Perché Patterson e il pensiero RISC contano ancora
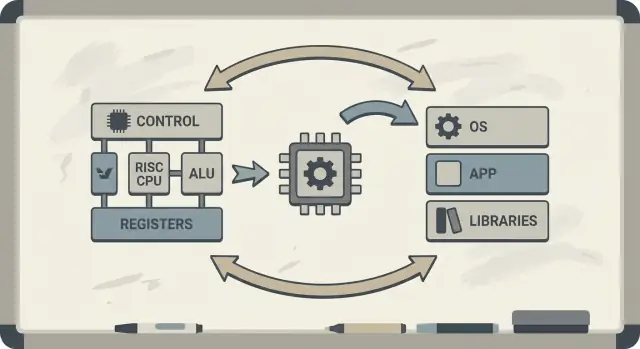
David Patterson viene spesso presentato come “un pioniere del RISC”, ma la sua influenza duratura è più ampia di un singolo design di CPU. Ha contribuito a rendere popolare un modo pratico di pensare ai computer: trattare le prestazioni come qualcosa che si può misurare, semplificare e migliorare end-to-end — dalle istruzioni che un chip comprende fino agli strumenti software che generano quelle istruzioni.
“RISC thinking” in parole semplici
RISC (Reduced Instruction Set Computing) è l'idea che un processore può funzionare più velocemente e in modo più prevedibile quando si concentra su un set ridotto di istruzioni semplici. Invece di costruire in hardware un enorme menu di operazioni complesse, si rendono le operazioni comuni veloci, regolari e facili da pipelinare. Il risultato non è “meno capacità”, ma che mattoni semplici, eseguiti in modo efficiente, spesso vincono nei carichi reali di lavoro.
Co-design: chip e codice che si migliorano a vicenda
Patterson ha anche sostenuto la co-progettazione hardware–software: un circuito di feedback in cui architetti di chip, autori di compilatori e progettisti di sistemi iterano insieme.
Se un processore è progettato per eseguire bene pattern semplici, i compilatori possono produrre quelle sequenze in modo affidabile. Se i compilatori mostrano che i programmi reali passano tempo in certe operazioni (come l’accesso alla memoria), l’hardware può essere aggiustato per gestire meglio quei casi. Per questo le discussioni sull’ISA si collegano naturalmente alle ottimizzazioni del compilatore, alla cache e al pipelining.
Cosa otterrai leggendo questo articolo
Capirai perché le idee RISC si collegano alle prestazioni per watt (non solo alla velocità grezza), come la “predicibilità” rende le CPU moderne e i chip mobili più efficienti, e come questi principi emergono nei dispositivi di oggi — dai laptop ai server cloud.
Se vuoi una mappa dei concetti chiave prima di approfondire, vai a /blog/key-takeaways-and-next-steps.
Il problema a cui rispondeva RISC
I primi microprocessori furono costruiti con vincoli stringenti: i chip avevano poco spazio per circuiteria, la memoria era costosa e lo storage era lento. I progettisti cercavano di spedire computer che fossero economici e “abbastanza veloci”, spesso con cache piccole (o assenti), frequenze di clock modeste e memoria principale molto limitata rispetto a ciò che il software desiderava.
La vecchia scommessa: istruzioni complesse = programmi più veloci
Un'idea popolare all’epoca era che se la CPU offriva istruzioni di alto livello più potenti — in grado di fare più passaggi in una volta — i programmi avrebbero girato più velocemente e sarebbero stati più facili da scrivere. Se un’istruzione poteva “fare il lavoro di più istruzioni”, si pensava che servissero meno istruzioni complessive, risparmiando tempo e memoria.
Questa intuizione sta alla base di molti design CISC (complex instruction set computing): dare a programmatori e compilatori una grande cassetta degli attrezzi di operazioni sofisticate.
