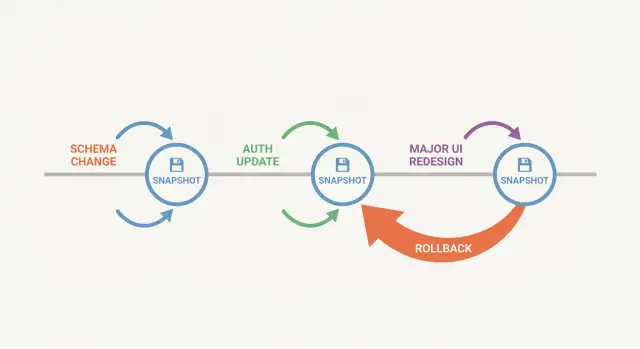
Cosa significa “snapshot-first” e perché aiuta
Un flusso di lavoro snapshot-first significa che crei un punto di salvataggio prima di fare una modifica che potrebbe rompere la tua app. Uno snapshot è una copia congelata del progetto in un dato momento. Se il passo successivo va storto, puoi tornare a quello stato esatto invece di cercare di annullare tutto a mano.
I grandi cambiamenti raramente falliscono in modo ovvio. Un aggiornamento dello schema può rompere un report a tre schermate di distanza. Una modifica all'autenticazione può bloccarti fuori. Una riscrittura UI può sembrare ok con dati di esempio e poi crollare con account reali e casi limite. Senza un chiaro punto di salvataggio, finisci per indovinare quale modifica ha causato il problema, o continui a rattoppare una versione rotta finché non ricordi più com'era “funzionante”.
Gli snapshot aiutano perché ti danno una baseline nota buona, rendono più economico provare idee coraggiose e semplificano i test. Quando qualcosa si rompe, puoi rispondere: “Era ancora ok subito dopo lo Snapshot X?”
Aiuta anche essere chiari su cosa uno snapshot può e non può proteggere. Uno snapshot conserva il codice e la configurazione com'erano (e su piattaforme come Koder.ai, può preservare lo stato completo dell'app con cui lavori). Ma non risolve ipotesi sbagliate. Se la tua nuova funzionalità si aspetta una colonna del database che non esiste in produzione, rollback del codice non annullerà il fatto che una migrazione è già stata eseguita. Ti serve comunque un piano per le modifiche ai dati, la compatibilità e l'ordine di deployment.
Il cambio di mentalità è trattare lo snapshotting come un'abitudine, non come un pulsante di salvataggio d'emergenza. Scatta snapshot subito prima delle mosse rischiose, non dopo che qualcosa si è rotto. Ti muoverai più veloce e con più calma perché avrai sempre un “ultimo noto buono” a cui tornare.
I cambiamenti che meritano un punto di salvataggio
Uno snapshot ripaga soprattutto quando una modifica può rompere molte cose insieme.
Il lavoro sullo schema è l'esempio ovvio: rinominare una colonna può rompere silenziosamente API, job in background, export e report che si aspettano ancora il vecchio nome. Anche le modifiche all'autenticazione sono rischiose: una piccola regola può bloccare amministratori o concedere accessi non desiderati. Le riscritture UI sono insidiose perché spesso mescolano cambiamenti visivi a cambiamenti di comportamento, e le regressioni si nascondono negli stati limite.
Se vuoi una regola semplice: fai uno snapshot prima di qualsiasi cosa che cambia la forma dei dati, l'identità e l'accesso, o più schermate insieme.
Gli interventi a basso rischio di solito non richiedono una pausa per lo snapshot. Cambiamenti di testo, piccoli aggiustamenti di spaziatura, una regola di validazione minore o la pulizia di una piccola funzione helper hanno in genere un raggio d'azione limitato. Puoi comunque fare uno snapshot se ti aiuta a concentrarti, ma non serve interrompere ogni piccola modifica.
I cambiamenti ad alto rischio sono diversi. Spesso funzionano nei test “happy path” ma falliscono su valori null in righe vecchie, utenti con combinazioni di ruoli insolite o stati UI che non tocchi manualmente.
