Perché le scelte iniziali di Joe Beda su Kubernetes contano ancora
Joe Beda è stato uno dei protagonisti del disegno iniziale di Kubernetes—insieme ad altri fondatori che hanno portato in campo le lezioni dai sistemi interni di Google verso una piattaforma aperta. La sua influenza non è stata inseguire feature alla moda; è stata scegliere primitive semplici che potessero resistere al caos della produzione e restare comprensibili per team quotidiani.
Quelle decisioni iniziali sono il motivo per cui Kubernetes è diventato più di “uno strumento per container”. È diventato un kernel riutilizzabile per le piattaforme moderne di applicazioni.
Orchestrazione dei container, in parole semplici
“Orchestrazione dei container” è l'insieme di regole e automazioni che mantiene la tua app in esecuzione quando le macchine falliscono, il traffico aumenta o distribuisci una nuova versione. Invece di avere una persona che sorveglia i server, il sistema programma i container sui computer, li riavvia quando crashano, li distribuisce per la resilienza e mette in piedi la rete così che gli utenti possano raggiungerli.
Il caos prima di Kubernetes
Prima che Kubernetes diventasse comune, i team spesso cucivano insieme script e strumenti custom per rispondere a domande di base:
- Dove deve girare questo container in questo momento?
- Cosa succede se un nodo muore alle 2 di notte?
- Come distribuiamo in sicurezza senza downtime?
- Come si trovano i servizi quando gli IP cambiano continuamente?
Quei sistemi fai-da-te funzionavano—finché non smettevano. Ogni nuova app o team aggiungeva logiche one-off, e la consistenza operativa era difficile da ottenere.
Cosa tratta questo articolo
Questo articolo passa in rassegna le scelte progettuali iniziali di Kubernetes (la “forma” di Kubernetes) e perché influenzano ancora le piattaforme moderne: il modello dichiarativo, i controller, i Pod, le label, i Service, un'API forte, uno stato di cluster coerente, uno scheduling pluggabile e l'estensibilità. Anche se non stai eseguendo Kubernetes direttamente, è probabile che tu stia usando una piattaforma costruita su queste idee—o che tu stia lottando con gli stessi problemi.
Il problema che Kubernetes voleva risolvere
Prima di Kubernetes, “eseguire container” significava spesso eseguirne pochi. I team mettevano insieme bash script, cron job, golden image e una manciata di strumenti ad-hoc per ottenere deploy. Quando qualcosa si rompeva, la soluzione spesso viveva nella testa di qualcuno—o in un README di cui nessuno si fidava. Le operazioni erano una serie di interventi one-off: riavviare processi, ricollegare load balancer, pulire disco e indovinare quale macchina fosse sicura da toccare.
I container su scala crearono nuovi modi di guasto
I container hanno reso il packaging più semplice, ma non hanno eliminato le parti messy della produzione. A scala, il sistema fallisce in più modi e più spesso: i nodi scompaiono, le reti si partizionano, le immagini vengono distribuite in modo incoerente e i workload differiscono da ciò che pensi stia girando. Un deploy “semplice” può trasformarsi in una cascata—alcune istanze aggiornate, altre no, alcune bloccate, altre sane ma irraggiungibili.
Il vero problema non era avviare container. Era mantenere i container giusti in esecuzione, nella forma corretta, nonostante il continuo cambiamento.
Un modello coerente attraverso le infrastrutture
I team dovevano anche gestire ambienti diversi: hardware on‑prem, VM, primi cloud provider e varie configurazioni di rete e storage. Ogni piattaforma aveva il suo vocabolario e i suoi pattern di guasto. Senza un modello condiviso, ogni migrazione significava riscrivere gli strumenti operativi e riqualificare le persone.
Kubernetes si propose di offrire un modo unico e coerente per descrivere le applicazioni e i loro bisogni operativi, indipendentemente da dove risiedessero le macchine.