Il disallineamento: cosa offrivano le CPU vs cosa veniva usato
Il problema era che i programmi reali (e i compilatori che li traducevano) non sfruttavano costantemente quella complessità. Molte delle istruzioni più elaborate venivano usate raramente, mentre un piccolo insieme di operazioni semplici — caricare dati, memorizzare dati, sommare, confrontare, saltare — compariva di continuo.
Nel frattempo, supportare un enorme menu di istruzioni complesse rendeva le CPU più difficili da costruire e meno facili da ottimizzare. La complessità consumava area del chip e sforzi di progettazione che avrebbero potuto essere impiegati per rendere le operazioni comuni veloci e prevedibili.
RISC fu una risposta a quel divario: concentra la CPU su ciò che il software fa davvero la maggior parte del tempo e rendi quei percorsi veloci — poi lascia che i compilatori facciano più del “lavoro di orchestrazione” in modo sistematico.
RISC vs CISC: l’idea in parole semplici
Un modo semplice per pensare a CISC vs RISC è confrontare i set di attrezzi.
CISC (Complex Instruction Set Computing) è come una bottega piena di strumenti specializzati e sofisticati — ognuno può fare molto in un solo colpo. Una singola “istruzione” potrebbe caricare dati dalla memoria, fare un calcolo e memorizzare il risultato, tutto insieme.
RISC (Reduced Instruction Set Computing) è come portare un set più piccolo di strumenti affidabili che usi costantemente — martello, cacciavite, metro — e costruire tutto con passaggi ripetibili. Ogni istruzione tende a fare un lavoro piccolo e chiaro.
Perché “più semplice” può essere più veloce
Quando le istruzioni sono più semplici e uniformi, la CPU può eseguirle con una catena di montaggio più pulita (una pipeline). Quella catena è più facile da progettare, più facile da far funzionare a frequenze più alte e più semplice da mantenere piena di lavoro.
Con istruzioni in stile CISC “che fanno molto”, la CPU spesso deve decodificare e scomporre l’istruzione complessa in passi interni più piccoli comunque. Questo può aggiungere complessità e rendere più difficile mantenere la pipeline fluida.
La predicibilità conta
RISC punta a una tempistica prevedibile delle istruzioni — molte istruzioni richiedono all’incirca lo stesso tempo. La predicibilità aiuta la CPU a schedulare il lavoro efficacemente e aiuta i compilatori a generare codice che mantenga la pipeline piena e non in stallo.
I compromessi (e perché spesso valgono la pena)
RISC richiede di solito più istruzioni per svolgere lo stesso compito. Questo può significare:
- Dimensione del programma leggermente maggiore (più byte di codice)
- Più fetch di istruzioni dalla memoria
Ma può comunque essere vantaggioso se ogni istruzione è veloce, la pipeline resta regolare e il design complessivo è più semplice.
Nella pratica, compilatori ben ottimizzati e una buona cache possono compensare lo svantaggio delle “più istruzioni” — e la CPU può spendere più tempo a fare lavoro utile e meno tempo a sbrogliare istruzioni complicate.
Berkeley RISC e la mentalità “misura, poi progetta”
Berkeley RISC non era solo un nuovo set di istruzioni. Era un atteggiamento di ricerca: non partire da ciò che sembra elegante sulla carta — parti da ciò che i programmi fanno realmente e poi modella la CPU attorno a quella realtà.
Core piccolo e veloce + compilatore intelligente
A livello concettuale, il team di Berkeley mirava a un core di CPU abbastanza semplice da funzionare molto rapidamente e in modo prevedibile. Invece di riempire l’hardware di “trucchetti” istruzionali complicati, si affidavano al compilatore per fare più lavoro: scegliere istruzioni semplici, schedularle bene e mantenere i dati nei registri il più possibile.
Questa divisione del lavoro contava. Un core più piccolo e pulito è più facile da pipelinare efficacemente, più facile da comprendere e spesso più veloce per transistor. Il compilatore, che vede l’intero programma, può pianificare avanti in modi che l’hardware non può fare facilmente al volo.
