15 nov 2025·8 min
TypeScript e C# di Hejlsberg: strumenti che fanno scalare il codice
Come Anders Hejlsberg ha plasmato C# e TypeScript per migliorare l'esperienza dello sviluppatore: tipi, servizi del linguaggio, refactor e loop di feedback che fanno scalare le codebase.
Perché l'esperienza dello sviluppatore conta quando le codebase crescono
Una codebase raramente rallenta perché gli ingegneri improvvisamente dimenticano come programmare. Rallenta perché il costo di capire le cose aumenta: comprendere moduli sconosciuti, fare una modifica in sicurezza e dimostrare che la modifica non ha rotto altro.
Man mano che un progetto cresce, il “cerca e modifica” smette di funzionare. Cominci a pagare per ogni indizio mancante: API poco chiare, pattern incoerenti, autocomplete debole, build lente ed errori poco utili. Il risultato non è solo una consegna più lenta—è una consegna più cauta. I team evitano refactor, rimandano pulizie e inviano cambi più piccoli e sicuri che non fanno progredire il prodotto.
Perché Anders Hejlsberg è rilevante qui
Anders Hejlsberg è una figura chiave dietro sia C# che TypeScript—due linguaggi che trattano l'esperienza dello sviluppatore (DX) come una caratteristica di prima classe. Questo conta perché un linguaggio non è solo sintassi e comportamento a runtime; è anche l'ecosistema di tooling attorno a esso: editor, strumenti di refactoring, navigazione e la qualità del feedback che ricevi mentre scrivi codice.
Questo articolo guarda TypeScript e C# con una lente pratica: come le loro scelte di design aiutano i team a muoversi più velocemente quando sistemi e squadre si espandono.
Cosa significa davvero “scalare”
Quando diciamo che una codebase sta “scalando”, di solito intendiamo diverse pressioni contemporanee:
- Dimensione del team: più contributori, più stili, più overhead di coordinamento.
- Dimensione del codice: più moduli, più dipendenze, più aree “sconosciute”.
- Velocità di cambiamento: rilasci più frequenti e flussi di lavoro paralleli.
Il tooling forte riduce la tassa creata da queste pressioni. Aiuta gli ingegneri a rispondere subito a domande comuni: “Dove è usato questo?”, “Cosa si aspetta questa funzione?”, “Cosa cambia se rinomino questo?”, e “È sicuro rilasciare questo?”. Questa è l'esperienza dello sviluppatore—e spesso è la differenza tra una grande codebase che evolve e una che si fossilizza.
L'influenza di Anders Hejlsberg: una lente pratica
L'influenza di Anders Hejlsberg è più facile da osservare non come una serie di citazioni o traguardi personali, ma come una filosofia di prodotto coerente che appare nel tooling mainstream: rendere il lavoro comune veloce, rendere gli errori ovvi presto e rendere i cambi su larga scala più sicuri.
Questa sezione non è una biografia. È una lente pratica per capire come il design del linguaggio e l'ecosistema di tooling circostante possano modellare la cultura ingegneristica quotidiana. Quando i team parlano di “buona DX”, spesso intendono cose che sono state progettate volontariamente in sistemi come C# e TypeScript: autocomplete prevedibile, impostazioni sensate, refactor di cui ti puoi fidare ed errori che ti indicano una correzione invece di rigettare semplicemente il tuo codice.
Come si manifesta l'“influenza” nella cultura del tooling
Puoi osservare l'impatto nelle aspettative che gli sviluppatori ora portano ai linguaggi e agli editor:
- Gli editor dovrebbero comprendere il codice, non solo colorarlo.
- Navigazione, rinomina e “trova riferimenti” dovrebbero funzionare su tutto il repo.
- I tipi (dove disponibili) dovrebbero migliorare la produttività, non rallentarla.
- Il tooling dovrebbe restare abbastanza veloce da usarlo costantemente, non solo prima di un rilascio.
Questi risultati sono misurabili nella pratica: meno errori a runtime evitabili, refactor più sicuri e meno tempo speso a “riapprendere” una codebase quando si entra in un team.
Perché confrontare C# e TypeScript
C# e TypeScript girano in ambienti diversi e servono pubblici differenti: C# è spesso usato per applicazioni server-side e enterprise, mentre TypeScript punta all'ecosistema JavaScript. Ma condividono un obiettivo DX simile: aiutare gli sviluppatori a muoversi velocemente riducendo il costo del cambiamento.
