Cosa cambia con i database serverless
I database serverless cambiano la domanda principale che ti fai all'inizio: invece di “Quanta capacità del database dobbiamo comprare?” chiedi “Quanto database useremo?”. Sembra sottile, ma riorienta il budgeting, la previsione e persino le decisioni di prodotto.
Dalla pianificazione della capacità al pay-per-use
Con un database tradizionale scegli di solito una dimensione (CPU/RAM/storage), la riservi e la paghi che tu sia occupato o no. Anche se usi l'autoscaling, pensi ancora in termini di istanze e capacità di picco.
Con il serverless la bolletta normalmente segue unità di consumo—per esempio richieste, tempo di calcolo, operazioni di lettura/scrittura, storage o trasferimento dati. Il database può scalare automaticamente, ma il compromesso è che paghi direttamente per ciò che accade dentro la tua app: ogni picco, job in background e query inefficiente può riflettersi nella spesa.
Perché lo shift del modello di costo conta nelle fasi iniziali
Nelle prime fasi le prestazioni spesso sono “abbastanza buone” finché gli utenti non lamentano problemi. Il costo, invece, influisce subito sul runway.
Il serverless può essere una grande vittoria perché ti evita di pagare capacità inattiva, specialmente prima del product‑market fit quando il traffico è imprevedibile. Ma significa anche:
- Il tuo costo diventa variabile, non principalmente fisso.
- La spesa può cambiare più rapidamente del personale, rendendo più difficile accorgersene prima della fattura.
- Le scelte di engineering (pattern di query, caching, batching) influenzano prima del previsto le unit economics.
Per questo i fondatori spesso percepiscono il cambiamento come un problema finanziario prima che di scalabilità.
Cosa aspettarsi da questa guida
I database serverless possono semplificare le operazioni e ridurre gli impegni iniziali, ma introducono nuovi compromessi: complessità dei prezzi, sorprese di costo durante i picchi e nuovi comportamenti di performance (come cold start o throttling, a seconda del provider).
Nelle sezioni successive analizzeremo come funziona comunemente il pricing serverless, dove si nascondono i costi inattesi e come prevedere e controllare la spesa—anche quando non hai dati perfetti.
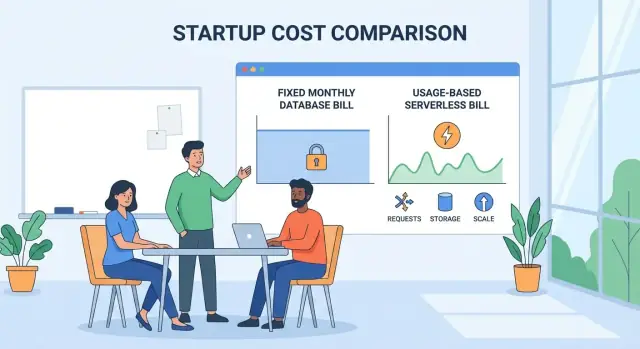
Il modello di costo tradizionale per le startup
Prima del serverless, molte startup compravano database come comprano uffici: si sceglie una dimensione, si sottoscrive un piano e si paga che lo si usi pienamente o no.
Costi fissi: pagare per capacità provisionata
La bolletta classica del cloud è dominata dalle istanze provisionate—una specifica dimensione macchina (o cluster) che tieni attiva 24/7. Anche se il traffico cala di notte, il contatore continua perché il database è ancora “acceso”.
Per ridurre il rischio si aggiunge spesso capacità riservata (impegno a uno o tre anni per uno sconto). Questo abbassa il costo orario ma ti vincola a una spesa di base che potrebbe non andare più bene se il prodotto cambia, la crescita rallenta o l'architettura evolve.
Poi c'è la sovradimensione: scegliere un'istanza più grande “per sicurezza”. È razionale se temi outage, ma spinge verso costi fissi più alti prima che i ricavi li supportino.
Il pattern comune nelle startup: comprare per il picco, pagare per l'inattività
Le startup raramente hanno carichi stabili e prevedibili. Puoi avere uno spike da PR, un lancio prodotto o traffico di fine mese. Con i database tradizionali di solito ridimensioni per la peggiore settimana immaginabile, perché ridimensionare dopo può essere rischioso (e spesso richiede pianificazione).
