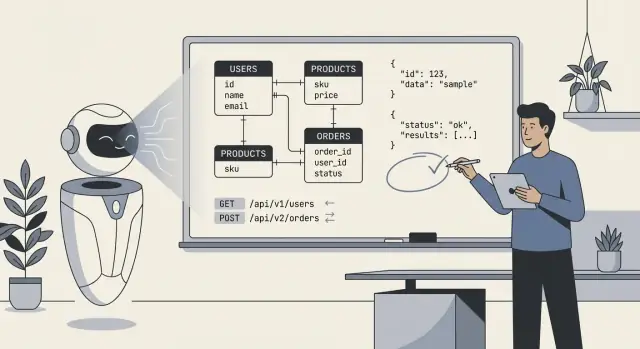
Cosa significa davvero “l'IA progetta il tuo backend”
Quando si dice “l'IA ha progettato il nostro backend”, spesso si intende che il modello ha prodotto una prima bozza del progetto tecnico centrale: tabelle del database (o collezioni), come quei pezzi si relazionano e le API che leggono e scrivono i dati. In pratica non è tanto “l'IA ha costruito tutto” quanto “l'IA ha proposto una struttura che possiamo implementare e raffinare”.
Cosa include tipicamente un backend progettato dall'IA
Al minimo, l'IA può generare:
- Schemi ed entità: tabelle/collezioni come
users, orders, subscriptions, più campi e tipi di base.
- Relazioni: relazioni uno-a-molti e molti-a-molti (es. un ordine ha molte line items; un prodotto appartiene a molte categorie).
- Vincoli e validazioni: campi obbligatori, chiavi uniche, range semplici, stati tipo enum e regole di integrità referenziale di base.
- Surface API: endpoint CRUD, formati di request/response, pattern di paginazione, formati di errore e talvolta suggerimenti sul versioning.
Cosa non può decidere senza il tuo contesto di business
L'IA può inferire pattern “tipici”, ma non può scegliere con affidabilità il modello corretto quando i requisiti sono ambigui o specifici del dominio. Non conoscerà le tue reali policy su:
- Cosa conta come “utente” (ruoli? organizzazioni? account guest?).
- Quali campi sono legalmente obbligatori, sensibili o soggetti a regole di retention.
- Quali azioni devono essere auditabili, reversibili o richiedere approvazione.
- Il vero significato degli stati (es.
cancelled vs refunded vs voided).
L'aspettativa giusta: copilota, non autorità finale
Tratta l'output dell'IA come un punto di partenza veloce e strutturato—utile per esplorare opzioni e individuare omissioni—ma non come una specifica da distribuire così com'è. Il tuo compito è fornire regole chiare e casi limite, poi rivedere ciò che l'IA ha prodotto come faresti con la prima bozza di un ingegnere junior: utile, a volte impressionante, ma talvolta sbagliata in modi sottili.
L'IA può abbozzare rapidamente uno schema o un'API, ma non può inventare i fatti mancanti che rendono un backend “adatto” al tuo prodotto. I migliori risultati arrivano quando tratti l'IA come un rapido progettista junior: tu fornisci vincoli chiari e lei propone opzioni.
Prima di chiedere tabelle, endpoint o modelli, annota l'essenziale:
- Entità principali e definizioni: quali oggetti esistono (es. User, Subscription, Order) e cosa significa ciascuno nel tuo business.
- Workflows chiave: i percorsi principali (signup, checkout, rimborsi, approvazioni) e gli stati attraverso cui passano.
- Ruoli e permessi: chi può fare cosa (admin, staff, cliente, auditor) e cosa deve essere ristretto.
- Bisogni di reporting e analytics: le domande a cui devi rispondere dopo (fatturato mensile, retention per coorti, metriche SLA), incluse le dimensioni per i group-by.
- Integrazioni e ID esterni: provider di pagamento, CRM, sistemi di identità—e quali ID devono essere salvati.
- Aspettative di scala e performance: ordine di grandezza (centinaia vs milioni di record) e aspettative di latenza.
- Compliance e retention: GDPR/CCPA, log di audit, regole di cancellazione, residenza dei dati, periodi di retention.
