“Performance-critical” non vuol dire “bello se è veloce”. Vuol dire che l'esperienza si deteriora quando l'app è anche soltanto leggermente lenta, incoerente o in ritardo. Gli utenti non solo notano il lag: perdono un momento, prendono decisioni sbagliate o perdono fiducia.
Alcuni tipi di app rendono questo evidente:
- Fotocamera e video: tocchi l'otturatore e ti aspetti che la cattura avvenga immediatamente. I ritardi possono farti perdere il momento. Preview che saltella, messa a fuoco lenta o frame persi rendono l'app inaffidabile.
- Mappe e navigazione: il puntino blu deve muoversi fluidamente, i ricalcoli dovrebbero sembrare istantanei e l'interfaccia deve restare reattiva mentre GPS, caricamento dati e rendering avvengono in parallelo.
- Trading e finanza: una quotazione che si aggiorna in ritardo, un pulsante che registra l'input tardi o uno schermo che si blocca durante la volatilità possono influenzare direttamente i risultati.
- Giochi: cali di frame e ritardi nell'input non sono solo sgradevoli, ma cambiano il gameplay. Un pacing coerente dei frame è importante quanto gli FPS grezzi.
In tutti questi casi, la performance non è una metrica tecnica nascosta: è visibile, percepita e giudicata in pochi secondi.
Cosa intendiamo per “framework nativi” (senza i termini di marketing)
Con framework nativi intendiamo costruire con gli strumenti di prima classe di ciascuna piattaforma:
- iOS: Swift/Objective‑C con gli SDK di Apple per iOS (ad es. UIKit o SwiftUI, più i framework di sistema)
- Android: Kotlin/Java con gli SDK Android (ad es. Jetpack, Views/Compose, più le API di piattaforma)
Native non significa automaticamente “migliore ingegneria”. Significa che la tua app parla il linguaggio della piattaforma in modo diretto — importante specialmente quando spingi il dispositivo al limite.
I framework cross-platform possono essere una scelta eccellente per molti prodotti, in particolare quando la velocità di sviluppo e il codice condiviso contano più che spremere ogni millisecondo.
Questo articolo non sostiene che “native sempre”. Sostiene che quando un'app è veramente critica per le prestazioni, i framework nativi spesso rimuovono intere categorie di overhead e limitazioni.
Le dimensioni che di solito decidono
Valuteremo le esigenze performance-critical su alcune dimensioni pratiche:
- Latenza: risposta al tocco, digitazione, interazioni in tempo reale, sync audio/video
- Rendering: scrolling fluido, animazioni, pacing dei frame, UI guidata dalla GPU
- Batteria e calore: efficienza sostenuta durante sessioni lunghe
- Accesso a hardware/SO: pipeline della fotocamera, sensori, Bluetooth, esecuzione in background, ML on-device
Queste sono le aree dove gli utenti percepiscono la differenza — e dove i framework nativi tendono a eccellere.
I framework cross-platform possono sembrare “abbastanza vicini” al native quando costruisci schermate tipiche, form e flussi guidati dalla rete. La differenza appare quando l'app è sensibile a piccoli ritardi, richiede un pacing coerente dei frame o deve spingere il dispositivo per sessioni prolungate.
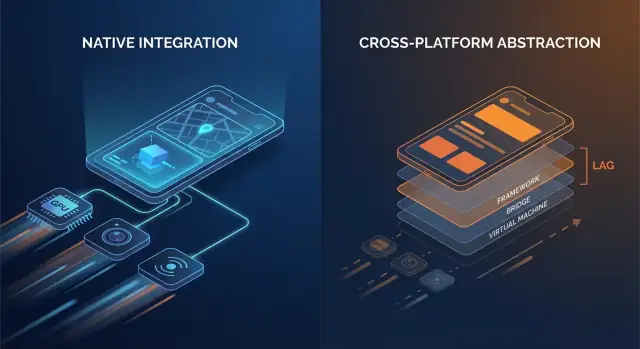
Il codice nativo parla in genere direttamente alle API del SO. Molti stack cross-platform aggiungono uno o più layer di traduzione tra la logica dell'app e ciò che il telefono effettivamente renderizza.
