03 nov 2025·8 min
Modelli SaaS multi-tenant: isolamento, scalabilità e progettazione con IA
Scopri i pattern comuni per SaaS multi-tenant, i compromessi sull'isolamento dei tenant e le strategie di scalabilità. Scopri come architetture generate dall'IA accelerano progettazione e revisioni.
Cosa significa multi-tenancy (senza gergo)
Multi-tenancy significa che un unico prodotto software serve più clienti (tenant) dallo stesso sistema in esecuzione. Ogni tenant ha la sensazione di avere “la propria app”, ma dietro le quinte condivide parti dell’infrastruttura — come gli stessi server web, lo stesso codebase e spesso lo stesso database.
Un modello mentale utile è quello di un condominio. Ognuno ha la propria unità chiusa a chiave (i propri dati e le proprie impostazioni), ma si condividono l’ascensore, l’impianto idraulico e il team di manutenzione (il compute, lo storage e le operazioni dell’app).
Perché i team scelgono la multi-tenancy
La maggior parte dei team non sceglie il SaaS multi-tenant perché è di moda — lo scelgono perché è efficiente:
- Costo per cliente più basso: l’infrastruttura condivisa è generalmente più economica rispetto al provisioning di uno stack completo per ogni cliente.
- Operazioni più semplici: una piattaforma da monitorare, patchare e mettere in sicurezza (invece di centinaia di deployment piccoli).
- Rilasci più rapidi: i miglioramenti vanno a tutti contemporaneamente e si evita la “deriva delle versioni” tra i clienti.
Dove può andare storto
I due classici problemi sono sicurezza e prestazioni.
Sulla sicurezza: se i confini tra tenant non sono applicati ovunque, un bug può far fuoriuscire dati tra clienti. Queste perdite raramente sono attacchi spettacolari — spesso sono errori ordinari come un filtro mancato, un controllo di permessi mal configurato o un job in background che gira senza il contesto del tenant.
Sulle prestazioni: le risorse condivise fanno sì che un tenant molto attivo possa rallentare gli altri. L’effetto “noisy neighbor” può manifestarsi con query lente, workload a raffica o un singolo cliente che consuma capacità API in modo sproporzionato.
Breve anteprima dei pattern trattati
Questo articolo percorre i mattoni che i team usano per gestire questi rischi: isolamento dei dati (database, schema o righe), identità e permessi a livello di tenant, controlli per i noisy neighbor e pattern operativi per la scalabilità e la gestione dei cambiamenti.
Il trade-off principale: isolamento vs efficienza
La multi-tenancy è una scelta su dove stare lungo uno spettro: quanto condividi tra tenant rispetto a quanto dedichi per tenant. Ogni pattern architetturale qui sotto è solo un punto diverso su quella linea.
Risorse condivise vs dedicate: lo spettro principale
A un estremo, i tenant condividono quasi tutto: le stesse istanze app, gli stessi database, le stesse code, le stesse cache — separati logicamente dagli ID dei tenant e dalle regole di accesso. Questo è tipicamente il più economico e il più semplice da gestire perché si mette in pool la capacità.
All’altro estremo, i tenant ottengono la propria “fetta” del sistema: database separati, compute separato, a volte anche deployment separati. Questo aumenta sicurezza e controllo, ma aumenta anche i costi operativi.
Perché isolamento e costo tirano in direzioni opposte
L’isolamento riduce la probabilità che un tenant possa accedere ai dati di un altro, consumare il budget di prestazioni altrui o essere impattato da pattern di utilizzo insoliti. Facilita anche alcuni audit e requisiti di compliance.
L’efficienza migliora quando ammortizzi la capacità inattiva su molti tenant. L’infrastruttura condivisa permette di eseguire meno server, mantenere pipeline di deployment più semplici e scalare sulla base della domanda aggregata invece che sul peggior caso per singolo tenant.
Driver comuni della decisione
Il punto “giusto” sullo spettro raramente è filosofico — è guidato da vincoli:
- SLA e aspettative dei clienti: target stringenti di uptime o latenza spingono verso più isolamento.
- Compliance e residenza dei dati: requisiti che possono imporre storage dedicato o ambienti separati.
- Fase di crescita: i prodotti early spesso partono più condivisi per muoversi più velocemente; in seguito si possono introdurre opzioni dedicate per clienti grandi.
