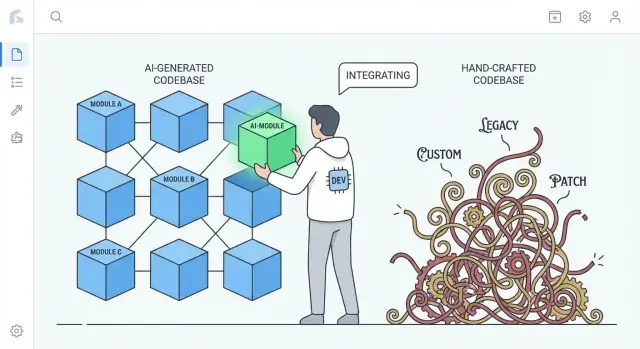
Cosa significa davvero "più facile da sostituire" nei progetti reali
"Più facile da sostituire" raramente significa cancellare un'intera applicazione e ricominciare da zero. Nei team reali, la sostituzione avviene su scale diverse, e ciò che significa "riscrittura" dipende da cosa stai sostituendo.
Sostituire vs riscrivere: cosa è davvero sul tavolo
Una sostituzione può essere:
- Un modulo (regole di fatturazione, generazione PDF, template email)
- Un servizio (API di raccomandazioni, background worker)
- Una superficie front-end (una pagina, un'area funzionale, o l'intera UI)
- Una riscrittura completa dell'app (raro, costoso, a volte necessario)
Quando si dice che un codebase è "più facile da riscrivere", di solito si intende che puoi ripartire una fetta senza disfare tutto il resto, mantenere il business attivo e migrare gradualmente.
Il confronto reale: generato dall'IA vs codice molto personalizzato
L'argomento non è "il codice IA è migliore". È sulle tendenze comuni.
- Il codice artigianale fortemente personalizzato può accumulare pattern unici, astrazioni intelligenti e mini-framework interni all'app. Questo può essere ottimo, ma crea anche un ecosistema privato che pochi comprendono.
- Il codice generato dall'IA tende a ricorrere a default familiari: librerie diffuse, stratificazioni convenzionali e pattern simili a quelli che trovi in molti progetti di riferimento.
Questa differenza conta in una riscrittura: il codice che segue convenzioni ampiamente comprese può spesso essere sostituito da un'implementazione convenzionale con meno trattative e meno sorprese.
Metti le aspettative a posto: il codice IA può essere disordinato
Il codice generato dall'IA può essere incoerente, ripetitivo o poco testato. "Più facile da sostituire" non vuol dire che sia più pulito—vuol dire che è spesso meno "speciale". Se un sottosistema è costruito con ingredienti comuni, sostituirlo è più come cambiare un pezzo standard che reverse-engineering di una macchina fatta su misura.
Anteprima: perché la standardizzazione abbassa i costi di switching
L'idea centrale è semplice: la standardizzazione abbassa i costi di sostituzione. Quando il codice è composto da pattern riconoscibili e cuciture (seams) chiare, puoi rigenerare, refactorare o riscrivere parti con meno paura di rompere dipendenze nascoste. Le sezioni seguenti mostrano come questo si traduca in struttura, responsabilità, testing e velocità ingegneristica quotidiana.
I pattern standard riducono il costo di ricominciare
Un vantaggio pratico del codice generato dall'IA è che spesso usa pattern comuni e riconoscibili: layout di cartelle familiari, naming prevedibile, convenzioni mainstream del framework e approcci "da manuale" per routing, validazione, gestione errori e accesso ai dati. Anche quando il codice non è perfetto, di solito è leggibile nello stesso modo in cui lo sono molti tutorial e progetti starter.
La familiarità batte l'originalità quando devi riscrivere
Le riscritture sono costose principalmente perché bisogna prima capire cosa esiste. Il codice che segue convenzioni note riduce quel tempo di "decodifica". I nuovi ingegneri possono mappare ciò che vedono su modelli mentali già noti: dove sta la configurazione, come scorrono le richieste, come sono cablate le dipendenze e dove mettere i test.
