Cosa deve fare un flusso di onboarding a più passaggi
Un onboarding a più passaggi è una sequenza guidata di schermate che aiuta un nuovo utente a passare da “registrato” a “pronto a usare il prodotto”. Invece di chiedere tutto in una volta, si suddivide la configurazione in passaggi più piccoli che possono essere completati in una sola sessione o nel tempo.
Hai bisogno di un onboarding a più passaggi quando la configurazione è più di un singolo modulo—soprattutto se include scelte, prerequisiti o verifiche di conformità. Se il tuo prodotto richiede contesto (settore, ruolo, preferenze), verifica (email/telefono/identità) o configurazione iniziale (spazi di lavoro, fatturazione, integrazioni), un flusso a passi mantiene le cose comprensibili e riduce gli errori.
Flussi di onboarding comuni che hai già visto
L'onboarding a più passaggi è ovunque perché supporta attività che avvengono naturalmente a fasi, come:
- Configurazione account: creare workspace, invitare colleghi, scegliere piano
- Completamento profilo: nome, ruolo, obiettivi, preferenze
- Verifiche: conferma email/telefono, controlli KYC/ID, impostazione 2FA
- Tutorial e guida al primo utilizzo: tour del prodotto, creazione di progetto di esempio, checklist “fai questo per primo”
Come dovrebbe apparire il “successo”
Un buon flusso di onboarding non è “schermate finite”, ma utenti che raggiungono il valore velocemente. Definisci il successo in termini che corrispondono al tuo prodotto:
- Attivazione: l'utente completa l'azione chiave che predice la retention a lungo termine (es. crea il primo progetto, collega una sorgente dati)
- Tasso di completamento: quale percentuale di utenti termina i passaggi richiesti (e quelli opzionali, se rilevante)
- Time-to-value: quanto ci mette un nuovo utente a raggiungere il primo risultato significativo
Il flusso deve anche supportare ripresa e continuità: gli utenti devono poter lasciare e tornare senza perdere i progressi, e atterrare sul passo logico successivo.
Rischi tipici da cui difendersi
L'onboarding a più passaggi fallisce in modi prevedibili:
- Abbandoni: troppi passaggi, benefici poco chiari o richiesta di informazioni sensibili troppo presto
- Passaggi confusi: etichette vaghe (“Setup”), requisiti nascosti o navigazione inconsistente
- Perdita di dati: problemi al refresh/indietro, timeout di sessione, salvataggi parziali non gestiti
Il tuo obiettivo è far sentire l'onboarding come un percorso guidato, non come un test: scopo chiaro per ogni passo, tracciamento del progresso affidabile e un modo semplice per riprendere da dove l'utente ha lasciato.
Definisci obiettivi, utenti e i criteri di “fatto”
Prima di disegnare schermate o scrivere codice, decidi cosa vuole ottenere il tuo onboarding—e per chi. Un flusso a più passaggi è “buono” solo se porta in modo affidabile le persone giuste allo stato finale corretto con il minimo confusione.
Identifica i tipi di utente chiave
Diversi utenti arrivano con contesto, permessi e urgenza differenti. Inizia nominando le personas di ingresso principali e cosa sai già di loro:
- Nuovo utente (signup self-serve): tipicamente necessita creazione account, verifica email, profilo di base e azioni di primo valore.
- Utente invitato: spesso appartiene già a un'organizzazione e dovrebbe saltare la creazione org; può dover accettare termini, impostare password e confermare ruolo.
- Account creato da admin: può avere campi precompilati e passaggi di sicurezza obbligatori (MFA, reset password al primo accesso).
Per ogni tipo, elenca vincoli (es. “non può modificare il nome azienda”), dati richiesti (es. “deve scegliere uno spazio di lavoro”) e scorciatoie potenziali (es. “già verificato via SSO”).
Definisci cosa significa “fatto”
Lo stato finale dell'onboarding deve essere esplicito e misurabile. “Fatto” non è “tutte le schermate completate”; è uno stato pronto per il business, come:
- Profilo concompletezza minima raggiunta
- Organizzazione/workspace configurato
- Fatturazione impostata (o esplicitamente rinviata)
- Utente che raggiunge la prima azione significativa (es. crea un progetto)
Scrivi i criteri di completamento come una checklist che il backend può valutare, non come un obiettivo vago.
