07 ago 2025·8 min
Database distribuiti: scambiare coerenza per disponibilità
Scopri perché i database distribuiti spesso rilassano la coerenza per restare disponibili durante i guasti, come funzionano CAP e i quorum, e quando scegliere ogni approccio.
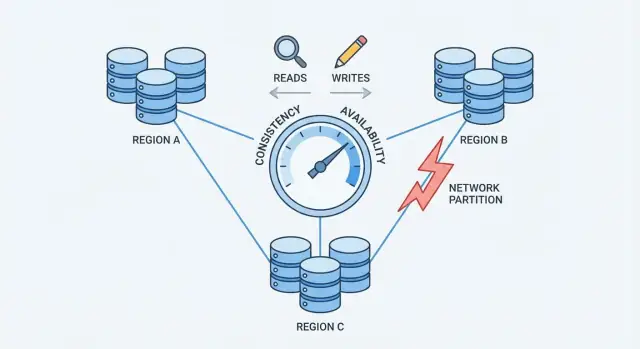
Cosa significano coerenza e disponibilità nella pratica
Quando un database è diviso su più macchine (repliche), ottieni velocità e resilienza—ma introduci anche periodi in cui quelle macchine non sono perfettamente d'accordo o non riescono a comunicare in modo affidabile.
Coerenza (significato semplice)
Coerenza significa: dopo una scrittura avvenuta con successo, tutti leggono lo stesso valore. Se aggiorni l'email del profilo, la lettura successiva—indipendentemente dalla replica che risponde—restituisce la nuova email.
Nella pratica, i sistemi che danno priorità alla coerenza possono ritardare o rifiutare alcune richieste durante i guasti per evitare risposte conflittuali.
Disponibilità (significato semplice)
Disponibilità significa: il sistema risponde a ogni richiesta, anche se alcuni server sono giù o scollegati. Potresti non ottenere i dati più aggiornati, ma ottieni una risposta.
Nella pratica, i sistemi che prediligono la disponibilità possono accettare scritture e servire letture anche mentre le repliche sono in disaccordo, e poi riconciliare le differenze più tardi.
Cosa implica il compromesso per le applicazioni reali
Un compromesso significa che non puoi massimizzare entrambi gli obiettivi nello stesso momento in ogni scenario di guasto. Se le repliche non possono coordinarsi, il database deve o:
- Aspettare/rigettare alcune richieste per proteggere una verità unica (favorire la coerenza), oppure
- Continuare a rispondere agli utenti anche se questo rischia dati obsoleti o conflitti (favorire la disponibilità)
Un esempio semplice: carrello vs bonifico bancario
- Carrello della spesa: se il conteggio del carrello è per qualche istante sbagliato su un altro dispositivo, è fastidioso ma normalmente accettabile. Molti team preferiscono alta disponibilità e riconciliano dopo.
- Bonifico bancario: se trasferisci 500$ e il saldo mostra temporaneamente due risposte diverse, è un problema serio. Qui, una coerenza più forte vale occasionali messaggi di “riprovare”.
Nessuna scelta “migliore” in assoluto
Il giusto equilibrio dipende dagli errori che puoi tollerare: un breve outage o un breve periodo di dati sbagliati/obsoleti. La maggior parte dei sistemi reali sceglie un punto intermedio—e rende esplicito il compromesso.
Perché la distribuzione cambia le regole
Un database è “distribuito” quando archivia e serve dati da più macchine (nodi) che si coordinano su una rete. All'applicazione può sembrare ancora un database unico—ma sotto il cofano le richieste possono essere gestite da nodi diversi in posti diversi.
Replicazione: perché i team aggiungono nodi
La maggior parte dei database distribuiti replica i dati: lo stesso record è memorizzato su più nodi. I team fanno questo per:
- mantenere il servizio in funzione se una macchina muore
- ridurre la latenza servendo gli utenti da un nodo vicino
- scalare le letture (e a volte le scritture) su più hardware
La replicazione è potente, ma subito pone una domanda: se due nodi hanno entrambe una copia dello stesso dato, come garantisci che siano sempre d'accordo?