Punti comuni di overhead includono:
- Chiamate bridge e cambio di contesto: se il layer UI e la logica vivono in runtime diversi (ad es. un runtime managed o un motore di scripting più il codice nativo), ogni interazione può richiedere un salto attraverso un confine.
- Serializzazione e copia: i dati passati oltre i confini possono richiedere conversione (payload tipo JSON, mappe tipizzate, buffer di byte). Quel lavoro di conversione può emergere nei percorsi caldi come lo scrolling o la digitazione.
- Gerarchie di view extra: alcuni framework creano il proprio albero UI e poi lo mappano a view native (o renderizzano su una canvas). Riconciliazione e layout possono diventare più costosi rispetto a un aggiornamento diretto della view nativa.
Nessuno di questi costi è enorme da solo. Il problema è la ripetizione: possono apparire ad ogni gesto, ogni tick di animazione e ogni elemento di una lista.
Tempo di avvio e “jank” a runtime
L'overhead non riguarda solo la velocità grezza; riguarda anche quando il lavoro avviene.
- Tempo di avvio può aumentare quando l'app deve inizializzare un runtime aggiuntivo, caricare asset incorporati, avviare un motore UI o ricostruire stato prima che la prima schermata sia interattiva.
- Il jank a runtime spesso viene da pause imprevedibili: garbage collection, backpressure sul bridge, diffing costoso o un task lungo che blocca il thread principale proprio quando l'UI deve rispettare il frame successivo.
Le app native possono incorrere anche in questi problemi — ma ci sono meno parti mobili, il che significa meno posti dove possono nascondersi sorprese.
Un modello mentale semplice
Pensa: meno layer = meno sorprese. Ogni layer aggiunto può essere ben progettato, ma introduce comunque più complessità di scheduling, più pressione sulla memoria e più lavoro di traduzione.
Quando l'overhead va bene — e quando no
Per molte app l'overhead è accettabile e il guadagno di produttività è reale. Ma per app performance-critical — feed a scorrimento veloce, animazioni pesanti, collaborazioni in tempo reale, elaborazione audio/video o qualsiasi cosa sensibile alla latenza — quei costi “piccoli” possono diventare rapidamente visibili all'utente.
Fluidità UI: frame, jank e percorsi di rendering nativi
Una UI fluida non è solo un “bello da avere” — è un segnale diretto di qualità. Su uno schermo a 60 Hz l'app ha circa 16.7 ms per produrre ogni frame. Su dispositivi a 120 Hz quel budget scende a 8.3 ms. Quando manchi quella finestra, l'utente lo vede come stutter (jank): scrolling che “si impiglia”, transizioni che scattano o un gesto che sembra in ritardo rispetto al dito.
Perché i frame mancati sono così facili da notare
Le persone non contano i frame, ma notano l'incoerenza. Un frame perso durante una dissolvenza lenta può essere tollerabile; pochi frame persi durante uno scroll veloce sono immediatamente evidenti. Gli schermi ad alta frequenza alzano le aspettative — una volta che gli utenti sperimentano la fluidità a 120 Hz, un rendering incoerente sembra peggiore che a 60 Hz.
Il thread principale è il collo di bottiglia tipico
La maggior parte dei framework UI si affida ancora a un thread principale/UI per coordinare input, layout e disegno. Lo jank appare quando quel thread fa troppo lavoro in un singolo frame:
- Passaggi di layout pesanti: gerarchie di view complesse, contenitori annidati o relayout frequenti causati da vincoli/cambi di dimensione.
- Animazioni costose: animare proprietà che forzano il relayout o la rerasterizzazione invece di lasciare che la GPU gestisca le trasformazioni.
- Lavoro sincrono nelle callback UI: parsing JSON, formattazione di grandi blocchi di testo o esecuzione di logica di business durante scroll/gesti.
I framework nativi tendono ad avere pipeline ben ottimizzate e best practice chiare per tenere il lavoro fuori dal main thread, minimizzare le invalidazioni di layout e usare animazioni amiche della GPU.
