30 ago 2025·8 min
Nginx vs HAProxy: scegliere il reverse proxy giusto
Confronta Nginx e HAProxy come reverse proxy: prestazioni, bilanciamento, TLS, osservabilità, sicurezza e setup comuni per scegliere la soluzione migliore.
Confronta Nginx e HAProxy come reverse proxy: prestazioni, bilanciamento, TLS, osservabilità, sicurezza e setup comuni per scegliere la soluzione migliore.
Un reverse proxy è un server che si pone davanti alle tue applicazioni e riceve prima le richieste dei client. Inoltra ogni richiesta al servizio backend corretto (i tuoi server applicativi) e restituisce la risposta al client. Gli utenti parlano con il proxy; il proxy parla con le tue app.
Un forward proxy funziona al contrario: si trova davanti ai client (per esempio dentro una rete aziendale) e inoltra le loro richieste in uscita verso Internet. Serve principalmente per controllare, filtrare o nascondere il traffico dei client.
Un load balancer viene spesso implementato come un reverse proxy, ma con un focus specifico: distribuire il traffico su più istanze backend. Molti prodotti (inclusi Nginx e HAProxy) fanno sia reverse proxying sia load balancing, quindi i termini a volte si sovrappongono.
La maggior parte delle implementazioni parte per uno o più di questi motivi:
/api a un servizio API, / a un'app web).I reverse proxy solitamente fronteggiano siti web, API e microservizi — sia al bordo (internet pubblico) sia internamente tra servizi. Negli stack moderni, vengono usati anche come componenti per ingress gateway, deploy blue/green e configurazioni ad alta disponibilità.
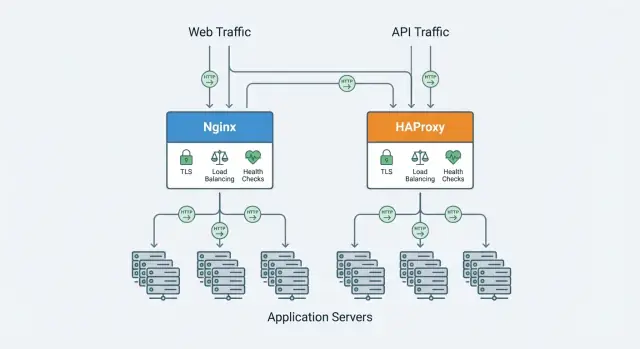
Nginx e HAProxy si sovrappongono, ma hanno enfasi diverse. Nelle sezioni successive confronteremo fattori decisionali come prestazioni sotto molte connessioni, bilanciamento del carico e controlli di integrità, supporto dei protocolli (HTTP/2, TCP), funzionalità TLS, osservabilità e configurazione/operazioni quotidiane.
Nginx è ampiamente usato sia come web server sia come reverse proxy. Molte squadre lo adottano inizialmente per servire un sito pubblico e poi ne espandono il ruolo per stare davanti ai server applicativi — gestendo TLS, instradamento del traffico e attenuando i picchi.
Nginx eccelle quando il tuo traffico è soprattutto HTTP(S) e vuoi una singola “porta d'ingresso” che faccia un po' di tutto. È particolarmente forte nel:
X-Forwarded-For, header di sicurezza)Poiché può sia servire contenuti sia fungere da proxy, Nginx è una scelta comune per ambienti small-to-medium dove si vogliono meno componenti.
Capacità popolari includono:
Nginx è spesso scelto quando hai bisogno di un punto d'ingresso per:
Se la tua priorità è una gestione ricca dell’HTTP e ti piace l'idea di unire web serving e reverse proxying, Nginx è frequentemente il punto di partenza.
HAProxy (High Availability Proxy) è comunemente usato come reverse proxy e load balancer che sta davanti a uno o più server applicativi. Accetta traffico in ingresso, applica regole di routing e inoltra le richieste a backend sani — spesso mantenendo tempi di risposta stabili sotto alta concorrenza.
I team tipicamente impiegano HAProxy per la gestione del traffico: distribuire richieste su più server, mantenere servizi disponibili durante i guasti e ammortizzare i picchi di traffico. È una scelta frequente sia al “bordo” del servizio (traffico north–south) sia tra servizi interni (east–west), specialmente quando serve comportamento prevedibile e forte controllo sulla gestione delle connessioni.
