Perché non sono scelte separate
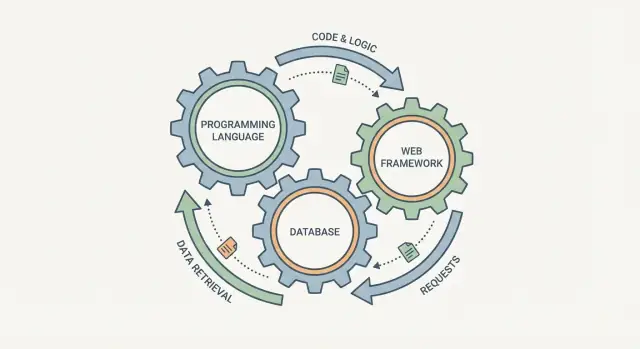
È facile segnare il linguaggio di programmazione, il database e il framework web come tre checkbox indipendenti. In pratica si comportano più come ingranaggi collegati: cambi uno e gli altri lo avvertono.
Un framework web definisce come vengono gestite le richieste, come vengono validate i dati e come vengono riportati gli errori. Il database determina cosa è “facile da memorizzare”, come si interrogano le informazioni e quali garanzie hai quando più utenti agiscono contemporaneamente. Il linguaggio sta in mezzo: determina quanto è sicuro esprimere regole, come gestire la concorrenza e su quali librerie e strumenti puoi contare.
Cosa significa “un unico sistema”
Trattare lo stack come un singolo sistema significa non ottimizzare ogni parte in isolamento. Scegli una combinazione che:
- Rappresenti i tuoi dati in modo naturale (così non combatti continuamente conversioni)
- Supporti le tue necessità di coerenza (così i bug non si nascondono negli edge case)
- Si adatti al flusso di lavoro del team (così rilasciare e mantenere è prevedibile)
Questo articolo resta pratico e volutamente poco tecnico. Non serve memorizzare teoria dei database o internals del linguaggio: serve vedere come le scelte riverberano sull'intera applicazione.
Un esempio rapido: usare un database senza schema per dati di business molto strutturati e orientati al reporting spesso porta a regole sparse nel codice applicativo e a analytics confuse. Un abbinamento migliore può essere il database relazionale con un framework che incoraggi validazione coerente e migrazioni, così i dati restano coerenti mentre il prodotto evolve.
Quando pianifichi lo stack insieme, progetti un unico insieme di compromessi—non tre scommesse indipendenti.
Un modello mentale semplice: richiesta in ingresso, dati in uscita
Un modo utile per pensare a uno “stack” è come una singola pipeline: una richiesta utente entra nel sistema e ne esce una risposta (più dati salvati). Linguaggio, framework e database non sono scelte indipendenti: sono tre parti dello stesso viaggio.
Il viaggio di una richiesta
Immagina che un cliente aggiorni l'indirizzo di spedizione.
- Request in: il framework riceve una richiesta HTTP. Il routing decide quale handler eseguire (es.
/account/address). La validazione verifica che l'input sia completo e sensato.
- Si lavora: il tuo codice applicativo (scritto nel linguaggio scelto) esegue le regole di business: “L'utente è autenticato?”, “Questo formato d'indirizzo è accettabile?”, “Dobbiamo segnare quell'ordine per un controllo?”
- Dati out: il livello di persistenza legge e scrive record—spesso all'interno di una transazione—così l'aggiornamento viene applicato tutto o niente.
- Response out: il framework formatta il risultato (HTML/JSON), imposta i codici di stato e lo restituisce all'utente.
- Dopo: job in background possono avviare altri lavori (inviare email di conferma, aggiornare l'indice di ricerca, notificare il magazzino).
Di cosa si occupa realmente ogni scelta
- Linguaggio: come gira il codice (runtime/modello di concorrenza), quanto è facile testare e fare debug, e se le competenze del team e gli strumenti rendono le modifiche sicure e rapide.