Confrontarli è utile perché separa i principi dalla piattaforma. Quando idee simili funzionano in due runtime molto diversi—linguaggio statico su runtime gestito (C#) e un livello tipato sopra JavaScript (TypeScript)—significa che il risultato non è casuale. È il risultato di scelte di design esplicite che danno priorità a feedback, chiarezza e manutenibilità su scala.
I tipi statici come meccanismo di scaling (non solo una preferenza)
La tipizzazione statica spesso viene inquadrata come questione di gusto: “Mi piacciono i tipi” vs. “Preferisco la flessibilità”. In codebase grandi, è meno una preferenza e più economia. I tipi sono un modo per mantenere il lavoro quotidiano prevedibile mentre più persone toccano più file più spesso.
Cosa ti danno i tipi forti giorno per giorno
Un sistema di tipi solido dà nomi e forme alle promesse del tuo programma: cosa si aspetta una funzione, cosa restituisce e quali stati sono permessi. Questo trasforma la conoscenza implicita (nella testa di qualcuno o nascosta nella documentazione) in qualcosa che il compilatore e il tooling possono far rispettare.
Praticamente, significa meno conversazioni del tipo “Aspetta, questo può essere null?”, autocomplete più chiaro, navigazione più sicura attraverso moduli sconosciuti e revisioni del codice più veloci perché l'intento è codificato nell'API.
Controlli a compile-time vs fallimenti a runtime
I controlli a compile-time falliscono presto, spesso prima che il codice venga unito. Se passi il tipo d'argomento sbagliato, dimentichi un campo obbligatorio o usi male un valore di ritorno, il compilatore lo segnala immediatamente.
I fallimenti a runtime emergono più tardi—forse in QA, forse in produzione—quando un particolare percorso di codice viene eseguito con dati reali. Quei bug sono generalmente più costosi: sono più difficili da riprodurre, interrompono gli utenti e creano lavoro reattivo.
I tipi statici non impediscono ogni bug a runtime, ma rimuovono una grande classe di errori “non avrebbe mai dovuto compilare”.
Fallimenti che i tipi aiutano a prevenire quando si scala
Quando i team crescono, i punti di rottura comuni sono:
- Contratti poco chiari: i moduli non dichiarano cosa garantiscono, quindi l'uso devia.
- Refactor non sicuri: rinomine e modifiche alle firme saltano call site in modo silenzioso.
- Accoppiamento nascosto: parti non correlate dipendono dalla stessa forma di oggetto vagamente definita.
I tipi fungono da mappa condivisa. Quando cambi un contratto, ottieni un elenco concreto di cosa deve essere aggiornato.
I compromessi (reali, ma gestibili)
La tipizzazione ha costi: curva di apprendimento, annotazioni aggiuntive (soprattutto ai confini) e attrito occasionale quando il sistema di tipi non riesce a esprimere chiaramente ciò che intendi. La chiave è usare i tipi in modo strategico—più intensamente sulle API pubbliche e sulle strutture dati condivise—così ottieni i benefici di scaling senza trasformare lo sviluppo in burocrazia.
Loop di feedback veloci: il vantaggio nascosto dei linguaggi moderni
Un loop di feedback è il piccolo ciclo che ripeti tutto il giorno: modifica → verifica → correggi. Cambi una riga, i tuoi strumenti la verificano immediatamente e correggi ciò che non va prima che la tua attenzione cambi contesto.
Feedback lento: quando i bug viaggiano lontano
In un loop lento, “verifica” significa principalmente avviare l'app e affidarsi a test manuali (o aspettare la CI). Quel ritardo trasforma piccoli errori in cacce al tesoro:
- Invi il codice.
- I test falliscono più tardi (o peggio, gli utenti lo segnalano).
- Qualcuno deve ricostruire l'intento, riprodurre il problema e applicare una patch sotto pressione.
Più lungo è il divario tra modifica e scoperta, più costosa diventa ogni correzione.
Feedback veloce: editor + compilatore come compagno di squadra
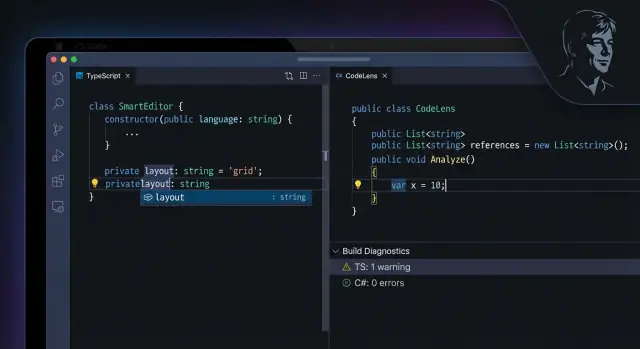
I linguaggi moderni e il loro tooling accorciano il ciclo a secondi. In TypeScript e C#, il tuo editor può segnalare problemi mentre digiti, spesso con una correzione suggerita.
