Flussi di lavoro centrati sui documenti: modello dati e pattern UI
Flussi document-centric spiegati con modelli dati pratici e pattern UI per versioni, anteprime, metadata e stati di stato chiari.
Che cosa rende un'app centrata sui documenti
Un'app è document-centric quando il documento stesso è il prodotto che gli utenti creano, revisionano e su cui fanno affidamento. L’esperienza è costruita attorno a file come PDF, immagini, scansioni e ricevute, non attorno a un modulo in cui un file è solo un allegato.
Nei flussi document-centric, le persone lavorano davvero all’interno del documento: lo aprono, controllano cosa è cambiato, aggiungono contesto e decidono cosa succede dopo. Se il documento non è affidabile, l’app smette di essere utile.
La maggior parte delle app document-centric ha bisogno di alcuni schermate core fin da subito:
- Una inbox per i nuovi upload, gli elementi assegnati e tutto ciò che richiede attenzione
- Una vista dettaglio documento con anteprima, metadata, commenti e cronologia
- Un flusso di revisione per approvare, rifiutare o richiedere modifiche
- Un’area di esportazione o condivisione per passare il file a un altro sistema
I problemi emergono in fretta. Gli utenti caricano la stessa ricevuta due volte. Qualcuno modifica un PDF e lo ricarica senza spiegare. Una scansione non ha data, venditore o proprietario. Settimane dopo, nessuno sa quale versione sia stata approvata o su cosa si sia basata la decisione.
Una buona app document-centric deve sembrare veloce e affidabile. Gli utenti dovrebbero poter rispondere a queste domande in pochi secondi:
- È questa l’ultima versione e chi l’ha modificata?
- Posso visualizzarla subito senza scaricarla?
- Che cos’è, descritto in pochi campi semplici su cui posso filtrare?
- In quale stato si trova ora e quale azione è attesa?
Quella chiarezza viene dalle definizioni. Prima di costruire schermate, decidete cosa significano “versione”, “anteprima”, “metadata” e “stato” nella vostra app. Se questi termini sono vaghi, otterrete duplicati, cronologie confuse e flussi di revisione che non corrispondono al lavoro reale.
Concetti core da modellare prima di costruire la UI
La UI spesso sembra semplice (una lista, un visualizzatore, qualche bottone), ma il modello dati porta il peso. Se gli oggetti core sono corretti, cronologia di audit, anteprime veloci e approvazioni affidabili diventano molto più facili.
Iniziate separando il “record documento” dal “contenuto file”. Il record è ciò di cui parlano gli utenti (Fattura da ACME, Ricevuta taxi). Il contenuto sono i byte (PDF, JPG) che possono essere sostituiti, rielaborati o spostati senza cambiare cosa il documento rappresenta nell’app.
Un set pratico di oggetti da modellare:
- Documento: l’entità stabile su cui gli utenti cercano, commentano e approvano
- File: un blob memorizzato (PDF/immagine) con dimensione, checksum, chiave di storage e MIME type
- Versione: uno snapshot del documento in un punto temporale, che punta a uno o più File
- Preview: asset derivati (thumbnail, immagine della prima pagina, estratto di testo) legati a un File o a una Versione
- Metadata: campi strutturati (merchant, totale, data) più output grezzo di estrazione e confidenza
- Stato: lo stato business corrente del lavoro (da revisionare, approvato, rifiutato)
Decidete cosa ottiene un ID che non cambia mai. Una regola utile è: Document ID vive per sempre, mentre File e Preview possono essere rigenerati. Anche le Versioni hanno bisogno di ID stabili, perché le persone fanno riferimento a “com’era ieri” e avrete bisogno di un audit trail.
Modellate le relazioni esplicitamente. Un Documento ha molte Versioni. Ogni Versione può avere multiple Preview (diverse dimensioni o formati). Questo mantiene le liste veloci perché possono caricare dati di anteprima leggeri, mentre le viste dettaglio caricano il file completo solo quando serve.
Esempio: un utente carica la foto stropicciata di una ricevuta. Create un Documento, memorizzate il File originale, generate una Preview thumbnail e create la Versione 1. Più tardi, l’utente carica una scansione più nitida. Quella diventa la Versione 2, senza rompere commenti, approvazioni o ricerche legate al Documento.