- Framework: il “controllo del traffico” per le richieste—routing, validazione, hook di autenticazione, gestione errori e pattern integrati per i job in background.
- Database: come vengono memorizzati e interrogati i dati, quali vincoli impediscono dati errati e come le transazioni mantengono consistenti gli aggiornamenti correlati.
Quando questi tre sono allineati, una richiesta scorre senza intoppi. Quando non lo sono, appare attrito: accesso ai dati goffo, validazioni che perdono informazioni e bug di coerenza sottili.
Modello dei dati prima di tutto: il driver nascosto dell'adattamento dello stack
La maggior parte dei dibattiti sullo “stack” parte dal linguaggio o dal brand del database. Un punto di partenza migliore è il tuo modello dati—perché detta silenziosamente cosa risulterà naturale (o doloroso) ovunque altrove: validazione, query, API, migrazioni e persino il flusso di lavoro del team.
Le applicazioni di solito gestiscono quattro forme contemporaneamente:
- Oggetti nel codice (classi, struct, record tipizzati)
- Righe in tabelle relazionali
- Documenti in storage stile JSON o API
- Eventi in log/stream (“OrderPlaced”, “EmailSent”)
Un buon abbinamento è quando non passi le giornate a tradurre tra forme. Se i tuoi dati core sono altamente connessi (utenti ↔ ordini ↔ prodotti), le righe e i join possono mantenere la logica semplice. Se i dati sono per lo più “un blob per entità” con campi variabili, i documenti possono ridurre la burocrazia—fino al momento in cui serve reporting cross-entità.
Schema vs struttura flessibile (e dove vivono le regole)
Quando il database ha uno schema forte, molte regole possono vivere vicino ai dati: tipi, vincoli, chiavi esterne, unicità. Questo spesso riduce i controlli duplicati tra servizi.
Con strutture flessibili, le regole si spostano nell'applicazione: codice di validazione, payload versionati, backfill e logica di lettura attenta (“se il campo esiste, allora …”). Questo può funzionare bene quando i requisiti di prodotto cambiano settimanalmente, ma incrementa il carico sul framework e sui test.
Come le scelte di modellazione influenzano la complessità del codice
Il tuo modello decide se il codice sarà per lo più:
- Query e join (relazionale-heavy)
- Trasformazione di JSON annidati (documentale-heavy)
- Replay e aggregazione di eventi (event-heavy)
Questo, a sua volta, influenza le esigenze di linguaggio e framework: il tipaggio forte può prevenire derive sottili nei campi JSON, mentre tool maturi per le migrazioni contano di più quando gli schemi evolvono frequentemente.
Esempi: profilo utente, ordini, log di audit
- Profilo utente: spesso simile a un documento (preferenze, campi opzionali) ma beneficia di vincoli relazionali per identità e unicità.
- Ordini: tipicamente relazionali (righe degli articoli, totali, stati) perché la coerenza e il reporting sono importanti.
- Audit log: naturalmente a eventi—voci append-only che raramente si aggiornano, ottimizzate per query per tempo, attore o entità.
Scegli il modello prima; la scelta “giusta” di framework e database spesso diventa più chiara dopo.
Transazioni e coerenza: dove iniziano spesso i bug
Le transazioni sono la garanzia “tutto o niente” da cui l'app dipende silenziosamente. Quando un checkout ha successo, ti aspetti che l'ordine, lo stato del pagamento e l'aggiornamento dell'inventario o tutto avvengano—o niente. Senza questa promessa ottieni i bug più difficili: rari, costosi e difficili da riprodurre.
Cosa fanno davvero le transazioni
Una transazione raggruppa più operazioni di database in un'unità di lavoro. Se qualcosa fallisce a metà (errore di validazione, timeout, processo crash), il database può fare rollback allo stato precedente sicuro.
Questo conta oltre i flussi di denaro: creazione account (riga utente + riga profilo), pubblicazione di contenuti (post + tag + puntatori per la ricerca) o qualsiasi workflow che tocca più di una tabella.
