Un Transformer è un modo per aiutare i computer a capire sequenze—cose dove ordine e contesto contano, come frasi, codice o una serie di query di ricerca. Invece di leggere un token alla volta e portarsi dietro una memoria fragile, i Transformer guardano l'intera sequenza e decidono a cosa prestare attenzione quando interpretano ogni parte.
Questo semplice cambio si è rivelato fondamentale. È una delle ragioni principali per cui i moderni modelli linguistici di grandi dimensioni (LLMs) riescono a mantenere il contesto, seguire istruzioni, scrivere paragrafi coerenti e generare codice che fa riferimento a funzioni e variabili viste prima.
Se hai usato una chatbot, una funzione “riassumi questo”, ricerca semantica o un assistente per il codice, hai interagito con sistemi basati su Transformer. Lo stesso schema di base supporta:
- Strumenti di chat e supporto clienti che tracciano ciò che hai detto prima
- Sistemi di ricerca e raccomandazione che abbinano il significato, non solo le parole chiave
- Riassunti che soppesano ciò che è centrale rispetto ai dettagli secondari
- Strumenti per il codice che collegano definizioni, utilizzi e intenzioni attraverso file diversi
Cosa imparerai in questo articolo
Spiegheremo le parti chiave—self-attention, multi-head attention, codifica posizionale e il blocco Transformer di base—and perché questo design scala così bene quando i modelli crescono.
Accenneremo anche a varianti moderne che mantengono l'idea centrale ma la modificano per velocità, costo o finestre di contesto più lunghe.
Cosa aspettarsi (e cosa no)
Questo è un viaggio ad alto livello con spiegazioni in linguaggio semplice e matematica minima. L'obiettivo è costruire un'intuizione: cosa fanno i pezzi, perché funzionano insieme e come questo si traduce in capacità reali di prodotto.
Noam Shazeer è un ricercatore e ingegnere AI noto soprattutto come uno dei co-autori dell'articolo del 2017 “Attention Is All You Need.” Quel paper ha introdotto l'architettura Transformer, che poi è diventata la base per molti moderni LLM. Il lavoro di Shazeer fa parte di uno sforzo di squadra: il Transformer è stato creato da un gruppo di ricercatori di Google, ed è importante riconoscerlo così.
Cosa cambiò nel paper del 2017
Prima del Transformer, molti sistemi NLP si basavano su modelli ricorrenti che processavano il testo passo dopo passo. La proposta del Transformer mostrò che si potevano modellare le sequenze efficacemente senza ricorrenza usando l'attenzione come meccanismo principale per combinare informazioni in una frase.
Questo cambiamento era importante perché rese l'addestramento più facile da parallelizzare (si possono processare molti token contemporaneamente) e aprì la porta a scalare modelli e dataset in modi che divennero rapidamente pratici per prodotti reali.
Dall'idea di ricerca al mattone di prodotto
Il contributo di Shazeer—insieme agli altri autori—non rimase confinato ai benchmark accademici. Il Transformer divenne un modulo riutilizzabile che i team potevano adattare: cambiare componenti, variare le dimensioni, ottimizzarlo per compiti e poi pre-addestrarlo su larga scala.
È così che molti progressi viaggiano: un paper introduce una ricetta pulita e generale; gli ingegneri la perfezionano; le aziende la industrializzano; e alla fine diventa la scelta predefinita per costruire funzionalità linguistiche.
Mantenere il credito preciso
È corretto dire che Shazeer è stato un contributore chiave e co-autore del paper sul Transformer. Non è corretto invece presentarlo come l'unico inventore. L'impatto deriva dal design collettivo—e dai numerosi miglioramenti successivi che la comunità ha costruito su quel blueprint originale.
Cosa c'era prima: RNN, LSTM e i loro limiti
Prima dei Transformer, la maggior parte dei problemi sequenziali (traduzione, parlato, generazione di testo) era dominata da Recurrent Neural Networks (RNN) e successivamente da LSTMs (Long Short-Term Memory). L'idea era semplice: leggere il testo un token alla volta, mantenere una “memoria” corrente (uno stato nascosto) e usare quello stato per predire il token successivo.
Un rapido quadro di come funzionavano
Un RNN elabora una frase come una catena. Ogni passo aggiorna lo stato nascosto basandosi sulla parola corrente e sullo stato precedente. Le LSTM migliorarono questo aggiungendo gate che decidono cosa mantenere, dimenticare o emettere—facilitando la conservazione di segnali utili più a lungo.