- Realtà operative: backfill, import, override manuali e scenari in cui il team di supporto deve modificare X.
Perché requisiti poco chiari generano modelli fragili
Quando i requisiti sono vaghi, l'IA tende a “indovinare” default: campi opzionali dappertutto, colonne di stato generiche, proprietà di ownership poco chiare e naming incoerente. Questo porta spesso a schemi apparentemente sensati che però si rompono all'uso reale—soprattutto su permessi, reporting e edge case (rimborsi, cancellazioni, spedizioni parziali, approvazioni multi-step). Pagherai quel debito più avanti con migrazioni, workaround e API confuse.
Template di requisiti copiabile
Usalo come punto di partenza e incollalo nel tuo prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
Dove l'IA aiuta di più: velocità, coerenza, copertura
L'IA dà il meglio quando la consideri come una macchina per bozze rapide: può tracciare un modello dati sensato e un set di endpoint in pochi minuti. Questa velocità cambia il modo di lavorare—non perché l'output sia magicamente “corretto”, ma perché puoi iterare su qualcosa di concreto subito.
Velocità: da pagina vuota a scheletro funzionante
Il guadagno più grande è eliminare il blocco iniziale. Fornisci all'IA una breve descrizione delle entità, i flussi utenti chiave e i vincoli, e può proporre tabelle/collezioni, relazioni e una baseline di API. È particolarmente utile quando ti serve una demo rapida o stai esplorando requisiti instabili.
La velocità paga di più in:
- Prototipi in cui devi validare un concetto con flussi dati reali
- Strumenti interni dove una struttura “abbastanza buona” conta più di un modelling perfetto
- Prime iterazioni di un prodotto dove prevedi di riscrivere parti comunque
Coerenza: decisioni noiose fatte nello stesso modo
Gli esseri umani si stancano e deviano. L'IA no—quindi è ottima nel ripetere convenzioni su tutto il backend:
- Pattern di naming coerenti (es.
createdAt, updatedAt, customerId)
- Forme endpoint prevedibili (
/resources, /resources/:id) e payload uniformi
- Parametri standard per paginazione e filtraggio
Questa coerenza rende il backend più semplice da documentare, testare e passare ad altri sviluppatori.
Copertura: “abbiamo dimenticato qualche endpoint?”
L'IA è anche brava nella completezza. Se chiedi CRUD più operazioni comuni (search, list, bulk update), solitamente genera una superficie iniziale più completa di una bozza umana frettolosa.
Un vantaggio rapido comune è standardizzare gli errori: un envelope di errore uniforme (code, message, details) su tutti gli endpoint. Anche se poi lo affini, avere una forma unica evita mix disordinati di risposte ad hoc.
La mentalità chiave: lascia che l'IA produca l'80% iniziale rapidamente, poi spendi il tempo sul 20% che richiede giudizio—regole di business, edge case e il “perché” dietro il modello.
Modalità di fallimento tipiche negli schemi generati dall'IA
Gli schemi generati dall'IA spesso sembrano “puliti” a prima vista: tabelle ordinate, nomi sensati e relazioni che seguono il percorso felice. I problemi emergono quando dati reali, utenti reali e workflow reali colpiscono il sistema.
Normalizzazione: troppa o troppo poca
L'IA può oscillare tra gli estremi:
- Over-normalization: spaccare tutto in molte tabelle (es. tabelle separate per ogni attributo), rendendo le query comuni costose e aumentando la complessità di join.
- Under-normalization: accatastare campi ripetuti in una singola tabella (es. più colonne indirizzo, flag di stato denormalizzati) che diventano difficili da validare e aggiornare.
Un semplice test: se le tue pagine più comuni richiedono 6+ join, potresti essere over-normalized; se gli aggiornamenti richiedono cambiare lo stesso valore in molte righe, potresti essere under-normalized.
Edge case mancanti che contano in produzione
L'IA spesso omette requisiti “noiosi” che guidano il design reale:
- Multi-tenant: dimenticare
tenant_id sulle tabelle o non applicare scoping tenant nei vincoli unici.