Misura carichi reali, non supposizioni
David Patterson enfatizzava la misurazione perché la progettazione dei computer è piena di miti allettanti — caratteristiche che suonano utili ma che raramente emergono nel codice reale. Berkeley RISC spingeva a usare benchmark e tracce di workload per trovare i percorsi caldi: loop, chiamate di funzione e accessi alla memoria che dominano il tempo di esecuzione.
Questo si collega direttamente al principio “rendere il caso comune veloce”. Se la maggior parte delle istruzioni sono operazioni semplici e load/store, allora ottimizzare quei casi frequenti ripaga più che accelerare istruzioni complesse e rare.
RISC come modo di pensare
La lezione duratura è che RISC è stato sia un’architettura sia una mentalità: semplifica ciò che è frequente, valida con i dati e tratta hardware e software come un unico sistema che può essere sintonizzato insieme.
Cosa significa co-progettazione hardware–software
La co-progettazione hardware–software è l’idea che non progetti una CPU in isolamento. Progetti il chip e il compilatore (e talvolta il sistema operativo) tenendo conto l’uno dell’altro, così che i programmi reali girino veloci ed efficienti — non solo sequenze di istruzioni sintetiche “best case”.
Un semplice loop di feedback
La co-progettazione funziona come un ciclo ingegneristico:
-
Scelte di ISA: l’ISA decide cosa la CPU può esprimere facilmente (per esempio, accesso memoria “load/store”, molti registri, modalità di indirizzamento semplici).
-
Strategie del compilatore: il compilatore si adatta — mantiene variabili calde nei registri, riordina le istruzioni per evitare stall e sceglie convenzioni di chiamata che riducono l’overhead.
-
Risultati sul workload: misuri programmi reali (compilatori, database, grafica, codice OS) e vedi dove vanno tempo ed energia.
-
Prossimo design: regoli l’ISA e la microarchitettura (profondità di pipeline, numero di registri, dimensioni delle cache) sulla base di quelle misurazioni.
Ecco un piccolo loop (C) che evidenzia il rapporto:
for (int i = 0; i < n; i++)
sum += a[i];
Su un ISA in stile RISC, il compilatore tipicamente mantiene sum e i nei registri, usa semplici istruzioni di load per a[i] e applica instruction scheduling in modo che la CPU resti occupata mentre un load è in volo.
Perché ignorare il compilatore spreca silicio ed energia
Se un chip aggiunge istruzioni complesse o hardware speciale che i compilatori usano raramente, quell’area consuma comunque potenza e sforzo di progettazione. Nel frattempo, le cose “noiose” su cui i compilatori contano — abbastanza registri, pipeline prevedibili, convenzioni di chiamata efficienti — potrebbero essere sottofinanziate.
Il pensiero RISC di Patterson enfatizzava spendere silicio dove il software reale può davvero beneficiare.
Pipeline, predicibilità e aiuto del compilatore
Sviluppa più velocemente con la pianificazione
Crea un'app web React e iterala rapidamente con la modalità di pianificazione in Koder.ai.
Un’idea chiave del RISC era rendere la “linea di montaggio” della CPU più facile da mantenere occupata. Quella linea è la pipeline: invece di finire completamente un’istruzione prima di iniziarne un’altra, il processore scompone il lavoro in stadi (fetch, decode, execute, write-back) e li sovrappone. Quando tutto scorre, completi vicino a un’istruzione per ciclo — come auto che attraversano una fabbrica a più stazioni.
Perché istruzioni più semplici mantengono la linea in movimento
Le pipeline funzionano meglio quando ogni elemento della linea è simile. Le istruzioni RISC sono progettate per essere relativamente uniformi e prevedibili (spesso di lunghezza fissa, con indirizzamento semplice). Questo riduce i “casi speciali” dove un’istruzione richiede tempo extra o risorse inusuali.
Quando la pipeline deve fermarsi: hazard e stall
I programmi reali non sono perfettamente regolari. A volte un’istruzione dipende dal risultato di una precedente (non puoi usare un valore prima che sia calcolato). Altre volte, la CPU deve aspettare dati dalla memoria o non sa ancora quale percorso prenderà un branch.