Il guasto parziale è normale, non eccezionale
Su un singolo server, “giù” di solito è ovvio: la macchina è su o non lo è. In un sistema distribuito, il guasto è spesso parziale. Un nodo può essere vivo ma lento. Un link di rete può perdere pacchetti. Un intero rack può perdere connettività mentre il resto del cluster continua a funzionare.
Questo conta perché i nodi non possono sapere istantaneamente se un altro nodo è davvero giù, temporaneamente irraggiungibile o solo rallentato. Mentre aspettano di scoprirlo, devono comunque decidere cosa fare con le letture e le scritture in arrivo.
Le garanzie cambiano quando la comunicazione non è garantita
Con un server solo, c'è una sola fonte di verità: ogni lettura vede l'ultima scrittura riuscita.
Con più nodi, “l'ultimo” dipende dalla coordinazione. Se una scrittura ha successo sul nodo A ma il nodo B non è raggiungibile, il database dovrebbe:
- bloccare la scrittura finché B non la conferma (proteggendo la coerenza), o
- accettare comunque la scrittura (proteggendo la disponibilità)?
Quella tensione—resa reale dalle reti imperfette—è il motivo per cui la distribuzione cambia le regole.
Partizioni di rete: il problema centrale
Una partizione di rete è una rottura nella comunicazione tra nodi che dovrebbero funzionare come un database unico. I nodi possono essere ancora attivi e sani, ma non possono scambiarsi messaggi in modo affidabile—a causa di uno switch guasto, un collegamento sovraccarico, un cambiamento di routing, regole firewall errate o anche un “noisy neighbor” in cloud.
Perché le partizioni sono inevitabili su larga scala
Una volta che un sistema è distribuito su più macchine (spesso su rack, zone o regioni), non controlli più ogni salto tra loro. Le reti perdono pacchetti, introducono ritardi e a volte si spezzano in “isole”. A piccola scala questi eventi sono rari; a grande scala sono routine. Anche una breve interruzione è sufficiente a importare, perché i database hanno bisogno di coordinazione continua per concordare cosa è successo.
Come le partizioni creano “ultimi” dati conflittuali
Durante una partizione, entrambi i lati continuano a ricevere richieste. Se gli utenti possono scrivere su entrambi i lati, ogni lato può accettare aggiornamenti che l'altro lato non vede.
Esempio: il Nodo A aggiorna l'indirizzo di un utente a “Via Nuova”. Allo stesso tempo, il Nodo B lo aggiorna a “Via Vecchia, Int. 2”. Ciascun lato crede che la propria scrittura sia la più recente—perché non ha modo di confrontare i dati in tempo reale.
Sintomi visibili all'utente
Le partizioni non si manifestano con messaggi di errore ordinati; appaiono come comportamenti confusi:
- Timeout: il database attende la conferma di scrittura o lettura da un altro nodo.
- Letture stale: aggiorni e vedi ancora dati vecchi perché hai colpito una replica che ha perso aggiornamenti.
- Comportamento split-brain: utenti diversi vedono “verità” differenti a seconda del lato a cui arrivano.
Questo è il punto di pressione che forza una scelta: quando la rete non garantisce comunicazione, un database distribuito deve decidere se dare priorità alla coerenza o alla disponibilità.
CAP senza il gergo
CAP è un modo compatto per descrivere cosa succede quando un database è distribuito su più macchine.
I tre termini (in parole semplici)
- Coerenza (C): dopo che scrivi un valore, qualsiasi lettura successiva restituisce quel valore.
- Disponibilità (A): ogni richiesta riceve una risposta non di errore, anche se alcuni server hanno problemi.
- Tolleranza alle partizioni (P): il sistema continua a funzionare anche se la rete si divide e i server non possono parlare affidabilmente.
Il punto chiave
Quando non c'è partizione, molti sistemi possono apparire sia coerenti sia disponibili.
Quando c'è una partizione, devi scegliere cosa prioritizzare:
- Scegli la coerenza: rifiuta o ritarda alcune richieste finché i server non possono concordare.