Questo rende più veloce:
- identificare le cuciture da sostituire (moduli, servizi, endpoint)
- replicare il comportamento in una nuova implementazione
- confrontare vecchio e nuovo affiancati senza tradurre tra stili
Al contrario, i codebase molto artigianali spesso riflettono uno stile profondamente personale: astrazioni uniche, mini-framework custom, codice di "colla" ingegnoso o pattern specifici del dominio comprensibili solo con il contesto storico. Quelle scelte possono essere eleganti—ma aumentano il costo di ricominciare perché una riscrittura deve prima ri-imparare la visione dell'autore.
Puoi comunque far rispettare le convenzioni in entrambi i casi
Non è magia esclusiva dell'IA. I team possono (e dovrebbero) far rispettare struttura e stile usando template, linter, formatter e scaffolding. La differenza è che l'IA tende a produrre un "generico di default", mentre i sistemi scritti a mano a volte scivolano verso soluzioni su misura se le convenzioni non vengono mantenute attivamente.
Meno "colla" personalizzata può significare meno dipendenze nascoste
Gran parte del dolore nelle riscritture non è causato dalla logica di business principale, ma dalla colla su misura: helper personalizzati, micro-framework interni, trucchi di metaprogrammazione e convenzioni one-off che collegano tutto in modo silenzioso.
Cosa conta come "colla su misura"
La colla su misura è quello che non fa parte del tuo prodotto, eppure il prodotto non può funzionare senza. Esempi: un container DI personalizzato, un layer di routing fatto in casa, una base class magica che auto-registra i modelli, o helper che mutano lo stato globale "per comodità". Spesso inizia come risparmio di tempo e finisce per diventare conoscenza obbligatoria per ogni cambiamento.
Perché la colla unica aumenta l'accoppiamento (e il rischio di riscrittura)
Il problema non è che la colla esista—ma che diventi accoppiamento invisibile. Quando la colla è unica per il tuo team, spesso:\n\n- crea dipendenze implicite (le cose funzionano solo perché gli helper vengono eseguiti in un certo ordine)\n- diffonde assunzioni attraverso i file (le convenzioni di naming diventano comportamento)\n- rende rischiosi i refactor "semplici" (cambi la colla, rompi tutto)
Durante una riscrittura, questa colla è difficile da replicare correttamente perché le regole raramente sono scritte. Le scopri rompendo la produzione.
Perché il codice generato dall'IA tende ad evitare genialità estreme
Gli output IA spesso preferiscono librerie standard, pattern comuni e wiring esplicito. Potrebbe non inventare un micro-framework quando basta un modulo semplice o un service object. Questa moderazione può essere una caratteristica: meno hook magici significa meno dipendenze nascoste, e questo rende più facile rimuovere un sottosistema e sostituirlo.
Il trade-off: verbosità al posto della genialità
Lo svantaggio è che il codice "semplice" può essere più verboso—più parametri passati, più plumbing esplicito, meno scorciatoie. Ma la verbosità è generalmente più economica del mistero. Quando decidi di riscrivere, vuoi codice facile da comprendere, facile da cancellare e difficile da interpretare male.
Una struttura prevedibile supporta riscritture incrementali
"Struttura prevedibile" riguarda meno l'estetica e più la coerenza: le stesse cartelle, regole di naming e flussi di richiesta si ripetono ovunque. I progetti generati dall'IA spesso puntano a default familiari—controllers/, services/, repositories/, models/—con endpoint CRUD ripetitivi e pattern di validazione simili.
Quell'uniformità conta perché trasforma una riscrittura da un salto nel vuoto a una scala a gradini.