HAProxy è noto per la gestione efficiente di grandi numeri di connessioni concorrenti. Questo conta quando hai molti client connessi contemporaneamente (API trafficate, connessioni long-lived, microservizi chatty) e vuoi che il proxy rimanga reattivo.
Le capacità di bilanciamento del carico sono una ragione chiave per sceglierlo. Oltre al round-robin, supporta più algoritmi e strategie di routing che aiutano a:
I controlli di integrità sono un altro punto forte. HAProxy può verificare attivamente lo stato dei backend e rimuovere automaticamente istanze non sane dalla rotazione, per poi reinserirle quando si ripristinano. Questo riduce downtime e impedisce che deploy parzialmente guasti impattino tutti gli utenti.
HAProxy può operare sia a Layer 4 (TCP) sia a Layer 7 (HTTP).
La differenza pratica: L4 è generalmente più semplice e molto veloce per il forwarding TCP, mentre L7 offre routing più ricco quando serve logica per le richieste.
HAProxy è spesso scelto quando l'obiettivo principale è bilanciamento del carico affidabile e ad alte prestazioni con controlli di integrità robusti — per esempio distribuire traffico API su più server, gestire failover tra zone di disponibilità, o fronteggiare servizi dove il volume di connessioni e il comportamento prevedibile del traffico contano più delle funzionalità di web server.
Le comparazioni delle prestazioni spesso sbagliano perché si guarda un singolo numero (es. “max RPS”) senza considerare cosa percepisce l'utente.
Un proxy può aumentare il throughput ma peggiorare la tail latency se mette in coda troppo lavoro sotto carico.
Pensa alla “forma” della tua applicazione:
Se fai benchmark con un pattern e ne produci un altro in produzione, i risultati non si trasferiranno.
Il buffering può aiutare quando i client sono lenti o bursty, perché il proxy può leggere la richiesta completa (o la risposta) e fornire al backend un ritmo più regolare.
Il buffering può danneggiare quando l'app beneficia dello streaming (server-sent events, grandi download, API realtime). Il buffering aggiuntivo aumenta la pressione sulla memoria e può peggiorare la tail latency.
Misura più che il “max RPS”:
Se il p95 sale rapidamente prima che appaiano errori, stai vedendo segnali di saturazione — non spazio libero.
Sia Nginx sia HAProxy possono stare davanti a più istanze applicative e distribuire il traffico, ma differiscono nella profondità delle funzionalità out-of-the-box.
Round-robin è la scelta predefinita quando i backend sono simili (stesse CPU/memoria, stesso costo per richiesta). È semplice, prevedibile e funziona bene per app stateless.
Least connections è utile quando la durata delle richieste varia (download di file, chiamate API lunghe, WebSocket). Favorisce i backend con meno richieste attive.
Weighted balancing (round-robin ponderato, o least-connections ponderato) è pratico quando i server non sono identici — mix di nodi vecchi e nuovi, dimensioni diverse, o migrazioni graduali.
In generale, HAProxy offre più scelte di algoritmi e controllo fine a Layer 4/7, mentre Nginx copre i casi comuni in modo pulito (e può essere esteso a seconda dell'edizione/moduli).
La stickiness mantiene un utente instradato allo stesso backend su più richieste.
Usa la persistenza solo quando necessario (sessioni server-side legacy). Le app stateless scalano e si ripristinano meglio senza di essa.
Health check attivi sondano periodicamente i backend (endpoint HTTP, connessione TCP, status atteso). Scoprono i guasti anche quando il traffico è basso.
Health check passivi reagiscono al traffico reale: timeout, errori di connessione o risposte errate marcano un server come non sano. Sono leggeri ma possono impiegare più tempo a rilevare problemi.
HAProxy è noto per controlli di integrità ricchi e controlli di failure (soglie, rise/fall, check dettagliati). Nginx supporta controlli solidi, con capacità che dipendono dalla build e dall'edizione.
Per i deploy rolling, cerca:
In entrambi i casi, abbina il draining a timeout brevi e endpoint “ready/unready” chiari in modo che il traffico si sposti senza scossoni durante i deploy.