Coerenza vs velocità (in termini semplici)
Coerenza significa “le letture rispecchiano la realtà”. Velocità significa “restituire qualcosa rapidamente”. Molti sistemi fanno compromessi:
- Coerenza forte: gli utenti vedono i dati più recenti, meno sorprese, spesso con costi di coordinazione più alti.
- Coerenza eventuale: gli aggiornamenti si propagano nel tempo, solitamente più veloce e più semplice da scalare, ma l'app deve gestire discrepanze temporanee.
Il fallimento comune è scegliere una configurazione eventualmente consistente e poi programmare come se fosse fortemente consistente.
Come framework e ORM influenzano i risultati
I framework e gli ORM non creano transazioni automaticamente solo perché hai chiamato più metodi “save”. Alcuni richiedono blocchi espliciti di transazione; altri avviano una transazione per richiesta, il che può nascondere problemi di performance.
I retry sono delicati: gli ORM possono riprovare su deadlock o errori transitori, ma il tuo codice deve essere sicuro da eseguire due volte.
Pitfall comuni
Le scritture parziali avvengono quando aggiorni A e poi fallisci prima di aggiornare B. Azioni duplicate si verificano quando una richiesta viene ritentata dopo un timeout—soprattutto se addebiti una carta o invii un'email prima che la transazione sia committata.
Una regola semplice aiuta: fai avvenire gli effetti collaterali (email, webhook) dopo il commit del database e rendi le azioni idempotenti usando vincoli di unicità o chiavi di idempotenza.
Il livello di accesso al database: ORM, query e migrazioni
Questo è il “livello di traduzione” tra il codice applicativo e il database. Le scelte qui spesso contano più del brand del database stesso nella quotidianità.
ORM vs query builder vs SQL grezzo (in termini semplici)
Un ORM (Object-Relational Mapper) ti permette di trattare le tabelle come oggetti: creare un User, aggiornare un Post e l'ORM genera SQL dietro le quinte. È produttivo perché standardizza compiti comuni e nasconde la burocrazia ripetitiva.
Un query builder è più esplicito: costruisci una query simile a SQL usando codice (catene o funzioni). Pensando comunque in “join, filtri, gruppi”, ottieni sicurezza sui parametri e composabilità.
SQL grezzo è scrivere la SQL reale. È il più diretto e spesso il più chiaro per query di reporting complesse—a costo di più lavoro manuale e convenzioni.
Come le caratteristiche del linguaggio modellano i pattern di accesso
I linguaggi con tipaggio forte (TypeScript, Kotlin, Rust) tendono a spingerti verso strumenti che possono validare query e forme dei risultati in anticipo. Questo riduce sorprese a runtime, ma spinge i team a centralizzare l'accesso ai dati affinché i tipi non devino.
I linguaggi con metaprogrammazione flessibile (Ruby, Python) spesso rendono gli ORM naturali e rapidi per iterare—fino a quando query nascoste o comportamenti impliciti diventano difficili da capire.
Migrazioni: mantenere codice e schema sincronizzati
Le migrazioni sono script di cambiamento versione per il tuo schema: aggiungi una colonna, crea un indice, esegui un backfill. L'obiettivo è semplice: chiunque può deployare l'app e ottenere la stessa struttura del database. Tratta le migrazioni come codice da revisionare, testare e, quando serve, ripristinare.
Quando le astrazioni “facili” fanno male
Gli ORM possono generare silenziosamente N+1 queries, recuperare righe enormi che non ti servono o rendere i join goffi. I query builder possono diventare catene illeggibili. SQL grezzo può essere duplicato e incoerente.
Una buona regola: usa lo strumento più semplice che mantenga l'intento evidente—e per i percorsi critici, ispeziona la SQL effettivamente eseguita.
Le prestazioni sono una proprietà del sistema, non del database
Testa le modifiche senza paura
Sperimenta con i cambi di schema e le feature, quindi ripristina in sicurezza quando qualcosa non va.