Come chiamare gli snapshot per mantenerli utili
Uno snapshot è utile solo se lo riconosci rapidamente sotto pressione. Il nome e le note sono ciò che trasformano un rollback in una decisione calma e veloce.
Un buon label risponde a tre domande:
- Cosa è cambiato?
- Perché è cambiato?
- Qual era il passo successivo?
Tienilo corto ma specifico. Evita nomi vaghi come “before update” o “try again”.
Un pattern di naming che resta leggibile
Scegli un pattern e mantienilo. Per esempio:
[WIP] Auth: add magic link (prep for OAuth)[GOLD] DB: users table v2 (passes smoke tests)[WIP] UI: dashboard layout refactor (next: charts)[GOLD] Release: billing fixes (deployed)Hotfix: login redirect loop (root cause noted)
Stato prima, poi area, poi azione, poi un breve “next”. Quest'ultima parte è sorprendentemente utile una settimana dopo.
I nomi da soli non bastano. Usa le note per catturare ciò che il tuo futuro sé dimenticherà: le assunzioni fatte, cosa hai testato, cosa è ancora rotto e cosa hai intenzionalmente ignorato.
Buone note di solito includono assunzioni, 2-3 passaggi di test rapidi, problemi noti e qualsiasi dettaglio rischioso (modifiche allo schema, cambi di permessi, cambi di routing).
“Golden” vs “work in progress”
Marca uno snapshot come GOLD solo quando è sicuro tornare a quello stato senza sorprese: i flussi base funzionano, gli errori sono compresi e potresti ripartire da lì. Tutto il resto è WIP. Questa piccola abitudine impedisce di fare rollback verso un punto che sembrava stabile solo perché avevi dimenticato il grosso bug lasciato indietro.
Passo dopo passo: un semplice loop snapshot-first
Un loop solido è semplice: procedi solo da punti noti buoni.
1) Parti da “funziona”
Prima di fare uno snapshot, assicurati che l'app giri effettivamente e che i flussi chiave si comportino. Tieni il controllo corto: puoi aprire la schermata principale, effettuare il login (se l'app lo richiede) e completare un'azione principale senza errori? Se qualcosa è già instabile, sistemalo prima. Altrimenti il tuo snapshot conserverà un problema.
2) Crea lo snapshot e scrivi l'intento
Crea uno snapshot, poi aggiungi una nota in una riga sul perché esiste. Descrivi il rischio imminente, non lo stato corrente.
Esempio: “Before changing users table + adding organization_id” o “Before auth middleware refactor to support SSO”.
3) Fai una singola modifica mirata
Evita di accumulare più grandi cambiamenti in un'unica iterazione (schema più auth più UI). Scegli una fetta singola, completala e fermati.
Una buona “singola modifica” è “aggiungi una nuova colonna e mantieni il vecchio codice funzionante” piuttosto che “sostituisci tutto il modello dati e aggiorna ogni schermata”.
4) Esegui un controllo piccolo e ripetibile dopo ogni cambio
Dopo ogni passo, esegui gli stessi controlli rapidi in modo che i risultati siano comparabili. Mantienilo breve così lo farai davvero.
- L'app si avvia senza errori
- Un flusso chiave funziona end-to-end
- Nessun nuovo errore in console/server durante quel flusso
- Qualsiasi nuovo caso limite introdotto è coperto (per esempio, uno stato vuoto)
5) Snapshot di nuovo al nuovo punto stabile
Quando la modifica funziona e hai di nuovo una baseline pulita, prendi un altro snapshot. Questo diventa il nuovo punto sicuro per il passo successivo.
Prima delle modifiche allo schema: dove mettere i punti di salvataggio
Refactor without losing your baseline
Keep a known-good checkpoint so big refactors stay reversible.
Le modifiche al database sembrano “piccole” fino al momento in cui rompono signup, report o un job in background che avevi dimenticato esistesse. Tratta il lavoro sullo schema come una sequenza di checkpoint sicuri, non come un grande salto.
Inizia con uno snapshot prima di toccare nulla. Poi scrivi una baseline in linguaggio semplice: quali tabelle sono coinvolte, quali schermate o chiamate API le leggono e cosa significa “corretto” (campi richiesti, regole di unicità, conteggi di righe attesi). Ci vogliono minuti e ti risparmi ore quando serve confrontare il comportamento.
