Joe Armstrong ed Erlang: “Let It Crash” per piattaforme affidabili
Scopri come Joe Armstrong ha formato la concorrenza di Erlang, la supervisione e la mentalità “let it crash” — idee ancora usate per costruire servizi real-time affidabili.
Cosa copre questo post (e perché conta ancora)
Joe Armstrong non ha solo contribuito a creare Erlang: è stato il suo spiegatore più chiaro e persuasivo. Con talk, paper e un approccio pragmatico, ha reso popolare un'idea semplice: se vuoi software che resti attivo, progetti pensando al fallimento invece di fingere che si possa evitare.
Questo post è un tour guidato della mentalità Erlang e del perché continua ad avere valore quando costruisci piattaforme real-time affidabili—come sistemi di chat, instradamento chiamate, notifiche live, coordinamento multiplayer e infrastrutture che devono rispondere in modo rapido e coerente anche quando parti di esse si comportano male.
“Real-time” in parole semplici
Real-time non sempre significa “microsecondi” o “scadenze rigide.” In molti prodotti significa:
- risposte rapide percepibili dagli utenti (niente pause misteriose)
- comportamento prevedibile sotto carico (può rallentare, ma non deve degenerare)
- servizio continuativo durante failure parziali (un componente difettoso non deve abbattere tutto)
Erlang è stato costruito per i sistemi telecom dove queste aspettative erano non negoziabili—e quella pressione ha plasmato le sue idee più influenti.
I tre pilastri su cui ci concentriamo
Piuttosto che entrare nella sintassi, ci concentreremo sui concetti che hanno reso Erlang famoso e che ricompaiono nel design dei sistemi moderni:
- Concorrenza come default: costruire software da molti piccoli worker isolati invece che pochi grandi.
- Tolleranza ai guasti come obiettivo di design: assumere che bug, timeout e crash accadranno—e pianificare cosa succede dopo.
- “Let it crash”: non sovra-proteggere ogni riga di codice; fallire rapidamente e recuperare in modo pulito usando la struttura (non eroi).
Lungo il percorso collegheremo queste idee al modello ad attori e al passaggio di messaggi, spiegheremo in termini accessibili gli alberi di supervisione e OTP, e mostreremo perché la BEAM VM rende l'approccio pratico.
Anche se non usi Erlang (e non lo userai mai), il punto rimane: l'inquadramento di Armstrong ti dà una checklist potente per costruire sistemi che restano reattivi e disponibili quando la realtà si fa incasinata.
La motivazione di Joe Armstrong: costruire sistemi che restano su
Gli switch telecom e le piattaforme di instradamento chiamate non possono “andare offline per manutenzione” come molti siti web. Devono continuare a gestire chiamate, eventi di fatturazione e traffico di segnalazione 24/7—spesso con requisiti severi di disponibilità e tempi di risposta prevedibili.
Erlang è nato dentro Ericsson alla fine degli anni '80 per affrontare quelle realtà con software, non solo hardware specializzato. Joe Armstrong e i suoi colleghi non inseguivano l'eleganza fine a sé stessa; stavano cercando di costruire sistemi di cui gli operatori potessero fidarsi sotto carico costante, failure parziali e condizioni reali disordinate.
Cosa significava “affidabile” nella pratica
Un cambiamento chiave di mentalità è che affidabilità non è uguale a “non fallire mai.” Nei sistemi grandi e a lunga esecuzione qualcosa fallirà: un processo riceverà input inatteso, un nodo si riavvierà, un link di rete fluttuerà o una dipendenza si bloccherà.
Quindi l'obiettivo diventa:
- continuare a servire gli utenti anche quando parti si comportano male
- rilevare i fallimenti rapidamente
- recuperare automaticamente, con intervento umano minimo
- isolare i guasti in modo che un bug non abbatta tutto
Questa mentalità fa sì che idee come gli alberi di supervisione e il “let it crash” risultino ragionevoli: progetti il fallimento come evento normale, non come catastrofe eccezionale.
Meno mito, più problem-solving
È facile raccontare la storia come la folgorazione di un singolo visionario. La prospettiva più utile è più semplice: i vincoli telecom hanno imposto un diverso insieme di tradeoff. Erlang ha privilegiato concorrenza, isolamento e recovery perché erano gli strumenti pratici per mantenere i servizi operativi mentre il mondo intorno cambiava.
