21 set 2025·8 min
Meilisearch per la ricerca lato server istantanea nelle tue app
Scopri come aggiungere Meilisearch al backend per una ricerca veloce e tollerante ai refusi: setup, indicizzazione, ranking, filtri, sicurezza e nozioni di scaling.
Scopri come aggiungere Meilisearch al backend per una ricerca veloce e tollerante ai refusi: setup, indicizzazione, ranking, filtri, sicurezza e nozioni di scaling.
La ricerca lato server significa che la query viene elaborata sul tuo server (o su un servizio di ricerca dedicato), non nel browser. La tua app invia una richiesta di ricerca, il server la esegue contro un indice e restituisce risultati ordinati.
Questo è importante quando il tuo dataset è troppo grande per essere inviato al client, quando hai bisogno di rilevanza coerente su più piattaforme o quando il controllo degli accessi è imprescindibile (per esempio, strumenti interni dove gli utenti devono vedere solo quello che è permesso). È anche la scelta predefinita quando vuoi analytics, logging e prestazioni prevedibili.
Le persone non pensano ai motori di ricerca: giudicano l'esperienza. Un buon flusso di ricerca “istantanea” di solito significa:
Se uno di questi manca, gli utenti compensano provando query diverse, scorrendo di più o abbandonando la ricerca del tutto.
Questo articolo è una guida pratica per costruire quell'esperienza con Meilisearch. Copriremo come configurarlo in modo sicuro, come strutturare e sincronizzare i dati indicizzati, come sintonizzare rilevanza e regole di ranking, come aggiungere filtri/ordinamento/facet e come pensare a sicurezza e scalabilità in modo che la ricerca resti veloce man mano che la tua app cresce.
Meilisearch è adatto per:
L'obiettivo: risultati che sembrano immediati, accurati e affidabili—senza trasformare la ricerca in un progetto d'ingegneria enorme.
Meilisearch è un motore di ricerca che esegui accanto alla tua app. Gli invii documenti (come prodotti, articoli, utenti o ticket di supporto) e costruisce un indice ottimizzato per ricerche veloci. Il tuo backend (o frontend) interroga poi Meilisearch tramite una semplice API HTTP e ottiene risultati ordinati in millisecondi.
Meilisearch mette a fuoco le funzionalità che gli utenti si aspettano da una ricerca moderna:
È progettato per risultare reattivo e indulgente, anche quando la query è breve, leggermente sbagliata o ambigua.
Meilisearch non sostituisce il tuo database principale. Il tuo database rimane la fonte di verità per le scritture, le transazioni e i vincoli. Meilisearch conserva una copia dei campi che scegli di rendere ricercabili, filtrabili o visualizzabili.
Un buon modello mentale è: database per memorizzare e aggiornare i dati, Meilisearch per trovarli velocemente.
Meilisearch può essere estremamente veloce, ma i risultati dipendono da alcuni fattori pratici:
Per dataset piccoli o medi, spesso basta una singola macchina. Man mano che l'indice cresce, dovrai essere più deliberato su cosa indicizzare e come mantenerlo aggiornato—argomenti che tratteremo nelle sezioni successive.
Prima di installare qualsiasi cosa, decidi cosa effettivamente vuoi cercare. Meilisearch sembrerà “istantaneo” solo se i tuoi indici e i documenti corrispondono a come le persone navigano la tua app.
Inizia elencando le entità ricercabili—tipicamente products, articles, users, help docs, locations, ecc. In molte app l'approccio più pulito è un indice per tipo di entità (es. products, articles). Questo mantiene regole di ranking e filtri prevedibili.
Se l'UX ricerca su più tipi in una sola casella (“search everything”), puoi comunque mantenere indici separati e unire i risultati nel backend, o creare in seguito un indice “globale” dedicato. Non forzare tutto in un unico indice a meno che i campi e i filtri siano veramente allineati.