Esempi concreti che vengono catturati presto:
- Proprietà mancante: accedi a
user.address.zip, maaddressnon è garantito esista. - Tipo parametro sbagliato: passi una stringa dove è richiesto un numero (o un enum specifico).
- Codice irraggiungibile: un
returnrende il resto della funzione impossibile da eseguire.
Questi non sono “tranelli”—sono scivoloni comuni che gli strumenti veloci trasformano in correzioni immediate.
Perché questo conta di più nei team
Il feedback veloce riduce i costi di coordinamento. Quando compilatore e language service catturano le discrepanze immediatamente, meno problemi sfuggono alla code review, alla QA o ai flussi di lavoro di altri team. Ciò significa meno scambi (“Cosa intendevi qui?”), meno build rotte e meno sorprese del tipo “qualcuno ha cambiato un tipo e la mia feature è esplosa”.
Su scala, la velocità non è solo performance a runtime—è quanto rapidamente gli sviluppatori possono essere certi che la loro modifica è valida.
Tooling che sembra nativo: servizi del linguaggio e integrazione IDE
“Language services” è un nome semplice per l'insieme di funzionalità dell'editor che rendono il codice ricercabile e sicuro da toccare. Pensa a: autocomplete che comprende il tuo progetto, “vai alla definizione” che salta al file giusto, rinomina che aggiorna ogni utilizzo e diagnostiche che sottolineano i problemi prima che esegua nulla.
TypeScript: il compilatore come assistente sempre attivo
L'esperienza editor di TypeScript funziona perché il compilatore TypeScript non serve solo a produrre JavaScript—alimenta anche il TypeScript Language Service, il motore dietro molte funzionalità IDE.
Quando apri un progetto TS in VS Code (o altri editor che parlano lo stesso protocollo), il language service legge il tuo tsconfig, segue le importazioni, costruisce un modello del programma e risponde continuamente a domande come:
- Di che tipo è questo valore in questo momento?
- Quale overload viene chiamato?
- Dove è definito questo simbolo nell'intero workspace?
Per questo TypeScript può offrire autocomplete accurato, rinomine sicure, vai-alla-definizione, “trova tutte le referenze”, correzioni rapide e errori inline mentre stai ancora digitando. In grandi repository ricchi di JavaScript, quel loop serrato è un vantaggio di scala: gli sviluppatori possono modificare moduli sconosciuti e ottenere guida immediata su cosa si romperà.
C#: compilatore + IDE che lavorano come un'unità
C# beneficia dello stesso principio, con integrazione IDE particolarmente profonda nei flussi di lavoro comuni (in particolare Visual Studio e anche VS Code tramite language server). La piattaforma del compilatore supporta analisi semantica ricca e l'IDE aggiunge refactor, azioni di codice, navigazione a livello di progetto e feedback al tempo di build.
Questo è importante quando i team crescono: spendi meno tempo a “compilare mentalmente” la codebase. Invece, gli strumenti possono confermare l'intento—mostrandoti il simbolo reale che stai chiamando, le aspettative di nullability, i call site impattati e se una modifica si propaga attraverso i progetti.
Perché questo scala oltre la comodità
A piccole dimensioni, il tooling è un nice-to-have. A grandi dimensioni, è come i team si muovono senza paura. Forti language services rendono il codice sconosciuto più facile da esplorare, più semplice da cambiare in sicurezza e più agevole da revisionare—perché gli stessi fatti (tipi, riferimenti, errori) sono visibili a tutti, non solo alla persona che ha scritto il modulo.
Supporto al refactoring: rendere il cambiamento economico e affidabile
Mantieni i loop di feedback stretti
Costruisci una vera app con un ciclo edit-check-fix veloce, direttamente dalla chat.
Il refactoring non è un evento di “pulizie di primavera” da fare dopo il lavoro vero. In grandi codebase, è il lavoro reale: rimodellare continuamente il codice affinché nuove funzionalità non diventino ogni mese più lente e rischiose.
