Definisci obiettivi, audience e criteri di successo
Prima di costruire qualsiasi cosa, mettetevi d'accordo su cosa significhi veramente “adozione” nella vostra organizzazione. Gli strumenti interni non si “vendono” da soli: l'adozione è di solito una combinazione di accesso, comportamento e abitudine.
Definite “adozione” in termini semplici
Scegliete un piccolo set di definizioni che tutti possano ripetere:
- Activation: il primo momento significativo di valore. Esempio: “Inviata la prima richiesta”, “Eseguito il primo report” o “Completata la checklist di onboarding”.
- Usage: attività ricorrente che indica che lo strumento viene usato per lavoro reale (non solo login). Esempio: “Creato un ticket”, “Approvato un acquisto”, “Pubblicata una dashboard”.
- Retention: uso continuativo nel tempo. Esempio: “Attivo in 3 delle ultime 4 settimane” per strumenti settimanali, o “Usato almeno una volta al mese” per workflow mensili.
Annotatele e trattatele come requisiti di prodotto, non come curiosità analitiche.
Decidete quali decisioni l'app deve supportare
Un'app di tracking è utile solo se cambia ciò che fate dopo. Elencate le decisioni che volete rendere più rapide o meno dibattute, come:
- Dove concentrare il training (quali team faticano dopo l'activation)
- Cosa prioritizzare nella roadmap (feature usate vs evitate)
- Se modificare gli accessi (chi ha bisogno dello strumento, chi no, chi necessita di diritti admin)
- Quando investire nel supporto (picchi di errori, retry ripetuti, workflow in stallo)
Se una metrica non guida una decisione, è opzionale per l'MVP.
Identificate stakeholder e le loro domande
Siate espliciti su audience e cosa ciascuna richiede:
- IT / Security: chi ha accesso a cosa e quando; segnali di audit conformi
- Ops / Enablement: dove le persone si bloccano; quali team necessitano coaching
- Owner degli strumenti: adozione delle feature, abbandoni e cicli di feedback
- Manager: progresso a livello di team senza esporre performance individuale
- Utenti finali: trasparenza su ciò che viene tracciato e perché
Definite criteri di successo e una timeline MVP
Definite criteri di successo per l'app di tracking stessa (non per lo strumento tracciato), per esempio:
- Il 90%+ dei workflow target emette gli eventi richiesti
- Un report settimanale di adozione viene generato automaticamente ed è ritenuto affidabile dagli stakeholder
- Le domande chiave possono essere risposte in meno di 2 minuti
Impostate una timeline semplice: Settimana 1 definizioni + stakeholder, Settimane 2–3 strumentazione MVP + dashboard di base, Settimana 4 revisione, correzione gap e pubblicazione di una cadenza ripetibile.
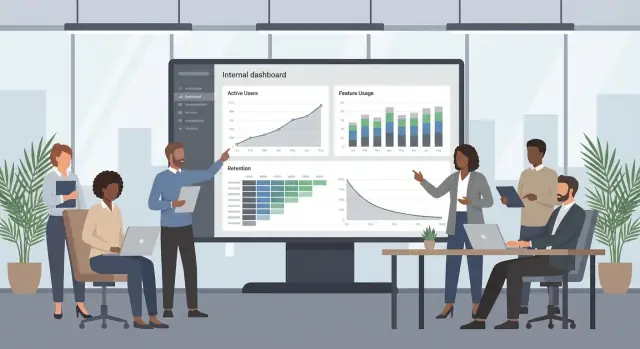
Scegliete metriche di adozione che aiutino davvero
L'analytics per strumenti interni funziona solo quando i numeri rispondono a una decisione. Se tracciate tutto, affogherete nei grafici senza sapere cosa correggere. Partite con un piccolo set di metriche di adozione che mappino agli obiettivi del rollout, poi aggiungete engagement e segmentazione.
Iniziate con quattro metriche core di adozione
Activated users: il conteggio (o %) di persone che hanno completato il minimo setup necessario per ottenere valore. Per esempio: autenticazione via SSO e completamento del primo workflow.
