Perché la cache aiuta — e perché complica i sistemi
La cache mantiene una copia dei dati vicina a dove servono, così le richieste possono essere soddisfatte più velocemente con meno viaggi verso i sistemi centrali. Il vantaggio è di solito una combinazione di velocità (latenza ridotta), costo (meno letture costose al database o chiamate upstream) e stabilità (i servizi di origine resistono ai picchi di traffico).
Il lato positivo: meno lavoro per l'origin
Quando una cache risponde a una richiesta, il tuo “origin” (server applicativi, database, API di terze parti) fa meno lavoro. La riduzione può essere drastica: meno query, meno cicli CPU, meno hop di rete e meno opportunità di timeout.
La cache aiuta anche a livellare i burst, permettendo a sistemi dimensionati per carico medio di gestire i momenti di picco senza scalare immediatamente (o cadere).
Il compromesso nascosto: più lavoro per gli ingegneri
La cache non elimina il lavoro; lo sposta nella progettazione e nelle operazioni. Ecco le domande che erediti:
- Cosa dovrebbe essere cachato?
- Per quanto tempo?
- Cosa succede quando i dati cambiano?
- Come prevenire risultati obsoleti o errati?
- Come debuggare problemi quando una cache “nasconde” il comportamento dell'origin?
Ogni livello di cache aggiunge configurazione, monitoraggio e casi limite. Una cache che velocizza il 99% delle richieste può comunque causare incidenti dolorosi nell'1%: scadenze sincronizzate, esperienze utente incoerenti o ondate improvvise verso l'origin.
Livello di cache vs. singola cache
Una singola cache è uno store (per esempio una cache in memoria accanto all'app). Un livello di cache è un punto di controllo distinto nel percorso della richiesta—CDN, cache del browser, cache dell'app, cache del database—ognuno con regole e modalità di guasto proprie.
Questo post si concentra sulla complessità pratica introdotta da più livelli: correttezza, invalidazione e operazioni (non sugli algoritmi di cache a basso livello o sul tuning specifico di vendor).
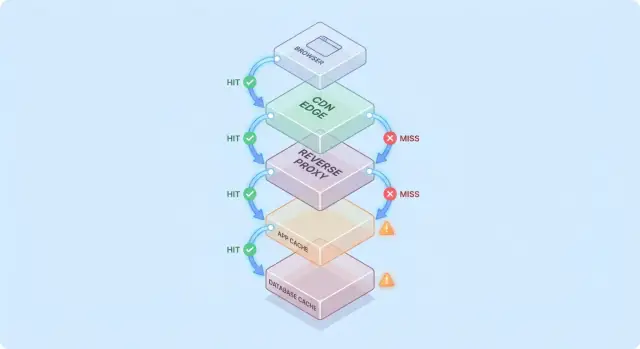
Un modello semplice: il flusso di una richiesta attraverso più layer
La cache è più semplice da capire se immagini una richiesta che attraversa una pila di checkpoint “forse ce l'ho già”.
Percorso tipico della richiesta
Un percorso comune è:
- Client → Edge (CDN) → App → Database
A ogni passaggio il sistema può restituire una risposta cached (hit) o inoltrare la richiesta allo step successivo (miss). Più presto avviene l'hit (ad esempio al edge), più carico eviti negli strati profondi.
Gli hit sono belli; le miss sono la vera prova
Gli hit rendono le dashboard soddisfacenti. Le miss sono dove appare la complessità: innescano lavoro reale (logica dell'app, query al DB) e aggiungono overhead (lookup in cache, serializzazione, scrittura nella cache).
Un modello mentale utile è: ogni miss paga la cache due volte—fai comunque il lavoro originale, più il lavoro di caching intorno ad esso.
Come i layer spostano i colli di bottiglia
Aggiungere un layer di cache raramente elimina i colli di bottiglia; spesso li sposta:
- Un CDN può spostare la pressione lontano dall'app, ma aumenta la sensibilità alla configurazione e alla velocità di purge.
- Una cache applicativa può ridurre il carico sul database, ma rende la CPU/memoria del livello app il nuovo fattore limitante.