Spesso si dà la colpa al “database” quando una pagina è lenta. Ma la maggior parte della latenza visibile all'utente è la somma di molte piccole attese lungo tutto il percorso della richiesta.
Da dove arriva davvero la latenza
Una singola richiesta tipicamente paga per:
- Tempo di rete (client → load balancer → app → database e ritorno)
- Tempo di query (SQL lento, indici mancanti, troppi round trip)
- Serializzazione/deserializzazione (encoding JSON, mapping ORM, compressione)
- Logica app (validazione, permessi, rendering, chiamate ad API esterne)
Anche se il database risponde in 5 ms, un'app che esegue 20 query per richiesta, blocca su I/O e impiega 30 ms a serializzare una risposta enorme risulterà comunque lenta.
Connection pooling: il moltiplicatore silenzioso delle prestazioni
Aprire una nuova connessione al database è costoso e può sovraccaricare il DB sotto carico. Un connection pool riusa connessioni esistenti così le richieste non pagano ripetutamente quel costo.
Il problema: la dimensione “giusta” del pool dipende dal modello di runtime. Un server async altamente concorrente può richiedere molte connessioni simultanee; senza limiti del pool vedrai code, timeout e fallimenti rumorosi. Con pool troppo piccoli, l'app diventa il collo di bottiglia.
Caching: cosa risolve—e cosa no
Il caching può stare nel browser, in un CDN, in cache in-process o in una cache condivisa (come Redis). Aiuta quando molte richieste hanno gli stessi risultati.
Ma il caching non risolve:
- Percorsi di scrittura inefficienti
- Risposte altamente personalizzate
- Endpoint lenti dominati da chiamate a API esterne
Il runtime conta: thread vs async
Il runtime del linguaggio influisce sulla throughput. I modelli thread-per-request possono sprecare risorse mentre aspettano I/O; i modelli async aumentano la concorrenza, ma rendono essenziale il backpressure (come i limiti del pool). Per questo il tuning delle prestazioni è una decisione di stack, non solo del database.
Sicurezza e affidabilità: responsabilità condivisa nello stack
La sicurezza non è qualcosa che “aggiungi” con un plugin del framework o una impostazione del database. È l'accordo tra linguaggio/runtime, framework web e database su cosa deve essere sempre vero—even quando un sviluppatore sbaglia o si aggiunge un endpoint.
Autenticazione vs autorizzazione: livelli diversi, stesso risultato
L'autenticazione (chi è?) di solito vive al bordo del framework: sessioni, JWT, callback OAuth, middleware. L'autorizzazione (cosa può fare?) deve essere applicata in modo coerente sia nella logica dell'app che nelle regole dati.
Un pattern comune: l'app decide l'intento (“l'utente può modificare questo progetto”), e il database applica confini (tenant ID, vincoli di proprietà e—dove ha senso—policy a livello di riga). Se l'autorizzazione esiste solo nei controller, job in background e script interni possono aggirarla accidentalmente.
Validazione: framework, database o entrambi?
La validazione nel framework dà feedback veloce e messaggi chiari. I vincoli del database forniscono una rete di sicurezza finale.
Usa entrambi quando conta:
- Framework: campi richiesti, formattazione, messaggi amichevoli.
- Database: unicità, chiavi esterne,
CHECK, NOT NULL.
Questo riduce gli “stati impossibili” che altrimenti emergono quando due richieste gareggiano o un nuovo servizio scrive dati in modo diverso.
Segreti, cifratura e auditing
I segreti dovrebbero essere gestiti dal runtime e dal workflow di deployment (env vars, secret manager), non hardcoded nel codice o nelle migrazioni. La cifratura può avvenire nell'app (cifratura a livello di campo) e/o nel database (encryption at-rest, KMS gestiti), ma serve chiarezza su chi ruota le chiavi e come funzionano i recovery.
L'auditing è condiviso: l'app deve emettere eventi significativi; il database deve conservare log immutabili dove appropriato (es. tabelle di audit append-only, accesso ristretto).