- Soft deletes: aggiungere
deleted_at senza aggiornare regole di unicità o pattern di query per escludere righe eliminate.
- Auditing: mancanza di
created_by/updated_by, cronologie di cambiamento o log di eventi immutabili.
- Time zone: mescolare "date" e "timestamp" senza regole chiare (storage in UTC vs visualizzazione locale), causando bug di off-by-one day.
Assunzioni errate su unicità e lifecycle
L'IA può presumere:
- che un campo sia globalmente unico quando è unico solo per tenant (es.
invoice_number),
- che un campo sia obbligatorio quando è opzionale durante l'onboarding,
- che uno stato singolo sia sufficiente quando servono stati di lifecycle (draft → active → suspended → archived).
Questi errori emergono come migrazioni goffe e workaround lato applicazione.
La maggior parte degli schemi generati non riflette come eseguirete le query:
- mancano indici composti per filtri comuni (
tenant_id + created_at),
- nessun piano per "hot path" (ultimi elementi, conteggi non letti),
- eccessivo affidamento su campi JSON senza strategia di indicizzazione.
Se il modello non descrive le prime 5 query dell'app, non può progettare affidabilmente lo schema per esse.
API Design: cosa l'IA fa bene e cosa no
L'IA è spesso sorprendentemente buona nel produrre un'API che “sembra standard”. Replicherà pattern familiari da framework e API pubbliche, il che può far risparmiare tempo. Il rischio è che ottimizzi per ciò che sembra plausibile invece che per ciò che è corretto per il tuo prodotto, il tuo modello di dati e i cambiamenti futuri.
Cosa l'IA solitamente azzecca
Basi del modeling delle risorse. Con un dominio chiaro, l'IA tende a scegliere sostantivi e URL sensati (es. /customers, /orders/{id}, /orders/{id}/items). È brava anche a mantenere convenzioni di naming coerenti.
Scaffolding degli endpoint comuni. Spesso include l'essenziale: endpoint list vs detail, create/update/delete e forme di request/response prevedibili.
Convenzioni di base. Se lo chiedi esplicitamente, può standardizzare paginazione, filtraggio e sorting. Per esempio: ?limit=50&cursor=... (cursor pagination) o ?page=2&pageSize=25 (page-based), oltre a ?sort=-createdAt e filtri come ?status=active.
Dove l'IA spesso sbaglia
Astrazioni che perdono dati. Un errore classico è esporre tabelle interne direttamente come "risorse", specialmente quando lo schema ha tabelle di join, campi denormalizzati o colonne di audit. Si finiscono per avere endpoint come /user_role_assignments che rispecchiano dettagli implementativi invece del concetto utente (“ruoli di un utente”). Questo rende l'API più difficile da usare e da evolvere.
Gestione errori incoerente. L'IA può mischiare stili: a volte restituire 200 con un body di errore, a volte usare 4xx/5xx. Vuoi un contratto chiaro:
- Usa codici HTTP appropriati (
400, 401, 403, 404, 409, 422)
- Un envelope di errore coerente (es.
{ "error": { "code": "...", "message": "...", "details": [...] } })
Versioning come dopo pensiero. Molti design generati saltano una strategia di versioning fino a quando non diventa doloroso. Decidi dal giorno 1 se userai path versioning (/v1/...) o versioning via header, e definisci cosa sia un breaking change. Avere regole previene rotture accidentali.
Regola pratica
Usa l'IA per velocità e coerenza, ma tratta il design API come un'interfaccia di prodotto. Se un endpoint rispecchia il database invece della mental model dell'utente, è un segnale che l'IA ha ottimizzato per facilità di generazione, non per usabilità a lungo termine.
Un workflow pratico per usare l'IA senza perdere il controllo
Make it real for users
Put your backend behind a custom domain when you are ready to share it.
Tratta l'IA come un progettista junior veloce: ottima nel produrre bozze, non responsabile del sistema finale. L'obiettivo è usare la sua velocità mantenendo l'architettura intenzionale, revisionabile e guidata dai test.