- Il caching del database (buffer pool, plan cache) può nascondere query lente finché il working set non entra in memoria.
Esempio semplice “cached due volte”
Supponiamo che la pagina prodotto sia cacheata al CDN per 5 minuti e che l'app abbia anche i dettagli prodotto in Redis per 30 minuti.
Se cambia un prezzo, il CDN potrebbe aggiornarsi rapidamente mentre Redis continua a servire il vecchio prezzo. Ora la “verità” dipende da quale layer ha risposto—un esempio di come i livelli di cache tagliano il carico ma aumentano la complessità del sistema.
Livelli di cache comuni e a cosa servono
La cache non è una sola cosa: è una pila di posti dove i dati possono essere salvati e riutilizzati. Ogni layer può ridurre il carico, ma ognuno ha regole diverse per freschezza, invalidazione e visibilità.
Cache del browser e del sistema operativo (ciò che controlli vs ciò che non controlli)
I browser cacheano immagini, script, CSS e talvolta risposte API basandosi su header HTTP (come Cache-Control ed ETag). Questo può eliminare download ripetuti—ottimo per le performance e per ridurre il traffico verso CDN/origin.
Il problema: una volta che una risposta è nella cache client-side non controlli completamente i tempi di revalidazione. Alcuni utenti possono tenere asset più vecchi a lungo (o cancellare la cache inaspettatamente), quindi gli URL versionati (es. app.3f2c.js) sono una rete di sicurezza comune.
Caching CDN/edge per contenuti statici e semi-statici
Un CDN conserva contenuti vicino agli utenti. È eccellente per file statici, pagine pubbliche e risposte “per lo più stabili” come immagini prodotto, documentazione o endpoint API a bassa variabilità.
I CDN possono anche cacheare HTML semi-statico se si presta attenzione alle variazioni (cookie, header, geo, device). Regole di variazione mal configurate sono una fonte frequente di contenuti sbagliati serviti all'utente sbagliato.
Reverse proxy caching (livello gateway)
I reverse proxy (come NGINX o Varnish) si pongono davanti all'applicazione e possono cacheare intere risposte. Questo è utile quando vuoi controllo centralizzato, eviction prevedibile e protezione rapida per gli origin durante picchi di traffico.
In genere sono meno distribuiti globalmente rispetto a un CDN, ma più facili da adattare alle rotte e agli header dell'app.
Cache a livello applicazione (in-memory, Redis, Memcached)
Questa cache mira a oggetti, risultati computati e chiamate costose (es. “profilo utente per id” o “regole di prezzo per regione”). È flessibile e può conoscere la logica di business.
Introduce però più decisioni: design delle chiavi, scelte di TTL, logica di invalidazione e necessità operative come dimensionamento e failover.
Caching del database e caching di query/risultati
La maggior parte dei database fa caching di pagine, indici e piani di esecuzione automaticamente; alcuni supportano caching dei risultati. Questo può velocizzare query ripetute senza cambiare il codice applicativo.
Va visto come un bonus, non una garanzia: le cache dei database sono spesso le meno prevedibili con pattern di query diversi, e non eliminano il costo delle scritture, dei lock o della contesa come possono fare le cache a monte.
Dove la cache riduce di più il carico
La cache paga quando trasforma operazioni backend ripetute e costose in una lookup economica. La sfida è abbinare la cache a workload dove le richieste sono abbastanza simili—e abbastanza stabili—perché il riuso sia alto.
Workload read-heavy e computazioni costose
Se il sistema serve molte più letture che scritture, la cache può rimuovere una grande fetta di lavoro su DB e app. Pagine prodotto, profili pubblici, articoli di help center e risultati di ricerca spesso vengono richiesti ripetutamente con gli stessi parametri.
La cache aiuta anche con lavori “costosi” che non sono strettamente legati al database: generare PDF, ridimensionare immagini, renderizzare template o calcolare aggregati. Anche una cache di breve durata (secondi o minuti) può collassare computazioni ripetute durante i periodi di traffico intenso.