Passaggi obbligatori vs opzionali, dipendenze e regole di skip
Mappa quali passaggi sono obbligatori per lo stato finale e quali sono opzionali. Documenta le dipendenze (“non puoi invitare colleghi finché lo workspace non esiste”).
Infine, definisci le regole di skip con precisione: quali passaggi possono essere saltati, da quale tipo di utente, in quali condizioni (es. “salta verifica email se autenticato via SSO”) e se i passaggi saltati possono essere rivisti successivamente nelle impostazioni.
Disegna la mappa del flusso: passaggi, rami e punti di ingresso
Prima di costruire schermate o API, disegna l'onboarding come una mappa del flusso: un piccolo diagramma che mostra ogni passo, dove può andare l'utente dopo e come può tornare.
1) Parti da una lista concreta di passaggi
Scrivi i passaggi con nomi brevi e orientati all'azione (i verbi aiutano): “Crea password”, “Conferma email”, “Aggiungi dettagli azienda”, “Invita colleghi”, “Collega fatturazione”, “Fine”. Mantieni la prima versione semplice, poi aggiungi dettagli come campi richiesti e dipendenze (es. la fatturazione non può avvenire prima della scelta del piano).
Un controllo utile: ogni passaggio dovrebbe rispondere a una domanda—o “Chi sei?”, “Di cosa hai bisogno?” o “Come va configurato il prodotto?”. Se un passaggio prova a fare tutte e tre le cose, dividilo.
2) Decidi lineare vs. rami condizionali
La maggior parte dei prodotti beneficia di una backbone per lo più lineare con rami condizionali solo quando l'esperienza cambia veramente. Regole di ramo tipiche:
- Ruolo: admin vs. membro
- Piano: gratuito vs. a pagamento
- Regione: requisiti IVA, consenso privacy
- Caso d'uso: personale vs. business
Documenta questi come note “if/then” sulla mappa (es. “If region = EU → mostra passo IVA”). Questo mantiene il flusso comprensibile ed evita di costruire un labirinto.
3) Definisci i punti di ingresso (come inizia l'onboarding)
Elenca ogni posto da cui un utente può entrare nel flusso:
- Primo login dopo il signup
- Accettazione di un link di invito
- Promemoria “Completa configurazione” dalle impostazioni (
/settings/onboarding)
Ogni ingresso dovrebbe portare l'utente al passo successivo corretto, non sempre al passo uno.
4) Pianifica la re-entrata (comportamento di ripresa)
Assumi che gli utenti lasceranno a metà. Decidi cosa succede quando tornano:
- Riprendono dall'ultimo passo incompleto
- Conservare campi parziali (bozza) vs. cancellare all'uscita
- Gestire passaggi “obsoleti” se il flusso cambia dopo
La tua mappa dovrebbe mostrare un percorso di “ripresa” chiaro così l'esperienza sembra affidabile, non fragile.
Pattern UX per un onboarding chiaro e a bassa frizione
Un buon onboarding sembra un percorso guidato, non un esame. L'obiettivo è ridurre l'affaticamento decisionale, rendere ovvie le aspettative e aiutare gli utenti a riprendersi rapidamente quando qualcosa va storto.
Scegli un pattern che corrisponda al lavoro
Un wizard funziona meglio quando i passaggi devono essere completati in ordine (es. identità → fatturazione → permessi). Una checklist si adatta a onboarding che possono essere fatti in qualsiasi ordine (es. “Aggiungi logo”, “Invita colleghi”, “Collega calendario”). Task guidati (suggerimenti ed evidenziazioni integrate nel prodotto) sono ottimi quando si impara facendo, non compilando moduli.
Se non sei sicuro, inizia con una checklist + deep link a ogni attività, poi metti vincoli solo sui passaggi veramente richiesti.
Mostra il progresso senza pressione
Il feedback sul progresso dovrebbe rispondere a: “Quanto manca?”. Usa una delle seguenti opzioni:
- Conteggio dei passi (es. Passo 2 di 5) per wizard lineari
- Traguardi (es. Account → Team → Integrazioni) per attività raggruppate
- Percentuale solo se è veritiera e stabile (evita salti improvvisi)
Aggiungi anche un suggerimento “Salva e termina dopo” specialmente per flussi lunghi.