Il risultato è un disallineamento: paghi la capacità di picco tutto il mese mentre l'uso medio è molto più basso. Quella «spesa inattiva» diventa invisibile nella fattura, ma può diventare una delle voci ricorrenti più grandi.
Anche l'overhead operativo è un costo
I database tradizionali portano anche un costo in tempo che pesa sulle piccole squadre:
- Manutenzione di routine (patch, upgrade, backup, tuning)
- Lavoro di scaling (capacity planning, load test, resize)
- Risposta agli incidenti quando la performance degrada sotto carico imprevisto
Anche con servizi gestiti, qualcuno deve occuparsi di queste attività. Per una startup spesso significa tempo di ingegneria costoso che avrebbe potuto andare a prodotto—un costo implicito che non appare come una singola voce ma influisce comunque sul runway.
Come funziona tipicamente il pricing serverless
I database “serverless” sono di solito database gestiti con capacità elastica. Non gestisci server, patch o dimensionamenti preventivi. Il provider aggiusta la capacità su/giù e ti fattura in base a segnali di utilizzo.
I contatori principali su cui vieni fatturato
La maggior parte dei provider combina pochi metri di fatturazione (i nomi variano, ma i concetti sono coerenti):
- Compute: il lavoro che il database fa per processare le query (spesso misurato come “unità di capacità” per secondo/minuto).
- Storage: quanto dati tieni a riposo, a volte diviso tra dati e indici.
- Letture/Scritture (I/O): quante operazioni di lettura e scrittura esegui, o quanto dati scansionati.
- Richieste/Query: chiamate API o richieste SQL, a volte con tier per “semplice” vs “complessa”.
- Connessioni: connessioni attive o tempo di connessione (meno comune, ma importante quando esiste).
Alcuni vendor fatturano separatamente anche backup, replica, trasferimento dati o feature speciali (chiavi di crittografia, point-in-time restore, repliche analitiche).
Autoscaling: perché la bolletta segue la domanda
L'autoscaling è il cambiamento comportamentale principale: quando il traffico schizza, il database aumenta capacità per mantenere le performance, e paghi di più in quel periodo. Quando la domanda scende, la capacità si riduce e i costi possono calare—talvolta in modo drastico per carichi molto bursty.
Questa flessibilità è il vantaggio, ma significa anche che la spesa non è più legata a una «dimensione istanza» fissa. Il costo segue i pattern di prodotto: una campagna marketing, un job in batch o una query inefficiente possono cambiare la bolletta mensile.
“Serverless” non significa necessariamente “economico”
È meglio leggere “serverless” come paga-per-ciò-che-usi plus convenienza operativa, non come uno sconto garantito. Il modello premia carichi variabili e iterazione rapida, ma può punire uso costante o query non ottimizzate.
Dall'infrastruttura alle unit economics
Con i database tradizionali i costi iniziali spesso sembrano “affitto”: paghi per una dimensione server (più repliche, backup e tempo ops) indipendentemente dalla presenza dei clienti. I database serverless ti spingono verso il ragionamento sul “costo del venduto”: la spesa segue ciò che il prodotto effettivamente fa.
Mappa l'attività di prodotto alle unità fatturabili
Per gestire bene la cosa, traduci il comportamento del prodotto nelle unità che il database fattura. Per molte squadre la mappatura pratica è:
- Iscrizioni → record utente creati, scritture profilo, lookup di verifica
- Sessioni → letture per feed home, viste cache, query di personalizzazione
- Chiamate API → esecuzioni di query, transazioni o unità di richiesta
- Ordini/eventi → picchi di scritture, controlli inventario, log di audit
Quando puoi legare una feature a un'unità misurabile, puoi rispondere: “Se l'attività raddoppia, cosa raddoppia esattamente nella bolletta?”
Introduci metriche semplici di unit economics
Oltre alla spesa cloud totale, introduce alcune metriche «costo per» che corrispondono al tuo modello di business:
- Costo per utente (MAU)
- Costo per 1.000 richieste (o per 1.000 letture/scritture)
- Costo per ordine (o per completamento di workflow)
Questi numeri ti aiutano a valutare se la crescita è sana. Un prodotto può “scalare” mentre i margini si erodono se l'uso del database cresce più velocemente dei ricavi.
Come il pricing influenza freemium e trial
Il pricing basato sull'uso influenza direttamente come strutturi tier gratuiti e trial. Se ogni utente free genera query significative, il canale di acquisizione “gratuito” può diventare un costo variabile reale.
