08 giu 2025·8 min
Come le garanzie ACID plasmano sistemi transazionali affidabili
Scopri come le garanzie ACID influenzano il design del database e il comportamento delle app. Esplora atomicità, consistenza, isolamento, durabilità, compromessi ed esempi pratici.
Cosa significa “ACID” per le transazioni di tutti i giorni
Quando paghi la spesa, prenoti un volo o trasferisci denaro tra conti, ti aspetti un risultato chiaro: o è riuscito, o non lo è. I database mirano a offrire la stessa certezza—anche quando molti utenti usano il sistema contemporaneamente, i server crashano o la rete balbetta.
Una transazione, in parole semplici
Una transazione è un'unità singola di lavoro che il database tratta come un unico “pacchetto.” Può includere più passaggi—sottrarre inventario, creare un record d'ordine, addebitare una carta e scrivere una ricevuta—but è pensata per comportarsi come una singola azione coerente.
Se uno qualsiasi dei passaggi fallisce, il sistema dovrebbe riavvolgere a un punto sicuro invece di lasciare una situazione a metà.
Perché gli aggiornamenti parziali creano problemi di business reali
Gli aggiornamenti parziali non sono solo guasti tecnici; diventano ticket di assistenza e rischi finanziari. Per esempio:
- Un pagamento viene catturato, ma l'ordine non viene creato—i clienti vengono addebitati senza conferma.
- Un ordine viene creato, ma l'inventario non viene ridotto—il sito sovravende e poi cancella ordini.
- Un bonifico addebita un conto ma non accredita l'altro—i saldi non tornano più.
Questi errori sono difficili da debuggare perché tutto sembra “per lo più corretto,” ma i numeri non tornano.
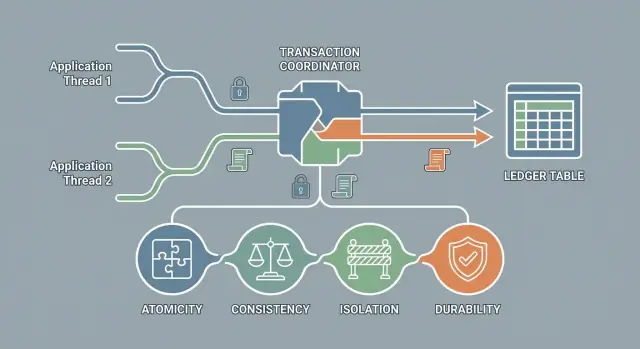
ACID è un insieme di garanzie (non un prodotto)
ACID è un'abbreviazione per quattro garanzie che molti database possono fornire per le transazioni:
- Atomicità: esecuzione tutto o niente
- Consistenza: i dati rimangono nei limiti delle regole valide
- Isolamento: le transazioni concorrenti non interferiscono in modi pericolosi
- Durabilità: una volta confermato, il cambiamento persiste
Non è un marchio di database o una singola opzione da attivare; è una promessa sul comportamento.
Benefici—e i costi che aspettarsi
Garanzie più forti di solito significano che il database deve fare più lavoro: coordinazione extra, attese per lock, tracciamento delle versioni e scrittura su log. Questo può ridurre la throughput o aumentare la latenza sotto carico. L'obiettivo non è “massimo ACID in ogni momento,” ma scegliere le garanzie che corrispondono ai rischi reali del tuo business.
Atomicità: aggiornamenti tutto-o-nulla
L'atomicità significa che una transazione è trattata come un'unità singola di lavoro: o termina completamente o non ha alcun effetto. Non ti ritrovi mai con un “aggiornamento a metà” visibile nel database.
Un semplice esempio di bonifico
Immagina di trasferire $50 da Alice a Bob. Sotto il cofano, questo tipicamente comporta almeno due cambiamenti:
- Sottrarre $50 dal saldo di Alice
- Aggiungere $50 al saldo di Bob
Con l'atomicità, quei due cambiamenti hanno successo insieme o falliscono insieme. Se il sistema non può eseguire entrambi in sicurezza, non deve eseguire nessuno dei due. Questo evita l'incubo in cui Alice viene addebitata ma Bob non riceve i soldi (o Bob li riceve senza che Alice sia stata addebitata).
