitamente rimandati).
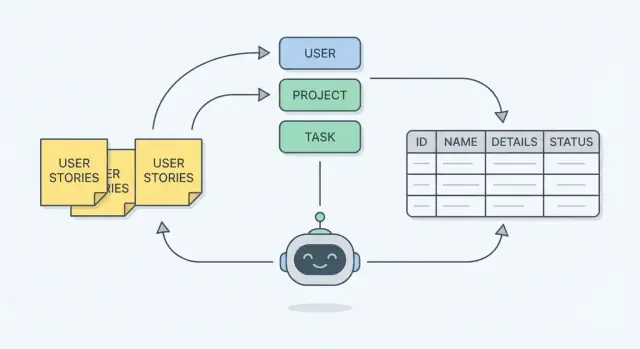
Step 1 — Estrai le entità dalle story (i sostantivi)
Prima di pensare a tabelle o diagrammi, leggi le user story e evidenzia i sostantivi. Nei requisiti, i sostantivi spesso puntano alle “cose” che il sistema deve ricordare—queste diventano spesso entità nello schema.
Un modello mentale rapido: i sostantivi diventano entità, mentre i verbi diventano azioni o workflow. Se una story dice “A manager assigns a technician to a job,” le entità probabili sono manager, technician e job—e “assigns” indica una relazione da modellare dopo.
Come capire se un sostantivo è una vera entità
Non ogni sostantivo merita una tabella. È una buona candidata quando:
- Ha una propria identità: puoi indicare un’istanza specifica (Job #1042, Customer A).
- Cambia nel tempo: ha un ciclo di vita (un job passa da scheduled → completed).
- Viene usato in più punti: più story lo riferiscono, o più workflow lo toccano.
Se un sostantivo compare solo una volta o descrive qualcos’altro (“red button”, “Friday”), potrebbe non essere un’entità.
Attributo vs entità separata (il test “Address” e “Tag”)
Un errore comune è trasformare ogni dettaglio in una tabella. Usa questa regola pratica:
- Se è un solo valore che descrive una cosa, è di solito un attributo (es.: Customer.phone_number).
- Se è ripetibile, condiviso o strutturato, è spesso una entità separata.
Due esempi classici:
- Address: se memorizzi indirizzi di spedizione e fatturazione, tieni cronologia o riusi indirizzi tra clienti/luoghi, Address è probabilmente un’entità. Se serve solo un indirizzo principale e mai riutilizzato, può restare attributo.
- Tag: i tag sono quasi sempre entità indipendenti perché sono ripetibili e molti-a-molti (un Job ha molti Tag; un Tag si applica a molti Job).
Usare l’AI per suggerire entità candidate (con cautela)
L’AI può accelerare la scoperta di entità analizzando le story e restituendo una bozza di sostantivi raggruppati per tema (persone, elementi di lavoro, documenti, luoghi). Un prompt utile è: “Extract nouns that represent data we must store, and group duplicates/synonyms.”
Tratta l’output come un punto di partenza, non come la risposta finale. Fai follow-up come:
- “Quali di questi hanno un lifecycle o bisogno di un ID?”
- “Quali sono stati, categorie o attributi?”
- “Ci sono sinonimi (es.: ‘client’ vs ‘customer’)?”
L’obiettivo dello Step 1 è una lista corta e pulita di entità che puoi difendere puntando alle story reali.
Step 2 — Trasforma i dettagli in campi (i promemoria da salvare)
Una volta nominate le entità (es.: Order, Customer, Ticket), il passo successivo è catturare i dettagli che ti serviranno dopo. In un database, quei dettagli sono i campi (o attributi)—i promemoria che il sistema non può permettersi di dimenticare.
Come scegliere i campi (senza indovinare)
Parti dalla user story, poi leggi i criteri di accettazione come una checklist di cosa deve essere salvato.
Se un requisito dice “Users can filter orders by delivery date”, allora delivery_date non è opzionale—deve esistere come campo (o essere derivabile in modo affidabile da altri dati). Se dice “Show who approved the request and when”, probabilmente ti servono approved_by e approved_at.
Un test pratico: Qualcuno avrà bisogno di questo per mostrare, cercare, ordinare, auditare o calcolare qualcosa? Se sì, probabilmente è un campo.
Regole semplici per campi puliti
- Mantieni i valori atomici: salva “First name” e “Last name” separati se li cercherai o ordinerai. Evita di impacchettare valori multipli in un campo (es.: “red, blue”).
