Perché le app real-time sembrano lente anche quando il codice è veloce
La velocità ha due facce: throughput e latenza. Il throughput è quanto lavoro esegui al secondo (richieste, messaggi, frame). La latenza è quanto tempo impiega una singola unità di lavoro dall'inizio alla fine.
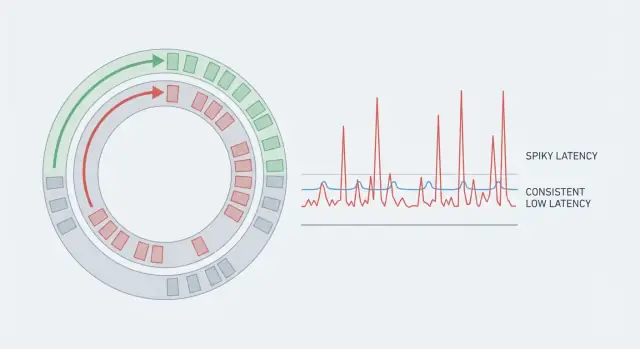
Un sistema può avere ottimo throughput e comunque sembrare lento se alcune richieste richiedono molto più tempo di altre. Ecco perché le medie ingannano. Se 99 azioni impiegano 5 ms e un'azione ne impiega 80, la media sembra accettabile, ma chi incappa nel caso da 80 ms percepisce lo stutter. Nei sistemi real-time, quegli spike rari sono tutta la storia perché rompono il ritmo.
Latenza prevedibile significa che non miri solo a una media bassa. Miri alla coerenza, così la maggior parte delle operazioni termina in un intervallo ristretto. Per questo i team guardano la coda (p95, p99). È lì che si nascondono le pause.
Un picco di 50 ms può contare in contesti come voce e video (scatti audio), giochi multiplayer (rubber-banding), trading in tempo reale (prezzi persi), monitoraggio industriale (allarmi in ritardo) e dashboard live (i numeri saltano, gli avvisi sembrano inaffidabili).
Un esempio semplice: un'app di chat può consegnare i messaggi velocemente la maggior parte delle volte. Ma se una pausa in background fa arrivare un messaggio con 60 ms di ritardo, gli indicatori di digitazione sfarfallano e la conversazione sembra lenta anche se il server appare “veloce” in media.
Se vuoi che il real-time sembri reale, hai bisogno di meno sorprese, non solo di codice più veloce.
Basi sulla latenza: dove va davvero il tempo
La maggior parte dei sistemi real-time non sono lenti perché la CPU è affaticata. Sembrano lenti perché il lavoro passa la maggior parte della sua vita in attesa: in attesa di essere schedulato, in coda, in attesa sulla rete o in attesa dello storage.
La latenza end-to-end è il tempo totale da “qualcosa è successo” a “l'utente vede il risultato”. Anche se il tuo handler gira in 2 ms, la richiesta può comunque impiegare 80 ms se si interrompe in cinque posti diversi.
Un modo utile per spezzare il percorso è:
- Tempo di rete (client verso edge, servizio a servizio, retry)
- Tempo di scheduling (il tuo thread aspetta di essere eseguito)
- Tempo in coda (il lavoro è dietro altro lavoro)
- Tempo di storage (disco, lock su DB, cache miss)
- Tempo di serializzazione (codifica e decodifica dei dati)
Queste attese si sommano. Alcuni millisecondi qua e là trasformano un percorso “veloce” in un'esperienza lenta.
La latenza di coda è dove gli utenti iniziano a lamentarsi. La latenza media può sembrare ok, ma p95 o p99 rappresentano il 5% o l'1% più lento delle richieste. Gli outlier spesso vengono da pause rare: un ciclo di GC, un vicino rumoroso sull'host, contesa di lock, un refill della cache o un burst che crea una coda.
Esempio concreto: un aggiornamento di prezzo arriva in rete in 5 ms, aspetta 10 ms per un worker occupato, passa 15 ms dietro altri eventi, poi incontra uno stall sul database per 30 ms. Il tuo codice è ancora eseguito in 2 ms, ma l'utente ha atteso 62 ms. L'obiettivo è rendere ogni fase prevedibile, non solo la computazione veloce.
Le fonti usuali di jitter oltre la velocità del codice
Un algoritmo veloce può comunque sembrare lento se il tempo per richiesta oscilla. Gli utenti notano i picchi, non le medie. Questa oscillazione è jitter, e spesso viene da cose che il tuo codice non controlla completamente.