Questo approccio orientato al problema è anche la ragione per cui le lezioni di Erlang si traducono ancora bene oggi—ovunque uptime e recovery rapido contino più della prevenzione perfetta.
Concorrenza come default: molti piccoli worker
Un'idea centrale in Erlang è che “fare molte cose contemporaneamente” non è una caratteristica da aggiungere dopo: è il modo normale di strutturare un sistema.
Processi leggeri, spiegati semplicemente
In Erlang il lavoro è diviso in tanti piccoli “processi.” Pensali come piccoli worker, ognuno responsabile di un compito: gestire una chiamata, tracciare una sessione di chat, monitorare un dispositivo, ritentare un pagamento o osservare una coda.
Sono leggeri, il che significa che puoi averne in grandissimo numero senza bisogno di hardware enorme. Invece di un unico worker pesante che tenta di fare tutto, ottieni una folla di worker focalizzati che possono avviarsi rapidamente, fermarsi rapidamente e essere rimpiazzati rapidamente.
Perché “un grande programma” fallisce in modo diverso
Molti sistemi sono progettati come un singolo grande programma con molte parti strettamente connesse. Quando quel tipo di sistema incontra un bug serio, un problema di memoria o un'operazione bloccante, il fallimento può propagarsi—come saltare un interruttore e oscurare tutto l'edificio.
Erlang spinge all'opposto: isola responsabilità. Se un piccolo worker si comporta male, puoi terminare e rimpiazzare quel worker senza abbattere lavori non correlati.
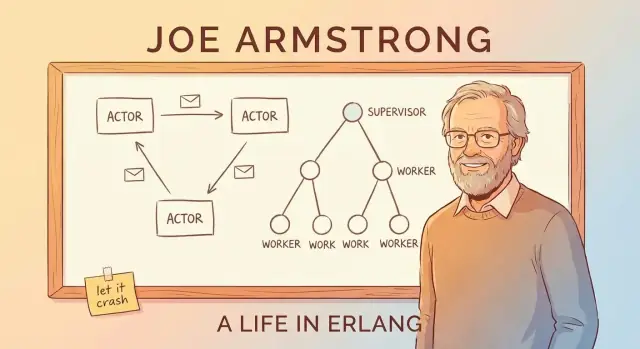
Passaggio di messaggi come “scambiarsi biglietti"
Come si coordinano questi worker? Non esplorano lo stato interno degli altri. Si scambiano messaggi—più simile a passarsi dei biglietti che condividere una lavagna confusa.
Un worker può dire “Ecco una nuova richiesta”, “Questo utente si è disconnesso” o “Riprova tra 5 secondi.” Il worker che riceve legge il biglietto e decide cosa fare.
Il vantaggio chiave è il contenimento: dato che i worker sono isolati e comunicano via messaggi, i fallimenti hanno meno probabilità di propagarsi all'intero sistema.
Passaggio di messaggi e modello ad attori (senza il gergo)
Un modo semplice per capire il “modello ad attori” di Erlang è immaginare un sistema composto da molti piccoli worker indipendenti.
Attori: piccoli worker che parlano solo inviando messaggi
Un attore è un'unità autonoma con il proprio stato privato e una mailbox. Fa tre cose di base:
- riceve messaggi (uno alla volta) dalla sua mailbox
- aggiorna il proprio stato interno
- invia messaggi ad altri attori
Questo è tutto. Niente variabili condivise nascoste, niente “entrare nella memoria di un altro worker.” Se un attore ha bisogno di qualcosa da un altro, lo chiede inviando un messaggio.
Perché evitare lo stato condiviso elimina intere categorie di bug
Quando più thread condividono gli stessi dati, compaiono race condition: due operazioni modificano lo stesso valore quasi contemporaneamente e il risultato dipende dai tempi. È lì che i bug diventano intermittenti e difficili da riprodurre.
Con il passaggio di messaggi, ogni attore possiede i suoi dati. Gli altri attori non possono mutarli direttamente. Non elimina tutti i bug, ma riduce drasticamente i problemi causati dall'accesso simultaneo allo stesso stato.
Back-pressure, spiegato come la fila al bar
I messaggi non arrivano “gratis.” Se un attore riceve messaggi più velocemente di quanto possa processarli, la sua mailbox (coda) cresce. Quello è il back-pressure: il sistema ti sta dicendo, indirettamente, “questa parte è sovraccarica.”