- Scegli la disponibilità: accetta le richieste su ogni lato dello split, anche se le risposte possono temporaneamente divergere.
Una semplice linea temporale che puoi immaginare
- 10:00 Il client scrive
balance = 100sul Server A. - 10:01 Partizione di rete: Server A non riesce a raggiungere Server B.
- 10:02 Il client legge dal Server B.
- Se dai priorità alla coerenza, Server B deve rifiutare o attendere.
- Se dai priorità alla disponibilità, Server B risponde, ma potrebbe ancora dire
balance = 80.
Fraintendimento comune
CAP non significa “scegli permanentemente solo due”. Significa durante una partizione non puoi garantire sia la Coerenza sia la Disponibilità contemporaneamente. Fuori dalle partizioni, puoi spesso avvicinarti molto ad entrambe—fino a quando la rete si comporta male.
Scegliere la coerenza: cosa si guadagna e cosa si perde
Scegliere la coerenza significa che il database dà priorità al “tutti vedono la stessa verità” rispetto al “rispondere sempre”. Nella pratica, questo tende verso la coerenza forte, spesso descritta come comportamento linearizzabile: una volta che una scrittura è riconosciuta, qualsiasi lettura successiva (da qualsiasi parte) restituisce quel valore, come se ci fosse una singola copia aggiornata.
Cosa succede durante una partizione
Quando la rete si divide e le repliche non possono coordinarsi, un sistema a coerenza forte non può accettare aggiornamenti indipendenti su entrambi i lati in sicurezza. Per proteggere la correttezza, tipicamente:
- Blocca le richieste in attesa di coordinazione, oppure
- Rifiuta le richieste (restituendo errori/timeout) se non riesce a raggiungere le repliche/leader necessari.
Dal punto di vista dell'utente, questo può assomigliare a un outage anche se alcune macchine stanno ancora girando.
Cosa si guadagna
Il vantaggio principale è un ragionamento più semplice. Il codice applicativo può comportarsi come se stesse parlando con un unico database, non con più repliche che potrebbero divergere. Questo riduce momenti “strani” come:
- Leggere dati vecchi subito dopo un aggiornamento riuscito
- Vedere due valori diversi per lo stesso record a seconda della replica
- Perdere invarianti (es. overselling dell'inventario) a causa di scritture concorrenti e conflittuali
Ottieni anche modelli mentali più puliti per auditing, fatturazione e qualsiasi cosa debba essere corretta la prima volta.
Cosa si perde
La coerenza ha costi reali:
- Maggiore latenza: molte operazioni devono attendere la coordinazione (spesso tra macchine o regioni).
- Più errori durante i guasti: partizioni, repliche lente o problemi del leader possono tradursi in timeout o “riprovare più tardi”.
Se il tuo prodotto non può tollerare richieste fallite durante outage parziali, la coerenza forte può risultare costosa—anche quando è la scelta giusta per la correttezza.
Scegliere la disponibilità: cosa si guadagna e cosa si perde
Testa modalità di lettura e scrittura
Avvia una app React e un'API in Go per testare scritture rigorose e letture rilassate.
Scegliere la disponibilità significa ottimizzare per una promessa semplice: il sistema risponde, anche quando parti dell'infrastruttura sono malate. Nella pratica, “alta disponibilità” non vuol dire “mai errori”—vuol dire che la maggior parte delle richieste riceve comunque una risposta durante guasti di nodi, repliche sovraccariche o link di rete interrotti.
Cosa succede durante una partizione di rete
Quando la rete si divide, le repliche non possono comunicare in modo affidabile. Un database orientato alla disponibilità tipicamente continua a servire traffico dal lato raggiungibile:
- Letture sono risposte localmente con i dati che la replica ha attualmente.
- Scritture sono accettate localmente e messe in coda/replicate più tardi quando la connettività ritorna.
Questo mantiene le applicazioni attive, ma significa anche che repliche diverse possono temporaneamente accettare verità differenti.