Quando un linguaggio e il suo tooling rendono il refactor sicuro, i team possono mantenere i moduli piccoli, i nomi accurati e i confini chiari—senza programmare una riscrittura rischiosa di settimane.
I refactor di cui avrai bisogno ogni giorno
Il supporto IDE moderno in TypeScript e C# tende a concentrarsi su pochi spostamenti ad alto rendimento:
- Rinomina sicura per variabili, metodi, classi, file e moduli
- Estrai metodo/funzione per trasformare blocchi lunghi in unità leggibili e testabili
- Sposta simbolo (es. spostare una classe in un file/namespace/modulo diverso) mantenendo import/usings corretti
- Organizza import/usings per ridurre rumore e evitare conflitti sottili
Sono azioni piccole, ma su larga scala fanno la differenza tra “possiamo cambiare questo” e “nessuno tocchi quel file”.
Perché il refactoring richiede comprensione semantica (non solo ricerca testuale)
La ricerca testuale non può dire se due parole identiche si riferiscano allo stesso simbolo. I veri strumenti di refactor usano la comprensione del compilatore—tipi, scope, overload, risoluzione moduli—per aggiornare il significato, non solo i caratteri.
Questo modello semantico permette di rinominare un'interfaccia senza toccare una stringa letterale, o spostare un metodo e correggere automaticamente ogni importazione e riferimento.
Modalità di fallimento che un buon tooling ti fa evitare
Senza refactoring semantico, i team spediscono rotture evitabili:
- Riferimenti rotti dopo rinomine o spostamenti
- Call site mancanti a causa di pattern dinamici, overload o nomi shadowati
- Modifiche accidentali a commenti/stringhe invece che al codice
- API mezze aggiornate dove alcuni file compilano e altri divergono silenziosamente
Qui l'esperienza dello sviluppatore diventa direttamente throughput ingegneristico: cambiare in sicurezza significa cambiare di più, prima—e con meno paura nel codice.
L'approccio di TypeScript: sicurezza graduale per un mondo JavaScript
TypeScript ha successo in gran parte perché non chiede ai team di “ricominciare da capo”. Accetta che la maggior parte dei progetti reali inizi come JavaScript—disordinato, rapido e già in produzione—e ti permette di sovrapporre sicurezza senza bloccare il momentum.
Tipizzazione strutturale, inferenza e tipizzazione graduale (in parole semplici)
TypeScript usa la tipizzazione strutturale, il che significa che la compatibilità si basa sulla forma di un valore (i suoi campi e metodi), non sul nome di un tipo dichiarato. Se un oggetto ha { id: number }, può solitamente essere usato ovunque quella forma sia attesa—anche se proviene da un modulo diverso o non è stato esplicitamente “dichiarato” come quel tipo.
Fa molto affidamento anche sull'inferenza dei tipi. Spesso ottieni tipi significativi senza scriverli:
const user = { id: 1, name: "Ava" }; // inferred as { id: number; name: string }
Infine, TypeScript è graduale: puoi mescolare codice tipato e non tipato. Puoi annotare prima i confini più critici (risposte API, utility condivise, moduli core del dominio) e lasciare il resto per dopo.
“Aggiungi tipi mentre procedi” rende l'adozione realistica
Questo percorso incrementale è il motivo per cui TypeScript si adatta a codebase JavaScript esistenti. I team possono convertire file uno alla volta, accettare qualche any all'inizio e ottenere comunque vantaggi immediati: autocomplete migliore, refactor più sicuri e contratti di funzione più chiari.
La severità è una manopola che i team alzano nel tempo
La maggior parte delle organizzazioni inizia con impostazioni moderate, poi aumenta la severità man mano che la codebase si stabilizza—abilitando opzioni come strict, irrigidendo noImplicitAny o migliorando la copertura di strictNullChecks. L'importante è progresso senza paralisi.
Una breve avvertenza: i tipi esprimono l'intento, non la verità
I tipi modellano ciò che ti aspetti accada; non provano il comportamento a runtime. Hai ancora bisogno di test—soprattutto per le regole di business, i confini di integrazione e tutto ciò che riguarda I/O o dati non fidati.
L'approccio di C#: feature di produttività che scalano i team
Progetta per il cambiamento fin da subito
Inizia un nuovo modulo con confini puliti, poi iteralo mentre cambiano i requisiti.
C# è cresciuto attorno a un'idea semplice: fare in modo che il modo “normale” di scrivere codice sia anche il più sicuro e leggibile. Questo è importante quando una codebase smette di essere qualcosa che una sola persona può tenere in testa e diventa un sistema condiviso mantenuto da molti.