In pratica, si monitorano le dimensioni delle mailbox e si costruiscono limiti: scaricare carico, batch, campionamento o spostare lavoro su più attori invece di lasciare le code a crescere all'infinito.
Un esempio concreto: notifiche di chat
Immagina un'app di chat. Ogni utente potrebbe avere un attore responsabile della consegna delle notifiche. Quando un utente va offline, i messaggi continuano ad arrivare—quindi la mailbox cresce. Un sistema ben progettato potrebbe limitare la coda, scartare notifiche non critiche o passare a una modalità digest, invece di permettere a un utente lento di degradare l'intero servizio.
“Let It Crash” spiegato: fallire veloce, recuperare più in fretta
“Let it crash” non è uno slogan per ingegneria approssimativa. È una strategia di affidabilità: quando un componente entra in uno stato cattivo o inatteso, dovrebbe fermarsi rapidamente e in modo evidente invece di arrancare.
Cosa significa realmente
Invece di scrivere codice che tenta di gestire ogni possibile caso limite dentro un singolo processo, Erlang incoraggia a mantenere ogni worker piccolo e focalizzato. Se quel worker incontra qualcosa che davvero non sa gestire (stato corrotto, ipotesi violate, input inaspettato), esce. Un'altra parte del sistema è responsabile di riavviarlo.
Questo sposta la domanda principale da “Come preveniamo il fallimento?” a “Come recuperiamo in modo pulito quando il fallimento accade?”
Il tradeoff: meno controlli difensivi, logica più chiara
La programmazione difensiva ovunque può trasformare flussi semplici in un labirinto di condizionali, retry e stati parziali. “Let it crash” baratta parte di quella complessità in-process per:
- percorsi di codice più semplici e leggibili
- rilevamento più rapido delle ipotesi rotte
- recovery coerente (perché centralizzata)
L’idea è che il recupero debba essere prevedibile e ripetibile, non improvvisato in ogni funzione.
Quando funziona—e quando no
Si adatta meglio quando i fallimenti sono recuperabili e isolati: un problema di rete temporaneo, una richiesta malformata, un worker bloccato, un timeout di terze parti.
Non è adatto quando un crash può causare danni irreversibili, come:
- perdita di dati senza una sorgente di verità duratura
- operazioni safety-critical dove “ritenta” non è accettabile
Riavvii veloci e stato noto-buono
Il crash aiuta solo se il ritorno è rapido e sicuro. Nella pratica questo significa riavviare worker in uno stato noto e buono—spesso ricaricando configurazioni, ricostruendo cache in memoria da storage duraturo e riprendendo il lavoro senza fingere che lo stato rotto non sia mai esistito.
Alberi di supervisione: progettare il fallimento di proposito
L'idea del “let it crash” funziona perché i crash non sono lasciati al caso. Il pattern chiave è l'albero di supervisione: una gerarchia dove i supervisor fanno i manager e i worker svolgono il lavoro reale (gestire una chiamata, tracciare una sessione, consumare una coda, ecc.). Quando un worker si comporta male, il manager se ne accorge e lo riavvia.
Manager che riavviano worker
Un supervisor non cerca di “riparare” un worker rotto sul posto. Applica invece una regola semplice e coerente: se il worker muore, avviane uno nuovo. Questo rende il percorso di recovery prevedibile e riduce la necessità di handling di errore ad-hoc sparso nel codice.
Ugualmente importante, i supervisor possono decidere quando non riavviare—se qualcosa crasha troppo frequentemente può indicare un problema più profondo, e riavvii ripetuti possono peggiorare la situazione.
Strategie di riavvio (alto livello)
La supervisione non è unica per tutti. Strategie comuni includono:
- One-for-one: solo il worker che fallisce viene riavviato. Adatta a task indipendenti dove un fallimento non deve disturbare gli altri.
- Group restarts: se un worker fallisce, un gruppo correlato viene riavviato insieme. Utile per componenti strettamente accoppiati che devono restare sincronizzati.
Dipendenze: la parte su cui devi riflettere
Un buon design di supervisione parte da una mappa di dipendenze: quali componenti dipendono da quali altri, e cosa significa davvero “start fresco” per ciascuno.