- Usa tipi coerenti: date come date, soldi come decimali, booleani come true/false—non formati misti come “$10”, “10 USD”, “10”.
- Evita testi duplicati: non copiare l’indirizzo del cliente in ogni riga d’ordine. Salvalo in Customers e riferisciti con un id.
Vocabolari controllati: status, tipi e categorie
Molte story usano parole come “status”, “type” o “priority”. Trattale come vocabolari controllati—un insieme limitato di valori ammessi.
Se l’elenco è piccolo e stabile, una semplice enum è sufficiente. Se può crescere, ha etichette o richiede permessi (es.: categorie gestite dagli admin), usa una tabella lookup (es.: status_codes) e memorizza un riferimento.
Così le story si trasformano in campi affidabili—ricercabili, reportabili e difficili da inserire male.
Step 3 — Collega le entità con relazioni
Dopo aver elencato le entità (User, Order, Invoice, Comment, ecc.) e abbozzato i loro campi, il passo successivo è collegarle. Le relazioni sono lo strato “come queste cose interagiscono” implicito nelle story.
Le tre forme di relazione (in parole semplici)
One-to-one (1:1) significa “una cosa ha esattamente un’altra cosa”.
- Frase di story: “Each user has one profile.”
- Idea di modello:
User↔Profile(spesso puoi unirle a meno che non ci sia un motivo per separarle).
One-to-many (1:N) significa “una cosa può averne molte”. È la più comune.
- Frase di story: “A user can have many orders.”
- Idea di modello:
User→Order(mettiuser_idsuOrder).
Many-to-many (M:N) significa “molte cose possono relazionarsi a molte altre”. Serve una tabella in più.
- Frase di story: “An order can include many products, and a product can be in many orders.”
Many-to-many: il trucco della join table
I database non gestiscono bene “una lista di product ID” dentro Order senza creare problemi dopo (ricerche, aggiornamenti, report). Crea invece una join table che rappresenti la relazione stessa.
Esempio:
OrderProductOrderItem(tabella di join)
OrderItem tipicamente include:
order_idproduct_id- dettagli dalla story come
quantity,unit_price,discount
Nota come i dettagli della story (“quantity”) spesso appartengono alla relazione, non a una singola entità.
Richiesto vs opzionale (senza gergo)
Le story dicono anche se una connessione è obbligatoria o talvolta assente.
- “An order must belong to a user” → ogni
Orderha bisogno diuser_id(non permettere vuoti). - “A user may have a phone number” →
phonepuò essere vuoto. - “An order can have a shipping address (if physical goods)” →
shipping_address_idpotrebbe essere vuoto per ordini digitali.
Un controllo rapido: se la story implica che non puoi creare il record senza il collegamento, trattalo come obbligatorio. Se la story dice “can”, “may” o dà eccezioni, trattalo come opzionale.
Trasforma le frasi di story in frasi di relazione
Quando leggi una story, riscrivila come un semplice accoppiamento:
- “A user can leave many comments” →
User1:NComment - “A comment belongs to one user” →
CommentN:1User
Fallo per ogni interazione nelle story. Alla fine avrai un modello connesso che corrisponde a come il lavoro avviene davvero—prima ancora di aprire uno strumento ER.
Step 4 — Usa i workflow per trovare stati, eventi e gap
Share a real preview
Ship a real app with your own custom domain when you are ready to share it.
Le user story dicono cosa vogliono le persone. I workflow mostrano come il lavoro si muove, passo dopo passo. Tradurre un workflow in dati è uno dei modi più rapidi per scoprire problemi del tipo “ci siamo dimenticati di salvare questo”—prima di costruire.
Parti da un workflow semplice
Scrivi il workflow come sequenza di azioni e cambi di stato. Per esempio:
- Create request → Draft
- Submit request → Submitted
- Manager reviews → Approved or Rejected
- If approved, work is scheduled → In progress
- Completed → Done
Quelle parole in grassetto diventano spesso un campo status (o una piccola tabella “state”), con valori ammessi chiari.
I workflow espongono campi mancanti
Camminando ogni passo chiediti: “Di cosa avremmo bisogno per provarlo più tardi?” I workflow rivelano spesso campi come:
- timestamp:
submitted_at,approved_at,completed_at - ownership:
created_by,assigned_to,approved_by - reason/context:
rejection_reason,approval_note - ordering:
sequenceper processi multi-step
Se il processo include attese, escalation o passaggi di mano, di solito ti serve almeno un timestamp e un campo “chi ce l’ha adesso”.