Versioning: come conservare la storia senza caos
Le persone si aspettano che un documento cambi nel tempo senza “trasformarsi” in un elemento diverso. Il modo più semplice per offrire questo è separare l’identità (il Documento) dal contenuto (la Versione e i File).
Partite con un document_id stabile che non cambia mai. Anche se l’utente ricarica lo stesso PDF, sostituisce una foto sfocata o carica una scansione corretta, dovrebbe restare lo stesso record documento. Commenti, assegnazioni e log di audit si collegano pulitamente a un ID duraturo.
Trattate ogni cambiamento significativo come una nuova riga version. Ogni versione dovrebbe catturare chi l’ha creata e quando, più puntatori di storage (file key, checksum, size, page count) e artefatti derivati (testo OCR, immagini di anteprima) legati a quel file specifico. Evitate di “modificare in place.” All’inizio sembra più semplice, ma rompe la tracciabilità e rende i bug difficili da risolvere.
Per letture veloci, mantenete un current_version_id sul documento. La maggior parte delle schermate ha bisogno solo della “ultima”, così non dovete ordinare le versioni a ogni caricamento. Quando serve la cronologia, caricate le versioni separatamente e mostrate una timeline chiara.
I rollback sono solo un cambio di puntatore. Invece di cancellare qualcosa, impostate current_version_id su una versione più vecchia. È rapido, sicuro e mantiene l’audit trail intatto.
Per mantenere la storia comprensibile, registrate perché ogni versione esiste. Un piccolo campo reason consistente (più una nota opzionale) evita una timeline piena di aggiornamenti misteriosi. Motivi comuni includono sostituzione re-upload, pulizia scansione, correzione OCR, redazione e modifica per approvazione.
Esempio: un team finance carica una foto di una ricevuta, la sostituisce con una scansione più nitida, poi corregge l’OCR per rendere leggibile il totale. Ogni passo è una nuova versione, ma il documento resta un unico elemento nella inbox. Se la correzione OCR era sbagliata, il rollback è un clic perché si cambia solo current_version_id.
Preview e thumbnail che restano veloci e affidabili
Nelle app document-centric, la preview è spesso l’elemento principale con cui gli utenti interagiscono. Se le preview sono lente o instabili, tutta l’app sembra guasta.
Trattate la generazione delle preview come un job separato, non qualcosa che la schermata di upload aspetta. Salvate prima il file originale, restituite il controllo all’utente e poi generate le preview in background. Questo mantiene la UI reattiva e rende i retry sicuri.
Memorizzate più dimensioni di preview. Una sola dimensione non copre tutti gli schermi: una miniatura per le liste, un’immagine media per le viste affiancate e immagini a pagina intera per la revisione dettagliata (pagina per pagina per i PDF).
Tracciate lo stato della preview esplicitamente così la UI sa sempre cosa mostrare: pending, ready, failed e needs_retry. Tenete le etichette user-friendly nella UI, ma mantenete stati chiari nei dati.
Per mantenere il rendering veloce, cacheate valori derivati insieme al record preview invece di ricalcolarli a ogni visualizzazione. Campi comuni includono page count, larghezza e altezza della preview, rotazione (0/90/180/270) e un opzionale “migliore pagina per la thumbnail”.
Progettate per file lenti e disordinati. Un PDF scansionato di 200 pagine o una foto di una ricevuta spiegazzata possono richiedere tempo per essere processati. Usate il caricamento progressivo: mostrate la prima pagina pronta non appena esiste, poi completate il resto.
Esempio: un utente carica 30 foto di ricevute. La vista lista mostra miniature come “pending”, poi ogni scheda passa a “ready” man mano che la preview finisce. Se alcune falliscono per un’immagine corrotta, restano visibili con una chiara azione di retry invece di scomparire o bloccare l’intero batch.
Metadata: cosa memorizzare e come mantenerlo utile
I metadata trasformano una pila di file in qualcosa che puoi cercare, ordinare, revisionare e approvare. Aiutano le persone a rispondere a domande semplici velocemente: Che cos’è questo documento? Da chi viene? È valido? Cosa dovrebbe succedere dopo?
Un modo pratico per mantenere i metadata puliti è separarli in base a da dove provengono:
- System metadata: nome file, dimensione, MIME type, page count, ora upload, checksum
- Extracted metadata: testo OCR, campi rilevati (merchant, data, totale), valori barcode/QR
- User-entered metadata: correzioni, tag, note, categorizzazioni, commenti approvatore
Questi bucket evitano discussioni successive. Se un totale è sbagliato, puoi vedere se viene dall’OCR o da una modifica umana.