Modalità di fallimento tipiche
L'eccessiva fiducia nella logica dell'app è il classico problema: vincoli mancanti, null silenziosi, flag “admin” memorizzati senza verifiche. La soluzione è semplice: parti dall'assunto che i bug accadranno e progetta lo stack in modo che il database rifiuti scritture non sicure—anche dal tuo stesso codice.
Vie di scalabilità: cosa ogni scelta abilita o blocca
Costruisci una slice verticale
Descrivi il flusso di lavoro e il modello dei dati in chat e ottieni una UI, un'API e un database di base.
La scalabilità raramente fallisce perché “il database non ce la fa”. Fallisce perché l'intero stack reagisce male quando il carico cambia forma: un endpoint diventa popolare, una query diventa hot, un workflow comincia a ritentare.
Quando il traffico cresce, il dolore appare in punti specifici
La maggior parte dei team incontra gli stessi colli di bottiglia iniziali:
- Query hot: una query di “pagina principale” o dashboard viene eseguita costantemente e domina CPU/IO.
- Contesa sui lock: aggiornamenti si accumulano dietro poche righe (contatori inventario, “last_seen”, tabelle di coda), rallentando tutto.
- Pressione sulle connessioni: worker dell'app aprono troppe connessioni DB; il database spende tempo a gestire sessioni invece che lavorare.
La capacità di reagire rapidamente dipende da quanto bene framework e tooling del database espongono piani di query, migrazioni, pooling e pattern di caching sicuri.
Read replica, sharding e code: quando compaiono
Le mosse comuni di scaling tendono ad arrivare in ordine:
- Read replica quando le letture superano le scritture e puoi tollerare dati leggermente obsoleti. Il tuo ORM/framework deve supportare split lettura/scrittura (o rendere facile instradare le query).
- Code/job in background quando il fare “subito” danneggia la latenza delle richieste (email, esportazioni, chiamate di billing). Qui entrano in gioco retry e deduplica.
- Sharding/partitioning quando un singolo primario non regge il throughput di scrittura o la crescita dello storage. Questo richiede modellazione attenta: chiavi di shard, query cross-shard e confini delle transazioni.
Il lavoro in background e l'idempotenza sono funzionalità del framework, non dettagli secondari
Uno stack scalabile necessita supporto di primo livello per task in background, scheduling e retry sicuri.
Se il tuo sistema di job non può imporre idempotenza (lo stesso job esegue due volte senza doppio addebito o doppio invio), “scalerai” verso corruzione dei dati. Scelte iniziali—come affidarsi a transazioni implicite, vincoli di unicità deboli o comportamenti ORM opachi—possono bloccare l'introduzione pulita di code, pattern outbox o workflow quasi-exactly-once in seguito.
L'allineamento precoce paga: scegli un database che corrisponda ai tuoi bisogni di coerenza e un ecosistema di framework che renda il prossimo passo di scaling (repliche, code, partizionamento) un percorso supportato piuttosto che un rewrite.
Esperienza sviluppatore e operazioni: un unico workflow
Uno stack sembra “semplice” quando sviluppo e operazioni condividono le stesse assunzioni: come avvii l'app, come cambiano i dati, come girano i test e come capisci cosa è successo quando qualcosa si rompe. Se quei pezzi non si allineano, i team perdono tempo su glue code, script fragili e runbook manuali.
Velocità nello sviluppo locale
Un setup locale veloce è una caratteristica. Preferisci un flusso dove un nuovo collega può clonare, installare, eseguire le migrazioni e avere dati di test realistici in minuti—non ore.
Questo di solito significa:
- Un comando per avviare app e dipendenze (spesso via container).
- Migrazioni che girano affidabili su ogni macchina.
- Seed data che corrispondono alla forma di produzione (non solo righe "hello world").
Se lo strumento di migrazione del tuo framework combatte la tua scelta di DB, ogni cambiamento di schema diventa un piccolo progetto.