La cache CPU e il comportamento della memoria sono costi nascosti. Se i dati "caldi" non entrano nella cache, la CPU si blocca aspettando la RAM. Strutture ricche di oggetti, memoria dispersa e “solo un lookup in più” possono trasformarsi in miss di cache ripetuti.
L'allocazione di memoria aggiunge casualità. Allocare molti oggetti a vita breve aumenta la pressione sul heap, che poi emerge come pause (garbage collection) o contesa sull'allocatore. Anche senza GC, allocazioni frequenti possono frammentare la memoria e danneggiare la località.
Lo scheduling dei thread è un'altra fonte comune. Quando un thread viene deschedulato, paghi il costo del context switch e perdi la "warmth" della cache. Su una macchina occupata, il tuo thread “real-time” può aspettare dietro lavoro non correlato.
La contesa sui lock è dove i sistemi prevedibili spesso crollano. Un lock “di solito libero” può trasformarsi in un convoglio: i thread si risvegliano, lottano per il lock e si rimettono a dormire a vicenda. Il lavoro viene comunque svolto, ma la latenza di coda si allunga.
Le attese di I/O possono sovrastare tutto il resto. Una singola syscall, un buffer di rete pieno, un handshake TLS, un flush su disco o una lookup DNS lenta possono creare un picco netto che nessuna micro-ottimizzazione risolverà.
Se stai cercando jitter, inizia guardando i miss di cache (spesso causati da strutture a puntatori e accesso casuale), le allocazioni frequenti, i context switch dovuti a troppi thread o vicini rumorosi, la contesa sui lock e qualsiasi I/O bloccante (rete, disco, logging, chiamate sincrone).
Esempio: un servizio ticker di prezzi può calcolare aggiornamenti in microsecondi, ma una chiamata al logger sincronizzato o un lock conteso per le metriche può occasionalmente aggiungere decine di millisecondi.
Martin Thompson e cos'è il pattern Disruptor
Martin Thompson è noto nell'ingegneria a bassa latenza per il suo focus su come i sistemi si comportano sotto pressione: non solo velocità media, ma velocità prevedibile. Insieme al team LMAX ha contribuito a popolarizzare il pattern Disruptor, un approccio di riferimento per muovere eventi attraverso un sistema con ritardi piccoli e coerenti.
L'approccio Disruptor risponde a ciò che rende molte app “veloci” imprevedibili: contesa e coordinazione. Le code tipiche spesso si affidano a lock o atomiche pesanti, risvegliano i thread continuamente e creano esplosioni di attesa quando produttori e consumatori si contendono strutture condivise.
Invece di una coda, Disruptor usa un ring buffer: un array circolare a dimensione fissa che contiene eventi in slot. I produttori reclamano lo slot successivo, scrivono i dati e poi pubblicano un numero di sequenza. I consumatori leggono in ordine seguendo quella sequenza. Poiché il buffer è preallocato, si evitano allocazioni frequenti e si riduce la pressione sul garbage collector.
Un'idea chiave è il principio del single-writer: mantenere un singolo componente responsabile di un dato pezzo di stato condiviso (per esempio, il cursore che avanza nel ring). Meno scrittori significa meno momenti di “chi va dopo?”.
Il backpressure è esplicito. Quando i consumatori restano indietro, i produttori alla fine raggiungono uno slot ancora in uso. A quel punto il sistema deve aspettare, scartare o rallentare, ma lo fa in modo controllato e visibile invece di nascondere il problema dentro una coda che cresce senza limiti.
Idee di design fondamentali che mantengono la latenza consistente
Ciò che rende veloci i design in stile Disruptor non è una micro-ottimizzazione geniale. È eliminare le pause imprevedibili che si verificano quando un sistema lotta con le proprie parti in movimento: allocazioni, miss di cache, contesa sui lock e lavoro lento nel percorso caldo.
Un modello mentale utile è una linea di montaggio. Gli eventi si muovono attraverso un percorso fisso con consegne chiare. Questo riduce lo stato condiviso e rende ogni passaggio più facile da mantenere semplice e misurabile.
Mantieni memoria e dati prevedibili
I sistemi veloci evitano allocazioni a sorpresa. Se preallocchi buffer e riusi oggetti messaggio, riduci gli spike “a volte” causati dalla garbage collection, dalla crescita dell'heap e dai lock dell'allocatore.