Un set pratico di punti di salvataggio per la maggior parte dei lavori sullo schema assomiglia a questo:
- Snapshot 1 (baseline): prima della prima migrazione. Nota tabelle chiave, query importanti e i flussi utente che userai per verificare.
- Snapshot 2 (additive changes): dopo aver aggiunto nuove tabelle/colonne (ancora senza eliminazioni). Il comportamento vecchio dovrebbe funzionare.
- Snapshot 3 (backfill): dopo aver copiato/calcolato i dati nelle nuove colonne, con alcuni controlli spot.
- Snapshot 4 (code switch): dopo che l'app legge dalla nuova struttura.
- Snapshot 5 (cleanup): solo dopo verifiche reali d'uso, rimuovi colonne vecchie o rinsalda vincoli.
Evita una sola enorme migrazione che rinomina tutto in una volta. Spezzala in passi più piccoli che puoi testare e roll backare.
Dopo ogni checkpoint, verifica più del happy path. I flussi CRUD che dipendono dalle tabelle cambiate contano, ma anche gli export (download CSV, fatture, report admin) sono importanti perché spesso usano query vecchie.
Pianifica la strada di rollback prima di iniziare. Se aggiungi una nuova colonna e inizi a scriverci, decidi cosa succede se reverti: il vecchio codice la ignorerà in sicurezza o ti serve una migrazione inversa? Se potresti ritrovarti con dati parzialmente migrati, decidi come lo rileverai e completerai la migrazione, o come abbandonerai la modifica pulitamente.
Prima delle modifiche all'autenticazione: come evitare i lockout
Le modifiche all'autenticazione sono uno dei modi più rapidi per bloccarti (e bloccare gli utenti). Un punto di salvataggio aiuta perché puoi provare una modifica rischiosa, testarla e revertare rapidamente se necessario.
Fai uno snapshot proprio prima di toccare l'aut auth. Poi annota cosa hai oggi, anche se ti sembra ovvio. Questo previene sorprese tipo “pensavo che gli admin potessero ancora accedere”.
Cattura le basi:
- Metodi di login attuali (email/password, magic link, SSO/OAuth, ecc.)
- Ruoli e permessi (cosa può fare un “user” vs un “admin”)
- Regole speciali (invite-only, 2FA obbligatorio, allowlist IP)
- Account di test (un utente normale, un admin)
- Segreti e impostazioni ambiente legati all'aut auth (chiavi, URL di callback, scadenza token)
Quando inizi a cambiare le cose, muovi una regola alla volta. Se modifichi i controlli di ruolo, la logica dei token e le schermate di login insieme, non saprai cosa ha causato il guasto.
Un buon ritmo è: cambia un pezzo, esegui gli stessi controlli rapidi, poi fai snapshot di nuovo se è pulito. Per esempio, quando aggiungi un ruolo “editor”, implementa prima la creazione e l'assegnazione e conferma che i login funzionano. Poi aggiungi una singola regola di permesso e ritesta.
Dopo la modifica, verifica il controllo accessi da tre angolazioni. Gli utenti normali non dovrebbero vedere azioni solo admin. Gli admin devono poter accedere ancora a impostazioni e gestione utenti. Poi prova i casi limite: sessioni scadute, reset password, account disabilitati e utenti che accedono con un metodo che non hai usato nei test.
Un dettaglio che molti dimenticano: i segreti spesso vivono fuori dal codice. Se fai rollback del codice ma lasci nuove chiavi e impostazioni callback, l'aut auth può rompersi in modi confusi. Lascia note chiare su eventuali cambiamenti d'ambiente che hai fatto o che devi revertare.
Prima delle riscritture UI: conservare il progresso senza caos
Make auth changes with confidence
Snapshot before auth work so you can recover fast from lockouts.
Le riscritture UI sono rischiose perché combinano lavoro visivo con cambiamenti di comportamento. Crea un punto di salvataggio quando la UI è stabile e prevedibile, anche se non è bella. Quello snapshot diventa la baseline di lavoro: l'ultima versione che spedirai se devi farlo.