Cosa si guadagna
Ottieni migliore uptime: gli utenti possono continuare a navigare, mettere articoli nel carrello, postare commenti o registrare eventi anche se una regione è isolata.
Hai anche un'esperienza utente più fluida sotto stress. Invece di timeout, la tua app può continuare con comportamenti ragionevoli (“il tuo aggiornamento è salvato”) e sincronizzare dopo. Per molti carichi consumer e di analytics, questo compromesso vale la pena.
Cosa si perde
Il prezzo è che il database può restituire letture stale. Un utente può aggiornare un profilo su una replica e poi leggere immediatamente da un'altra replica e vedere il valore precedente.
Si rischiano anche conflitti di scrittura. Due utenti (o lo stesso utente in due posizioni) possono aggiornare lo stesso record su lati diversi di una partizione. Quando la partizione si risana, il sistema deve riconciliare storie divergenti. A seconda delle regole, una scrittura può “vincere”, i campi possono essere fusi o il conflitto può richiedere logica applicativa.
Il design orientato alla disponibilità accetta il disaccordo temporaneo per mantenere il prodotto reattivo—poi investe nel come rilevare e riparare il disaccordo più tardi.
Quorum e votazioni: un punto intermedio
I quorum sono una tecnica pratica di “voto” che molti database replicati usano per bilanciare coerenza e disponibilità. Invece di fidarsi di una singola replica, il sistema chiede a sufficienti repliche di essere d'accordo.
L'idea (N, R, W)
Spesso i quorum sono descritti con tre numeri:
- N: quante repliche esistono per un dato pezzo di dati
- W: quante repliche devono confermare una scrittura prima che sia considerata riuscita
- R: quante repliche sono consultate per una lettura
Una regola pratica è: se R + W > N, allora ogni lettura si sovrappone con l'ultima scrittura riuscita su almeno una replica, il che riduce la probabilità di leggere dati obsoleti.
Esempi intuitivi
Se hai N=3 repliche:
- Approccio a replica singola (R=1, W=1): Veloce e molto disponibile, ma è facile leggere una replica obsoleta.
- Voting di maggioranza (R=2, W=2): Una scrittura deve raggiungere 2 repliche e una lettura consulta 2 repliche. Questo aumenta le probabilità di vedere il valore più recente perché gli insiemi di lettura e scrittura si sovrappongono.
Alcuni sistemi usano W=3 (tutte le repliche) per maggiore coerenza, ma questo può causare più fallimenti di scrittura quando una replica è lenta o giù.
Cosa fanno i quorum durante le partizioni
I quorum non eliminano i problemi di partizione—definiscono chi è autorizzato a progredire. Se la rete si divide 2–1, il lato con 2 repliche può ancora soddisfare R=2 e W=2, mentre la singola replica isolata no. Questo riduce gli aggiornamenti conflittuali, ma significa che alcuni client vedranno errori o timeout.
I compromessi
I quorum di solito implicano maggiore latenza (più nodi da contattare), costi più alti (più traffico cross-node) e comportamenti di failure più sfumati (i timeout possono sembrare indisponibilità). Il beneficio è un punto intermedio regolabile: puoi impostare R e W verso letture più fresche o maggiore successo delle scritture a seconda di cosa conta di più.
Consistenza eventuale e anomalie comuni
La consistenza eventuale significa che le repliche possono essere temporaneamente non sincronizzate, purché convergano allo stesso valore dopo un po'.
Un'analogia concreta
Pensa a una catena di caffetterie che aggiorna un cartello condiviso “sold out” per una pasticceria. Un negozio lo segna come esaurito, ma l'aggiornamento raggiunge gli altri negozi qualche minuto dopo. Durante quella finestra, un altro negozio potrebbe ancora mostrare “disponibile” e vendere l'ultimo pezzo. Il sistema non è “rotto”—gli aggiornamenti stanno solo recuperando il ritardo.
Anomalie comuni che noterai
Quando i dati si stanno ancora propagando, i client possono osservare comportamenti che sembrano sorprendenti:
- Letture stale: leggi dati vecchi da una replica che non ha ricevuto l'ultima scrittura.
