Integrazioni webhook affidabili: firma, idempotenza, debug
Impara a gestire webhook in modo affidabile con firma, chiavi di idempotenza, protezione contro replay e un workflow veloce per il debug di errori segnalati dai clienti.
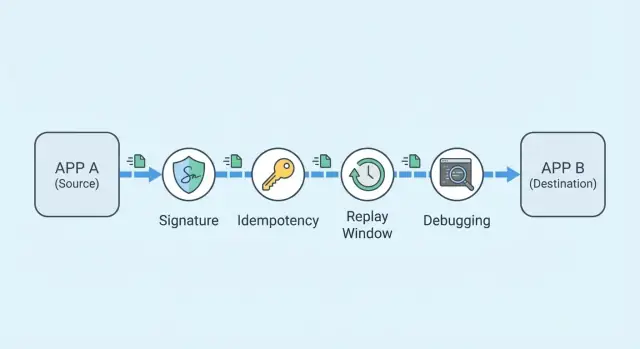
Perché i webhook falliscono nella vita reale
Quando qualcuno dice “i webhook non funzionano”, di solito intende una di tre cose: eventi mai arrivati, eventi arrivati due volte, o eventi arrivati in un ordine confuso. Dal loro punto di vista il sistema ha “perso” qualcosa. Dal tuo punto di vista il provider ha inviato l'evento, ma il tuo endpoint non l'ha accettato, non l'ha processato o non lo ha registrato come ti aspettavi.
I webhook vivono su Internet pubblico. Le richieste vengono ritardate, ritentate e talvolta consegnate fuori ordine. La maggior parte dei provider ritenta aggressivamente quando vede timeout o risposte non 2xx. Questo trasforma un piccolo intoppo (un database lento, un deploy, una breve interruzione) in duplicati e condizioni di race.
Log scadenti fanno sembrare il tutto casuale. Se non puoi dimostrare se una richiesta era autentica, non puoi agirci in sicurezza. Se non riesci a collegare il reclamo di un cliente a un tentativo di consegna specifico, finisci per indovinare.
La maggior parte dei failure reali rientra in pochi casi:
- Eventi “mancanti” (hai fatto timeout, hai restituito un errore o hai fallito dopo aver riconosciuto)
- Duplicati (retry con handler non idempotente)
- Ordine sbagliato (hai assunto che l'ordine di consegna sia l'ordine degli eventi)
- Richieste misteriose (nessuna verifica firma, quindi non puoi separare reale da falso)
L'obiettivo pratico è semplice: accettare eventi reali una volta sola, rifiutare i falsi e lasciare una traccia chiara così puoi fare debug di una segnalazione cliente in pochi minuti.
Come si comportano davvero i webhook
Un webhook è solo una richiesta HTTP che un provider invia a un endpoint che esponi. Non la richiami come una API. Il mittente la spinge quando succede qualcosa, e il tuo compito è riceverla, rispondere rapidamente e processarla in sicurezza.
Una consegna tipica include un body della richiesta (spesso JSON) più header che ti aiutano a validare e tracciare ciò che hai ricevuto. Molti provider includono un timestamp, un tipo di evento (come invoice.paid) e un ID evento univoco che puoi memorizzare per rilevare duplicati.
La parte che sorprende i team: la consegna è quasi mai “esattamente una volta”. La maggior parte dei provider punta a “almeno una volta”, cioè lo stesso evento può arrivare più volte, a volte con minuti o ore di distanza.
I retry accadono per motivi banali: il tuo server è lento o va in timeout, restituisci un 500, la loro rete non vede il tuo 200, o il tuo endpoint è temporaneamente non disponibile durante deploy o picchi di traffico.
Un timeout è particolarmente insidioso. Il tuo server potrebbe ricevere la richiesta e anche finire di processarla, ma la risposta non arriva al mittente in tempo. Dal punto di vista del provider è fallita, quindi ritentano. Senza protezioni, processi lo stesso evento due volte.
Un buon modello mentale è trattare la richiesta HTTP come un “tentativo di consegna”, non come “l'evento”. L'evento è identificato dal suo ID. La tua elaborazione dovrebbe basarsi su quell'ID, non su quante volte il provider ti chiama.