I reverse proxy stanno al bordo del sistema, quindi le scelte di protocollo e TLS influenzano tutto, dalle prestazioni browser a come i servizi comunicano tra loro.
Sia Nginx che HAProxy possono “terminare” TLS: accettano connessioni cifrate dai client, decriptano il traffico e inoltrano richieste agli upstream via HTTP o TLS ri-cifrato.
La realtà operativa è la gestione dei certificati. Serve un piano per:
Nginx è spesso scelto quando la terminazione TLS è affiancata a funzionalità da web server (file statici, redirect). HAProxy è spesso scelto quando TLS fa parte principalmente di un layer di gestione del traffico.
HTTP/2 può ridurre i tempi di caricamento per i browser multiplexando più richieste su una sola connessione. Entrambi gli strumenti supportano HTTP/2 sul lato client.
Considerazioni chiave:
Se devi instradare traffico non HTTP (database, SMTP, Redis, protocolli custom), serve il proxy TCP invece del routing HTTP. HAProxy è ampiamente usato per il bilanciamento TCP ad alte prestazioni con controlli fini sulle connessioni. Nginx può proxyare TCP (tramite le sue capacità stream), sufficiente per setup di pass-through semplici.
mTLS verifica entrambe le parti: i client presentano certificati, non solo i server. È utile per comunicazioni servizio-servizio, integrazioni con partner o design zero-trust. Entrambi i proxy possono imporre la validazione del client certificate al bordo, e molti team usano mTLS anche internamente tra proxy e upstream per ridurre l'assunzione di “rete fidata”.
I reverse proxy stanno nel mezzo di ogni richiesta, quindi sono spesso il posto migliore per rispondere a “cosa è successo?”. Buona osservabilità significa log coerenti, un set ridotto di metriche ad alto segnale e un modo ripetibile per debug di timeout ed errori gateway.
Al minimo, tieni access log e error log attivi in produzione. Per gli access log, includi i timing upstream per capire se la lentezza è del proxy o dell'app.
In Nginx, campi comuni sono request time e upstream timing (es. $request_time, $upstream_response_time, $upstream_status). In HAProxy, abilita la modalità HTTP log e cattura i campi di timing (queue/connect/response) per separare “attesa per uno slot backend” da “backend lento”.
Mantieni i log strutturati (JSON se possibile) e aggiungi un request ID (da un header in ingresso o generato) per correlare log del proxy con quelli dell'app.
Che tu usi Prometheus o altro, esporta un set coerente:
Nginx spesso usa lo stub status endpoint o un exporter Prometheus; HAProxy ha un endpoint stats integrato che molti exporter leggono.
Esponi un leggero /health (processo attivo) e /ready (può raggiungere dipendenze). Usali in automazioni: health check del load balancer, deploy e decisioni di auto-scaling.
Quando fai troubleshooting, confronta i timing del proxy (connect/queue) con il tempo di risposta upstream. Se connect/queue è alto, aggiungi capacità o regola il bilanciamento; se upstream è lento, concentrati su applicazione e database.
Gestire un reverse proxy non è solo picchi: conta anche quanto velocemente il team può fare cambi sicuri alle 14:00 (o alle 2:00 di notte).
La configurazione di Nginx è basata su direttive e gerarchica. Si legge come “blocchi dentro blocchi” (http → server → location), e per molti è intuitiva quando si pensa a siti e rotte.
La configurazione di HAProxy è più “a pipeline”: definisci frontends (cosa accetti), backends (dove invii il traffico) e poi attacchi regole (ACL) per collegarli. Può risultare più esplicita e prevedibile una volta interiorizzato il modello, specialmente per la logica di routing.
Nginx tipicamente ricarica la config avviando nuovi worker e facendo il draining di quelli vecchi. Questo è comodo per aggiornamenti frequenti di route e rinnovi di certificati.
HAProxy può fare reload senza interruzioni, ma i team spesso lo trattano come un “appliance”: controllo delle modifiche più restrittivo, config versionata e coordinazione attenta del comando di reload.
Entrambi supportano test di configurazione prima del reload (obbligatorio per CI/CD). In pratica, probabilmente terrai le config DRY generandole:
L'abitudine operativa chiave: tratta la config del proxy come codice — revisionata, testata e distribuita come il software applicativo.