Per ricevute e fatture, un set ridotto di campi ripaga purché li usiate con coerenza (stessi nomi, stessi formati). Campi ancore comuni sono merchant, data, totale, valuta e document_number. Teneteli opzionali all’inizio. Le persone caricano scansioni parziali e foto sfuocate, e bloccare il progresso perché manca un campo rallenta tutto il workflow.
Trattate i valori sconosciuti come di prima classe. Usate stati espliciti come null/unknown, più una ragione quando utile (pagina mancante, illeggibile, non applicabile). Questo permette al documento di andare avanti mostrando però ai revisori cosa richiede attenzione.
Conservate anche provenienza e confidenza per i campi estratti. La sorgente può essere user, OCR, import o API. La confidenza può essere un punteggio 0-1 o un insieme ridotto come high/medium/low. Se l’OCR legge “€18.70” con bassa confidenza perché l’ultima cifra è sfocata, la UI può evidenziarlo e chiedere una conferma rapida.
I documenti multi-pagina richiedono una decisione in più: cosa appartiene al documento intero rispetto a una singola pagina. Totali e merchant di solito appartengono al documento. Note a livello pagina, redazioni, rotazione e classificazione per pagina spesso appartengono al livello pagina.
Stati che rispecchiano il lavoro reale
Lo stato risponde a una domanda: “Dove si trova questo documento nel processo?” Mantienilo piccolo e noioso. Se aggiungi uno stato ogni volta che qualcuno lo chiede, finirai con filtri di cui nessuno si fida.
Un insieme pratico di stati business che mappa decisioni reali:
- Importato: il file esiste, ma nulla è stato ancora controllato
- In attesa di revisione: è necessaria la conferma umana di campi chiave o della leggibilità
- Approvato: pronto per l’uso a valle (pagamento, archiviazione, pubblicazione o esportazione)
- Rifiutato: non utilizzabile, con una motivazione
- Archiviato: mantenuto per registro, fuori dal lavoro attivo
Tieni i “processing” fuori dallo stato business. OCR in esecuzione e generazione preview descrivono cosa sta facendo il sistema, non cosa deve fare una persona dopo. Memorizza quelli come stati di processamento separati.
Separa anche l’assegnazione dallo stato (assignee_id, team_id, due_date). Un documento può essere Approvato ma ancora assegnato per follow-up, o In attesa di revisione senza un responsabile.
Registra la storia degli stati, non solo il valore corrente. Un semplice log come (from_status, to_status, changed_at, changed_by, reason) ripaga quando qualcuno chiede “Chi ha rifiutato questa ricevuta e perché?”
Infine, decidete quali azioni sono consentite in ogni stato. Tenete le regole semplici: Importato può passare a In attesa di revisione; Approvato è di sola lettura a meno che non venga creata una nuova versione; Rifiutato può essere riaperto ma deve mantenere la ragione precedente.
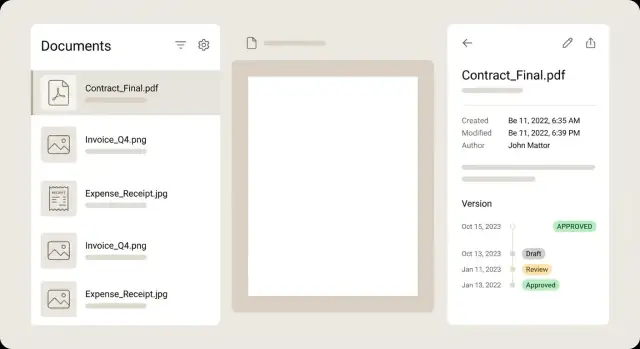
Pattern UI per liste, viste dettaglio e flussi di revisione
La maggior parte del tempo si spende a scansionare una lista, aprire un elemento, correggere pochi campi e andare avanti. Una buona UI rende questi passaggi rapidi e prevedibili.
Per la lista dei documenti, trattate ogni riga come un sommario così gli utenti decidono senza aprire ogni file. Una riga forte mostra una piccola miniatura, un titolo chiaro, pochi campi chiave (merchant, data, totale), un badge di stato e un avviso sottile quando qualcosa richiede attenzione.
