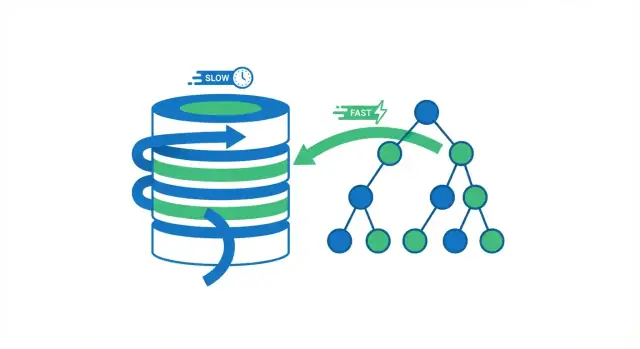
Cosa fa davvero l'indicizzazione del database
Un indice di database è una struttura di ricerca separata che aiuta il database a trovare le righe più velocemente. Non è una seconda copia della tabella. Pensalo come le pagine dell'indice di un libro: usi l'indice per saltare vicino al punto giusto, poi leggi la pagina esatta (la riga) che ti serve.
Senza indice, il database spesso ha un solo approccio sicuro: leggere molte righe per verificare quali corrispondono alla query. Va bene quando una tabella ha poche migliaia di righe. Man mano che la tabella cresce fino a milioni di righe, “controllare più righe” si traduce in più letture da disco, più pressione sulla memoria e più lavoro della CPU—quindi la stessa query che prima era istantanea comincia a rallentare.
Cosa cambia con un indice (e cosa no)
Gli indici riducono la quantità di dati che il database deve controllare per rispondere a domande come “trova l'ordine con ID 123” o “recupera gli utenti con questa email”. Invece di scansionare tutto, il database segue una struttura compatta che restringe rapidamente la ricerca.
Ma l'indicizzazione non è una soluzione universale. Alcune query richiedono comunque di processare molte righe (report ampi, filtri a bassa selettività, aggregazioni pesanti). E gli indici hanno costi reali: spazio aggiuntivo e scritture più lente, perché inserimenti e aggiornamenti devono aggiornare anche l'indice.
Cosa imparerai in questa guida
Vedrai:
- perché evitare le scansioni complete è il vero guadagno in velocità
- come le strutture di indice comuni (come il B-tree) rendono le ricerche veloci
- quali query ne traggono maggior beneficio e quando invece no
- come scegliere indici composti/covering e convalidarli con un piano EXPLAIN
- come mantenere gli indici nel tempo perché le prestazioni non degradino silenziosamente
Il guadagno principale: evitare le scansioni complete
Quando un database esegue una query, ha due opzioni generali: scansionare l'intera tabella riga per riga, o saltare direttamente alle righe che corrispondono. La maggior parte dei miglioramenti dati dagli indici deriva dall'evitare letture non necessarie.
Scansione completa vs. lookup tramite indice
Una scansione completa della tabella è esattamente come suona: il database legge ogni riga, verifica se soddisfa la condizione WHERE e poi restituisce i risultati. È accettabile per tabelle piccole, ma rallenta in modo prevedibile con la crescita della tabella: più righe vuol dire più lavoro.
Usando un indice, il database spesso evita di leggere la maggior parte delle righe. Prima consulta l'indice (una struttura compatta pensata per la ricerca) per trovare dove risiedono le righe corrispondenti, poi legge solo quelle specifiche righe.
Un'analogia semplice
Pensa a un libro. Se vuoi ogni pagina che menziona “fotosintesi”, potresti leggere tutto il libro (scansione completa). Oppure puoi usare l'indice, saltare alle pagine elencate e leggere solo quelle sezioni (lookup tramite indice). Il secondo approccio è più veloce perché salti quasi tutte le pagine.
Perché meno letture significa quasi sempre query più veloci
I database passano molto tempo aspettando letture—soprattutto quando i dati non sono già in memoria. Ridurre il numero di righe (e pagine) che il database deve toccare tipicamente diminuisce:
- letture da disco/SSD
- tempo CPU speso per valutare i filtri
- pressione sulla memoria per mettere dati inutili in cache
Quando si vede il guadagno in velocità
L'indicizzazione aiuta di più quando i dati sono grandi e il pattern di query è selettivo (per esempio, recuperare 20 righe corrispondenti su 10 milioni). Se la query restituisce comunque la maggior parte delle righe, o la tabella è abbastanza piccola da stare tutta in memoria, una scansione completa può essere altrettanto veloce—o persino più veloce.
