Cosa intendiamo per “Palantir” e per “Software enterprise tradizionale” qui
Spesso si usa “Palantir” come abbreviazione per alcuni prodotti correlati e per un modo complessivo di costruire operazioni guidate dai dati. Per mantenere chiaro questo confronto, è utile specificare cosa stiamo effettivamente discutendo — e cosa no.
Cosa indica “Palantir” in questo post
Quando qualcuno dice “Palantir” in un contesto enterprise, di solito si riferisce a uno (o più) di questi:\n
- Foundry: la piattaforma commerciale di Palantir, focalizzata sull'integrazione dei dati, la loro modellazione e l'abilitazione delle decisioni operative.\n- Gotham: spesso associata a casi d'uso per la difesa e il settore pubblico, con temi simili ma storia e posizionamento diversi.\n- Apollo: un sistema di distribuzione e delivery usato per spedire e gestire software attraverso molti ambienti (inclusi quelli con restrizioni).
In questo post usiamo “in stile Palantir” per descrivere la combinazione di (1) forte integrazione dei dati, (2) un livello semantico/ontologia che allinea i team sul significato, e (3) pattern di deployment che possono coprire cloud, on‑prem e ambienti disconnessi.
Cosa significa qui “software enterprise tradizionale”
“Software enterprise tradizionale” non è un unico prodotto — è lo stack tipico che molte organizzazioni assemblano nel tempo, come:
- Sistemi ERP e CRM (sistemi di record per finanza, supply chain, vendite)
- Un data warehouse o data lake più dashboard BI (sistemi per reporting e analisi)
- Middleware di integrazione (strumenti ETL/ELT, iPaaS, code di messaggi, API)
In questo approccio, integrazione, analisi e operazioni sono spesso gestite da strumenti e team separati, collegati tramite progetti e processi di governance.
Cosa è (e cosa non è) questo confronto
Questo è un confronto di approccio, non un endorsement di vendor. Molte organizzazioni ottengono ottimi risultati con stack convenzionali; altre traggono vantaggio da un modello di piattaforma più unificato.
La domanda pratica è: quali compromessi stai facendo in termini di velocità, controllo e di quanto direttamente l'analisi si collega al lavoro quotidiano?
Per mantenere il resto dell'articolo concreto, ci concentreremo su tre aree:
- Integrazione dei dati: come i dati vengono connessi, mantenuti e di chi è la proprietà\n2. Analisi operativa: come l'analisi va oltre i dashboard verso le decisioni\n3. Modelli di deployment: cloud, on‑prem e realtà disconnesse/air‑gapped
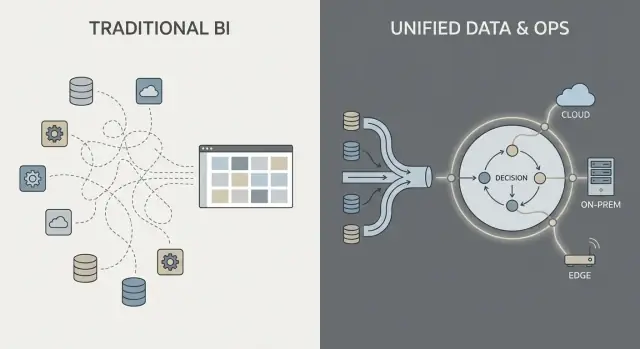
Integrazione dei dati: pipeline e responsabilità
La maggior parte del lavoro dati negli stack “tradizionali” segue una catena familiare: estrarre dati dai sistemi (ERP, CRM, log), trasformarli, caricarli in un warehouse o lake e poi costruire dashboard BI più alcune app downstream.
Questo schema può funzionare bene, ma spesso trasforma l'integrazione in una serie di passaggi fragili: un team possiede gli script di estrazione, un altro i modelli nel warehouse, un terzo le definizioni delle dashboard, mentre i team di business mantengono fogli di calcolo che rinegoziano in silenzio “il numero reale”.
Il modello tradizionale: ETL/ELT come staffetta
Con ETL/ELT, le modifiche tendono a riverberare. Un nuovo campo nel sistema sorgente può rompere una pipeline. Una “riparazione veloce” genera una seconda pipeline. Presto ci sono metriche duplicate (“fatturato” in tre posti) e non è chiaro chi sia responsabile quando i numeri non corrispondono.