Piramide dei test che rispecchia il tuo stack
Il tuo stack dovrebbe rendere naturale scrivere:
- Unit test che non richiedono il database.
- Integration test che colpiscono lo schema e le query reali.
- End-to-end test che esercitano l'intero percorso della richiesta.
Un fallimento comune: i team si affidano ai soli unit test perché gli integration test sono lenti o difficili da mettere in piedi. Spesso è un disallineamento stack/ops—il provisioning del DB di test, le migrazioni e i fixture non sono snelli.
Osservabilità attraverso app e database
Quando la latenza sale, serve seguire una singola richiesta attraverso il framework fino al database.
Cerca log strutturati coerenti, metriche di base (tasso richieste, errori, tempo DB) e trace che includano timing delle query. Anche un semplice correlation ID che compare nei log app e nei log DB può trasformare il “indovinare” in “trovare”.
Fit operativo: cambi sicuri e recovery
Operazioni non è separata dallo sviluppo; è la sua continuazione.
Scegli tool che supportano:
- Backup e restore testati (non solo configurati).
- Cambi di schema che possano avanzare in sicurezza (e occasionalmente tornare indietro).
- Una strada chiara per “cosa succede durante il deploy” così i rilasci non dipendono dalla knowledge tribale.
Se non sai provare un restore o una migrazione localmente, non lo farai bene sotto pressione.
Checklist pratica per scegliere uno stack coerente
Scegliere uno stack non è scegliere gli “strumenti migliori” ma strumenti che lavorino bene insieme sotto i tuoi vincoli reali. Usa questa checklist per forzare l'allineamento fin da subito.
1) Checklist rapida (fit prima delle feature)
- Competenze del team: Cosa il tuo team può consegnare e mantenere con fiducia per 12–24 mesi?
- Forma del dominio: workflow e record, regole complesse o reporting intenso?
- Bisogni sui dati: integrità relazionale, documenti flessibili, time-series, ricerca full-text, analytics?
- Vincoli: compliance, obiettivi di latenza, modello di deployment, budget, infrastruttura esistente.
- Tolleranza al fallimento: puoi accettare coerenza eventuale o hai bisogno di transazioni rigorose?
2) Mappa il prodotto a pattern comuni
- App CRUD-heavy (internal tools, back office, early SaaS): un framework convenzionale + DB relazionale è spesso il percorso più veloce perché migrazioni, transazioni e workflow admin sono semplici.
- Analytics-heavy (dashboard, event tracking): pianifica presto uno store OLAP o un data warehouse; cercare di “fare di Postgres un sistema BI” può rallentare query e lavoro prodotto.
- Real-time (chat, collaboration, streaming): prioritizza supporto WebSocket, pub/sub e concorrenza prevedibile. La scelta del linguaggio/runtime influisce su quanto sarà doloroso.
- SaaS multi-tenant: decidi da subito: DB separati, schemi separati o tenancy a livello di riga. Questa scelta si propaga in auth, migrazioni e operazioni di supporto.
3) Esegui un piccolo proof of concept (senza overbuilding)
Limita a 2–5 giorni. Costruisci una thin vertical slice: un workflow core, un job in background, una query tipo report e auth di base. Misura attrito per gli sviluppatori, ergonomia delle migrazioni, chiarezza delle query e facilità di test.
Se vuoi accelerare, uno strumento come Koder.ai può essere utile per generare rapidamente una vertical slice funzionante (UI, API e database) da una specifica guidata in chat—poi iterare con snapshot/rollback ed esportare il codice sorgente quando sei pronto a impegnarti.
4) Scrivi un decision record di una pagina
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
Mismatches comuni (e come evitarli)
Rendilo facile da revisionare
Condividi una vera app con il tuo team e gli stakeholder usando un dominio personalizzato.
Anche team validi finiscono con mismatch di stack—scelte che sembrano ok in isolamento ma creano attriti quando il sistema è in produzione. La buona notizia: la maggior parte è prevedibile e la si può evitare con qualche controllo.