- Maturità operativa: più isolamento significa più cose da monitorare, patchare e migrare.
Un modello mentale semplice per scegliere i pattern
Fatti due domande:
-
Qual è il raggio d’azione (blast radius) se un tenant si comporta male o viene compromesso?
-
Qual è il costo di business per ridurre quel raggio d’azione?
Se il blast radius deve essere minimo, scegli componenti più dedicati. Se il costo e la velocità sono ciò che conta, condividi di più — e investi in controlli d’accesso forti, limiti di velocità e monitoraggio per tenant per mantenere la condivisione sicura.
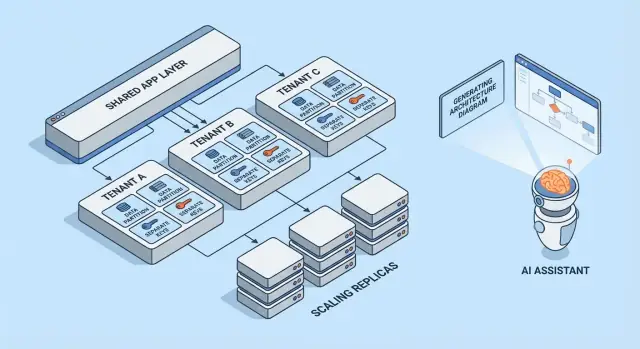
Modelli multi-tenant a colpo d’occhio
La multi-tenancy non è un’architettura unica — è un insieme di modi per condividere (o non condividere) l’infrastruttura tra i clienti. Il modello migliore dipende da quanto isolamento serve, da quanti tenant ti aspetti e da quanto overhead operativo il tuo team può gestire.
1) Single-tenant (dedicato) — il baseline
Ogni cliente ha il proprio stack app (o almeno runtime e database isolati). È il più semplice da ragionare per sicurezza e prestazioni, ma è di solito il più costoso per tenant e può rallentare la scalabilità operativa.
2) App condivisa + DB condiviso — costo più basso, cura maggiore
Tutti i tenant girano sulla stessa applicazione e database. I costi sono tipicamente i più bassi perché massimizzi il riuso, ma devi essere meticoloso sul contesto tenant ovunque (query, caching, job in background, esportazioni per analytics). Un singolo errore può diventare una perdita di dati cross-tenant.
3) App condivisa + DB separati — isolamento più forte, più operazioni
L’applicazione è condivisa, ma ogni tenant ha il proprio database (o istanza di database). Questo migliora il controllo del blast radius per gli incidenti, rende più semplici backup/restore per singolo tenant e può semplificare conversazioni di compliance. Lo svantaggio è operativo: più database da provisionare, monitorare, migrare e mettere in sicurezza.
4) Modelli ibridi per “grandi tenant”
Molti prodotti SaaS mescolano approcci: la maggior parte dei clienti risiede in infrastruttura condivisa, mentre tenant grandi o regolamentati ottengono database dedicati o compute dedicato. L’ibrido è spesso l’esito pratico, ma richiede regole chiare: chi ne ha diritto, quanto costa e come vengono gestiti gli aggiornamenti.
Se vuoi un approfondimento sulle tecniche di isolamento dentro ogni modello, vedi blog/data-isolation-patterns.
Pattern di isolamento dei dati (DB, Schema, Riga)
L’isolamento dei dati risponde a una domanda semplice: “Un cliente può mai vedere o influenzare i dati di un altro cliente?” Ci sono tre pattern comuni, ognuno con implicazioni diverse su sicurezza e operazioni.
Isolamento a livello di riga (tabelle condivise + tenant_id)
Tutti i tenant condividono le stesse tabelle e ogni riga include una colonna tenant_id. Questo è il modello più efficiente per tenant piccoli e medi perché minimizza l’infrastruttura e mantiene semplici reporting e analytics.