Perché le dipendenze a lungo raggio erano difficili
Nella pratica, la memoria sequenziale ha un collo di bottiglia: molte informazioni devono essere compresse in un unico stato man mano che la frase si allunga. Anche con le LSTM, i segnali di parole molto precedenti possono sbiadire o essere sovrascritti.
Questo rendeva difficili da imparare in modo affidabile certe relazioni—come collegare un pronome al sostantivo corretto molte parole prima, o mantenere il filo di un argomento attraverso diverse proposizioni.
Sfide di addestramento e scalabilità
RNN e LSTM sono anche lenti da addestrare perché non possono parallelizzare completamente nel tempo. Puoi batchare su frasi diverse, ma all'interno di una frase, il passo 50 dipende dal passo 49, che dipende dal passo 48 e così via.
Questa computazione passo-passo diventa una limitazione seria quando vuoi modelli più grandi, più dati e sperimentazione più rapida.
La motivazione per un approccio più parallel-friendly
I ricercatori avevano bisogno di un design che potesse mettere in relazione parole tra loro senza dover marciare strettamente da sinistra a destra durante l'addestramento—un modo per modellare direttamente relazioni a lunga distanza e sfruttare meglio l'hardware moderno. Questa pressione ha preparato il terreno per l'approccio “attention-first” introdotto in Attention Is All You Need.
Attenzione, spiegata senza matematica
L'attenzione è il modo del modello di chiedersi: "Quali altre parole dovrei guardare in questo momento per capire questa parola?" Invece di leggere una frase strettamente da sinistra a destra sperando che la memoria regga, l'attenzione permette al modello di sbirciare le parti più rilevanti della frase quando ne ha bisogno.
L'idea di “cerca e recupera”
Un modello mentale utile è un piccolo motore di ricerca che gira dentro la frase.
- Query: ciò che la parola corrente sta cercando (la domanda)
- Keys: ciò che ogni altra parola offre (le etichette sui possibili match)
- Values: l'informazione concreta da estrarre se c'è una corrispondenza (il contenuto)
Quindi il modello forma una query per la posizione corrente, la confronta con le keys di tutte le posizioni e poi recupera una miscela di values.
Punteggi di rilevanza → pesi di attenzione
Quei confronti producono punteggi di rilevanza: segnali grezzi del tipo “quanto è correlato questo?”. Il modello li trasforma poi in pesi di attenzione, che sono proporzioni che sommano a 1.
Se una parola è molto rilevante ottiene una fetta più grande dell'attenzione del modello. Se più parole sono importanti, l'attenzione può distribuirsi tra loro.
Un esempio semplice (pronomi e grammatica)
Prendi: “Maria ha detto a Jenna che lei avrebbe chiamato più tardi.”
Per interpretare lei, il modello dovrebbe guardare indietro a candidati come “Maria” e “Jenna.” L'attenzione assegna un peso maggiore al nome che si adatta meglio al contesto.
Oppure considera: “Le chiavi dell'armadio sono scomparse.” L'attenzione aiuta a collegare “sono” a “chiavi” (il vero soggetto), non a “armadio”, anche se “armadio” è più vicino. Questo è il vantaggio principale: l'attenzione collega il significato su distanze, su richiesta.
Self-attention: il meccanismo centrale
La self-attention è l'idea per cui ogni token in una sequenza può guardare altri token nella stessa sequenza per decidere cosa conta in quel momento. Invece di processare le parole strettamente da sinistra a destra (come facevano i vecchi modelli ricorrenti), il Transformer permette a ogni token di raccogliere indizi da qualsiasi parte dell'input.
Token che fanno attenzione ad altri token
Immagina la frase: “Ho versato l'acqua nella tazza perché era vuota.” La parola “era” dovrebbe collegarsi a “tazza”, non a “acqua.” Con la self-attention, il token per “era” assegna maggiore importanza ai token che aiutano a risolvere il suo significato (“tazza”, “vuota”) e minore importanza a quelli irrilevanti.
Come si costruisce il contesto
Dopo la self-attention, ogni token non è più solo se stesso. Diventa una versione consapevole del contesto—una miscela ponderata delle informazioni dagli altri token. Puoi pensarla come se ogni token creasse un riassunto personalizzato dell'intera frase, sintonizzato su ciò che quel token richiede.