Come le strutture di indice rendono veloci le ricerche
Gli indici funzionano perché organizzano i valori in modo che il database possa saltare vicino a ciò che cerchi invece di controllare ogni riga.
Indici B-tree: il cavallo di battaglia predefinito
La struttura di indice più comune nei database SQL è il B-tree (spesso scritto "B-tree" o "B+tree"). Concettualmente:
- i valori sono mantenuti ordinati
- l'indice è suddiviso in pagine (chunk) che puntano ad altre pagine e infine alle righe corrispondenti della tabella
Poiché è ordinato, un B-tree è ottimo sia per ricerche per uguaglianza (WHERE email = ...) sia per query per intervallo (WHERE created_at >= ... AND created_at < ...). Il database può navigare verso il vicinato giusto di valori e poi scorrere in avanti in ordine.
Cosa significa “logaritmico” (senza la matematica)
Si dice che le ricerche su B-tree sono “logaritmiche”. Praticamente significa che: quando la tabella cresce da migliaia a milioni di righe, il numero di passi per trovare un valore cresce lentamente, non proporzionalmente.
Invece di “il doppio dei dati significa il doppio del lavoro”, è più come “molto più dati aggiungono solo pochi passi in più”, perché il database segue puntatori attraverso pochi livelli dell'albero.
Indici hash: veloci per le corrispondenze esatte (con limiti)
Alcuni motori offrono anche indici hash. Possono essere molto rapidi per confronti di uguaglianza perché il valore viene trasformato in una hash e usato per trovare direttamente la voce.
Il compromesso: gli indici hash in genere non aiutano con intervalli o scansioni ordinate, e disponibilità e comportamento variano tra i database.
I dettagli del motore differiscono, l'idea resta la stessa
PostgreSQL, MySQL/InnoDB, SQL Server e altri memorizzano e usano gli indici in modo leggermente diverso (dimensione delle pagine, clustering, colonne incluse, controlli di visibilità). Ma il concetto centrale è: gli indici creano una struttura compatta e navigabile che permette al database di individuare le righe corrispondenti con molto meno lavoro rispetto alla scansione dell'intera tabella.
Query che traggono più vantaggio dagli indici
Gli indici non accelerano la "SQL" in generale—velocizzano pattern di accesso specifici. Quando un indice rispecchia come la query filtra, unisce o ordina, il database può saltare direttamente alle righe rilevanti invece di leggere tutta la tabella.
I pattern di query più favorevoli agli indici
1) Filtri WHERE (soprattutto su colonne selettive)
Se la tua query spesso restringe una tabella grande a un piccolo insieme di righe, un indice è di solito il primo elemento da considerare. Un esempio classico è cercare un utente per identificatore.
Senza un indice su users.email, il database potrebbe dover scansionare ogni riga:
SELECT * FROM users WHERE email = '[email protected]';
Con un indice su email, può localizzare rapidamente la/e riga/e corrispondente/i e fermarsi.
2) Chiavi di JOIN (foreign key e chiavi referenziate)
I JOIN sono dove “piccole inefficienze” si trasformano in costi grandi. Se fai join tra orders.user_id e users.id, indicizzare le colonne di join (tipicamente orders.user_id e la primary key users.id) aiuta il database a mettere in corrispondenza le righe senza scansionare ripetutamente.
3) ORDER BY (quando vuoi risultati già ordinati)
L'ordinamento è costoso quando il database deve raccogliere molte righe e ordinarle dopo. Se esegui frequentemente:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
un indice che si allinea con user_id e la colonna di ordinamento può permettere al motore di leggere le righe nell'ordine richiesto invece di ordinare un grande risultato intermedio.
4) GROUP BY (quando il raggruppamento si allinea con un indice)
Il raggruppamento può beneficiare quando il database può leggere i dati già in ordine raggruppato. Non è garantito, ma se raggruppi spesso su una colonna usata anche per il filtro (o naturalmente clusterizzata nell'indice), il motore potrebbe fare meno lavoro.