I workflow espongono tabelle mancanti
Alcuni passaggi non sono solo campi—sono strutture di dati separate:
- Audit log / history per “chi ha cambiato cosa quando”
- Approvals per approvazioni multi-approvatore o condizionali
- Attachments quando gli utenti caricano file in un passo
- Comments quando la discussione è parte del processo
Usare l’AI per un controllo gap
Dai all’AI sia: (1) le user story e i criteri, sia (2) i passi del workflow. Chiedile di elencare ogni passo e identificare i dati richiesti per ciascuno (stato, attore, timestamp, output), poi evidenzia qualsiasi requisito che non sia supportato dai campi/tabelle correnti.
In piattaforme come Koder.ai, questo “gap check” è pratico perché puoi iterare velocemente: aggiusti le ipotesi di schema, rigeneri lo scaffolding e continui senza una lunga deviazione manuale.
Chiavi, unicità e vincoli base (senza gergo)
Quando trasformi le story in tabelle, non stai solo elencando campi—decidi anche come i dati restano identificabili e coerenti nel tempo.
Primary key: una “carta d’identità” stabile per ogni riga
Una primary key identifica univocamente una riga—pensa a una carta d’identità permanente della riga.
Perché ogni riga ne ha bisogno: le story implicano aggiornamenti, riferimenti e cronologie. Se una story dice “Support can view an order and issue a refund”, ti serve un modo stabile per puntare all’ordine—anche se il cliente cambia email, l’indirizzo viene modificato o lo status cambia.
In pratica è di solito un id interno (numero o UUID) che non cambia.
Foreign key: puntatori tra tabelle
Una foreign key è come un puntatore sicuro. Se orders.customer_id riferisce customers.id, il database può far rispettare che ogni ordine appartiene a un cliente reale.
Questo corrisponde a story come “As a user, I can see my invoices.” L’invoice non galleggia: è attaccata a un customer (e spesso a un order o subscription).
Regole di unicità: trasformare “deve essere unico” in enforcement
Le user story contengono regole di unicità nascoste:
- “Users sign up with email” → applica unique email (o unico per tenant se supporti account multipli).
- “Finance searches by invoice number” → applica unique invoice_number.
Queste regole prevengono duplicati confusi che emergono mesi dopo come “bug” nei dati.
Indicizzazione (alto livello): rendere veloci le ricerche comuni
Gli indici accelerano ricerche come “trova customer per email” o “lista ordini per customer”. Parti con indici che riflettono le query più comuni e le regole di unicità.
Cosa rimandare: indicizzazione pesante per report rari o filtri speculativi. Registra quei bisogni nelle story, valida lo schema, poi ottimizza basandoti su utilizzo reale e query lente osservate.
Mantenere i dati coerenti: checklist pratica di normalizzazione
Plan the model first
Map entities, workflows, and constraints before you generate any code in Koder.ai.
La normalizzazione ha un obiettivo semplice: prevenire duplicati conflittuali. Se lo stesso fatto può essere salvato in due posti, prima o poi sarà diverso (due ortografie, due prezzi, due indirizzi “correnti”). Uno schema normalizzato memorizza ogni fatto una volta sola e poi lo riferisce.
Checklist rapida su qualsiasi schema di prova
1) Attento ai gruppi ripetuti
Se vedi pattern come “Phone1, Phone2, Phone3” o “ItemA, ItemB, ItemC”, è segnale di una tabella separata (es.: CustomerPhones, OrderItems). I gruppi ripetuti complicano ricerca, validazione e scalabilità.
2) Non copiare lo stesso nome/dettaglio in più tabelle
Se CustomerName appare in Orders, Invoices e Shipments, hai più fonti di verità. Mantieni i dettagli del cliente in Customers e memorizza solo customer_id altrove.
3) Evita più colonne per la stessa cosa
Colonne come billing_address, shipping_address, home_address vanno bene se sono concetti davvero diversi. Ma se stai modellando “molti indirizzi di tipi diversi”, usa una tabella Addresses con un campo type.
4) Separa lookup da testo libero
Se gli utenti scelgono da un insieme noto (status, category, role), modella coerentemente: enum vincolata o tabella lookup. Questo evita “Pending” vs “pending” vs “PENDING”.
5) Verifica che ogni campo non-ID dipenda dalla cosa giusta
Un controllo mentale: in una tabella, se una colonna descrive qualcosa di diverso dall’entità principale, probabilmente appartiene altrove. Esempio: Orders non dovrebbe memorizzare product_price a meno che non significhi “prezzo al momento dell’ordine” (uno snapshot storico).