Cosa significa prevedibilità
Vedi pattern ripetersi tra le feature:
- Confini di cartelle chiari (API → service → accesso ai dati)
- Naming coerente (
UserService, UserRepository, UserController)
- Flusso CRUD simile (list → get → create → update → delete)
- "Forma" standard per errori, logging e oggetti request/response
Quando ogni feature è costruita nello stesso modo, puoi sostituire una parte senza dover "ri-imparare" il sistema ogni volta.
Sostituire un pezzo alla volta
Le riscritture incrementali funzionano meglio quando puoi isolare un confine e ricostruire dietro di esso. Le strutture prevedibili creano naturalmente quelle cuciture: ogni layer ha un compito limitato e la maggior parte delle chiamate passa attraverso una piccola serie di interfacce.
Un approccio pratico è lo stile "strangler": mantieni stabile l'API pubblica e sostituisci internamente gradualmente.
Esempio: sostituire il layer di accesso ai dati senza toccare l'API
Supponi che la tua app abbia controller che chiamano un service, e il service chiama un repository:
OrdersController → OrdersService → OrdersRepository
Vuoi passare da query SQL dirette a un ORM, o da un DB a un altro. In un codebase prevedibile, il cambiamento può essere contenuto:
- Crea
OrdersRepositoryV2 (nuova implementazione)
- Mantieni le firme dei metodi uguali (
getOrder(id), listOrders(filters))
- Cambia il wiring in un punto (dependency injection o factory)
- Esegui i test e rilascia feature per feature
Il controller e il service restano per lo più intatti.
Contrasto: architetture artigianali
I sistemi altamente artigianali possono essere eccellenti—but spesso codificano idee uniche: astrazioni custom, metaprogramming intelligente o comportamenti cross-cutting nascosti in classi base. Questo rende ogni cambiamento richiedente un contesto storico profondo. Con una struttura prevedibile, la domanda "dove cambio questa cosa?" è di solito semplice, il che rende fattibili piccole riscritture settimana dopo settimana.
Minore “attaccamento dell'autore” rende la cancellazione più accettabile
Un blocco silenzioso in molte riscritture non è tecnico ma sociale. I team spesso portano con sé il rischio di ownership, dove una sola persona capisce davvero come funziona il sistema. Quando quella persona ha scritto grandi porzioni a mano, il codice può diventare un artefatto personale: "la mia progettazione", "la mia soluzione intelligente", "il mio workaround che ha salvato la release". Questo attaccamento rende la cancellazione emotivamente costosa, anche quando è economicamente razionale.
Il codice generato dall'IA può ridurre questo effetto. Perché la bozza iniziale può essere prodotta da uno strumento (e spesso segue pattern familiari), il codice sembra meno una firma e più un'implementazione intercambiabile. Le persone sono generalmente più a loro agio nel dire "Sostituiamo questo modulo" quando non sembra che stiano cancellando l'artigianato di qualcuno—o mettendo in discussione lo status di quel collega.
Perché questo cambia il comportamento di riscrittura
Quando l'attaccamento dell'autore è più basso, i team tendono a:\n\n- Mettere in discussione il codice esistente più liberamente ("È ancora la soluzione migliore?")\n- Cancellare grandi sezioni senza negoziazioni su orgoglio o politica\n- Scegliere la rigenerazione o la sostituzione prima, invece di mesi di patch cautious\n- Diffondere la conoscenza più rapidamente, perché nessuno tratta gli internals come territorio "posseduto"
Nota pratica
Le decisioni di riscrittura dovrebbero comunque essere guidate da costi e risultati: timeline di delivery, rischio, manutenibilità e impatto sull'utente. "È facile cancellare" è una proprietà utile—non una strategia da sola.
Prompt e tracce di generazione possono fungere da documentazione
Possiedi il codice che generi
Mantieni piena proprietà esportando il codice sorgente quando devi spostarlo o rivederlo offline.