Filtri per intervallo: un vantaggio comune dei B-tree
Gli indici B-tree sono particolarmente adatti per condizioni di intervallo—pensa a date, prezzi e query "between":
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Per dashboard, report e schermate di “attività recente” questo pattern è ovunque, e un indice sulla colonna di intervallo spesso produce un miglioramento immediato.
Il tema è semplice: gli indici aiutano quando rispecchiano come cerchi e ordini. Se le tue query si allineano con questi pattern di accesso, il database può fare letture mirate invece di scansioni ampie.
Selettività: perché alcuni indici non aiutano
Un indice è utile quando restringe molto il numero di righe che il database deve toccare. Questa proprietà si chiama selettività.
Cosa significa “selettività” in pratica
La selettività è fondamentalmente: quante righe corrispondono a un dato valore? Una colonna altamente selettiva ha molti valori distinti, quindi ogni ricerca corrisponde a poche righe.
- Alta selettività:
email, user_id, order_number (spesso unici o quasi)
- Bassa selettività:
is_active, is_deleted, status con pochi valori comuni
Con alta selettività, un indice può saltare direttamente a un piccolo set di righe. Con bassa selettività, l'indice punta a un grande pezzo della tabella—quindi il database deve comunque leggere e filtrare molto.
Perché gli indici su booleani spesso deludono
Considera una tabella con 10 milioni di righe e una colonna is_deleted dove il 98% è false. Un indice su is_deleted non risparmia molto per:
SELECT * FROM orders WHERE is_deleted = false;
Il set di risultati è ancora quasi l'intera tabella. Usare l'indice può addirittura essere più lento di una scansione sequenziale perché il motore fa lavoro extra saltando tra voci di indice e pagine della tabella.
Perché il database può ignorare il tuo indice
I planner stimano i costi. Se un indice non ridurrà abbastanza il lavoro—perché troppe righe corrispondono, o perché la query necessita della maggior parte delle colonne—possono scegliere una scansione completa.
La selettività cambia nel tempo
La distribuzione dei dati non è fissa. Una colonna status può partire distribuita equamente, poi evolvere fino a che un valore domina. Se le statistiche non sono aggiornate, il planner può fare scelte sbagliate, e un indice che prima aiutava può smettere di essere utile.
Indici composti e covering (e l'ordine delle colonne)
Gli indici su singola colonna sono un buon inizio, ma molte query reali filtrano su una colonna e ordinano o filtrano su un'altra. Qui entrano in gioco gli indici composti (multi-colonna): un unico indice può servire più parti della query.
Ordine delle colonne: la regola "da sinistra a destra"
La maggior parte dei database (specialmente con indici B-tree) può utilizzare un indice composto in modo efficiente solo partendo dalle colonne più a sinistra. Pensa all'indice come ordinato prima per la colonna A, poi per la colonna B, e così via.
Questo significa:
- un indice su (account_id, created_at) è ottimo per query che filtrano per
account_id e poi ordinano o filtrano per created_at
- lo stesso indice di solito non è d'aiuto per una query che filtra solo su
created_at (perché non è la colonna più a sinistra)
Un pattern pratico: timeline per account
Un carico comune è “mostrami gli eventi più recenti per questo account.” Questo pattern:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
beneficia spesso moltissimo da:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Il database può saltare direttamente alla porzione di indice per quell'account e leggere le righe in ordine temporale, invece di scansionare e ordinare un grande insieme.
Indici covering: quando l'indice è la risposta
Un indice covering contiene tutte le colonne che la query richiede, così il database può restituire i risultati dall'indice senza cercare le righe nella tabella (meno letture, meno I/O casuale).
Attenzione: aggiungere colonne aumenta la dimensione dell'indice e il costo. Aggiungi colonne extra solo quando servono per query specifiche ad alto valore.
Non creare indici composti ampi “a casaccio”
Indici composti ampi possono rallentare le scritture e consumare molto spazio. Aggiungili solo per query identificate e verifica con un piano EXPLAIN e misure reali prima e dopo.