Traffico a picchi e protezione dai burst
La cache è particolarmente efficace quando il traffico è irregolare. Se una email di marketing, una menzione sui media o un post social manda una raffica di utenti agli stessi URL, un CDN o una cache edge può assorbire la maggior parte dell'ondata.
Questo riduce il carico oltre la sola “maggiore velocità”: può prevenire autoscaling eccessivo, evitare l'esaurimento delle connessioni al database e comprare tempo perché rate limit e backpressure funzionino.
Backend ad alta latenza e utenti cross-region
Se il backend è lontano dagli utenti—letteralmente (cross-region) o logicamente (dipendenza lenta)—la cache può ridurre carico e latenza percepita. Servire contenuti da un CDN vicino all'utente evita ripetuti viaggi lunga distanza verso l'origin.
La cache interna aiuta anche quando il collo di bottiglia è uno store ad alta latenza (database remoto, API di terze parti, servizio condiviso). Ridurre il numero di chiamate diminuisce la pressione sulla concorrenza e migliora la latenza di coda.
Quando la cache ha poco senso
La cache dà meno benefici quando le risposte sono altamente personalizzate (dati per utente, dettagli sensibili) o quando i dati sottostanti cambiano costantemente (dashboard live, inventari in rapido aggiornamento). In questi casi il tasso di hit è basso, i costi di invalidazione salgono e il risparmio di lavoro backend può essere marginale.
Una regola pratica: la cache è più utile quando molti utenti chiedono la stessa cosa entro una finestra di tempo in cui “la stessa cosa” rimane valida. Se questa sovrapposizione non esiste, un altro livello di cache può aggiungere complessità senza ridurre molto il carico.
Invalidazione della cache: la principale fonte di complessità
La cache è semplice quando i dati non cambiano. Quando cambiano, erediti la parte più difficile: decidere quando i dati cached non sono più affidabili e come ogni livello di cache apprende la modifica.
Scadenza TTL: semplice, ma raramente “giusta”
Time-to-live (TTL) è attraente perché è un numero e non richiede coordinazione. Il problema è che il TTL “corretto” dipende dall'uso dei dati.
Se imposti un TTL di 5 minuti su un prezzo prodotto, alcuni utenti vedranno il prezzo vecchio dopo la modifica—con possibili problemi legali o di supporto. Se lo imposti a 5 secondi, potresti non ridurre molto il carico. Peggio ancora, campi diversi nella stessa risposta cambiano a ritmi diversi (inventario vs descrizione), quindi un unico TTL impone un compromesso.
Invalidazione guidata da eventi: accurata, ma pesante da coordinare
L'invalidazione guidata da eventi dice: quando la sorgente di verità cambia, pubblica un evento e purga/aggiorna tutte le chiavi di cache interessate. Può essere molto corretta, ma crea nuovo lavoro:
- Ogni percorso di scrittura deve emettere eventi in modo affidabile.
- Ogni layer di cache deve sottoscriversi, retryare, deduplicare e gestire consegne fuori ordine.
- Serve una mappatura chiara da “cosa è cambiato” a “quali chiavi invalidare”.
Quella mappatura è dove "le due cose difficili: naming e invalidation" diventa concretamente problematica. Se cachate /users/123 e anche una lista “top contributors”, un cambio di username impatta più di una chiave. Se non tracci le relazioni, servirai una realtà mista.
Pattern: cache-aside vs write-through vs write-back
Cache-aside (l'app legge/scrive il DB e popola la cache) è comune, ma l'invalidazione è responsabilità tua.
Write-through (scrivi cache e DB insieme) riduce il rischio di staleness, ma aggiunge latenza e complessità nel gestire i fallimenti.
Write-back (scrivi prima nella cache e poi flush successivo) aumenta la velocità, ma rende correttezza e recovery molto più difficili.
Stale-while-revalidate: “abbastanza buono” di proposito
Stale-while-revalidate serve dati leggermente obsoleti mentre li aggiorna in background. Livella i picchi e protegge l'origin, ma è anche una decisione di prodotto: stai scegliendo esplicitamente “veloce e per lo più recente” rispetto a “sempre l'ultimo”.
Tradeoff di coerenza e correttezza visibile all'utente
Recreate the request path
Spin up a React plus Go plus Postgres stack from chat to reproduce your cache issue.