Un beneficio sottovalutato del codice generato dall'IA è che gli input alla generazione possono funzionare come una specifica vivente. Un prompt, un template e una configurazione del generatore possono descrivere l'intento in linguaggio naturale: cosa deve fare la feature, quali vincoli contano (sicurezza, performance, stile) e cosa significa "fatto".
Prompt come specifiche viventi
Quando i team usano prompt ripetibili (o librerie di prompt) e template stabili, creano una traccia decisionale di scelte che altrimenti rimarrebbero implicite. Un buon prompt può dichiarare cose che un futuro manutentore altrimenti dovrebbe indovinare:\n\n- il flusso utente atteso e i casi limite\n- convenzioni di naming e struttura di cartelle\n- come gestire e loggare gli errori\n- cosa va testato (e cosa si può mockare)
Questo è significativamente diverso da molti codebase scritti a mano, dove decisioni chiave sono sparse tra commit message, conoscenza tribale e piccole convenzioni non scritte.
Le tracce di generazione aiutano a riprodurre il comportamento
Se conservi le tracce di generazione (prompt + modello/versione + input + passaggi di post-processing), una riscrittura non parte da zero. Puoi riutilizzare lo stesso checklist per ricreare lo stesso comportamento sotto una struttura più pulita e poi confrontare gli output.
Praticamente, questo può trasformare una riscrittura in: "rigenera la feature X sotto nuove convenzioni, poi verifica la parità", invece di "reverse-engineering di cosa doveva fare la feature X".
Avvertenza importante: tratta i prompt come codice
Questo funziona solo se prompt e config sono gestiti con la stessa disciplina del codice sorgente:\n\n- versionali nel repo (non nelle note personali)\n- richiedi review per i cambiamenti\n- registra quale prompt/config ha generato quali moduli
Senza questo, i prompt diventano un'altra dipendenza non documentata. Con queste pratiche, possono essere la documentazione che molti sistemi fatti a mano desidererebbero avere.
"Più facile da sostituire" non riguarda tanto chi ha scritto il codice quanto se puoi cambiarlo con fiducia. Una riscrittura diventa ingegneria di routine quando i test ti dicono, in modo rapido e affidabile, che il comportamento è rimasto lo stesso.
Il codice generato dall'IA può aiutare—quando lo richiedi. Molti team chiedono boilerplate di test insieme alle feature (unit test base, test d'integrazione happy-path, mock semplici). Quei test possono non essere perfetti, ma creano una rete di sicurezza iniziale spesso assente nei sistemi fatti a mano dove i test sono stati rimandati "a dopo".
Prioritizza i test di contratto ai confini
Se vuoi sostituibilità, concentra l'energia dei test sulle cuciture dove le parti si incontrano:\n\n- API esterne: request, response, codici di errore, retry, paginazione\n- Adapter: provider di pagamento, servizi email, storage, code\n- Modelli dati: migrazioni, serializzazione, regole di validazione\n\nI test di contratto fissano cosa deve restare vero anche se sostituisci gli internals. Così puoi riscrivere un modulo dietro un'API o sostituire un adapter senza rimettere in discussione il comportamento di business.
Usa la coverage come bussole, non come trofeo
I numeri di coverage possono indicare dove sono i rischi, ma inseguire il 100% spesso produce test fragili che bloccano i refactor. Invece:\n\n- Aggiungi test dove i fallimenti sarebbero costosi (soldi, perdita dati, fiducia dell'utente)\n- Preferisci pochi test ad alto segnale rispetto a tanti test superficiali\n- Quando riscrivi, confronta le vecchie e nuove implementazioni con gli stessi test di contratto
Con test solidi, le riscritture smettono di essere progetti eroici e diventano una serie di step sicuri e reversibili.
I difetti comuni del codice IA sono spesso facili da individuare e isolare
Estendi la riscrittura al mobile
Genera un'app Flutter dalla chat e mantieni le stesse convenzioni su web e mobile.