Componenti nativi vs UI renderizzata custom
Una differenza chiave è il percorso di rendering:
- Componenti nativi di piattaforma di solito si mappano direttamente a widget ottimizzati dal SO e sistemi di compositing.
- Approcci con UI custom-rendered (comuni negli stack cross-platform) possono aggiungere un albero di rendering separato, upload di texture extra o lavoro di riconciliazione aggiuntivo. Questo può andare bene — finché lo schermo non diventa ricco di animazioni o liste e l'overhead non comincia a competere per un budget di frame ristretto.
Dove lo percepisci: esempi reali di schermate
Liste complesse sono il classico stress test: scorrimento veloce + caricamento immagini + altezze dinamiche delle celle possono creare churn di layout e pressione su GC/memoria.
Le transizioni possono rivelare inefficienze di pipeline: animazioni con elementi condivisi, sfocature di sfondo e ombre stratificate sono ricche visivamente ma possono innalzare i costi GPU e l'overdraw.
Schermate con molti gesti (drag-to-reorder, swipe card, scrubber) sono implacabili perché l'UI deve rispondere continuamente. Quando i frame arrivano in ritardo, l'UI smette di sentirsi “attaccata” al dito dell'utente — cosa che le app ad alte prestazioni evitano a tutti i costi.
Bassa latenza: tocco, digitazione, audio e UX in tempo reale
La latenza è il tempo tra un'azione dell'utente e la risposta dell'app. Non la “velocità” complessiva, ma il gap che senti quando tocchi un pulsante, digiti un carattere, trascini uno slider, disegni una traccia o suoni una nota.
Input→risposta: dove “veloce” diventa “giusto”
Soglie pratiche di riferimento:
- 0–50 ms: sembra istantaneo. Tocchi e digitazione sembrano direttamente collegati al dito.
- 50–100 ms: generalmente accettabile, ma si percepisce “morbidezza”, soprattutto durante drag e scrub.
- 100–200 ms: lag percepibile. Digitare sembra in ritardo; disegnare linee “insegue” lo stilo.
- 200 ms+: frustrante. Gli utenti rallentano per compensare.
Le app performance-critical — messaggistica, note, trading, navigazione, strumenti creativi — vivono e muoiono da questi gap.
Loop di eventi, scheduling e “thread hop”
La maggior parte dei framework tratta l'input su un thread, esegue la logica su un altro e poi chiede all'UI di aggiornarsi. Quando quel percorso è lungo o incoerente, la latenza schizza.
I layer cross-platform possono aggiungere passaggi extra:
- l'input arriva → viene tradotto in eventi del framework
- la logica gira in un runtime separato (spesso con il suo event loop)
- i cambi di stato vengono serializzati e inviati indietro
- gli aggiornamenti UI sono schedulati più tardi, a volte mancando il frame successivo
Ogni passaggio (un “thread hop”) aggiunge overhead e, cosa più importante, jitter — la variabilità della risposta — che spesso si percepisce peggio di un ritardo costante.
I framework nativi tendono ad avere un percorso più corto e prevedibile da tocco → aggiornamento UI perché si allineano strettamente con lo scheduler del SO, il sistema di input e la pipeline di rendering.
UX in tempo reale: audio, video e collaborazione live
Alcuni scenari hanno limiti rigidi:
- Monitoraggio audio/strumenti: la latenza round-trip deve spesso rimanere sotto i ~20 ms per risultare suonabile.
- Chiamate voce/video: puoi bufferizzare per nascondere problemi di rete, ma i controlli UI (mute, speaker, sottotitoli) devono rispondere immediatamente.
- Collaborazione live (documenti, lavagne): le modifiche locali devono apparire istantanee, anche se la sincronizzazione remota richiede più tempo.
Implementazioni native-first semplificano mantenere il “percorso critico” corto — dando priorità a input e rendering rispetto al lavoro in background — così le interazioni in tempo reale restano rapide e affidabili.
Funzionalità hardware e OS profonde: native first, sempre
Stabilisci i budget di prestazione presto
Avvia un MVP in fretta, poi profila i dispositivi reali con obiettivi chiari di latenza e frame.