Etichette, microcopy e impostazioni predefinite amichevoli
Usa etichette chiare (“Nome azienda”, non “Entity identifier”). Aggiungi microcopy che spieghi perché stai chiedendo qualcosa (“Lo usiamo per personalizzare le fatture”). Quando possibile, precompila con dati esistenti e scegli default sicuri.
Stati di errore e recupero
Progetta gli errori come una via d'uscita: evidenzia il campo, spiega cosa fare, conserva l'input dell'utente e focalizza il primo campo non valido. Per errori server, mostra un'opzione di retry e conserva i progressi in modo che gli utenti non ripetano passaggi già completati.
Mobile e accessibilità fin da subito
Rendi i target touch grandi, evita form multi-colonna e mantieni l'azione primaria visibile. Garantire navigazione completa da tastiera, stati di focus visibili, input etichettati e testo di progresso leggibile da screen reader (non solo una barra visiva).
Modello dati: utenti, passaggi, progresso e versioni
Un flusso di onboarding fluido dipende da un modello dati che possa rispondere a tre domande in modo affidabile: cosa deve vedere l'utente dopo, cosa ha già fornito e quale definizione del flusso sta seguendo.
Entità core (cosa salvare)
Inizia con un piccolo set di tabelle/collection e cresci solo quando serve:
- User: il record utente esistente.
- OnboardingFlow: un flusso nominato (es. “Default onboarding”, “Enterprise onboarding”).
- Step: definizione di un singolo passo (titolo, tipo, ordine, campi richiesti, testo di aiuto). I passaggi dovrebbero appartenere a una specifica versione del flusso.
- StepResponse: i dati salvati dall'utente per un passo (le risposte), più lo stato di validazione.
- Completion (o OnboardingProgress): un record riassuntivo che collega un utente a una versione del flusso e traccia lo stato complessivo.
Questa separazione mantiene la “configurazione” (Flow/Step) separata dai “dati utente” (StepResponse/Progress).
Versioni: non rompere gli utenti in corso
Decidi in anticipo se i flussi sono versionati. Nella maggior parte dei prodotti, la risposta è sì.
Quando modifichi passi (rinomina, riordino, aggiungi campi obbligatori), non vuoi che gli utenti a metà onbarding falliscano improvvisamente la validazione o perdano il loro posto. Un approccio semplice è:
- Il flow ha
id e version (o un flow_version_id immutabile).
- Il progresso punta a un
flow_version_id specifico per sempre.
- I nuovi utenti ricevono l'ultima versione; gli utenti esistenti continuano sulla versione assegnata a meno che non vengano migrati intenzionalmente.
Progresso parziale e timestamp
Per salvare il progresso, scegli tra autosave (salvare mentre l'utente digita) e salvataggio esplicito “Avanti”. Molti team combinano entrambe le cose: autosave per bozze, e poi mark del passo come “completato” solo su Next.
Traccia timestamp per report e debugging: started_at, completed_at e last_seen_at (più per-step saved_at). Questi campi alimentano le analisi sull'onboarding e aiutano il supporto a capire dove un utente si è bloccato.
Logica di workflow: stato e transizioni
Testa le modifiche con rollback
Itera sull'onboarding in sicurezza e torna indietro rapidamente se una modifica peggiora i tassi di completamento.
Un onboarding a più passaggi è più semplice da ragionare se lo tratti come una macchina a stati: la sessione di onboarding dell'utente è sempre in uno “stato” (passo corrente + stato), e permetti solo transizioni specifiche tra stati.
Modella il flusso come transizioni permesse
Invece di lasciare il frontend libero di saltare a qualsiasi URL, definisci un piccolo set di stati per passo (per esempio: not_started → in_progress → completed) e un insieme chiaro di transizioni (per esempio: start_step, save_draft, submit_step, go_back, reset_step).
Questo ti dà comportamento prevedibile:
- Gli utenti non possono saltare i passaggi obbligatori a meno che le regole del flusso lo permettano.
- “Riprendi onboarding” è semplicemente caricare l'ultimo stato noto.
- I rami sono espliciti: una transizione può portare a passi diversi in base alle risposte salvate.