Il codice generato dall'IA tende a fallire in modi prevedibili. Spesso vedi logiche duplicate (lo stesso helper reimplementato tre volte), branch "quasi uguali" che gestiscono i casi limite in modo diverso, o funzioni che crescono per accrezione mentre il modello continua ad aggiungere fix. Niente di tutto ciò è ideale—ma ha un vantaggio: i problemi sono di solito visibili.
I difetti ovvi battono i bug sottili e ingegnosi
I sistemi fatti a mano possono nascondere complessità dietro astrazioni intelligenti, micro-ottimizzazioni o comportamenti strettamente accoppiati che sembrano corretti e passano una review superficiale. Questi bug sono dolorosi proprio perché sembrano giusti.
Il codice IA è più propenso a essere visibilmente incoerente: un parametro ignorato in un percorso, un controllo di validazione in un file ma non in un altro, o stili di gestione errori che cambiano ogni poche funzioni. Queste incongruenze emergono durante la review e l'analisi statica e sono più facili da isolare perché raramente dipendono da invarianti profonde e intenzionali.
I candidati alla riscrittura emergono dalla ripetizione
La ripetizione è l'indizio. Quando vedi la stessa sequenza di passaggi riapparire—parse input → normalizza → valida → mappa → return—su endpoint o servizi diversi, hai trovato una cucitura naturale da sostituire. L'IA spesso "risolve" una nuova richiesta ristampando una soluzione precedente con piccole modifiche, creando cluster di near-duplicate.
Un approccio pratico è segnare qualsiasi blocco ripetuto come candidato per estrazione o sostituzione, specialmente quando:\n\n- Appare in 3+ posti con differenze minori\n- Le differenze sono principalmente gestione di edge-case o messaggi di errore\n- Il codice non ha un chiaro proprietario e viene continuamente patchato
Regola pratica: consolida i ripetuti in un modulo testato
Se riesci a nominare il comportamento ripetuto in una frase, probabilmente dovrebbe essere un modulo singolo.
Sostituisci i frammenti ripetuti con un componente ben testato (utility, servizio condiviso o funzione di libreria), scrivi test che fissino i casi limite attesi e poi elimina i duplicati. Hai trasformato molte copie fragili in un unico punto da migliorare—e un unico punto da riscrivere in futuro se necessario.
Leggibilità e coerenza possono valere più delle ottimizzazioni artigianali
Il codice generato dall'IA spesso eccelle quando gli chiedi di ottimizzare la chiarezza invece della genialità. Con i prompt giusti e regole di linting, di solito sceglie flow di controllo familiari, naming convenzionali e moduli "noiosi" rispetto alla novità. Questo può essere un vantaggio a lungo termine maggiore di qualche punto percentuale di velocità guadagnata da trucchi hand-tuned.
Perché il codice leggibile è più facile da riscrivere
Le riscritture hanno successo quando nuove persone possono rapidamente costruire un modello mentale corretto del sistema. Codice leggibile e coerente riduce il tempo per rispondere a domande base come "Dove entra questa richiesta?" e "Che forma ha questo dato qui?". Se ogni servizio segue pattern simili (layout, gestione errori, logging, configurazione), un nuovo team può sostituire una fetta alla volta senza dover continuamente ri-imparare convenzioni locali.
La coerenza riduce anche la paura. Quando il codice è prevedibile, gli ingegneri possono cancellare e ricostruire parti con fiducia perché la superficie da capire è minore e il "raggio d'azione" sembra più limitato.
Il codice altamente ottimizzato a mano può essere difficile da riscrivere perché le tecniche di performance spesso si infiltrano ovunque: layer di caching custom, micro-ottimizzazioni, pattern di concorrenza casalinghi o accoppiamenti stretti a certe strutture dati. Queste scelte possono essere valide, ma creano spesso vincoli sottili che non sono evidenti fino al momento del guasto.