La performance non è solo velocità della CPU o frame rate. Per molte app, i momenti decisivi avvengono ai margini — dove il tuo codice tocca fotocamera, sensori, radio e servizi a livello di SO. Quelle capacità sono progettate e rilasciate prima come API native, e questa realtà influenza cosa è fattibile (e quanto sia stabile) negli stack cross-platform.
L'accesso all'hardware raramente è generico
Funzionalità come pipeline della fotocamera, AR, BLE, NFC e sensori di movimento spesso richiedono integrazione stretta con framework specifici del dispositivo. I wrapper cross-platform possono coprire i casi comuni, ma gli scenari avanzati tendono a mostrare lacune.
Esempi in cui le API native contano:
- Controlli avanzati della fotocamera: messa a fuoco manuale ed esposizione, cattura RAW, video ad alta frequenza, HDR, switch multi-camera (wide/tele), dati di profondità e comportamento in condizioni di scarsa luce.
- Esperienze AR: ARKit/ARCore evolvono rapidamente (occlusione, rilevamento piani, ricostruzione scena).
- BLE e modalità background: scansione, riconnessione e comportamento “funziona con lo schermo spento” dipendono spesso dalle regole di esecuzione in background della piattaforma.
- NFC: accesso al secure element, limiti di emulazione carta e gestione delle sessioni reader sono molto specifici della piattaforma.
- Dati sanitari: permessi HealthKit/Google Fit, tipi di dato e delivery in background possono essere sfumati e richiedere gestione native-first.
Gli aggiornamenti del SO arrivano prima sul native
Quando iOS o Android introducono nuove funzionalità, le API ufficiali sono immediatamente disponibili negli SDK nativi. I layer cross-platform possono impiegare settimane (o più) per aggiungere binding, aggiornare plugin e risolvere casi limite.
Quel ritardo non è solo scomodo — può creare rischio di affidabilità. Se un wrapper non è aggiornato per una nuova release del SO, potresti vedere:
- flussi di permessi che si rompono,
- task in background resi più restrittivi,
- crash causati da comportamenti di sistema aggiornati,
- regressioni che emergono su specifici modelli di dispositivo.
Per app performance-critical, i framework nativi riducono il problema del “dover aspettare il wrapper” e permettono ai team di adottare le nuove capacità del SO già dal primo giorno — spesso la differenza tra una feature che esce questo trimestre o il prossimo.
Batteria, memoria e calore: prestazioni che senti col tempo
La velocità in una demo rapida è solo metà della storia. Le prestazioni che gli utenti ricordano sono quelle che reggono dopo 20 minuti d'uso — quando il telefono è caldo, la batteria cala e l'app è stata inviata in background qualche volta.
Da dove viene veramente il consumo della batteria
La maggior parte dei consumi “misteriosi” sono autoprodotti:
- Wake lock e timer fuori controllo tengono la CPU sveglia anche a schermo spento.
- Lavoro in background che non si ferma mai (polling, controlli di posizione frequenti, retry di rete continui) si accumula rapidamente.
- Ridisegni eccessivi — ricostruire UI o rerenderizzare animazioni più spesso del necessario — tengono CPU/GPU occupati.
I framework nativi di solito offrono strumenti più chiari e prevedibili per schedulare il lavoro in modo efficiente (task in background, job scheduling, refresh gestiti dal SO), così puoi fare meno lavoro complessivamente — e farlo nei momenti migliori.
Pressione sulla memoria: la fonte nascosta degli stutter
La memoria non influisce solo sul crash dell'app — influisce sulla fluidità.
Molti stack cross-platform si appoggiano a un runtime managed con garbage collection (GC). Quando la memoria cresce, la GC può mettere in pausa l'app brevemente per liberare oggetti non più usati. Non serve conoscere i dettagli interni per sentirlo: micro-freeze occasionali durante lo scrolling, la digitazione o le transizioni.
Le app native tendono a seguire pattern della piattaforma (come il ARC su Apple), che spesso distribuiscono il lavoro di pulizia in modo più uniforme. Il risultato può essere meno pause “a sorpresa” — specialmente in condizioni di memoria ristretta.