Regolazioni pratiche includono limitare azioni costose (ricerche pesanti, export, cronologia lunga), accorciare la retention nei piani gratuiti o mettere a pagamento feature che generano carichi bursty. L'obiettivo non è criptopare il prodotto, ma garantire che l'esperienza free sia sostenibile per costo per utente attivato.
Perché le startup avvertono l'impatto prima
Prototype your unit economics
Trasforma le azioni utente in letture e scritture misurabili mentre costruisci.
Le startup vivono spesso il disallineamento più estremo tra “ciò che serve oggi” e “ciò che potrebbe servire il mese prossimo”. Ed è qui che i database serverless cambiano la conversazione sui costi: trasformano il capacity planning (una stima) in una bolletta che segue da vicino l'uso reale.
A differenza delle aziende mature con basi stabili e team ops dedicati, le prime squadre bilanciano runway, iterazione rapida di prodotto e domanda imprevedibile. Un piccolo spostamento nel traffico può trasformare la spesa del database da «errore di arrotondamento» a voce significativa, e il feedback è immediato.
Il traffico spiky è normale, non un caso limite
La crescita iniziale non arriva liscia. Si presenta a raffiche:
- Giorni di lancio e spike su Product Hunt
- Campagne, menzioni di influencer, press e referral da partnership
- Picchi stagionali (vacanze, rinnovi annuali, fine trimestre)
Con un setup tradizionale spesso paghi il picco tutto il mese per sopravvivere a poche ore di punta. Con il serverless l'elasticità può ridurre lo spreco perché è meno probabile mantenere capacità costosa inattiva “giusto in caso”.
L'incertezza iniziale rende doloroso il dimensionamento fisso
Le startup cambiano spesso direzione: nuove feature, nuovi flussi di onboarding, nuovi tier di prezzo, nuovi mercati. La curva di crescita è incerta—e il carico sul database può cambiare senza preavviso (più letture, analytics più pesanti, documenti più grandi, sessioni più lunghe).
Se pre-provisioni, rischi due errori costosi:
- Sovradimensionamento: pagare capacità inutilizzata per conservare liquidità
- Sottodimensionamento: raggiungere limiti di performance che causano pagine lente, checkout falliti o degrado dell'esperienza
Il serverless può abbassare il rischio di outage da sottodimensionamento perché scala con la domanda invece di aspettare che un umano ridimensioni in un incidente.
L'impatto è finanziario e operativo
Per i fondatori il guadagno più grande non è solo una minore spesa media—è minor impegno. Il pricing basato sull'uso ti permette di allineare i costi alla traction e imparare più velocemente: puoi correre esperimenti, sopravvivere a uno spike improvviso e solo dopo decidere se ottimizzare, riservare capacità o cercare alternative.
Il compromesso è che i costi diventano più variabili, quindi le startup hanno bisogno di guardrail leggeri presto (budget, alert e attribuzione d'uso di base) per evitare sorprese pur sfruttando l'elasticità.
Driver di costo nascosti da tenere d'occhio
La fatturazione serverless è ottima per allineare la spesa all'attività—finché “attività” non include tanto lavoro che non avevi realizzato di generare. Le sorprese più grandi arrivano spesso da comportamenti piccoli e ripetuti che si moltiplicano.
Crescita dello storage e retention
Lo storage raramente resta piatto. Tabelle di eventi, log di audit e analytics prodotto possono crescere più velocemente dei dati utente core.
Backup e point-in-time recovery possono essere fatturati separatamente (o duplicare lo storage). Una regola pratica è impostare politiche di retention esplicite per:
- log ed eventi applicativi
- snapshot storici ed export
- ambienti di test che tengono dataset simili alla produzione per errore
Costi di rete e trasferimento dati
Molte squadre presumono che il “costo del database” sia solo letture/scritture e storage. Ma la rete può dominare quando:
- esegui app server in una regione e il database in un'altra
- replichi dati cross-region per affidabilità
- invii grandi result set a client o strumenti analitici
Anche se il provider pubblicizza un prezzo basso per richiesta, il traffico inter-region e l'egress possono trasformare un carico modesto in una voce significativa.
Query inefficaci che moltiplicano l'uso
Il pricing basato sull'uso ingrandisce i pattern di query scorretti. N+1, indici mancanti e scansioni non limitate possono trasformare una singola azione utente in dozzine (o centinaia) di operazioni fatturate.