WAU/MAU: weekly active users vs monthly active users. Indica rapidamente se l'uso è abituale o occasionale.
Retention: quanti nuovi utenti continuano a usare lo strumento dopo la prima settimana o mese. Definite la coorte (es. “ha usato lo strumento per la prima volta in ottobre”) e una regola chiara per “attivo”.
Time-to-first-value (TTFV): quanto tempo impiega un nuovo utente a raggiungere il primo risultato significativo. TTFV più breve di solito correla con migliore adozione a lungo termine.
Aggiungete metriche di engagement che indirizzino cambi prodotto
Dopo le metriche core, aggiungete un piccolo set di misure di engagement:
- Feature usage: quali funzionalità chiave vengono usate e da chi (non ogni click—solo le azioni che contano).
- Task completion: tasso di successo per i job principali dello strumento (es. “richiesta inviata”, “fattura approvata”).
- Frequency and depth: numero di sessioni per settimana e quante azioni significative avvengono per sessione.
Segmentate senza creare trappole di privacy o interpretazione
Suddividete le metriche per reparto, ruolo, sede o team, ma evitate tagli eccessivamente granulari che favoriscano il “scoreboarding” di individui o gruppi minuscoli. L'obiettivo è trovare dove serve enablement, formazione o redesign del workflow—not microgestire.
Definite “adozione sana” e alert
Scrivete soglie come:
- WAU/MAU ≥ 0.55 per i team target
- Retention ≥ 60% alla settimana 4
- TTFV ≤ 2 giorni
Aggiungete alert per cali bruschi (es. “uso feature X -30% settimana su settimana”) così potete indagare rapidamente—problemi di rilascio, permessi o cambi di processo spesso emergono qui per primi.
Mappate i journey utente e create una tassonomia di eventi
Prima di aggiungere codice di tracking, chiarite cosa significa “adozione” nel lavoro quotidiano. Gli strumenti interni spesso hanno meno utenti rispetto alle app clienti, quindi ogni evento deve meritare il suo posto: deve spiegare se lo strumento aiuta a completare compiti reali.
Documentate i journey che contano
Partite con 2–4 workflow comuni e scriveteli come brevi journey passo-passo. Per esempio:
- Get started: apri lo strumento → effettua il login → arrivi nella home → completi il primo setup richiesto
- Core task: crea → modifica → invia → approva/rifiuta
- Output: esporta → condividi link → invia a un altro sistema
Per ogni journey, segnate i momenti che vi interessano: primo successo, passaggi di consegna (es. invia → approva) e colli di bottiglia (es. errori di validazione).
Decidete cosa catturare: eventi, page view o log backend
Usate eventi per azioni significative (crea, approva, esporta) e per cambi di stato che definiscono il progresso.
Usate page view con parsimonia—utili per capire navigazione e drop-off, ma rumorose se usate come proxy di usage.
Usate backend logs quando serve affidabilità o copertura attraverso client diversi (es. approvazioni via API, job schedulati, import bulk). Un pattern pratico è: tracciare il click UI come evento e tracciare il completamento reale nel backend.
Create una convenzione di naming e proprietà richieste
Scegliete uno stile coerente e mantenetelo (es. verb_noun: create_request, approve_request, export_report). Definite proprietà obbligatorie così gli eventi restano utilizzabili tra i team:
user_id (identificatore stabile)tool_id (quale strumento interno)feature (raggruppamento opzionale, es. approvals)timestamp (UTC)
Aggiungete contesto utile quando è sicuro: org_unit, role, request_type, success/error_code.
Pianificate il versioning
Gli strumenti cambiano. La vostra tassonomia dovrebbe tollerare questo senza rompere le dashboard:
- Aggiungete
schema_version (o event_version) nei payload.
- Deprecatate eventi invece di riutilizzare silenziosamente nomi con significati nuovi.
- Tenete un changelog semplice così gli analisti sanno quando le definizioni sono cambiate.
Progettate il modello dati e gli identificatori
Un modello dati chiaro previene futuri mal di testa di reporting. L'obiettivo è rendere ogni evento univoco: chi ha fatto cosa in quale strumento, e quando, mantenendo il sistema facile da gestire.