Con la crescita dei servizi, lo sprawl di certificati e routing diventa il vero problema. Pianifica per:
Se prevedi centinaia di host, considera la centralizzazione dei pattern e la generazione di config da metadata dei servizi invece di modificare file a mano.
Se costruisci e iteri su più servizi, un reverse proxy è solo una parte della delivery pipeline — hai comunque bisogno di scaffolding ripetibile per le app, parity tra ambienti e rollout sicuri.
Koder.ai può aiutare i team a muoversi più velocemente dall'idea al servizio in esecuzione generando React frontend, backend Go + PostgreSQL e app Flutter tramite workflow in chat, quindi supportando export del codice, deploy/hosting, domini custom e snapshot con rollback. In pratica, puoi prototipare un'API + frontend, deployare e poi decidere se Nginx o HAProxy è la porta giusta basandoti su pattern di traffico reali invece che su ipotesi.
La sicurezza raramente è una singola “feature magica” — è ridurre il raggio d'azione e stringere i default attorno a traffico che non controlli completamente.
Esegui il proxy con il minimo privilegio necessario: bind a porte privilegiate tramite capabilities (Linux) o un servizio frontale, e mantieni i processi worker non privilegiati. Proteggi config e materiali chiave (chiavi private TLS, param DH) in sola lettura per l'account di servizio.
A livello di rete, permetti inbound solo dalle sorgenti attese (internet → proxy; proxy → backend). Nega l'accesso diretto ai backend quando possibile, così il proxy è il punto di controllo per autenticazione, rate limit e logging.
Nginx ha primitive di prima classe come limit_req / limit_conn. HAProxy usa tipicamente stick tables per tracciare tassi di richiesta, connessioni concorrenti o pattern di errore e quindi negare, tarpare o rallentare client abusivi.
Scegli un approccio che corrisponda al tuo modello di minaccia:
Sii esplicito su quali header ti fidi. Accetta X-Forwarded-For (e simili) solo da upstream noti; altrimenti gli attaccanti possono spoofare l'IP cliente e bypassare controlli basati su IP. Allo stesso modo, valida o imposta Host per prevenire attacchi host-header e cache poisoning.
Una regola pratica: il proxy dovrebbe impostare gli header di forwarding, non passarli ciecamente.
Il request smuggling sfrutta parsing ambigui (Content-Length vs Transfer-Encoding, spazi strani, header non validi). Preferisci modalità di parsing HTTP severe, rifiuta header malformati e imposta limiti conservativi:
Connection, Upgrade e hop-by-hop headersQuesti controlli differiscono nella sintassi tra Nginx e HAProxy, ma l'outcome deve essere lo stesso: fallire chiuso su ambiguità e mantenere limiti espliciti.
I reverse proxy vengono introdotti in due modi: come front door dedicato per una singola app, o come gateway condiviso davanti a molti servizi. Entrambi possono essere fatti con Nginx o HAProxy — conta quanto routing vuoi al bordo e come vuoi operarlo giorno per giorno.
Questo pattern mette un reverse proxy direttamente davanti a un'app web singola (o un piccolo set di servizi correlati). È ideale quando serve principalmente terminazione TLS, HTTP/2, compressione, caching (con Nginx) o separazione netta tra Internet pubblico e app privata.
Usalo quando:
Qui, uno (o un piccolo cluster) di proxy instrada il traffico a più applicazioni in base a hostname, path, header o altre proprietà. Riduce i punti d'ingresso pubblici ma aumenta l'importanza della gestione delle configurazioni e del controllo delle modifiche.
Usalo quando:
app1.example.com, app2.example.com) e vuoi un unico layer di ingressI proxy possono dividere il traffico tra versione “vecchia” e “nuova” senza cambiare DNS o codice app. Un approccio comune è definire due pool upstream (blue e green) o due backend (v1 e v2) e spostare il traffico gradualmente.
Usi tipici:
Questo è utile quando il tuo tooling di deploy non può fare rollout ponderati o quando vuoi un meccanismo di rollout coerente tra team.