Firma dei webhook in termini semplici
La firma del webhook è il modo in cui il mittente dimostra che una richiesta è davvero partita da loro e non è stata modificata in transito. Senza firma, chiunque indovini la tua URL webhook può postare falsi eventi “pagamento riuscito” o “utente aggiornato”. Peggio ancora, un evento reale potrebbe essere alterato (importo, ID cliente, tipo evento) e sembrare comunque valido alla tua app.
Il pattern più comune è HMAC con un secret condiviso. Entrambe le parti conoscono lo stesso valore segreto. Il mittente prende il payload esatto (di solito il body grezzo), calcola un HMAC usando quel segreto e invia la firma insieme al payload. Il tuo compito è ricalcolare l'HMAC sugli stessi byte e verificare che le firme combacino.
I dati della firma sono solitamente posti in un header HTTP. Alcuni provider includono anche un timestamp lì così puoi aggiungere protezione contro replay. Meno comune è che la firma sia nel corpo JSON, il che è più rischioso perché i parser o la rserializzazione possono cambiare il formato e rompere la verifica.
Quando confronti le firme, non usare un confronto di stringhe normale. I confronti basici possono rivelare differenze temporali che aiutano un attaccante a indovinare la firma corretta dopo molti tentativi. Usa una funzione di confronto a tempo costante fornita dal tuo linguaggio o libreria crittografica e rifiuta al primo mismatch.
Se un cliente segnala “il vostro sistema ha accettato un evento che non abbiamo inviato”, parti dai controlli di firma. Se la verifica fallisce, probabilmente hai un mismatch di secret o stai hashando i byte sbagliati (per esempio JSON parsato invece del body grezzo). Se passa, puoi fidarti dell'identità del mittente e passare a deduping, ordinamento e retry.
Passo dopo passo: verifica di una firma webhook
La gestione affidabile dei webhook parte da una regola noiosa: verifica ciò che hai ricevuto, non ciò che vorresti aver ricevuto.
Il modo sicuro per verificare
Cattura il body grezzo della richiesta esattamente com'è arrivato. Non parsare e rserializzare il JSON prima di controllare la firma. Piccole differenze (whitespace, ordine delle chiavi, unicode) cambiano i byte e possono far sembrare invalide firme genuine.
Poi ricostruisci l'esatta stringa che il provider si aspetta che tu firmi. Molti sistemi firmano una stringa come timestamp + "." + raw_body. Il timestamp non è decorazione. Serve a rifiutare richieste vecchie.
Calcola l'HMAC usando il secret condiviso e l'algoritmo richiesto (spesso SHA-256). Conserva il secret in uno store sicuro e trattalo come una password.
Infine, confronta il valore calcolato con l'header della firma usando un confronto a tempo costante. Se non coincide, ritorna un 4xx e fermati. Non “accettare comunque”.
Checklist rapida di implementazione:
- Leggi il body come byte una volta, memorizzalo e usa quegli stessi byte per la verifica.
- Ricrea la stringa firmata esattamente, inclusi separatori e formato timestamp.
- Calcola l'HMAC con il secret e l'algoritmo corretti.
- Confronta le firme in modo sicuro e rifiuta i mismatch.
- Logga perché la verifica è fallita (header mancante, timestamp errato, mismatch) senza loggare il secret o la firma completa.
Un esempio veloce
Un cliente segnala “i webhook hanno smesso di funzionare” dopo che avete aggiunto middleware di parsing JSON. Vedi mismatch di firma, soprattutto su payload più grandi. La soluzione è solitamente verificare usando il body grezzo prima di qualsiasi parsing e loggare quale passo è fallito (per esempio “header firma mancante” vs “timestamp fuori finestra”). Quel dettaglio spesso riduce il tempo di debug da ore a minuti.
Chiavi di idempotenza: accetta una volta, in sicurezza
I provider ritentano perché la consegna non è garantita. Il tuo server potrebbe essere giù per un minuto, un hop di rete può perdere la richiesta, o il tuo handler va in timeout. Il provider presume “forse è andata a buon fine” e reinvia lo stesso evento.