Se usi uno strumento vibe-coding come Koder.ai, questa separazione di responsabilità diventa ancora più importante: la piattaforma può abbozzare e implementare rapidamente un backend (per esempio servizi Go con PostgreSQL), ma devi comunque definire invarianti, confini di autorizzazione e regole di migrazione accettabili.
Un loop ripetibile: prompt → draft → review → tests → revise
Inizia con un prompt preciso che descriva dominio, vincoli e “che cosa significa successo”. Richiedi prima un modello concettuale (entità, relazioni, invarianti), non tabelle.
Poi itera in un ciclo fisso:
- Prompt: indica requisiti, non-goals, assunzioni di scala e convenzioni di naming.
- Draft: l'IA propone un modello concettuale + uno schema di prima mano + contratti API.
- Review: controlli correttezza di dominio, edge case e conformità con decisioni di prodotto.
- Tests: scrivi o genera test che codificano le decisioni (validazioni, autorizzazioni, idempotenza, sicurezza delle migrazioni).
- Revise: reinserisci i fallimenti rilevati (note di review + test falliti) e richiedi una versione corretta.
Questo loop funziona perché trasforma i suggerimenti dell'IA in artefatti che possono essere provati o rifiutati.
Separa modello concettuale, schema fisico e contratti API
Mantieni tre livelli distinti:
- Modello concettuale: ciò che interessa al business (es. “Subscription può essere messa in pausa”, “Invoice deve riferirsi a un periodo di fatturazione”).
- Schema fisico: come lo memorizzi (tabelle/collezioni, indici, vincoli, partizionamento).
- Contratti API: come i client interagiscono (risorse, request/response, codici di errore, strategia di versioning).
Chiedi all'IA di restituire queste sezioni separatamente. Quando qualcosa cambia (es. un nuovo stato o regola), aggiorni prima il livello concettuale e poi riconcili schema e API. Questo riduce l'accoppiamento accidentale e rende i refactor meno dolorosi.
Tieni traccia delle decisioni con note leggere
Ogni iterazione dovrebbe lasciare una traccia. Usa brevi riassunti in stile ADR (una pagina o meno) che catturino:
- Decisione: cosa hai scelto (es. “soft delete via
deleted_at”).
- Razionalità: perché (requisiti di audit, flusso di restore).
- Alternative considerate: e perché scartate.
- Conseguenze: impatto su migrazione, complessità delle query, comportamento API.
Quando incolli feedback all'IA, includi le note di decisione rilevanti testualmente. Questo evita che il modello “dimentichi” scelte precedenti e aiuta il team a comprendere il backend mesi dopo.
Prompt che producono schemi e API migliori
L'IA è più facile da guidare quando tratti il prompting come scrittura di specifiche: definisci il dominio, indica i vincoli e esigi output concreti (DDL, tabelle endpoint, esempi). L'obiettivo non è “essere creativi” ma “essere precisi”.
Prompt per entità e relazioni (con vincoli)
Chiedi un modello dati e le regole che lo mantengono consistente.
- “Design a relational schema for subscriptions with entities: User, Plan, Subscription, Invoice. Include cardinalities, unique constraints, and soft-delete strategy. Rules: one active subscription per user; invoices must reference immutable plan price at purchase time; store currency as ISO code; timestamps in UTC.”
Se hai convenzioni già fissate, dicile: stile di naming, tipo di ID (UUID vs bigint), policy di nullable e aspettative di indicizzazione.
Prompt per endpoint e contratti (con esempi)
Richiedi una tabella API con contratti espliciti, non solo una lista di rotte.
- “Propose REST endpoints for Subscription management. For each endpoint: method, path, auth, query params, request JSON, response JSON, error codes, and idempotency guidance. Include examples for success and two failure cases.”
Aggiungi comportamenti di business: stile di paginazione, campi per sorting e come funzionano i filtri.
Prompt per migrazioni e compatibilità all'indietro
Fai ragionare il modello in release.
- “We’re adding
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field.”
Anti-pattern di prompt da evitare
I prompt vaghi producono sistemi vaghi.
- “Design the database for an e-commerce app” (troppo ampio)
- “Make it scalable and secure” (mancano vincoli misurabili)
- “Generate the best schema” (nessuna regola di dominio)
- “Create APIs for everything” (mancano confini e priorità)
Quando vuoi output migliore, stringi il prompt: specifica le regole, gli edge case e il formato del deliverable.