Leggibilità e intento come impostazioni predefinite
C# moderno punta su una sintassi che legge come intento di business più che meccanica. Piccole feature si sommano: inizializzazione oggetti più chiara, pattern matching per “gestire queste forme di dati” ed espressive switch expressions che riducono if annidati.
Quando dozzine di sviluppatori toccano gli stessi file, questi strumenti riducono la necessità di conoscenza tribale. Le code review diventano meno decifrare e più validare il comportamento.
Sicurezza che si adatta al codice reale
Uno dei miglioramenti di scala più pratici è la nullabilità. Invece di trattare null come una sorpresa sempre presente, C# aiuta i team a esprimere l'intento:
- “Questo valore non può mai essere null” (così i consumatori possono farci affidamento)
- “Questo potrebbe essere null” (così i chiamanti sono spinti a gestire il caso)
Questo sposta molti difetti dalla produzione al compile time, ed è particolarmente utile in team numerosi dove le API sono usate da persone che non le hanno scritte.
Ergonomia di async/await: concorrenza scalabile per esseri umani
Man mano che i sistemi crescono, aumentano le chiamate di rete, I/O su file e lavori in background. async/await di C# rende il codice asincrono leggibile come codice sincrono, riducendo il carico cognitivo della concorrenza.
Invece di infilare callback in tutto il codice, i team possono scrivere flussi lineari—recupera dati, valida, poi continua—mentre il runtime gestisce l'attesa. Il risultato sono meno bug legati al timing e meno convenzioni personalizzate che i nuovi membri devono apprendere.
Tooling che resta utile in soluzioni grandi
La storia di produttività di C# è inseparabile dai suoi servizi del linguaggio e dall'integrazione IDE. In grandi solution, un forte tooling cambia ciò che è fattibile giorno per giorno:
- Navigazione veloce attraverso progetti (vai alla definizione, trova riferimenti)
- Analisi a livello di solution che cattura cambiamenti rompenti presto
- Refactor sicuri e automatizzati (rinomina, estrai metodo, cambia firma)
Così i team mantengono lo slancio. Quando l'IDE può rispondere affidabilmente a “dove è usato questo?” e “cosa romperà questa modifica?”, gli sviluppatori migliorano proattivamente invece di evitare il cambiamento.
Una “pit of success” coerente
Il pattern duraturo è la coerenza: attività comuni (gestione del null, flussi async, refactor) sono supportate sia dal linguaggio sia dagli strumenti. Questa combinazione trasforma buone abitudini ingegneristiche nella strada più semplice—esattamente ciò che desideri quando scalare una codebase e il team che la mantiene.
Diagnostiche e messaggi di errore che insegnano (non solo bloccano)
Quando una codebase è piccola, un errore vago può andare bene. Su scala, le diagnostiche diventano parte del sistema di comunicazione del team. TypeScript e C# riflettono entrambi una tendenza “alla Hejlsberg”: messaggi che non solo ti fermano, ma ti mostrano come procedere.
Come sono fatti i buoni messaggi di errore
Le diagnostiche utili tendono a condividere tre tratti:
- Azione concreta: suggeriscono il passo successivo (“Intendevi…”, “Aggiungi un controllo null”, “Converti in async”).
- Specifiche: nominano il simbolo esatto, il tipo atteso o il membro mancante invece di descrivere solo la categoria di fallimento.
- Locali: indicano l'area più piccola di codice responsabile, così puoi correggere senza scavare in file non correlati.
Questo conta perché gli errori si leggono spesso sotto pressione. Un messaggio che insegna riduce i rimbalzi e trasforma il tempo “bloccato” in tempo di apprendimento.
Warning vs error: perché gli avvisi proteggono il tuo futuro
Gli errori impongono correttezza ora. Gli avvisi proteggono la salute a lungo termine: API deprecate, codice irraggiungibile, uso discutibile del null, implicit any e altri problemi del tipo “funziona oggi, ma potrebbe rompersi dopo”.
I team possono trattare gli avvisi come una ratchetta graduale: iniziare permissivi, poi irrigidirsi nel tempo (e idealmente evitare che il numero di avvisi aumenti).
Le diagnostiche come standard di team e carburante per l'onboarding
Diagnostiche coerenti creano codice coerente. Invece di affidarsi alla conoscenza tribale (“qui non si fa così”), gli strumenti spiegano la regola nel momento in cui conta.
