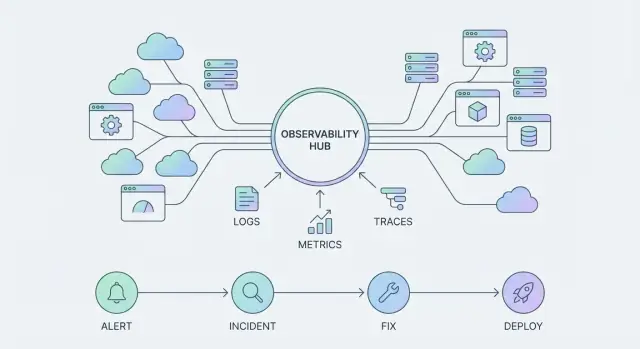
Uno strumento di osservabilità ti aiuta a rispondere a domande specifiche su un sistema—di solito mostrando grafici, log o il risultato di una query. È qualcosa che “usi” quando c'è un problema.
Una piattaforma di osservabilità è più ampia: standardizza come la telemetria viene raccolta, come i team la esplorano e come gli incidenti vengono gestiti end-to-end. Diventa qualcosa che la tua organizzazione “gestisce” ogni giorno, attraverso molti servizi e team.
Dai grafici agli esiti
La maggior parte dei team inizia con dashboard: grafici CPU, tassi di errore, magari qualche ricerca nei log. È utile, ma l'obiettivo reale non sono grafici più belli—è rilevare e risolvere più velocemente.
Un cambiamento verso la piattaforma avviene quando smetti di chiederti, “Possiamo graficare questo?” e inizi a chiedere:
- L'ingegnere on-call può trovare la causa in minuti, non ore?\n- Possiamo instradare automaticamente l'alert giusto al team giusto?\n- Possiamo trasformare pattern di incidenti ripetuti in playbook ripetibili?
Sono domande focalizzate sugli esiti, e richiedono più della visualizzazione. Richiedono standard dati condivisi, integrazioni coerenti e workflow che colleghino la telemetria all'azione.
I tre pilastri che stai davvero comprando
Man mano che piattaforme come la piattaforma di osservabilità Datadog evolvono, la “superficie prodotto” non sono solo le dashboard. Sono tre pilastri interconnessi:
- Telemetria: log, metriche e tracce raccolti in modo consistente e etichettati abbastanza bene da essere affidabili.\n2. Integrazioni: connessioni predefinite che facilitano l'adozione ed espandono la copertura senza colla custom.\n3. Workflow: risposta agli incidenti, instradamento degli alert, ownership e follow-up—così l'apprendimento si somma.
Una singola dashboard può aiutare un singolo team. Una piattaforma si rafforza con ogni servizio onboardato, ogni integrazione aggiunta e ogni workflow standardizzato. Col tempo questo si traduce in meno punti ciechi, meno strumenti duplicati e incidenti più brevi—perché ogni miglioramento diventa riutilizzabile, non un caso isolato.
La telemetria diventa la superficie del prodotto
Quando l'osservabilità passa da “uno strumento che interroghiamo” a “una piattaforma su cui costruiamo”, la telemetria smette di essere semplice scarico grezzo e inizia a comportarsi come la superficie del prodotto. Ciò che scegli di emettere—e quanto coerentemente lo emetti—determina cosa i tuoi team possono vedere, automatizzare e fidarsi.
I tipi di telemetria principali (e a cosa servono)
La maggior parte dei team si standardizza su un piccolo insieme di segnali:
- Metriche: trend numerici nel tempo (latenza, tasso di errori, saturazione).\n- Log: registri dettagliati e leggibili dall'umano per investigazione e audit.\n- Tracce: percorsi delle richieste tra servizi per trovare dove si spende tempo o avvengono fallimenti.\n- Eventi: registrazioni discrete di “qualcosa è cambiato” (deploy, feature flag, incidenti).\n- Profile: comportamento CPU/memoria per individuare percorsi di codice costosi.
Singolarmente, ogni segnale è utile. Insieme, diventano un'interfaccia unica verso i tuoi sistemi—quello che vedi in dashboard, alert, timeline degli incidenti e postmortem.
Coerenza batte volume
Un errore comune è raccogliere “tutto” ma chiamarlo in modo incoerente. Se un servizio usa userId, un altro uid e un terzo non registra nulla, non puoi sezionare i dati in modo affidabile, unire segnali o costruire monitor riutilizzabili.
