18 ago 2025·8 min
LLVM di Chris Lattner: il motore silenzioso dietro le toolchain moderne
Scopri come LLVM di Chris Lattner è diventato la piattaforma modulare del compilatore dietro linguaggi e strumenti—abilitando ottimizzazioni, diagnostiche migliori e build veloci.
Che cos'è LLVM, in parole semplici
LLVM si può pensare come la "sala macchine" che molti compilatori e strumenti per sviluppatori condividono.
Quando scrivi codice in un linguaggio come C, Swift o Rust, qualcosa deve tradurre quel codice in istruzioni che la CPU può eseguire. Un compilatore tradizionale spesso costruiva ogni parte di quella pipeline da solo. LLVM adotta un approccio diverso: fornisce un nucleo riutilizzabile e di alta qualità che gestisce le parti difficili e costose—ottimizzazione, analisi e generazione di codice macchina per molti tipi di processori.
Una base condivisa per molti linguaggi
LLVM non è quasi mai un singolo compilatore che "usi direttamente". È infrastruttura per compilatori: mattoni che i team dei linguaggi possono assemblare in una toolchain. Un team può concentrarsi su sintassi, semantica e funzionalità per gli sviluppatori, quindi affidare il lavoro pesante a LLVM.
Questa base condivisa è una grande ragione per cui i linguaggi moderni possono spedire toolchain veloci e sicure senza reinventare decenni di lavoro sui compilatori.
Perché conta anche se non sei un esperto di compilatori
LLVM influisce sull'esperienza quotidiana dello sviluppatore:
- Velocità: può trasformare codice ad alto livello in codice macchina efficiente su più piattaforme.
- Errori e debugging migliori: l'ecosistema attorno a LLVM permette diagnostica più ricca e strumenti migliori.
- Non solo "compilazione": analisi statica, sanitizzatori, coverage e altri aiuti per sviluppatori spesso si basano sulla stessa rappresentazione e librerie sottostanti.
Cosa sarà (e cosa non sarà) questo articolo
Questo è un tour guidato delle idee messe in moto da Chris Lattner: come è strutturato LLVM, perché lo strato intermedio conta e come abilita ottimizzazioni e supporto multipiattaforma. Non è un manuale accademico—ci concentreremo sull'intuizione e sull'impatto reale più che sulla teoria formale.
La visione originale di Chris Lattner
Chris Lattner è un informatico e ingegnere che, da studente laureato all'inizio degli anni 2000, iniziò LLVM partendo da una frustrazione pratica: la tecnologia dei compilatori era potente, ma difficile da riutilizzare. Se volevi un nuovo linguaggio, ottimizzazioni migliori o supporto per una nuova CPU, spesso dovevi smanettare con un compilatore "tutto in uno" strettamente accoppiato dove ogni modifica aveva effetti collaterali.
Il problema che voleva risolvere
All'epoca molti compilatori erano costruiti come grandi macchine monolitiche: la parte che capiva il linguaggio, la parte che ottimizzava e la parte che generava codice macchina erano profondamente intrecciate. Questo li rendeva efficaci per lo scopo originale, ma costosi da adattare.
L'obiettivo di Lattner non era "un compilatore per un solo linguaggio". Era una base condivisa che potesse alimentare molti linguaggi e molti strumenti—senza che tutti riscrivessero gli stessi pezzi complessi più e più volte. La scommessa era che, se riuscivi a standardizzare la parte centrale della pipeline, potevi innovare più velocemente ai bordi.
Perché l'"infrastruttura modulare" era una novità
La svolta chiave fu trattare la compilazione come un insieme di blocchi separabili con confini chiari. In un mondo modulare:
- un team linguistico può concentrarsi su parsing e funzionalità rivolte agli sviluppatori,
- un team di ottimizzazione può migliorare le prestazioni una volta e condividerle in modo ampio,
- il supporto hardware può essere aggiunto senza riprogettare tutto a monte.
Questa separazione ora sembra ovvia, ma allora andava contro l'evoluzione di molti compilatori di produzione.