La cache cambia cosa significa “corretto”. Senza cache, gli utenti vedono per lo più l'ultimo dato committato (salvo comportamento normale del database). Con le cache, gli utenti possono vedere dati un po' indietro—o incoerenti tra schermate—talvolta senza un errore evidente.
Coerenza forte vs eventuale (e ciò che gli utenti notano)
La coerenza forte mira al “read-after-write”: se un utente aggiorna il proprio indirizzo, il caricamento successivo dovrebbe mostrare il nuovo indirizzo ovunque. Questo è intuitivo, ma può essere costoso se ogni scrittura deve pulire o aggiornare immediatamente più cache.
La coerenza eventuale permette breve staleness: l'aggiornamento apparirà a breve, ma non istantaneamente. Gli utenti accettano questo comportamento per contenuti a basso rischio (conteggi visualizzazioni), ma non per soldi, permessi o qualsiasi cosa che influisca sulle azioni successive.
Race condition tra scritture e refresh della cache
Un errore comune è una scrittura che avviene nello stesso momento in cui la cache viene ripopolata:
- L'utente aggiorna un profilo.
- La cache viene invalidata.
- Un'altra richiesta ripopola la cache da una replica che non ha ancora ricevuto l'aggiornamento.
Ora la cache contiene dati vecchi per l'intero TTL, anche se il database è corretto.
Incoerenza multi-layer: edge dice A, app dice B
Con più livelli, parti diverse del sistema possono non concordare:
- Il CDN restituisce una pagina HTML vecchia (“Indirizzo: Via Vecchia”).
- La cache dell'app restituisce JSON più nuovo (“Indirizzo: Via Nuova”).
- L'interfaccia mostra un mix e l'utente interpreta il sistema come “rotto”, non come “eventualmente consistente”.
Il versioning riduce l'ambiguità:
- ETags permettono a client/CDN di revalidare efficientemente e evitare di servire contenuti obsoleti quando la rappresentazione cambia.
- Chiavi di cache versionate (es.
user:123:v7) permettono di avanzare in sicurezza: una scrittura incrementa la versione e le letture passano naturalmente alla nuova chiave senza cancellazioni perfettamente sincronizzate.
Definire la staleness accettabile per feature
La decisione chiave non è “i dati stale sono male?” ma dove lo sono. Imposta budget di staleness espliciti per feature (secondi/minuti/ore) e allineali alle aspettative dell'utente. I risultati di ricerca possono avere un ritardo di un minuto; saldi di conto e controllo accessi no. Questo trasforma la “correttezza della cache” in un requisito di prodotto che puoi testare e monitorare.
Modalità di guasto: stampede, hot key e outage della cache
La cache spesso fallisce in modi che sembrano “tutto andava bene, poi tutto si è rotto insieme”. Questi guasti non significano che la cache sia cattiva—significano che le cache concentrano i pattern di traffico, quindi piccoli cambi possono scatenare effetti grandi.
Dopo un deploy, un autoscale o un flush della cache, potresti trovarti con una cache per lo più vuota. La successiva ondata di traffico costringe molte richieste a colpire direttamente il database o le API upstream.
Questo è particolarmente doloroso quando il traffico sale rapidamente, perché la cache non ha avuto tempo per scaldarsi con gli item popolari. Se i deploy coincidono con i picchi, puoi creare involontariamente il tuo load test.
Cache stampedes (thundering herd)
Uno stampede avviene quando molti utenti richiedono lo stesso item proprio quando scade (o non è ancora in cache). Invece di una singola richiesta che ricalcola il valore, centinaia o migliaia lo fanno—sovraccaricando l'origin.
Mitigazioni comuni includono:
- Request coalescing: lascia che la prima richiesta ricalcoli mentre le altre aspettano il risultato.
- Lock / single-flight: garantire “solo un builder” per chiave di cache.
- TTL con jitter: randomizzare le scadenze così le chiavi non scadono tutte insieme.
Se i requisiti di correttezza lo permettono, stale-while-revalidate può anche livellare i picchi.