I team ottengono più valore accordandosi su poche convenzioni—nomi dei servizi, tag di ambiente, ID richiesta e un set standard di attributi—piuttosto che raddoppiare il volume di ingestione.
Cosa significa davvero alta cardinalità (e perché conta)
I campi ad alta cardinalità sono attributi con molti valori possibili (come user_id, order_id o session_id). Sono potenti per il debug di problemi che “accadono solo a un cliente”, ma possono anche aumentare i costi e rallentare le query se usati ovunque.
L'approccio della piattaforma è intenzionale: mantieni l'alta cardinalità dove porta chiaro valore investigativo e evitane l'uso nei punti pensati per aggregati globali.
Il contesto unificato riduce il lavoro di correlazione
Il ritorno è velocità. Quando metriche, log, tracce, eventi e profile condividono lo stesso contesto (service, versione, regione, request ID), gli ingegneri passano meno tempo a cucire evidenze e più tempo a risolvere il problema reale. Invece di saltare tra strumenti e indovinare, segui un unico filo dal sintomo alla causa radice.
Dalla raccolta dati a una strategia di telemetria
La maggior parte dei team inizia l'osservabilità “facendo entrare i dati”. È necessario, ma non è una strategia. Una strategia di telemetria mantiene l'onboarding veloce e rende i dati abbastanza coerenti da alimentare dashboard condivise, alert affidabili e SLO significativi.
Percorsi di ingestione comuni (e a cosa servono)
Datadog tipicamente riceve telemetria tramite alcune vie pratiche:
- Agent sui host/VM: il modo più rapido per raccogliere metriche infrastrutturali, log e APM con minime modifiche al codice.\n- Collector e gateway (es. OpenTelemetry Collector): utile quando vuoi controllo centrale, routing verso più destinazioni, redaction o elaborazione standard.\n- API e SDK diretti: utili per eventi custom, metriche di business o quando un agent non è fattibile.\n- Integrazioni serverless: comode per runtime gestiti dove non controlli l'host, ma devi decidere deliberatamente cosa emettere.
Velocità vs. standardizzazione: decidi cosa ottimizzare
All'inizio vince la velocità: i team installano un agent, attivano alcune integrazioni e vedono subito valore. Il rischio è che ogni team inventi i propri tag, nomi servizio e formati di log—rendendo le viste cross-service disordinate e gli alert poco affidabili.
Una regola semplice: consenti l'onboarding rapido, ma richiedi la standardizzazione entro 30 giorni. Questo dà momentum senza cristallizzare il caos.
Una convenzione leggera per naming e tagging
Non serve una tassonomia enorme. Inizia con un piccolo set che ogni segnale (log, metriche, tracce) deve avere:
service: breve, stabile, lowercase (es. checkout-api)\n- env: prod, staging, dev\n- team: identificatore del team responsabile (es. payments)\n- version: versione del deploy o git SHA
Se vuoi un campo in più che renda tutto più semplice, aggiungi tier (frontend, backend, data) per semplificare i filtri.
Campionamento, retention e predefiniti attenti ai costi
I problemi di costo solitamente nascono da default troppo generosi:
- Tracce: inizia con sampling head-based per endpoint ad alto volume; mantieni il 100% per flussi critici.\n- Log: di default registra “errori + eventi business importanti”, poi aggiungi info/debug selettivamente con retention temporizzata.\n- Retention: conserva dati ad alta risoluzione per meno giorni, conserva aggregati chiave più a lungo (settimane/mesi).
L'obiettivo non è raccogliere meno, ma raccogliere i dati giusti in modo coerente, così puoi scalare l'uso senza sorprese.
Le integrazioni come vero canale di distribuzione
La maggior parte pensa agli strumenti di osservabilità come “qualcosa da installare”. In pratica, si diffondono in un'organizzazione così come si diffondono i connettori efficaci: un'integrazione alla volta.
Cosa significa davvero “integrazione”
Un'integrazione non è solo una pipe dati. Di solito ha tre parti:
- Fonti dati: raccolgono metriche, log, tracce, eventi e topologia dai sistemi che già esegui (cloud, Kubernetes, database, CI/CD, tool SaaS).\n- Arricchimento: aggiungono contesto così la telemetria è subito utilizzabile—nomi dei servizi, ambienti, tag di ownership, versioni di deploy e metadata cloud.\n- Azioni: fanno qualcosa con quanto appreso—creano ticket, paginano on-call, annotano deploy, scalano risorse o attivano runbook.