Questo è un vantaggio di scala: i nuovi arrivati possono risolvere problemi che non hanno mai visto prima perché il compilatore e l'IDE documentano essenzialmente l'intento—direttamente nella lista di errori.
Performance e incrementalità: mantenere gli strumenti veloci su scala
Quando una codebase cresce, il feedback lento diventa una tassa quotidiana. Raramente appare come un singolo “grande” problema; è la morte per mille attese: build più lunghe, suite di test più lente e pipeline CI che trasformano controlli rapidi in interruzioni di ore.
Il dolore di scala che si percepisce
Alcuni sintomi comuni emergono tra i team e gli stack:
- I tempi di build aumentano man mano che progetti, codice generato e dipendenze si accumulano.
- I tempi dei test esplodono, specialmente quando “esegui tutto” diventa la scelta predefinita.
- I ritardi della CI causano PR accavallate, più conflitti di merge e revisioni basate su congetture anziché risultati verificati.
- Lag dell'editor (autocomplete, vai alla definizione, rinomina) fa sì che gli sviluppatori aggirino gli strumenti anziché lavorare con essi.
Perché l'incrementalità cambia l'esperienza
I toolchain moderni trattano sempre di più “ricompila tutto” come ultima risorsa. L'idea chiave è semplice: la maggior parte delle modifiche interessa solo una piccola fetta del programma, quindi gli strumenti dovrebbero riutilizzare il lavoro precedente.
La compilazione incrementale e il caching si basano tipicamente su:
- Tracciamento delle dipendenze: sapere quali file/moduli dipendono da cosa.
- Risultati intermedi stabili: mantenere alberi di sintassi parsati, informazioni sui tipi o output compilati che possono essere riutilizzati.
- Invalidazione intelligente: ricalcolare solo ciò che è cambiato—e ciò che deve cambiare di conseguenza.
Questo non riguarda solo build più veloci. È ciò che permette ai servizi del linguaggio “live” di restare reattivi mentre digiti, anche in repository di grandi dimensioni.
Reattività dell'editor come barriera di qualità
Considera la reattività dell'IDE come una metrica di prodotto, non un extra. Se rinomina, trova riferimenti e diagnostiche impiegano secondi, le persone smettono di fidarsi—e smettono di refattorizzare.
Modi pratici per mantenere il feedback veloce
Stabilisci budget espliciti (per esempio: build locale sotto X minuti, azioni chiave dell'editor sotto Y ms, controlli CI sotto Z minuti). Misurali continuamente.
Poi agisci sui numeri: separa i percorsi caldi nella CI, esegui il set minimo di test che provi una modifica e investi in caching e flussi di lavoro incrementali dove puoi. L'obiettivo è semplice: rendere il percorso più veloce la scelta predefinita.
Progettare per il cambiamento: API, confini e manutenibilità
Rilascia cambiamenti con meno attriti
Trasforma un'idea di funzionalità in codice React, Go e PostgreSQL senza cambiare continuamente strumenti.
Le grandi codebase non falliscono di solito per una funzione sbagliata—falliscono perché i confini si annebbiano nel tempo. Il modo più semplice per mantenere il cambiamento sicuro è trattare le API (anche quelle interne) come prodotti: piccole, stabili e intenzionali.
Contratti chiari (e perché i tipi aiutano)
In TypeScript e C#, i tipi trasformano “come chiamare questo” in un contratto esplicito. Quando una libreria condivisa espone tipi ben scelti—input stretti, forme di ritorno chiare, enum significativi—riduci il numero di “regole implicite” che vivono solo nella testa di qualcuno.
Per le API interne, questo conta ancora di più: i team si spostano, la ownership cambia e la libreria diventa una dipendenza che non puoi “semplicemente leggere in fretta”. I tipi forti rendono l'uso scorretto più difficile e i refactor più sicuri perché i chiamanti rompono a compile time invece che in produzione.
Controllare la superficie esposta con confini
Un sistema manutenibile è di solito stratificato:
- Superficie pubblica vs internals: esporta solo ciò che intendi supportare; mantieni helper privati.
- Moduli/namespace: raggruppa capacità correlate così la discoverability è alta e l'accoppiamento accidentale è basso.
- Direzione delle dipendenze: il codice di livello superiore dipende da primitive di livello inferiore, non il contrario.
Non si tratta tanto di “purezza architetturale” quanto di rendere ovvio dove dovrebbero avvenire i cambiamenti.