Odori a cui fare attenzione
Un odore classico è scegliere un DB o framework perché è di moda mentre il modello dati è ancora vago. Un altro è fare scaling prematuro: ottimizzare per milioni di utenti prima di saper gestire centinaia, che spesso porta a infrastrutture extra e più modalità di failure.
Attenzione anche a stack dove il team non sa spiegare perché ogni pezzo esiste. Se la risposta è “perché lo usa tutti”, stai accumulando rischio.
Rischi di integrazione che mordono più avanti
Molti problemi appaiono alle giunture:
- Driver e feature non allineati: il driver del tuo linguaggio non supporta le feature del database che presumevi (tipi, streaming, retry).
- Migrazioni deboli: i cambi di schema sono gestiti manualmente, o gli strumenti di migrazione non corrispondono all'evoluzione dell'app, causando drift tra ambienti.
- Pooling di connessioni povero: framework che aprono troppe connessioni, o deployment che moltiplicano i pool attraverso processi/container, portando a timeout sotto carico.
Questi non sono “problemi del DB” o “problemi del framework”—sono problemi di sistema.
Come semplificare (e de-risk)
Preferisci meno parti mobili e un percorso chiaro per i compiti comuni: un approccio alle migrazioni, uno stile di query per la maggior parte delle feature e convenzioni coerenti tra servizi. Se il framework incoraggia un pattern (lifecycle della request, dependency injection, pipeline dei job), sfruttalo invece di mescolare stili.
Quando rivedere le decisioni—e cambiare in sicurezza
Rivedi le scelte quando vedi incidenti ricorrenti in produzione, attrito persistente per gli sviluppatori o quando nuovi requisiti prodotto cambiano radicalmente i pattern di accesso ai dati.
Cambia in sicurezza isolando la giunzione: introduce un layer adapter, migra incrementally (dual-write o backfill se serve) e prova la parità con test automatici prima di commutare il traffico.
Conclusione: tratta lo stack come un unico sistema
Scegliere linguaggio, framework e database non sono tre decisioni indipendenti—è una decisione di design di sistema espressa in tre posti. L'opzione “migliore” è la combinazione che si allinea con la forma dei dati, i bisogni di coerenza, il flusso di lavoro del team e come prevedi che il prodotto cresca.
Cosa portare a casa
- Costruisci lo stack attorno al tuo modello dati core e alle operazioni che esegui più spesso.
- Coerenza e transazioni sono preoccupazioni applicative: progetta end-to-end, non solo sul database.
- I colli di bottiglia di performance di solito attraversano confini (schema, query, caching, serializzazione, queue).
- Sicurezza e affidabilità sono responsabilità condivise tra codice, configurazione e operazioni.
- L'esperienza sviluppatore conta perché determina quanto velocemente puoi rilasciare in sicurezza.
Documenta le assunzioni (prima che diventino vincoli)
Annota le ragioni dietro le scelte: pattern di traffico previsti, latenza accettabile, regole di retention, modalità di fallimento tollerabili e cosa non stai ottimizzando ora. Questo rende visibili i compromessi, aiuta i futuri colleghi a capire il “perché” e previene la deriva architetturale quando i requisiti cambiano.
Prossimi passi
Passa il tuo setup attuale attraverso la checklist e segnala dove le decisioni non si allineano (per esempio, uno schema che combatte l'ORM o un framework che rende il lavoro in background scomodo).
Se esplori una nuova direzione, strumenti come Koder.ai possono aiutarti a confrontare rapidamente le ipotesi di stack generando una app di base (comunemente React sul web, Go services con PostgreSQL e Flutter per mobile) che puoi ispezionare, esportare ed evolvere—senza impegnarti in un lungo ciclo di sviluppo upfront.
Per approfondire, sfoglia le guide correlate su /blog, cerca dettagli di implementazione in /docs o confronta opzioni di supporto e deployment su /pricing.