In pratica, questo significa che la rappresentazione di “tazza” può portare segnali da “versato”, “acqua” e “vuota”, mentre “vuota” può richiamare ciò che descrive.
Perché l'addestramento può essere parallelo
Poiché ogni token può calcolare la sua attenzione sull'intera sequenza allo stesso tempo, l'addestramento non deve aspettare che i token precedenti siano processati passo dopo passo. Questa elaborazione parallela è una delle ragioni principali per cui i Transformer si addestrano in modo efficiente su grandi dataset e scalano a modelli enormi.
Perché è forte nelle relazioni a lungo raggio
La self-attention rende più semplice collegare parti distanti del testo. Un token può concentrarsi direttamente su una parola rilevante lontana—senza passare informazioni attraverso una lunga catena di passaggi intermedi.
Quella via diretta aiuta in compiti come la coreferenza (“lei”, “esso”, “loro”), mantenere traccia di argomenti attraverso paragrafi e gestire istruzioni che dipendono da dettagli precedenti.
Multi-Head Attention: molte viste della stessa frase
Pianifica prima di programmare
Progetta il flusso di lavoro in modalità planning prima di generare codice.
Un singolo meccanismo di attenzione è potente, ma può essere come cercare di capire una conversazione guardando da una sola angolazione. Le frasi spesso contengono più relazioni contemporaneamente: chi ha fatto cosa, a cosa si riferisce “it”, quali parole stabiliscono il tono e qual è l'argomento generale.
Perché una sola vista non basta
Quando leggi “Il trofeo non entrava nella valigia perché era troppo piccolo”, potresti dover seguire indizi diversi allo stesso tempo (grammatica, significato e contesto del mondo reale). Un'attention “vista” potrebbe fissarsi sul sostantivo più vicino; un'altra potrebbe usare la frase verbale per decidere a cosa si riferisce “era”.
Cosa fanno le teste multiple
La multi-head attention esegue diversi calcoli di attenzione in parallelo. Ogni “head” è incoraggiata a guardare la frase attraverso una lente diversa—spesso descritta come sottospazi differenti. In pratica, questo significa che le teste possono specializzarsi in pattern differenti, come:
- Sintassi locale (es. aggettivo → sostantivo)
- Collegamenti a lungo raggio (es. soggetto ↔ verbo su una clausola)
- Coreference (es. pronome → entità)
- Segnali tematici (parole che impostano l'argomento o il tono)
Come si combinano le teste
Dopo che ogni head produce il proprio insieme di insight, il modello non sceglie solo una. Concatena gli output delle teste (li affianca) e poi li proietta nuovamente nello spazio di lavoro principale del modello con un layer lineare appreso.
Pensalo come fondere diversi appunti parziali in un riassunto pulito che lo strato successivo può usare. Il risultato è una rappresentazione che cattura molte relazioni insieme—una delle ragioni per cui i Transformer funzionano così bene su larga scala.
Codifica posizionale: insegnare al modello l'ordine delle parole
La self-attention è ottima a individuare relazioni—ma da sola non sa chi è venuto prima. Se mescoli le parole in una frase, un layer di self-attention puro potrebbe trattare la versione mescolata come ugualmente valida, perché confronta token senza alcun senso intrinseco di posizione.
La codifica posizionale risolve questo inserendo l'informazione “dove sono nella sequenza?” nelle rappresentazioni dei token. Una volta che la posizione è attaccata, l'attenzione può apprendere pattern come “la parola subito dopo non conta molto” o “il soggetto appare solitamente prima del verbo” senza dover dedurre l'ordine da zero.
Come le codifiche posizionali aggiungono l'ordine
L'idea fondamentale è semplice: ogni embedding di token viene combinato con un segnale di posizione prima di entrare nel blocco Transformer. Quel segnale di posizione può essere pensato come un ulteriore set di feature che etichettano un token come 1°, 2°, 3°… nell'input.
Esistono alcuni approcci comuni:
- Posizioni assolute (fisse): i Transformer classici usavano pattern sinusoidali deterministici. Questi non aggiungono nuovi parametri e possono generalizzare a lunghezze oltre quelle viste in addestramento (entro certi limiti).
- Posizioni assolute apprese: il modello impara un vettore per “posizione 1”, “posizione 2”, ecc. Funziona molto bene, ma spesso lega il modello a una finestra di contesto massima usata in addestramento.
- Posizioni relative: invece di codificare “questo è il token 57”, il modello si concentra su distanze come “questo token è 3 passi prima di quell'altro”. Le varianti moderne (inclusi i metodi rotary) rientrano spesso in questa famiglia.