Mantenete la vista dettaglio calma e scansionabile. Un layout comune è anteprima a sinistra e metadata a destra, con controlli di modifica accanto a ogni campo. Gli utenti dovrebbero poter zoomare, ruotare e sfogliare le pagine senza perdere il punto nel form. Se un campo è estratto dall’OCR, mostrate un piccolo suggerimento di confidenza e, idealmente, evidenziate l’area sorgente sull’anteprima quando il campo è focalizzato.
Le versioni funzionano meglio come una timeline, non come un dropdown. Mostrate chi ha cambiato cosa e quando, e permettete di aprire qualsiasi versione passata in sola lettura. Se offrite il confronto, concentratevi sulle differenze di metadata (totale cambiato, merchant corretto) piuttosto che forzare un confronto pixel-per-pixel del PDF.
La modalità revisione dovrebbe ottimizzare la velocità. Un flusso triage orientato alla tastiera è spesso sufficiente: azioni rapide approva/rifiuta, correzioni veloci per i campi comuni e una breve casella commenti per i rifiuti.
Gli stati vuoti contano perché i documenti sono spesso in mezzo al processamento. Invece di un riquadro vuoto, spiegate cosa sta succedendo: “Preview in generazione”, “OCR in esecuzione” o “Nessuna anteprima per questo tipo di file”.
Passo-passo: un workflow semplice da upload ad approvazione
Un workflow semplice sembra “carica, controlla, approva.” Sotto, funziona meglio quando separate il file stesso (versioni e preview) dal significato business (metadata e stato).
1) L’upload finisce in una inbox
L’utente carica un PDF, una foto o una scansione di una ricevuta e lo vede immediatamente in una lista inbox. Non aspettate che il processamento finisca. Mostrate nome file, ora di upload e un badge chiaro come “Processing”. Se conoscete già la sorgente (import da email, fotocamera mobile, drag-and-drop), mostratela.
2) Create Documento + Versione, la preview parte in pending
Al caricamento, create un record Documento (la cosa duratura) e una Versione (questo file specifico). Impostate current_version_id alla nuova versione. Memorizzate preview_state = pending e extraction_state = pending così la UI può dire onestamente cosa è pronto.
La vista dettaglio dovrebbe aprirsi subito, ma mostrare un viewer placeholder e un messaggio chiaro “Preparazione anteprima” invece di un frame rotto.
3) Il processamento in background genera preview ed estrae metadata
Un job in background crea thumbnail e una preview visualizzabile (immagini pagina per pagina per i PDF, immagini ridimensionate per le foto). Un altro job estrae metadata (merchant, data, totale, valuta, tipo di documento). Quando ogni job termina, aggiornate solo il suo stato e i suoi timestamp così potete ritentare i fallimenti senza toccare tutto il resto.
Mantenete la UI compatta: mostrate lo stato preview, lo stato dati ed evidenziate campi con bassa confidenza.
4) Il revisore corregge campi, cambia stato e aggiunge note
Quando la preview è pronta, i revisori correggono campi, aggiungono note e muovono il documento attraverso stati business come Importato -> In attesa di revisione -> Approvato (o Rifiutato). Registrate chi ha cambiato cosa e quando.
Se un revisore carica un file corretto, questo diventa una nuova Versione e il documento torna automaticamente a In attesa di revisione.
5) L’uso a valle legge la versione corrente e i metadata approvati
Esportazioni, sincronizzazioni contabili o report interni dovrebbero leggere da current_version_id e dallo snapshot dei metadata approvati, non da “ultima estrazione”. Questo evita che un re-upload in mezzo al processamento cambi i numeri.
Errori comuni e trappole da evitare
I flussi document-centric falliscono per motivi noiosi: scorciatoie iniziali diventano un dolore quotidiano quando le persone caricano duplicati, correggono errori o chiedono “Chi ha cambiato questo e quando?”.
Trattare il nome file come identità del documento è un errore classico. I nomi cambiano, gli utenti ricaricano e le fotocamere producono duplicati come IMG_0001. Date a ogni documento un ID stabile e trattate il nome file come un’etichetta.
Sovrascrivere il file originale quando qualcuno carica una sostituzione crea problemi. Sembra più semplice, ma perdete la cronologia e non potete rispondere a domande basilari in seguito (cosa è stato approvato, cosa è stato modificato, cosa è stato inviato). Tenete il file binario immutabile e aggiungete un nuovo record versione.