Il rischio è semplice: se una query dimentica di filtrare per tenant_id, puoi esporre dati. Anche un singolo endpoint “admin” o un job in background può diventare un punto debole. Le mitigazioni includono:
- Forzare il filtraggio per tenant in un layer di accesso ai dati condiviso (così gli sviluppatori non scrivono filtri a mano)
- Usare funzionalità del database come la row-level security (RLS) quando disponibili
- Aggiungere test automatici che tentano intenzionalmente accessi cross-tenant
- Indicizzare i percorsi d’accesso comuni (spesso
(tenant_id, created_at)o(tenant_id, id)) in modo che le query a ambito tenant rimangano veloci
Schema-per-tenant (stesso database, schemi separati)
Ogni tenant ottiene il proprio schema (namespace come tenant_123.users, tenant_456.users). Questo migliora l’isolamento rispetto alla condivisione a livello di riga e può rendere più semplici esportazioni o tuning specifici per tenant.
Lo svantaggio è l’overhead operativo. Le migrazioni devono essere eseguite su molti schemi e i fallimenti diventano più complicati: potresti migrare con successo 9.900 tenant e rimanere bloccato su 100. Monitoraggio e tooling sono importanti — il processo di migrazione deve avere retry e reporting chiari.
Database-per-tenant (database separati)
Ogni tenant ha un database separato. L’isolamento è forte: i confini di accesso sono più chiari, query rumorose di un tenant sono meno propense a impattare un altro e ripristinare un singolo tenant da backup è molto più pulito.
I costi e la scalabilità sono gli svantaggi principali: più database da gestire, più pool di connessioni e potenzialmente più lavoro per upgrade/migrazione. Molti team riservano questo modello per tenant di alto valore o regolamentati, mentre i tenant più piccoli restano su infrastruttura condivisa.
Sharding e strategie di placement man mano che i tenant crescono
I sistemi reali spesso mescolano questi pattern. Un percorso comune è l’isolamento a livello di riga nella crescita iniziale, poi “promuovere” i tenant più grandi in schemi o database separati.
Lo sharding aggiunge un livello di placement: decidere in quale cluster di database viva un tenant (per regione, fascia di dimensione o hashing). La chiave è rendere la collocazione del tenant esplicita e modificabile — così puoi muovere un tenant senza riscrivere l’app e scalare aggiungendo shard invece di ridisegnare tutto.
Identità, accesso e contesto del tenant
La multi-tenancy fallisce in modi sorprendentemente ordinari: un filtro mancante, un oggetto in cache condiviso tra tenant o uno strumento admin che “dimentica” a chi appartiene la richiesta. La soluzione non è una singola grande funzionalità di sicurezza — è un contesto tenant coerente dal primo byte della richiesta fino all’ultima query al database.
Identificazione del tenant (come sapere “chi”)
La maggior parte dei prodotti SaaS sceglie un identificatore principale e tratta il resto come convenienza:
- Sottodominio:
acme.yourapp.comè comodo per gli utenti e funziona bene con esperienze brandizzate. - Header: utile per client API e servizi interni (ma deve essere autenticato).
- Claim nel token: un JWT firmato (o sessione) include
tenant_id, rendendo difficile la manomissione.
Scegli una sola fonte di verità e loggala ovunque. Se supporti segnali multipli (sottodominio + token), definisci la precedenza e rifiuta richieste ambigue.
Scoping della richiesta (come ogni query resta nel tenant)
Una buona regola: una volta risolto il tenant_id, tutto il downstream dovrebbe leggerlo da un unico posto (contesto della richiesta), non ricalcolarlo.
Guardrail comuni includono:
- Middleware che attacca
tenant_idal contesto della richiesta - Helper di accesso ai dati che richiedono
tenant_idcome parametro - Applicazioni del database (come policy a livello di riga) così che gli errori falliscano chiusi
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Fondamentali di autorizzazione (ruoli all’interno di un tenant)
Separa autenticazione (chi è l’utente) da autorizzazione (cosa può fare).
I ruoli tipici SaaS sono Proprietario / Admin / Membro / Sola lettura, ma l’importante è l’ambito: un utente può essere Admin nel Tenant A e Membro nel Tenant B. Memorizza i permessi per-tenant, non a livello globale.
Prevenire fughe cross-tenant (test e guardrail)
Tratta l’accesso cross-tenant come un incidente di alto livello e prevenilo proattivamente:
- Aggiungi test automatici che tentano di leggere i dati del Tenant B mentre si è autenticati come Tenant A
- Rendi più difficile spedire bug dovuti a filtri mancanti (linters, query builder, parametri tenant obbligatori)
- Logga e alert su pattern sospetti (es. mismatch tra token e sottodominio)
Se vuoi una checklist operativa più approfondita, integra queste regole nei runbook di ingegneria (security) e tienile versionate insieme al codice.