La leggibilità non dà licenza a essere lenti. L'idea è guadagnare performance con evidenze. Prima di una riscrittura, cattura metriche di baseline (percentili di latenza, CPU, memoria, costi). Dopo aver sostituito un componente, misura di nuovo. Se le performance peggiorano, ottimizza il percorso caldo specifico—senza trasformare tutto il codebase in un rompicapo.
Rigenerare vs refattorizzare vs riscrivere: scegliere il reset giusto
Quando un codice assistito dall'IA comincia a farti dire "non va bene", non hai automaticamente bisogno di una riscrittura completa. Il reset migliore dipende da quanto del sistema è sbagliato rispetto a quanto è semplicemente disordinato.
Tre opzioni di reset
Rigenerare significa ricreare una parte del codice da una specifica o da un prompt—spesso a partire da un template o da un pattern noto—e riapplicare i punti di integrazione (route, contratti, test). Non è "cancella tutto", è "ricostruisci questa fetta da una descrizione più chiara".
Refactor mantiene il comportamento ma cambia la struttura interna: rinomina, divide moduli, semplifica condizionali, rimuove duplicazioni, migliora i test.
Rewrite sostituisce un componente o un sistema con una nuova implementazione, di solito perché il design attuale non può essere raddrizzato senza cambiare comportamento, confini o flussi dati.
Quando la rigenerazione è ottima
La rigenerazione brilla quando il codice è per lo più boilerplate e il valore sta nelle interfacce più che negli internals:\n\n- Schermate CRUD e pannelli admin\n- Adapter API e thin integration layer\n- Scaffolding: routing, serializer, DTO, validazione semplice, gestione errori comune
Se la specifica è chiara e il confine del modulo è pulito, rigenerare è spesso più veloce che sbrogliare modifiche incrementali.
Quando la rigenerazione è rischiosa (o fallisce)
Sii cauto quando il codice incapsula conoscenza di dominio difficile o vincoli di correttezza sottili:\n\n- regole di business dominate dal dominio con molti casi limite\n- concorrenza complessa (code, lock, retry, idempotenza)\n- logiche di conformità (audit trail, retention, privacy)
In queste aree, il "vicino" può costare caro—la rigenerazione può aiutare, ma solo se puoi provare l'equivalenza con test robusti e review.
Gate di revisione e rollout graduali
Tratta il codice rigenerato come una nuova dipendenza: richiedi review umana, esegui l'intera suite di test e aggiungi test mirati per i fallimenti già incontrati. Rilascia in piccoli slice—un endpoint, una schermata, un adapter—dietro feature flag o con rollout graduale se possibile.
Un default utile è: rigenera la shell, refatta le cuciture, riscrivi solo le parti dove le assunzioni continuano a rompersi.
Rischi e guardrail per il codice “sostituibile per design”
Mantieni l'architettura noiosa
Genera una struttura convenzionale che puoi riscrivere slice dopo slice senza dover riscoprire il glue personalizzato.
"Facile da sostituire" resta un vantaggio solo se i team considerano la sostituzione come un'attività ingegneristica, non come un pulsante per resettare alla leggera. I moduli generati dall'IA possono essere scambiati più rapidamente—ma possono anche fallire più velocemente se ti fidi più di quanto verifichi.
Rischi chiave da tenere d'occhio
Il codice generato dall'IA spesso sembra completo anche quando non lo è. Questo può creare una falsa fiducia, specialmente quando demo happy-path passano.\n\nUn secondo rischio sono i casi limite mancanti: input insoliti, timeout, quirks di concorrenza e gestione degli errori che non sono stati coperti dal prompt o dai dati di esempio.\n\nInfine, c'è l'incertezza su licenze/IP. Anche se il rischio è basso in molti casi, i team dovrebbero avere una policy su quali sorgenti e strumenti sono accettabili e su come tracciare la provenienza.