Open source, pensato per essere usato da altri
LLVM fu rilasciato come open source fin da subito, e questo contò perché un'infrastruttura condivisa funziona solo se più gruppi possono fidarsi, ispezionarla ed estenderla. Nel tempo università, aziende e contributori indipendenti hanno modellato il progetto aggiungendo target, correggendo casi limite, migliorando le prestazioni e costruendo nuovi strumenti attorno ad esso.
Quell'aspetto comunitario non era solo buonismo—era parte del design: rendi il core ampiamente utile e diventa vantaggioso mantenerlo insieme.
L'idea grande: frontend, un core condiviso e backend
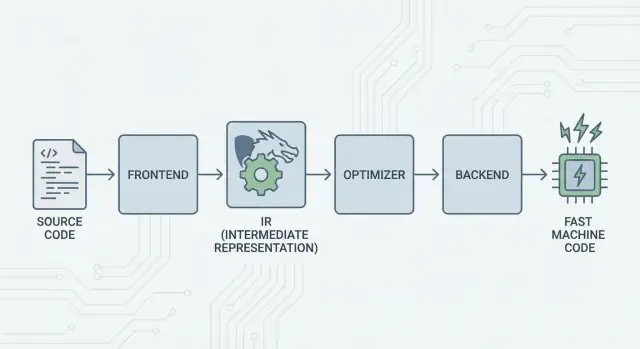
L'idea centrale di LLVM è semplice: dividere un compilatore in tre pezzi principali in modo che molti linguaggi possano condividere il lavoro più difficile.
1) Frontend: "Cosa intendeva il programmatore?"
Un frontend comprende un linguaggio di programmazione specifico. Legge il codice sorgente, verifica le regole (sintassi e tipi) e lo trasforma in una rappresentazione strutturata.
Il punto chiave: i frontend non devono conoscere ogni dettaglio della CPU. Il loro lavoro è tradurre i concetti del linguaggio—funzioni, cicli, variabili—in qualcosa di più universale.
2) Il centro condiviso: un solo core invece di N×M lavori
Tradizionalmente, costruire un compilatore significava ripetere lo stesso lavoro:
- Con N linguaggi e M target hardware, finisci con N×M combinazioni da supportare.
LLVM riduce questo a:
- N frontend che traducono in una forma condivisa
- M backend che traducono da quella forma condivisa a codice macchina
Quella "forma condivisa" è il centro di LLVM: una pipeline comune dove risiedono ottimizzazioni e analisi. Questo è il grande semplificatore. I miglioramenti nel centro (come ottimizzazioni migliori o informazioni di debug più precise) possono beneficiare molti linguaggi contemporaneamente, invece di essere reimplementati in ogni compilatore.
3) Backend: "Come facciamo a farlo girare velocemente su quella CPU?"
Un backend prende la rappresentazione condivisa e produce output specifico per la macchina: istruzioni per x86, ARM, e così via. Qui contano dettagli come registri, convenzioni di chiamata e selezione delle istruzioni.
Un'immagine intuitiva della pipeline
Pensa alla compilazione come a un percorso di viaggio:
- Codice sorgente comincia in un paese specifico del linguaggio (frontend).
- Attraversa un confine verso una "lingua intermedia" standardizzata (il core e le passate di LLVM).
- Poi prende un treno locale verso una città di destinazione specifica (backend per la macchina target).
Il risultato è una toolchain modulare: i linguaggi possono concentrarsi sull'esprimere idee chiaramente, mentre il core condiviso di LLVM si concentra sul far funzionare quelle idee in modo efficiente su molte piattaforme.
LLVM IR: lo strato intermedio che permette il riutilizzo
LLVM IR (Intermediate Representation) è la "lingua comune" che sta tra un linguaggio di programmazione e il codice macchina che la CPU esegue.
Un frontend di compilatore (come Clang per C/C++) traduce il tuo codice sorgente in questa forma condivisa. Poi gli ottimizzatori e i generatori di codice di LLVM lavorano sull'IR, non sul linguaggio originale. Infine, un backend trasforma l'IR in istruzioni per un target specifico (x86, ARM, e così via).