Calore e prestazioni sostenute
Il calore è prestazione. Man mano che i dispositivi si riscaldano, il SO può throttlare CPU/GPU per proteggere l'hardware, e i frame calano. Questo è comune in carichi sostenuti come giochi, navigazione turn-by-turn, fotocamera + filtri o audio in tempo reale.
Il codice nativo può essere più efficiente energeticamente in questi scenari perché può usare API accelerate dall'hardware e sintonizzate dal SO per compiti pesanti — ad esempio pipeline native per la riproduzione video, campionamento sensori efficiente e codec media di piattaforma — riducendo lavoro sprecato che si trasforma in calore.
Quando “veloce” significa anche “fresco e stabile”, i framework nativi spesso hanno un vantaggio.
Profiling e debugging: vedere i veri colli di bottiglia
Distribuisci e rollbacka velocemente
Distribuisci su Koder.ai e ripristina istantaneamente con gli snapshot quando un esperimento peggiora le prestazioni.
Il lavoro sulle prestazioni riesce o fallisce sulla visibilità. I framework nativi in genere includono i ganci più profondi nel sistema operativo, nel runtime e nella pipeline di rendering — perché sono costruiti dagli stessi vendor che definiscono quei layer.
Le app native possono agganciare profiler nei punti in cui si introducono i ritardi: main thread, render thread, system compositor, stack audio e sottosistemi di rete e storage. Quando stai inseguendo uno stutter che accade una volta ogni 30 secondi o un consumo di batteria che appare solo su certi dispositivi, quelle tracce “sotto il framework” sono spesso l'unico modo per ottenere una risposta definitiva.
Non serve memorizzarli tutti per beneficiarne, ma è utile sapere cosa esiste:
- Xcode Instruments (Time Profiler, Allocations, Leaks, Core Animation, Energy Log)
- Xcode Debugger (ispezione thread, memory graph, breakpoint simbolici)
- Android Studio Profiler (CPU, Memory, Network, Energy)
- Perfetto / System Trace (tracing a livello di sistema su Android)
- Tool GPU come gli strumenti Metal di Xcode o inspector GPU dei vendor (per diagnosticare overdraw, costo shader, pacing dei frame)
Questi strumenti sono pensati per rispondere a domande concrete: “Quale funzione è hot?”, “Quale oggetto non viene rilasciato?”, “Quale frame ha mancato la deadline e perché?”.
I bug dell'“ultimo 5%”: freeze, leak e frame drop
I problemi di prestazione più difficili spesso si nascondono nei casi limite: un rare deadlock di sincronizzazione, un parse JSON lento sul main thread, una singola view che scatena un layout costoso o una perdita di memoria che emerge dopo 20 minuti di uso.
Il profiling nativo ti permette di correlare sintomi (un freeze o jank) con cause reali (uno specifico call stack, pattern di allocazione o spike GPU) invece di affidarti a tentativi ed errori.
Fix più veloci per problemi ad alto impatto
Una migliore visibilità accorcia i tempi di risoluzione perché trasforma i dibattiti in evidenza. I team possono catturare una traccia, condividerla e concordare rapidamente il collo di bottiglia — spesso riducendo giorni di speculazioni a una patch mirata e a un risultato misurabile prima/dopo.
Affidabilità su scala: dispositivi, aggiornamenti SO e casi limite
Le prestazioni non sono l'unica cosa che si rompe quando rilasci su milioni di telefoni — la coerenza sì. La stessa app può comportarsi diversamente tra versioni del SO, personalizzazioni OEM e persino driver GPU dei vendor. L'affidabilità su scala è la capacità di mantenere l'app prevedibile quando l'ecosistema non lo è.
Perché “stesso Android/iOS” non è davvero lo stesso
Su Android, le skin OEM possono modificare limiti background, notifiche, picker file e gestione dell'energia. Due dispositivi con la stessa versione Android possono differire perché i vendor distribuiscono componenti di sistema e patch diversi.