Se un handler di sessione dipende da un processo cache, riavviare solo l'handler potrebbe lasciarlo connesso a uno stato corrotto. Raggrupparli sotto il supervisor giusto (o riavviarli insieme) trasforma modalità di failure confuse in comportamenti di recovery consistenti e ripetibili.
OTP: mattoni riutilizzabili per servizi affidabili
Se Erlang è il linguaggio, OTP (Open Telecom Platform) è la cassetta degli attrezzi che trasforma il “let it crash” in qualcosa che puoi far girare in produzione per anni.
OTP come cassetta di pattern provati
OTP non è una singola libreria—è un insieme di convenzioni e componenti pronti (chiamati behaviours) che risolvono le parti noiose ma critiche della costruzione dei servizi:
gen_serverper un worker di lunga durata che mantiene stato e gestisce richieste una alla voltasupervisorper riavviare automaticamente i worker falliti secondo regole chiareapplicationper definire come un servizio intero si avvia, si ferma e si incastra in una release
Non sono “magia.” Sono template con callback ben definiti, così il tuo codice si inserisce in una forma nota invece di inventare una forma nuova per ogni progetto.
Perché pattern standard battono framework custom
I team spesso costruiscono worker ad-hoc, hook di monitoring fatti in casa e logiche di riavvio una tantum. Funziona—fino a quando non funziona più. OTP riduce quel rischio spingendo tutti verso lo stesso vocabolario e ciclo di vita. Quando un nuovo ingegnere arriva, non deve prima imparare il tuo framework custom; può contare su pattern condivisi e ben compresi nella comunità Erlang.
Come OTP guida l'architettura quotidiana
OTP ti spinge a pensare in termini di ruoli di processo e responsabilità: cos'è un worker, cos'è un coordinatore, cosa riavvia cosa e cosa non dovrebbe mai essere riavviato automaticamente.
Incoraggia anche buona igiene: naming chiari, ordine di avvio esplicito, spegnimento prevedibile e segnali di monitoring incorporati. Il risultato è software pensato per girare continuamente—servizi che possono recuperare dai guasti, evolvere nel tempo e continuare a svolgere il proprio compito senza babysitting umano costante.
BEAM VM: il runtime che rende pratico il modello
Le grandi idee di Erlang—processi minuscoli, passaggio di messaggi e “let it crash”—sarebbero molto più difficili da usare in produzione senza la macchina virtuale BEAM. BEAM è il runtime che rende questi pattern naturali, non fragili.
Scheduling: equità rispetto a “un grande thread”
BEAM è costruita per eseguire un numero enorme di processi leggeri. Invece di affidarsi a poche thread del sistema operativo sperando che l'applicazione si comporti, BEAM programma i processi Erlang da sola.
Il beneficio pratico è reattività sotto carico: il lavoro è tagliato in piccoli pezzi e ruotato equamente, così nessun worker occupato dovrebbe dominare il sistema a lungo. Questo si adatta perfettamente a un servizio fatto di molti task indipendenti—ognuno fa un po' di lavoro e poi cede.
Isolamento e garbage collection per processo
Ogni processo Erlang ha il proprio heap e la propria garbage collection. È un dettaglio chiave: pulire la memoria in un processo non richiede di mettere in pausa l'intero programma.
Ugualmente importante, i processi sono isolati. Se uno crasha, non corrompe la memoria degli altri e la VM resta viva. Questo isolamento è la base che rende realistici gli alberi di supervisione: il fallimento è contenuto e poi gestito riavviando la parte fallita anziché buttare giù tutto.
Distribuzione: più nodi, un solo sistema
BEAM supporta anche la distribuzione in termini semplici: puoi eseguire più nodi Erlang (istanze VM separate) e lasciarli comunicare inviando messaggi. Se hai capito che “i processi parlano inviando messaggi”, la distribuzione è un'estensione della stessa idea—alcuni processi semplicemente vivono su un altro nodo.
BEAM non promette velocità pura. Promette che concorrenza, contenimento dei guasti e recovery siano il comportamento di default, così la storia dell'affidabilità è pratica e non teorica.