Perché conta per compiti con contesto lungo
Le scelte posizionali possono influenzare sensibilmente il modeling a lungo contesto—cose come riassumere un lungo rapporto, seguire entità attraverso molti paragrafi o recuperare un dettaglio menzionato migliaia di token prima.
Con input lunghi, il modello non impara solo la lingua; impara dove guardare. Gli schemi relativi e rotary tendono a rendere più facile confrontare token molto distanti e preservare pattern man mano che il contesto cresce, mentre alcune soluzioni assolute possono degradare più rapidamente oltre la finestra usata in addestramento.
In pratica, la codifica posizionale è una di quelle decisioni progettuali silenziose che possono determinare se un LLM rimane nitido e coerente a 2.000 token—e ancora comprensibile a 100.000.
Costruisci una funzionalità LLM in fretta
Trasforma le idee dei Transformer in una funzionalità LLM funzionante descrivendo la tua app in chat.
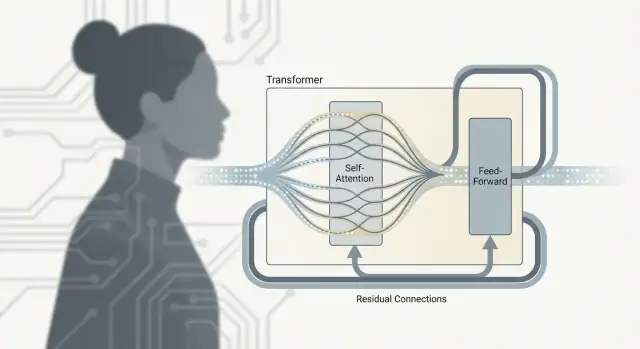
Un Transformer non è solo “attenzione”. Il lavoro reale avviene all'interno di un'unità ripetuta—spesso chiamata blocco Transformer—che mescola informazioni tra i token e poi le affina. Impila molti di questi blocchi e ottieni la profondità che rende i modelli linguistici così capaci.
Dopo l'attenzione: cosa fa l'FFN/MLP
La self-attention è il passo di comunicazione: ogni token raccoglie contesto dagli altri token.
La feed-forward network (FFN), chiamata anche MLP, è il passo di ragionamento: prende la rappresentazione aggiornata di ogni token ed esegue la stessa piccola rete neurale su di essa in modo indipendente.
In parole semplici, l'FFN trasforma e rimodella ciò che ogni token ora sa, aiutando il modello a costruire feature più ricche (pattern sintattici, fatti, o segnali stilistici) dopo aver raccolto il contesto rilevante.
Perché i blocchi alternano attenzione e FFN
L'alternanza è importante perché le due parti svolgono compiti diversi:
- L'attenzione muove informazioni tra i token (chi dovrebbe influenzare chi)
- L'FFN elabora informazioni all'interno di ogni token (come convertire quel contesto in feature utili)
Ripetere questo schema permette al modello di costruire gradualmente significati di livello più alto: comunica, calcola, comunica di nuovo, calcola di nuovo.
Connessioni residuali: le “corsie di salto”
Ogni sotto-strato (attenzione o FFN) è avvolto con una connessione residuale: l'input viene sommato all'output. Questo aiuta i modelli profondi nell'addestramento perché i gradienti possono scorrere attraverso la “corsia di salto” anche se uno strato è ancora in fase di apprendimento. Permette anche a uno strato di fare piccoli aggiustamenti invece di dover reimparare tutto da zero.
Layer normalization: mantenere i segnali stabili
La layer normalization è uno stabilizzatore che evita che le attivazioni diventino troppo grandi o troppo piccole passando attraverso molti strati. Pensalo come mantenere il livello del volume coerente in modo che gli strati successivi non vengano sovraccaricati o privati di segnale—rendendo l'addestramento più fluido e affidabile, specialmente su scala LLM.
Encoder–Decoder vs Decoder-only: quale alimenta gli LLM?
Il Transformer originale in Attention Is All You Need fu costruito per la traduzione, dove converti una sequenza (francese) in un'altra (inglese). Quel compito si divide naturalmente in due ruoli: leggere bene l'input e scrivere l'output fluentemente.
Encoder–Decoder: “Leggi, poi scrivi”
In un Transformer encoder–decoder, l'encoder elabora l'intera frase di input e produce un insieme ricco di rappresentazioni. Il decoder poi genera l'output token per token.