Queste situazioni provocano stall — pause brevi dove parte della pipeline resta inattiva. L’intuizione è semplice: gli stall succedono quando lo stadio successivo non può fare lavoro utile perché qualcosa che gli serve non è ancora arrivato.
Il compilatore come controllore del traffico
Qui la co-progettazione hardware–software emerge chiaramente. Se l’hardware è prevedibile, il compilatore può aiutare riordinando le istruzioni (senza cambiare il significato del programma) per riempire i “buchi”. Per esempio, mentre si aspetta che un valore venga prodotto, il compilatore può schedulare un’istruzione indipendente che non dipende da quel valore.
Il rendimento è una responsabilità condivisa: la CPU resta più semplice e veloce nel caso comune, mentre il compilatore fa più pianificazione. Insieme riducono gli stall e aumentano la throughput — spesso migliorando le prestazioni reali senza necessità di un ISA più complesso.
Cache e la memory wall: dove la co-progettazione paga
Una CPU può eseguire operazioni semplici in pochi cicli, ma prelevare dati dalla memoria principale (DRAM) può richiedere centinaia di cicli. Quel divario esiste perché la DRAM è fisicamente più lontana, ottimizzata per capacità e costo, e limitata sia in latenza (quanto impiega una singola richiesta) sia in banda (quanti byte al secondo puoi muovere).
Man mano che le CPU diventavano più veloci, la memoria non teneva lo stesso passo — questo divario crescente è spesso chiamato memory wall.
Cache e località
Le cache sono memorie piccole e veloci poste vicino alla CPU per evitare di pagare il costo della DRAM a ogni accesso. Funzionano perché i programmi reali hanno località:
- Località temporale: se hai usato un valore o un’istruzione di recente, è probabile che lo userai ancora a breve.
- Località spaziale: se hai letto un indirizzo, è probabile che leggerai indirizzi vicini.
I chip moderni impilano cache (L1, L2, L3) cercando di mantenere il “working set” di codice e dati vicino al core.
Dove ISA e compilatori influenzano il comportamento della cache
Qui la co-progettazione hardware–software dà i suoi frutti. L’ISA e il compilatore insieme modellano quanta pressione sulla cache crea un programma.
- La dimensione del codice conta. Binaries più grandi e sequenze di istruzioni più pesanti possono saturare la cache delle istruzioni, causando stall. Scelte di ISA che migliorano la densità del codice (per esempio, istruzioni compresse opzionali) possono aumentare i tassi di hit nella instruction cache.
- I pattern di accesso contano. Il design load/store in stile RISC rende gli accessi memoria espliciti. I compilatori possono schedulare i load prima, mantenere i valori caldi più a lungo nei registri e ridurre il traffico memoria inutile.
- Layout e blocking. Ottimizzazioni del compilatore come loop tiling (blocking), riordino di strutture dati e prefetching cercano di trasformare “viaggi casuali alla DRAM” in hit prevedibili nella cache.
La memory wall nelle prestazioni reali
In termini pratici, la memory wall spiega perché una CPU con alta frequenza di clock può comunque sembrare lenta: aprire un’app grande, eseguire una query di database, scorrere un feed o processare un grosso dataset spesso è vincolato da miss di cache e banda di memoria — non dalla pura velocità aritmetica.
Efficienza: prestazioni per watt, non solo velocità grezza
Accelera i cicli di iterazione
Accorcia il ciclo build-measure con iterazioni più veloci e maggiore capacità in Koder.ai.
Per molto tempo le discussioni sulle CPU suonavano come una corsa: quale chip termina un compito più veloce “vince”. Ma i computer reali vivono dentro limiti fisici — capacità della batteria, calore, rumore delle ventole e bollette dell’elettricità.
Per questo prestazioni per watt è diventata una metrica centrale: quanto lavoro utile ottieni per l’energia spesa.