Tabelle core per partire
La maggior parte delle app di tracking per adozione interna può partire con poche tabelle:
- users: record utente stabile, più riferimenti alla vostra fonte di identità
- teams/departments: la struttura organizzativa per i report
- tools: gli strumenti interni che misurate (nome, owner, stato)
- sessions (opzionale): utile per “active users” e analisi basate sul tempo
- events: il registro di attività (il cuore dell'analytics)
- permissions/roles: cosa un utente può vedere e amministrare dentro la vostra app di tracking
Mantenete la tabella events coerente: event_name, timestamp, user_id, tool_id e un piccolo campo JSON/properties per dettagli su cui filtrare (es. feature, page, workflow_step).
Identificatori: rendeteli stabili e noiosi
Usate ID interni stabili che non cambiano quando qualcuno aggiorna email o nome:
- user_id: UUID dell'app, mappato a un IdP immutabile (es.
idp_subject)
- tool_id: UUID per ogni tool (non usare il nome dello strumento come chiave)
- anonymous_id (opzionale): solo se servite davvero tracking pre-login; altrimenti evitatelo per app interne
Definite per quanto tempo conservate gli eventi raw (es. 13 mesi) e pianificate tabelle rollup giornaliere/settimanali (tool × team × date) così le dashboard restano veloci.
Proprietà dei dati e sorgenti
Documentate da dove provengono i campi:
- HRIS/IdP: reparto, manager, stato di impiego, identità canonica
- La vostra app: metadata strumenti, owner, permessi dentro l'app di tracking
Questo evita “campi misteriosi” e chiarisce chi può correggere dati errati.
Instrumentazione della raccolta dati (Front End e Back End)
L'instrumentazione è dove il tracking diventa reale: traducete l'attività utente in eventi affidabili. La decisione chiave è dove gli eventi vengono generati—client, server o entrambi—e come rendere quei dati abbastanza affidabili da fidarsene.
Scegliete i metodi di tracciamento giusti
La maggior parte degli strumenti interni beneficia di un approccio ibrido:
- Client-side SDK events catturano interazioni UI (click, page view, cambi filtro) e il contesto utente al momento dell'azione.
- Server-side events catturano azioni autorevoli (record creato, approvazione inviata, esportazione generata) anche se l'interfaccia cambia.
- Entrambi spesso sono l'ideale: la UI può registrare “attempted”, mentre il server registra “completed”, aiutandovi a individuare attriti.
Limitate il tracciamento client-side: non registrate ogni battitura. Concentratevi sui momenti che indicano progresso nel workflow.
Rendete la consegna affidabile (retry + batching)
I problemi di rete e i limiti del browser accadono. Aggiungete:
- Batching per inviare più eventi in una singola richiesta (meno overhead, meno fallimenti).
- Retry con backoff per richieste fallite, con un limite ragionevole per evitare loop infiniti.
- Una piccola coda locale (es. in memoria o localStorage) così gli eventi non si perdono se una tab viene chiusa.
Sul server, trattate l'ingest analytics come non-bloccante: se il logging fallisce, l'azione di business deve comunque riuscire.
Validate i payload per mantenere i dati puliti
Implementate controlli di schema in ingest (e idealmente nella libreria client). Validate campi obbligatori (event name, timestamp, actor ID, org/team ID), tipi di dato e valori ammessi. Rifiutate o mettete in quarantena eventi malformati così non inquinano silenziosamente le dashboard.
Separate gli ambienti così i dati di test non si mescolano
Includete sempre tag di environment come env=prod|stage|dev e filtrate i report di conseguenza. Questo evita che QA, demo o test degli sviluppatori gonfino le metriche di adozione.
Se serve una regola semplice: partite con eventi server-side per le azioni core, poi aggiungete eventi client-side solo dove serve più dettaglio su intenti e attriti UI.