Ogni documento ha bisogno di un identificatore stabile (chiave primaria). Scegli qualcosa che:
id, sku, slug)Per la forma del documento, preferisci campi piatti quando possibile. Le strutture piatte sono più facili da filtrare e ordinare. I campi annidati vanno bene quando rappresentano un pacchetto compatto e poco soggetto a cambiamento (es. un oggetto author), ma evita annidamenti profondi che rispecchiano l'intero schema relazionale—i documenti di ricerca dovrebbero essere ottimizzati per la lettura, non modellati come il DB.
Un modo pratico per progettare i documenti è assegnare a ogni campo un ruolo:
Questo evita un errore comune: indicizzare un campo “nel caso” e poi chiedersi perché i risultati sono rumorosi o i filtri lenti.
“Lingua” può significare cose diverse nei tuoi dati:
lang: "en")Decidi presto se userai indici separati per lingua (semplice e prevedibile) o un indice unico con campi di lingua (meno indici, più logica). La scelta dipende dal fatto che gli utenti cerchino in una lingua alla volta e da come memorizzi le traduzioni.
Eseguire Meilisearch è semplice, ma “sicuro per impostazione predefinita” richiede alcune scelte deliberate: dove deployarlo, come persistere i dati e come gestire la master key.
Storage: Meilisearch scrive l'indice su disco. Metti la directory dati su storage affidabile e persistente (non su storage effimero dei container). Pianifica la capacità per la crescita: gli indici possono espandersi rapidamente con campi testuali grandi e molti attributi.
Memoria: assegna RAM sufficiente per mantenere la ricerca reattiva sotto carico. Se noti swapping, le prestazioni ne risentiranno.
Backup: esegui il backup della directory dati di Meilisearch (o usa snapshot a livello di storage). Verifica il ripristino almeno una volta; un backup che non puoi ripristinare è solo un file.
Monitoring: monitora CPU, RAM, spazio su disco e I/O disco. Monitora anche lo stato del processo e gli errori nei log. Al minimo, imposta alert se il servizio si ferma o lo spazio su disco è basso.
Esegui sempre Meilisearch con una master key in qualsiasi ambiente diverso dallo sviluppo locale. Conservala in un secret manager o in uno store di variabili d'ambiente crittografate (non su Git, non in un .env in chiaro committato).
Esempio (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Considera anche regole di rete: binda su un'interfaccia privata o limita l'accesso in ingresso in modo che solo il tuo backend possa raggiungere Meilisearch.
curl -s http://localhost:7700/version
L'indicizzazione in Meilisearch è asincrona: invii documenti, Meilisearch mette in coda un task e solo quando quel task ha successo i documenti diventano ricercabili. Tratta l'indicizzazione come un sistema di job, non come una singola richiesta sincrona.
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
taskUid. Poll fino a quando non è succeeded (o failed).curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Se i conteggi non corrispondono, non indovinare—controlla prima i dettagli di errore del task.
Il batching serve a mantenere i task prevedibili e recuperabili.
addDocuments funziona come un upsert: documenti con la stessa chiave primaria sono aggiornati, i nuovi vengono inseriti. Usalo per aggiornamenti normali.
Fai un reindex completo quando:
Per le rimozioni, chiama esplicitamente deleteDocument(s); altrimenti i record vecchi possono rimanere.
L'indicizzazione deve essere ritentabile. La chiave sono gli id dei documenti stabili.
taskUid restituito insieme all'id del batch/job, e ritenta basandoti sullo stato del task.Prima dei dati di produzione, indicizza un piccolo dataset (200–500 elementi) che rispecchi i tuoi campi reali. Esempio: un set products con id, name, description, category, brand, price, inStock, createdAt. È sufficiente per validare flusso di task, conteggi e comportamento update/delete—senza attendere un'importazione massiva.
La “rilevanza” di ricerca è semplicemente: cosa appare per primo e perché. Meilisearch rende questo regolabile senza costringerti a costruire un intero sistema di scoring.