Gli sviluppatori volevano self-service: deploy senza ticket, scalare senza chiedere capacità e rollback senza drammi. I team di ops volevano prevedibilità: health check standardizzati, deploy ripetibili e una fonte di verità chiara su cosa dovesse girare.
Kubernetes non cercava di essere solo un scheduler raffinato. Puntava a essere la base per una piattaforma applicativa affidabile—che trasformasse la realtà caotica in un sistema ragionevole.
Decisione 1: un modello dichiarativo di stato desiderato
Una delle scelte più influenti fu rendere Kubernetes dichiarativo: descrivi ciò che vuoi e il sistema lavora per far corrispondere la realtà a quella descrizione.
Stato desiderato, spiegato con un termostato
Un termostato è un esempio quotidiano utile. Non accendi e spegni manualmente il riscaldamento ogni pochi minuti. Imposti la temperatura desiderata—per esempio 21°C—e il termostato controlla la stanza e regola il riscaldamento per restare vicino a quell'obiettivo.
Kubernetes funziona allo stesso modo. Invece di dire al cluster, passo dopo passo, “avvia questo container su quella macchina, poi riavvialo se fallisce,” dichiari il risultato: “voglio 3 copie di questa app in esecuzione.” Kubernetes controlla continuamente cosa è effettivamente in esecuzione e corregge lo scostamento.
Meno passaggi manuali, meno sorprese
La configurazione dichiarativa riduce la checklist operativa nascosta che spesso vive nella testa di qualcuno o in un runbook parzialmente aggiornato. Applichi la config e Kubernetes si occupa della meccanica—posizionamento, riavvii e riconciliazione delle modifiche.
Rende anche più facile la revisione delle modifiche. Un cambiamento è visibile come un diff nella configurazione, non come una serie di comandi ad-hoc.
Ripetibilità tra ambienti
Poiché lo stato desiderato è scritto, puoi riutilizzare lo stesso approccio in dev, staging e produzione. L'ambiente può differire, ma l'intento resta coerente, il che rende i deploy più prevedibili e più semplici da verificare.
I compromessi
I sistemi dichiarativi hanno una curva di apprendimento: bisogna pensare in termini di “cosa dovrebbe essere vero” invece che “cosa faccio dopo”. Dipendono anche da buoni default e convenzioni chiare—senza di esse, i team possono produrre configurazioni che funzionano tecnicamente ma sono difficili da capire e mantenere.
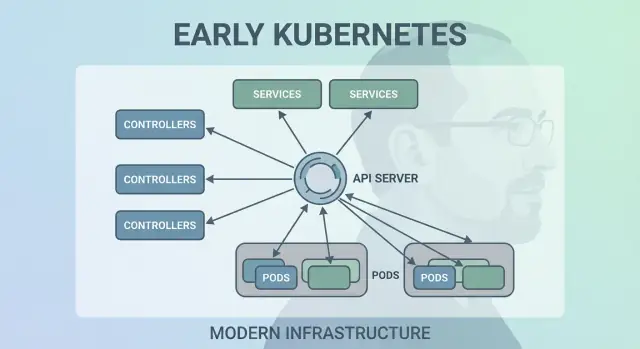
Decisione 2: i control loop (controller) come motore
Kubernetes non ha avuto successo perché poteva avviare container una sola volta—ha avuto successo perché poteva mantenerli correttamente nel tempo. La grande mossa progettuale fu usare i “control loop” (controller) come motore principale del sistema.
Cos'è un controller
Un controller è un ciclo semplice:
- Osserva lo stato corrente (cosa sta realmente girando)
- Lo confronta con lo stato desiderato (ciò che hai richiesto)
- Agisce finché i due non coincidono
È meno un compito eseguito una volta e più un pilota automatico. Non "babysitti" i workload; dichiari ciò che vuoi e i controller continuano a ricondurre il cluster verso quell'esito.
Gestire crash, perdita di nodi e drift
Questo pattern è il motivo per cui Kubernetes è resiliente quando le cose reali vanno storte:
- Crash dei container: il controller nota meno istanze in esecuzione del desiderato e avvia i rimpiazzi.