Crucialmente, il decoder non si basa solo sui propri token passati. Usa anche la cross-attention per guardare l'output dell'encoder, aiutandolo a restare ancorato al testo sorgente.
Questa configurazione è ancora eccellente quando devi condizionare strettamente l'output su un input—traduzione, riassunto o question answering con un passaggio specifico.
Decoder-only: un modello che continua a prevedere
La maggior parte dei moderni LLM è decoder-only. Sono addestrati a fare un compito semplice e potente: predire il token successivo.
Per farlo, usano la self-attention mascherata (causale). Ogni posizione può attenersi solo ai token precedenti, non a quelli futuri, così la generazione rimane coerente: il modello scrive left-to-right, estendendo continuamente la sequenza.
Questo approccio è dominante per gli LLM perché è semplice da addestrare su enormi corpora di testo, corrisponde direttamente al caso d'uso della generazione e scala in modo efficiente con dati e calcolo.
Dove si collocano i modelli encoder-only
I Transformer encoder-only (stile BERT) non generano testo; leggono l'intero input bidirezionalmente. Sono ottimi per classificazione, ricerca ed embeddings—qualsiasi cosa in cui capire un pezzo di testo conti più che produrre una lunga continuazione.
I Transformer si sono rivelati particolarmente adatti alla scala: se gli dai più testo, più calcolo e modelli più grandi, tendono a migliorare in modo prevedibile.
Una grande ragione è la semplicità strutturale. Un Transformer è costruito da blocchi ripetuti (self-attention + una piccola rete feed-forward, più normalizzazione), e quei blocchi si comportano in modo simile che tu stia addestrando su un milione di parole o un trilione.
L'addestramento parallelo è il superpotere nascosto
I modelli di sequenza precedenti (come gli RNN) dovevano processare token uno per volta, il che limita quanto lavoro si può fare contemporaneamente. I Transformer, al contrario, possono processare tutti i token di una sequenza in parallelo durante l'addestramento.
Questo li rende perfetti per GPU/TPU e setup distribuiti—esattamente ciò che serve per addestrare gli LLM moderni.
La “finestra di contesto” e perché conta
La finestra di contesto è il pezzo di testo che il modello può “vedere” in un dato momento—il tuo prompt più la conversazione o il documento recente. Una finestra più ampia permette al modello di collegare idee attraverso più frasi o pagine, mantenere vincoli e rispondere a domande che dipendono da dettagli precedenti.
Ma il contesto non è gratuito.
Il vincolo chiave: il costo dell'attenzione cresce con la lunghezza
La self-attention confronta i token tra loro. All'aumentare della lunghezza della sequenza, il numero di confronti cresce rapidamente (approssimativamente con il quadrato della lunghezza).
Per questo le finestre di contesto molto lunghe possono essere costose in memoria e calcolo, e perché molti sforzi moderni puntano a rendere l'attenzione più efficiente.
La scalabilità ha sbloccato comportamenti general-purpose
Quando i Transformer sono addestrati su larga scala, non migliorano solo in un compito specifico. Spesso emergono capacità ampie e flessibili—riassumere, tradurre, scrivere, programmare e ragionare—perché la stessa macchina di apprendimento generale viene applicata su dati massivi e vari.
Varianti moderne costruite sullo stesso schema
Portalo su mobile
Trasforma il tuo flusso LLM in un'app mobile Flutter dalla stessa build guidata in chat.
Il disegno originale del Transformer è ancora il punto di riferimento, ma la maggior parte degli LLM di produzione è un “Transformer plus”: piccole modifiche pratiche che mantengono il blocco centrale (attention + MLP) migliorando velocità, stabilità o lunghezza del contesto.
Miglioramenti comuni che vedrai
Molti upgrade riguardano più il come il modello viene addestrato e servito che il cosa del modello:
- Metodi posizionali migliori: alternative alle posizioni sinusoidali classiche (spesso rotary o relative) che migliorano la gestione del testo a lunga distanza.
- Ottimizzazioni dell'attenzione: implementazioni che riducono l'uso di memoria e aumentano il throughput (per esempio kernel fusi o calcoli di attenzione più efficienti).
- Aggiustamenti nella normalizzazione: variazioni su dove e come applicare la normalizzazione possono migliorare la stabilità dell'addestramento e ridurre la sensibilità agli iperparametri.