Due impostazioni definiscono cosa Meilisearch può fare con i tuoi contenuti:
searchableAttributes: i campi in cui Meilisearch cerca quando l'utente digita (per esempio: title, summary, tags). L'ordine conta: i campi più in alto sono considerati più importanti.displayedAttributes: i campi restituiti nella risposta. Questo è importante per privacy e dimensione del payload—se un campo non è visualizzato, non verrà inviato.Una baseline pratica è rendere ricercabili pochi campi ad alto segnale (title, testo chiave) e mantenere i campi mostrati a quanto serve all'interfaccia.
Meilisearch ordina i documenti corrispondenti usando le ranking rules—una pipeline di "tie-breaker". Concettualmente preferisce:
Non è necessario memorizzare i dettagli interni per sintonizzarlo efficacemente; scegli principalmente quali campi contano di più e quando applicare ordinamenti personalizzati.
Obiettivo: “I match sul titolo devono vincere.” Metti title per primo:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Obiettivo: “I contenuti più recenti prima.” Aggiungi un attributo ordinabile e ordina a query time (o imposta un ranking personalizzato):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Poi richiedi:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Obiettivo: “Promuovi gli elementi popolari.” Rendi popularity ordinabile e ordina per esso quando opportuno.
Scegli 5–10 query reali che gli utenti digitano. Salva i risultati top prima delle modifiche, poi confronta dopo.
Esempio:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerSe la lista “dopo” rispecchia meglio l'intento dell'utente, mantieni le impostazioni. Se peggiora in casi limite, modifica una cosa alla volta (ordine attributi, poi regole di ordinamento) per capire cosa ha causato il cambiamento.
Una buona casella di ricerca non è solo “digita parole, ottieni corrispondenze.” Le persone vogliono anche restringere i risultati (“solo articoli disponibili”) e ordinarli (“i più economici prima”). In Meilisearch lo fai con filtri, ordinamento e facet.
Un filtro è una regola che applichi al set di risultati. Un facet è ciò che mostri nell'interfaccia per aiutare gli utenti a costruire quelle regole (spesso checkbox o conteggi).
Esempi non tecnici:
Un utente potrebbe cercare “running” e poi filtrare con category = Shoes e status = in_stock. I facet possono mostrare conteggi come “Shoes (128)” e “Jackets (42)” così l'utente capisce cosa è disponibile.
Meilisearch richiede che tu abiliti esplicitamente i campi usati per filtri e ordinamenti.
category, status, brand, price, created_at, tenant_id.price, rating, created_at, popularity.Mantieni questa lista ristretta. Rendere tutto filterable/sortable può aumentare la dimensione dell'indice e rallentare gli aggiornamenti.
Anche se hai 50.000 corrispondenze, gli utenti vedono solo la prima pagina. Usa pagine piccole (spesso 20–50 risultati), imposta un limit sensato e paginazione con offset (o le feature di paginazione più nuove se preferisci). Limita anche la profondità massima della pagina nell'app per evitare richieste costose come “pagina 400”.
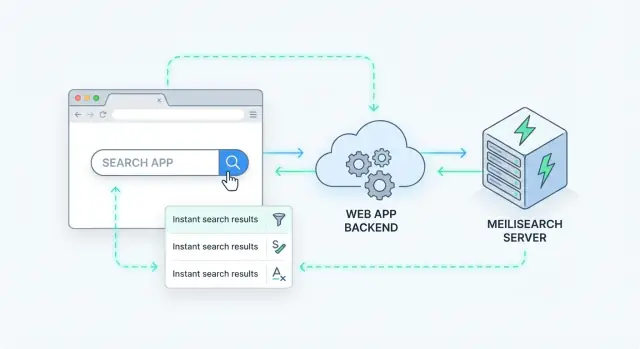
Un modo pulito per aggiungere la ricerca lato server è trattare Meilisearch come un servizio dati specializzato dietro la tua API. La tua app riceve una richiesta di ricerca, chiama Meilisearch e restituisce una risposta curata al client.