Commit vs. rollback (in parole semplici)
I database offrono due uscite per le transazioni:
- Commit: “Tutti i passaggi sono riusciti; rendi i risultati ufficiali.”
- Rollback: “Qualcosa è andato storto; annulla tutto ciò che è stato fatto in questa transazione.”
Un modello mentale utile è “bozza vs. pubblica.” Mentre la transazione è in esecuzione, le modifiche sono provvisorie. Solo un commit le pubblica.
Cosa può andare storto a metà transazione?
L'atomicità è importante perché i fallimenti sono normali:
- Crash dell'app: il servizio si ferma dopo aver aggiornato una tabella ma prima di aggiornare la successiva.
- Perdita di rete: l'app non raggiunge il database, o il client non riceve mai la risposta di “successo”.
- Perdita di energia: il server DB si arresta inaspettatamente.
Se uno di questi succede prima che il commit sia completato, l'atomicità assicura che il database possa effettuare il rollback in modo che il lavoro parziale non entri nei saldi reali.
Atomicità più idempotenza e retry
L'atomicità protegge lo stato del database, ma la tua applicazione deve ancora gestire l'incertezza—specialmente quando una perdita di rete rende poco chiaro se un commit sia avvenuto.
Due complementi pratici:
- Retry: ripetere una richiesta quando non si riceve risposta.
- Idempotenza: rendere sicuro ripetere la stessa richiesta (per esempio, usando una chiave di idempotenza in modo che “transfer #123” venga applicato al massimo una volta).
Insieme, transazioni atomiche e retry idempotenti aiutano a evitare sia aggiornamenti parziali sia addebiti doppi accidentali.
Consistenza: mantenere i dati entro regole valide
La consistenza in ACID non significa “i dati sembrano ragionevoli” o “tutte le repliche corrispondono.” Significa che ogni transazione deve portare il database da uno stato valido a un altro stato valido—secondo le regole che definisci.
La consistenza è definita dalle regole che scegli
Un database può mantenere la consistenza solo rispetto a vincoli, trigger e invarianti espliciti che descrivono cosa significa “valido” per il tuo sistema. ACID non inventa queste regole; le applica durante le transazioni.
Esempi comuni includono:
- Foreign key: ogni
order.customer_iddeve puntare a un cliente esistente. - Vincoli di unicità: nessun due utenti possono condividere la stessa email.
- Check / invarianti: un saldo conto non può scendere sotto zero, o la quantità di un articolo non può essere negativa.
Se queste regole sono attive, il database respingerà qualsiasi transazione che le violi—così non ti ritrovi con dati “mezzo validi”.
Validazione nell'app vs. vincoli nel database
La validazione a livello di app è importante, ma non sufficiente da sola.
- Validazione nell'app migliora l'esperienza utente (messaggi chiari, feedback precoce) e può applicare regole di business complesse.
- Vincoli nel database fanno da guardiano finale—soprattutto quando più servizi, job in background, importazioni o strumenti admin scrivono nelle stesse tabelle.
Un fallimento classico è verificare qualcosa nell'app (“email disponibile”) e poi inserire la riga. In concorrenza, due richieste possono superare la verifica simultaneamente. Un vincolo di unicità nel database è ciò che garantisce che solo un inserimento abbia successo.
Cosa significa la consistenza nella pratica
Se codifichi “saldo non negativo” come vincolo (o lo fai rispettare affidabilmente in una singola transazione), allora qualsiasi trasferimento che sconvolgerebbe il conto deve fallire per intero. Se non codifichi quella regola da nessuna parte, ACID non può proteggerla—perché non c'è nulla da far rispettare.
La consistenza riguarda in definitiva l'essere espliciti: definisci le regole, poi lascia che le transazioni assicurino che non vengano mai violate.
Isolamento: lavorare in sicurezza sotto concorrenza
L'isolamento assicura che le transazioni non si pestino i piedi a vicenda. Mentre una transazione è in corso, le altre non dovrebbero vedere lavori a metà o sovrascriverli per errore. L'obiettivo è semplice: ogni transazione dovrebbe comportarsi come se girasse da sola, anche quando molti utenti sono attivi contemporaneamente.