Guardrail che mantengono le riscritture sicure
Metti la sostituzione dietro gli stessi gate di qualsiasi altra modifica:\n\n- Code review con una lente esplicita "generated code": chiarezza, modalità di fallimento, validazione degli input e logging.\n- Controlli di sicurezza (SAST, scansione dipendenze, rilevamento segreti) e regole che impediscano al codice generato di bypassarli.\n- Policy sulle dipendenze: preferire librerie conosciute e poche, pin delle versioni, evitare di introdurre un nuovo framework solo perché il prompt lo suggerisce.\n- Tracce di audit: conserva prompt, versione dello strumento/modello e note di generazione nel repo così le modifiche sono spiegabili in futuro.
Documenta i confini prima di sostituire i moduli
Prima di sostituire un componente, scrivi il suo confine e le invarianti: quali input accetta, cosa garantisce, cosa non deve mai fare (es.: "mai cancellare i dati dei clienti"), e aspettative di performance/latency. Questo "contratto" è ciò che testi—indipendentemente da chi (o cosa) scrive il codice.
Checklist leggera
- Definisci il contratto del modulo (input/output, invarianti).\n2) Aggiungi/conferma test per i casi limite.\n3) Esegui scansioni di sicurezza e dipendenze.\n4) Revisiona per leggibilità e gestione dei fallimenti.\n5) Registra metadati su prompt/tooling.\n6) Rilascia dietro feature flag e monitora.
Takeaway pratici e un semplice piano di prossimi passi
Il codice generato dall'IA è spesso più facile da riscrivere perché tende a seguire pattern familiari, evita una personalizzazione profonda e si presta rapidamente alla rigenerazione quando i requisiti cambiano. Quella prevedibilità riduce i costi tecnici e sociali di cancellare e sostituire parti del sistema.
L'obiettivo non è "buttare via il codice", ma rendere la sostituzione una opzione normale e a basso attrito—sostenuta da contratti e test.
Azioni pratiche che puoi implementare questa settimana
Inizia standardizzando convenzioni così qualsiasi codice rigenerato o riscritto si integri nello stesso stampo:\n\n- Blocca le convenzioni: formattazione, struttura delle cartelle, naming, gestione errori e forma delle API. Metti per iscritto queste regole in un breve CONTRIBUTING.md.\n- Aggiungi test di contratto ai confini: concentrati su input/output per moduli e servizi (endpoint HTTP, messaggi in coda, layer di accesso al DB). Questi test devono passare anche se l'implementazione viene sostituita.\n- Traccia prompt e specifiche: conserva prompt, note sui requisiti e tracce di generazione insieme al codice così le future riscritture possano riprodurre l'intento, non solo il testo.
Se usi un flusso di lavoro "vibe-coding", cerca tool che rendano queste pratiche semplici: salvare specifiche di "planning mode" accanto al repo, catturare tracce di generazione e supportare il rollback sicuro. Ad esempio, Koder.ai è progettato attorno alla generazione chat-driven con snapshot e rollback, e si adatta bene all'approccio "sostituibile per design": rigenerare una slice, mantenere il contratto stabile e tornare indietro rapidamente se i test di parità falliscono.
Esegui un piccolo pilot su un “modulo sostituibile”
Scegli un modulo importante ma isolato—generazione report, invio notifiche o un singolo ambito CRUD. Definisci la sua interfaccia pubblica, aggiungi test di contratto, poi permettiti di rigenerare/refattorizzare/riscrivere gli internals finché non è noioso. Misura il tempo di ciclo, il tasso di difetti e lo sforzo di review; usa i risultati per stabilire regole a livello di team.
Per operationalizzare, tieni una checklist nel playbook interno e rendi obbligatorio il trio “contratti + convenzioni + tracce” per il nuovo lavoro. Se stai valutando supporto tooling, documenta ciò di cui avresti bisogno da una soluzione prima di guardare i prezzi.