- Perdita di nodi: quando un nodo scompare, i controller riprogrammano i pod altrove per ripristinare il numero desiderato.
- Drift di configurazione: se qualcuno modifica o elimina risorse, i controller riconciliano la differenza e la correggono.
Invece di trattare i guasti come casi speciali, i controller li trattano come semplici “disallineamenti di stato” e li risolvono nello stesso modo ogni volta.
Perché scala meglio degli script
Gli script di automazione tradizionali spesso presumono un ambiente stabile: esegui passo A, poi B, poi C. Nei sistemi distribuiti, quelle assunzioni si rompono continuamente. I controller scalano meglio perché sono idempotenti (sicuri da rieseguire) e eventualmente consistenti (continuano a provare finché l'obiettivo non è raggiunto).
Esempi quotidiani: Deployments e ReplicaSets
Se hai usato un Deployment, hai usato control loop. Sotto il cofano, Kubernetes usa un controller di ReplicaSet per assicurarsi che il numero richiesto di pod esista—e un controller di Deployment per gestire update rolling e rollback in modo prevedibile.
Decisione 3: i Pod come unità atomica di scheduling
Kubernetes avrebbe potuto schedulare “solo container”, ma il team di Joe Beda introdusse i Pod per rappresentare l'unità più piccola distribuibile che il cluster mette su una macchina. L'idea chiave: molte applicazioni reali non sono un singolo processo. Sono un piccolo gruppo di processi strettamente accoppiati che devono vivere insieme.
Perché i Pod invece dei container singoli?
Un Pod è un involucro attorno a uno o più container che condividono la stessa sorte: partono insieme, girano sullo stesso nodo e scalano insieme. Questo rende naturali pattern come i sidecar—pensa a un log shipper, a un proxy, a un reload di configurazione o a un agente di sicurezza che deve sempre accompagnare l'app principale.
Invece di insegnare ad ogni app a integrare quegli helper, Kubernetes ti permette di pacchettarli come container separati che però si comportano come un'unità.
Cosa hanno reso possibili i Pod per rete e storage
I Pod hanno reso pratiche due assunzioni importanti:
- Networking: i container in un Pod condividono un'identità di rete (un IP e uno spazio di porte). L'app principale può parlare con il sidecar su
localhost, semplice e veloce.
- Storage: i container in un Pod possono condividere volumi. Un helper può scrivere file che l'app legge (o viceversa), senza salti esterni scomodi.
Queste scelte hanno ridotto la necessità di codice glue custom, mantenendo comunque l'isolamento dei container a livello di processo.
Dove i Pod confondono i nuovi arrivati
I nuovi utenti spesso si aspettano “un container = un'app”, poi si inciampano nei concetti a livello di Pod: riavvii, IP e scaling. Molte piattaforme semplificano questo offrendo template opinionati (per esempio “web service”, “worker” o “job”) che generano Pod dietro le quinte—così i team beneficiano di sidecar e risorse condivise senza pensare ogni giorno ai dettagli dei Pod.
Decisione 4: label e selector per un accoppiamento lasco
Make it feel like a real product
Put your app on a custom domain when it is ready for teammates or users.
Una scelta iniziale silenziosamente potente in Kubernetes fu trattare le label come metadati di prima classe e i selector come il modo principale per “trovare” le cose. Invece di collegamenti rigidi (tipo “queste tre macchine eseguono la mia app”), Kubernetes incoraggia a descrivere gruppi tramite attributi condivisi.
Label: tag flessibili su tutto
Una label è una semplice coppia chiave/valore che alleghi alle risorse—Pods, Deployments, Nodes, Namespaces e altro. Agiscono come tag interrogabili e coerenti:
app=checkoutenv=prodtier=frontend
Essendo leggere e definite dall'utente, puoi modellare la realtà della tua organizzazione: team, centri di costo, zone di compliance, canali di release o qualunque cosa sia importante per le tue operazioni.