Quell'ultima parte è ciò che trasforma le integrazioni in distribuzione. Se lo strumento solo legge, è una destinazione per dashboard. Se può anche scrivere, diventa parte del lavoro quotidiano.
Perché le integrazioni accelerano l'adozione
Le buone integrazioni riducono il tempo di setup perché arrivano con default sensati: dashboard preconfezionate, monitor raccomandati, regole di parsing e tag comuni. Invece di far inventare a ogni team la propria “dashboard CPU” o “alert Postgres”, ottieni un punto di partenza standard che segue le best practice.
I team personalizzano comunque—ma partono da una baseline condivisa. Questa standardizzazione conta quando consolidi strumenti: le integrazioni creano pattern ripetibili che i nuovi servizi possono copiare, mantenendo la crescita gestibile.
Dai priorità alle integrazioni bidirezionali
Quando valuti le opzioni, chiediti: può ingestire segnali e eseguire azioni? Esempi includono l'apertura di incidenti nel sistema di ticketing, l'aggiornamento dei canali di incidenti o l'allegare un link a una trace in una PR o vista di deploy. Le configurazioni bidirezionali sono dove i workflow cominciano a sentirsi “native”.
Un metodo semplice per la short list
Inizia piccolo e prevedibile:
- Infrastruttura critica prima (cloud provider, Kubernetes, load balancer, DB core).\n2. Poi la pipeline di deploy (CI/CD, feature flag, tracciamento release) così la telemetria si allinea ai cambiamenti.\n3. Aggiungi SaaS per team (code, cache, auth, pagamenti) una volta che tagging e convenzioni di ownership sono stabili.
Se vuoi una regola pratica: dai priorità alle integrazioni che migliorano immediatamente la risposta agli incidenti, non a quelle che aggiungono solo più grafici.
Viste standard: servizi, dashboard e monitor
Le viste standard sono dove una piattaforma di osservabilità diventa utilizzabile giorno per giorno. Quando i team condividono lo stesso modello mentale—cos'è un “servizio”, cosa significa “sano” e dove cliccare per primo—il debug è più veloce e i passaggi di consegna più puliti.
Inizia con i golden signals (e rendili visibili)
Scegli un piccolo set di “golden signals” e mappa ciascuno a una dashboard concreta e riutilizzabile. Per la maggior parte dei servizi, sono:\n
- Latenza (p95/p99 per endpoint chiave)\n- Traffico (richieste al secondo, job processati)\n- Errori (tasso e principali tipi di errore)\n- Saturazione (CPU, memoria, profondità code, connessioni DB)
La chiave è la coerenza: un layout di dashboard che funziona per tutti i servizi batte dieci dashboard su misura e sparpagliate.
I cataloghi servizi creano ownership condivisa
Un catalogo servizi (anche leggero) trasforma “qualcuno dovrebbe guardare questo” in “questo team lo possiede”. Quando i servizi sono taggati con proprietari, ambienti e dipendenze, la piattaforma può rispondere a domande basilari istantaneamente: quali monitor si applicano a questo servizio? Quali dashboard aprire? Chi viene paginato?
Quella chiarezza riduce il ping-pong su Slack durante gli incidenti e aiuta i nuovi ingegneri a self-service.
I mattoni che scalano
Considera questi come artefatti standard, non opzionali:\n
- Dashboard per golden signals e dipendenze chiave\n- Monitor legati a SLO o sintomi che impattano gli utenti\n- Notebook per investigazioni e timeline post-incidente\n- Runbook (linkati dai monitor) per i primi 5–10 minuti di risposta
Anti-pattern da evitare
Dashboard di facciata (grafici belli senza decisioni dietro), alert one-off (creati in fretta e mai sintonizzati) e query non documentate (solo una persona capisce il filtro magico) generano rumore sulla piattaforma. Se una query conta, salvala, nominala e allegala alla vista del servizio in modo che gli altri la trovino.
Workflow: dove l'osservabilità fornisce valore al business
Launch a Runbook Center
Trasforma gli incidenti ripetuti in una semplice libreria di runbook che il tuo team possa davvero utilizzare.