Versioning, deprecazioni e abitudini di team
Le API evolvono. Pianificalo:
- Introduci nuovi punti di ingresso insieme a quelli vecchi, marca i vecchi come deprecati e fissa una data di rimozione.
- Mantieni un changelog leggero per i pacchetti condivisi così gli upgrade non diventano archeologia.
Supporta queste abitudini con automazione: regole di lint che vietano importazioni interne, checklist di code review per i cambi API e controlli CI che impongono semver e prevengono esportazioni pubbliche accidentali. Quando le regole sono eseguibili, la manutenibilità smette di essere una virtù personale e diventa una garanzia di team.
Azioni pratiche per scalare grandi codebase
Le grandi codebase non falliscono perché un team “ha scelto il linguaggio sbagliato”. Falliscono perché il cambiamento diventa rischioso e lento. Il modello pratico dietro TypeScript e C# è semplice: tipi + tooling + feedback veloci rendono il cambiamento quotidiano più sicuro.
Il nucleo del messaggio
I tipi statici sono più preziosi quando sono accoppiati a ottimi servizi del linguaggio (autocomplete, navigazione, correzioni rapide) e a loop di feedback serrati (errori istantanei, build incrementali). Questa combinazione trasforma il refactor da evento stressante in attività di routine.
Dove si inserisce Koder.ai nella storia della DX
Non ogni guadagno di scala viene solo dal linguaggio—anche il workflow conta. Piattaforme come Koder.ai mirano a comprimere ulteriormente il ciclo “edit → check → fix” permettendo ai team di costruire app web, backend e mobile tramite un flusso conversazionale (React sul web, Go + PostgreSQL sul backend, Flutter per mobile), mantenendo comunque il risultato ancorato a codice sorgente reale ed esportabile.
Nella pratica, funzionalità come modalità di pianificazione (per chiarire l'intento prima dei cambi), snapshot e rollback (per rendere i refactor più sicuri) e distribuzione/hosting integrati con domini personalizzati si collegano direttamente allo stesso tema di questo articolo: ridurre il costo del cambiamento e mantenere il feedback stretto mentre i sistemi crescono.
Una roadmap di adozione semplice (che funziona nella realtà)
-
Inizia con i guadagni dal tooling. Standardizza un setup IDE, abilita formattazione consistente, aggiungi linting e assicurati che “vai alla definizione” e rinomina funzionino su tutto il repo.
-
Aggiungi sicurezza gradualmente. Attiva il controllo dei tipi dove fa più male (moduli condivisi, API, codice ad alta frequenza di modifica). Migra verso impostazioni più severe nel tempo invece di provare a “girare l'interruttore” in una settimana.
-
Rifattorizza con protezioni. Quando tipi e tooling sono affidabili, investi in refactor più grandi: estrarre moduli, chiarire confini e rimuovere codice morto. Usa il compilatore e l'IDE per fare il lavoro pesante.
Segni che stai scalando bene
- I cambiamenti sono prevedibili: riesci a stimare l'impegno senza debug eroici.
- Le regressioni scendono perché i breaking change vengono catturati presto.
- I refactor sono sicuri: rinomina/muovi/estrai diventano banali, non spaventosi.
- I nuovi arrivati diventano produttivi più velocemente perché la codebase si “auto-spiega” tramite tipi e tooling.
Passi pratici successivi
Scegli una funzionalità imminente e trattala come pilot: irrigidisci i tipi nell'area interessata, richiedi build verdi in CI e misura lead time e tasso di bug prima/dopo.
Se vuoi altre idee, consulta i post di ingegneria correlati su /blog.
Domande frequenti
Cosa significa “esperienza dello sviluppatore” nel contesto di grandi codebase?
L'esperienza dello sviluppatore (DX) è il costo quotidiano per apportare una modifica: comprendere il codice, modificare in sicurezza e dimostrare che funziona. Quando codebase e team crescono, quel costo di “capire le cose” diventa dominante—e una buona DX (navigazione rapida, refactor affidabili, errori chiari) evita che la velocità di consegna collassi sotto la complessità.
Perché l'esperienza dello sviluppatore diventa più importante man mano che un progetto scala?
In un grande repository, il tempo si perde nell'incertezza: contratti poco chiari, pattern incoerenti e feedback lenti.
Un buon tooling riduce quell'incertezza rispondendo rapidamente:
- Dove è usato questo?
- Che tipo/forma è atteso qui?
- Cosa si romperà se rinomino o sposto questo?