Isolamento oltre il database
Set Up Tenant Routing
Test subdomain or custom domain tenant routing without rebuilding your stack.
L’isolamento del database è solo metà della storia. Molti incidenti reali multi-tenant avvengono nella tubatura condivisa attorno all’app: cache, code e storage. Questi layer sono veloci, comodi e facili da rendere accidentalmente globali.
Cache condivise: prevenire collisioni di chiavi e fughe di dati
Se più tenant condividono Redis o Memcached, la regola principale è semplice: non salvare mai chiavi agnostiche rispetto al tenant.
Un pattern pratico è prefissare ogni chiave con un identificatore tenant stabile (non un dominio email, non un nome visualizzato). Per esempio: t:{tenant_id}:user:{user_id}. Questo fa due cose:
- Previene collisioni dove due tenant hanno gli stessi ID interni
- Rende l’invalidazione bulk fattibile (cancellare per prefisso) durante incidenti di supporto o migrazioni
Decidi anche cosa può essere condiviso globalmente (es. feature flag pubbliche, metadata statici) e documentalo — i globali accidentali sono fonte comune di esposizione cross-tenant.
Rate limit e quote a livello di tenant
Anche se i dati sono isolati, i tenant possono comunque impattarsi a vicenda attraverso il compute condiviso. Aggiungi limiti tenant-aware ai bordi:
- Rate limit API per tenant (e spesso per utente dentro un tenant)
- Quote per operazioni costose (esportazioni, generazione di report, chiamate a servizi IA)
Rendi il limite visibile (header, avvisi UI) così i clienti capiscono che lo throttling è policy, non instabilità.
Job in background: partizionare le code per tenant
Una coda condivisa può permettere a un tenant impegnato di dominare il tempo dei worker.
Fix comuni:
- Code separate per tier/piano (es.
free,pro,enterprise) - Code partizionate per bucket di tenant (hash tenant_id in N code)
- Scheduling tenant-aware così ogni tenant ottiene una fetta equa
Propaga sempre il contesto tenant nel payload del job e nei log per evitare effetti collaterali su tenant sbagliati.
Storage file/object: percorsi, policy e chiavi separate
Per storage tipo S3/GCS, l’isolamento è di solito basato su path e policy:
- Bucket per tenant per separazione stretta (confini più forti, più overhead)
- Bucket condiviso con prefissi per tenant (più semplice, richiede IAM e signed URL attenti)
Qualunque scelta, fai in modo che upload/download validino la proprietà del tenant su ogni richiesta, non solo nella UI.
Gestire i noisy neighbor e l’uso equo delle risorse
I sistemi multi-tenant condividono infrastruttura, il che significa che un tenant può consumare più della sua parte. Questo è il problema del noisy neighbor: un singolo carico rumoroso degrada le prestazioni per tutti gli altri.
Come si presenta un “noisy neighbor”
Immagina una funzione di report che esporta un anno di dati in CSV. Il Tenant A programma 20 esportazioni alle 9:00. Queste esportazioni saturano CPU e I/O DB, così gli schermi normali del Tenant B iniziano a timeoutare — nonostante B non stia facendo nulla di insolito.
Controlli sulle risorse: limiti, quote e shaping dei carichi
Prevenire questo inizia con confini espliciti delle risorse:
- Rate limit (richieste per secondo) per tenant e per endpoint, così API costose non possono essere spamate.
- Quote (totali giornaliere/mensili) per esportazioni, email, chiamate a IA o job in background.
- Workload shaping: mettere task pesanti (esportazioni, importazioni, re-indicizzazione) in code con cap di concorrenza per tenant e regole di priorità.
Un pattern pratico è separare il traffico interattivo dal lavoro batch: tenere le richieste user-facing in una corsia veloce e spostare tutto il resto in code controllate.
Circuit breaker e bulkhead per tenant
Aggiungi valvole di sicurezza che scattano quando un tenant supera una soglia:
- Circuit breaker: rifiutare temporaneamente o deferire operazioni costose quando tassi di errore, latenza o profondità delle code superano limiti per quel tenant.