Checklist di revisione umana prima di rilasciare
Extend beyond the backend
Generate web, server, and mobile apps from chat when your backend is ready.
L'IA può abbozzare un backend decente, ma metterlo in produzione richiede ancora un passaggio umano. Tratta questa checklist come un “gate di rilascio”: se non puoi rispondere con sicurezza a un punto, fermati e correggi prima che diventi dati di produzione.
Checklist schema (tabelle, collezioni e colonne)
- Primary keys: ogni tabella ha una PK chiara. Se usi UUID, conferma strategy di generazione (DB vs app) e indicizzazione.
- Foreign keys & constraints: aggiungi FK dove le relazioni sono reali. Verifica regole ON DELETE/ON UPDATE intenzionali (restrict vs cascade vs set null).
- Unicità: applica unicità nel DB (non solo nel codice): email, ID esterni, vincoli composti (es.
(tenant_id, slug)).
- Nullability: rivedi ogni campo nullable. Se “sconosciuto” è diverso da “vuoto”, modellalo esplicitamente.
- Indici: aggiungi indici per filtri/ordinamenti/join frequenti. Rimuovi indici accidentali su campi a bassa cardinalità.
- Coerenza di naming: scegli convenzioni (singolare vs plurale, suffisso
_id, timestamp) e applicale uniformemente.
Decisioni di integrità dati (quelle costose da cambiare dopo)
Conferma le regole del sistema per iscritto:
- Integrità referenziale: quali relazioni non devono mai rompersi? Quali possono essere "best-effort"?
- Regole di cascading: se un genitore viene cancellato, i figli vanno cancellati, orfani o bloccati?
- Strategia di soft delete: se usi soft delete, assicurati che le query non rimettano in vita record eliminati. Decidi se i vincoli unici devono ignorare le righe soft-deleted.
Checklist API (comportamento e sicurezza)
- Auth & authorization: identifica chi può chiamare ogni endpoint e cosa può accedere (soprattutto in scenari multi-tenant).
- Validazione: valida tipi, range, formati e regole cross-field. Non affidarti agli errori DB come validazione.
- Rate limit & controlli anti-abuso: aggiungi default sensati, per utente/token/IP dove appropriato.
- Idempotency: per operazioni di create/pagamento, supporta chiavi di idempotenza o request IDs deterministici.
- Errori coerenti: standardizza shape degli errori e codici HTTP. Assicurati che i messaggi non perdano internals sensibili.
Prima di unire, fai una rapida review “happy path + worst path”: una request normale, una invalida, una non autorizzata e uno scenario di alto volume. Se l'API ti sorprende, sorprenderà anche gli utenti.
Strategia di testing per backend progettati dall'IA
L'IA può generare uno schema e una surface API plausibili, ma non può dimostrare che il backend si comporterà correttamente sotto traffico reale, con dati reali e futuri cambiamenti. Tratta l'output dell'IA come una bozza e ancorala con test che fissino il comportamento.
Contract test per API
Inizia con test di contratto che validano request, response e semantica degli errori—non solo i "happy paths". Esegui una piccola suite contro un'istanza reale (o container) del servizio.
Concentrati su:
- codici di stato e body di errore (es. 400 vs 404 vs 409 conflict)
- edge case di validazione (stringhe vuote, payload sovradimensionati, campi inattesi)
- stabilità di paginazione e sorting (ordinamento consistente, correttezza del cursor)
- idempotenza per create/update (retry sicuri, uso di idempotency keys se previsto)
Se pubblichi uno spec OpenAPI, genera test da esso—ma aggiungi anche casi scritti a mano per le parti delicate che lo spec non esprime (regole di autorizzazione, vincoli di business).
Test di migrazione e piani di rollback
Gli schemi generati dall'IA spesso tralasciano dettagli operativi: default sicuri, backfill e reversibilità. Aggiungi test di migrazione che:
- applichino migrazioni da DB vuoto e da snapshot "sporco" più vecchio
- verifichino che i vincoli (unici, FK) si comportino come previsto dopo il backfill
- esercitino il rollback (o almeno un piano di fix forward) per ogni migrazione
Tieni uno scriptato piano di rollback per produzione: cosa fare se una migrazione è lenta, blocca tabelle o rompe compatibilità.