Perché la concorrenza rende difficile questo obiettivo
I sistemi reali sono trafficati: clienti che fanno ordini, agenti di supporto che aggiornano profili, job in background che riconciliano pagamenti—tutto insieme. Queste azioni si sovrappongono nel tempo e spesso toccano le stesse righe (un saldo conto, il conteggio dell'inventario, o uno slot di prenotazione).
Senza isolamento, il timing diventa parte della logica di business. Un aggiornamento “sottrai stock” potrebbe gareggiare con un altro checkout, o un report potrebbe leggere dati a metà cambiamento e mostrare numeri che non sono mai esistiti in uno stato stabile.
L'isolamento è generalmente configurabile
Il pieno isolamento “comportati come se fossi solo” può essere costoso. Può ridurre la throughput, aumentare le attese (lock) o causare retry di transazioni. Nel frattempo, molti flussi di lavoro non necessitano della protezione più severa—per esempio, leggere le analytics di ieri può tollerare piccole incoerenze.
Per questo i database offrono livelli di isolamento configurabili: scegli quanto rischio di concorrenza accettare in cambio di prestazioni migliori e meno conflitti.
Un'anteprima rapida: le anomalie che l'isolamento previene (o permette)
Quando l'isolamento è troppo debole per il tuo carico, incontrerai anomalie classiche:
- Dirty reads: leggere cambiamenti che un'altra transazione non ha ancora confermato.
- Lost updates: due transazioni si sovrascrivono a vicenda e una serie di cambiamenti scompare.
- Phantom reads: rieseguire una query restituisce un set diverso di righe perché un'altra transazione ha inserito o rimosso dati corrispondenti.
Capire questi casi d'errore rende più facile scegliere un livello di isolamento che corrisponda alle promesse del tuo prodotto.
Anomalie comuni che l'isolamento previene (o permette)
Costruisci un workflow sicuro ACID
Trasforma il tuo workflow transazionale in un'app React, Go e PostgreSQL funzionante tramite chat.
L'isolamento determina cosa puoi “vedere” delle altre transazioni mentre la tua è in esecuzione. Quando l'isolamento è troppo debole, ottieni anomalie—comportamenti possibili ma sorprendenti per gli utenti.
Anomalie di lettura
Dirty read avviene quando leggi dati scritti da un'altra transazione ma non ancora commessi.
Scenario: Alex trasferisce $500 da un conto, il saldo diventa temporaneamente $200, e tu leggi quel $200 prima che il trasferimento di Alex fallisca e venga rollbackato.
Esito utente: un cliente vede un saldo errato basso, una regola antifrode si attiva per sbaglio, o un operatore di supporto fornisce una risposta sbagliata.
Non-repeatable read significa che leggi la stessa riga due volte e ottieni valori diversi perché un'altra transazione ha commitato nel frattempo.
Scenario: Carichi il totale di un ordine ($49,00), poi aggiorni i dettagli e vedi $54,00 perché una riga sconto è stata rimossa.
Esito utente: “Il mio totale è cambiato mentre procedeva il checkout,” causando sfiducia o abbandono del carrello.
Phantom read è simile alla non-repeatable read, ma riguarda un insieme di righe: una seconda query restituisce righe in più (o in meno) perché un'altra transazione ha inserito/eliminato record corrispondenti.
Scenario: Una ricerca di hotel mostra “3 camere disponibili,” poi durante la prenotazione il sistema ricontrolla e non ne trova più perché nuove prenotazioni sono state aggiunte.
Esito utente: tentativi di doppia prenotazione, schermate di disponibilità incoerenti o overselling.
Anomalie di scrittura (bug comuni nel mondo reale)
Lost update si verifica quando due transazioni leggono lo stesso valore e entrambe scrivono aggiornamenti, con la scrittura successiva che sovrascrive la precedente.
Scenario: Due admin modificano lo stesso prezzo di prodotto. Partono entrambi da $10; uno salva $12, l'altro salva $11 per ultimo.
Esito utente: la modifica di qualcuno scompare; totali e report sono sbagliati.
Write skew succede quando due transazioni ciascuna applica una modifica che è valida singolarmente, ma insieme violano una regola.
Scenario: Regola: “Almeno un medico on-call deve essere programmato.” Due medici si tolgono entrambi dalla reperibilità dopo aver verificato che l'altro fosse ancora on-call.