Anche le GPU introducono variabili. I driver dei vendor (Adreno, Mali, PowerVR) possono divergere in precisione shader, formati texture e quanto ottimizzano aggressivamente. Un percorso di rendering che sembra corretto su una GPU può mostrare flicker, banding o crash rari su un'altra — soprattutto attorno a video, fotocamera e grafica custom.
iOS è più controllato, ma gli aggiornamenti del SO cambiano comunque comportamento: flussi di permessi, quirk della tastiera/autofill, regole della sessione audio e politiche dei task in background possono mutare anche tra minor release.
Perché il native gestisce meglio i casi limite
Le piattaforme espongono prima le API “reali”. Quando il SO cambia, gli SDK nativi e la documentazione di solito riflettono quei cambiamenti subito, e gli strumenti di piattaforma (Xcode/Android Studio, log di sistema, simboli di crash) si allineano con ciò che gira sui dispositivi.
Gli stack cross-platform aggiungono un ulteriore layer di traduzione: il framework, il suo runtime/rendering e i plugin. Quando appare un caso limite, stai debuggando sia la tua app sia il bridge.
Rischio di dipendenze: aggiornamenti, breaking change e qualità dei plugin
Gli upgrade del framework possono introdurre cambiamenti runtime (threading, rendering, input testuale, gestione dei gesture) che fallano solo su certi dispositivi. I plugin possono essere peggio: alcuni sono semplici wrapper; altri incorporano codice nativo pesante con manutenzione irregolare.
Checklist: valutare librerie di terze parti nei percorsi critici
- Manutenzione: release recenti, triage attivo delle issue, ownership chiara.
- Parità nativa: usa API ufficiali della piattaforma (non hook privati/unsupported).
- Prestazioni: benchmark, evita copie/allocazioni extra, minimizza hop sul bridge.
- Modalità di fallimento: fallback eleganti, timeout e reporting degli errori.
- Compatibilità: test su versioni SO, dispositivi OEM e vendor GPU.
- Osservabilità: log, simboli di crash e test case riproducibili.
- Sicurezza di upgrade: disciplina semver, changelog e note di migrazione.
Su scala, l'affidabilità raramente è questione di un singolo bug — è ridurre il numero di layer dove le sorprese possono nascondersi.
Prototipa lo schermo più difficile
Usa Koder.ai per creare un prototipo React + Go da chat e misurarlo sui dispositivi.
Alcuni carichi di lavoro puniscono anche piccoli overhead. Se la tua app ha bisogno di FPS sostenuti, lavoro GPU pesante o controllo preciso su decoding e buffer, i framework nativi di solito vincono perché possono guidare i percorsi più veloci della piattaforma direttamente.
Carichi che favoriscono fortemente il native
Native è una scelta chiara per scene 3D, esperienze AR, giochi ad alto FPS, editing video e app incentrate sulla fotocamera con filtri in tempo reale. Questi casi non sono solo “pesanti di calcolo” — sono pesanti di pipeline: sposti grandi texture e frame tra CPU, GPU, fotocamera e encoder decine di volte al secondo.
Copie extra, frame tardivi o sincronizzazioni errate si notano subito come frame persi, surriscaldamento o controlli rallentati.
Accesso diretto ad API GPU, codec e accelerazione
Su iOS, il codice nativo può usare Metal e lo stack media di sistema senza layer intermedi. Su Android può accedere a Vulkan/OpenGL e ai codec di piattaforma e accelerazione hardware tramite l'NDK e le API media.
Ciò conta perché la submission dei comandi GPU, la compilazione degli shader e la gestione delle texture sono sensibili a come l'app pianifica il lavoro.
Pipeline di rendering e upload di texture (alto livello)
Una pipeline real-time tipica è: cattura o carica frame → converte formati → upload texture → esegue shader GPU → compone UI → presenta.
Il codice nativo può ridurre l'overhead mantenendo i dati in formati amici della GPU più a lungo, batchando draw call ed evitando upload ripetuti di texture. Anche una conversione inutile per frame (es. RGBA ↔ YUV) può aggiungere abbastanza costo da compromettere la riproduzione fluida.