- Bulkhead: isolare pool condivisi (connessioni DB, thread worker, cache) così un tenant non può esaurire la capacità globale.
Fatto bene, il Tenant A può rallentare le proprie esportazioni senza mandare giù il Tenant B.
Quando spostare un tenant su capacità dedicata
Sposta un tenant su risorse dedicate quando supera costantemente le assunzioni della condivisione: throughput sostenuto elevato, picchi imprevedibili legati a eventi business-critical, requisiti di compliance stringenti o quando il loro workload richiede tuning custom. Una regola semplice: se proteggere altri tenant richiede throttling permanente di un cliente pagante, è ora di capacità dedicata (o di un tier superiore) anziché di lotta continua.
Pattern di scalabilità che funzionano nel SaaS multi-tenant
Build and Earn Credits
Share what you built with Koder.ai and earn credits through the content program.
Scalare multi-tenant è meno “più server” e più evitare che la crescita di un tenant sorprenda tutti gli altri. I pattern migliori rendono la scala prevedibile, misurabile e reversibile.
Scalabilità orizzontale per servizi stateless
Inizia rendendo il tier web/API stateless: memorizza le sessioni in una cache condivisa (o usa auth basata su token), tieni gli upload in object storage e spingi i lavori lunghi in job in background. Una volta che le richieste non dipendono da memoria o disco locali, puoi aggiungere istanze dietro un load balancer e scalare rapidamente.
Un consiglio pratico: mantieni il contesto tenant al bordo (derivato da sottodominio o header) e passalo a ogni handler. Stateless non significa non conoscere il tenant — significa essere tenant-aware senza server sticky.
Hotspot per singolo tenant: identificarli e ammortizzarli
La maggior parte dei problemi di scala è “un tenant è diverso”. Cerca hotspot come:
- Un singolo tenant che genera traffico sovradimensionato
- Alcuni tenant con dataset molto grandi
- Uso batch (report di fine mese, import notturni)
Tattiche per ammortizzare: rate limit per tenant, ingestion basata su code, caching di percorsi di lettura specifici per tenant e sharding di tenant pesanti in pool di worker separati.
Repliche di lettura, partitioning e workload asincroni
Usa repliche di lettura per carichi read-heavy (dashboard, search, analytics) e tieni le scritture sul primario. Il partitioning (per tenant, per tempo o entrambi) aiuta a mantenere gli indici piccoli e le query veloci. Per task costosi — esportazioni, scoring ML, webhook — preferisci job asincroni con idempotenza così i retry non moltiplichino il carico.
Segnali di capacity planning e soglie semplici
Tieni i segnali semplici e tenant-aware: latenza p95, tasso di errori, profondità delle code, CPU DB e tasso di richieste per tenant. Imposta soglie facili (es. “queue depth > N per 10 minuti” o “p95 > X ms”) che attivino autoscaling o limiti temporanei per tenant — prima che gli altri tenant lo percepiscano.
Observability e operazioni per tenant
I sistemi multi-tenant non falliscono globalmente per primi — di solito falliscono per un tenant, un piano o un workload rumoroso. Se i tuoi log e dashboard non rispondono in pochi secondi alla domanda “quale tenant è impattato?”, il tempo on-call diventa indovinare.
Log, metriche e trace tenant-aware
Inizia con un contesto tenant coerente nella telemetria:
- Log: includi
tenant_id,request_ide unactor_idstabile (utente/servizio) su ogni richiesta e job in background. - Metriche: emetti contatori e istogrammi di latenza suddivisi per tier tenant minimo (es.
tier=basic|premium) e per endpoint ad alto livello (non URL grezzi). - Trace: propaga il contesto tenant come attributo della trace così puoi filtrare una trace lenta per tenant specifico e vedere dove si spende il tempo (DB, cache, chiamate terze parti).
Controlla la cardinalità: metriche per singolo tenant per tutti i tenant possono costare caro. Un compromesso comune è metriche per tier di default più drill-down per tenant su richiesta (es. campionare trace per “top 20 tenant per traffico” o per “tenant che violano SLO”).
Evitare fughe di dati sensibili nella telemetria
La telemetria è un canale di esportazione dati. Trattala come dati di produzione.