Aiuta anche mantenere i messaggi piccoli e stabili. Quando i dati toccati per evento stanno nella cache CPU, passi meno tempo in attesa della memoria.
In pratica, le abitudini che contano di più sono: riusare oggetti invece di crearne di nuovi per evento, mantenere i dati degli eventi compatti, preferire un singolo scrittore per lo stato condiviso e batchare con attenzione in modo da pagare i costi di coordinazione meno spesso.
Rendi i percorsi lenti evidenti
Le app real-time spesso richiedono extra come logging, metriche, retry o scritture su DB. La mentalità Disruptor è isolare queste operazioni dal loop principale così non possono bloccarlo.
In un feed di prezzi live, il percorso caldo potrebbe solo validare un tick e pubblicare il prossimo snapshot di prezzo. Qualunque cosa possa stallare (disco, chiamate di rete, serializzazione pesante) viene spostata su un consumer separato o su un canale laterale, così il percorso prevedibile rimane prevedibile.
Scelte architetturali per una latenza prevedibile
La latenza prevedibile è soprattutto un problema di architettura. Puoi avere codice veloce e comunque avere spike se troppi thread lottano per gli stessi dati, o se i messaggi rimbalzano attraverso la rete senza motivo.
Inizia decidendo quanti writer e reader toccano la stessa coda o buffer. Un singolo produttore è più facile da mantenere fluido perché evita il coordinamento. Configurazioni multi-producer possono aumentare il throughput, ma spesso aggiungono contesa e rendono i tempi nel peggior caso meno prevedibili. Se hai bisogno di più produttori, riduci le scritture condivise shardando gli eventi per chiave (per esempio per userId o instrumentId) così ogni shard ha il proprio percorso caldo.
Dal lato consumer, un singolo consumer dà il timing più stabile quando l'ordine è importante, perché lo stato resta locale a un thread. I pool di worker aiutano quando i task sono veramente indipendenti, ma aggiungono ritardi di scheduling e possono riordinare il lavoro a meno che tu non sia attento.
Il batching è un altro compromesso. Batch piccoli riducono l'overhead (meno wakeup, meno miss di cache), ma il batching può anche aggiungere attesa se tenete gli eventi per riempire un batch. Se fai batching in un sistema real-time, limita il tempo di attesa (per esempio: “fino a 16 eventi o 200 microsecondi, quello che arriva prima”).
I confini di servizio contano anche. La messaggistica in-process è di solito la scelta migliore quando serve latenza stretta. Gli hop di rete valgono la pena per scalare, ma ogni hop aggiunge code, retry e ritardo variabile. Se hai bisogno di un hop, mantieni il protocollo semplice ed evita fan-out nel percorso caldo.
Una serie di regole pratiche: mantieni un singolo writer per shard quando puoi, scala shardando le chiavi invece di condividere una coda calda, batcha solo con un limite di tempo rigoroso, aggiungi pool di worker solo per lavori paralleli e indipendenti, e tratta ogni hop di rete come una potenziale fonte di jitter finché non lo hai misurato.
Passo dopo passo: progettare una pipeline a bassa varianza
Inizia con un budget di latenza scritto prima di toccare il codice. Scegli un obiettivo (come deve sentirsi “buono”) e un p99 (sotto cui devi restare). Dividi quel numero tra stadi come input, validazione, matching, persistenza e aggiornamenti outbound. Se uno stadio non ha budget, non ha limiti.
Poi disegna il flusso dati completo e marca ogni handoff: confini di thread, code, hop di rete e chiamate di storage. Ogni handoff è un posto dove si nasconde il jitter. Quando li vedi, puoi ridurli.
Un workflow che mantiene il design onesto:
- Scrivi un budget per stadio (target e p99), più un piccolo buffer per incognite.
- Mappa la pipeline e etichetta code, lock, allocazioni e chiamate bloccanti.
- Scegli un modello di concorrenza che puoi ragionare (single writer, worker partizionati per chiave o un thread I/O dedicato).
- Definisci la forma del messaggio presto: schemi stabili, payload compatti e copie minime.
- Decidi le regole di backpressure in anticipo: drop, delay, degradare o shed load. Rendilo visibile e misurabile.
Poi decidi cosa può essere asincrono senza rompere l'esperienza utente. Una regola semplice: tutto ciò che cambia ciò che l'utente vede “ora” resta sul percorso critico. Tutto il resto si sposta fuori.