L'osservabilità diventa “reale” per il business quando accorcia il tempo tra un problema e una risoluzione sicura. Questo avviene tramite workflow—percorsi ripetibili che ti portano dal segnale all'azione, e dall'azione all'apprendimento.
Il viaggio dell'incidente: alert → triage → comunicazione → mitigazione → apprendimento
Un workflow scalabile è più del semplice paging.
Un alert dovrebbe aprire un ciclo di triage focalizzato: confermare l'impatto, identificare il servizio interessato e raccogliere il contesto più rilevante (deploy recenti, salute delle dipendenze, picchi di errori, segnali di saturazione). Da lì, la comunicazione trasforma un evento tecnico in una risposta coordinata—chi è il responsabile, cosa vedono gli utenti e quando è il prossimo aggiornamento.
La mitigazione è il punto in cui vuoi avere “mosse sicure” a portata di mano: feature flag, shifting del traffico, rollback, rate limit o una workaround conosciuta. Infine, l'apprendimento chiude il ciclo con una review leggera che cattura cosa è cambiato, cosa ha funzionato e cosa dovrebbe essere automatizzato.
Strumenti per incidenti + ChatOps = collaborazione, non eroismi
Piattaforme come la piattaforma di osservabilità Datadog aggiungono valore quando supportano lavoro condiviso: canali di incidente, aggiornamenti di stato, handoff e timeline coerenti. Le integrazioni ChatOps possono trasformare gli alert in conversazioni strutturate—creando un incidente, assegnando ruoli e pubblicando grafici e query chiave direttamente nel thread così tutti vedono la stessa evidenza.
Cosa contiene veramente un buon runbook
Un runbook utile è breve, opinabile e sicuro. Dovrebbe includere: l'obiettivo (ripristinare il servizio), proprietari chiari/rotazione on-call, controlli passo-passo, link alle dashboard/monitor giusti e “azioni sicure” che riducono il rischio (con passi di rollback). Se non è sicuro da eseguire alle 3 di notte, non è completo.
Collega gli incidenti ai deploy e ai cambiamenti
La causa radice è più veloce quando gli incidenti sono correlati automaticamente a deploy, modifiche di configurazione e flip di feature flag. Fai in modo che “cosa è cambiato?” sia una vista di prima classe così il triage parte dall'evidenza, non dalle ipotesi.
SLO e budget di errore come sistema operativo di team
Cos'è uno SLO (e perché batte le “dashboard verdi”)
Un SLO (Service Level Objective) è una promessa semplice sull'esperienza utente in una finestra temporale—per esempio “99.9% delle richieste va a buon fine in 30 giorni” o “p95 dei caricamenti sotto 2 secondi”.
Questo batte una “dashboard verde” perché le dashboard spesso mostrano salute del sistema (CPU, memoria, profondità code) piuttosto che impatto utente. Un servizio può sembrare sano e comunque fallire nel servire gli utenti (es. una dipendenza va in timeout, o gli errori sono concentrati in una regione). Gli SLO costringono il team a misurare ciò che gli utenti effettivamente percepiscono.
Budget di errore: un modo condiviso di parlare di rischio
Un budget di errore è la quantità di non-affidabilità permessa dallo SLO. Se prometti il 99.9% su 30 giorni, sei “autorizzato” a circa 43 minuti di errori in quella finestra.
Questo crea un sistema operativo pratico per le decisioni:
- Budget sano: rilascia funzionalità, sperimenta, prendi rischi ragionevoli.\n- Budget in consumo: rallenta i rilasci, concentrati sulla reliability.\n- Budget esaurito: sospendi deploy rischiosi e affronta le cause principali di failure.
Invece di discutere opinioni in una riunione di release, si discute un numero che tutti possono vedere.
Allerta sul burn rate, non su ogni spike
L'alerting basato su SLO funziona meglio quando allerti sul burn rate (quanto velocemente consumi il budget di errore), non sui conteggi grezzi di errori. Questo riduce il rumore:\n
- Uno spike breve che si auto-risolve potrebbe non paginare nessuno.\n- Un problema sostenuto che esaurirebbe presto il budget innesca un alert chiaro e azionabile.
Molti team usano due finestre: un fast burn (pagina rapidamente) e un slow burn (ticket/notifica).