Alcune chiavi diventano sproporzionatamente popolari (payload della homepage, prodotto di tendenza, configurazione globale). Le hot key creano carico non uniforme: un nodo di cache o un percorso backend viene martellato mentre gli altri restano inattivi.
Mitigazioni: dividere grandi chiavi “globali” in chiavi più piccole, aggiungere sharding/partitioning o cahare a un layer diverso (ad esempio spostare contenuti veramente pubblici più vicini agli utenti tramite CDN).
Quando la cache è giù: scegli il fallback
Gli outage della cache possono essere peggiori dell'assenza di cache, perché le app possono dipendere da essa. Decidi in anticipo:
- Fail open (bypass della cache, hit origin): migliore disponibilità, rischio di carico più alto.
- Fail closed (ritorna errori): protegge l'origin, peggiore esperienza utente.
- Degrade gracefully (servire stale/default): spesso il compromesso migliore.
Qualunque sia la scelta, rate limit e circuit breaker aiutano a prevenire che un guasto della cache diventi un outage dell'origin.
Overhead operativo: più componenti da gestire
Run a caching ROI trial
Build a small trial around your top endpoint and compare latency and origin load.
La cache può ridurre il carico sugli origin, ma aumenta il numero di servizi che operi quotidianamente. Anche le cache “gestite” richiedono pianificazione, tuning e risposta agli incidenti.
Più componenti da gestire
Un nuovo layer di cache spesso significa un nuovo cluster (o almeno un nuovo tier) con limiti di capacità propri. I team devono decidere dimensionamento memoria, policy di eviction e cosa succede sotto pressione. Se la cache è sottodimensionata, churn: il tasso di hit cala, la latenza sale e l'origin viene comunque martellato.
Deriva di configurazione tra i layer
La cache raramente vive in un solo posto. Potresti avere un CDN, una cache applicativa e caching nel database—ognuno interpreta le regole diversamente.
Piccole incongruenze si sommano:
- Il CDN rispetta gli header, la cache app usa TTL hard-coded.
- Un layer bypassa su cookie mentre un altro no.
- Le regole di purge esistono in un posto ma non in un altro.
Col tempo, “perché questa richiesta è in cache?” diventa un progetto di archeologia.
Compiti operativi nuovi
Le cache creano lavoro ricorrente: scaldare chiavi critiche dopo i deploy, purgare o revalidare quando cambiano dati, resharding quando si aggiungono/rimuovono nodi e provare cosa succede dopo un flush completo.
Complessità on-call durante gli incidenti
Quando gli utenti segnalano dati stale o lentezza improvvisa, i responder hanno ora molti sospetti: il CDN, il cluster di cache, il client della cache nell'app e l'origin. Il debug spesso significa controllare hit rate, spike di eviction e timeout attraverso i layer—poi decidere se bypassare, purgare o scalare.
Osservabilità: dimostrare che la cache aiuta davvero
La cache è vantaggiosa solo se riduce il lavoro backend e migliora la velocità percepita dall'utente. Poiché le richieste possono essere servite da più layer (edge/CDN, cache app, cache DB), serve osservabilità che risponda:
- Quale layer ha servito questa richiesta?
- Cosa è cambiato quando non l'ha fatto?
Metriche che spiegano davvero i risultati
Un alto hit ratio suona bene, ma può nascondere problemi (come letture lente dalla cache o churn costante). Monitora un piccolo set di metriche per layer:
- Hit ratio e miss ratio, suddivise per endpoint o namespace
- Latenza per layer (tempo di lettura cache vs tempo dell'origin), idealmente p50/p95/p99
- Tasso di eviction e età degli item (quanto sopravvivono prima di essere rimossi)
- Indicatori di carico sull'origin (DB QPS, CPU, saturazione pool connessioni) correlati con gli hit della cache
Se il hit ratio sale ma la latenza totale non migliora, la cache potrebbe essere lenta, troppo serializzata o restituire payload troppo grandi.
Tracing attraverso i layer
Il tracing distribuito dovrebbe mostrare se una richiesta è stata servita al edge, dalla cache app o dal database. Aggiungi tag coerenti come cache.layer=cdn|app|db e cache.result=hit|miss|stale così puoi filtrare le trace e confrontare i tempi dei percorsi hit vs miss.