Analytics, log di audit e indicizzazione secondaria spesso possono essere spostati fuori dal percorso caldo. Validazione, ordinamento e passaggi necessari a produrre il prossimo stato di solito non possono esserlo.
Scelte runtime e OS che influenzano la latenza di coda
Il codice veloce può comunque sembrare lento quando il runtime o il sistema operativo mettono in pausa il tuo lavoro al momento sbagliato. L'obiettivo non è solo alto throughput. Sono meno sorprese nell'1% più lento delle richieste.
I runtime con garbage collection (JVM, Go, .NET) possono essere ottimi per produttività, ma possono introdurre pause quando la memoria necessita pulizia. I collector moderni sono molto migliori di una volta, ma la latenza di coda può ancora saltare se crei molti oggetti a vita corta sotto carico. Linguaggi senza GC (Rust, C, C++) evitano le pause da GC, ma spostano il costo nella disciplina di ownership e allocazione manuale. In ogni caso, il comportamento della memoria conta tanto quanto la velocità della CPU.
L'abitudine pratica è semplice: trova dove avvengono le allocazioni e rendile noiose. Riusare oggetti, pre-dimensionare buffer ed evitare di trasformare dati caldi in stringhe o map temporanee.
Le scelte di threading si manifestano anch'esse come jitter. Ogni coda extra, hop asincrono o handoff di pool aggiunge attesa e aumenta la varianza. Preferisci un numero piccolo di thread long-lived, mantieni chiari i confini produttore-consumatore ed evita chiamate bloccanti nel percorso caldo.
Alcune impostazioni OS e container spesso decidono se la tua coda è pulita o a scatti. Throttling CPU per limiti stretti, vicini rumorosi su host condivisi e logging/metriche posizionate male possono creare rallentamenti improvvisi. Se cambi una sola cosa, inizia misurando il tasso di allocazione e i context switch durante i picchi di latenza.
Dati, storage e confini di servizio senza pause a sorpresa
Molti spike di latenza non sono “codice lento”. Sono attese non pianificate: un lock sul DB, una tempesta di retry, una chiamata cross-service che si blocca o un cache miss che diventa un giro completo.
Mantieni il percorso critico corto. Ogni hop extra aggiunge scheduling, serializzazione, code di rete e altri posti dove bloccare. Se puoi rispondere a una richiesta da un processo e un datastore, fallo prima. Dividi in più servizi solo quando ogni chiamata è opzionale o strettamente limitata.
L'attesa limitata è la differenza tra medie veloci e latenza prevedibile. Metti timeout netti sulle chiamate remote e fallisci velocemente quando una dipendenza è malsana. I circuit breaker non servono solo a salvare i server. Limitano quanto a lungo gli utenti possono restare bloccati.
Quando l'accesso ai dati blocca, separa i percorsi. Le letture spesso vogliono forme indicizzate, denormalizzate e cache-friendly. Le scritture spesso vogliono durabilità e ordinamento. Separandole puoi rimuovere contesa e ridurre il tempo di lock. Se la tua coerenza lo permette, i record append-only (un log di eventi) spesso si comportano più prevedibilmente rispetto ad aggiornamenti in place che scatenano hot-row locking o manutenzione in background.
Una regola semplice per le app real-time: la persistenza non dovrebbe essere sul percorso critico a meno che non sia davvero necessaria per correttezza. Spesso la forma migliore è: aggiorna in memoria, rispondi, poi persisti asincronamente con un meccanismo di replay (come outbox o write-ahead log).
In molte pipeline a ring buffer questo finisce così: pubblica in un buffer in-memory, aggiorna lo stato, rispondi, poi lascia che un consumer separato batta le scritture su PostgreSQL a batch.
Un esempio realistico: aggiornamenti real-time con latenza prevedibile
Immagina un'app di collaborazione live (o un piccolo gioco multiplayer) che invia aggiornamenti ogni 16 ms (circa 60 volte al secondo). L'obiettivo non è “veloce in media”. È “di solito sotto 16 ms”, anche quando la connessione di un utente è scadente.
Un semplice flusso in stile Disruptor appare così: l'input utente diventa un evento piccolo, viene pubblicato in un ring buffer preallocato, poi processato da un insieme fisso di handler in ordine (validate -> apply -> prepare outbound messages), e infine broadcast ai client.
Il batching può aiutare ai bordi. Per esempio, batcha le scritture outbound per client una volta per tick così chiami meno volte lo strato di rete. Ma non batchare dentro il percorso caldo in modo da aspettare “solo un pochino” altri eventi. Aspettare è come mancare il tick.