Un singolo proxy è un singolo punto di failure. Pattern HA comuni includono:
Scegli in base all'ambiente: VRRP è popolare su VM/metal; LB gestiti sono semplici in cloud.
Una catena tipica è: CDN (opzionale) → WAF (opzionale) → reverse proxy → applicazione.
Se già usi CDN/WAF, mantieni il proxy focalizzato su delivery e routing applicativo piuttosto che farne l'unico layer di sicurezza.
Kubernetes cambia come “fai fronte” alle applicazioni: i servizi sono effimeri, gli IP cambiano e le decisioni di routing spesso avvengono al bordo del cluster tramite un Ingress controller. Sia Nginx sia HAProxy si adattano bene, ma brillano in ruoli leggermente diversi.
Nella pratica, la decisione raramente è “migliore in assoluto”, ma piuttosto “cosa si adatta al tuo pattern di traffico e a quanto manipoli l’HTTP al bordo”.
Se esegui un service mesh (es. mTLS e policy di traffico interne), puoi comunque mantenere Nginx/HAProxy al perimetro per il traffico north–south (internet → cluster). La mesh gestisce il traffico east–west. Questa divisione separa le preoccupazioni edge (terminazione TLS, WAF/rate limiting, routing) dalle feature interne di affidabilità come retry e circuit breaking.
gRPC e connessioni persistenti stressano i proxy diversamente rispetto a richieste HTTP brevi. Occhio a:
Qualunque scelta, testa con durate realistiche (minuti/ore), non solo con test rapidi.
Tratta la config del proxy come codice: mettila in Git, valida le modifiche in CI (lint, config test) e rolla tramite CD con deploy controllati (canary o blue/green). Questo rende gli upgrade più sicuri e dà una traccia audit quando una modifica impatta la produzione.
Il modo più rapido per decidere è partire da cosa ti aspetti che il proxy faccia quotidianamente: servire contenuti, modellare traffico HTTP o gestire strettamente connessioni e logica di bilanciamento.
Se il tuo reverse proxy è anche una “porta” per il web, Nginx è spesso il default più comodo.
Se la priorità è distribuzione precisa del traffico e controllo sotto carico, HAProxy tende a emergere.
Usare entrambi è comune quando vuoi comodità da web server e bilanciamento specializzato:
Questa separazione può anche aiutare a dividere responsabilità: questioni web vs ingegneria del traffico.
Chiediti:
A reverse proxy sits in front of your applications: clients connect to the proxy, and the proxy forwards requests to the correct backend service and returns the response.
A forward proxy sits in front of clients and controls outbound internet access (common in corporate networks).
A load balancer focuses on distributing traffic across multiple backend instances. Many load balancers are implemented as reverse proxies, which is why the terms overlap.
In practice, you’ll often use one tool (like Nginx or HAProxy) to do both: reverse proxying + load balancing.
Put it at the boundary where you want a single control point:
The key is to avoid letting clients hit backends directly so the proxy remains the choke point for policy and visibility.
TLS termination means the proxy handles HTTPS: it accepts encrypted client connections, decrypts them, and forwards traffic to your upstreams over HTTP or re-encrypted TLS.
Operationally, you must plan for:
Pick Nginx when your proxy is also a web “front door”:
Pick HAProxy when traffic management and predictability under load are the priority:
Use round-robin for similar backends and mostly uniform request cost.
Use least connections when request duration varies (downloads, long API calls, long-lived connections) to avoid overloading slower instances.
Use weighted variants when backends differ (instance sizes, mixed hardware, gradual migrations) so you can shift traffic intentionally.
Stickiness keeps a user routed to the same backend across requests.
Avoid stickiness if you can: stateless services scale, fail over, and roll out more cleanly without it.
Buffering can help by smoothing slow or bursty clients so your app sees steadier traffic.
It can hurt when you need streaming behavior (SSE, WebSockets, large downloads), because extra buffering increases memory pressure and can worsen tail latency.
If your app is stream-oriented, test and tune buffering explicitly rather than relying on defaults.
Start by separating proxy delay from backend delay using logs/metrics.
Common meanings:
Useful signals to compare:
Fixes usually involve adjusting timeouts, increasing backend capacity, or improving health checks/readiness endpoints.