Il batch processing è comune: i dati atterrano la notte, le dashboard si aggiornano la mattina. Il near‑real‑time è possibile, ma spesso diventa uno stack di streaming separato con i suoi strumenti e proprietari.
Il modello in stile Palantir: integrare, standardizzare il significato, poi riusare ovunque
Un approccio in stile Palantir mira a unificare le sorgenti e applicare semantiche coerenti (definizioni, relazioni e regole) prima, quindi esporre gli stessi dati curati ad analisi e workflow operativi.
In termini semplici: invece di lasciare che ogni dashboard o app “capisca” da sé cosa sia un cliente, un asset, un caso o una spedizione, quel significato viene definito una volta e riutilizzato. Ciò può ridurre la logica duplicata e chiarire la proprietà — perché quando una definizione cambia, sai dove vive e chi la approva.
Punti dolenti comuni da osservare
L'integrazione fallisce di solito sulle responsabilità, non sui connettori:
- Pipeline fragili che si rompono al minimo cambiamento delle sorgenti
- Metriche duplicate definite in modo diverso tra i team
- Proprietà poco chiara per qualità dei dati, definizioni e correzioni
La domanda chiave non è solo “Possiamo connetterci al sistema X?” ma “Chi possiede la pipeline, le definizioni delle metriche e il significato di business nel tempo?”
Livello semantico e ontologia: un diverso centro di gravità
Il software enterprise tradizionale spesso tratta il “significato” come un ripensamento: i dati sono memorizzati in molti schemi specifici per applicazione, le definizioni delle metriche vivono dentro singole dashboard e i team mantengono le proprie versioni di “cos'è un ordine” o “quando un caso è risolto”. Il risultato è noto: numeri diversi in posti diversi, riunioni lente di riconciliazione e proprietà poco chiara quando qualcosa non torna.
Ontologia, spiegata semplicemente
In un approccio in stile Palantir, il livello semantico non è solo una comodità per il reporting. Un'ontologia agisce come modello di business condiviso che definisce:
- Entità (cose che interessano al business): Order, Customer, Asset, Shipment, Case
- Relazioni (come queste cose si collegano): un Order appartiene a un Customer; una Shipment evasione di un Order; un Asset è installato in un Site
- Azioni (cosa le persone fanno con loro): approve, dispatch, escalate, retire, refund
Questo diventa il “centro di gravità” per analisi e operazioni: più sorgenti dati possono esistere, ma mappano in un insieme comune di oggetti di business con definizioni coerenti.
Perché la semantica conta più di quanto si pensi
Un modello condiviso riduce i numeri discordanti perché i team non reinventano le definizioni in ogni report o app. Migliora anche la responsabilità: se “Consegna puntuale” è definita rispetto agli eventi Shipment nell'ontologia, è più chiaro chi possiede i dati sottostanti e la logica di business.
Esempi pratici
- Ordini: Sales, finance e support vedono lo stesso oggetto Order, inclusi stato, valore, approvazioni ed eccezioni — niente “tabelle ordini” separate per reparto.\n- Asset: manutenzione, operations e compliance condividono un unico record Asset con ubicazione, storico ispezioni e flag di rischio.\n- Casi: i casi di supporto sono collegati a clienti, ordini e spedizioni, così le regole di escalation e le metriche di servizio non si allontanano tra team.
Fatto bene, un'ontologia non pulisce solo i dashboard — rende le decisioni quotidiane più rapide e meno controverse.
Analisi operativa vs dashboard BI
I dashboard BI e il reporting tradizionale riguardano soprattutto il retrospettivo e il monitoraggio. Rispondono a domande come “Cosa è successo la settimana scorsa?” o “Siamo in linea con i KPI?” Un dashboard vendite, un report di chiusura finanziaria o una scorecard esecutiva sono preziosi — ma spesso si fermano alla visibilità.
L'analisi operativa è diversa: è analisi incorporata nelle decisioni e nell'esecuzione quotidiana. Invece di un “luogo di analisi” separato, l'analisi appare dentro il workflow dove il lavoro è svolto e guida il passo successivo specifico.
BI: osservare e spiegare
Il BI/reporting solitamente si concentra su:
- Metriche standardizzate e definizioni di KPI
- Aggiornamenti schedulati e revisioni settimanali/mensili
- Visualizzazioni aggregate (team, regioni, intervalli temporali)
- Esplorazioni di root‑cause dopo che l'esito è noto
Questo è eccellente per governance, gestione delle performance e accountability.