Una chiave di idempotenza è il numero di ricevuta che usi per riconoscere un evento già processato. Non è una funzionalità di sicurezza e non sostituisce la verifica della firma. Non risolve nemmeno le condizioni di race a meno che non la memorizzi e la verifichi in modo sicuro sotto concorrenza.
Scegliere la chiave dipende da cosa ti fornisce il provider. Preferisci un valore che rimane stabile tra i retry:
- Event ID (migliore quando un evento mappa a una singola modifica business)
- Delivery ID o message ID (migliore quando i retry mantengono lo stesso identificatore di consegna)
- Un hash di campi stabili (ultima risorsa se non esiste un ID)
Quando ricevi un webhook, scrivi la chiave nello storage prima usando una regola di unicità così solo una richiesta “vince”. Poi processa l'evento. Se vedi la stessa chiave di nuovo, ritorna successo senza rifare il lavoro.
Mantieni la ricevuta memorizzata piccola ma utile: la chiave, stato di processamento (ricevuto/processato/failed), timestamp (first seen/last seen) e un sommario minimo (tipo evento e ID dell'oggetto correlato). Molti team conservano le chiavi per 7–30 giorni così i retry tardivi e la maggior parte delle segnalazioni clienti sono coperti.
Protezione contro replay senza bloccare traffico reale
La protezione contro replay ferma un problema semplice ma caro: qualcuno cattura una richiesta webhook reale (con firma valida) e la invia di nuovo più tardi. Se il tuo handler tratta ogni consegna come nuova, quel replay può causare rimborsi duplicati, inviti utente ripetuti o cambi di stato ripetuti.
Un approccio comune è firmare non solo il payload ma anche un timestamp. Il tuo webhook include header come X-Signature e X-Timestamp. A ricezione, verifica la firma e controlla che il timestamp sia fresco dentro una finestra breve.
Il clock drift è ciò che solitamente causa falsi rifiuti. I tuoi server e quelli del mittente possono avere differenze di uno o due minuti, e le reti possono ritardare la consegna. Mantieni un buffer e logga perché hai rifiutato una richiesta.
Regole pratiche che funzionano bene:
- Accetta solo se
abs(now - timestamp) <= window(per esempio 5 minuti più una piccola tolleranza). - Fai affidamento sull'idempotenza come vera rete di salvataggio. Anche dentro la finestra, i retry non dovrebbero applicare due volte le azioni.
- Se rifiuti per tempo, ritorna un 4xx chiaro e logga il timestamp ricevuto e l'ora del tuo server.
Se mancano i timestamp, non puoi fare vera protezione replay basata solo sul tempo. In quel caso, punta di più sull'idempotenza (memorizza e rifiuta ID evento duplicati) e considera di richiedere timestamp nella prossima versione del webhook.
La rotazione dei secret è importante. Se ruoti i secret di firma, conserva più secret attivi per un breve periodo di sovrapposizione. Verifica contro il secret più recente prima, poi fai fallback a quelli più vecchi. Questo evita rotture durante il rollout. Se il tuo team rilascia endpoint velocemente (per esempio generando codice con Koder.ai e usando snapshot e rollback durante i deploy), quella finestra di sovrapposizione aiuta perché versioni più vecchie potrebbero restare live per un po'.
Progetta l'handler in modo che i retry non ti danneggino
I retry sono normali. Presumi che ogni consegna possa essere duplicata, ritardata o fuori ordine. Il tuo handler dovrebbe comportarsi allo stesso modo sia che veda un evento una volta sia cinque volte.
Mantieni il percorso della richiesta corto. Fai solo ciò che serve per accettare l'evento, poi sposta il lavoro pesante in un job di background.
Un pattern semplice che regge in produzione:
- Valida le basi (metodo, content type, header richiesti).
- Verifica l'autenticità (firma) e rifiuta tutto ciò che fallisce.
- Parsifica e valida il payload.
- Dedupe usando l'event ID (o idempotency key) in una tabella con vincolo di unicità.
- Enqueue il lavoro con l'event ID, poi rispondi.