La maggior parte dei team arriva a un flusso simile:
GET /api/search?q=wireless+headphones&limit=20).Questo pattern mantiene Meilisearch sostituibile e impedisce al frontend di dipendere dagli interni dell'indice.
Se stai costruendo una nuova app (o ricostruendo uno strumento interno) e vuoi implementare rapidamente questo pattern, una piattaforma vibe-coding come Koder.ai può aiutare a scaffoldare il flusso completo—React UI, backend Go e PostgreSQL—e integrare Meilisearch dietro un singolo endpoint /api/search così il client resta semplice e i permessi rimangono lato server.
Meilisearch supporta query client-side, ma le query via backend sono solitamente più sicure perché:
Le query client-side possono funzionare per dati pubblici con chiavi limitate, ma se hai regole di visibilità per utente, passa la ricerca tramite il server.
Il traffico di ricerca spesso ripete query (“iphone case”, “return policy”). Aggiungi caching a livello API:
Tratta la ricerca come un endpoint pubblico:
limit massimo e una lunghezza massima di query.Meilisearch è spesso posizionato “dietro” la tua app perché può restituire dati business sensibili velocemente. Trattalo come un database: blindalo e espone solo ciò che ogni chiamante dovrebbe vedere.
Meilisearch ha una master key che può fare tutto: creare/eliminare indici, aggiornare settings e leggere/scrivere documenti. Tienila solo sul server.
Per le applicazioni, genera chiavi API con azioni limitate e indici limitati. Uno schema comune:
Il principio del minimo privilegio significa che una chiave rubata non può eliminare dati o leggere indici non autorizzati.
Se servi più clienti (tenant), hai due opzioni principali:
1) Un indice per tenant.
Semplice da ragionare e riduce il rischio di accesso cross-tenant. Contro: più indici da gestire e aggiornamenti delle impostazioni da applicare coerentemente.
2) Indice condiviso + filtro per tenant.
Memorizza un campo tenantId su ogni documento e richiedi un filtro come tenantId = "t_123" per tutte le ricerche. Scala bene, ma solo se assicuri che ogni richiesta applichi sempre il filtro (idealmente tramite una chiave scoped che non permetta di rimuoverlo).
Anche se la ricerca è corretta, i risultati possono rivelare campi che non volevi mostrare (email, note interne, prezzi di costo). Configura cosa può essere restituito:
Esegui un test “worst-case”: cerca un termine comune e conferma che non appaiano campi privati.
Se non sei sicuro che una chiave debba stare client-side, assumi “no” e tieni la ricerca server-side.
Meilisearch è veloce quando tieni a mente due workload: indicizzazione (scritture) e query di ricerca (letture). La maggior parte dei rallentamenti misteriosi deriva dal fatto che uno di questi compete per CPU, RAM o disco.
Carico di indicizzazione può esplodere quando importi grandi batch, fai aggiornamenti frequenti o aggiungi molti campi ricercabili. L'indicizzazione è un task in background ma consuma comunque CPU e banda disco. Se la coda dei task cresce, le ricerche possono iniziare a rallentare anche se il volume di query è invariato.
Carico di query cresce con il traffico, ma anche con le feature: più filtri, più facet, set di risultati più grandi e maggiore tolleranza agli errori aumentano il lavoro per richiesta.
I/O disco è il colpevole silenzioso. Dischi lenti (o "noisy neighbors" su volumi condivisi) possono trasformare “istantaneo” in “eventuale”. NVMe/SSD è la baseline tipica per produzione.