Un set iniziale leggero di SLO per un servizio web tipico
Inizia piccolo—due-quattro SLO che userai davvero:
- Disponibilità: % di richieste riuscite (es. HTTP 2xx/3xx) su 30 giorni.\n- Latenza: p95 sotto una soglia (separare read e write se necessario).\n- Endpoint critico (es. checkout): tasso di successo per il percorso business più importante.\n- Freshness (se applicabile): job background completati entro X minuti.
Quando questi sono stabili puoi espandere—altrimenti costruirai solo un'altra parete di dashboard. Per altro, vedi /blog/slo-monitoring-basics.
Alerting che scala senza bruciare le persone
Track Integrations and Actions
Costruisci un portale semplice per tracciare integrazioni, ownership e quali azioni ognuna può attivare.
L'alerting è il punto in cui molti programmi di osservabilità si bloccano: i dati ci sono, le dashboard sono belle, ma l'esperienza on-call diventa rumorosa e non affidabile. Se le persone imparano a ignorare gli alert, la tua piattaforma perde la capacità di proteggere il business.
Perché si verifica l'alert fatigue (e perché i segnali si duplicano)
Le cause più comuni sono ricorrenti:\n
- Troppi alert “FYI” che non richiedono azione.\n- Soglie copiate tra servizi senza contesto (stessa regola CPU per workload molto diversi).\n- Più strumenti o team che alertano lo stesso sintomo—per esempio un monitor APM e un monitor basato su log che paginano per lo stesso incidente.\n- Metriche rumorose (percentili di latenza altalenanti, effetti di autoscaling) che generano fluttuazioni invece di problemi reali.
In termini pratici, i segnali duplicati spesso emergono quando i monitor sono creati da diverse “superfici” (metriche, log, tracce) senza decidere quale sia il canale canonico per paginare.
Instradamento: ownership, severità e quiet hours
Scala l'alerting con regole di instradamento comprensibili alle persone:\n
- Ownership: ogni monitor dovrebbe avere un owner chiaro (service/team) e un percorso di escalation.\n- Severità: riserva il paging per problemi urgenti che impattano gli utenti; usa ticket o notifiche chat per severità minore.\n- Finestre di manutenzione: deploy pianificati, migrazioni e test di carico non dovrebbero generare pagine.
Regole semplici che mantengono gli alert azionabili
Un default utile è: alert sui sintomi, non su ogni variazione di metrica. Pagina su ciò che gli utenti percepiscono (tasso di errori, checkout falliti, latenza sostenuta, burn di SLO), non sugli “input” (CPU, numero di pod) a meno che non prevedano in modo affidabile l'impatto.
Una cadenza di revisione che funziona davvero
Rendi l'igiene degli alert parte delle operazioni: revisione e pruning mensile dei monitor. Rimuovi i monitor che non scattano mai, aggiusta soglie che scattano troppo spesso e unisci duplicati in modo che ogni incidente abbia una pagina primaria più contesto di supporto.
Fatto bene, l'alerting diventa un workflow di cui la gente si fida—non un rumore di fondo.
Chiamare osservabilità una “piattaforma” non riguarda solo avere log, metriche, tracce e molte integrazioni in un unico posto. Implica anche governance: coerenza e guardrail che mantengono il sistema utilizzabile man mano che il numero di team, servizi, dashboard e alert cresce.
Senza governance, Datadog (o qualsiasi piattaforma) può degenerare in un album disordinato—centinaia di dashboard leggermente diverse, tag incoerenti, ownership poco chiara e alert di cui nessuno si fida.
La governance è un problema di persone e processi
Una buona governance chiarisce chi decide cosa e chi è responsabile quando la piattaforma diventa caotica:\n
- Platform team: definisce standard (tagging, naming, pattern dashboard), fornisce componenti condivisi e mantiene integrazioni.\n- Service owner: si occupa della qualità della telemetria per il proprio servizio e mantiene i monitor significativi.\n- Sicurezza & compliance: definisce regole di gestione dei dati (PII, retention, confini d'accesso) e revisiona integrazioni ad alto rischio.\n- Leadership: allinea la governance con le priorità di business (obiettivi di affidabilità, aspettative di risposta agli incidenti) e finanzia il lavoro.