- È sicuro distribuire questa modifica?
Perché Anders Hejlsberg è rilevante in una discussione sullo scaling dei team di ingegneria?
Perché rappresenta una filosofia di progettazione ripetibile che emerge in entrambi gli ecosistemi: dare priorità a feedback veloci, servizi del linguaggio robusti e refactor sicuri. La lezione pratica non è “seguire una persona”, ma creare un flusso di lavoro dove il lavoro comune è veloce e gli errori vengono evidenziati presto.
In che modo i tipi statici aiutano concretamente un team a muoversi più velocemente (e non più lentamente)?
I tipi statici trasformano assunzioni implicite in contratti verificabili. Questo è particolarmente utile quando molte persone toccano lo stesso codice:
- Le API comunicano l'intento tramite i tipi invece che tramite conoscenza tribale.
- I breaking change emergono a compile time, non in produzione.
- I refactor (rinomina/modifica firma) producono un elenco concreto di aggiornamenti necessari.
Qual è la differenza pratica tra errori a compile time e bug a runtime?
I controlli a compile time falliscono presto—spesso mentre scrivi o prima del merge—quindi risolvi i problemi quando il contesto è fresco. I bug a runtime emergono dopo (QA/produzione) e costano di più: riproduzione, interruzione e patch d'emergenza.
Una regola pratica: usa i tipi per prevenire gli errori del tipo “non avrebbe mai dovuto compilare” e usa i test per validare il comportamento a runtime e le regole di business.
Perché TypeScript è considerato “graduale”, e perché questo è importante per l'adozione?
TypeScript è pensato per un'adozione incrementale in codice JavaScript esistente:
- Tipizzazione graduale: puoi mescolare codice tipato e non tipato.
- Inferenza: spesso ottieni tipi utili senza scrivere molte annotazioni.
- Tipizzazione strutturale: la compatibilità si basa sulla forma dell'oggetto, che si adatta ai pattern JS tipici.
Una strategia di migrazione comune è convertire file uno alla volta e inasprire nel tempo.
Quali feature di C# migliorano più direttamente la manutenibilità in grandi soluzioni?
C# tende a far sì che il modo “normale” di scrivere codice sia anche il più leggibile e sicuro su larga scala:
- Le annotazioni di nullabilità aiutano a comunicare se un valore può essere
null. async/awaitmantiene i flussi asincroni leggibili.- I refactor guidati dall'IDE e l'analisi a livello di soluzione rendono i grandi cambiamenti più sicuri.
Il risultato è meno dipendenza da convenzioni personali e più coerenza imposta dagli strumenti.
Cosa sono i “language services” e perché contano più del semplice syntax highlighting?
I servizi del linguaggio sono le funzionalità dell'editor alimentate da una comprensione semantica del codice (non solo testo). Includono tipicamente:
- Autocomplete basato su tipi reali
- Vai alla definizione
- Trova tutte le riferimenti
- Rinomina/sposta sicuri
- Diagnostiche inline e correzioni rapide
In TypeScript questo è guidato dal compilatore + TypeScript Language Service; in C#, dall'infrastruttura di compilazione/analisi più l'integrazione IDE.
Come si rifattorizza in sicurezza quando un repo è troppo grande per “cercare e sostituire”?
Usa il refactoring semantico (supportato da IDE/compilatore), non la ricerca e sostituzione testuale. I buoni refactor si basano sulla comprensione di scope, overload, risoluzione moduli e identità dei simboli.
Abitudini pratiche:
- Preferisci “Rename Symbol” e “Change Signature”.
- Attiva il controllo dei tipi/della strictness nelle aree che refattorizzi di più.
- Mantieni i cambi piccoli e lascia che il compilatore elenchi i call site impattati.
Quali sono i modi pratici per mantenere veloci build, CI e feedback dell'editor man mano che il codice cresce?
Tratta la velocità come una metrica di prodotto e ottimizza il ciclo di feedback:
- Imposta budget (es.: build locale sotto X minuti, azioni IDE sotto Y ms, CI sotto Z minuti).
- Usa compilazione incrementale/caching quando disponibile.
- Esegui test mirati per cambiamenti piccoli; lascia le suite complete per i gate di merge o le nightly.
- Risolvi subito la lentezza dell'editor—se gli sviluppatori smettono di fidarsi di rinomina/trova-riferimenti, i refactor si fermano.
L'obiettivo è mantenere edit → check → fix abbastanza serrato da far sentire sicuri i cambiamenti.