Cosa significa davvero “prestazioni per watt”
Pensalo come efficienza, non come forza massima. Due processori possono sembrare simili nell’uso quotidiano, eppure uno può farlo consumando meno energia, rimanendo più fresco e durando più a lungo con la stessa batteria.
Nei laptop e negli smartphone questo incide direttamente sulla durata della batteria e sul comfort. Nei data center influisce sul costo di alimentare e raffreddare migliaia di macchine, oltre a quanto densamente puoi impilare i server senza surriscaldarli.
Perché i core più semplici spesso sprecano meno energia
Il pensiero RISC ha spinto il design delle CPU verso l’esecuzione di meno funzioni in hardware, in modo più prevedibile. Un core più semplice può ridurre il consumo energetico in vari modi:
- Logica di controllo meno complessa significa meno parti interne che commutano ogni ciclo.
- Esecuzione più prevedibile rende più facile mantenere la pipeline piena senza costose operazioni di recupero.
- Design favorevole ai compilatori permette al software di schedulare il lavoro efficientemente, evitando che l’hardware faccia lavoro extra inutile.
Non si dice che “semplice è sempre meglio”. Si dice che la complessità ha un costo energetico, e un ISA e una microarchitettura ben scelti possono scambiare un po’ di astuzia per molta efficienza.
Mobile e server convergono sullo stesso obiettivo
I telefoni si preoccupano di batteria e calore; i server si preoccupano di alimentazione e raffreddamento. Ambienti diversi, stessa lezione: il chip più veloce non è sempre il miglior computer. Spesso vincono i design che offrono throughput costante mantenendo il consumo energetico sotto controllo.
Cosa RISC ha fatto bene — e cosa è più complicato
RISC è spesso riassunto come “istruzioni più semplici vincono”, ma la lezione più duratura è più sottile: l’ISA conta, ma molti guadagni reali venivano da come i chip venivano costruiti, non solo da come l’ISA appariva sulla carta.
Il dibattito “l’ISA conta”
Gli argomenti iniziali del RISC implicavano che un ISA più pulito e piccolo avrebbe automaticamente reso i computer più veloci. Nella pratica, i maggiori incrementi di velocità spesso derivarono dalle scelte di implementazione rese più semplici dal RISC: decodifica più semplice, pipelining più profondo, clock più alti e compilatori capaci di schedulare il lavoro in modo prevedibile.
Ecco perché due CPU con ISA diverse possono finire sorprendentemente vicine in prestazioni se la microarchitettura, le dimensioni delle cache, la predizione dei branch e il processo di fabbricazione differiscono. L’ISA stabilisce le regole; la microarchitettura gioca la partita.
La misurazione batte le liste di caratteristiche
Un cambiamento chiave dell’era Patterson fu progettare dai dati, non dalle supposizioni. Invece di aggiungere istruzioni perché sembravano utili, i team misuravano cosa facevano realmente i programmi e poi ottimizzavano il caso comune.
Quella mentalità spesso superava i design “guidati dalle feature”, dove la complessità cresce più in fretta dei benefici. Inoltre rende i compromessi più chiari: un’istruzione che salva poche righe di codice può costare cicli extra, potenza o area del chip — e quei costi si vedono ovunque.
Non è una storia “vincitore prende tutto”
Il pensiero RISC non ha plasmato solo “chip RISC”. Col tempo, molte CPU CISC hanno adottato tecniche interne in stile RISC (per esempio scomponendo istruzioni complesse in operazioni interne più semplici) pur mantenendo le loro ISA compatibili.
Quindi l’esito non fu “RISC ha battuto CISC”. Fu un’evoluzione verso design che valorizzano misurazione, predicibilità e stretta coordinazione hardware–software — indipendentemente dal logo sull’ISA.
Da MIPS a RISC-V: un filo continuo
RISC non è rimasto nel laboratorio. Una delle linee più chiare dalla ricerca al pratico va da MIPS a RISC-V — due ISA che hanno fatto della semplicità e della chiarezza una caratteristica, non un vincolo.