Esito utente: rimani senza copertura, nonostante ogni transazione fosse “valida”.
Perché non usare sempre l'isolamento più rigido?
Un isolamento più forte riduce le anomalie ma può aumentare attese, retry e costi sotto alta concorrenza. Molti sistemi scelgono un isolamento più debole per analytics in lettura, mentre usano impostazioni più severe per movimenti di denaro, prenotazioni e altri flussi critici per la correttezza.
Livelli di isolamento: scegliere l'impostazione di sicurezza giusta
L'isolamento riguarda ciò che la tua transazione può “vedere” mentre altre sono in corso. I database lo espongono come livelli di isolamento: livelli più alti riducono i comportamenti sorprendenti, ma possono costare in termini di throughput o aumentare le attese.
I livelli comuni di isolamento
- Read Uncommitted: puoi leggere modifiche di un'altra transazione non ancora commesse (“dirty reads”). Quasi nulla è prevenuto.
- Read Committed: leggi solo dati commessi, quindi i dirty reads sono prevenuti. Ma rieseguendo la stessa query potresti vedere risultati diversi perché qualcun altro ha commitato nel frattempo (“non-repeatable reads”).
- Repeatable Read: le letture già effettuate restano stabili durante la transazione, quindi le non-repeatable reads sono generalmente prevenute. A seconda del motore, potresti comunque vedere “phantoms” o potresti no.
- Serializable: le transazioni si comportano come se fossero eseguite una alla volta. È l'impostazione più forte, generalmente previene dirty reads, non-repeatable reads e phantoms, e riduce molte sottili anomalie di scrittura.
Scegliere un livello: throughput vs. correttezza
I team spesso scelgono Read Committed come default per app user-facing: buone prestazioni e l'assenza di dirty reads corrisponde alle aspettative. Usa Repeatable Read quando ti servono risultati stabili dentro una transazione (es. generare una fattura) e puoi tollerare overhead. Usa Serializable quando la correttezza è più importante della concorrenza (es. far rispettare invarianti complesse come “mai oversellare l'inventario”), o quando non riesci a ragionare facilmente sulle condizioni di gara nel codice applicativo.
Read Uncommitted è raro nei sistemi OLTP; a volte è usato per monitoraggio o reportistica approssimativa dove letture occasionalmente sbagliate sono accettabili.
Avvertenza importante: il comportamento varia
I nomi sono standardizzati, ma le garanzie esatte differiscono per motore database (e talvolta per configurazione). Conferma con la documentazione del tuo database e testa le anomalie che contano per il tuo business.
Durabilità: far sopravvivere i commit
La durabilità significa che una volta che una transazione è commessa, i suoi risultati devono sopravvivere a un crash—perdita di corrente, riavvio del processo o reset improvviso della macchina. Se la tua app dice al cliente “pagamento riuscito,” la durabilità è la promessa che il database non “dimenticherà” quel fatto dopo il prossimo guasto.
Come i database fanno sopravvivere i commit ai crash
La maggior parte dei database relazionali raggiunge la durabilità con il write-ahead logging (WAL). A grandi linee, il database scrive una “ricevuta” sequenziale delle modifiche su un log su disco prima di considerare la transazione commessa. Se il database crasha, può riprodurre il log all'avvio per ripristinare le modifiche commesse.
Per mantenere i tempi di recupero ragionevoli, i database creano anche checkpoint. Un checkpoint è un momento in cui il database assicura che abbastanza delle modifiche recenti siano state scritte nei file di dati principali, così il recovery non deve riprodurre una quantità illimitata di log.
La durabilità dipende dallo storage e dalla configurazione
La durabilità non è un interruttore on/off; dipende da quanto aggressivamente il database forza i dati su storage stabile.
- Con impostazioni sincrone, il database aspetta che il log venga flushato (spesso tramite un
fsynca livello OS) prima di confermare il commit. Questo è più sicuro, ma può aggiungere latenza. - Con impostazioni asincrone, il database può riconoscere il commit prima che il log sia completamente su storage durevole. Le prestazioni possono migliorare, ma un crash può far perdere le transazioni “commesse” più recenti.
L'hardware sottostante conta anche: SSD, controller RAID con cache di scrittura e volumi cloud possono comportarsi diversamente in caso di guasto.
Backup e replica sono correlati—ma diversi
Backup e replica aiutano a recuperare o ridurre i tempi di inattività, ma non sono la stessa cosa della durabilità. Una transazione può essere durabile sul primario anche se non è ancora arrivata su una replica, e i backup sono tipicamente snapshot a punti nel tempo piuttosto che garanzie commit-per-commit.
Come i database applicano ACID sotto il cofano
Sperimenta senza paura
Itera su schemi e scelte di isolamento, poi snapshotta e ripristina quando necessario.
Quando esegui BEGIN e poi COMMIT, il database coordina molte parti in movimento: chi può leggere quali righe, chi può aggiornarle, e cosa succede se due persone tentano di cambiare lo stesso record simultaneamente.
Controllo della concorrenza pessimista vs. ottimistica
Una scelta chiave “sotto il cofano” è come gestire i conflitti:
- Locking pessimista assume che i conflitti siano probabili. Quando una transazione aggiorna una riga, il database la blocca così le altre devono aspettare. Questo previene molte anomalie, ma può causare blocchi.
- Approcci ottimistici assumono che i conflitti siano rari. Le transazioni procedono con meno blocchi e il database rileva i conflitti al commit (o tramite controlli) e può respingere una transazione così che venga ritentata.
Molti sistemi mischiano le due idee in base al carico e al livello di isolamento.
MVCC: i lettori non bloccano gli scrittori
I database moderni spesso usano MVCC (Multi-Version Concurrency Control): invece di tenere una sola copia di una riga, il database mantiene più versioni.
- I lettori possono vedere uno snapshot consistente (una versione più vecchia) senza aspettare.
- Gli scrittori possono creare una nuova versione mentre le letture continuano.
Questo è un motivo importante per cui alcuni database gestiscono molte letture e scritture contemporanee con meno blocchi—anche se i conflitti write/write devono ancora essere risolti.
Deadlock: quando l'attesa forma un ciclo
I lock possono portare a deadlock: la Transazione A aspetta un lock tenuto da B, mentre B aspetta un lock tenuto da A.
I database tipicamente risolvono questo rilevando il ciclo e abbandonando una transazione (la “vittima del deadlock”), restituendo un errore così l'app può ritentare.
Segnali pratici che qualcosa non va
Se l'applicazione soffre per l'applicazione di ACID, vedrai spesso:
- Aumenti delle attese per lock durante i picchi
- Timeout (query che falliscono dopo aver aspettato troppo)
- Hotspot di contesa (poche righe/tabelle aggiornate costantemente, come contatori o campi “last seen”)
Questi sintomi spesso significano che è ora di rivedere la dimensione delle transazioni, gli indici o quale strategia di isolamento/locking si adatta al carico.
Come ACID influenza le decisioni di design dell'applicazione
Le garanzie ACID non sono solo teoria del database—influenzano come progetti API, job in background e persino i flussi UI. L'idea centrale è semplice: decidi quali passi devono riuscire insieme, poi racchiudi solo quei passi in una transazione.
Progettare API attorno a “un cambiamento di business”
Una buona API transazionale di solito mappa a una singola azione di business, anche se tocca più tabelle. Per esempio, un'operazione /checkout potrebbe: creare un ordine, riservare inventario e registrare un intento di pagamento. Quelle scritture dovrebbero tipicamente vivere in una transazione in modo che commitino insieme (o rollbackino insieme) se una validazione fallisce.
Un pattern comune è:
- Esegui la validazione degli input prima di aprire la transazione.
- Apri una transazione.
- Esegui il minimo di letture/scritture richieste.
- Commit.
Questo mantiene atomicità e consistenza evitando transazioni lente e fragili.
Confini transazionali in richieste, servizi e job
Dove posizioni i confini delle transazioni dipende da cosa significa “un'unità di lavoro”:
- Richieste utente: Mantieni le transazioni brevi—idealmente poche query. Non tenere lock mentre generi viste o aspetti risposte esterne.
- Job in background: Tratta ogni tentativo di job come un'unità di lavoro. Se un job elabora 10.000 record, fai commit a batch in modo da poter ripartire in sicurezza.
- Confini di servizio: Preferisci mantenere una transazione all'interno del database di un singolo servizio. Attraversare servizi di solito richiede un approccio diverso (come l'outbox), perché una transazione ACID non copre facilmente più database.
Gestione degli errori: rollback, retry e replay sicuri
ACID aiuta, ma l'applicazione deve ancora gestire correttamente i fallimenti:
- Rollback su errore: Se un passaggio fallisce, abortire la transazione così gli aggiornamenti parziali non trapelano.
- Retry su errori transitori: Errori di serializzazione e deadlock sono normali sotto concorrenza. Ritentare l'intera transazione è spesso la soluzione giusta.
- Operazioni idempotenti: Se una richiesta viene ritentata (dal client o dal job runner), dovresti poterla “riprodurre in sicurezza” senza raddoppiare addebiti o spedizioni—usa chiavi di idempotenza e vincoli unici.
Anti-pattern comuni
Evita transazioni lunghe, chiamare API esterne dentro una transazione, e tempo di pensiero dell'utente dentro una transazione (per esempio, “blocca la riga del carrello, chiedi conferma all'utente”). Queste pratiche aumentano la contesa e rendono i conflitti di isolamento molto più probabili.
Dove gli strumenti possono aiutare (senza cambiare i fondamenti)
Se stai costruendo un sistema transazionale velocemente, il rischio maggiore raramente è “non conoscere ACID”—è disperdere un'azione di business su più endpoint, job o tabelle senza un confine transazionale chiaro.
Piattaforme come Koder.ai possono aiutarti a muoverti più velocemente mantenendo il design attorno ad ACID: puoi descrivere un workflow (per esempio, “checkout con riserva inventario e intento di pagamento”) in una chat orientata alla pianificazione, generare una UI React più un backend Go + PostgreSQL, e iterare con snapshot/rollback se uno schema o il confine della transazione deve cambiare. Il database continua a far rispettare le garanzie; il valore è accelerare il percorso da un design corretto a un'implementazione funzionante.
ACID in sistemi distribuiti e multi-servizio
Trasforma le garanzie in codice
Passa dalla teoria ACID a un'implementazione che puoi iterare con snapshot e rollback.
Un singolo database può solitamente offrire garanzie ACID all'interno di un confine transazionale. Quando distribuisci il lavoro su più servizi (e spesso più database), quelle stesse garanzie diventano più difficili da mantenere—e più costose quando ci provi.
Coerenza vs. disponibilità: il compromesso che senti in produzione
La coerenza stretta significa che ogni lettura vede la “verità commessa più recente.” L'alta disponibilità significa che il sistema continua a rispondere anche quando parti sono lente o irraggiungibili.
In un setup multi-servizio, un problema di rete temporaneo può forzare una scelta: bloccare o fallire le richieste finché ogni partecipante non è d'accordo (più consistente, meno disponibile), o accettare che i servizi possano essere brevemente fuori sincronia (più disponibile, meno consistente). Nessuna scelta è sempre giusta—dipende dagli errori che il tuo business può tollerare.
Perché le transazioni distribuite sono difficili
Le transazioni distribuite richiedono coordinazione attraverso confini che non controlli completamente: ritardi di rete, retry, timeout, crash di servizio e fallimenti parziali.
Anche se ogni servizio è corretto, la rete può creare ambiguità: il servizio di pagamento ha committato ma il servizio ordine non ha mai ricevuto la conferma? Per risolvere questo in modo sicuro, i sistemi usano protocolli di coordinamento (come two-phase commit), che possono essere lenti, ridurre la disponibilità in caso di failure e aggiungere complessità operativa.
Pattern pratici che sostituiscono “una grande transazione”
Sagas spezzano un workflow in passi, ciascuno commitato localmente. Se un passo successivo fallisce, i passi precedenti vengono “annullati” con azioni compensative (es. rimborsare un addebito).
Outbox/inbox rende affidabile la pubblicazione e il consumo di eventi. Un servizio scrive i dati di business e un record “da pubblicare” nello stesso database locale (outbox). I consumer registrano gli ID dei messaggi processati (inbox) per gestire retry senza duplicare effetti.
Eventual consistency accetta finestre temporanee in cui i dati differiscono tra servizi, con un piano chiaro di riconciliazione.
Quando rilassare le garanzie—e come controllare il rischio
Rilassa le garanzie quando:
- Puoi tollerare discrepanze temporanee (stato spedizione che lagga dietro la creazione dell'ordine).
- Puoi correggere errori con compensazioni (refund, cancellazioni).
- La latenza e l'uptime contano più della correttezza globale istantanea.
Controlla il rischio definendo invarianti (cosa non deve mai essere violato), progettando operazioni idempotenti, usando timeout e retry con backoff, e monitorando la deriva (sagas bloccate, compensazioni ripetute, tabelle outbox in crescita). Per invarianti davvero critiche (es. “mai spendere oltre il saldo”), mantienile all'interno di un singolo servizio e di un singolo database transazionale quando possibile.
Checklist pratica: progettare, testare e monitorare sistemi ACID
Una transazione può essere “corretta” in un test unitario e comunque fallire sotto traffico reale, riavvii e concorrenza. Usa questa checklist per mantenere le garanzie ACID allineate con il comportamento in produzione.
1) Design: definisci invarianti e confine transazionale
Inizia scrivendo cosa deve sempre essere vero (le tue invarianti di dati). Esempi: “saldo account mai negativo,” “totale ordine uguale alla somma delle righe,” “inventario non può scendere sotto zero,” “un pagamento è legato esattamente a un ordine.” Tratta queste regole come regole di prodotto, non trivia del DB.
Poi decidi cosa deve stare dentro una transazione e cosa può essere rimandato.
- Invarianti dati: elenca tabelle/righe coinvolte e la regola esatta.
- Scenari di fallimento: crash del processo a metà richiesta, timeout di rete dopo il commit, retry che causa duplicati, failover di replica, disco pieno.
- Profilo di concorrenza: quali operazioni girano in parallelo (picchi di checkout, aggiornamenti batch, job schedulati), punti di contesa previsti e se le letture devono essere “in tempo reale” o possono essere leggermente stale.
Mantieni le transazioni piccole: tocca meno righe, fai meno lavoro (nessuna chiamata API esterna) e committa rapidamente.
2) Test: dimostra il comportamento sotto race e guasti
Rendi la concorrenza una dimensione di test di prima classe.
- Test per condizioni di gara: esegui la stessa operazione critica in parallelo (es. due checkout per l'ultimo articolo) e asserisci che le invarianti non si rompano.
- Fault injection: kill il processo app a metà transazione; inietta timeout; simula retry; forza un riavvio DB; verifica che gli esiti siano o commessi una volta o rollback sicuro.
- Load test con controlli di correttezza: sotto throughput massimo, valida non solo la latenza ma anche totali, conteggi e vincoli “no duplicati”.
Se supporti i retry, aggiungi una chiave di idempotenza esplicita e testa “richiesta ripetuta dopo successo.”
3) Monitor: cattura i dolori ACID prima degli utenti
Monitora indicatori che le garanzie stanno diventando costose o fragili:
- Lock waits e tempi di coda (aumento della contesa)
- Deadlock (frequenza, query vittime)
- Transazioni long-running (spesso causa principale)
- Lag di replica (letture stale e failover ritardati)
- Tempi di commit/fsync (pressione sullo storage; costo della durabilità)
Allerta sulle tendenze, non solo sui picchi, e collega le metriche agli endpoint o job che le causano.
Regole pratiche: isolamento e ambito della transazione
Usa il livello di isolamento più debole che protegga le tue invarianti; non "massimizzarlo" di default. Quando hai bisogno di correttezza stretta per una piccola sezione critica (movimenti di denaro, decremento inventario), restringi la transazione a quella sezione e tieni tutto il resto fuori.
Domande frequenti
Cosa significa ACID in un database, in termini pratici?
ACID è un insieme di garanzie transazionali che aiutano i database a comportarsi in modo prevedibile in caso di guasti e concorrenza:
- Atomicità: tutti i passaggi riescono oppure nessuno viene applicato
- Consistenza: ogni commit preserva le regole/vincoli che hai definito
- Isolamento: le transazioni concorrenti non creano interferenze pericolose
- Durabilità: le modifiche confermate sopravvivono ai crash
Cos'è una transazione e perché è importante?
Una transazione è una singola “unità di lavoro” che il database tratta come un pacchetto. Anche se esegue più istruzioni SQL (es. creare un ordine, decrementare l'inventario, registrare un intento di pagamento), ha solo due esiti:
- Commit: tutte le modifiche diventano ufficiali
- Rollback: nessuna delle modifiche ha effetto
Perché gli aggiornamenti parziali sono un grande problema di business?
Perché gli aggiornamenti parziali creano contraddizioni reali difficili e costose da correggere, ad esempio:
- cliente addebitato ma nessun ordine registrato
- ordine registrato ma inventario non ridotto (overselling)
- una parte di un trasferimento applicata ma non l'altra
ACID (soprattutto atomicità + consistenza) impedisce che questi stati “metà finiti” diventino verità visibili.
Come previene l'atomicità le operazioni a metà?
L'atomicità garantisce che il database non esponga mai una transazione “a metà completamento”. Se qualcosa fallisce prima del commit—crash dell'app, perdita di rete, riavvio del DB—la transazione viene rollbackata così che i passaggi precedenti non fuoriescano nello stato persistente.
In pratica, l'atomicità rende sicuri cambiamenti multi-step (ad es. un trasferimento che aggiorna due saldi).
Se ACID è sicuro, perché ho ancora bisogno di idempotenza e retry?
Non sempre sai se un commit è avvenuto quando il client perde la risposta (es. timeout di rete subito dopo il commit). Combina ACID con:
- Retry per errori transitori
- Chiavi di idempotenza (o vincoli unici) in modo che ripetere la stessa richiesta venga applicato al più una volta
Questo evita sia aggiornamenti parziali sia addebiti/doppi invii accidentali.
Cosa significa “consistenza” in ACID (e cosa non significa)?
In ACID, “consistenza” significa che il database passa da uno stato valido a un altro stato valido in base alle regole che definisci—vincoli, foreign key, unicità e check.
Se non codifichi una regola (es. “il saldo non può essere negativo”), ACID non può proteggerla automaticamente. Il database ha bisogno di invarianti esplicite per far rispettare la consistenza.
Perché usare vincoli nel database se la mia applicazione valida già gli input?
La validazione nell'app migliora l'UX e può applicare regole complesse, ma può fallire sotto concorrenza (due richieste che passano la stessa verifica simultaneamente).
I vincoli nel database sono il guardiano finale:
- Vincoli di unicità evitano email duplicate
- Foreign key evitano record orfani
- Check/invarianti evitano valori non validi
Usa entrambi: valida presto nell'app, fai rispettare definitivamente nel database.
Quali tipi di bug di concorrenza protegge l'isolamento?
L'isolamento controlla cosa la tua transazione può osservare mentre altre sono in esecuzione. Un'isolamento debole può produrre anomalie come:
- Dirty reads: leggendo dati non ancora commessi
- Non-repeatable reads: la stessa riga cambia tra due letture
- Phantom reads: un'interrogazione restituisce un set diverso di righe
- Lost updates / write skew: scritture concorrenti che rompono la correttezza
I livelli di isolamento ti permettono di scegliere il compromesso fra prestazioni e protezione contro queste anomalie.
Come scelgo un livello di isolamento senza distruggere le prestazioni?
Un buon punto di partenza pratico è Read Committed per molte applicazioni OLTP: impedisce i dirty reads e offre buone prestazioni. Salire quando necessario:
- Repeatable Read per letture stabili all'interno di una transazione (es. generare una fattura)
- Serializable per invarianti critici (es. evitare oversell) quando puoi tollerare più contesa/retry
Conferma sempre il comportamento sul tuo specifico motore database perché i dettagli variano.
Cosa garantisce la durabilità e cosa può indebolirla?
La durabilità garantisce che una volta che il database conferma un commit, la modifica sopravviverà ai crash. Tipicamente ciò si ottiene con il write-ahead logging (WAL) e i checkpoint.
Fai attenzione alle configurazioni:
- Commit sincrono/fsync: più sicuro, può aumentare la latenza
- Impostazioni asincrone: più veloce, ma si possono perdere transazioni “committed” recenti in caso di crash
Backup e replica aiutano nel recupero/disponibilità, ma non sono la stessa cosa della durabilità.