Quando la denormalizzazione è accettabile (scelta successiva)
A volte duplicare è voluto:
- Reporting/performance: totali pre-aggregati o tabelle di riepilogo.
- Caching: un valore calcolato memorizzato per evitare ricalcoli pesanti.
- Audit/history: copiare “nome al momento dell’acquisto” per preservare la realtà passata.
La chiave è che sia intenzionale: documenta quale campo è la fonte di verità e come le copie si aggiornano.
Dove aiuta l’AI—e dove decide l’umano
L’AI può segnalare duplicazioni sospette (colonne ripetute, nomi simili, campi status incoerenti) e suggerire split in tabelle. Gli umani scelgono il trade-off—semplicità vs flessibilità vs performance—basandosi su come il prodotto sarà usato.
Salvato vs calcolato: cosa mettere nel database
Una regola utile: salva i fatti che non puoi ricreare in modo affidabile dopo; calcola tutto il resto.
Salvato vs calcolato (derivato)
I dati salvati sono la fonte di verità: line item, timestamp, cambi di stato, chi ha fatto cosa. I dati calcolati derivano da quei fatti: totali, contatori, flag come “is overdue” e rollup come “inventory corrente”.
Se due valori possono essere calcolati dagli stessi fatti, preferisci memorizzare i fatti e calcolare il resto per evitare contraddizioni.
Perché i valori derivati causano discrepanze
I valori derivati cambiano quando cambiano gli input. Se salvi sia gli input sia il risultato derivato, devi mantenerli sincronizzati in ogni workflow e caso limite (modifiche, rimborsi, spedizioni parziali, retrodatazioni). Una sincronizzazione mancata fa sì che il database racconti due storie diverse.
Esempio: salvare order_total e contemporaneamente order_items. Se qualcuno modifica una quantità o applica uno sconto e il totale non viene aggiornato perfettamente, la contabilità vede un numero diverso dal carrello.
Usa i workflow per decidere cosa salvare (storia e snapshot)
I workflow mostrano quando serve la verità storica, non solo la verità corrente. Se gli utenti devono sapere quale valore era al momento, salva uno snapshot.
Per un ordine potresti salvare:
- line item e prezzi (fatti)
- un
order_totalcatturato al checkout (snapshot), perché tasse, sconti e regole di prezzo possono cambiare dopo
Per l’inventario, il “livello inventario” si calcola spesso dai movimenti (ricevute, vendite, aggiustamenti). Ma se ti serve audit, salva i movimenti e opzionalmente snapshot periodici per velocizzare i report.
Per il tracciamento login, salva last_login_at come fatto (timestamp di evento). “È attivo negli ultimi 30 giorni?” resta un calcolo.
Esempio pratico: da 5 user story a un modello ER
Usiamo una nota app di support ticket. Passeremo da cinque user story a un ER semplice (entità + campi + relazioni), poi lo confronteremo con un workflow.
5 user story → sostantivi → entità
- As a customer, I can create a support ticket with a subject, description, and category.
- As an agent, I can assign a ticket to myself or another agent.
- As an agent, I can add internal notes and public replies to a ticket.
- As a customer, I can see when my ticket is updated and when it’s closed.
- As a manager, I can track how long tickets stay open and who closed them.
Dai sostantivi otteniamo entità principali:
- User (customers, agents, managers)
- Ticket
- Message (public replies + internal notes)
- Category
- TicketEvent (audit/history)
Campi e relazioni (modello ER compatto)
- User: id, name, email, role
- Category: id, name
- Ticket: id, subject, description, status, created_at, updated_at, closed_at
- relazioni: Ticket.category_id → Category.id
- relazioni: Ticket.requester_id → User.id (customer)
- relazioni: Ticket.assignee_id → User.id (agent, nullable)
- Message: id, ticket_id, author_id, body, is_internal, created_at
- relazioni: Message.ticket_id → Ticket.id
- relazioni: Message.author_id → User.id
- TicketEvent: id, ticket_id, actor_id, type, from_status, to_status, created_at
Mappatura workflow: create → update → close
- Create: insert Ticket (status = “open”, created_at), insert TicketEvent(type = “created”).
- Update (assign, reply): insert Message o aggiornare Ticket.assignee_id, e inserire TicketEvent(type = “assigned”/“replied”, updated_at).