Restituisci 2xx solo dopo aver verificato la firma e registrato l'evento (o messo in coda). Se rispondi 200 prima di salvare qualcosa, puoi perdere eventi in caso di crash. Se fai lavoro pesante prima di rispondere, i timeout triggerano retry e potresti ripetere side effect.
Sistemi downstream lenti sono la ragione principale per cui i retry diventano dolorosi. Se il tuo provider email, CRM o database è lento, lascia che una coda assorba il ritardo. Il worker potrà ritentare con backoff e potrai allertare sui job bloccati senza bloccare il mittente.
Gli eventi fuori ordine accadono anch'essi. Per esempio, un subscription.updated potrebbe arrivare prima di subscription.created. Costruisci tolleranza controllando lo stato corrente prima di applicare cambiamenti, permettendo upsert e trattando il “not found” come motivo per riprovare più tardi (quando ha senso) invece che come fallimento permanente.
Errori comuni che causano bug difficili da tracciare
Molti problemi “casuali” sui webhook sono autoinflitti. Sembrano reti fluttuanti, ma si ripetono in pattern, spesso dopo un deploy, una rotazione di secret o una piccola modifica al parsing.
Il bug di firma più comune è hashare i byte sbagliati. Se parsate il JSON prima, il server può riformattarlo (whitespace, ordine chiavi, formattazione numeri). Poi verifichi la firma su un body diverso da quello che il mittente ha firmato, e la verifica fallisce anche se il payload è genuino. Verifica sempre contro i byte grezzi esatti della richiesta così come ricevuti.
La fonte successiva di confusione sono i secret. I team testano in staging ma per sbaglio verificano con il secret di produzione, o tengono un secret vecchio dopo la rotazione. Quando un cliente segnala fallimenti “solo in un ambiente”, assumi prima secret sbagliato o config errata.
Alcuni errori che portano a lunghe indagini:
- Loggare il body completo per debug e poi perdere token, email o dettagli di pagamento nei log.
- Restituire 500 mentre si eseguono side effect (inviare email, aggiornare ordini). I retry ripeteranno i side effect.
- Usare una chiave di idempotenza che non è davvero unica (per esempio tipo evento + minuto). Gli eventi reali vengono scartati come “duplicati”.
- Trattare una risposta 2xx come “processata”, quando il codice ha solo messo in coda il lavoro che poi è fallito.
Esempio: un cliente dice “order.paid non è mai arrivato”. Vedi che i fallimenti di firma sono iniziati dopo un refactor che ha cambiato il middleware di parsing delle richieste. Il middleware legge e riformatta il JSON, quindi il controllo firma usa ora un body modificato. La soluzione è semplice, ma la trovi solo se sai dove cercare.
Debug rapido delle segnalazioni clienti
Quando un cliente dice “il vostro webhook non è scattato”, trattalo come un problema di trace, non come un problema di indovinare. Ancora su un singolo tentativo di consegna dal provider e seguilo nel sistema.
Inizia ottenendo l'identificatore di consegna del provider, request ID o event ID per il tentativo fallito. Con quell'unico valore dovresti poter trovare la voce di log corrispondente rapidamente.
Da lì, controlla tre cose in ordine:
- La verifica della firma è passata?
- Il controllo timestamp/finestra replay è passato (se lo usi)?
- L'idempotenza lo ha trattato come nuovo o come duplicato?
Poi conferma cosa hai restituito al provider. Un 200 lento può essere tanto dannoso quanto un 500 se il provider va in timeout e ritenta. Guarda codice di stato, tempo di risposta e se il tuo handler ha riconosciuto prima di fare lavoro pesante.
Se devi riprodurre, fallo in modo sicuro: memorizza un campione raw della richiesta redatto (header chiave più body grezzo) e riproducilo in un ambiente di test usando lo stesso secret e lo stesso codice di verifica.
Checklist rapida che puoi eseguire in 10 minuti
Quando un'integrazione webhook comincia a fallare “a caso”, la velocità conta più della perfezione. Questo runbook cattura le cause più comuni.
Prendi prima un esempio concreto: nome del provider, tipo evento, timestamp approssimativo (con timezone) e qualsiasi event ID che il cliente possa vedere.