Non benchmarkare endpoint generici. Cattura pattern di query rappresentativi (liste principali, ricerca, join, aggregazioni) e testali sotto carico.
Misura:
- latenza p95/p99 per endpoint
- numero di query DB e query lente
- utilizzo e mancanza di indici
Qui i design IA spesso cedono: tabelle “ragionevoli” che generano join costosi sotto carico.
Fondamentali di security testing
Aggiungi controlli automatici per:
- regole AuthZ (l'utente A non può accedere alle risorse dell'utente B)
- injection (SQL/NoSQL, path traversal, JSON injection)
- gestione dei dati sensibili (niente segreti nei log, redaction corretta, cifratura quando richiesta)
Anche test di base di sicurezza evitano gli errori più costosi: endpoint funzionanti che però espongono troppo.
Migrazioni, refactor e mantenibilità a lungo termine
L'IA può abbozzare un buon schema "versione 0", ma il tuo backend vivrà fino alla versione 50. La differenza tra un backend che invecchia bene e uno che collassa è come lo fai evolvere: migrazioni, refactor controllati e documentazione chiara delle intenzioni.
Far evolvere in sicurezza schemi generati dall'IA
Tratta ogni cambiamento di schema come una migrazione, anche se l'IA suggerisce "alter table". Usa passi espliciti e reversibili: aggiungi colonne nuove prima, backfilla, poi rafforza i vincoli. Preferisci cambiamenti additivi (nuovi campi, nuove tabelle) piuttosto che distruttivi (rename/drop) finché non hai provato che nessuno dipende dalla forma vecchia.
Quando chiedi all'IA aggiornamenti di schema, includi lo schema corrente e le regole di migrazione che segui (es. “no drop di colonne; usa expand/contract”). Questo riduce la probabilità che proponga cambiamenti teoricamente corretti ma rischiosi in produzione.
Gestire breaking changes senza caos
I cambiamenti breaking raramente sono un singolo istante; sono una transizione.
- Deprecation: mantieni vecchi campi/endpoint funzionanti mentre logghi l'uso.
- Dual-write: scrivi simultaneamente su colonne/tabelle vecchie e nuove durante la finestra di transizione.
- Backfills: esegui job one-time o incrementali per popolare le nuove strutture.
L'IA è utile a scrivere piani step-by-step (inclusi snippet SQL e ordine di rollout), ma valida sempre l'impatto runtime: lock, transazioni lunghe e se il backfill è riprendibile.
Rifattorizzare modelli dati senza riscrivere tutto
I refactor dovrebbero mirare a isolare il cambiamento. Se devi normalizzare, splittare una tabella o introdurre un event log, mantieni layer di compatibilità: view, codice di traduzione o tabelle shadow. Chiedi all'IA di proporre un refactor che preservi i contratti API esistenti e di elencare cosa deve cambiare in query, indici e vincoli.
Documenta le assunzioni in modo che i futuri prompt restino coerenti
La maggior parte della deriva a lungo termine accade perché il prossimo prompt dimentica l'intento originario. Tieni un breve “data model contract”: regole di naming, strategia ID, semantica dei timestamp, policy di soft-delete e invarianti (es. “un order total è derivato, non memorizzato”). Collega questo documento nella docs interna (es. /docs/data-model) e riusalo nei prompt futuri così che i progetti restino dentro gli stessi confini.
Considerazioni su sicurezza e privacy
Iterate without fear
Experiment with migrations and roll back safely using snapshots and rollback.
L'IA può scrivere tabelle e endpoint rapidamente, ma non possiede il rischio. Tratta sicurezza e privacy come requisiti di prima classe da includere nel prompt e poi verifica in review—soprattutto attorno ai dati sensibili.
Parti dalla classificazione dei dati
Prima di accettare uno schema, etichetta i campi per sensibilità (public, internal, confidential, regulated). Quella classificazione guida cosa cifrare, mascherare o minimizzare.