Analisi operativa: decidere e fare
L'analisi operativa si concentra su:
- Segnali in tempo reale o quasi
- Supporto decisionale nel momento dell'azione
- Raccomandazioni, prioritarizzazione e gestione delle eccezioni
- Loop di feedback (l'azione ha funzionato e cosa è cambiato?)
Esempi concreti somigliano meno a “un grafico” e più a una coda di lavoro con contesto:
- Dispatching: scegliere quale intervento mandare a quale squadra dato posizione, competenze, SLA e disponibilità parti
- Allocazione inventario: decidere dove inviare scorte limitate per ridurre backorder e mancate consegne
- Triage frodi: ordinare i casi per rischio e instradarli agli investigatori con le prove allegate
- Programmazione manutenzione: prevedere guasti e schedulare fermate compatibilmente con la produzione
Il cambiamento chiave: da “vedere” a “agire”
Il cambiamento più importante è che l'analisi è legata a uno step di workflow specifico. Un dashboard BI può mostrare “le consegne in ritardo sono aumentate.” L'analisi operativa lo trasforma in “ecco le 37 spedizioni a rischio oggi, le cause probabili e le azioni raccomandate,” con la possibilità di eseguire o assegnare il passo successivo immediatamente.
Dagli insight alle azioni: design centrato sul workflow
L'analisi enterprise tradizionale spesso finisce con una vista dashboard: qualcuno nota un problema, esporta in CSV, manda una email e un team separato “fa qualcosa” più tardi. Un approccio in stile Palantir è progettato per accorciare quel divario incorporando l'analisi direttamente nel workflow dove si prendono le decisioni.
Decisioni human-in-the-loop (non autopilot)
I sistemi centrati sui workflow tipicamente generano raccomandazioni (es. “priorizza queste 12 spedizioni”, “segnala questi 3 fornitori”, “programma manutenzione entro 72 ore”) ma richiedono comunque approvazioni esplicite. Quel passo di approvazione conta perché crea:
- Responsabilità decisionale: chi ha approvato, quando e basandosi su quali dati
- Tracce di audit: una catena registrata da dati di input → logica/modello → raccomandazione → azione
- Eccezioni controllate: gli operatori possono sovrascrivere con una motivazione, invece di aggirare lo strumento
Questo è particolarmente utile in operazioni regolamentate o ad alto rischio dove “il modello l'ha detto” non è una giustificazione accettabile.
I workflow rimpiazzano il “passaggio del report”
Invece di trattare l'analisi come una destinazione separata, l'interfaccia può indirizzare gli insight in compiti: assegnare a una coda, richiedere firma, inviare una notifica, aprire un caso o creare un ordine di lavoro. Lo spostamento importante è che gli esiti sono tracciati nello stesso sistema — così puoi misurare se le azioni hanno effettivamente ridotto rischio, costi o ritardi.
Esperienze basate sui ruoli e diritti decisionali
Il design centrato sul workflow di solito separa le esperienze per ruolo:
- Operatori di prima linea: code veloci, next‑best action chiara, minimo contesto necessario
- Analisti: drill‑down più profondi, test di scenario e monitoraggio qualità dati/modelli
- Esecutivi: KPI legati al throughput operativo e ai colli di bottiglia, non solo ai grafici
Il fattore di successo comune è allineare il prodotto con i diritti decisionali e le procedure operative: chi può agire, quali approvazioni servono e cosa significa “fatto” operativamente.
Governance, sicurezza e fiducia nei dati
Rendi coerente il significato
Modella Orders, Assets e Cases come oggetti condivisi che i tuoi team possono riutilizzare.
La governance è dove molti programmi di analytics vincono o si bloccano. Non è solo “impostazioni di sicurezza” — è l'insieme pratico di regole ed evidenze che permette alle persone di fidarsi dei numeri, condividerli in sicurezza e usarli per prendere decisioni reali.
Cosa deve coprire la governance (oltre il login)
La maggior parte delle imprese ha bisogno degli stessi controlli base, indipendentemente dal fornitore:
- Controlli di accesso: chi può vedere, modificare o approvare dati, modelli e output operativi
- Lineage dei dati: da dove proviene una metrica, quali sorgenti l'hanno alimentata e quali trasformazioni sono state applicate
- Log di audit: un registro difendibile di chi ha cambiato cosa e quando
- Approvazioni e change control: specialmente per metriche “ufficiali”, dataset condivisi e workflow di produzione
Questi non sono burocrazia fine a sé stessa. Sono il modo per evitare il problema delle “due versioni della verità” e ridurre il rischio quando l'analisi si avvicina alle operazioni.