Regole di completamento dei passaggi (validazione + controlli server)
Un passaggio è “completato” solo quando entrambe le condizioni sono soddisfatte:
- Validazione client passata (campi richiesti, formati, ecc.).
- Controlli server passati (regole di business e verifiche esterne), come “questa email non è già usata”, “il codice fiscale corrisponde al paese” o “il nome azienda è consentito”.
Salva la decisione del server insieme al passo, inclusi eventuali codici di errore. Questo evita casi in cui la UI pensa che un passo sia fatto ma il backend dissente.
Gestire l'invalidazione quando cambiano risposte precedenti
Un caso limite facile da perdere: un utente modifica un passo precedente e rende errati i passi successivi. Esempio: cambiare “Paese” può invalidare “Dettagli fiscali” o “Piani disponibili”.
Gestiscilo tracciando le dipendenze e rivalutando i passi a valle dopo ogni submit. Risultati comuni:
- Marca i passi interessati come
needs_review (o torna a in_progress).
- Cancella campi specifici non più applicabili.
- Ricalcola il passo successivo basato sulla nuova condizione di ramo.
Navigazione indietro e ri-validazione
Il pulsante “Indietro” va supportato, ma deve essere sicuro:
- Permetti di navigare ai passaggi precedenti senza perdere i dati.
- Quando l'utente ritorna a un passo successivo, riesegui la validazione usando le risposte correnti e le regole server attuali.
Questo mantiene l'esperienza flessibile assicurando che lo stato della sessione resti consistente e applicabile.
Progettazione API backend per onboarding a passaggi
Il tuo backend è la “fonte di verità” per dove si trova un utente nell'onboarding, cosa ha già inserito e cosa può fare dopo. Una buona API mantiene il frontend semplice: può renderizzare il passo corrente, inviare dati in modo sicuro e riprendersi dopo refresh o problemi di rete.
Endpoint di base di cui di solito hai bisogno
Al minimo, progetta le seguenti azioni:
- Get current step (e progresso)
GET /api/onboarding → restituisce la chiave del passo corrente, la % di completamento e eventuali valori di bozza salvati necessari per renderizzare il passo.
- Save step data (bozza o finale)
PUT /api/onboarding/steps/{stepKey} con { "data": {…}, "mode": "draft" | "submit" }
- Move next / previous (opzionale se deduci il prossimo dallo stato salvato)
POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previous
- Complete onboarding
POST /api/onboarding/complete (il server verifica che tutti i passi obbligatori siano soddisfatti)
Mantieni le risposte coerenti. Per esempio, dopo il salvataggio, ritorna il progresso aggiornato più il passo successivo deciso dal server:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
Idempotenza: proteggi il progresso da doppie submit
Gli utenti cliccheranno due volte, faranno retry con connessioni lente o il frontend potrebbe rimandare richieste dopo un timeout. Rendi il salvataggio sicuro:
- Accetta un header
Idempotency-Key per richieste PUT/POST e deduplica usando (userId, endpoint, key).
- Tratta
PUT /steps/{stepKey} come sovrascrittura completa del payload memorizzato (o documenta chiaramente regole di merge parziale).
- Opzionalmente aggiungi una
version (o etag) per evitare che dati più vecchi sovrascrivano dati più recenti in retry.
Errori chiari e validazione a livello di campo
Ritorna messaggi azionabili che la UI può mostrare accanto ai campi:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
Distingui anche 403 (non permesso) da 409 (conflitto / passo sbagliato) e 422 (validazione) così il frontend può reagire correttamente.
Autenticazione e autorizzazione
Separa capacità utente e admin:
- Gli endpoint utente richiedono una sessione autenticata e devono accedere solo allo stato di onboarding del chiamante.
- Gli endpoint admin (es.
GET /api/admin/onboarding/users/{userId} o override) devono essere limitati per ruolo e auditati.
Questa separazione previene fughe di privilegi accidentali e permette support/operations di aiutare gli utenti bloccati.
Implementazione frontend: routing, ripresa e affidabilità
Il compito del frontend è far sembrare l'onboarding fluido anche quando la rete è scarsa. Serve routing prevedibile, comportamento di ripresa affidabile e feedback chiaro quando i dati vengono salvati.