Inizia con una dimensione semplice: fornisci a Meilisearch RAM sufficiente per tenere gli indici caldi e CPU per gestire il picco di QPS. Poi separa i carichi:
Monitora pochi segnali chiave:
I backup devono essere routine, non eroici. Usa la feature di snapshot di Meilisearch su schedule, conserva gli snapshot fuori dalla macchina e testa il restore periodicamente. Per gli upgrade, leggi le note di rilascio, esegui l'upgrade in staging e pianifica tempi di reindicizzazione se una versione cambia il comportamento di indicizzazione.
Se già usi snapshot/rollback nell'infrastruttura (per esempio, tramite i workflow snapshot/rollback di Koder.ai), allinea il rollout della ricerca alla stessa disciplina: snapshot prima delle modifiche, verifica health checks e tieni una via rapida per tornare a uno stato noto buono.
Anche con un'integrazione pulita, i problemi di ricerca rientrano spesso in poche categorie ripetute. La buona notizia: Meilisearch offre abbastanza visibilità (tasks, log, settings deterministici) per fare debug velocemente—se lo affronti in modo sistematico.
filterableAttributes, oppure i documenti lo memorizzano in una forma inattesa (string vs array vs oggetto annidato).sortableAttributes/rankingRules stanno promuovendo gli elementi sbagliati.Inizia controllando se Meilisearch ha applicato con successo l'ultima modifica.
filter, poi sort, poi facets.Se non riesci a spiegare un risultato, riduci temporaneamente la configurazione: rimuovi sinonimi, riduci tweak alle ranking rule e testa con un dataset piccolo. I problemi di rilevanza complessi sono molto più facili da diagnosticare su 50 documenti che su 5 milioni.
your_index_v2 in parallelo, applica le impostazioni e riproduci un campione di query di produzione.filterableAttributes e sortableAttributes corrispondano ai requisiti dell'interfaccia.Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
Server-side search significa che la query viene eseguita sul tuo backend (o su un servizio di ricerca dedicato), non nel browser. È la scelta giusta quando:
Gli utenti notano quattro cose immediatamente:
Se manca uno di questi elementi, le persone riscrivono query, scorrono troppo o abbandonano la ricerca.
Consideralo come un indice di ricerca, non la tua fonte di verità. Il database gestisce scritture, transazioni e vincoli; Meilisearch conserva una copia dei campi selezionati ottimizzata per il recupero rapido.
Un modello mentale utile è:
Una scelta comune è un indice per tipo di entità (es. products, articles). Questo mantiene:
Se servono ricerche “globali”, puoi interrogare più indici e unire i risultati nel backend, o creare in seguito un indice globale dedicato.
Scegli una chiave primaria che sia:
id, sku, slug)ID stabili rendono l'indicizzazione idempotente: se ritenti un upload non crei duplicati perché gli aggiornamenti diventano upsert sicuri.
Classifica ogni campo per scopo in modo da non sovra-indicizzare:
Esplicitare questi ruoli riduce risultati rumorosi e previene indici lenti o gonfi.
L'indicizzazione è asincrona: gli upload di documenti creano un task e i documenti diventano ricercabili solo dopo il successo del task.
Un flusso affidabile è:
succeeded o failedSe i risultati sembrano obsoleti, controlla prima lo stato del task.
Usa molti batch più piccoli invece di un unico upload gigantesco. Punti di partenza pratici:
Batch più piccoli sono più facili da ritentare, da debuggar e meno soggetti a timeout.
Due leve ad alto impatto sono:
searchableAttributes: quali campi vengono cercati e in che ordine di prioritàpublishedAt, price o popularityUn approccio pratico: prendi 5–10 query reali, salva i risultati “prima”, cambia una sola impostazione e confronta “dopo”.
I problemi di filtro/ordinamento derivano spesso da configurazioni mancanti:
filterableAttributes per poter essere filtratosortableAttributes per poter essere ordinatoVerifica inoltre la forma e i tipi dei campi nei documenti (string vs array vs oggetto annidato). Se un filtro fallisce, ispeziona lo stato dell'ultimo task/setting e conferma che i documenti indicizzati contengano i valori attesi.