Poi verifica:
- La verifica firma usa i byte grezzi del body (prima del parsing JSON) e il secret corretto per quell'ambiente.
- I controlli replay hanno senso per il comportamento reale dei retry (e l'orologio del server è sano).
- L'idempotenza davvero deduplica (vincolo unico, scritto prima del processamento, ritenzione sensata).
- Il tuo handler riconosce solo dopo validazione e registrazione/queue duratura.
- I log includono una ricevuta minimale e ricercabile: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Se il provider dice “abbiamo ritentato 20 volte”, controlla prima pattern comuni: secret sbagliato (firma fallisce), drift orologio (finestra replay), limiti di dimensione payload (413), timeout (nessuna risposta) e picchi di 5xx dalle dipendenze downstream.
Esempio: tracciare una segnalazione di “evento mancante” end to end
Un cliente scrive: “Ci siamo persi un evento invoice.paid ieri. Il nostro sistema non si è aggiornato.” Ecco un modo veloce per tracciarlo.
Per prima cosa, conferma se il provider ha tentato la consegna. Estrai event ID, timestamp, URL di destinazione e l'esatto codice di risposta che il tuo endpoint ha restituito. Se ci sono stati retry, annota la prima ragione di fallimento e se un retry successivo è riuscito.
Poi valida cosa ha visto il tuo codice al bordo: conferma il secret di firma configurato per quell'endpoint, ricalcola la verifica della firma usando il body grezzo e controlla il timestamp della richiesta rispetto alla tua finestra consentita.
Fai attenzione alle finestre di replay durante i retry. Se la tua finestra è di 5 minuti e il provider ritenta 30 minuti dopo, potresti rifiutare un retry legittimo. Se quella è la tua policy, assicurati sia intenzionale e documentata. Se non lo è, amplia la finestra o cambia la logica in modo che l'idempotenza rimanga la difesa primaria contro i duplicati.
Se firma e timestamp sono a posto, segui l'event ID nel tuo sistema e rispondi: l'avete processato, deduplicato o scartato?
Esiti comuni:
- Dedupe: la chiave di idempotenza esiste già, quindi hai restituito 200 senza rieseguire la logica business.
- Rifiutato: la validazione è fallita (mismatch firma, timestamp vecchio, header mancanti).
- Timeout: l'handler ha impiegato troppo, il provider l'ha segnato come fallito e poi ha ritentato.
Quando rispondi al cliente, sii conciso e specifico: “Abbiamo ricevuto tentativi di consegna alle 10:03 e 10:33 UTC. Il primo è andato in timeout dopo 10s; il retry è stato rifiutato perché il timestamp era fuori dalla nostra finestra di 5 minuti. Abbiamo ampliato la finestra e aggiunto un riconoscimento più veloce. Invia di nuovo l'event ID X se necessario.”
Prossimi passi: rendilo ripetibile
Il modo più rapido per fermare i problemi con i webhook è far sì che ogni integrazione segua lo stesso playbook. Scrivi il contratto che tu e il mittente concordate: header richiesti, metodo di firma esatto, quale timestamp usare e quali ID trattare come unici.
Standardizza poi ciò che registri per ogni tentativo di consegna. Un piccolo log di ricevuta di solito è sufficiente: received_at, event_id, delivery_id, signature_valid, idempotency_result (new/duplicate), handler_version e response status.
Un workflow che resta utile man mano che cresci:
- Mantieni un endpoint di test dedicato che verifica le firme e ritorna 2xx senza eseguire azioni business.
- Conserva il body grezzo e gli header chiave per un breve periodo, giusto il tempo per fare debug e replay.
- Costruisci un job di reprocess sicuro per replay che riesegue eventi memorizzati attraverso lo stesso percorso handler.
- Mantieni una checklist interna che support, QA e engineering seguono.
Se costruisci app su Koder.ai (Koder.ai), Planning Mode è un buon modo per definire prima il contratto webhook (header, firma, ID, comportamento dei retry) e poi generare un endpoint consistente e un record di ricevuta attraverso i progetti. Quella coerenza è ciò che rende il debug veloce invece che eroico.