La confusione di stato causa bug sottili. “OCR in esecuzione” non è la stessa cosa di “In attesa di revisione.” Gli stati di processamento descrivono cosa fa il sistema; lo stato business descrive cosa deve fare una persona. Quando si mescolano, i documenti finiscono nel bucket sbagliato.
Decisioni UI possono creare attrito. Se bloccate lo schermo finché le preview non sono generate, le persone percepiscono l’app come lenta anche quando l’upload è riuscito. Mostrate il documento subito con un placeholder chiaro, poi sostituite le miniature quando sono pronte.
Infine, i metadata diventano inaffidabili quando memorizzi valori senza provenienza. Se il totale proviene dall’OCR, ditelo. Conservate timestamp.
Una rapida lista di controllo mentale:
- ID documento stabile separato dal nome file
- Nuova versione per ogni sostituzione, niente overwrite
- Stato business separato dallo stato di processamento
- Caricamento preview e miniature non bloccante
- Metadata includono provenienza e timestamp
Esempio: in un’app di ricevute, un utente ricarica una foto più nitida. Se fate versioning, mantenete l’immagine vecchia, segnate l’OCR come in reprocessing e mantenete In attesa di revisione finché una persona non conferma l’importo.
Checklist rapida prima del rilascio
I flussi document-centric sembrano “completi” solo quando le persone possono fidarsi di ciò che vedono e recuperare quando qualcosa va storto. Prima del lancio, testate con documenti reali e disordinati (ricevute sfocate, PDF ruotati, upload ripetuti).
Cinque controlli che catturano la maggior parte delle sorprese:
- La versione corrente è inequivocabile. Indicate la versione attiva, mostrate chi l’ha cambiata per ultimo e quando, e includete una breve ragione come “ritagliata” o “re-upload”.
- Le preview falliscono in modo elegante. Se una preview è ancora in generazione, mostrate un placeholder utile (nome file, ora upload, numero di pagine se noto) e uno stato pending chiaro. Se la generazione fallisce, mostrate un errore e un’opzione di retry.
- Gli stati corrispondono ad azioni. Ogni stato necessita di un significato chiaro e di un piccolo insieme di azioni consentite. Se esiste Approvato, rendetelo di sola lettura.
- Le modifiche ai metadata non cancellano l’estrazione. Permettete agli utenti di correggere l’OCR senza perdere il valore estratto originale. Conservate entrambi e mostrate quale viene usato.
- Il recupero è integrato. Rendete facili le correzioni comuni: rollback a una versione precedente, rilanciare l’estrazione, rigenerare le preview.
Un test di realtà: chiedete a qualcuno di revisionare tre ricevute simili e fate fare volutamente una modifica sbagliata. Se riescono a individuare la versione corrente, capire lo stato e correggere l’errore in meno di un minuto, siete vicini.
Scenario di esempio e prossimi passi pratici
I rimborsi mensili delle ricevute sono un esempio chiaro di lavoro document-centric. Un dipendente carica ricevute, poi due revisori le controllano: un manager e poi la finanza. La ricevuta è il prodotto, quindi la vostra app vive o muore su versioning, preview, metadata e stati chiari.
Jamie carica la foto di una ricevuta taxi. Il sistema crea Documento #1842 con Versione v1 (il file originale), una thumbnail e una preview, e metadata come merchant, data, valuta, totale e un punteggio di confidenza OCR. Il documento parte come Importato, poi passa a In attesa di revisione una volta pronte preview ed estrazione.
Più tardi, Jamie carica la stessa ricevuta per errore. Un controllo duplicati (hash file più merchant/data/totale simili) può mostrare una scelta semplice: “Sembra un duplicato di #1842. Allega comunque o scarta.” Se la allega, memorizzatela come un altro File collegato allo stesso Documento così mantenete un unico thread di revisione e un solo stato.
Durante la revisione il manager vede l’anteprima, i campi chiave e gli avvisi. L’OCR ha ipotizzato il totale a €18.00, ma l’immagine mostra chiaramente €13.00. Jamie corregge il totale. Non sovrascrivete la storia. Create la Versione v2 con i campi aggiornati, mantenete v1 inalterata e registrate “Totale corretto da Jamie.”