Aggiornamenti senza fermare il sistema (codice a caldo, con cautela)
Uno dei trucchi più noti di Erlang è l'hot code swapping: aggiornare parti di un sistema in esecuzione con downtime minimo (quando runtime e tool lo supportano). La promessa pratica non è “non riavviare mai”, ma “deployare fix senza trasformare un bug breve in un outage lungo.”
Cosa significa davvero “hot code”
In Erlang/OTP il runtime può tenere caricate due versioni di un modulo contemporaneamente. I processi esistenti possono terminare il lavoro usando la vecchia versione mentre le nuove chiamate possono partire usando la nuova. Questo ti dà spazio per patchare un bug, rilasciare una feature o modificare comportamento senza disconnettere tutti.
Fatto bene, questo supporta direttamente gli obiettivi di affidabilità: meno riavvii completi, finestre di manutenzione più brevi e recupero più veloce quando qualcosa sfugge in produzione.
I vincoli che nessuno dovrebbe ignorare
Non ogni cambiamento è sicuro da fare live. Alcuni esempi di cambiamenti che richiedono più attenzione (o un riavvio) includono:
- cambiamenti nella forma dello stato (un processo si aspetta dati in un formato, il nuovo codice ne aspetta un altro)
- cambiamenti di protocollo o formato messaggi che devono coincidere tra servizi
- migrazioni di schema che richiedono tempo o coordinazione
Erlang fornisce meccanismi per transizioni controllate, ma devi comunque progettare il percorso di upgrade.
La mentalità: upgrade e rollback sono normali
Gli hot upgrade funzionano meglio quando upgrade e rollback sono trattati come operazioni di routine, non emergenze rare. Questo significa pianificare versioning, compatibilità e una chiara via di “undo” fin dall'inizio. Nella pratica, i team affiancano tecniche di live-upgrade a rollout graduali, health check e recovery basato su supervisione.
Anche se non userai Erlang, la lezione trasversale è: progetta i sistemi in modo che cambiarli in sicurezza sia un requisito di prima classe, non un ripensamento.
Dove le idee di Erlang brillano nelle piattaforme real-time
Le piattaforme real-time sono meno una questione di timing perfetto e più di restare reattivi mentre le cose vanno spesso storte: le reti ondeggiano, le dipendenze rallentano e i picchi di traffico arrivano. Il design di Erlang—sostenuto da Joe Armstrong—si adatta a questa realtà perché assume il fallimento e considera la concorrenza come normale, non eccezionale.
Casi d'uso comuni “real-time”
Vedrai il pensiero in stile Erlang brillare ovunque ci siano molte attività indipendenti in corso:
- Messaging e chat: milioni di conversazioni piccole, ognuna con il proprio stato e retry.
- Comunicazione real-time: signaling voce/video, aggiornamenti di presence e coordinamento di sessioni.
- Coordinamento IoT: flotte di dispositivi che si connettono, spariscono e ricompaiono in modo imprevedibile.
- Workflow di pagamento: processi multi-step dove alcuni step sono lenti, non disponibili o richiedono azioni compensative.
Cosa significa solitamente “soft real-time”
La maggior parte dei prodotti non richiede garanzie rigide come “ogni azione completa in 10 ms.” Hanno bisogno di soft real-time: latenza bassa e consistente per le richieste tipiche, recupero rapido quando parti falliscono e alta disponibilità così che gli utenti notino raramente gli incidenti.
Il fallimento è normale: progetta per questo
I sistemi reali incontrano problemi come:
- Connessioni cadute (reti mobili, handoff Wi‑Fi)
- Timeout quando un servizio downstream è lento
- Outage parziali dove una regione o una dipendenza degrada
Il modello di Erlang incoraggia a isolare ogni attività (una sessione utente, un dispositivo, un tentativo di pagamento) così un fallimento non si propaga. Invece di costruire un unico componente gigantesco che tenta di gestire tutto, i team ragionano in unità più piccole: ogni worker fa un lavoro, comunica via messaggi e, se si rompe, viene riavviato pulitamente.
Questo spostamento—da “prevenire ogni fallimento” a “contenere e recuperare rapidamente dai fallimenti”—è spesso ciò che fa sembrare stabili le piattaforme real-time sotto pressione.
Malintesi comuni e limiti reali
La reputazione di Erlang può suonare come una promessa: sistemi che non si fermano mai perché si riavviano. La realtà è più pratica—e più utile. “Let it crash” è uno strumento per costruire servizi affidabili, non una licenza per ignorare i problemi seri.