Selector: relazioni senza dipendenze rigide
I selector sono query sulle label (per esempio, “tutti i Pod dove app=checkout e env=prod”). Questo è meglio delle liste fisse di host perché il sistema può adattarsi mentre i Pod vengono reschedulati, scalati o sostituiti durante un rollout. La tua configurazione resta stabile anche quando le istanze sottostanti cambiano continuamente.
Raggruppamento dinamico a scala
Questo design scala operativamente: non gestisci migliaia di identità di istanze—gestisci poche serie di label significative. Questa è l'essenza dell'accoppiamento lasco: i componenti si connettono a gruppi la cui membership può cambiare in sicurezza.
Le label abilitano più che il raggruppamento
Una volta che le label esistono, diventano un vocabolario condiviso in tutta la piattaforma. Vengono usate per instradamento del traffico (Services), confini di policy (NetworkPolicy), filtri di osservabilità (metrica/log), e persino per il monitoraggio dei costi e chargeback. Una sola idea semplice—taggare le risorse con coerenza—sblocca un intero ecosistema di automazione.
Decisione 5: i Service per una rete stabile
Kubernetes aveva bisogno di un modo per far sembrare la rete prevedibile anche se i container non lo sono. I Pod vengono rimpiazzati, rischedulati e scalati—quindi i loro IP e le macchine specifiche cambieranno. L'idea centrale di un Service è semplice: fornire una “porta d'ingresso” stabile a un set di Pod che si muove.
Accesso stabile a Pod che cambiano
Un Service ti dà un IP virtuale consistente e un nome DNS (come payments). Dietro quel nome, Kubernetes traccia continuamente quali Pod corrispondono al selector del Service e instrada il traffico di conseguenza. Se un Pod muore e ne appare uno nuovo, il Service punta ancora al posto giusto senza che tu debba toccare la configurazione dell'app.
Service discovery che semplificò la configurazione
Questo approccio rimosse molto wiring manuale. Invece di mettere IP in file di configurazione, le app possono dipendere da nomi. Distribuisci l'app, distribuisci il Service e gli altri componenti la trovano via DNS—nessun registro custom, nessun endpoint hard-coded.
Bilanciamento integrato per l'affidabilità
I Service introducono anche un comportamento di bilanciamento tra endpoint sani. Ciò significava che i team non dovevano costruire (o ricostruire) i loro bilanciatori per ogni microservizio interno. Distribuire il traffico riduce la blast radius di un singolo Pod fallito e rende gli aggiornamenti rolling meno rischiosi.
Limiti—e come Ingress/Gateway lo estendono
Un Service è ottimo per il livello L4 (TCP/UDP), ma non modella regole di routing HTTP, terminazione TLS o policy di edge. Qui entrano Ingress e, sempre più, il Gateway API: costruiscono sopra i Service per gestire hostname, percorsi e punti di ingresso esterni in modo più pulito.
Decisione 6: un'API come superficie di prodotto
Una delle scelte iniziali più radicali fu trattare Kubernetes come un'API contro cui costruire—non come uno strumento monolitico da “usare”. Questo approccio API-first rese Kubernetes qualcosa su cui si può estendere, scriptare e governare.
Quando l'API è la superficie, i team piattaforma possono standardizzare come le applicazioni sono descritte e gestite, indipendentemente da quale UI, pipeline o portale interno viene messo sopra. “Deployare un'app” diventa “inviare e aggiornare oggetti API” (come Deployments, Services e ConfigMaps), che è un contratto molto più pulito tra i team app e la piattaforma.
Poiché tutto passa attraverso la stessa API, i nuovi strumenti non hanno bisogno di backdoor privilegiati. Dashboard, controller GitOps, motori di policy e sistemi CI/CD possono tutti operare come normali client API con permessi ben confinati.
Quella simmetria conta: le stesse regole, auth, auditing e admission control si applicano che la richiesta venga da una persona, da uno script o da una UI interna della piattaforma.