Quando qualcosa rallenta, trattalo come un problema di contenimento. Se un handler rallenta, isolalo dietro il suo buffer e pubblica un work item leggero invece di bloccare il loop principale. Se un client è lento, non lasciare che intasi il broadcaster; dà a ogni client una piccola coda di invio e scarta o coalesci aggiornamenti vecchi così mantieni lo stato più recente. Se la profondità dei buffer cresce, applica backpressure al bordo (smetti di accettare input extra per quel tick o degrada funzionalità).
Capisci che funziona quando i numeri restano "noiosi": la profondità del backlog oscilla vicino a zero, eventi scartati/coalescati sono rari e spiegabili, e p99 resta sotto il tuo budget per tick sotto carico realistico.
Errori comuni che creano picchi di latenza
La maggior parte dei picchi di latenza è auto-inflitta. Il codice può essere veloce, ma il sistema si ferma quando aspetta altri thread, l'OS o qualsiasi cosa fuori dalla cache CPU.
Alcuni errori ricorrenti:
- Usare lock condivisi ovunque perché sembra semplice. Un lock conteso può bloccare molte richieste.
- Mescolare I/O lento nel percorso caldo, come logging sincrono, scritture DB o chiamate remote.
- Tenere code non limitate. Nascondono l'overload finché non hai secondi di backlog.
- Guardare le medie invece di p95 e p99.
- Over-tuning prematuro. Pinning dei thread non aiuta se i ritardi vengono da GC, contesa o attesa su una socket.
Un modo rapido per ridurre i picchi è rendere le attese visibili e limitate. Metti il lavoro lento su un percorso separato, limita le code e decidi cosa fare quando sei pieno (scarta, shed, coalesci o applica backpressure).
Checklist rapida per latenza prevedibile
Tratta la latenza prevedibile come una caratteristica di prodotto, non come un caso fortuito. Prima di ottimizzare il codice, assicurati che il sistema abbia obiettivi e guardrail chiari.
- Imposta un target p99 esplicito (e p99.9 se conta), poi scrivi un budget di latenza per stadio.
- Tieni il percorso caldo libero da I/O bloccante. Se l'I/O deve succedere, spostalo su un percorso laterale e decidi cosa fare quando rallenta.
- Usa code con limite e definisci il comportamento di overload (drop, shed load, coalesce o backpressure).
- Misura continuamente: profondità del backlog, tempo per stadio e latenza di coda.
- Minimizza le allocazioni nel loop caldo e rendile facili da individuare nei profili.
Un semplice test: simula un burst (10x traffico normale per 30 secondi). Se p99 esplode, chiediti dove avviene l'attesa: code in crescita, un consumer lento, una pausa di GC o una risorsa condivisa.
Prossimi passi: come applicarlo nella tua app
Tratta il pattern Disruptor come un workflow, non come una scelta libreria. Dimostra la latenza prevedibile con una thin slice prima di aggiungere funzionalità.
Scegli un'azione utente che deve sembrare istantanea (per esempio, “arriva un nuovo prezzo, l'UI si aggiorna”). Scrivi il budget end-to-end, poi misura p50, p95 e p99 fin dal primo giorno.
Una sequenza che funziona spesso:
- Costruisci una pipeline sottile con un input, un core loop e un output. Valida p99 sotto carico presto.
- Rendi esplicite le responsabilità (chi possiede lo stato, chi pubblica, chi consuma) e mantieni lo stato condiviso piccolo.
- Aggiungi concorrenza e buffering a piccoli passi e mantieni le modifiche reversibili.
- Distribuisci vicino agli utenti quando il budget è stretto, poi rimesura sotto carico realistico (stesse dimensioni di payload, stessi pattern di burst).
Se stai costruendo su Koder.ai (koder.ai), può aiutare mappare prima il flusso degli eventi in Planning Mode così code, lock e confini di servizio non compaiono per caso. Snapshot e rollback rendono anche più facile eseguire esperimenti ripetuti sulla latenza e annullare cambiamenti che migliorano il throughput ma peggiorano p99.
Mantieni le misurazioni oneste. Usa uno script di test fisso, riscalda il sistema e registra sia throughput sia latenza. Quando p99 salta con il carico, non cominciare subito con “ottimizziamo il codice”. Cerca pause dovute a GC, vicini rumorosi, esplosioni di logging, scheduling dei thread o chiamate bloccanti nascoste.