Se volete costruire questo tipo di workflow rapidamente, Koder.ai (koder.ai) può aiutarvi a generare la prima versione dell’app da un piano basato su chat, ma la stessa regola vale: definite prima gli oggetti e gli stati, poi lasciate che gli schermi seguano.
Prossimi passi pratici:
- Schizzate il modello dati: Document, Version, File, ExtractedField, Review, StatusHistory
- Progettate due schermate: inbox list (stato + avvisi) e vista dettaglio (preview + campi + versioni)
- Testate con cinque ricevute reali e iterate su stati, regole duplicati e velocità di revisione
Domande frequenti
Cosa significa veramente “document-centric” in un’app?
Un’app document-centric tratta il documento come l’elemento principale su cui gli utenti lavorano, non come un allegato secondario. Le persone devono poterlo aprire, fidarsi di ciò che vedono, capire cosa è cambiato e decidere la prossima azione basata su quel documento.
Quali sono le prime schermate da costruire per un workflow document-centric?
Inizia con una inbox/lista, una vista dettaglio documento con anteprima veloce, un’area semplice per le azioni di revisione (approva/rifiuta/richiesta modifiche) e un modo per esportare o condividere. Questi quattro schermi coprono il ciclo comune: trova, apri, decidi e consegna.
Come dovrei modellare documenti vs file così che i re-upload non rompano tutto?
Modella un record stabile Document che non cambia mai e conserva i byte reali come oggetti separati File. Poi aggiungi Version come snapshot che collega un documento a uno specifico file (e ai suoi output derivati). Questa separazione mantiene commenti, assegnazioni e cronologia intatti anche quando il file viene sostituito.
Quando dovrei creare una nuova versione invece di sovrascrivere un file?
Ogni cambiamento significativo deve essere una nuova versione invece di sovrascrivere in place. Mantieni un current_version_id sul documento per letture veloci della "ultima" versione e conserva una timeline delle versioni per audit e rollback. Questo evita confusione su cosa è stato approvato e perché.
Come mantenere veloci le preview e le miniature senza bloccare la UI?
Genera le preview in modo asincrono dopo aver salvato il file originale, così gli upload sembrano istantanei e i retry sono sicuri. Traccia lo stato della preview come pending/ready/failed in modo che l’interfaccia dica sempre la verità, e memorizza più dimensioni in modo che le liste restino leggere mentre le viste dettaglio restano nitide.
Quali metadata dovrei memorizzare e come mantenere la loro affidabilità?
Conserva i metadata in tre categorie: system (dimensione file, tipo), extracted (campi OCR e confidenza) e user-entered (correzioni manuali). Memorizza la provenienza così si può sapere se un valore viene dall’OCR o da una persona, e non obbligare a compilare ogni campo prima che il flusso possa procedere.
Quali stati di status funzionano meglio e cosa dovrei evitare?
Usa un piccolo insieme di stati business che descrivono cosa dovrebbe fare una persona dopo, per esempio Importato, In attesa di revisione, Approvato, Rifiutato e Archiviato. Tieni i processi tecnici separati (preview/OCR in esecuzione) così i documenti non restano bloccati in uno stato che mescola lavoro umano e lavoro macchina.
Come posso rilevare duplicati senza infastidire gli utenti?
Conserva checksum immutabili dei file e confrontali all’upload, poi aggiungi un secondo controllo usando campi chiave come merchant/data/importo quando disponibili. Se sospetti un duplicato, offri la scelta chiara: allegalo allo stesso thread documento o scartalo, così non frammenti la storia di revisione su copie diverse.
Come progetto audit trail e rollback facili?
Tieni un log di cronologia stato con chi ha cambiato cosa, quando e perché, e conserva le versioni leggibili tramite una timeline. Il rollback dovrebbe essere un semplice cambio di puntatore verso una versione precedente, non una cancellazione, così si recupera rapidamente senza perdere la traccia dell’audit.
In che modo Koder.ai può aiutarmi a costruire un’app document-centric più velocemente senza creare un modello caotico?
Definisci prima gli oggetti e gli stati, poi lascia che la UI segua quelle definizioni. Se usi Koder.ai per generare un’app a partire da un piano chat, sii esplicito su Document/Version/File, stati di preview ed estrazione e regole di status, così gli schermi generati rispecchiano comportamenti reali di workflow.