Controlla gli endpoint dove la latenza cresce con la dimensione del dataset—spesso sono gli stessi endpoint dove i costi aumentano in modo non lineare.
Tempeste di connessioni e limiti di concorrenza
Le app serverless possono scalare istantaneamente, il che significa che il conteggio delle connessioni può esplodere. Cold start, eventi di autoscaling e retry a “thundering herd” possono creare raffiche che:
- aumentano le unità di compute/richiesta fatturate
- innescano throttling che causa altri retry (e altro uso)
Se il tuo database fattura per connessione o per concorrenza, questo può essere particolarmente costoso durante deploy o incidenti.
Job in background e workload analitici
Backfill, reindexing, job di raccomandazione e refresh delle dashboard non sembrano “uso prodotto”, ma spesso generano query grandi e letture di lunga durata.
Una regola pratica: tratta analytics e batch come workload separati con budget e orari propri, così non consumano silenziosamente il budget destinato a servire utenti.
Tradeoff tra costo e prestazioni
I database serverless non cambiano solo quanto paghi—cambiano per cosa paghi. Il compromesso centrale è semplice: minimizzare la spesa a vuoto con lo scale-to-zero può introdurre latenza e variabilità che gli utenti notano.
Cold start e scale-to-zero: quando aiutano e quando danneggiano
Lo scale-to-zero è ottimo per carichi bursty: dashboard admin, strumenti interni, traffico MVP iniziale o job settimanali. Smetti di pagare capacità che non usi.
Il rovescio è il cold start. Se il database (o il suo layer compute) va inattivo, la richiesta successiva può pagare una penale di “wake-up”—a volte qualche centinaio di millisecondi, a volte secondi—dipende dal servizio e dal pattern di query. Questo può andare bene per task in background, ma essere doloroso per:
- Flussi di checkout e login
- Ricerca o feed rivolti all'utente
- API con obiettivi di latenza p95/p99 stringenti
Un errore comune è ottimizzare per bollette mensili più basse intaccando inconsapevolmente il «budget di performance» che danneggia conversione o retention.
Strategie di caching e warm-up che bilanciano costo e latenza
Puoi ridurre l'impatto dei cold start senza rinunciare ai risparmi:
- Cache le letture calde (profili, feature flag) in una cache edge o in Redis gestito per alleggerire query ripetute.
- Precalcola risultati costosi (conteggi, rollup, raccomandazioni) così le richieste fanno meno lavoro.
- Warm-up schedulati (ping leggeri ogni pochi minuti) mantengono il sistema reattivo durante l'orario lavorativo, lasciando ridurre la notte.
Il compromesso: ogni mitigazione sposta il costo su una voce diversa (cache, funzioni, job schedulati). Spesso è comunque più economico dell'aver sempre on, ma va misurato, soprattutto quando il traffico diventa costante.
Scegliere tra realtime, batch e approcci ibridi
La forma del workload determina il miglior bilanciamento costo/prestazioni:
- Serving realtime (bassa latenza, alta disponibilità): considera capacità minima provisionata o mantenere servizi caldi.
- Batch (ETL, report, backfill): il serverless eccelle—corri forte, finisci in fretta, paga solo per il job.
- Ibrido: servi da tabelle precompute o cache in realtime e esegui join/aggregazioni pesanti in batch.
Per i fondatori la domanda pratica è: quali azioni utente richiedono velocità costante e quali possono tollerare ritardo? Allinea la modalità del database a quella risposta, non solo alla bolletta.
Prevedere la spesa senza dati perfetti
Deploy and host in minutes
Ottieni un ambiente funzionante rapidamente per misurare traffico reale e costi.
All'inizio raramente conosci il mix di query, il picco di traffico o la velocità di adozione delle feature. Con i database serverless quell'incertezza conta perché la fatturazione segue da vicino l'uso. Lo scopo non è la previsione perfetta—è ottenere un intervallo “sufficientemente buono” che eviti bollette a sorpresa e supporti decisioni di pricing.
Metodo semplice di previsione: baseline + crescita + moltiplicatore di picco
Parti da una settimana baseline che rappresenta l'uso “normale” (anche se deriva da staging o un piccolo beta). Misura le poche metriche che il provider fattura (comuni: letture/scritture, tempo di compute, storage, egress).