“Sicurezza nella dashboard” vs sicurezza in tutta la catena
Le implementazioni BI tradizionali spesso mettono la sicurezza principalmente al livello del report: gli utenti possono vedere certe dashboard e gli amministratori gestiscono i permessi lì. Questo può funzionare quando l'analisi è principalmente descrittiva.
Un approccio in stile Palantir spinge la sicurezza e la governance attraverso tutta la pipeline: dall'ingest dei dati grezzi, al livello semantico (oggetti, relazioni, definizioni), ai modelli e persino alle azioni scatenate dagli insight. L'obiettivo è che una decisione operativa erediti gli stessi controlli dei dati che la alimentano.
Minimo privilegio e segregazione dei compiti (in parole semplici)
Due principi contano per sicurezza e responsabilità:
- Minimo privilegio: le persone ottengono solo l'accesso di cui hanno bisogno per fare il loro lavoro
- Segregazione dei compiti: chi costruisce o cambia la logica non è la stessa persona che l'approva per l'uso in produzione
Per esempio, un analista può proporre una definizione di metrica, uno steward dei dati la approva e le operations la usano — con una traccia di audit chiara.
Perché la governance guida l'adozione
Una buona governance non è solo per i team di compliance. Quando gli utenti business possono cliccare il lineage, vedere le definizioni e contare su permessi coerenti, smettono di litigare sul foglio di calcolo e iniziano ad agire sugli insight. Questa fiducia trasforma l'analisi da “report interessanti” a comportamento operativo.
Modelli di deployment: cloud, on‑prem e ambienti disconnessi
Dove gira il software enterprise non è più una questione solo IT — plasma quello che puoi fare con i dati, quanto velocemente puoi cambiare e quali rischi puoi accettare. I buyer solitamente valutano quattro pattern di deployment.
Public cloud
Il public cloud (AWS/Azure/GCP) ottimizza per velocità: il provisioning è rapido, i servizi gestiti riducono il lavoro infrastrutturale e la scalabilità è semplice. Le domande principali per chi compra sono la residenza dei dati (quale regione, quale backup, quale accesso del supporto), l'integrazione con sistemi on‑prem e se il tuo modello di sicurezza può tollerare la connettività di rete in cloud.
Private cloud
Un private cloud (single‑tenant o Kubernetes/VM gestiti dal cliente) è spesso scelto quando si desidera automazione in stile cloud ma con confini di rete e requisiti di audit più stretti. Può ridurre qualche frizione di compliance, ma richiede comunque disciplina operativa su patching, monitoraggio e revisioni accessi.
On‑prem
Gli ambienti on‑prem restano comuni in manufacturing, energia e settori altamente regolamentati dove i sistemi core e i dati non possono lasciare la struttura. Il compromesso è l'overhead operativo: ciclo di vita hardware, pianificazione della capacità e più lavoro per mantenere gli ambienti coerenti tra dev/test/prod. Se l'organizzazione fatica a gestire piattaforme affidabili, l'on‑prem può rallentare il time‑to‑value.
Disconnesso / air‑gapped
Gli ambienti disconnessi (air‑gapped) sono un caso speciale: difesa, infrastrutture critiche o siti con connettività limitata. Qui il modello di deployment deve supportare controlli stretti sugli aggiornamenti — artifact firmati, promozione controllata delle release e installazioni ripetibili in reti isolate.
I vincoli di rete influenzano anche il movimento dei dati: invece di sync continuo, potresti fare affidamento su trasferimenti a fasi e flussi “export/import”.
I compromessi chiave
In pratica è un triangolo: flessibilità (cloud), controllo (on‑prem/air‑gapped) e velocità di cambiamento (automazione + aggiornamenti). La scelta giusta dipende da regole di residenza, realtà di rete e da quanto operation della piattaforma il tuo team è disposto a gestire.
Operationalizzare gli aggiornamenti: cosa cambia una delivery in stile Apollo
Prototipa un pilot di workflow
Trasforma un singolo flusso operativo in un'app funzionante a partire da una conversazione in chat.