Aggiungere autenticazione, ruoli e controllo accessi
Se le persone non si fidano di come i dati di adozione sono accessibili, non useranno il sistema—o eviteranno il tracciamento. Trattate auth e permessi come funzionalità di prima classe, non come pensiero successivo.
Preferite SSO ed evitate password
Usate l'identity provider aziendale così gli accessi corrispondono a come i dipendenti si autenticano già.
- Implementate SSO via OIDC (comune con Okta, Azure AD) o SAML quando necessario.
- Minimize la gestione delle password: idealmente non archiviate password. Se dovete, usate una libreria auth consolidata e hashing forte, ma predefinite lo SSO.
Definite ruoli e accesso scope-based
Un modello di ruoli semplice copre la maggior parte dei casi interni:
- Admin: gestisce impostazioni org-wide, connessioni identity e permessi globali.
- Tool owner: gestisce le impostazioni di tracking, dashboard e alert per uno specifico tool.
- Manager: può vedere l'adozione per la propria unità/team (serve una mappatura team).
- Viewer: accesso in sola lettura alle dashboard approvate.
Rendete l'accesso scope-based (per tool, dipartimento, team o sede) così “tool owner” non significa automaticamente “vedere tutto”. Limitate anche le esportazioni—i leak di dati spesso avvengono tramite CSV.
Audit log e default sicuri
Aggiungete audit log per:
- cambi di permessi/ruoli
- modifiche alle impostazioni di tracking (mappature eventi, filtri)
- cambiamenti nella condivisione delle dashboard
- esportazioni di dati e creazione token API
Documentate default di least-privilege (es. nuovi utenti partono come Viewer) e un flusso di approvazione per Admin—riduce sorprese e rende le review semplici.
Nota: per la richiesta di accesso, inserite una pagina o un form di richiesta interno dedicato come parte del processo di gestione degli accessi (documentazione interna o pagina di richiesta accesso).
Affrontare privacy, compliance e fiducia
Tracciare l'adozione di strumenti interni coinvolge dati dei dipendenti: la privacy non può essere un ripensamento. Se le persone si sentono monitorate, resisteranno allo strumento—e i dati saranno meno affidabili. Trattate la fiducia come un requisito di prodotto.
Stabilite regole chiare su cosa tracciate
Iniziate definendo eventi “sicuri”. Tracciate azioni e risultati, non i contenuti che gli impiegati digitano.
- Preferite eventi come
report_exported, ticket_closed, approval_submitted.
- Evitate campi di testo, corpi di messaggi, note libere, query di ricerca, allegati e qualsiasi cosa possa contenere dati personali.
- Non registrate URL completi se possono contenere ID o parametri sensibili; memorizzate un template di route (per esempio,
/orders/:id).
Documentate queste regole e includetele nella checklist di strumentazione così le nuove feature non introducono accidentalmente capture sensibili.
Allineate con policy interne (e legge)
Collaborate con HR, Legal e Security precocemente. Decidete lo scopo del tracking (es. bisogni di formazione, colli di bottiglia) e proibite usi specifici (es. valutazione delle performance senza processo separato). Documentate:
- Retention dei dati (per quanto tempo si conservano gli eventi raw)
- Chi può accedere alle viste a livello di dipendente e con quali approvazioni
- Dove i dati sono archiviati e se escono dalla vostra regione
Anonimizzate e aggregate di default
La maggior parte degli stakeholder non ha bisogno di dati a livello persona. Fornite aggregazioni per team/org come vista predefinita e consentite drill-down identificabili solo a pochi amministratori.
Usate soglie di soppressione per gruppi piccoli così non esponete comportamenti di gruppi ristretti (es. nascondere breakdown con dimensione \u003c 5). Questo riduce anche il rischio di re-identification combinando filtri.
Siate trasparenti: avvisi + FAQ interne
Aggiungere una breve nota nell'app (e nell'onboarding) che spiega cosa viene raccolto e perché. Mantenete una FAQ interna viva che includa esempi di dati tracciati vs non tracciati, timeline di retention e come sollevare preoccupazioni. Collegate questa FAQ dalla dashboard e dalla pagina delle impostazioni come parte della documentazione interna.