Controlli pratici che prevengono lo “sprawl” dell'osservabilità
Alcuni controlli leggeri fanno più di lunghi documenti di policy:\n
- Template di default: dashboard starter e pack di monitor per tipo di servizio (API, worker, database) così i team partono coerenti.\n- Policy di tagging: un piccolo set obbligatorio (es.
service, env, team, tier) più regole chiare per i tag opzionali. Applica in CI dove possibile.\n- Accesso e ownership: usa RBAC per dati sensibili e richiedi un owner per dashboard e monitor.\n- Flow di approvazione per cambiamenti ad alto impatto: monitor che paginano, pipeline di log che impattano i costi e integrazioni che estraggono dati sensibili dovrebbero avere step di revisione.
Il riuso batte la reinvenzione
Il modo più veloce per scalare la qualità è condividere ciò che funziona:\n
- Librerie condivise: pacchetti interni o snippet che standardizzano campi di log, attributi di trace e metriche comuni.\n- Dashboard e monitor riutilizzabili: un catalogo centrale di dashboard “golden” e template di monitor che i team possono clonare e adattare.\n- Standard versionati: tratta gli asset chiave come codice—documenta i cambiamenti, depreca pattern vecchi e annuncia aggiornamenti in un posto solo.
Se vuoi che rimanga nel tempo, rendi il percorso governato anche il più semplice: meno click, setup più veloce e ownership più chiara.
Una volta che l'osservabilità si comporta come una piattaforma, tende a seguire l'economia delle piattaforme: più team la adottano, più telemetria viene prodotta e più diventa utile.
Questo crea un volano:\n
- Più servizi onboardati → migliore visibilità cross-service e correlazione\n- Migliore visibilità → diagnosi più veloce, meno incidenti ripetuti, maggiore fiducia nello strumento\n- Più fiducia → più team instrumentano e integrano → ancora più dati
Il problema è che lo stesso loop aumenta anche i costi. Più host, container, log, trace, synthetic e metriche custom possono crescere più rapidamente del budget se non gestiti deliberatamente.
Le leve pratiche sui costi (senza uccidere il segnale)
Non devi “spegnere tutto”. Parti modellando i dati:\n
- Sampling: mantieni trace ad alta fedeltà per endpoint critici, campiona più aggressivamente altrove.\n- Tier di retention: retention breve per raw log ad alto volume; retention più lunga per stream curati di sicurezza/audit.\n- Filtraggio e parsing dei log: elimina il rumore evidente presto (health check, richieste di asset statici) e standardizza il parsing così puoi instradare per attributi.\n- Aggregazione delle metriche: preferisci percentili, rate e rollup rispetto a cardinalità illimitata (es. ID utente per metrica).
KPI che collegano costo e risultati
Monitora un piccolo set di misure che mostrino se la piattaforma ripaga:\n
- MTTD (mean time to detect)\n- MTTR (mean time to resolve)\n- Numero di incidenti e incidenti ripetuti (stessa causa radice)\n- Frequenza di deploy (e change failure rate se lo tracci)
Eseguire una review trimestrale “valore vs costo” (senza colpe)
Falla diventare una review di prodotto, non un audit. Coinvolgi proprietari della piattaforma, alcuni team di servizio e finance. Revisiona:\n
- Principali driver di costo per tipo di dato (log/metriche/tracce) e per team\n- Principali risultati: incidenti accorciati, outage evitati, toil rimosso\n- 2–3 azioni concordate (es. aggiustare regole di sampling, aggiungere tier di retention, sistemare un'integrazione rumorosa)
L'obiettivo è ownership condivisa: il costo diventa un input per decisioni migliori sull'instrumentazione, non una ragione per smettere di osservare.
Cosa significa per il tuo stack di strumenti di osservabilità
Put SLOs Front and Center
Prototipa una dashboard SLO che evidenzi il burn rate e mantenga gli alert legati all'impatto sull'utente.
Se l'osservabilità sta diventando una piattaforma, il tuo “stack” smette di essere una collezione di soluzioni puntuali e inizia a comportarsi come infrastruttura condivisa. Questo cambiamento rende lo sprawl di strumenti più che un fastidio: genera strumentazione duplicata, definizioni incoerenti (cosa conta come errore?) e maggiore carico on-call perché i segnali non coincidono tra log, metriche, tracce e incidenti.