“La delivery in stile Apollo” è fondamentalmente continuous delivery per ambienti ad alto rischio: puoi spedire miglioramenti frequentemente (settimanali, giornalieri, anche più volte al giorno) mantenendo stabile l'operatività.
L'obiettivo non è “muoversi velocemente e rompere le cose.” È “muoversi spesso e non rompere nulla.”
Continuous delivery in parole semplici
Invece di accumulare le modifiche in un grande rilascio trimestrale, i team consegnano aggiornamenti piccoli e reversibili. Ogni aggiornamento è più facile da testare, spiegare e ripristinare se qualcosa va storto.
Per l'analisi operativa questo conta perché il tuo “software” non è solo UI — sono pipeline dati, logica di business e i workflow su cui le persone fanno affidamento. Un processo di aggiornamento più sicuro diventa parte delle operazioni quotidiane.
Come questo si differenzia dai cicli enterprise tradizionali
Gli aggiornamenti del software enterprise tradizionale spesso somigliano a progetti: finestre di pianificazione lunghe, coordinamento dei downtime, problemi di compatibilità, riqualificazione e una data di cutover netta. Anche quando i vendor offrono patch, molte organizzazioni posticipano gli aggiornamenti perché rischio e sforzo sono imprevedibili.
Gli strumenti in stile Apollo mirano a rendere l'aggiornamento di routine piuttosto che eccezionale — più simile a mantenere l'infrastruttura che a eseguire una migrazione importante.
Separare il “costruire” dallo “spedire”
Il tooling moderno permette ai team di sviluppare e testare in ambienti isolati, poi “promuovere” la stessa build attraverso stadi (dev → test → staging → produzione) con controlli coerenti. Questa separazione aiuta a ridurre sorprese dell'ultimo minuto causate da differenze tra ambienti.
Domande da porre al vendor
- Come gestite il rollback — con un click, rollback parziale o passi di recupero complessi?\n- Che versioning esiste per pipeline, modelli e cambiamenti ontologici (non solo per la UI)?\n- Come funziona la promozione degli ambienti e chi può approvarla?\n- È possibile eseguire canary release (prima un sottoinsieme) o usare feature flag?\n- Quale audit trail mostra chi ha spedito cosa, quando e perché?\n- Qual è il downtime previsto — idealmente nullo — per aggiornamenti tipici?
Implementazione e time‑to‑value: cosa richiede veramente sforzo
Il time‑to‑value è meno su quanto rapidamente puoi “installare” qualcosa e più su quanto velocemente i team riescono a concordare definizioni, connettere dati disordinati e trasformare gli insight in decisioni quotidiane.
Stili di implementazione: configurare, assemblare o costruire
Il software enterprise tradizionale spesso enfatizza la configurazione: adotti un modello dati e workflow predefiniti e mappi il tuo business in essi.
Le piattaforme in stile Palantir tendono a mescolare tre modalità:
- Configurazione per controlli di accesso, connessioni dati e componenti standard\n- Blocchi riutilizzabili (template, componenti, pattern) che si assemblano in nuovi casi d'uso\n- Sviluppo applicativo personalizzato quando il workflow è unico (es. approvazioni, gestione eccezioni, handoff operativi)
La promessa è flessibilità — ma signifca anche che serve chiarezza su cosa stai costruendo rispetto a cosa stai standardizzando.
Una opzione pratica durante la discovery è prototipare app workflow rapidamente — prima di impegnarsi in un rollout di piattaforma. Ad esempio, i team a volte usano Koder.ai (una piattaforma vibe‑coding) per trasformare la descrizione di un workflow in una web app funzionante via chat, poi iterare con gli stakeholder usando planning mode, snapshots e rollback. Poiché Koder.ai supporta export del codice sorgente e stack di produzione comuni (React per il web; Go + PostgreSQL per il backend; Flutter per il mobile), può essere un modo a basso attrito per validare l'UX “insight → task → audit trail” e i requisiti di integrazione durante un proof‑of‑value.