Domande frequenti
Why do webhooks seem to “randomly” fail or duplicate in production?
Perché la consegna dei webhook è solitamente at-least-once, non exactly-once. I provider ritentano su timeout, risposte 5xx o quando non vedono il tuo 2xx in tempo, quindi puoi avere duplicati, ritardi e consegne fuori ordine anche quando tutto sembra funzionare.
What’s the safest basic flow for handling a webhook request?
Di base segui questa regola: verifica prima la firma, poi registra/dedupe l'evento, quindi rispondi 2xx, infine esegui il lavoro pesante in modo asincrono.
Se fai lavori pesanti prima della risposta, incappi in timeout e triggeri retry; se rispondi prima di registrare tutto, rischi di perdere eventi in caso di crash.
How do I avoid signature mismatches when verifying webhooks?
Usa esattamente i byte grezzi del body della richiesta così come sono arrivati. Non parsare il JSON e poi rserializzarlo prima della verifica: spazi, ordine delle chiavi e formattazione dei numeri possono cambiare la firma.
Assicurati inoltre di ricreare esattamente la stringa che il provider firma (spesso timestamp + "." + raw_body).
What should my endpoint do when signature verification fails?
Restituisci un 4xx (comune 400 o 401) e non processare il payload.
Logga una ragione minimale (header firma mancante, mismatch, timestamp fuori finestra), ma non registrare segreti né payload sensibili completi.
What is an idempotency key for webhooks, and which value should I use?
Una chiave di idempotenza è un identificatore stabile e unico che memorizzi così i retry non riapplichino side effect.
Opzioni migliori:
- Event ID (ideale quando un evento corrisponde a una singola modifica business)
- Delivery/message ID (se rimane costante tra i retry)
- Hash di campi stabili (ultima risorsa)
Applicala con un vincolo di unicità così solo una richiesta “vince” sotto concorrenza.
How do I dedupe webhooks without race conditions?
Scrivi la chiave di idempotenza prima di effettuare side effect, con una regola di unicità. Poi:
- Segna come "processed" dopo il successo, oppure
- Registra uno stato di fallimento così puoi riprovare in modo sicuro
Se l'inserimento fallisce perché la chiave esiste già, ritorna 2xx e salta l'azione business.
How do I add replay protection without rejecting legitimate retries?
Includi il timestamp nei dati firmati e rifiuta le richieste fuori da una breve finestra (ad esempio pochi minuti).
Per evitare di bloccare retry legittimi:
- Permetti qualche drift di orologio
- Logga server time e timestamp ricevuto quando rifiuti
- Tratta l'idempotenza come la difesa principale contro i duplicati; la finestra temporale serve soprattutto a fermare replay tardivi
How should I handle out-of-order webhook events?
Non presumere che l'ordine di consegna corrisponda all'ordine degli eventi. Rendi i handler tolleranti:
- Usa upsert quando possibile
- Controlla lo stato corrente prima di applicare cambiamenti
- Se un oggetto non è trovato, considera di riprovare più tardi (via queue) invece di fallire definitivamente
Memorizza event ID e tipo così puoi ricostruire cosa è successo anche con ordini strani.
What should I log so webhook debugging doesn’t turn into guessing?
Registra una piccola “ricevuta” per ogni tentativo di consegna così puoi tracciare un evento end-to-end:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- risultato idempotency (new/duplicate)
- response_code, latency_ms
- timestamp (received/first_seen/last_seen)
Rendi i log ricercabili per event ID così il supporto può rispondere rapidamente alle segnalazioni dei clienti.
What’s a fast way to investigate a customer report that “a webhook never arrived”?
Chiedi prima un identificatore concreto: event ID o delivery ID, più un timestamp approssimativo.
Poi verifica in ordine:
- Risultato della verifica firma
- Risultato del controllo timestamp/finestra replay (se usata)
- Esito idempotenza (new vs duplicate)
- Cosa hai restituito (status code + latenza)
Se usi Koder.ai, mantieni lo stesso pattern handler (verify → record/dedupe → queue → respond). La coerenza rende queste verifiche rapide durante gli incidenti.