Inferenza ML: throughput, latenza e consumo
Il ML on-device spesso dipende da delegate/backend (Neural Engine, GPU, DSP/NPU). L'integrazione nativa tende a esporre queste opzioni prima e con più possibilità di tuning — importante quando ti interessa la latenza dell'inferenza e la batteria.
Strategia ibrida: moduli nativi per gli hotspot
Non serve sempre un'app completamente native. Molte squadre mantengono UI cross-platform per la maggior parte delle schermate e aggiungono moduli nativi per gli hotspot: pipeline fotocamera, renderer custom, motori audio o inferenza ML.
Questo può avvicinare le prestazioni al native dove conta, senza riscrivere tutto.
Scegliere un framework è meno ideologico e più una questione di far corrispondere le aspettative degli utenti a ciò che il dispositivo deve fare. Se la tua app sembra istantanea, resta fresca e rimane fluida sotto stress, gli utenti raramente chiedono con cosa è stata costruita.
Una matrice pratica di decisione
Usa queste domande per restringere rapidamente la scelta:
- Aspettative utenti: è un'app “utility” dove hiccup occasionali sono tollerabili, o un'esperienza dove lo stutter rompe la fiducia (banking, navigazione, collaborazione live, strumenti per creator)?
- Bisogni hardware: ti servono pipeline della fotocamera, periferiche Bluetooth, sensori, processamento in background, audio a bassa latenza, AR o lavoro GPU pesante? Più ti avvicini al metallo, più il native ripaga.
- Timeline e velocità di iterazione: il cross-platform può ridurre il time-to-market per UI più semplici e flussi condivisi. Il native può essere più veloce per tuning delle prestazioni perché lavori direttamente con tool e API della piattaforma.
- Competenze del team e hiring: un team iOS/Android forte consegnerà codice nativo di alta qualità più rapidamente. Un team piccolo con esperienza web può arrivare a un MVP più in fretta con cross-platform — se i vincoli di performance sono moderati.
Se stai prototipando più direzioni, può aiutare validare i flussi prodotto prima di investire in ottimizzazioni native profonde. Per esempio, i team a volte usano Koder.ai per creare una web app funzionante (React + Go + PostgreSQL) tramite chat, testare l'UX e il modello dati, e poi impegnarsi in una build mobile native o ibrida quando le schermate critiche per le prestazioni sono chiaramente definite.
Cosa significa davvero “ibrido” (e perché spesso vince)
Ibrido non deve significare “web dentro un'app”. Per prodotti performance-critical, ibrido spesso vuol dire:
- Core nativo + logica condivisa: mantieni networking, state e logica dominio condivisi, mentre UI e parti sensibili alle prestazioni restano native.
- Shell nativa + UI condivisa dove è sicuro: usa UI condivisa per schermate statiche o form-based, e tieni native le viste ricche di animazioni o in tempo reale.
Questo approccio limita il rischio: puoi ottimizzare i percorsi più caldi senza riscrivere tutto.
Misura prima, poi decidi
Prima di impegnarti, costruisci un piccolo prototipo della schermata più difficile (es. feed live, timeline editor, mappa + overlay). Benchmarka stabilità dei frame, latenza input, memoria e batteria in una sessione di 10–15 minuti. Usa quei dati — non supposizioni — per scegliere.
Se usi uno strumento assistito da AI come Koder.ai per le prime iterazioni, trattalo come un moltiplicatore di velocità per esplorare architettura e UX — non come sostituto del profiling a livello di dispositivo. Quando punti a un'esperienza performance-critical, la stessa regola vale: misura su dispositivi reali, stabilisci budget di prestazione e tieni i percorsi critici (rendering, input, media) il più vicino possibile al native che le tue esigenze richiedono.
Evita l'ottimizzazione prematura
Inizia rendendo l'app corretta e osservabile (profiling di base, logging e budget di prestazione). Ottimizza solo quando puoi indicare un collo di bottiglia che gli utenti sentiranno. Questo evita di far sprecare settimane al team a limare millisecondi su codice che non è sul percorso critico.