- Close: update Ticket.status = “closed”, impostare closed_at, inserire TicketEvent(type = “closed”, actor_id = closer).
“Prima e dopo”: l’AI individua un vincolo mancante
Prima (errore comune): Ticket ha assignee_id, ma non abbiamo garantito che solo gli agent possano essere assegnati.
Dopo: l’AI lo segnala e aggiungi una regola pratica: assignee must be a User with role = “agent” (implementabile via validazione applicativa o constraint/policy DB, a seconda dello stack). Questo evita dati “assigned to customer” che rompono i report più avanti.
Validare lo schema: ricondurre ogni story
Get a schema draft fast
Draft tables, fields, and relationships from your acceptance criteria, then refine them fast.
Uno schema è “finito” solo quando ogni user story può essere soddisfatta con dati che puoi memorizzare e interrogare in modo affidabile. Il passo di validazione più semplice è prendere ogni story e chiedersi: “Possiamo rispondere a questa domanda dal database, per ogni caso?” Se la risposta è “forse”, il modello ha un gap.
Trasforma ogni story in una domanda database
Riscrivi ogni user story come una o più domande di test—quelle che ti aspetteresti da un report, una schermata o un’API. Esempi:
- Report: “Mostra tutti gli ordini aperti per cliente, con i totali degli ultimi 30 giorni.”
- Permessi: “Quali utenti possono approvare rimborsi per questo store?”
- Casi limite: “Un ordine può esistere senza indirizzo di spedizione? E per articoli digitali?”
- Cancellazioni: “Se cancelliamo un customer, cosa succede a ordini, fatture e note?”
Se non riesci a trasformare una story in una domanda chiara, la story è poco chiara. Se puoi, ma non puoi rispondere con lo schema, manca un campo, una relazione, uno status/evento o un vincolo.
Usa dati di esempio per un controllo rapido
Crea un piccolo dataset (5–20 righe per tabella chiave) che includa casi normali e quelli più scomodi (duplicati, valori mancanti, cancellazioni). Poi “recita” le story con quei dati. Vedrai in fretta problemi tipo “non possiamo sapere quale indirizzo è stato usato al momento dell’acquisto” o “non abbiamo dove salvare chi ha approvato la modifica”.
Lascia che l’AI trovi i casi non gestiti
Chiedi all’AI di generare domande di validazione per ogni story (inclusi edge case e scenari di cancellazione) e di elencare i dati necessari per rispondervi. Confronta quella lista con lo schema: ogni mismatch è un’azione concreta, non una sensazione vaga che “qualcosa non va”.
Usare l’AI in sicurezza e mantenere lo schema manutenibile
L’AI può velocizzare la modellazione dati, ma aumenta anche il rischio di esporre informazioni sensibili o di fissare assunzioni sbagliate. Usala come assistente molto veloce: utile, ma con regole.
Cosa condividere con l’AI (e cosa evitare)
Condividi input realistici ma sanitizzati:
- User story sanitizzate (rinomina clienti, prodotti, luoghi)
- Acceptance criteria e edge case (“refund within 14 days”, “one active subscription per account”)
- Campi di esempio con dati finti (es.:
invoice_total: 129.50,status: "paid") - Header CSV o tabelle esistenti (la struttura è solitamente sicura; il contenuto spesso no)
Evita qualsiasi cosa che identifichi persone o riveli operazioni confidenziali:
- Nomi reali, email, telefoni, indirizzi
- Storie ordini reali, ticket di supporto, note interne
- API key, credenziali DB, screenshot con dati privati
Se ti serve realismo, genera campioni sintetici che rispettino formati e range—mai copiare righe di produzione.
Metti le assunzioni accanto allo schema
Gli schemi falliscono quando “tutti hanno dato per scontato” qualcosa di diverso. Accanto al modello ER (o nel repo), tieni un breve registro decisionale:
- Definizioni (“Cosa conta come account ‘attivo’?”)
- Vincoli (“Un utente può appartenere a più organizzazioni”)
- Compromessi (“Salviamo currency code su ogni fattura per audit”)
Questo trasforma l’output dell’AI in conoscenza di team invece che in un artefatto isolato.
Pianifica il cambiamento: versioning e migrazioni
Lo schema evolverà con nuove story. Proteggilo con:
- Versioning delle modifiche (file di migrazione in Git)
- Migrazioni reversibili quando possibile
- Aggiornamento di seed ed esempi così i cambi sono testabili
- Revisione delle migrazioni generate dall’AI come qualsiasi altro codice
Se usi una piattaforma come Koder.ai, sfrutta guardrail come snapshot e rollback quando iteri gli schemi, ed esporta il codice sorgente quando ti serve una revisione tradizionale.