Compromessi: rallentamenti in scrittura e spazio aggiuntivo
Gli indici spesso vengono descritti come “velocità gratuita”, ma non lo sono. Le strutture degli indici devono essere mantenute ogni volta che la tabella cambia e consumano risorse reali.
INSERT/UPDATE/DELETE più lenti (perché ogni indice va aggiornato)
Quando fai un INSERT, il database non scrive solo la riga: inserisce anche le voci corrispondenti in ogni indice sulla tabella. Lo stesso vale per DELETE e molti UPDATE.
Per questo “più indici” può rallentare significativamente workload con molte scritture. Un UPDATE che tocca una colonna indicizzata può essere particolarmente costoso: il database potrebbe dover rimuovere la vecchia voce d'indice e aggiungerne una nuova (e in alcuni motori questo può causare page split o riequilibri interni). Se la tua app scrive molto—eventi d'ordine, dati di sensori, log di audit—indicizzare tutto può rendere il database percepibilmente lento anche se le letture sono veloci.
Ogni indice occupa spazio su disco. Su tabelle grandi, gli indici possono competere con la dimensione della tabella, specialmente se hai indici sovrapposti.
Ciò influisce anche sulla memoria. I database si affidano molto alla cache; se il tuo working set include diversi indici grandi, la cache deve contenere più pagine per rimanere veloce. Altrimenti vedrai più I/O da disco e prestazioni meno prevedibili.
L'equilibrio pratico
Indicizzare significa scegliere cosa accelerare. Se il tuo workload è a prevalenza di letture, più indici possono valerne la pena. Se è a prevalenza di scritture, dai priorità agli indici che servono le query più importanti ed evita duplicazioni. Una regola utile: aggiungi un indice solo quando sai nominare la query che aiuta—e verifica che il guadagno in lettura compensi il costo in scrittura e manutenzione.
Come dimostrare che un indice aiuta: EXPLAIN e misurazioni
Aggiungere un indice sembra che dovrebbe aiutare—ma puoi (e dovresti) verificarlo. Gli strumenti che rendono tutto concreto sono il piano della query (EXPLAIN) e misurazioni reali prima/dopo.
Leggere il piano: l'indice viene davvero usato?
Esegui EXPLAIN (o EXPLAIN ANALYZE) sulla query esatta che ti interessa.
- Tipo di scansione: una Seq Scan / Full Table Scan significa che il database legge tutta la tabella. Una Index Scan / Index Seek (o Index Range Scan) suggerisce che sta usando un indice per restringere le righe.
- Righe stimate vs reali (specialmente in
EXPLAIN ANALYZE): se il piano stimava 100 righe ma in realtà ne ha toccate 100.000, l'ottimizzatore ha sbagliato—spesso perché le statistiche sono obsolete o il filtro è meno selettivo del previsto.
- Passaggi di ordinamento: se vedi un Sort esplicito, il database sta ordinando i risultati dopo averli recuperati. Se un nuovo indice corrisponde all'
ORDER BY, quel sort potrebbe sparire, con un grande vantaggio.
Misura correttamente: prima/dopo, stesse condizioni
Benchmarka la query con gli stessi parametri, su dati rappresentativi, e cattura sia la latenza sia le righe processate.
Fai attenzione alla cache: la prima esecuzione può essere più lenta perché i dati non sono in memoria; esecuzioni ripetute possono sembrare “risolte” anche senza indice. Per non ingannarti, confronta più esecuzioni e concentrati sul fatto se il piano cambia (uso dell'indice, meno righe lette) oltre al tempo puro.
Se EXPLAIN ANALYZE mostra meno righe toccate e meno passaggi costosi (come gli ordinamenti), hai dimostrato che l'indice aiuta—non solo sperato.
Errori comuni che annullano i benefici degli indici
Puoi aggiungere l'indice “giusto” e comunque non vedere miglioramenti se la query è scritta in modo che impedisca al database di usarlo. Questi problemi sono spesso sottili, perché la query restituisce comunque il risultato corretto—è solo costretta in un piano più lento.
Anti-pattern che bloccano l'uso dell'indice
1) Wildcard all'inizio
Quando scrivi:
WHERE name LIKE '%term'
il database non può usare un normale indice B-tree per saltare al punto di partenza, perché non sa dove in ordine alfabetico inizi “%term”. Di solito ricade nello scan di molte righe.