MIPS: l’ISA pulita che si poteva costruire (e imparare)
MIPS è spesso ricordata come un’ISA didattica, e per buone ragioni: le regole sono facili da spiegare, i formati delle istruzioni sono coerenti e il modello load/store lascia il compilatore libero di agire.
Quella pulizia non era solo accademica. I processori MIPS sono stati commercializzati in prodotti reali per anni (dalle workstation ai sistemi embedded), anche perché un’ISA semplice rendeva più facile costruire pipeline veloci, compilatori prevedibili e toolchain efficienti. Quando il comportamento hardware è regolare, il software può pianificare intorno a esso.
RISC-V: aperto, pratico e amico della co-progettazione
RISC-V ha rinnovato l’interesse per il pensiero RISC facendo un passo chiave che MIPS non fece: è un’ISA aperta. Questo cambia gli incentivi. Università, startup e grandi aziende possono sperimentare, spedire silicio e condividere gli strumenti senza negoziare l’accesso all’insieme di istruzioni.
Per la co-progettazione, quell’apertura conta perché il lato software (compilatori, sistemi operativi, runtime) può evolvere pubblicamente insieme all’hardware, con meno barriere artificiali.
Estensioni modulari: aggiungi ciò che serve, quando serve
Un altro motivo per cui RISC-V si sposa bene con la co-progettazione è il suo approccio modulare. Si parte da una piccola ISA di base e si aggiungono estensioni per necessità specifiche — come la matematica vettoriale, vincoli embedded o funzionalità di sicurezza.
Questo incoraggia un trade-off più sano: invece di infilare ogni possibile feature in un design monolitico, i team possono allineare le feature hardware col software che effettivamente eseguono.
Se vuoi un primer più approfondito, vedi /blog/what-is-risc-v.
Cambia in sicurezza con gli snapshot
Sperimenta liberamente e torna indietro quando una modifica peggiora prestazioni o stabilità.
La co-progettazione non è una nota storica dell’era RISC — è il modo in cui l’informatica moderna continua a diventare più veloce ed efficiente. L’idea chiave è sempre alla Patterson: non “vinci” solo con l’hardware o solo con il software. Vinci quando i due si adattano ai punti di forza e ai vincoli reciproci.
Il pensiero RISC nei dispositivi che usi ogni giorno
Smartphone e molti dispositivi embedded si basano fortemente su principi RISC (spesso ARM): istruzioni più semplici, esecuzione prevedibile ed enfasi sull’uso dell’energia.
Quella predicibilità aiuta i compilatori a generare codice efficiente e ai progettisti a costruire core che consumano poco mentre scorri, ma che possono scattare per una pipeline di fotocamera o un gioco.
Laptop e server perseguono sempre più lo stesso obiettivo — soprattutto la prestazione per watt. Anche quando l’ISA non è tradizionalmente “RISC”, molte scelte di design interne mirano all’efficienza in stile RISC: pipelining profondo, esecuzione ampia e gestione energetica aggressiva tarata sul comportamento del software reale.
Gli acceleratori sono co-progettazione in azione
GPU, accelerator AI (TPU/NPUs) e motori multimediali sono una forma pratica di co-progettazione: invece di forzare tutto il lavoro attraverso una CPU general-purpose, la piattaforma fornisce hardware che corrisponde ai pattern di calcolo comuni.
Ciò che rende questo co-design (non solo “hardware extra”) è lo stack software che lo circonda:
- Le GPU ottengono velocità da modelli di programmazione come CUDA e dalle API come Vulkan/Metal.
- Gli accelerator AI dipendono da compilatori e ottimizzatori di grafi che trasformano un modello nelle operazioni preferite dal chip.
- Encoder/decoder video ripagano perché OS, browser e app sono scritti per usarli.
Se il software non prende di mira l’acceleratore, la velocità teorica resta teorica.