Versioning e compatibilità per cluster di lunga vita
Il versioning dell'API rese possibile evolvere Kubernetes senza rompere ogni cluster o strumento da un giorno all'altro. Le deprecazioni possono essere scaglionate; la compatibilità testata; gli upgrade pianificati. Per le organizzazioni che gestiscono cluster per anni, questa è la differenza tra “possiamo aggiornare” e “siamo bloccati”.
Cosa rappresenta davvero kubectl
kubectl non è Kubernetes—è un client. Quel modello mentale spinge i team a pensare in termini di workflow API: puoi sostituire kubectl con automazione, una UI web o un portale custom, e il sistema resta consistente perché il contratto è l'API stessa.
Decisione 7: stato centralizzato del cluster (etcd) e consistenza
Prototype a mobile companion app
Generate a Flutter mobile app alongside your backend to test the full workflow.
Kubernetes aveva bisogno di una sola “fonte di verità” su come il cluster dovrebbe apparire in questo momento: quali Pod esistono, quali nodi sono sani, quali Service puntano a cosa e quali oggetti sono in aggiornamento. Questo è ciò che fornisce etcd.
Cosa fa etcd (in termini semplici)
etcd è il database per il control plane. Quando crei un Deployment, scali un ReplicaSet o aggiorni un Service, la configurazione desiderata viene scritta in etcd. I controller e gli altri componenti del control plane osservano quello stato memorizzato e lavorano per far corrispondere la realtà.
Perché la consistenza conta quando tutto reagisce insieme
Un cluster Kubernetes è pieno di parti in movimento: scheduler, controller, kubelet, autoscaler e admission check possono reagire simultaneamente. Se leggessero versioni diverse della “verità”, ottieni condizioni di race—come due componenti che prendono decisioni confliggenti sullo stesso Pod.
La forte consistenza di etcd assicura che quando il control plane dice “questo è lo stato corrente”, tutti siano allineati. Quell'allineamento rende i control loop prevedibili invece che caotici.
Come impatta backup, upgrade e disaster recovery
Poiché etcd contiene la configurazione del cluster e la storia delle modifiche, è anche ciò che proteggi durante:
- Backup: senza uno snapshot di etcd non puoi ripristinare in modo affidabile gli oggetti del cluster.
- Upgrade: salute accurata di etcd e snapshot riducono il rischio durante gli upgrade.
- Disaster recovery: ripristinare etcd è spesso la via più rapida per riportare il control plane con lo stesso intento.
Guida pratica
Tratta lo stato del control plane come dati critici. Fai snapshot regolari di etcd, testa i ripristini e conserva i backup fuori dal cluster. Se usi Kubernetes gestito, impara cosa il provider esegue in backup—e cosa devi ancora proteggere tu (per esempio volumi persistenti e dati applicativi).
Decisione 8: scheduling pluggabile e consapevolezza delle risorse
Kubernetes non considerò “dove gira un workload” come un dettaglio secondario. Fin dall'inizio, lo scheduler fu un componente distinto con un compito chiaro: abbinare i Pod ai nodi che possono effettivamente eseguirli, usando lo stato corrente del cluster e i requisiti del Pod.
Come lo scheduler abbina workload e nodi
A grandi linee, lo scheduling è una decisione in due fasi:
- Filter: rimuovere i nodi che non rispettano vincoli rigidi (CPU/memoria insufficienti, label richieste mancanti, taint incompatibili, porte occupate, ecc.).
- Score: classificare i nodi rimanenti per preferenze (distribuire tra zone, impaccare per efficienza, evitare vicini rumorosi, rispettare regole di affinità).
Questa struttura rese possibile evolvere lo scheduling senza riscrivere tutto.
Separazione delle responsabilità: scheduler vs runtime vs networking
Una scelta chiave fu mantenere le responsabilità pulite:
- Lo scheduler decide il posizionamento.
- Il container runtime (e kubelet) esegue l'esecuzione sul nodo scelto.