I riavvii non sono un cerotto
Un errore comune è trattare la supervisione come un modo per nascondere bug profondi. Se un processo crasha immediatamente dopo l'avvio, un supervisor può continuare a riavviarlo fino a entrare in un crash loop—consumando CPU, riempiendo log e potenzialmente causando un outage più grande del bug originale.
I sistemi ben progettati aggiungono backoff, limiti di intensità di riavvio e comportamenti chiari di “arrendersi e segnalare”. I riavvii dovrebbero ristabilire l'operazione sana, non mascherare un'invariante rotta.
Lo stato è la parte difficile
Riavviare un processo è spesso facile; recuperare lo stato corretto non lo è. Se lo stato vive solo in memoria, devi decidere cosa significa “corretto” dopo un crash:
- Ricostruirlo da uno store duraturo?
- Riprodurre eventi in modo sicuro (idempotenza)?
- Cosa succede al lavoro in volo o agli aggiornamenti parziali?
La fault tolerance non sostituisce un'attenta progettazione dei dati. Ti costringe ad essere esplicito su di essa.
Hai ancora bisogno di osservabilità
I crash sono utili solo se li vedi presto e li comprendi. Ciò significa investire in logging, metriche e tracing—non solo “si è riavviato, quindi va bene.” Vuoi notare l'aumento delle rate di riavvio, code in crescita e dipendenze lente prima che gli utenti le percepiscano.
Esistono limiti operativi reali
Anche con i punti di forza della BEAM, i sistemi possono fallire in modi ordinari:
- Crescita della memoria dovuta a leak, cache o heap grandi
- Accodamento mailbox quando i producer superano i consumer (picchi di latenza e timeout)
- Fallimenti di dipendenze (DB, API di terze parti, DNS) dove riavviare il codice non risolve la causa principale
Il modello di Erlang ti aiuta a contenere e recuperare dai fallimenti—ma non li elimina.
Come applicare le lezioni oggi (anche se non usi Erlang)
Il dono più grande di Erlang non è la sintassi: sono un insieme di abitudini per costruire servizi che restano in esecuzione quando parti inevitabilmente falliscono. Puoi applicare quelle abitudini quasi in qualsiasi stack.
Traduci le idee in azioni concrete
Inizia rendendo espliciti i confini di fallimento. Suddividi il sistema in componenti che possono fallire indipendentemente e assicurati che ciascuno abbia un contratto chiaro (input, output e cosa significa “male”).
Poi automatizza il recovery invece di provare a prevenire ogni errore:
- Isola i componenti: esegui lavoro rischioso in processi/container/thread separati così un crash non avvelena tutto.
- Definisci confini: timeout, retry con backoff, circuit breaker e bulkhead per fermare i failure a catena.
- Rendi il recovery routine: health check, riavvii automatici e default sicuri così il sistema torna rapidamente a uno stato noto.
Un modo pratico per rendere queste abitudini “reali” è integrarle negli strumenti e nel lifecycle, non solo nel codice. Ad esempio, quando i team usano Koder.ai per vibe-code web, backend o app mobile via chat, il flusso naturalmente incoraggia pianificazione esplicita (Planning Mode), deployment ripetibili e iterazione sicura con snapshot e rollback—concetti che si allineano con la stessa mentalità operativa che Erlang ha reso popolare: assumere che cambio e failure accadranno e rendere il recovery noioso.
Punti di partenza fuori da Erlang
Puoi approssimare i pattern di supervisione con strumenti che forse già usi:
- Supervisor: systemd, Kubernetes Deployments o un process manager (restart-on-failure, readiness probes).
- Isolamento dei processi: servizi worker separati per task CPU-intensive o non attendibili.
- Passaggio di messaggi: code/stream (RabbitMQ, SQS, Kafka) per disaccoppiare produttori e consumatori e levigare i picchi.
Checklist decisionale rapida
Prima di copiare pattern, decidi cosa ti serve davvero:
- Modalità di failure previste: sovraccarico, outage parziali, dipendenze lente, input errati, memory leak.
- Necessità di latenza: richiedi risposte real-time o il processamento eventuale è OK?
- Obiettivo di recovery: riavvio veloce, degrado controllato o intervento manuale?
- Competenze del team e tooling: chi sarà on-call, osservabilità e gestione degli incidenti?