Una lingua comune tra strumenti e CPU
Pensa a LLVM IR come a un ponte ben progettato:
- Sopra di esso: molti linguaggi sorgente possono collegarsi (C, C++, Rust, Swift, Julia, ecc.).
- Sotto di esso: molte CPU possono essere targettizzate.
- Nel mezzo: gli stessi strumenti di analisi e ottimizzazione possono essere riutilizzati.
Per questo spesso si descrive LLVM come "infrastruttura per compilatori" piuttosto che come "un compilatore". L'IR è il contratto condiviso che rende quell'infrastruttura riutilizzabile.
Perché l'IR abilita il riuso (e fa risparmiare lavoro)
Una volta che il codice è in LLVM IR, la maggior parte delle passate di ottimizzazione non deve sapere se è nato come template C++, iteratori Rust o generici Swift. Si interessano per lo più a idee universali come:
- "Questo valore è costante."
- "Questa computazione si ripete; possiamo riutilizzare il risultato?"
- "Questo caricamento di memoria può essere spostato o rimosso in sicurezza."
Quindi i team dei linguaggi non devono costruire (e mantenere) il proprio stack completo di ottimizzazione. Possono concentrarsi sul frontend—parsing, type checking, regole specifiche del linguaggio—e poi affidare il lavoro pesante a LLVM.
Come appare concettualmente
LLVM IR è abbastanza a basso livello da mappare pulitamente al codice macchina, ma ancora strutturato a sufficienza per essere analizzato. Concettualmente è costruito da istruzioni semplici (add, compare, load/store), controllo di flusso esplicito (branch) e valori fortemente tipizzati—più simile a un'assembly ordinata pensata per i compilatori che a qualcosa che gli umani scrivono normalmente.
Come funzionano le ottimizzazioni (senza la matematica)
Quando si sente "ottimizzazioni del compilatore", spesso si immaginano trucchi misteriosi. In LLVM, la maggior parte delle ottimizzazioni è meglio intesa come riscritture meccaniche sicure del programma—trasformazioni che preservano il comportamento del codice ma mirano a farlo funzionare più velocemente (o a occupare meno spazio).
Pensalo come editing, non inventare
LLVM prende il tuo codice (in LLVM IR) e applica ripetutamente piccoli miglioramenti, un po' come lucidare una bozza:
- Rimuovere lavoro duplicato: se un valore è calcolato due volte e nulla cambia nel frattempo, LLVM può calcolarlo una sola volta e riutilizzare il risultato.
- Semplificare logica ovvia: espressioni costanti possono essere valutate in anticipo (es. trasformare
3 * 4in12), così la CPU fa meno lavoro a runtime. - Snellire i cicli: le passate sui loop possono ridurre controlli ripetuti, spostare lavoro invariante fuori dal ciclo o riconoscere pattern che si possono eseguire più efficacemente.
Questi cambiamenti sono deliberatamente conservativi. Una passata esegue una riscrittura solo quando può provare che non cambierà il significato del programma.
Esempi concreti
Se il tuo programma concettualmente fa:
- Legge lo stesso valore di configurazione a ogni iterazione di un ciclo
- Esegue lo stesso calcolo sugli stessi input in più punti
- Controlla una condizione che è sempre vera/falsa in un dato contesto
…LLVM cerca di trasformare tutto ciò in "fai l'impostazione una volta sola", "riusa i risultati" e "elimina rami morti". È meno magia e più cura della casa.
Il vero compromesso: tempo di compilazione vs. tempo di esecuzione
L'ottimizzazione non è gratuita: più analisi e più passate normalmente significano compilazione più lenta, anche se il programma finale gira più velocemente. Per questo le toolchain offrono livelli come "ottimizza poco" contro "ottimizza aggressivamente".
I profili aiutano qui. Con la profile-guided optimization (PGO), esegui il programma, raccogli dati di utilizzo reali e poi ricompili in modo che LLVM concentri gli sforzi sui percorsi che contano davvero—rendendo il compromesso più prevedibile.