- Gap read-your-writes: scrivi un aggiornamento e poi leggi subito da un'altra replica (o dopo un failover) e non vedi il tuo cambiamento.
- Aggiornamenti fuori ordine: due aggiornamenti arrivano in sequenze diverse su repliche diverse, producendo brevi viste incoerenti.
Tecniche che aiutano le repliche a convergere
I sistemi eventual-consistent spesso aggiungono meccanismi in background per ridurre le finestre di incoerenza:
- Read repair: se una lettura rileva repliche discordanti, il sistema aggiorna le repliche stale in background.
- Hinted handoff: se una replica è giù, un altro nodo conserva temporaneamente “hint” di scritture da inoltrare al ritorno.
- Anti-entropy (sync): riconciliazioni periodiche (spesso via merkle tree o checksum) per trovare e correggere la deriva.
Quando la consistenza eventuale è adatta
È adatta quando la disponibilità è più importante dell'essere perfettamente aggiornati: feed di attività, contatori di visualizzazioni, raccomandazioni, profili in cache, log/telemetria e altri dati non critici dove “corretto tra un momento” è accettabile.
Risoluzione dei conflitti: come si riconciliano scritture divergenti
Pianifica la tua architettura in chat
Mappa il tuo modello di dati, gli endpoint e le regole di coerenza prima di scrivere i dettagli di implementazione.
Quando un database accetta scritture su più repliche, può trovarsi con conflitti: due (o più) aggiornamenti allo stesso oggetto accaduti indipendentemente su repliche diverse prima che queste potessero sincronizzarsi.
Un esempio classico è un utente che aggiorna l'indirizzo di spedizione su un dispositivo mentre cambia il numero di telefono su un altro. Se ogni aggiornamento arriva su una replica diversa durante una disconnessione temporanea, il sistema deve decidere quale sia il record “vero” quando le repliche si scambiano i dati.
Last-write-wins (LWW): semplice ma rischioso
Molti sistemi partono con last-write-wins: l'aggiornamento con timestamp più recente sovrascrive gli altri.
È attraente perché è facile da implementare e veloce da calcolare. Il rovescio della medaglia è che può perdere dati silenziosamente. Se “il più recente” vince, allora un cambiamento più vecchio ma importante viene scartato—even se i due aggiornamenti riguardavano campi diversi.
Assume anche che gli orologi siano affidabili. Lo skew degli orologi tra macchine (o client) può far vincere l'aggiornamento sbagliato.
Conservare la storia: vettori di versione e idee correlate
La gestione dei conflitti più sicura di solito richiede di tracciare la storia causale.
A livello concettuale, vettori di versione (e varianti più semplici) allegano un piccolo metadata a ogni record che riassume “quale replica ha visto quali aggiornamenti”. Quando le repliche si scambiano versioni, il database può rilevare se una versione include un'altra (nessun conflitto) o se sono divergenti (conflitto che richiede risoluzione).
Alcuni sistemi usano timestamp logici (es. Lamport clock) o hybrid logical clocks per ridurre la dipendenza dall'orologio di sistema pur fornendo un suggerimento d'ordine.
Fondere invece di sovrascrivere
Una volta rilevato un conflitto, hai delle scelte:
- Merge a livello di applicazione: l'app decide come combinare i campi, chiedere all'utente o conservare entrambe le versioni per revisione.
- CRDT (Conflict-Free Replicated Data Types): strutture dati progettate per fondersi automaticamente e in modo deterministico (utili per contatori, set, testo collaborativo, ecc.). Evitano spesso il comportamento “vincitore-prende-tutto” mantenendo alta disponibilità.
La soluzione migliore dipende da cosa significa “corretto” per i tuoi dati—a volte perdere una scrittura è accettabile, altre volte è un bug critico di business.
Come scegliere per il tuo caso d'uso
Scegliere una postura su coerenza/disponibilità non è un dibattito filosofico—è una decisione di prodotto. Inizia chiedendo: qual è il costo di essere sbagliati per un momento, e qual è il costo di dire “riprovare più tardi”?