- Lo strato di rete fornisce la connettività una volta che tutto è in esecuzione.
Perché queste responsabilità sono separate, miglioramenti in un'area (per esempio un nuovo plugin CNI) non obbligano a un nuovo modello di scheduling.
Vincoli e priorità cresciute naturalmente
La consapevolezza delle risorse iniziò con requests e limits, dando segnali utili allo scheduler invece di congetture. Da lì Kubernetes aggiunse controlli più ricchi—node affinity/anti-affinity, pod affinity, priorities and preemption, taints and tolerations e spreading topology-aware—costruiti sulla stessa base.
Impatto moderno: multi-tenant e posizionamento costo-efficiente
Questo approccio abilita i cluster condivisi di oggi: i team possono isolare servizi critici con priorità e taint, mentre tutti beneficiano di una maggiore utilizzazione. Con un migliore bin-packing e controlli di topology, le piattaforme possono posizionare i workload in modo più economico senza sacrificare l'affidabilità.
Decisione 9: estensibilità invece di una “via built-in” unica
Ship without risky deploys
Deploy and host your app, then keep changes safe with snapshots and rollback.
Kubernetes avrebbe potuto uscire con un'esperienza PaaS completa e opinionata—buildpacks, regole di routing app, job in background, convenzioni di config e altro. Invece, Joe Beda e il team iniziale mantennero il core focalizzato su una promessa più ridotta: eseguire e riparare workload in modo affidabile, esporli e fornire un'API coerente per l'automazione.
Perché Kubernetes non voleva essere un PaaS completo
Un “PaaS completo” avrebbe imposto un workflow e un set di compromessi a tutti. Kubernetes puntò a una base più ampia che potesse supportare molti stili di piattaforma—semplicità tipo Heroku, governance enterprise, pipeline batch/ML o controllo dell'infrastruttura—senza vincolare a una singola filosofia di prodotto.
Come le estensioni permettono di aggiungere funzionalità in sicurezza
I meccanismi di estensibilità di Kubernetes crearono un modo controllato di far crescere le capacità:
- CRD (CustomResourceDefinitions) permettono di aggiungere nuovi tipi API (per esempio
Certificate o Database) che sembrano e si comportano in modo nativo.
- Controller/operator riconciliano quelle nuove risorse usando lo stesso pattern dichiarativo dei componenti integrati.
- Admission controller/webhook applicano policy (sicurezza, naming, quote) e impostano default al confine API.
Questo significa che i team interni e i vendor possono distribuire funzionalità come add-on, continuando a usare primitive Kubernetes come RBAC, namespaces e log di audit.
Benefici—e il rischio principale
Per i vendor, permette prodotti differenziati senza forkare Kubernetes. Per i team interni, abilita una “piattaforma su Kubernetes” su misura per le esigenze aziendali.
Il compromesso è la proliferazione dell'ecosistema: troppe CRD, strumenti sovrapposti e convenzioni incoerenti. La governance—standard, ownership, versioning e regole di deprecazione—diventa parte del lavoro di piattaforma.
Le scelte iniziali di Kubernetes non hanno solo creato uno scheduler per container—hanno creato un nucleo di piattaforma riutilizzabile. Per questo molte moderne internal developer platform (IDP) sono, nel loro nucleo, “Kubernetes più workflow opinionati”. Il modello dichiarativo, i controller e un'API coerente hanno reso possibile costruire prodotti di livello superiore—senza reinventare ogni volta deploy, riconciliazione e service discovery.
Kubernetes come control plane condiviso
Poiché l'API è la superficie di prodotto, vendor e team piattaforma possono standardizzare su un singolo control plane e costruire esperienze diverse sopra: GitOps, gestione multi-cluster, policy, cataloghi di servizi e automazione dei deploy. Questa è una grande ragione per cui Kubernetes è diventato il denominatore comune per le piattaforme cloud native: le integrazioni mirano all'API, non a una UI specifica.