Backend: raggiungere molte CPU senza riscrivere tutto
Spedisci un'App Full Stack
Genera un front end React con backend in Go e PostgreSQL in un unico flusso.
Un compilatore ha due lavori molto diversi. Primo, deve capire il tuo codice sorgente. Secondo, deve produrre codice macchina che una CPU specifica possa eseguire. I backend di LLVM si concentrano su questo secondo lavoro.
Cosa fa realmente un backend
Pensa a LLVM IR come a una "ricetta universale" per ciò che il programma deve fare. Un backend trasforma quella ricetta nelle istruzioni esatte per una famiglia di processori—x86-64 per la maggior parte dei desktop e server, ARM64 per molti telefoni e laptop recenti, o target specializzati come WebAssembly.
Concretamente, un backend si occupa di:
- Selezione delle istruzioni: mappare operazioni IR a vere istruzioni CPU
- Allocazione dei registri: scegliere quali valori vivono nei registri veloci della CPU vs. memoria
- Scheduling: ordinare le istruzioni in modo che la CPU le esegua efficacemente
- Output assembly/oggetto: emettere codice che linker e OS possano usare
Perché l'infrastruttura condivisa semplifica il supporto per nuovo hardware
Senza un core condiviso, ogni linguaggio dovrebbe reimplementare tutto questo per ogni CPU che vuole supportare—un lavoro enorme e un onere di manutenzione costante.
LLVM capovolge la situazione: i frontend (come Clang) producono LLVM IR una sola volta, e i backend gestiscono l'"ultimo miglio" per ciascun target. Aggiungere supporto per una nuova CPU in genere significa scrivere un backend (o estenderne uno esistente), non riscrivere ogni compilatore esistente.
Portabilità per i team che distribuiscono su più piattaforme
Per progetti che devono girare su Windows/macOS/Linux, su x86 e ARM, o persino nel browser, il modello dei backend di LLVM è un vantaggio pratico. Puoi mantenere un solo codebase e in gran parte una sola pipeline di build, quindi ritargettare scegliendo un backend diverso (o cross-compilando).
Quella portabilità è il motivo per cui LLVM è così diffuso: non riguarda solo la velocità—si tratta anche di evitare lavoro specifico per piattaforma che rallenta i team.
Clang: dove molti sviluppatori incontrano per la prima volta LLVM
Clang è il frontend per C, C++ e Objective-C che si collega a LLVM. Se LLVM è il motore condiviso che può ottimizzare e generare codice macchina, Clang è la parte che legge i tuoi file sorgente, capisce le regole del linguaggio e trasforma ciò che hai scritto in una forma su cui LLVM può lavorare.
Perché Clang si è fatto notare
Molti sviluppatori non hanno scoperto LLVM leggendo paper sui compilatori—l'hanno incontrato la prima volta quando hanno cambiato compilatore e il feedback è migliorato all'improvviso.
Le diagnostiche di Clang sono note per essere più leggibili e più specifiche. Invece di errori vaghi, spesso indica il token esatto che ha causato il problema, mostra la riga rilevante e spiega cosa si aspettava. Questo conta nel lavoro quotidiano perché il ciclo "compila, correggi, ripeti" diventa meno frustrante.
Clang espone anche interfacce pulite e ben documentate (in particolare tramite libclang e l'ecosistema di tooling Clang). Questo ha reso più semplice per editor, IDE e altri strumenti integrarsi con una comprensione profonda del linguaggio C/C++ senza reinventare un parser.
Come si manifesta nei flussi di lavoro quotidiani
Una volta che uno strumento può analizzare e parsare il tuo codice in modo affidabile, inizi a ottenere funzionalità che sembrano meno editing di testo e più lavoro con un programma strutturato:
- Navigazione del codice accurata ("vai alla definizione", "trova riferimenti") anche in grandi progetti C++ con molte macro
- Supporto al refactoring che comprende simboli e scope, non solo cerca-e-sostituisci
- Suggerimenti inline e correzioni rapide guidate da vera informazione su sintassi e tipi
Ecco perché Clang è spesso il primo punto di contatto per LLVM: è da lì che derivano miglioramenti pratici dell'esperienza sviluppatore. Anche se non pensi mai a LLVM IR o ai backend, ne benefici quando l'autocomplete è più intelligente, i controlli statici sono più precisi e gli errori di build sono più facili da correggere.