Preferisci ID rispetto al contenuto: logga customer_id=123 invece di nomi, email, token o payload di query. Aggiungi redaction nel layer logger/SDK e blocklista secret comuni (Authorization header, API key). Per workflow di supporto, conserva i payload di debug in un sistema separato e access-controlled — non nei log condivisi.
SLO per tier di tenant (senza promettere troppo)
Definisci SLO che corrispondano a ciò che puoi effettivamente far rispettare. I tenant premium possono avere budget di latenza/errori più stringenti, ma solo se hai anche controlli (rate limit, isolamento del workload, code prioritarie). Pubblica i SLO per tier come obiettivi e tracciali per tier e per un insieme curato di tenant di alto valore.
Runbook on-call: incidenti comuni nel SaaS multi-tenant
I runbook dovrebbero partire con “identifica i tenant coinvolti” e poi l’azione più rapida per isolare:
- Noisy neighbor: throttla il tenant, pausa job pesanti o spostalo in una coda a priorità inferiore.
- Hotspot DB/query runaway: abilita timeouts sulle query, ispeziona le query top per tenant, applica un indice o limita l’endpoint.
- Bug di contesto tenant (mix di dati): disabilita immediatamente il feature flag o l’endpoint e verifica lo scoping tenant nei controlli d’accesso.
- Accumulo job in background: svuota code per-tenant, limita la concorrenza e replay con salvaguardie di idempotenza.
Operativamente, l’obiettivo è semplice: rilevare per tenant, contenere per tenant e recuperare senza impattare tutti gli altri.
Deploy, migrazioni e rilasci tenant-by-tenant
La multi-tenancy cambia il ritmo del rilascio. Non stai deployando “un’app”; stai deployando runtime e percorsi dati condivisi di cui molti clienti dipendono contemporaneamente. L’obiettivo è consegnare nuove funzionalità senza costringere un aggiornamento sincronizzato e totale per ogni tenant.
Rolling deploy e migrazioni a basso downtime
Preferisci pattern di deployment che tollerino versioni miste per una finestra breve (blue/green, canary, rolling). Questo funziona solo se anche i cambi database sono staged.
Una regola pratica è expand → migrate → contract:
- Expand: aggiungi colonne/tabelle/indici senza rompere il codice esistente.
- Migrate: backfill dei dati in batch (spesso per tenant) e verifica.
- Contract: rimuovi i campi vecchi solo dopo che tutte le istanze dell’app non li usano più.
Per tabelle “calde”, fai backfill incrementali (e throttlali), altrimenti genererai tu stesso un evento noisy-neighbor durante la migrazione.
Feature flag per tenant per rollout più sicuri
I feature flag a livello di tenant ti permettono di rilasciare codice globalmente abilitando il comportamento in modo selettivo.
Questo supporta:
- Programmi early access per pochi tenant
- Rollback rapido disabilitando la feature solo per tenant interessati
- Esperimenti A/B senza forkare i deployment
Mantieni il sistema di flag auditabile: chi ha abilitato cosa, per quale tenant e quando.
Versioning e aspettative di backward compatibility
Assumi che alcuni tenant possano restare indietro su configurazione, integrazioni o pattern d’uso. Progetta API ed eventi con versioning chiaro così nuovi producer non rompano vecchi consumer.
Aspettative comuni da fissare internamente:
- I nuovi rilasci devono leggere sia le forme vecchie che quelle nuove durante le finestre di migrazione.
- Le deprecazioni richiedono una timeline pubblicata (anche solo note interne più template email per i clienti).
Gestione della configurazione specifica per tenant
Tratta la configurazione per tenant come superficie di prodotto: necessita validazione, valori di default e cronologia delle modifiche.
Conserva la configurazione separata dal codice (e idealmente separata dai secret runtime) e supporta una modalità safe fallback quando la config è invalida. Una pagina interna leggera come settings/tenants può risparmiare ore durante la risposta agli incidenti e i rollout graduati.
Come aiutano (e i limiti di) architetture generate dall’IA
Control Noisy Neighbors
Build per-tenant rate limits and queued jobs so noisy neighbors stay contained.
L’IA può accelerare il pensiero architetturale iniziale per un SaaS multi-tenant, ma non sostituisce il giudizio ingegneristico, i test o la revisione di sicurezza. Trattala come un partner di brainstorming che produce bozze — poi verifica ogni assunzione.