Gli stack software fanno parte delle prestazioni
Due piattaforme con specifiche simili possono sembrare molto diverse perché il “prodotto reale” include compilatori, librerie e framework. Una libreria matematica ben ottimizzata (BLAS), un buon JIT o un compilatore più intelligente possono produrre grandi guadagni senza cambiare il chip.
Per questo il design delle CPU moderne è spesso guidato da benchmark: i team hardware osservano cosa fanno compilatori e workload, poi regolano feature (cache, predizione dei branch, istruzioni vettoriali, prefetching) per velocizzare il caso comune.
Una checklist rapida: cosa osservare
Quando valuti una piattaforma (telefono, laptop, server o scheda embedded), cerca segnali di co-progettazione:
- Match del workload: le tue app sono bound dalla CPU, dalla GPU, dalla memoria o favoriscono gli acceleratori?
- Disponibilità di acceleratori: c’è un NPU/GPU/motore multimediale — e i tuoi strumenti lo usano davvero?
- Maturità di compilatore/toolchain: ci sono build ottimizzate, buoni strumenti di profilazione e supporto attivo?
- Ecosistema di librerie: le librerie core (math, vision, crypto) sono ottimizzate per quell’hardware?
- Comportamento energetico: ottieni prestazioni sostenute entro i limiti termici/di potenza?
Il progresso informatico moderno riguarda meno una singola “CPU più veloce” e più un intero sistema hardware+software che è stato modellato — misurato, poi progettato — attorno a workload reali.
Punti chiave e passi pratici successivi
Il pensiero RISC e il messaggio più ampio di Patterson si possono sintetizzare in poche lezioni durature: semplifica ciò che deve essere veloce, misura ciò che succede realmente e tratta hardware e software come un unico sistema — perché gli utenti sperimentano il tutto, non i singoli componenti.
Le lezioni da tenere
Prima, la semplicità è una strategia, non un’estetica. Un’ISA pulita e un’esecuzione prevedibile rendono più facile per i compilatori generare buon codice e per le CPU eseguirlo efficientemente.
Secondo, la misurazione batte l’intuizione. Usa benchmark con workload rappresentativi, raccogli dati di profiling e lascia che i colli di bottiglia reali guidino le decisioni di design — che tu stia ottimizzando il compilatore, scegliendo una SKU di CPU o riprogettando un percorso critico.
Terzo, la co-progettazione è dove i guadagni si sommano. Codice pipeline-friendly, strutture dati cache-aware e obiettivi realistici di prestazione-per-watt spesso danno più velocità pratica che inseguire il rendimento teorico di picco.
Passi pratici per i team di prodotto
Se stai selezionando una piattaforma (x86, ARM o sistemi basati su RISC-V), valutala come faranno i tuoi utenti:
- Esegui benchmark end-to-end (tempo di avvio, throughput in regime, latenza di coda), non solo microbenchmark.
- Monitora metriche di efficienza (watt, termiche, impatto sulla batteria) insieme alle prestazioni.
- Itera: profila → cambia una cosa → misura di nuovo. Piccoli passi convalidati si sommano.
Se parte del tuo lavoro è trasformare queste misurazioni in software distribuito, può aiutare accorciare il ciclo build–measure. Per esempio, i team usano Koder.ai per prototipare ed evolvere applicazioni reali tramite un workflow guidato da chat (web, backend e mobile), quindi rieseguire gli stessi benchmark end-to-end dopo ogni modifica. Funzionalità come la modalità pianificazione, snapshot e rollback supportano la stessa disciplina “misura, poi progetta” che Patterson promuoveva — applicata allo sviluppo prodotto moderno.
Per un primer più approfondito sull’efficienza, vedi /blog/performance-per-watt-basics. Se stai confrontando ambienti e ti serve un modo semplice per stimare i compromessi costo/prestazioni, guarda /pricing.
La lezione duratura: le idee — semplicità, misurazione e co-progettazione — continuano a ripagare, anche mentre le implementazioni evolvono dalle pipeline dell’era MIPS a core eterogenei moderni e nuovi ISA come RISC-V.