Perché molti linguaggi moderni si basano su LLVM
LLVM è attraente per i team di linguaggi per una ragione semplice: permette loro di concentrarsi sul linguaggio invece di passare anni a reinventare un compilatore ottimizzante completo.
Tempo di immissione sul mercato più rapido
Costruire un nuovo linguaggio già richiede parsing, type-checking, diagnostica, tooling per i pacchetti, documentazione e supporto della community. Se devi anche creare un ottimizzatore di livello produttivo, un generatore di codice e il supporto piattaforma da zero, il rilascio si ritarda—talvolta di anni.
LLVM fornisce un core di compilazione pronto: allocazione dei registri, selezione delle istruzioni, passate di ottimizzazione mature e target per CPU comuni. I team possono collegare un frontend che riduce il loro linguaggio a LLVM IR e fare affidamento sulla pipeline esistente per produrre codice nativo per macOS, Linux e Windows.
Alte prestazioni (senza eroi)
L'ottimizzatore e i backend di LLVM sono il risultato di ingegneria a lungo termine e test continuo nel mondo reale. Questo si traduce in buone prestazioni di base per i linguaggi che lo adottano—spesso sufficienti sin dall'inizio e migliorabili man mano che LLVM evolve.
Per questo alcuni linguaggi noti si sono sviluppati attorno a LLVM:
- Swift usa LLVM per generare binari nativi altamente ottimizzati su piattaforme Apple.
- Rust si affida a LLVM per la generazione di codice e per molti target di architettura.
- Julia usa LLVM per abilitare codice numerico veloce, inclusa la compilazione a runtime per carichi specializzati.
Non tutti i linguaggi hanno bisogno di LLVM
Scegliere LLVM è un compromesso, non un obbligo. Alcuni linguaggi danno priorità a binari minuscoli, compilazione ultra-rapida o controllo rigoroso dell'intera toolchain. Altri hanno già compilatori consolidati (come ecosistemi basati su GCC) o preferiscono backend più semplici.
LLVM è popolare perché è una buona soluzione predefinita—non perché sia l'unica via valida.
JIT e compilazione a runtime: cicli di feedback rapidi
Trasforma la Condivisione in Crediti
Ottieni crediti condividendo quello che costruisci o invitando altri a provare Koder.ai.
"Just-in-time" (JIT) è più facile da pensare come compilare mentre esegui. Invece di tradurre tutto il codice in anticipo in un eseguibile finale, un motore JIT aspetta finché un pezzo di codice è necessario e compila quella parte al volo—spesso usando informazioni runtime reali (come i tipi esatti e le dimensioni dei dati) per fare scelte migliori.
Perché il JIT può sembrare veloce
Perché non devi compilare tutto in anticipo, i sistemi JIT possono dare feedback rapidi per lavoro interattivo. Scrivi o generi un frammento di codice, lo esegui immediatamente e il sistema compila solo ciò che serve in quel momento. Se quel codice viene eseguito ripetutamente, il JIT può memorizzare nella cache il risultato compilato o ricompilare le sezioni "calde" più aggressivamente.
Dove la compilazione a runtime aiuta nella pratica
Il JIT eccelle quando i carichi sono dinamici o interattivi:
- REPL e notebook: valuta snippet istantaneamente mantenendo esecuzione a velocità nativa per loop pesanti.
- Plugin ed estensioni: le applicazioni possono caricare codice utente a runtime e compilarlo per adattarsi alla CPU host.
- Carichi dinamici: quando gli input variano molto, il profiling a runtime può guidare su quali percorsi valga la pena ottimizzare.