Routing: un URL per passo vs pagina singola
Un URL per passo (es. /onboarding/profile, /onboarding/billing) è solitamente la scelta più semplice. Supporta back/forward del browser, deep link dalle email e rende semplice il refresh senza perdere il contesto.
Una pagina singola con stato interno può andare bene per flussi molto brevi, ma aumenta i rischi su refresh, crash e “condividi link per continuare”. Se scegli questa strada, serve persistenza forte (vedi sotto) e gestione attenta della history.
Persistenza del progresso: il server è la fonte di verità
Memorizza il completamento dei passaggi e i dati più recenti sul server, non solo in local storage. Al caricamento della pagina, recupera lo stato corrente (passo corrente, passi completati e eventuali bozze) e rendi da lì.
Questo abilita:
- Sicurezza al refresh
- Continuazione su più dispositivi
- Vista coerente dopo che gli admin modificano il flusso
UI ottimistica senza confondere l'utente
La UI ottimistica può ridurre la frizione, ma servono guardrail:
- Mostra uno stato chiaro Salvataggio… / Salvato / Errore vicino al pulsante principale.
- Disabilita il pulsante di submit mentre la richiesta è in volo per evitare doppie submit.
- Se fai autosave, debounce delle modifiche e rendi visibili i fallimenti (“Impossibile salvare. Riprova”).
Riprendi l'onboarding, con garbo
Quando un utente torna, non buttarlo al passo uno. Mostra qualcosa come: “Hai completato il 60%—vuoi continuare da dove hai lasciato?” con due azioni:
- Continua (collega al prossimo passo richiesto)
- Finisco dopo (porta all'app, con un banner persistente che linka di nuovo a
/onboarding)
Questa piccola attenzione riduce l'abbandono rispettando gli utenti che non sono pronti a completare tutto subito.
Strategia di validazione e gestione dei dati parziali
Crea un Flow Builder per gli admin
Crea un semplice editor di flussi con versioni, rollout e override di supporto senza partire da zero.
La validazione è il momento in cui i flussi di onboarding diventano fluidi o frustranti. L'obiettivo è intercettare gli errori presto, mantenere gli utenti in movimento e proteggere il sistema quando i dati sono incompleti o sospetti.
Valida nel browser (feedback veloce)
Usa validazione client per prevenire errori ovvi prima di una richiesta di rete. Riduce il churn e rende ogni passo più reattivo.
Controlli tipici: campi obbligatori, limiti di lunghezza, formati base (email/telefono) e regole semplici tra campi (conferma password). Mantieni i messaggi specifici (“Inserisci una email valida aziendale”) e posizionali vicino al campo.
Valida sul server (correttezza e sicurezza)
Tratta la validazione server come la fonte di verità. Anche se la UI valida perfettamente, gli utenti possono aggirarla.
La validazione server dovrebbe imporre:
- Autorizzazione (l'utente può modificare solo il proprio onboarding)
- Valori ammessi (enum, codici paese, tipi di documento)
- Integrità dei dati (vincoli di unicità, foreign key)
- Controlli di sicurezza (rate limit, sanificazione input)
Ritorna errori strutturati per campo in modo che il frontend possa evidenziare esattamente cosa correggere.
Supporta controlli asincroni
Alcune verifiche dipendono da segnali esterni o ritardati: unicità email, codici invito, segnali antifrode o verifica documenti.
Gestiscili con stati espliciti (es. pending, verified, rejected) e un'interfaccia utente chiara. Se un controllo è pendente, lascia proseguire l'utente dove possibile e mostra quando verrà notificato o quale passo si sbloccherà dopo.
Decidi come gestire i fallimenti parziali
I dati parziali sono normali in un onboarding a più passaggi. Decidi per ogni passo se:
- Salvare bozza: memorizza input parziali e permetti di navigare via; marca il passo come “in progress”.
- Bloccare il progresso: richiedi un insieme minimo di campi prima di andare avanti.
Un approccio pratico: “salva sempre la bozza, blocca solo al completamento del passo.” Questo supporta la ripresa senza abbassare la qualità dei dati.