Un workflow semplice e ripetibile
- Sanitize stories + crea 5–10 esempi sintetici.
- Chiedi all’AI di proporre entità, campi, relazioni e vincoli.
- Revisiona con il team; registra le assunzioni.
- Implementa migrazioni; esegui un piccolo “story trace” test (ogni story è soddisfatta dal modello).
- Ripeti quando le story cambiano; mantieni schema e note sincronizzati.
Domande frequenti
How do I extract database entities from user stories?
Inizia dalle user story e sottolinea i sostantivi che rappresentano cose che il sistema deve ricordare (es.: Ticket, User, Category).
Promuovi un sostantivo a entità quando:
- ha bisogno del proprio ID
- cambia nel tempo (ha un lifecycle / uno status)
- compare in più user story
Mantieni una lista breve che tu possa giustificare indicando frasi specifiche delle story.
When should something be a field vs. its own table?
Usa un test “attributo vs entità":
- Fallo diventare un campo se è un singolo valore che descrive una singola riga (es.:
customer.phone_number). - Fallo diventare una tabella separata se è ripetibile, condiviso, strutturato o richiede storia (es.: più indirizzi, tag, allegati).
Un indizio rapido: se ti serve “molti di questi”, probabilmente serve un’altra tabella.
How do acceptance criteria translate into fields and constraints?
Tratta i criteri di accettazione come una checklist di cosa conservare. Se un requisito dice che devi filtrare/ordinare/mostrare/registrare qualcosa, devi memorizzarla (o poterla ricavare in modo affidabile).
Esempi:
- “Show who approved and when” →
approved_by,approved_at - “Filter by delivery date” →
delivery_date
How do I turn story text into table relationships (1:1, 1:N, M:N)?
Riscrivi le frasi delle story in frasi di relazione:
- “A customer can have many orders” → 1:N (metti
customer_idsuorders) - “An order includes many products” → M:N (aggiungi una tabella di join come
order_items)
Se la relazione stessa ha dati (quantità, prezzo, ruolo), quei dati vanno sulla tabella di join.
What’s the right way to model many-to-many relationships?
Modella M:N con una tabella di join che contiene entrambe le chiavi esterne più i campi specifici della relazione.
Schema tipico:
ordersproducts
How do workflows help me find missing tables or fields?
Segui il workflow passo dopo passo e chiediti: “Cosa dovremo dimostrare in seguito?”
Aggiunte comuni:
- timestamp:
submitted_at,closed_at - attori: , ,
Which constraints should I add first (keys, uniqueness, indexes)?
Inizia con:
- una primary key stabile per ogni tabella (
id) - foreign key per le relazioni (
orders.customer_id → customers.id) - regole di unicità tratte dai requisiti (email, numero fattura)
Poi aggiungi indici per le ricerche più comuni (es.: , , ). Rimanda ottimizzazioni speculative fino a quando non vedi pattern reali di query lente.
How do I know if my schema is normalized enough without overdoing it?
Esegui un controllo rapido di consistenza:
- Se vedi gruppi ripetuti come
Phone1/Phone2, sposta in una tabella figlia. - Se lo stesso fatto appare in più tabelle, scegli una fonte di verità e riferisciti a quella.
- Se una colonna descrive qualcosa di diverso dall'entità principale della tabella, spostala.
Denormalizza dopo solo con una ragione chiara (performance, report, snapshot di audit) e documenta cosa è autorevole.
What should be stored vs. calculated in the database?
Conserva i fatti che non puoi ricreare in modo affidabile; calcola tutto il resto.
Buono da conservare:
- eventi e timestamp
- line item e prezzi storici
- “chi ha fatto cosa” per auditing
Buono da calcolare:
- totali (da line item)
- flag come “is overdue” (da date)
Se conservi valori derivati (es.: ), definisci chiaramente come mantenere la sincronizzazione e testa i casi limite (rimborsi, modifiche, spedizioni parziali).
How can I use AI safely to speed up schema design without making bad assumptions?
Usa l’AI per bozze, poi verifica contro i tuoi artefatti.
Prompt pratici:
- “Extract candidate entities and synonyms from these stories.”
- “List fields implied by acceptance criteria (timestamps, actors, statuses).”
- “Given this workflow, what data is required at each step?”
Linee guida: