03 apr 2025·8 min
Gestire lo stato tra frontend e backend nelle app AI
Scopri come lo stato dell'interfaccia, della sessione e dei dati si sposta tra frontend e backend nelle app AI, con pattern pratici per sincronizzazione, persistenza, caching e sicurezza.
Cosa significa “stato” in un'app costruita con AI
“Stato” è tutto ciò che la tua app deve ricordare per comportarsi correttamente da un momento all'altro.
Se un utente clicca Invia in un'interfaccia di chat, l'app non dovrebbe dimenticare cosa ha scritto, cosa ha già risposto l'assistente, se una richiesta è ancora in corso o quali impostazioni (tono, modello, strumenti) sono attive. Tutto questo è stato.
Stato, in termini semplici
Un modo utile per pensare allo stato è: la verità corrente dell'app—valori che influenzano ciò che l'utente vede e ciò che il sistema farà dopo. Include cose ovvie come i campi dei form, ma anche fatti “invisibili” come:
- In quale conversazione si trova l'utente
- Se l'ultima risposta è in streaming o completata
- L'elenco dei messaggi e il loro ordine
- Chiamate a strumenti e risultati degli strumenti (risultati di ricerca, lookup su DB, estrazioni da file)
- Errori, ritentativi e backoff per rate-limit
Perché le app AI hanno più parti in movimento
Le app tradizionali spesso leggono dati, li mostrano e salvano aggiornamenti. Le app AI aggiungono passaggi e output intermedi:
- Una singola azione utente può scatenare più operazioni backend (chiamata LLM, chiamata a uno strumento, altra chiamata LLM).
- Le risposte possono arrivare in modo incrementale (token in streaming), quindi l'UI deve gestire lo stato parziale.
- Il contesto è importante: il sistema può aver bisogno di mantenere memoria della conversazione, output degli strumenti e impostazioni del modello coerenti tra le richieste.
Questo movimento aggiuntivo è il motivo per cui la gestione dello stato è spesso la complessità nascosta nelle applicazioni AI.
Cosa tratteremo in questa guida
Nelle sezioni seguenti, divideremo lo stato in categorie pratiche (stato UI, stato di sessione, dati persistenti e stato del modello/runtime) e mostreremo dove dovrebbe risiedere ciascuno (frontend vs backend). Tratteremo anche sincronizzazione, caching, job a lunga esecuzione, aggiornamenti in streaming e sicurezza—perché lo stato è utile solo se è corretto e protetto.
Esempio rapido
Immagina una chat in cui un utente chiede: “Riepiloga le fatture del mese scorso e segnala eventuali anomalie.” Il backend potrebbe (1) recuperare le fatture, (2) eseguire uno strumento di analisi, (3) streammare un sommario all'UI, e (4) salvare il rapporto finale.
Perché questo sia fluido, l'app deve tenere traccia di messaggi, risultati degli strumenti, progresso e output salvato—senza confondere conversazioni o far trapelare dati tra utenti.
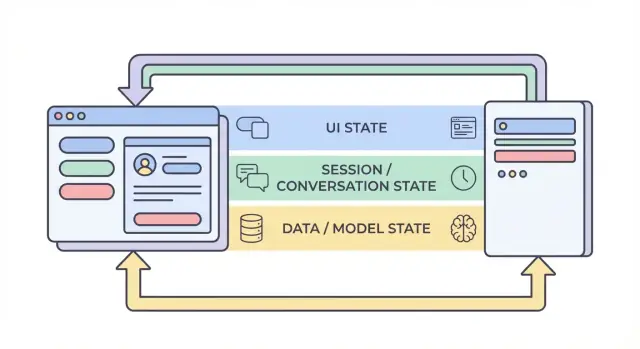
I quattro livelli di stato: UI, sessione, dati e modello
Quando si parla di “stato” in un'app AI, spesso si mescolano cose molto diverse. Dividere lo stato in quattro livelli—UI, sessione, dati e modello/runtime—rende più semplice decidere dove qualcosa dovrebbe vivere, chi può modificarla e come dovrebbe essere memorizzata.
1) Stato UI (cosa fa l'utente in questo momento)
Lo stato UI è lo stato live, momento per momento, nel browser o nell'app mobile: input di testo, toggle, elementi selezionati, quale scheda è aperta e se un pulsante è disabilitato.
Le app AI aggiungono qualche dettaglio specifico di UI:
- Indicatori di caricamento e stati di “pensiero”
- Token in streaming (testo parziale che appare man mano che viene generato)
- Bozze locali dei messaggi (prima di inviarli)
Lo stato UI dovrebbe essere facile da resettare e sicuro da perdere. Se l'utente ricarica la pagina, potresti perderlo—e di solito va bene.
2) Stato di sessione / conversazione (contesto condiviso per il flusso dell'utente)
Lo stato di sessione lega un utente a un'interazione in corso: identità utente, un ID conversazione e una vista consistente della cronologia dei messaggi.
Nelle app AI, spesso include:
- Cronologia dei messaggi (o riferimenti a essa)
- Tracce degli strumenti (quali funzioni/strumenti sono stati chiamati e con quali risultati)
- Scelte del “working set” come progetto/documento corrente, modello selezionato o workspace
Questo livello spesso attraversa frontend e backend: il frontend tiene identificatori leggeri, mentre il backend è l'autorità per la continuità della sessione e il controllo degli accessi.
3) Stato dati (record duraturi nello storage)
Lo stato dati è ciò che memorizzi intenzionalmente in un database: progetti, documenti, embedding, preferenze, log di audit, eventi di fatturazione e trascrizioni di conversazioni salvate.
A differenza di UI e sessione, lo stato dati dovrebbe essere:
- Durevole (sopravvive ai riavvii)
- Interrogabile (puoi cercarlo/filtrarlo)
- Auditabile (puoi capire cosa è successo in seguito)
4) Stato modello / runtime (come l'AI è configurata ora)
Lo stato modello/runtime è la configurazione operativa usata per produrre una risposta: prompt di sistema, strumenti abilitati, temperature/max tokens, impostazioni di sicurezza, rate limit e cache temporanee.
Una parte è configurazione (predefiniti stabili); una parte è effimera (cache a breve durata o budget di token per richiesta). La maggior parte di questo appartiene al backend in modo da poter essere controllata in modo coerente e non esposta inutilmente.
Perché la separazione riduce i bug
Quando questi livelli si confondono, ottieni fallimenti classici: l'UI mostra testo che non è stato salvato, il backend usa impostazioni di prompt differenti da quelle che il frontend si aspetta, o la memoria della conversazione “perde” dati tra utenti. Confini chiari creano fonti di verità più chiare—e rendono ovvio cosa deve persistere, cosa può essere ricalcolato e cosa deve essere protetto.
Cosa vive nel frontend vs. backend (e perché)
Un modo affidabile per ridurre i bug nelle app AI è decidere, per ogni pezzo di stato, dove dovrebbe risiedere: nel browser (frontend), sul server (backend) o in entrambi. Questa scelta influenza affidabilità, sicurezza e quanto “sorprendente” appare l'app quando gli utenti ricaricano, aprono una nuova scheda o perdono connessione.
Stato frontend: veloce, temporaneo e guidato dall'utente
Lo stato frontend è ideale per cose che cambiano rapidamente e non devono sopravvivere a un refresh. Tenerlo locale rende l'UI reattiva ed evita chiamate API inutili.
Esempi comuni solo frontend:
- Testo bozza del messaggio che l'utente sta scrivendo
- Filtri locali e ordine in una tabella
- Stato di modali aperti/chiusi, scheda selezionata, stati hover
Se perdi questo stato con un refresh, di solito è accettabile (e spesso ci si aspetta).
Stato backend: autorevole, sensibile e condiviso
Il backend dovrebbe contenere tutto ciò che deve essere trusted, auditabile o applicato in modo coerente. Questo include stato che altri dispositivi/schede devono vedere o che deve rimanere corretto anche se il client viene modificato.
Esempi comuni solo backend:
- Permessi e ruoli (cosa l'utente è autorizzato a fare)
- Stato di fatturazione/sottoscrizione e limiti di utilizzo
- Job a lunga esecuzione (indicizzazione documenti, esportazioni grandi, fine-tune) e il loro stato
Una buona mentalità: se uno stato scorretto potrebbe costare soldi, far trapelare dati o rompere i controlli di accesso, appartiene al backend.
Stato condiviso: coordinato, ma con una fonte di verità
Alcuni stati sono naturalmente condivisi:
- Titolo della conversazione
- Fonti di conoscenza selezionate per una chat
- Campi profilo utente usati su dispositivi diversi
Anche quando condivisi, scegli una “fonte di verità.” Tipicamente il backend è autorevole e il frontend ne conserva una copia in cache per velocità.
Regola pratica (e un anti-pattern comune)
Tieni lo stato più vicino a dove serve, ma persisti ciò che deve sopravvivere a refresh, cambi di dispositivo o interruzioni.
Evita l'anti-pattern di memorizzare stato sensibile o autorevole solo nel browser (per esempio, trattare un flag isAdmin client-side, il piano dell'utente o lo stato di completamento di un job come verità). L'UI può mostrare questi valori, ma il backend deve verificarli.
Ciclo tipico di una richiesta AI: dal click al completamento
Una funzionalità AI sembra un’unica azione, ma è davvero una catena di transizioni di stato condivise tra browser e server. Capire il ciclo di vita aiuta a evitare UI disallineate, contesti mancanti e addebiti duplicati.
1) Azione utente → frontend prepara l'intento
Un utente clicca Invia. L'UI aggiorna immediatamente lo stato locale: può aggiungere una bolla messaggio “pending”, disabilitare il pulsante di invio e catturare gli input correnti (testo, allegati, strumenti selezionati).
A questo punto il frontend dovrebbe generare o allegare identificatori di correlazione:
- conversation_id: a quale thread appartiene
- message_id: l'ID client per il nuovo messaggio utente
- request_id: unico per ogni tentativo (utile per i retry)
Questi ID consentono a entrambi i lati di parlare dello stesso evento anche quando le risposte arrivano in ritardo o duplicate.
2) Chiamata API → server valida e persiste
Il frontend invia una richiesta API con il messaggio utente più gli ID. Il server valida permessi, rate limits e forma del payload, quindi persiste il messaggio utente (o almeno un registro immutabile) indicizzato da conversation_id e message_id.
Questo passaggio di persistenza previene una “cronologia fantasma” quando l'utente ricarica a metà richiesta.
3) Server ricostruisce il contesto
Per chiamare il modello, il server ricostruisce il contesto dalla sua fonte di verità:
- Recupera i messaggi recenti per il conversation_id
- Estrae record correlati (documenti, preferenze, output degli strumenti)
- Applica policy di conversazione (prompt di sistema, regole di memoria, troncamento)
L'idea chiave: non fare affidamento sul client per fornire la storia completa. Il client può essere obsoleto.
4) Esecuzione modello/strumenti → stato intermedio
Il server può chiamare strumenti (ricerca, query DB) prima o durante la generazione del modello. Ogni chiamata a strumento produce stato intermedio che dovrebbe essere tracciato rispetto al request_id così da poter essere auditato e ritentato in sicurezza.
5) Risposta (streaming o no) → completamento in UI
Con lo streaming, il server invia token/ eventi parziali. L'UI aggiorna incrementale il messaggio assistente in pending, ma lo considera “in corso” finché un evento finale non segna il completamento.
6) Punti di failure da pianificare
Retry, submit duplicati e risposte fuori ordine accadono. Usa request_id per deduplicare sul server e message_id per riconciliare in UI (ignora chunk tardivi che non combaciano con la richiesta attiva). Mostra sempre uno stato chiaro di “failed” con un retry sicuro che non generi messaggi duplicati.
Sessioni e memoria della conversazione: mantenere il contesto senza caos
Esporta e possiedi il codice
Genera veloce, poi esporta il codice sorgente per estenderlo a tuo modo.
Una sessione è il “filo” che collega le azioni di un utente: quale workspace è aperto, cosa ha cercato per ultimo, quale bozza stava modificando e a quale conversazione deve proseguire una risposta AI. Buono stato di sessione rende l'app continua tra le pagine—e idealmente tra i dispositivi—senza trasformare il backend in un deposito di tutto ciò che l'utente ha detto.
Obiettivi dello stato di sessione
Punta a: (1) continuità (un utente può partire e tornare), (2) correttezza (l'AI usa il contesto giusto per la conversazione giusta) e (3) contenimento (una sessione non dovrebbe trapelare in un'altra). Se supporti più dispositivi, tratta le sessioni come scoperte per utente più dispositivo: “stesso account” non significa sempre “stessa sessione aperta”.
Cookie vs token vs sessioni server
Solitamente sceglierai uno di questi modi per identificare la sessione:
- Cookie: il più semplice per le web app perché il browser li invia automaticamente. Ottimi per sessioni tradizionali, ma devi impostare flag di sicurezza (
HttpOnly,Secure,SameSite) e gestire CSRF. - Token (es. JWT): utili per API e app mobili perché il client li allega esplicitamente. Scalabili, ma la revoca e rotazione richiedono design aggiuntivo (e non dovresti mettere stato sensibile dentro il token).
- Sessioni server: il server memorizza dati di sessione (spesso in Redis) e il client mantiene solo un session ID opaco. Più semplice da revocare e aggiornare, ma devi eseguire e scalare lo store di sessione.
Strategie di memoria della conversazione
“La memoria” è solo lo stato che scegli di rimandare nel modello.
- Storia completa: più accurata, ma costosa e può esporre contenuti sensibili vecchi.
- Storia sommaria: mantieni un sommario continuo più pochi turni recenti; più economico e di solito “sufficientemente buono”.
- Contesto a finestra: solo gli ultimi N messaggi; semplice, ma può perdere decisioni importanti precedenti.
Un pattern pratico è sommario + finestra: è prevedibile e aiuta a evitare comportamenti sorprendenti del modello.
Chiamate a strumenti: riproducibili e auditabili
Se l'AI usa strumenti (ricerca, query DB, lettura file), memorizza ogni chiamata allo strumento con: input, timestamp, versione dello strumento e output restituito (o un riferimento a esso). Questo ti permette di spiegare “perché l'AI ha detto così”, riprodurre run per debug e rilevare quando i risultati cambiano perché uno strumento o dataset è cambiato.
Guardrail per la privacy
Non memorizzare memoria a lungo termine per default. Conserva solo ciò che serve per la continuità (ID conversazione, sommari e log strumenti), imposta limiti di retention e evita di persistere testo utente grezzo a meno che non ci sia una chiara ragione di prodotto e consenso dell'utente.
Sincronizzare lo stato in sicurezza: fonti di verità e gestione dei conflitti
Lo stato diventa rischioso quando la stessa “cosa” può essere modificata in più posti—la tua UI, una seconda scheda del browser o un job in background che aggiorna una conversazione. La soluzione è meno codice furbo e più chiara proprietà.
Definire le fonti di verità
Decidi quale sistema è autorevole per ogni pezzo di stato. Nella maggior parte delle applicazioni AI, il backend dovrebbe possedere il record canonico per ciò che deve essere corretto: impostazioni conversazione, permessi strumenti, cronologia messaggi, limiti di fatturazione e stato dei job. Il frontend può cache-are e derivare stato per velocità (scheda selezionata, testo bozza, indicatori “sta scrivendo”), ma dovrebbe assumere che il backend abbia ragione in caso di mismatch.
Una regola pratica: se ti disturberebbe perderlo con un refresh, probabilmente appartiene al backend.
UI ottimistica (usala con cautela)
Gli aggiornamenti ottimistici rendono l'app istantanea: toggli un'impostazione, aggiorni subito l'UI, poi confermi col server. Funziona bene per azioni a basso rischio e reversibili (es. mettere una conversazione tra i preferiti).
Crea confusione quando il server potrebbe rifiutare o trasformare il cambiamento (controlli permessi, limiti di quota, validazione o default lato server). In quei casi, mostra uno stato “salvataggio in corso…” e aggiorna l'UI solo dopo la conferma.
Gestire conflitti (due schede, una conversazione)
I conflitti succedono quando due client aggiornano lo stesso record partendo da versioni diverse. Esempio comune: Tab A e Tab B cambiano entrambi la temperatura del modello.
Usa versioning leggero così il backend può rilevare scritture stale:
- Timestamp
updated_at(semplice e leggibile) - ETag / header
If-Match(nativo HTTP) - Numeri di revisione incrementali (rilevazione esplicita dei conflitti)
Se la versione non coincide, ritorna un conflitto (spesso HTTP 409) e restituisci l'oggetto server aggiornato.
Progetta API per ridurre i mismatch
Dopo una scrittura, fai in modo che l'API ritorni l'oggetto salvato come persistito (inclusi default generati dal server, campi normalizzati e la nuova versione). Questo permette al frontend di sostituire immediatamente la sua copia cache—un aggiornamento della fonte di verità invece di indovinare cosa è cambiato.
Caching e performance: velocizzare senza stato stale
Il caching è uno dei modi più rapidi per far sembrare un'app AI istantanea, ma crea anche una seconda copia dello stato. Se cacheri la cosa sbagliata—o nel posto sbagliato—spedirai un'UI veloce ma confusa.
Cosa cachare sul client
Le cache client-side dovrebbero concentrarsi sull'esperienza, non sull'autorità. Buoni candidati includono anteprime recenti delle conversazioni (titoli, snippet dell'ultimo messaggio), preferenze UI (tema, modello selezionato, stato della sidebar) e stato ottimistico (messaggi in “invia”).
Mantieni la cache client piccola e usa: se viene cancellata, l'app dovrebbe comunque funzionare rifacendo fetch dal server.
Cosa cachare sul server
Le cache server-side dovrebbero concentrarsi su lavoro costoso o ripetuto frequentemente:
- Risultati di strumenti riutilizzabili (es. previsioni meteo per la stessa città entro 5 minuti)
- Lookup di embedding e risultati di ricerca vettoriale per query ripetute (spesso con TTL brevi)
- Stato di rate-limit e contatori di throttling (per proteggere la tua API e costi)
Qui puoi anche cachare stato derivato come conteggi di token, decisioni di moderazione o output di parsing documenti—qualunque cosa deterministica e costosa.
Basi di invalidazione della cache (senza complicarsi)
Tre regole pratiche:
- Usa chiavi di cache chiare che codifichino gli input (
user_id, modello, parametri dello strumento, versione del documento). - Imposta TTL basati su quanto rapidamente cambiano i dati sottostanti. Un TTL breve batte logiche troppo complesse.
- Ignora la cache quando la correttezza è più importante della velocità: dopo che un utente aggiorna un documento, cambia permessi o richiede un refresh.
Se non sai spiegare quando una entry di cache diventa errata, non la cacheare.
Non cachare segreti o dati personali in cache condivise
Evita di mettere chiavi API, token di auth, prompt grezzi contenenti testo sensibile o contenuto user-specific in layer condivisi come CDN. Se devi cacheare dati utente, isola per utente e cifra a riposo—or tienili nel database primario.
Misura l'impatto: velocità vs UI stale
Il caching deve essere dimostrato, non dato per scontato. Monitora la latenza p95 prima/dopo, hit rate della cache e errori visibili dall'utente come “messaggio aggiornato dopo il rendering.” Una risposta veloce che poi contraddice l'UI è spesso peggiore di una leggermente più lenta ma coerente.
Persistenza e lavori a lunga esecuzione: job, code e stato di avanzamento
Previeni duplicati da retry
Fai sì che Koder.ai incorpori request ID e chiavi di idempotenza negli endpoint.
Alcune funzionalità AI finiscono in un secondo. Altre richiedono minuti: upload e parsing di un PDF, embedding e indicizzazione di una knowledge base, o workflow multi-step di strumenti. Per questi, lo “stato” non è solo ciò che c'è sullo schermo—è ciò che sopravvive a refresh, retry e tempo.
Cosa persistere (e perché)
Persisti solo ciò che abilita reale valore di prodotto.
Cronologia conversazioni è ovvio: messaggi, timestamp, identità utente e (spesso) quale modello/strumentazione è stata usata. Questo abilita “riprendi dopo”, tracciabilità e supporto migliore.
Impostazioni utente e workspace dovrebbero vivere nel database: modello preferito, default di temperature, feature toggles, prompt di sistema e preferenze UI che devono seguire l'utente su dispositivi.
File e artefatti (upload, testo estratto, report generati) sono solitamente in object storage con record DB che li puntano. Il DB contiene metadata (owner, dimensione, content type, stato di processo), mentre il blob store contiene i byte.
Job in background per attività lunghe
Se una richiesta non può finire entro un timeout HTTP normale, sposta il lavoro in una coda.
Un pattern tipico:
- Il frontend chiama un'API tipo
POST /jobscon input (file id, conversation id, parametri). - Il backend mette in coda un job (estrazione, indicizzazione, run batch di strumenti) e ritorna subito un
job_id. - I worker processano i job asincronamente e scrivono i risultati nello storage persistente.
Questo mantiene l'UI reattiva e rende i retry più sicuri.
Stato del job di cui l'UI può fidarsi
Rendi lo stato del job esplicito e interrogabile: queued → running → succeeded/failed (opzionalmente canceled). Memorizza queste transizioni server-side con timestamp e dettagli di errore.
Sul frontend, rifletti lo stato chiaramente:
- Queued/running: mostra uno spinner e disabilita azioni duplicate.
- Failed: mostra un errore conciso e un pulsante Retry.
- Succeeded: carica l'artefatto risultante o aggiorna la conversazione.
Espone GET /jobs/{id} (polling) o stream di aggiornamenti (SSE/WebSocket) così l'UI non deve indovinare.
Chiavi di idempotenza: retry senza scritture duplicate
I timeout di rete accadono. Se il frontend ritenta POST /jobs, non vuoi due job identici (e due fatture).
Richiedi una Idempotency-Key per ogni azione logica. Il backend memorizza la chiave con il job_id/risultato e ritorna lo stesso risultato per richieste ripetute.
Politiche di cleanup e scadenza
Le app AI a lunga esecuzione accumulano dati velocemente. Definisci regole di retention presto:
- Scadere le conversazioni vecchie dopo N giorni (o lasciare che l'utente configuri).
- Eliminare artefatti derivati quando la risorsa sorgente è cancellata.
- Pulire periodicamente job falliti e file intermedi.
Tratta il cleanup come parte della gestione dello stato: riduce rischio, costi e confusione.
Risposte in streaming e aggiornamenti in tempo reale: gestire lo stato parziale
Lo streaming rende lo stato più complicato perché la “risposta” non è più un singolo blob. Hai a che fare con token parziali (testo che arriva parola per parola) e a volte lavoro strumentale parziale (una ricerca inizia e finisce dopo). Questo significa che UI e backend devono essere d'accordo su cosa è temporaneo e cosa è finale.
Backend: stream di eventi tipizzati, non solo testo
Un pattern pulito è streammare una sequenza di piccoli eventi, ciascuno con un tipo e un payload. Per esempio:
token: testo incrementale (o un piccolo chunk)tool_start: una chiamata a strumento è iniziata (es. “Searching…”, con un id)tool_result: l'output dello strumento è pronto (stesso id)done: il messaggio dell'assistente è completoerror: qualcosa è fallito (includi un messaggio user-safe e un debug id)
Questo stream di eventi è più facile da versionare e debuggare rispetto al solo testo in streaming, perché il frontend può renderizzare il progresso accuratamente (e mostrare lo stato degli strumenti) senza indovinare.
Frontend: aggiornamenti append-only, poi commit finale
Sul client, tratta lo streaming come append-only: crea un messaggio assistente “draft” e continua ad estenderlo mentre arrivano gli eventi token. Quando ricevi done, esegui un commit: marca il messaggio come finale, persistilo (se lo memorizzi localmente) e sblocca azioni come copia, vota o rigenera.
Questo evita di riscrivere la storia a metà stream e mantiene l'UI prevedibile.
Gestire interruzioni (cancel, drop, timeout)
Lo streaming aumenta la possibilità di lavori a metà:
- Utente annulla: invia un segnale di cancel; smetti di renderizzare token; mantieni la bozza visibilmente cancellata.
- Perdita di rete: interrompi lo stream; mostra “riconnettendo…” e non presumere il completamento.
- Timeout/errore server: finalizza la bozza come failed e fornisci un retry che inizi una nuova richiesta (non unire silentemente stream differenti).
Reidratazione: ricaricare e ricostruire stato stabile
Se la pagina si ricarica a metà stream, ricostruisci dallo stato stabile più recente: gli ultimi messaggi commessi più eventuali metadati bozza memorizzati (message id, testo accumulato finora, stati strumenti). Se non puoi riprendere lo stream, mostra la bozza come interrotta e lascia che l'utente ritenti, invece di fingere che sia completata.
Sicurezza e privacy: proteggere lo stato end-to-end
Aggiungi job di background in modo pulito
Modella flussi queued-running-succeeded e mostra il progresso affidabile nell'UI.
Lo stato non è solo “dati che memorizzi”—è prompt dell'utente, upload, preferenze, output generati e i metadata che legano tutto insieme. Nelle app AI, quello stato può essere insolitamente sensibile (info personali, documenti proprietari, decisioni interne), quindi la sicurezza deve essere progettata in ogni layer.
Mantieni i segreti sul server
Qualsiasi cosa che permetta a un client di impersonare la tua app deve restare lato backend: chiavi API, connettori privati (Slack/Drive/credenziali DB) e prompt di sistema interni o logica di routing. Il frontend può richiedere un'azione (“riassumi questo file”), ma il backend dovrebbe decidere come eseguirla e con quali credenziali.
Autorizza ogni scrittura (e molte letture)
Tratta ogni mutazione di stato come un'operazione privilegiata. Quando il client prova a creare un messaggio, rinominare una conversazione o allegare un file, il backend dovrebbe verificare:
- L'utente è autenticato.
- L'utente possiede la risorsa (conversation, workspace, project).
- L'utente è autorizzato a compiere quell'azione (ruolo, limiti del piano, policy org).
Questo previene attacchi di “ID guessing” dove qualcuno scambia un conversation_id e accede alla cronologia di un altro utente.
Non fidarti mai del browser: valida e sanitizza
Assumi che qualsiasi stato fornito dal client sia input non fidato. Valida schema e vincoli (tipi, lunghezze, enum consentiti) e sanitizza per la destinazione (SQL/NoSQL, log, rendering HTML). Se accetti “aggiornamenti di stato” (es. impostazioni, parametri strumenti), whitelist dei campi consentiti invece di fare merge di JSON arbitrario.
Tracce di audit per azioni critiche
Per azioni che cambiano stato duraturo—condivisione, esportazione, cancellazione, accesso a connettori—registra chi ha fatto cosa e quando. Un log di audit leggero aiuta nella risposta a incidenti, supporto clienti e compliance.
Minimizzazione dei dati e cifratura
Memorizza solo ciò che serve per la funzionalità. Se non ti servono i prompt completi per sempre, considera finestre di retention o redazione. Cifra lo stato sensibile a riposo dove appropriato (token, credenziali connettori, documenti uploadati) e usa TLS in transito. Separa metadata operativi dal contenuto in modo da poter restringere gli accessi più strettamente.
Architettura di riferimento pratica e checklist di build
Un default utile per le app AI è semplice: il backend è la fonte di verità, il frontend è una cache veloce e ottimistica. L'UI può sembrare istantanea, ma tutto ciò che ti dispiacerebbe perdere (messaggi, stato job, output strumenti, eventi rilevanti per la fatturazione) dovrebbe essere confermato e memorizzato server-side.