Analytics: misura il completamento e trova i punti di abbandono
L'analytics per l'onboarding a più passaggi deve rispondere a due domande: “Dove si bloccano le persone?” e “Quale cambiamento migliorerebbe il completamento?”. L'essenziale è tracciare un piccolo set di eventi coerenti su ogni passo e mantenerli comparabili anche quando il flusso cambia.
Eventi da tracciare per fidarsi dei dati
Traccia gli stessi eventi core per ogni passo:
step_viewed (l'utente ha visto il passo)step_completed (l'utente ha inviato e passato la validazione)step_failed (tentativo di invio fallito per validazione o controlli server)flow_completed (l'utente ha raggiunto lo stato finale di successo)
Includi un payload di contesto minimale e stabile con ogni evento: user_id, flow_id, flow_version, step_id, step_index e un session_id (così si distingue “nella stessa sessione” da “su più giorni”). Se supporti la ripresa, includi anche resume=true/false su step_viewed.
Abbandono e tempo per passo
Per misurare l'abbandono per passo, confronta i conteggi di step_viewed vs step_completed per la stessa flow_version. Per misurare il tempo, cattura i timestamp e calcola:
- tempo da
step_viewed → step_completed
- tempo da
step_viewed → next_step_viewed (utile quando gli utenti saltano)
Mantieni le metriche temporali raggruppate per versione; altrimenti i miglioramenti possono essere nascosti dal mescolare vecchi e nuovi flussi.
Hook per esperimenti senza rompere le metriche
Se fai A/B test su copy o riordino dei passaggi, trattalo come parte dell'identità dell'evento:
- aggiungi
experiment_id e variant_id a ogni evento
- mantieni
step_id stabile anche se il testo cambia
- quando riordini, mantieni lo stesso
step_id e usa step_index per la posizione
Dashboard ed export per gli stakeholder
Costruisci una dashboard semplice che mostri tasso di completamento, abbandono per passo, tempo mediano per passo e i “campi più falliti” (dai metadati di step_failed). Aggiungi esportazioni CSV così i team possono analizzare e condividere senza accesso diretto allo strumento di analytics.
Strumenti admin: flow builder, rollout e override
Distribuisci la tua app di onboarding
Ospita la tua app di onboarding e spingi aggiornamenti senza ricostruire la pipeline.
Un sistema di onboarding a più passaggi richiederà operazioni quotidiane: modifiche prodotto, eccezioni di supporto e sperimentazione sicura. Costruire una piccola area admin interna evita che l'ingegneria diventi il collo di bottiglia.
Flow builder: crea e modifica passaggi senza deploy
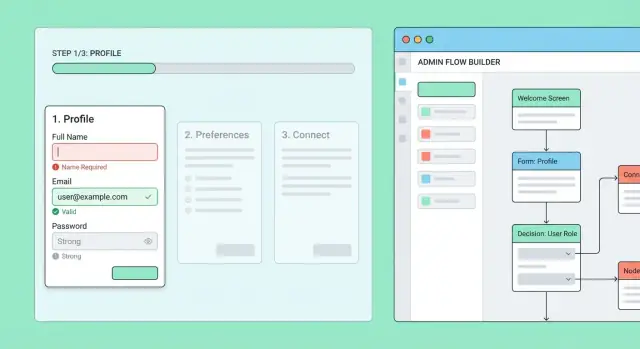
Inizia con un semplice “flow builder” che permette al personale autorizzato di creare e modificare flussi di onboarding e i loro passaggi.
Ogni passo dovrebbe essere editabile con:
- Titolo e testo di aiuto breve
- Tipo di passo (form, checklist, upload documento, scheduling, ecc.)
- Campi richiesti e regole di validazione
- Regole di branching opzionali (es. “Se l'utente seleziona Azienda, mostra passo IVA”)
Aggiungi una modalità anteprima che renda il passo come lo vedrebbe l'utente finale. Questo cattura copy confuso, campi mancanti e branching rotti prima che raggiungano gli utenti reali.
Versioning e rollout sicuro
Evita di modificare un flusso live in place. Pubblica invece versioni:
- Draft: modificabile, con anteprima
- Published: definizione immutabile usata dagli utenti
- Archived: conservata per supporto e audit
I rollout dovrebbero essere configurabili per versione:
- Solo nuovi utenti: gli utenti esistenti mantengono la loro versione
- Percentuale graduale: inizia al 5–10% e aumenta se le metriche sono sane
- Targeting (opzionale): per piano, regione, partner o campagna di inviti
Questo riduce il rischio e dà confronti puliti quando misuri il completamento e l'abbandono.