Log e alert senza esporre dati
Logga le chiavi di cache con attenzione: evita identificatori utente grezzi, email, token o URL completi con query string. Preferisci chiavi normalizzate o hashed e logga solo un prefisso breve.
Allerta su picchi anomali di miss-rate, salti improvvisi di latenza sui miss e segnali di stampede (molte miss concorrenti per lo stesso pattern di chiave). Separa le dashboard in viste per edge, app e database, più un pannello end-to-end che le leghi insieme.
Rischi di sicurezza e privacy nelle risposte cacheate
La cache è ottima per ripetere risposte velocemente—ma può anche ripetere la risposta sbagliata alla persona sbagliata. Gli incidenti legati al caching sono spesso silenziosi: tutto sembra veloce e sano mentre i dati vengono esposti.
Come i dati sensibili finiscono nelle cache
Un errore comune è cachare contenuti personalizzati o confidenziali (dettagli account, fatture, ticket di supporto, pagine admin). Questo può accadere a qualunque layer—CDN, reverse proxy o cache applicativa—specialmente con regole “cache everything” troppo larghe.
Un leak sottile: cachare risposte che includono stato di sessione (es. header Set-Cookie) e servire quella risposta cached ad altri utenti.
Errori di autorizzazione: richiesta corretta, visualizzatore sbagliato
Un bug classico è cachare l'HTML/JSON per l'Utente A e poi servirlo all'Utente B perché la chiave di cache non includeva il contesto utente. Nei sistemi multi-tenant, l'identità del tenant deve far parte della chiave.
Regola pratica: se la risposta dipende da autenticazione, ruoli, geolocalizzazione, tier di prezzo o feature flag, la chiave di cache (o la logica di bypass) deve riflettere quella dipendenza.
Il comportamento di caching HTTP è guidato dagli header:
Cache-Control: impedire memorizzazioni accidentali con private / no-store quando necessarioVary: assicurare che le cache separino le risposte per header rilevanti (es. Authorization, Accept-Language)Set-Cookie: spesso è un segnale che la risposta non dovrebbe essere cacheata pubblicamente
Quando evitare la cache del tutto
Se il rischio o la compliance è alto—PII, dati sanitari/finanziari, documenti legali—preferisci Cache-Control: no-store e ottimizza lato server. Per pagine miste, cachea solo frammenti non sensibili o asset statici e tieni i dati personalizzati fuori dalle cache condivise.
Costi e ROI: decidere se aggiungere un altro layer conviene
Keep full code control
Generate the app, then export source code to integrate your preferred cache and observability.
I livelli di cache possono ridurre il carico sull'origin, ma raramente sono “performance gratuite”. Tratta ogni nuova cache come un investimento: acquisti latenza minore e meno lavoro backend in cambio di denaro, tempo ingegneristico e una superficie di correttezza più ampia.
Cosa paghi vs cosa risparmi
Costo infrastruttura extra vs risparmio sull'origin. Un CDN può ridurre egress e letture DB, ma costa per richieste CDN, storage cache e talvolta chiamate di invalidazione. Una cache applicativa (Redis/Memcached) aggiunge costi di cluster, upgrade e on-call. I risparmi possono tradursi in meno repliche DB, istanze più piccole o scalare più lentamente.
Vantaggi di latenza vs costi di freschezza. Ogni cache introduce la domanda “quanto è accettabile essere obsoleti?”. Freschezza stretta richiede più plumbing di invalidazione (e più miss). La staleness tollerata risparmia computazione ma può costare fiducia degli utenti—soprattutto per prezzi, disponibilità o permessi.
Tempo ingegneristico: velocità di feature vs lavoro di affidabilità. Un nuovo layer significa spesso percorsi di codice in più, più testing e nuove classi di incidenti da prevenire (stampede, hot key, invalidazione parziale). Budget per la manutenzione continua, non solo per l'implementazione iniziale.
Esegui piccoli esperimenti per misurare il ROI
Prima di un rollout ampio, fai una prova limitata:
- Scegli un endpoint o una pagina con carico chiaro (es. top 5% del traffico).