Dove i team spendono veramente tempo
La maggior parte dello sforzo va di solito in quattro aree:
- Onboarding dei dati: ottenere l'accesso dai proprietari delle sorgenti, documentare i campi, gestire gap di qualità e impostare aspettative di refresh\n2. Modeling e semanticità: concordare definizioni di business (cosa conta come “attivo”, “in ritardo”, “disponibile”) e mantenerle coerenti\n3. Design dei workflow: decidere chi agisce sulle allerte, quali decisioni sono consentite e cosa significa “fatto”\n4. Formazione e adozione: trasformare uno strumento in una abitudine — specialmente per gli operatori di prima linea che non tollerano complessità
Segnali d'allarme che rallentano o uccidono il valore
Fai attenzione a proprietà non chiara (nessun owner dati/prodotto responsabile), troppe definizioni ad hoc (ogni team inventa le proprie metriche) e nessun percorso da pilot a scala (una demo che non può essere operazionalizzata, supportata o governata).
Strutturare un pilot che possa scalare
Un buon pilot è intenzionalmente ristretto: scegli un workflow, definisci utenti specifici e impegnati su un risultato misurabile (es. ridurre i tempi di risposta del 15%, tagliare il backlog delle eccezioni del 30%). Progetta il pilot in modo che gli stessi dati, semantiche e controlli possano estendersi al caso d'uso successivo — invece di ricominciare da zero.
Le conversazioni sui costi possono confondere perché una “piattaforma” raggruppa capacità che spesso si acquistano come strumenti separati. La chiave è mappare i prezzi agli outcome che servono (integrazione + modellazione + governance + app operative), non solo a una voce chiamata “software”.
La maggior parte degli accordi di piattaforma è plasmata da poche variabili:
- Numero di utenti e ruoli: builder (ingegneri, modeler) vs consumer (operatori, analisti)\n- Compute e storage: workload pesanti (dati in tempo reale, simulazioni, join ampi) aumentano i costi infrastrutturali\n- Numero di ambienti: dev/test/prod, più ambienti regolamentati o disconnessi aggiungono overhead\n- Requisiti di supporto e uptime: supporto 24/7, SLA incidenti e team di success dedicati cambiano il prezzo\n- Servizi professionali: onboarding iniziale dei dati, design dell'ontologia e sviluppo dei workflow spesso sono il vero driver di costo iniziale
Cosa nascondono i costi dello stack tradizionale
Un approccio a soluzioni point può sembrare più economico all'inizio, ma il costo totale tende a distribuirsi su:
- Licenze multiple (ETL/ELT, BI, catalogo, governance, workflow, feature store, ecc.)\n- Lavoro di integrazione tra strumenti (connettori, identità, sincronizzazione permessi/metadata)\n- Manutenzione continua (upgrade, pipeline rotte, definizioni metriche duplicate)
Le piattaforme spesso riducono lo sprawl degli strumenti, ma si scambia con un contratto più grande e strategico.
Con una piattaforma, il procurement dovrebbe trattarla come infrastruttura condivisa: definire scope enterprise, domini dati, requisiti di sicurezza e milestone di delivery. Chiedi una separazione chiara tra licenza, cloud/infrastruttura e servizi, così puoi confrontare offerte in modo omogeneo.
Checklist semplice per il budget
- Quali team costruiranno attivamente vs solo consulteranno?\n- Quali workflow devono girare in produzione (non solo dashboard)?\n- Quanti ambienti e regioni servono?\n- Ci sono siti air‑gapped o offline?\n- Crescita prevista di volume dati/frequenza di refresh?\n- Servizi necessari per i primi 90 giorni?
Se vuoi un modo rapido per strutturare le assunzioni, consulta /pricing.
Quando gli approcci in stile Palantir sono adatti (e quando no)
Prova Koder.ai oggi
Usa il piano gratuito per testare il primo workflow senza una lunga configurazione.
Le piattaforme in stile Palantir tendono a brillare quando il problema è operativo (le persone devono prendere decisioni e agire attraverso sistemi), non solo analitico (le persone hanno bisogno di un report). Il compromesso è che si adotta uno stile più “piattaforma” — potente, ma che chiede di più all'organizzazione rispetto a un semplice rollout BI.
Scenari ad alta affinità
Un approccio in stile Palantir è solitamente adatto quando il lavoro attraversa più sistemi e team e non ci si può permettere passaggi fragili.
Esempi comuni includono operazioni cross‑system come coordinamento supply chain, operazioni anti‑frode e rischio, pianificazione missioni, gestione casi o workflow di fleet e manutenzione — dove gli stessi dati devono essere interpretati coerentemente da ruoli diversi.
Si adatta bene anche quando le autorizzazioni sono complesse (accesso riga/colonna, dati multi‑tenant, regole need‑to‑know) e quando serve una traccia chiara di come i dati sono stati usati. Infine, è adatto in ambienti regolamentati o vincolati: requisiti on‑prem, deploy air‑gapped/disconnessi o accreditamenti di sicurezza stringenti.