Cosa dovrebbero (e non dovrebbero) fare le architetture generate dall’IA
L’IA è utile per generare opzioni e evidenziare modalità di fallimento tipiche (dove il contesto tenant può perdersi, o dove le risorse condivise possono creare sorprese). Non dovrebbe decidere il tuo modello, garantire compliance o validare le prestazioni. Non può vedere il tuo traffico reale, la forza del tuo team o i casi limite nascosti nelle integrazioni legacy.
Input importanti: requisiti, vincoli, rischi, crescita
La qualità dell’output dipende da ciò che gli fornisci. Input utili includono:
- Numero di tenant oggi vs tra 12–24 mesi e volume dati previsto per tenant
- Requisiti di isolamento (contrattuali, normativi, aspettative cliente)
- Budget e capacità operative (maturità on-call, supporto SRE, tooling)
- Target di latenza, pattern di picco e burst per tenant
- Tolleranza al rischio: cosa accade se un tenant impatta un altro?
Usare l’IA per proporre opzioni di pattern con i trade-off
Chiedi 2–4 design candidati (es.: database-per-tenant vs schema-per-tenant vs isolamento a livello di riga) e richiedi una tabella chiara di trade-off: costo, complessità operativa, blast radius, sforzo di migrazione e limiti di scala. L’IA è brava a elencare i problemi comuni che puoi trasformare in domande di design per il team.
Se vuoi passare da “bozza architetturale” a prototipo funzionante più in fretta, una piattaforma vibe-coding come Koder.ai può aiutarti a trasformare quelle scelte in uno scheletro d’app reale via chat — spesso con frontend React e backend Go + PostgreSQL — così puoi validare la propagazione del contesto tenant, i rate limit e i workflow di migrazione prima.
Usare l’IA per generare threat model e checklist
L’IA può redigere un threat model semplice: punti di ingresso, confini di fiducia, propagazione del contesto tenant e errori comuni (es. controlli di autorizzazione mancanti sui job in background). Usala per generare checklist di revisione per PR e runbook — ma convalida con esperti di sicurezza reali e la storia degli incidenti del tuo team.
Una checklist pratica per il tuo team
Scegliere un approccio multi-tenant è meno “best practice” e più adattamento: sensibilità dei dati, tasso di crescita e quanto complessità operativa puoi sostenere.
Checklist passo-passo (usala in un workshop di 30 minuti)
-
Dati: quali dati sono condivisi tra tenant (se ce ne sono)? Cosa non deve mai essere co-locato?
-
Identità: dove vive l’identità tenant (link d’invito, domini, claim SSO)? Come si stabilisce il contesto tenant su ogni richiesta?
-
Isolamento: decidi il livello di isolamento di default (riga/schema/database) e identifica le eccezioni (es. clienti enterprise che richiedono separazioni più forti).
-
Scalabilità: identifica la prima pressione di scala che ti aspetti (storage, traffico di lettura, job in background, analytics) e scegli il pattern più semplice che la affronta.
Domande da convalidare con ingegneri e reviewer di sicurezza
- Come preveniamo accessi cross-tenant se uno sviluppatore dimentica un filtro?
- Qual è la nostra storia di audit per tenant (chi ha fatto cosa, quando)?
- Come gestiamo cancellazione e retention dei dati per tenant?
- Qual è il blast radius di una migrazione sbagliata o di una query runaway?
- Possiamo throttlare, rate-limitare e budgettare risorse per tenant?
Segnali di allarme che richiedono lavoro di design più profondo
- “Aggiungeremo i controlli tenant dopo.”
- Strumenti admin condivisi che possono vedere tutto senza controlli stringenti.
- Nessun piano per backup/restore per singolo tenant o risposta agli incidenti.
- Una singola coda/pool worker senza fairness per tenant.
Esempio di “prossima azione raccomandata”
Raccomandazione: Inizia con isolamento a livello di riga + enforcement rigoroso del contesto tenant, aggiungi throttling per tenant e definisci un percorso di upgrade a schema/database per i tenant ad alto rischio.
Prossime azioni (2 settimane): threat-model dei confini tenant, prototipa l’enforcement in un endpoint e fai una prova di migrazione su una copia di staging. Per linee guida sul rollout, vedi blog/tenant-release-strategies.