Se costruisci con un workflow di “vibe-coding”—dove molta superficie prodotto viene generata rapidamente—il modello di stato diventa ancora più importante. Piattaforme come Koder.ai possono aiutare i team a spedire app web, backend e mobile partendo da una chat, ma la stessa regola vale: l'iterazione rapida è più sicura quando le fonti di verità, gli ID e le transizioni di stato sono progettati fin dall'inizio.
Architettura di riferimento (una che puoi mettere in produzione)
Frontend (browser/mobile)
- Stato UI: pannelli aperti, testo bozza, modello selezionato, indicatori temporanei di “typing”.
- Stato cacheato dal server: conversazioni recenti, ultimo stato job conosciuto, buffer parziale di streaming.
- Una sola pipeline di request che allega sempre:
session_id,conversation_ide un nuovorequest_id.
Backend (API + worker)
- Servizio API: valida input, crea record, fornisce risposte in streaming.
- Store duraturo (SQL/NoSQL): conversazioni, messaggi, chiamate a strumenti, stato job.
- Queue + worker: task a lunga esecuzione (RAG indexing, parsing file, generazione immagini).
- Cache (opzionale): letture calde (sommari conversazioni, metadata embedding), sempre indicizzate con versioni/timestamp.
Nota: un modo pratico per mantenere coerenza è standardizzare lo stack backend presto. Per esempio, i backend generati da Koder.ai usano comunemente Go con PostgreSQL (e React sul frontend), il che rende semplice centralizzare lo stato “autorevole” in SQL mantenendo la cache client usa e getta.
Progetta prima il tuo modello di stato
Prima di costruire schermate, definisci i campi su cui farai affidamento in ogni layer:
- ID e proprietà:
user_id,org_id,conversation_id,message_id,request_id. - Timestamp e ordinamento:
created_at,updated_ate unasequenceesplicita per i messaggi. - Campi di stato:
queued | running | streaming | succeeded | failed | canceled(per job e chiamate a strumenti). - Versioning:
etagoversionper aggiornamenti sicuri contro i conflitti.
Questo previene il bug classico dove l'UI “sembra corretta” ma non riesce a riconciliare retry, refresh o modifiche concorrenti.
Usa shape API coerenti
Mantieni endpoint prevedibili tra le feature:
GET /conversations(lista)GET /conversations/{id}(get)POST /conversations(create)POST /conversations/{id}/messages(append)PATCH /jobs/{id}(update status)GET /streams/{request_id}oPOST .../stream(stream)
Ritorna lo stesso envelope ovunque (inclusi errori) così il frontend può aggiornare lo stato in modo uniforme.
Aggiungi osservabilità dove lo stato può rompersi
Logga e ritorna un request_id per ogni chiamata AI. Registra input/output delle chiamate a strumenti (con redazione), latenza, retry e stato finale. Rendilo facile rispondere a: “Cosa ha visto il modello, quali strumenti sono stati eseguiti e che stato abbiamo persistito?”
Checklist di build (per evitare bug comuni di stato)
- Il backend è la fonte di verità; la cache frontend è chiaramente etichettata e usa e getta.
- Ogni scrittura è idempotente (sicura da ritentare) usando
request_id(e/o Idempotency-Key). - Le transizioni di stato sono esplicite e validate (niente salti silenziosi da
queuedasucceeded). - Gli aggiornamenti in streaming si fondono tramite ID/sequenza, non con la logica “last message wins”.
- I conflitti sono gestiti tramite
version/etago regole di merge server-side. - PII e segreti non vengono mai memorizzati nello stato client; redigi i log per default.
- Esiste una vista dashboard per il debug: requests, chiamate strumenti, stato job ed errori.
Quando adotti cicli di sviluppo più veloci (inclusa generazione assistita dall'AI), considera di aggiungere guardrail che forzano questi punti della checklist automaticamente—validazione schema, idempotenza e streaming event-driven—così “muoversi veloce” non si traduce in drift di stato. In pratica, è qui che una piattaforma end-to-end come Koder.ai può essere utile: accelera la delivery e allo stesso tempo permette di esportare il codice sorgente mantenendo pattern coerenti di gestione dello stato tra web, backend e mobile.