- Calcolo scientifico: kernel generati (per una dimensione di matrice specifica, forma di modello o feature hardware) possono essere compilati su richiesta.
Il ruolo di LLVM (senza l'hype)
LLVM non rende magicamente ogni programma più veloce e non è un JIT completo da solo. Offre però un kit di strumenti: un IR ben definito, molte passate di ottimizzazione e generazione di codice per molte CPU. I progetti possono costruire motori JIT sopra questi mattoni, scegliendo il compromesso giusto tra tempo di avvio, prestazioni di picco e complessità.
Prestazioni, prevedibilità e compromessi nel mondo reale
Le toolchain basate su LLVM possono produrre codice estremamente veloce—ma "veloce" non è una proprietà singola e stabile. Dipende dalla versione del compilatore, dalla CPU target, dalle impostazioni di ottimizzazione e persino da cosa chiedi al compilatore di assumere sul programma.
Perché lo stesso sorgente può dare risultati diversi
Due compilatori possono leggere lo stesso sorgente e comunque generare codice macchina significativamente diverso. Parte di questo è intenzionale: ogni compilatore ha le sue passate di ottimizzazione, euristiche e impostazioni predefinite. Anche all'interno di LLVM, Clang 15 e Clang 18 possono prendere decisioni diverse su inlining, vettorizzazione dei loop o scheduling delle istruzioni.
Può anche essere causato da comportamento indefinito e comportamento non specificato nel linguaggio. Se il tuo programma dipende per errore da qualcosa che lo standard non garantisce (come overflow con segno in C), compilatori diversi—o flag diversi—possono "ottimizzare" in modi che cambiano il risultato.
Determinismo, build di debug e build di release
Spesso ci si aspetta che la compilazione sia deterministica: stessi input, stessi output. In pratica ci si avvicina, ma non si ottengono sempre binari identici in ambienti diversi. Percorsi di build, timestamp, ordine di link, dati guidati dal profilo e scelte LTO possono tutti influenzare l'artefatto finale.
La distinzione più pratica è debug vs release. Le build di debug tipicamente disabilitano molte ottimizzazioni per preservare il debug passo-passo e stack trace leggibili. Le build di release abilitano trasformazioni aggressive che possono riorganizzare il codice, inlinare funzioni e rimuovere variabili—ottimo per le prestazioni, ma a volte più difficile da debuggare.
Consiglio pratico: misura, non indovinare
Tratta le prestazioni come un problema di misura:
- Esegui benchmark su hardware rappresentativo e con dataset realistici.
- Riscalda le cache e esegui più iterazioni.
- Confronta build con flag espliciti (ad esempio cambiando
-O2vs-O3, abilitando/disabilitando LTO o selezionando un target con-march).
Piccole modifiche ai flag possono spostare le prestazioni in entrambe le direzioni. Il flusso di lavoro più sicuro è: formula un'ipotesi, misurala e tieni i benchmark vicini a ciò che usano i tuoi utenti.
Tooling oltre la compilazione: analisi, debugging e sicurezza
Dallo Sviluppo al Live
Pubblica una versione ospitata senza dover cucire insieme i passaggi di build a mano.
LLVM è spesso descritto come un kit di strumenti per compilatori, ma molti sviluppatori ne percepiscono l'impatto tramite strumenti che stanno intorno alla compilazione: analizzatori, debugger e controlli di sicurezza che si attivano durante build e test.
Analisi e strumentazione come "componenti aggiuntivi"
Poiché LLVM espone una rappresentazione intermedia (IR) ben definita e una pipeline a passate, è naturale costruire passaggi extra che ispezionano o riscrivono il codice per scopi diversi dalla sola velocità. Una passata può inserire contatori per il profiling, marcare operazioni di memoria sospette o raccogliere dati di coverage.
Il punto chiave è che queste funzionalità si possono integrare senza che ogni team linguistico reinventi la stessa infrastruttura.