Scenari meno adatti
Se l'obiettivo è principalmente reporting semplice — KPI settimanali, poche dashboard, rollup finanziari di base — il BI tradizionale su un warehouse ben gestito può essere più rapido e meno costoso.
Può anche essere eccessivo per dataset piccoli, schemi stabili o analisi di un singolo dipartimento dove un team controlla sorgenti e definizioni e l'azione principale avviene fuori dallo strumento.
Criteri decisionali (fit al problema)
Fatti tre domande pratiche:
- Urgenza: i team hanno bisogno di workflow funzionanti in settimane, o è un programma di modernizzazione a lungo termine?\n- Complessità dati: decisioni chiave sono bloccate da definizioni incoerenti e sistemi sorgente frammentati?\n- Capacità di cambiamento: avete ownership di prodotto, SME e banda di governance per adottare una piattaforma e mantenerla aggiornata?
I migliori risultati vengono dal trattare questo come “adeguato al problema”, non come “uno strumento che sostituisce tutto”. Molte organizzazioni mantengono BI esistente per il reporting generale mentre usano un approccio in stile Palantir per i domini operativi più critici.
Checklist per l'acquirente e prossimi passi
Comprare una piattaforma “in stile Palantir” vs software enterprise tradizionale riguarda meno i checkbox di funzionalità e più il posto dove realmente ricadrà il lavoro: integrazione, significato condiviso (semantica) e uso operativo quotidiano. Usa la checklist qui sotto per chiarire le cose in anticipo, prima di bloccarti in una lunga implementazione o in uno strumento point.
Checklist pratica di confronto vendor
Chiedi a ogni vendor di essere specifico su chi fa cosa, come rimane coerente e come viene usato in operazioni reali.
- Sforzo di integrazione: quali sorgenti dati sono tipiche (ERP, log, fogli di calcolo, feed partner)? Cosa è pre‑built vs custom? Chi mantiene le pipeline dopo il go‑live — IT, data engineering o il vendor?\n- Coerenza semantica: come impediscono a cinque team di definire “customer”, “asset” o “mission‑ready” in modo diverso? Possono mostrare un livello business governato (ontologia/modello semantico) e come le modifiche si propagano?\n- Supporto workflow: i team di front line possono completare un task (triage, approva, dispatch, investigare) dentro il prodotto, o è “analizza qui, agisci altrove”? Come gestiscono le eccezioni?\n- Governance e sicurezza: controlli di accesso granulari, log di audit e policy management — i proprietari dei dati possono decidere chi vede cosa, a quale granularità e perché?\n- Vincoli di deployment: può eseguire nell'ambiente richiesto (cloud, on‑prem, air‑gapped/disconnesso)? Cosa smette di funzionare quando la connettività è limitata? Qual è il percorso di upgrade?
Domande prova per le demo (non accettare slide)
- Mostra il lineage: scegli un KPI critico e traccialo dalla sorgente alla metrica finale. Dove può sbagliare e come lo rileveresti?\n2. Dimostra un workflow end‑to‑end: parti dai dati grezzi, poi alert → decisione → azione → audit trail. Includi approvazioni e “chi ha cambiato cosa”.\n3. Simula un outage/rollback: cosa succede se una pipeline fallisce o una release causa regressione? Possono rollbackare pulitamente e con quale rapidità?
Chi mettere in stanza
Includi stakeholder che vivranno i compromessi:
- IT e owner della piattaforma (ownership integrazione, affidabilità, costi)\n- Sicurezza e compliance (controlli, auditing, approvazioni di deployment)\n- Proprietari/steward dei dati (definizioni, regole di accesso, responsabilità)\n- Leader operativi (impatto sui processi, adozione)\n- Utenti di prima linea (li aiuta davvero a fare il lavoro più velocemente?)
Prossimi passi
Esegui un proof‑of‑value a tempo limitato centrato su un workflow operativo ad alto impatto (non un dashboard generico). Definisci i criteri di successo in anticipo: tempo‑to‑decisione, riduzione errori, auditabilità e ownership del lavoro dati continuo.
Se vuoi ulteriore guida sui pattern di valutazione, consulta /blog. Per aiuto nel definire un proof‑of‑value o una shortlist di vendor, contatta /contact.