Spezza la riscrittura in fette
Le riscritture UI falliscono se trattate come un grande interruttore. Dividi il lavoro in fette che possano reggere da sole: una schermata, una route o un componente.
Se stai riscrivendo il checkout, spezzalo in Cart, Address, Payment e Confirmation. Dopo ogni fetta, riproduci prima il comportamento vecchio. Poi migliora layout, copy e piccole interazioni. Quando quella fetta è “sufficientemente finita” da mantenere, fai uno snapshot.
Ritestare le parti che di solito si rompono
Dopo ogni fetta, esegui un rapido retest focalizzato su ciò che tipicamente fallisce durante le riscritture:
- Navigazione: puoi ancora raggiungere la schermata dai percorsi principali?
- Form: validazione, campi obbligatori, azioni di submit
- Stati di caricamento e stati vuoti
- Stati di errore (richieste fallite, errori di permesso, retry)
- Comportamento mobile (schermi piccoli, scroll, target tappabili)
Un fallimento comune è questo: la nuova schermata Profilo ha un layout migliore, ma un campo non si salva più perché un componente ha cambiato la forma del payload. Con un buon checkpoint, puoi rollbackare, confrontare e riapplicare i miglioramenti visivi senza perdere giorni di lavoro.
Come rollbackare in sicurezza senza perdere il lavoro buono
Il rollback dovrebbe essere controllato, non una mossa da panico. Prima decidi se serve un rollback completo a un punto noto buono, o un annullamento parziale di una singola modifica.
Un rollback completo ha senso quando l'app è rotta in molti punti (test falliscono, server non parte, login bloccato). Un undo parziale è adatto quando un pezzo singolo è andato storto, come una singola migrazione, una guard route o un componente che causa crash.
Sequenza sicura di rollback
Tratta il tuo ultimo snapshot stabile come base:
- Torna all'ultimo snapshot stabile.
- Conferma che i flussi chiave funzionano di nuovo (avvia l'app, effettua il login, raggiungi la schermata principale, esegui un'azione critica).
- Crea immediatamente un nuovo snapshot, chiamandolo qualcosa come “stable-after-rollback”.
- Riapplica l'iterazione buona in passi più piccoli (una migrazione, una regola auth, una fetta UI).
- Snapshot dopo ogni passo pulito così puoi fermarti proprio prima della parte successiva rischiosa.
Poi dedica cinque minuti alle basi. È facile rollbackare e dimenticare una rottura silenziosa, come un job in background che non parte più.
Controlli rapidi che catturano la maggior parte dei problemi:
- Un nuovo utente può registrarsi e fare login?
- La pagina principale si carica senza errori?
- Le azioni di creazione e salvataggio funzionano (il “percorso del denaro”)?
- I dati sono ancora presenti e leggibili?
Esempio: hai provato una grande refactor dell'aut auth e hai bloccato il tuo account admin. Torna allo snapshot di poco prima della modifica, verifica che puoi entrare, poi riapplica le modifiche in passi più piccoli: prima i ruoli, poi il middleware, poi il gating UI. Se si rompe di nuovo, saprai esattamente quale passo l'ha causato.
Infine, lascia una nota breve: cosa si è rotto, come lo hai notato, cosa l'ha sistemato e cosa farai diversamente la prossima volta. Questo trasforma i rollback in apprendimento invece che in tempo perso.
Errori comuni che rendono i rollback dolorosi
Build safer with planning mode
Map out schema, auth, and UI changes before you generate or edit code.
Il dolore del rollback arriva di solito da punti di salvataggio poco chiari, cambiamenti mescolati e controlli saltati.
Salvare troppo poco è un classico. Le persone spingono attraverso una “tweak” veloce allo schema, una piccola modifica auth e un aggiustamento UI, poi scoprono che l'app è rotta senza un posto pulito dove tornare.
Il problema opposto è salvare costantemente senza note. Dieci snapshot chiamati “test” o “wip” sono praticamente uno snapshot perché non sai quale è sicuro.