Questi cambiamenti di solito non alterano la “Transformer-ness” fondamentale del modello—lo raffinano.
Approcci per contesti lunghi (a alto livello)
Estendere il contesto da poche migliaia di token a decine o centinaia di migliaia spesso si basa su attention sparsa (attenzione solo a token selezionati) o varianti efficienti dell'attenzione (approssimano o ristrutturano l'attenzione per ridurre il calcolo).
Il compromesso è solitamente tra accuratezza, memoria e complessità ingegneristica.
Mixture-of-Experts (MoE): più capacità senza costo lineare
I modelli MoE aggiungono molte sotto-reti “expert” e instradano ogni token solo attraverso un sottoinsieme. Concettualmente: ottieni un cervello più grande, ma non lo attivi tutto ogni volta.
Questo può abbassare il compute per token per una data quantità di parametri, ma aumenta la complessità di sistema (instradamento, bilanciamento degli expert, serving).
Come valutare le affermazioni sulle varianti
Quando un modello vanta una nuova variante Transformer, chiedi:
- Benchmark rilevanti per i tuoi compiti (non solo punteggi di headline)
- Latenza (tempo al primo token e token/sec)
- Costo (addestramento e inferenza), inclusi memoria e bisogni hardware
La maggior parte dei miglioramenti è reale—ma raramente è gratuita.
Cosa significa per i team che costruiscono con gli LLM
Le idee dei Transformer come self-attention e scaling sono affascinanti—ma i team di prodotto le sentono soprattutto come scelte di compromesso: quanto testo puoi inserire, quanto velocemente ricevi una risposta e quanto costa ogni richiesta.
Scegliere un modello o un provider: i quattro compromessi
Lunghezza del contesto: un contesto più lungo permette di includere più documenti, cronologia chat e istruzioni. Aumenta anche il consumo di token e può rallentare le risposte. Se la tua funzionalità richiede “leggi queste 30 pagine e rispondi”, dai priorità alla lunghezza del contesto.
Latenza: esperienze utente in chat o copilot vivono o muoiono sulla velocità di risposta. Lo streaming aiuta, ma contano anche scelta del modello, regione e batch.
Costo: il prezzo è spesso per token (input + output). Un modello che è del 10% “migliore” può costare 2–5× di più. Usa confronti sul costo per decidere quale livello di qualità vale la pena pagare.
Qualità: definiscila per il tuo caso d'uso: accuratezza fattuale, seguire istruzioni, tono, uso di tool o codice. Valuta con esempi reali del tuo dominio, non solo benchmark generici.
Quando gli embeddings battono la generazione
Se hai bisogno principalmente di ricerca, deduplicazione, clustering, raccomandazioni o “trova simili”, gli embeddings (spesso modelli encoder-style) sono tipicamente più economici, più veloci e più stabili rispetto al prompting di un modello di generazione. Usa la generazione solo per il passo finale (riassunti, spiegazioni, redazione) dopo il retrieval.
Per un'analisi più approfondita, coinvolgi il tuo team con un explainer tecnico tipo /blog/embeddings-vs-generation.
Dove questo emerge nei flussi di lavoro reali
Quando trasformi le capacità dei Transformer in un prodotto, la parte difficile è spesso meno l'architettura e più il flusso di lavoro attorno a essa: iterazione sui prompt, grounding, valutazione e deployment sicuro.
Un percorso pratico è usare una piattaforma vibe-coding come Koder.ai per prototipare e lanciare funzionalità supportate da LLM più velocemente: puoi descrivere l'app web, gli endpoint backend e il modello di dati in chat, iterare in modalità planning e poi esportare codice sorgente o distribuire con hosting, domini personalizzati e rollback tramite snapshot. Questo è particolarmente utile quando sperimenti con retrieval, embeddings o loop di tool e vuoi cicli di iterazione rapidi senza ricostruire sempre la stessa infrastruttura.
Una checklist pratica per l'adozione
- Scrivi una specifica di una pagina: obiettivo utente, modalità di fallimento e cosa significa “bene”.
- Decidi cosa deve essere ancorato ai tuoi dati (RAG, citazioni o chiamate a tool).
- Stabilisci budget per token, latenza e spesa mensile; misurali in staging.
- Aggiungi salvaguardie: rifiuti, redazione e comportamenti “non lo so”.
- Costruisci la valutazione in anticipo: prompt golden, test di regressione e revisione umana.
- Pianifica per switch di modello: mantieni prompt e instradamento configurabili.