Override per support e operations
Il team di support ha bisogno di strumenti per sbloccare gli utenti senza modifiche manuali al DB:
- Marca un passo come completato (con motivo)
- Resetta il flusso di un utente all'inizio o a un passo specifico
- Riporta indietro un utente di un passo dopo un errore
- Reinvia invito / magic link / email di verifica legata all'onboarding
Log di audit e permessi
Ogni azione admin dovrebbe essere loggata: chi ha cambiato cosa, quando e i valori prima/dopo. Restringi l'accesso con ruoli (solo lettura, editor, publisher, override support) così azioni sensibili—come resettare il progresso—sono controllate e tracciabili.
Test, sicurezza e monitoring prima del lancio
Prima di rilasciare un flusso di onboarding a più passaggi, dai per scontato due cose: gli utenti prenderanno percorsi inaspettati, e qualcosa si romperà a metà strada (rete, validazione, permessi). Una checklist di lancio valida il flusso, protegge i dati utente e fornisce segnali di allerta presto quando la realtà diverge dal piano.
Testa la mappa del flusso, non solo l'interfaccia
Inizia con test unitari per la logica del workflow (stati e transizioni). Questi test dovrebbero verificare che ogni passo:
- possa essere raggiunto solo dai passi permessi precedenti
- produca il prossimo passo atteso dato un set di risposte/ruolo/piano
- gestisca edge case (skip, navigazione indietro, sessioni scadute)
Poi aggiungi test di integrazione che esercitino le API: salvataggio payload, ripresa del progresso e rifiuto di transizioni invalide. I test di integrazione sono dove si trovano problemi tipo indici mancanti, bug di serializzazione o mismatch di versione tra frontend e backend.
Test end-to-end per i percorsi critici
Gli E2E dovrebbero coprire almeno:
- il percorso felice da start → completion
- fallimenti comuni: errori di validazione, 500 server, timeout/retry e ripresa dopo la chiusura del browser
Mantieni gli scenari E2E piccoli ma significativi—focalizzati sui pochi percorsi che rappresentano la maggior parte degli utenti e l'impatto maggiore su ricavi/attivazione.
Proteggi i dati sensibili per impostazione predefinita
Applica il principio del privilegio minimo: gli admin dell'onboarding non dovrebbero ottenere automaticamente accesso completo ai record utente, e gli account di servizio dovrebbero toccare solo le tabelle/endpoint necessari.
Cripta dove conta (token, identificatori sensibili, campi regolamentati) e tratta i log come rischio di perdita dati. Evita di loggare payload grezzi dei form; registra invece ID dei passaggi, codici di errore e timing. Se devi loggare porzioni di payload per debug, redigi i campi in modo consistente.
Monitoring che cattura i problemi presto
Strumenta l'onboarding come funnel di prodotto e come API.
Traccia errori per passo, latenza dei salvataggi (p95/p99) e fallimenti nella ripresa. Imposta alert per cali improvvisi nel tasso di completamento, picchi di fallimenti di validazione su un singolo passo o tassi di errore API elevati dopo un rilascio. Così puoi riparare il passo rotto prima che i ticket di support si accumulino.
Dove si colloca Koder.ai (se vuoi costruire più in fretta)
Se implementi da zero un sistema di onboarding a passaggi, la maggior parte del tempo va spesa sugli stessi blocchi: routing dei passaggi, persistenza, validazioni, logica di stato/progresso e un'interfaccia admin per versioning e rollout. Koder.ai può aiutarti a prototipare e spedire questi pezzi più rapidamente generando app full-stack da specifiche guidate in chat—tipicamente con frontend React, backend Go e un modello dati PostgreSQL che mappa chiaramente a flussi, step e step responses.
Poiché Koder.ai supporta export del codice sorgente, hosting/deploy e snapshot con rollback, è utile anche quando vuoi iterare sulle versioni di onboarding in sicurezza (e recuperare rapidamente se un rollout peggiora il completamento).