Sanitizzatori: trovare bug vicino alla sorgente
Clang e LLVM hanno reso popolari i cosiddetti "sanitizzatori" runtime che strumentano i programmi per rilevare classi comuni di bug durante i test—pensate a out-of-bounds, use-after-free, race condition e pattern di comportamento indefinito. Non sono scudi magici e rallentano il programma, quindi si usano principalmente in CI e test pre-release. Ma quando scattano, spesso indicano una posizione sorgente precisa e una spiegazione leggibile, esattamente ciò che serve per inseguire crash intermittenti.
Diagnostica migliore = onboarding più rapido
La qualità degli strumenti riguarda anche la comunicazione. Avvisi chiari, messaggi di errore azionabili e informazioni di debug coerenti riducono il fattore "mistero" per i nuovi arrivati. Quando la toolchain spiega cosa è successo e come risolverlo, gli sviluppatori spendono meno tempo a memorizzare stranezze del compilatore e più tempo a imparare il codice.
LLVM non garantisce diagnostica o sicurezza perfette da solo, ma fornisce una base comune che rende pratico costruire, mantenere e condividere questi strumenti tra molti progetti.
Quando usare LLVM (e quando no)
LLVM è meglio pensato come un "costruisci-il-tuo-compilatore e kit di tooling". Quella flessibilità è proprio il motivo per cui alimenta molte toolchain moderne—ma è anche il motivo per cui non è la risposta giusta per ogni progetto.
Quando LLVM è una buona scelta
LLVM brilla quando vuoi riutilizzare ingegneria seria dei compilatori senza reinventarla.
Se stai costruendo un nuovo linguaggio di programmazione, LLVM può darti una pipeline di ottimizzazione collaudata, generazione di codice matura per molte CPU e un percorso verso un buon supporto di debug.
Se distribuisci app cross-platform, l'ecosistema di backend di LLVM riduce il lavoro per target diversi. Ti concentri sulla logica del linguaggio o del prodotto, invece di scrivere generatori di codice separati.
Se il tuo obiettivo è tooling per sviluppatori—linters, analisi statiche, navigazione del codice, refactoring—LLVM (e l'ecosistema attorno) è una solida base perché il compilatore già "capisce" struttura e tipi del codice.
Quando può essere eccessivo
LLVM può essere pesante se lavori su embedded molto piccoli dove dimensione di build, memoria e tempo di compilazione sono vincoli stretti.
Potrebbe non essere adatto anche per pipeline molto specializzate dove non vuoi ottimizzazioni generiche, o dove il tuo "linguaggio" è più vicino a una DSL fissa con una mappatura diretta e semplice verso il codice macchina.
Una semplice checklist
Fatti tre domande:
- Dobbiamo targettizzare più piattaforme/CPU ora o presto?
- Traiamo beneficio da ottimizzazioni e info di debug esistenti, invece di costruirle da zero?
- Preferiamo un percorso con ecosistema (tooling, integrazioni, recruiting) rispetto a un compilatore minimale e personalizzato?
Se hai risposto "sì" alla maggior parte, LLVM è di solito una scommessa pratica. Se vuoi principalmente il compilatore più piccolo e semplice che risolve un problema molto specifico, un approccio più leggero può vincere.
Una nota pratica per i team di prodotto: i benefici di LLVM senza diventare esperti di compilatori
La maggior parte dei team non vuole "adottare LLVM" come progetto. Vogliono risultati: build cross-platform, binari veloci, diagnostica chiara e tooling affidabile.
Per questo piattaforme come Koder.ai risultano interessanti in questo contesto. Se il tuo flusso di lavoro è sempre più guidato da automazione di alto livello (pianificazione, generazione di scaffolding, iterare in loop stretti), benefici comunque di LLVM indirettamente attraverso le toolchain sottostanti—che tu stia costruendo una web app React, un backend Go con PostgreSQL o un client mobile Flutter. L'approccio chat-driven "vibe-coding" di Koder.ai si concentra sul far arrivare il prodotto più in fretta, mentre l'infrastruttura di compilazione moderna (LLVM/Clang e affini, dove applicabile) continua a svolgere il lavoro ingrato di ottimizzazione, diagnostica e portabilità dietro le quinte.