Mappa il rischio di business ai bisogni di coerenza
Alcuni domini richiedono una risposta autorevole al momento della scrittura perché “quasi corretto” è comunque sbagliato:
- Denaro e fatturazione: doppie addebiti, scoperti e rimborsi richiedono spesso coerenza forte.
- Identità e permessi: login, reset password, controllo accessi e cambi di ruolo dovrebbero evitare comportamenti split-brain.
- Inventario e capacità: se l'overselling è inaccettabile (biglietti, stock limitato), preferisci coerenza o progetta prenotazioni esplicite.
Se l'impatto di una discrepanza temporanea è basso o reversibile, puoi solitamente inclinare verso maggiore disponibilità.
Decidi quanto dato obsoleto puoi tolerare
Molte esperienze utente funzionano bene con letture leggermente vecchie:
- Feed e timeline: che un post appaia con qualche secondo di ritardo è spesso accettabile.
- Analytics e dashboard: numeri batch o ritardati sono comuni e attesi.
- Cache e indici di ricerca: gli utenti accettano “non ancora aggiornato” se è veloce e stabile.
Sii esplicito su quanto obsoleto va bene: secondi, minuti o ore. Quel budget di tempo guida le tue scelte di replicazione e quorum.
Scegli la modalità di guasto che gli utenti odieranno di meno
Quando le repliche non riescono a mettersi d'accordo, di solito avrai una di tre uscite UX:
- Spinner / attesa (priorizza correttezza, può sembrare lento)
- Errore / retry (onesto, ma dirompente)
- Risultato stale (fluido, ma occasionalmente sorprendente)
Scegli l'opzione meno dannosa per ciascuna feature, non globalmente.
Checklist rapida
Inclina su C (coerenza) se: risultati sbagliati creano rischi finanziari/legali, problemi di sicurezza o azioni irreversibili.
Inclina su A (disponibilità) se: gli utenti valorizzano la reattività, i dati stale sono tollerabili e i conflitti possono essere risolti in sicurezza dopo.
In caso di dubbi, separa il sistema: tieni record critici con coerenza forte e lascia viste derivate (feed, cache, analytics) ottimizzare per disponibilità.
Pattern di design per ridurre il dolore del compromesso
Costruisci e condividi per crediti
Condividi ciò che costruisci con Koder.ai e guadagna crediti mentre insegni agli altri.
Raramente devi scegliere un'unica “impostazione di coerenza” per tutto il sistema. Molti database distribuiti moderni ti permettono di scegliere la coerenza per operazione—e le applicazioni intelligenti sfruttano questo per mantenere l'esperienza utente fluida senza ignorare il compromesso.
Usa livelli di coerenza per operazione
Tratta la coerenza come una manopola da ruotare in base all'azione dell'utente:
- Aggiornamenti critici (pagamenti, decrementi di inventario, cambi password): usa coerenza più forte (es., scritture quorum/linearizzabili).
- Letture non critiche (feed, dashboard, “ultimo accesso”): consenti letture più deboli (locale/una replica/eventuale) per velocità e resilienza.
Questo evita di pagare il costo della coerenza più forte per tutto, proteggendo comunque le operazioni che ne hanno veramente bisogno.
Mischiare forte e debole in un unico flusso
Un pattern comune è forte per le scritture, più debole per le letture:
- Scrivi con un livello rigido così il sistema ha un record autorevole.
- Leggi con un livello più flessibile e, se rilevi qualcosa di “strano” (elemento mancante, contatore stale), aggiorna con una lettura più forte o mostra un messaggio “in aggiornamento”.
In alcuni casi funziona il contrario: scritture veloci (in coda/eventuali) più letture forti quando confermi un risultato (“Il mio ordine è stato inviato?”).
Progetta per i retry: idempotenza
Quando le reti oscillano, i client ritentano. Rendi i retry sicuri con idempotency key così “invia ordine” eseguito due volte non crea due ordini. Memorizza e riusa il primo risultato quando vedi la stessa key.