Cosa è rimasto difficile (la realtà del Day-2)
Anche con astrazioni pulite, il lavoro più duro è ancora operativo:
- Sicurezza: identity, network policy, segreti e fiducia nella supply chain
- Upgrade: versioni di Kubernetes, CRD e add-on che evolvono a velocità diverse
- Affidabilità: debug dei controller, misconfigurazioni e vicini rumorosi
Fai domande che rivelino la maturità operativa:
- Come vengono gestiti gli upgrade e qual è la storia dei rollback?
- Quali parti sono Kubernetes standard vs estensioni proprietarie?
- Quali guardrail esistono (policy, default, template) per evitare errori pericolosi?
- Quanto è osservabile il sistema (eventi, log, audit) e chi possiede gli incidenti?
Una buona piattaforma riduce il carico cognitivo senza nascondere il control plane sottostante o rendere difficili le uscite di emergenza.
Una lente pratica: la piattaforma aiuta i team a passare da “idea → servizio in esecuzione” senza costringerli a diventare esperti di Kubernetes dal giorno uno? Strumenti nella categoria “vibe-coding”—come Koder.ai—puntano su questo permettendo ai team di generare applicazioni reali dalla chat (web in React, backend in Go con PostgreSQL, mobile in Flutter) e poi iterare rapidamente con funzionalità come planning mode, snapshot e rollback. Che tu adotti qualcosa di simile o costruisca il tuo portale, lo scopo è lo stesso: preservare le primitive solide di Kubernetes riducendo l'overhead dei workflow attorno a esse.
Principali lezioni e takeaways pratici
Kubernetes può sembrare complicato, ma gran parte della sua “stranezza” è intenzionale: è un insieme di piccole primitive progettate per comporsi in molti tipi di piattaforme.
Sfoltire due idee sbagliate comuni
Primo: “Kubernetes è solo orchestrazione di Docker.” Kubernetes non è primariamente avviare container. Si tratta di riconciliare continuamente lo stato desiderato (ciò che vuoi che giri) con lo stato reale (ciò che sta veramente succedendo), attraverso guasti, rollout e domanda variabile.
Secondo: “Se usiamo Kubernetes, tutto diventa microservizi.” Kubernetes supporta i microservizi, ma supporta anche monoliti, job batch e piattaforme interne. Le primitive (Pod, Service, label, controller e l'API) sono neutrali; le scelte architetturali non sono imposte dallo strumento.
Da dove nasce davvero la complessità
Le parti difficili di solito non sono YAML o Pod—sono rete, sicurezza e uso multi-team: identity e accesso, gestione dei segreti, policy, ingress, osservabilità, controlli della supply chain e creare guardrail in modo che i team possano rilasciare in sicurezza senza pestarsi i piedi.
Takeaway a livello decisionale che puoi usare
Quando pianifichi, pensa in termini delle scommesse progettuali originali:
- Preferisci workflow dichiarativi e automazioni che possano riconciliare il drift.
- Usa label/selector per mantenere basso l'accoppiamento tra team e componenti.
- Tratta l'API come un prodotto: versioning, convenzioni e ownership chiara contano.
Un passo pratico successivo
Mappa i tuoi requisiti reali alle primitive Kubernetes e ai layer di piattaforma:
-
Workload → Pods/Deployments/Jobs
-
Connettività → Services/Ingress
-
Operazioni → controller, policy e osservabilità
Se stai valutando o standardizzando, metti questa mappatura per iscritto e rivedila con gli stakeholder—poi costruisci la tua piattaforma incrementale attorno alle lacune, non alle mode.
Se vuoi anche accelerare il lato “build” (non solo il lato “run”), considera come il tuo workflow di delivery trasforma l'intento in servizi deployabili. Per alcuni team è un set curato di template; per altri è un workflow assistito dall'AI come Koder.ai che può produrre un servizio iniziale funzionante e poi esportare il codice sorgente per personalizzazioni più profonde—mentre la tua piattaforma continua a beneficiare dalle decisioni progettuali fondamentali di Kubernetes sotto il cofano.