Poi prevedi in tre passi:
- Baseline: uso e costo medio giornaliero di oggi.
- Crescita: un tasso di crescita settimanale/mensile legato a una metrica prodotto che tracci (iscrizioni, WAU, ordini).
- Moltiplicatore di picco: moltiplica la baseline per un fattore (spesso 2×–5×) per lanci, spike e job.
Questo ti dà una banda: spesa attesa (baseline + crescita) e “spesa da stress” (moltiplicatore di picco). Considera il numero di stress come quello che il tuo cash flow deve sopportare.
Stima i costi a milestone chiave con test di carico
Esegui load test leggeri su endpoint rappresentativi per stimare il costo a milestone come 1k, 10k, 100k utenti. Lo scopo è scoprire dove le curve di costo si piegano (per esempio quando una chat raddoppia le scritture o una query analytics scatena scan pesanti).
Documenta le assunzioni: richieste medie per utente, rapporto letture/scritture e concorrenza di picco.
Metti guardrail prima che arrivino le sorprese
Imposta un budget mensile e soglie di allerta (per esempio 50%, 80%, 100%) e un alert per “spike anomalo” sulla spesa giornaliera. Affianca gli alert a un playbook: disabilita job non essenziali, riduci logging/analytic query o applica rate limit agli endpoint costosi.
Infine, quando confronti provider o tier, usa le stesse assunzioni d'uso e confrontale con i dettagli sul piano alla voce /pricing per assicurarti parità di confronto.
Controlli pratici dei costi e guardrail
I database serverless premiano l'efficienza, ma puniscono le sorprese. L'obiettivo non è “ottimizzare tutto”—è impedire spese fuori controllo mentre impari i pattern di traffico.
Imposta budget per ambiente
Tratta dev, staging e prod come prodotti separati con limiti separati. Un errore comune è lasciare che workload sperimentali condividano lo stesso pool di fatturazione del traffico cliente.
Imposta un budget mensile per ogni ambiente e soglie di alert (es. 50%, 80%, 100%). Dev dovrebbe essere intenzionalmente stringente: se un test di migrazione può bruciare soldi veri, deve fallire rumorosamente.
Se iteri velocemente aiuta usare tooling che renda “change sicuro + rollback veloce” una routine. Per esempio, piattaforme come Koder.ai enfatizzano snapshot e rollback così puoi spedire esperimenti mantenendo controllo sui costi e regressioni di performance.
Rendi visibili i costi con tagging e allocazione
Se non puoi attribuire i costi, non puoi gestirli. Standardizza tag/label da subito così ogni database, progetto o meter d'uso sia attribuibile a un servizio, team e (idealmente) feature.
Punta a uno schema semplice da far rispettare nelle review:
- service: api, worker, analytics
- team: growth, core, data
- feature: search, onboarding, recommendations
Questo trasforma “la bolletta del database è salita” in “le letture di search sono raddoppiate dopo il rilascio X”.
Prevenire picchi con default sensati
La maggior parte dei picchi nasce da pochi pattern errati: polling troppo frequente, mancanza di paginazione, query non limitate e fan-out accidentale.
Aggiungi guardrail leggeri:
- Review delle query per ogni cambiamento che tocchi percorsi caldi (specialmente nuovi indici, join o scansioni complete)
- Rate limit per endpoint e per cliente per evitare che un tenant domini la spesa
- Default sicuri: paginazione richiesta, dimensione massima pagina, timeout e limiti di risultato
Limiti, quote e circuit breaker
Usa limiti rigidi quando il downside di downtime è minore del downside di bollette aperte.
- Caps/quote: utili per dev/staging e strumenti interni; considera quote per tenant in produzione.
- Circuit breaker: se la spesa o le QPS superano una soglia degrada con grazia (servi dati cache, disattivi feature pesanti, o chiedi di riprovare più tardi).
Se costruisci questi controlli ora, te ne ringrazierai dopo—soprattutto quando farai cloud spend management e FinOps per startup.
Quando il serverless potrebbe non essere l'opzione più economica
Export the source anytime
Mantieni il controllo esportando il codice quando sei pronto a gestire la pipeline da solo.
I database serverless brillano quando l'uso è spiky e incerto. Ma quando il workload diventa costante e intenso, la matematica del “paga-per-ciò-che-usi” può ribaltarsi.