Workflow lunghi: saghe e compensazioni
Per azioni multi-step tra servizi, usa una saga: ogni passo ha un'azione compensativa corrispondente (rimborso, rilascio prenotazione, annulla spedizione). Questo mantiene il sistema recuperabile anche quando parti temporaneamente non sono d'accordo o falliscono.
Testing e osservabilità per coerenza vs disponibilità
Non puoi gestire il compromesso se non lo vedi. I problemi in produzione spesso sembrano “guasti casuali” finché non aggiungi le misure e i test giusti.
Cosa misurare (e perché)
Inizia con un piccolo set di metriche che mappano direttamente all'impatto utente:
- Latenza (p50/p95/p99): osserva i picchi durante failover, cambi leader o retry di quorum.
- Tasso di errore: separa errori “hard” (timeout, 5xx) da errori “soft” (servito da fallback, risultati parziali).
- Tasso di letture stale: percentuale di letture che restituiscono dati più vecchi del tuo target (es., più vecchie di 2 secondi).
- Tasso di conflitti: quanto spesso scritture concorrenti richiedono riconciliazione (inclusi sovrascritti LWW).
Se puoi, tagga le metriche per modalità di coerenza (quorum vs locale) e regione/zone per individuare dove il comportamento diverge.
Testa le partizioni intenzionalmente
Non aspettare il guasto reale. In staging, esegui esperimenti di chaos che simulano:
- pacchetti persi e alta latenza tra repliche
- una regione diventata irraggiungibile
- partizioni parziali dove solo alcuni nodi possono parlare
Verifica non solo che “il sistema resta su”, ma quali garanzie tengono: le letture restano fresche, le scritture si bloccano, i client ricevono errori chiari?
Alert che catturano il compromesso presto
Aggiungi alert per:
- lag di replicazione che supera la finestra di staleness tollerata
- fallimenti di quorum (impossibile raggiungere abbastanza repliche) e aumento dei conteggi di retry
- aumento dei conflitti di scrittura o backlog di riconciliazione
Infine, rendi esplicite le garanzie: documenta cosa promette il tuo sistema durante l'operazione normale e durante le partizioni, e forma i team di prodotto e support su cosa gli utenti potrebbero vedere e come rispondere.
Prototipare scelte CAP più velocemente (senza rifare tutto)
Se stai esplorando questi compromessi in un nuovo prodotto, aiuta molto validare le ipotesi presto—soprattutto intorno ai modi di fallimento, al comportamento dei retry e a cosa significa “stale” nell'interfaccia.
Un approccio pratico è prototipare una piccola versione del workflow (percorso di scrittura, percorso di lettura, retry/idempotenza e un job di riconciliazione) prima di impegnarti in un'architettura completa. Con Koder.ai, i team possono avviare web app e backend tramite un flusso guidato in chat, iterare rapidamente su modelli di dati e API, e testare diversi pattern di coerenza (per esempio, scritture rigorose + letture rilassate) senza il sovraccarico di una pipeline di build tradizionale. Quando il prototipo mostra il comportamento desiderato, puoi esportare il codice sorgente ed evolverlo in produzione.
Domande frequenti
Perché i database distribuiti affrontano un compromesso tra coerenza e disponibilità?
In un database replicato, gli stessi dati vivono su più macchine. Questo aumenta resilienza e può ridurre la latenza, ma introduce problemi di coordinamento: i nodi possono essere lenti, irraggiungibili o separati dalla rete, quindi non possono sempre concordare subito l'ultima scrittura.
Cosa significa “coerenza” in termini semplici?
La coerenza significa: dopo una scrittura avvenuta con successo, qualsiasi lettura successiva restituisce lo stesso valore—indipendentemente da quale replica risponde. In pratica, i sistemi spesso applicano questa condizione ritardando o rifiutando letture/scritture finché un numero sufficiente di repliche (o il leader) non conferma l'aggiornamento.
Cosa significa “disponibilità” in termini semplici?