Per esempio: password mai memorizzate in chiaro (solo hash salati), token a breve durata e cifrati a riposo, PII come email/telefono possono richiedere masking nelle view admin ed export. Se un campo non è necessario al valore prodotto, non memorizzarlo—l'IA tende ad aggiungere attributi “carini” che aumentano l'esposizione.
Controllo degli accessi: RBAC vs ABAC
Le API generate dall'IA spesso defaultano a semplici controlli per ruolo. RBAC è facile da ragionare ma può rompersi con regole di ownership (“l'utente vede solo le sue fatture”) o regole contestuali (“supporto può vedere dati solo durante un ticket attivo”). ABAC gestisce meglio questi casi ma richiede policy esplicite.
Sii chiaro sul pattern scelto e assicurati che ogni endpoint lo applichi coerentemente—soprattutto list/search che sono punti comuni di leakage.
Evita il logging accidentale di campi sensibili
Il codice generato può loggare interi body di request, header o righe DB durante errori. Questo può esporre password, token e PII in log e strumenti APM.
Imposta default come: log strutturati, allowlist di campi loggabili, redaction dei segreti (Authorization, cookies, reset tokens) e evita di loggare payload grezzi su fallimento di validazione.
Privacy, retention e cancellazione
Progetta la cancellazione fin dal giorno 1: delete iniziata dall'utente, chiusura account e workflow per il "diritto all'oblio". Definisci finestre di retention per classe di dato (es. audit events vs eventi marketing) e assicurati di poter provare cosa è stato cancellato e quando.
Se tieni log di audit, memorizza identificatori minimi, proteggili con accessi più restrittivi e documenta come esportare o cancellare i dati quando richiesto.
Quando usare l'IA (e quando no)
L'IA rende il meglio quando la tratti come un architetto junior veloce: ottima per bozze, debole nelle tradeoff critici del dominio. La domanda giusta non è tanto “L'IA può progettare il mio backend?” quanto “Quali parti può abbozzare in sicurezza e quali richiedono ownership esperta?”
Buoni usi: bozze, prototipi e pattern ben compresi
L'IA fa risparmiare tempo quando costruisci:
- Prototipi piccoli, tool interni e MVP dove l'obiettivo è imparare in fretta.
- Sistemi CRUD con entità familiari (users, orders, subscriptions) e vincoli standard.
- Momenti di pagina bianca: generare uno schema iniziale, surface API e convenzioni di naming su cui iterare.
Qui l'IA è preziosa per velocità, coerenza e copertura—soprattutto se sai già come vuoi che il prodotto si comporti e puoi riconoscere gli errori.
Casi sconsigliati: domini regolamentati, ad alto rischio o ricchi di dominio
Sii prudente (o limita l'IA a ispirazione) quando lavori in:
- Finance: ledger, riconciliazione, tracciamento di audit e regole di idempotenza che devono essere esatte.
- Healthcare: dati paziente, modelli di consenso, regole di retention, interoperabilità.
- Domini safety-critical: dove un"assunzione ragionevole" può diventare un incidente costoso.
In questi ambiti, l'expertise di dominio pesa più della velocità dell'IA. Requisiti sottili—legali, clinici, contabili, operativi—spesso non sono nel prompt e l'IA li riempirà con confidenza.
Guida decisionale: usa l'IA per bozze, impONE la firma umana
Regola pratica: lascia che l'IA proponga opzioni, ma richiedi sempre revisione finale per invarianti del modello dati, confini di autorizzazione e strategia di migrazione. Se non puoi nominare chi è responsabile per schema e contratti API, non mettere in produzione un backend progettato dall'IA.
Prossimi passi
Se stai valutando workflow e guardrail, vedi le guide correlate in /blog. Se vuoi aiuto ad applicare queste pratiche al processo del tuo team, controlla /pricing.
Se preferisci un workflow end-to-end dove puoi iterare via chat, generare un'app funzionante e mantenere comunque il controllo tramite export del codice sorgente e snapshot rollback-friendly, Koder.ai è pensata proprio per questo stile di costruzione e revisione.