Mescolare più cambiamenti rischiosi in un'unica iterazione è un'altra trappola. Se schema, permessi e UI arrivano insieme, un rollback diventa un gioco di indovinelli. Perdi anche l'opzione di mantenere la parte buona (per esempio un miglioramento UI) mentre reverti la parte rischiosa (per esempio una migrazione).
Un altro problema: rollbackare senza controllare assunzioni sui dati e permessi. Dopo un rollback, il database potrebbe ancora contenere nuove colonne, null inaspettati o righe parzialmente migrate. Oppure potresti ripristinare la logica auth vecchia mentre ruoli sono stati creati con le nuove regole. Quel mismatch può sembrare un “rollback che non ha funzionato” quando in realtà ha funzionato.
Se vuoi un modo semplice per evitare la maggior parte di questo:
- Fai snapshot nei punti decisionali (prima e dopo una modifica rischiosa), non solo a fine giornata.
- Scrivi una frase di note: cosa è cambiato, cosa hai testato, cosa significa “buono”.
- Spezza i lavori grandi in chunk separati: schema, poi auth, poi UI.
- Dopo un rollback, verifica lo stato del database e un percorso di permessi reale.
- Riproduci esattamente il fallimento che ha scatenato il rollback, poi conferma che è sparito.
Checklist, un esempio realistico e prossimi passi
Gli snapshot funzionano meglio se abbinati a controlli rapidi. Questi controlli non sono un piano di test completo. Sono un piccolo set di azioni che ti dicono, velocemente, se puoi continuare o se devi revertare.
Controlli rapidi prima di una modifica rischiosa
Esegui questi subito prima di prendere lo snapshot. Stai dimostrando che la versione corrente vale la pena di essere salvata.
- L'app parte e carica senza errori.
- Il login funziona con almeno un utente reale (o un utente di test).
- Un flusso core funziona end-to-end (crea qualcosa, salvalo, rivedilo).
- Il database è raggiungibile e letture base funzionano.
- Riesci a dire in una frase cosa cambierai dopo.
Se qualcosa è già rotto, sistemalo prima. Non salvare un problema a meno che tu non lo stia conservando intenzionalmente per il debugging.
Controlli rapidi dopo una modifica rischiosa
Punta su un happy path, un error path e un controllo di permessi.
- Happy path: completa l'azione principale che hai toccato.
- Error path: scatena un fallimento noto e conferma che il messaggio ha senso.
- Permessi: verifica che un utente che dovrebbe avere accesso lo abbia, e uno che non dovrebbe non lo abbia.
- Ricarica e visita di nuovo: aggiorna e conferma che lo stato non è perso.
- Se c'è una migrazione: controlla una riga vecchia e una nuova.
Esempio: nuovo ruolo utente e redesign della schermata Impostazioni
Immagina che tu stia aggiungendo un nuovo ruolo chiamato “Manager” e riscrivendo la schermata Impostazioni.
-
Parti da una build stabile. Esegui i controlli pre-change, poi fai uno snapshot con un nome chiaro, per esempio: “pre-manager-role + pre-settings-redesign”.
-
Fai prima il lavoro backend sui ruoli (tabelle, permessi, API). Quando ruoli e regole d'accesso si comportano correttamente, fai un altro snapshot: “roles-working”.
-
Poi inizia il redesign della UI delle Impostazioni. Prima di una grande riscrittura di layout, fai uno snapshot: “pre-settings-ui-rewrite”. Se la UI diventa disordinata, torna a quel punto e prova un approccio più pulito senza perdere il lavoro sui ruoli.
-
Quando la nuova UI delle Impostazioni è utilizzabile, fai uno snapshot: “settings-ui-clean”. Solo allora passa alla fase di rifinitura.
Prossimi passi
Prova questo su una piccola feature questa settimana. Scegli una modifica rischiosa, piazza due snapshot attorno (prima e dopo) e pratica un rollback di proposito.
Se stai costruendo su Koder.ai (koder.ai), i suoi snapshot e rollback integrati rendono facile mantenere questo flusso mentre iteri. L'obiettivo è semplice: far sembrare i grandi cambiamenti reversibili, così puoi muoverti rapidamente senza scommettere sulla tua migliore versione funzionante.