La disponibilità significa che il sistema restituisce una risposta non di errore a ogni richiesta, anche quando alcuni nodi sono giù o non possono comunicare. La risposta potrebbe essere obsoleta, parziale o basata sulla conoscenza locale, ma il sistema evita di bloccare gli utenti durante i guasti.
Cos'è una partizione di rete e perché è così importante?
Una partizione di rete è una interruzione nella comunicazione tra nodi che dovrebbero comportarsi come un unico sistema. I nodi possono essere ancora sani, ma i messaggi non possono attraversare lo split in modo affidabile, il che costringe il database a scegliere tra:
- bloccare/rifiutare le richieste per preservare una verità unica (coerenza), oppure
- rispondere alle richieste su ciascun lato e riconciliare dopo (disponibilità).
Cosa vedono gli utenti durante partizioni o disaccordi tra repliche?
Durante una partizione, entrambi i lati possono accettare aggiornamenti che non riescono a condividere subito. Questo può portare a:
- Timeout (attesa di repliche irraggiungibili)
- Letture stale (letture da una replica indietro)
- Comportamento split-brain (utenti diversi vedono verità diverse)
Questi sono risultati visibili agli utenti quando le repliche non riescono temporaneamente a coordinarsi.
La teoria CAP significa davvero che puoi scegliere solo due dei tre?
Non significa “scegliere permanentemente due su tre”. Significa che quando si verifica una partizione, non puoi garantire entrambe le cose contemporaneamente:
- Coerenza (tutte le letture vedono l'ultima scrittura riconosciuta), e
- Disponibilità (ogni richiesta ottiene una risposta)
Fuori dalle partizioni, molti sistemi possono apparire sia coerenti che disponibili per la maggior parte del tempo—fino a quando la rete si comporta male.
Come aiutano i quorum (N, R, W) a bilanciare coerenza e disponibilità?
I quorum usano il voto tra repliche:
- N = numero di repliche
- W = repliche che devono confermare una scrittura
- R = repliche consultate per una lettura
Una linea guida comune è R + W > N per ridurre le letture stale. I quorum non risolvono le partizioni; definiscono quale lato può progredire (per esempio, il lato che ha ancora la maggioranza).
Cos'è la consistenza eventuale e quali anomalie aspettarsi?
La consistenza eventuale permette alle repliche di essere temporaneamente non sincronizzate purché poi convergano allo stesso valore. Anomalie comuni includono:
- Letture stale
- Lacune “read-your-writes” (non vedi subito il tuo aggiornamento)
- Aggiornamenti fuori ordine
I sistemi mitigano spesso questo con , e riconciliazioni periodiche (anti-entropy).
Come vengono riconciliate le scritture divergenti dopo che una partizione si risana?
I conflitti capitano quando repliche diverse accettano scritture distinte allo stesso elemento durante una disconnessione. Le strategie di risoluzione includono:
- Last-write-wins (LWW): semplice ma può eliminare aggiornamenti (e dipende dagli orologi)
- Vettori di versione / metadata causali: rilevano conflitti reali vs aggiornamenti ordinati
- Merge / CRDT: riconciliazione deterministica per certi tipi di dati
Scegli la strategia in base a cosa significa “corretto” per i tuoi dati.
Come scelgo la giusta postura tra coerenza e disponibilità per la mia applicazione?
Decidi in base al rischio di business e a quale modalità di errore gli utenti possono sopportare:
- Preferisci coerenza forte per denaro, permessi, inventario e azioni irreversibili.
- Preferisci disponibilità/eventuale per feed, analytics, cache e log dove lievi ritardi sono accettabili.
Pattern pratici includono livelli di coerenza per operazione, retry sicuri con , e con compensazioni per workflow multi-step.
Quale modalità di errore gli utenti detestano di più?
Durante una partizione, le scelte tipiche di UX sono tre:
- Spinner / attesa (priorizza correttezza, può sembrare lento)
- Errore / retry (onesto ma dirompente)
- Risultato stale (fluido ma occasionalmente sorprendente)
Scegli la modalità meno dannosa per ciascuna funzionalità, non per tutto il sistema in modo uniforme.