La consolidazione non significa automaticamente “un vendor per tutto”. Significa meno sistemi di record per telemetria e risposta, ownership più chiara e un numero ridotto di posti dove guardare durante un outage.
Cosa può risolvere davvero la consolidazione
Lo sprawl degli strumenti nasconde tipicamente costi in tre posti: tempo perso a saltare tra UI, integrazioni fragili da mantenere e governance frammentata (naming, tag, retention, accesso).
Un approccio più consolidato può ridurre il context switching, standardizzare le viste dei servizi e rendere i workflow di incidente ripetibili.
Una checklist decisionale (veloce ma pratica)
Quando valuti il tuo stack (incluso Datadog o alternative), verifica:
- Integrazioni indispensabili: cloud provider, Kubernetes, CI/CD, gestione incidenti, paging e data store chiave—più qualsiasi sistema business che “non possiamo spedire senza”.\n- Workflow: puoi andare da alert → owner → runbook → timeline → postmortem senza copia/incolla manuale?\n- Governance: standard di tagging, controlli d'accesso, retention e guardrail per lo sprawl di dashboard/monitor.\n- Modello di pricing: cosa guida il costo (host, container, log ingeriti, trace indicizzati)? Puoi prevedere la crescita senza sorprese?
Esegui un pilot con una metrica di successo chiara
Scegli uno o due servizi con traffico reale. Definisci una metrica di successo come “tempo per identificare la causa radice scende da 30 a 10 minuti” o “ridurre alert rumorosi del 40%”. Instrumenta solo quello che serve e rivedi i risultati dopo due settimane.
Centralizza la documentazione interna così l'apprendimento si accumula—collega il runbook del pilot, le regole di tagging e le dashboard in un unico posto (per esempio, /blog/observability-basics come punto di partenza interno).
Un piano di adozione pratico che puoi copiare
Non “fai il rollout di Datadog” una volta sola. Parti in piccolo, definisci standard presto, poi scala ciò che funziona.
Rollout 30/60/90 giorni
Giorni 0–30: Onboard (provare valore velocemente)
Scegli 1–2 servizi critici e un percorso cliente. Instrumenta log, metriche e tracce in modo coerente e connetti le integrazioni già in uso (cloud, Kubernetes, CI/CD, on-call).
Giorni 31–60: Standardizza (rendilo ripetibile)
Trasforma l'apprendimento in default: naming dei servizi, tagging, template di dashboard, naming dei monitor e ownership. Crea viste “golden signals” (latenza, traffico, errori, saturazione) e un set minimo di SLO per gli endpoint più importanti.
Giorni 61–90: Scala (espandi senza caos)
Onboarda team aggiuntivi usando gli stessi template. Introduci governance (regole di tag, metadata richiesti, processo di revisione per nuovi monitor) e inizia a tracciare costo vs utilizzo così la piattaforma resta sana.
Dove si inserisce Koder.ai (pragmaticamente)
Quando tratti l'osservabilità come piattaforma, spesso desidererai piccole app “colla”: un'interfaccia catalogo servizi, un hub di runbook, una pagina timeline degli incidenti o un portale interno che colleghi owner → dashboard → SLO → playbook.
Questo è il tipo di tooling interno leggero che puoi costruire rapidamente con Koder.ai—una piattaforma vibe-coding che genera app via chat (comunemente React frontend, Go + PostgreSQL backend), con esportazione codice sorgente e supporto per deploy/hosting. In pratica, i team la usano per prototipare e spedire superfici operative che facilitano governance e workflow senza distogliere un intero team prodotto dalla roadmap.
Vittorie rapide da lanciare nella prima settimana
- Top 10 monitor per disponibilità, tasso di errori, latenza, saturazione e dipendenze chiave\n- Marker di deploy (dal CI/CD) su dashboard e trace per correlazione immediata dei cambiamenti\n- Template incidente: cosa è successo, impatto, timeline, owner, link a dashboard/query, azioni successive
Esegui due sessioni da 45 minuti: (1) “Come facciamo query qui” con pattern di query condivisi (per service, env, regione, versione), e (2) “Playbook di troubleshooting” con un flow semplice: conferma impatto → controlla marker di deploy → restringi al servizio → ispeziona tracce → conferma salute delle dipendenze → decidi rollback/mitigazione.
Checklist copy/paste