- Definisci metriche di successo: latenza p95, DB QPS, error rate, hit ratio.
- Scala gradualmente; monitora i cambi di costo insieme alle performance.
- Limita la durata dell'esperimento e tieni uno switch di rollback.
Checklist decisionale semplice
Aggiungi un nuovo layer di cache solo se:
- Il collo di bottiglia è provato (non ipotizzato) tramite metriche.
- C'è un obiettivo chiaro (es. ridurre le letture DB del 40%).
- Le regole di staleness e invalidazione sono esplicitamente accettabili.
- Puoi monitorarlo (hit rate, eviction, latenza, errori).
- I risparmi previsti superano i costi operativi e ingegneristici su un orizzonte realistico.
Linee guida pratiche per ridurre la complessità della cache
La cache rende più rapidamente i benefici quando la tratti come una feature di prodotto: servono un owner, regole chiare e un modo sicuro per disattivarla.
Parti in piccolo, assegna responsabilità
Aggiungi un layer per volta (es. prima CDN o cache applicativa), e assegna un team o una persona responsabile.
Definisci chi possiede:
- le modifiche di configurazione (TTL, regole di bypass)
- capacità e comportamento di eviction
- risposta agli incidenti (cosa fare quando è sbagliata)
Rendi le chiavi di cache noiose e prevedibili
La maggior parte dei bug nelle cache sono bug di chiavi. Usa una convenzione documentata che includa gli input che cambiano la risposta: ambito tenant/user, locale, classe di device e feature flag rilevanti.
Aggiungi versioning esplicito delle chiavi (es. product:v3:...) così puoi invalidare in sicurezza bumpando una versione invece di tentare di cancellare milioni di voci.
Preferisci staleness limitata alla perfezione della freschezza
Cercare di mantenere tutto perfettamente aggiornato sposta la complessità in ogni percorso di scrittura.
Decidi invece cosa significa “accettabilmente stale” per endpoint (secondi, minuti o “fino al prossimo refresh”) e implementalo con:
- TTL che rispecchiano le aspettative di business
- refresh in background (servire leggermente stale mentre si aggiorna)
- invalidazione guidata da eventi solo per dati realmente sensibili
Costruisci default sicuri per i guasti
Assumi che la cache sarà lenta, sbagliata o giù.
Usa timeouts e circuit breaker così le chiamate alla cache non possano bloccare il percorso della richiesta. Definisci degradazione esplicita: se la cache fallisce, ricorri all'origin con rate limit o servi una risposta minima.
Rollout con controlli e runbook
Rilascia la cache dietro un canary o rollout percentuale e tieni uno switch di bypass (per rotta o header) per il troubleshooting veloce.
Documenta runbook: come purgare, come bumpare versioni di chiavi, come disabilitare temporaneamente la cache e dove controllare le metriche. Collega questi runbook nei manuali interni così l'on-call può agire rapidamente.
Prototipare cambi di caching senza rallentare il delivery
Il lavoro sulla cache spesso rallenta perché tocca più layer (header, logica app, modelli dati e piani di rollback). Un modo per ridurre il costo d'iterazione è prototipare l'intero percorso di richiesta in un ambiente controllato.
Con Koder.ai, i team possono rapidamente avviare uno stack app realistico (React sul web, backend Go con PostgreSQL e anche client mobile Flutter) tramite workflow chat-driven, poi testare decisioni di caching (TTL, design delle chiavi, stale-while-revalidate) end-to-end. Funzionalità come planning mode aiutano a documentare il comportamento atteso della cache prima dell'implementazione, e snapshots/rollback rendono più sicuro sperimentare configurazioni o logiche di invalidazione. Quando sei pronto, puoi exportare il codice sorgente o distribuire/hostare con domini personalizzati—utile per prove di performance che devono rispecchiare il traffico di produzione.
Se usi una piattaforma del genere, considerala complementare all'osservabilità di produzione: l'obiettivo è iterare più velocemente sul design della cache mantenendo espliciti i requisiti di correttezza e le procedure di rollback.