Se vuoi passi pratici successivi, il post rimanda a guide correlate nel blog e ai dettagli di implementazione in docs (e ai piani in pricing se stai valutando tool).
Domande frequenti
Why is Joe Armstrong’s Erlang mindset still relevant today?
Erlang ha reso popolare un approccio pratico all'affidabilità: assumi che parti del sistema possano fallire e progetta cosa succede dopo.
Invece di cercare di prevenire ogni crash, enfatizza isolamento dei guasti, rilevamento rapido e recupero automatico, che si applicano bene a piattaforme real-time come chat, instradamento chiamate, notifiche e servizi di coordinamento.
What does “real-time” mean in the post’s plain terms?
In questo contesto, “real-time” di solito significa soft real-time:
- risposte percepibilmente rapide e coerenti
- comportamento prevedibile sotto carico
- il sistema continua a funzionare durante failure parziali
È meno una questione di microsecondi e più di evitare blocchi, spirali e outage a catena.
What does “concurrency by default” mean in Erlang-style design?
Concorrenza di default significa strutturare il sistema come molti piccoli worker isolati invece di pochi componenti grandi e strettamente accoppiati.
Ogni worker gestisce una responsabilità ristretta (una sessione, un dispositivo, una chiamata, un loop di retry), il che facilita scaling e contenimento dei guasti.
What are Erlang “lightweight processes,” and why do they matter?
I processi leggeri sono piccoli worker indipendenti che puoi creare in gran numero.
Praticamente, aiutano perché:
- puoi modellare un processo per ogni “cosa” (utente/sessione/dispositivo)
- i fallimenti restano locali a un singolo worker
- riavviare il lavoro è economico rispetto al riavvio di un monolite
Why does Erlang prefer message passing over shared state?
Il passing di messaggi coordina tramite invio di messaggi invece di condividere uno stato mutabile.
Questo riduce molte classi di bug di concorrenza (come le race condition) perché ogni worker possiede il proprio stato interno; gli altri possono solo richiedere cambiamenti indirettamente tramite messaggi.
What is back-pressure in an actor/message system, and how do you handle it?
Il back-pressure si verifica quando un worker riceve messaggi più velocemente di quanto possa elaborarli, quindi la sua mailbox cresce.
Modi pratici per gestirlo includono:
- monitorare le dimensioni delle mailbox/queue
- applicare limiti (drop, campionamento o cap)
- distribuire il carico su più worker
- degradare con grazia (es. passare a digest per notifiche non critiche)
What does “let it crash” actually mean (and what doesn’t it mean)?
“Let it crash” significa: se un worker raggiunge uno stato invalido o inatteso, dovrebbe fallire rapidamente invece di arrancare.
La recovery è gestita in modo strutturato (via supervisione), il che può produrre percorsi logici più semplici e un recupero più prevedibile—a condizione che i riavvii siano sicuri e rapidi.
What are supervision trees, and why are they central to fault tolerance?
Un albero di supervisione è una gerarchia in cui i supervisor osservano i worker e li riavviano secondo regole definite.
Invece di spargere logiche di recovery ad-hoc ovunque, la centralizzi:
- decidi cosa riavviare quando qualcosa fallisce
- previeni crash loop con limiti e backoff
- riavvia gruppi insieme quando i componenti devono rimanere sincronizzati
What is OTP, and how does it help build reliable services?
OTP è l'insieme di pattern standard (behaviours) e convenzioni che rendono i sistemi Erlang operabili a lungo termine.
Componenti comuni includono:
gen_serverper worker di lunga durata con statosupervisorper policy di riavvioapplicationper definire come si avvia, arresta e si integra un servizio
Il vantaggio è avere cicli di vita condivisi e ben compresi invece di framework ad-hoc.
How can I apply Erlang’s lessons if I’m not using Erlang?
Puoi applicare gli stessi principi in altri stack rendendo failure e recovery elementi di prima classe:
- isola il lavoro rischioso (processi/servizi/container separati)
- aggiungi timeout, retry con backoff, circuit breaker e bulkhead
- automatizza il recovery (health check + restart-on-failure)
- usa code/stream per disaccoppiare produttori e consumatori
Per approfondire, il post rimanda a guide correlate in blog e ai dettagli di implementazione in docs.