Carico costante e alto: il provisioned può vincere
Se il tuo database è occupato la maggior parte delle ore del giorno, il pricing basato sull'uso può superare il costo di un'istanza provisionata (o di capacità riservata) che paghi comunque. Un pattern comune è un prodotto B2B maturo con traffico costante in orario lavorativo più job notturni: un cluster a dimensione fissa con pricing riservato può offrire un costo per richiesta più basso, soprattutto tenendo alta l'utilizzazione.
Serverless non è sempre amico di:
- traffico prevedibile dove puoi dimensionare un deployment fisso
- analytics pesanti (scansioni grandi, join massicci) che consumano molte unità di lettura/compute
- query di lunga durata che tengono risorse per minuti
Questi workload possono creare un doppio danno: maggior uso misurato e rallentamenti occasionali quando si raggiungono limiti di scaling o di concorrenza.
Checklist per confrontare vendor (prima di impegnarsi)
Le pagine prezzi possono sembrare simili mentre i metri differiscono. Quando confronti provider, conferma:
- Cosa è misurato (compute, letture/scritture, storage, I/O, backup, egress)
- Dettagli del free tier e cosa succede quando lo superi
- Comportamento di scaling (quanto scala velocemente, unità minime di fatturazione, regole di scale-to-zero)
- Limiti (max concorrenza, max connessioni, rate limit, timeout query)
Quando ripensare la scelta
Rivaluta quando noti uno di questi trend:
- Il tuo uso baseline smette di fluttuare e sembra una linea piatta
- Il costo unitario per cliente cresce con la scala (segnale di warning sui margini)
A quel punto esegui un modello affiancato: bolletta serverless attuale vs setup provisioned dimensionato correttamente (con riservazioni possibili), aggiungendo l'overhead operativo che assumeresti. Se ti serve aiuto per costruire quel modello, vedi /blog/cost-forecasting-basics.
Checklist rapida per i fondatori
I database serverless possono essere una buona scelta quando hai traffico irregolare e dai valore alla velocità di iterazione. Possono però sorprendere quando i «meter» non corrispondono a come il tuo prodotto si comporta. Usa questa checklist per decidere in fretta e per evitare di sottoscrivere un modello di costo che non sapresti spiegare al team o agli investitori.
1) Checklist veloce: puoi modellare il tuo workload?
- Definisci il workload: qual è il percorso core—login, feed, checkout, analytics? Quali operazioni sono “sempre attive” vs bursty?
- Stima i metri: letture/scritture, crescita storage, tempo di compute, conteggio richieste, trasferimento dati, backup e eventuali costi per feature (indici, ricerca vettoriale, change streams).
- Imposta budget e alert: crea un budget mensile e una «soglia panico» (es. 2× settimana normale). Applica limiti nella fatturazione, non solo nelle dashboard.
- Testa i picchi: esegui un load test o riproduci traffico di produzione per l'ora/giorno peggiore. Il pricing spesso cambia agli estremi.
2) Domande da porre ai provider prima di impegnarsi
- Cosa è esattamente fatturabile e a quale granularità? (per richiesta, per secondo, per GB, per regione)
- Quali impostazioni di default aumentano la spesa? (retention, backup, repliche, minimi di autoscaling)
- Come vengono gestiti i picchi? Ci sono throttling, smoothing o prezzi di picco?
- Ci sono free tier, crediti o sconti per impegno—e cosa succede alla loro scadenza?
- Quali sono le vie di fuga? Velocità/costo di export dati, rischi di lock-in e percorsi di migrazione.
- Come gestite isolamento multi-tenant vs dedicato? (noisy neighbors, variazione di performance)
Conclusione principale
Allinea il modello di prezzo con la tua incertezza di crescita: se traffico, query o dimensione dati possono cambiare rapidamente, preferisci modelli che puoi prevedere con pochi driver che controlli.
Passo successivo
Esegui un piccolo pilot su una feature reale, rivedi i costi settimanali per un mese e annota quale meter ha guidato ogni aumento. Se non riesci a spiegare la bolletta in una frase, non scala ancora.
Se stai costruendo il pilot da zero, valuta quanto velocemente puoi iterare su strumentazione e guardrail. Per esempio, Koder.ai può aiutare i team a generare rapidamente un'app React + Go + PostgreSQL, esportare il codice quando serve e mantenere gli esperimenti sicuri con planning mode e snapshot—utile mentre impari quali query e workflow guideranno la tua economia unitaria.