Alternative:
- Se possibile, usa una ricerca con prefisso:
WHERE name LIKE 'term%'.
- Se hai bisogno di una ricerca "contiene", considera tipi di indice specializzati (p.es. full-text o trigram) invece di aspettarti che un indice standard aiuti.
2) Funzioni su colonne indicizzate
Sembra innocuo:
WHERE LOWER(email) = '[email protected]'
Ma LOWER(email) cambia l'espressione, quindi l'indice su email non può essere usato direttamente.
Alternative:
- Memorizza dati normalizzati (p.es. email in minuscolo) e usa
WHERE email = ....
- Oppure crea un indice su espressione (se il database lo supporta) specifico per
LOWER(email).
Blocchi d'indice nascosti che si sottovalutano
Cast impliciti: Confrontare tipi diversi può costringere il database a fare un cast su un lato, cosa che può disabilitare l'indice. Es.: confrontare una colonna integer con una stringa letterale.
Collazioni/encoding non corrispondenti: Se il confronto usa una collation diversa da quella con cui è stato costruito l'indice (comune per colonne testuali in locali diverse), l'ottimizzatore può evitare l'indice.
Checklist rapida: “Perché il mio indice non viene usato?”
- La condizione inizia con un wildcard (
LIKE '%x')?
- Applichi una funzione alla colonna indicizzata (
LOWER(col), DATE(col), CAST(col))?
- I tipi sono identici su entrambi i lati (nessun cast implicito)?
- La collation/locale è coerente per il confronto?
- Il predicato è abbastanza selettivo (non corrisponde a una porzione enorme della tabella)?
- Stai filtrando/ordinando sulle colonne più a sinistra di un indice composto?
- Hai controllato il piano con
EXPLAIN per confermare la scelta del database?
Manutenzione degli indici: statistiche, bloat e salute a lungo termine
Gli indici non sono “impostali e dimenticali”. Nel tempo i dati cambiano, i pattern di query evolvono e la forma fisica di tabelle e indici degrada. Un indice ben scelto può lentamente diventare meno efficace—o addirittura dannoso—se non lo mantieni.
Statistiche: la mappa del planner può diventare obsoleta
La maggior parte dei database si affida a un planner (ottimizzatore) per scegliere come eseguire una query: quale indice usare, l'ordine dei join e se un lookup è conveniente. Per decidere usa statistiche—sintesi sulla distribuzione dei valori, conteggio righe e skew dei dati.
Quando le statistiche sono obsolete, le stime sulle righe possono essere completamente sbagliate. Questo porta a scelte di piano errate, come scegliere un indice che restituisce molte più righe del previsto o saltare un indice utile.
Rimedio di routine: programma aggiornamenti regolari delle statistiche (spesso ANALYZE o simili). Dopo grandi carichi di dati, cancellazioni massicce o cambiamenti significativi, aggiorna le statistiche prima.
Bloat e frammentazione: quando le strutture diventano disordinate
Con insert, update e delete, gli indici possono accumulare bloat (pagine vuote o poco utilizzate) e frammentazione (dati sparsi che aumentano l'I/O). Il risultato sono indici più grandi, più letture e scansioni più lente—soprattutto per le query per intervallo.
Rimedio di routine: ricostruire o riorganizzare periodicamente gli indici molto usati quando sono cresciuti sproporzionatamente o le prestazioni degradano. Gli strumenti e l'impatto variano per motore, quindi trattalo come un'operazione misurata.
Monitora nel tempo, non solo una volta
Imposta monitoraggio per:
- query lente (latenza, frequenza e peggiori offender)
- uso degli indici (indici mai usati vs quelli "hot")
- crescita della dimensione degli indici e cambi improvvisi di piano
Quel feedback ti aiuta a capire quando la manutenzione è necessaria—e quando un indice dovrebbe essere aggiustato o rimosso. Per maggiori dettagli su come convalidare miglioramenti, vedi il workflow "Come dimostrare che un indice aiuta — EXPLAIN e misurazioni".
Un workflow pratico per aggiungere l'indice giusto
Aggiungere un indice deve essere una modifica deliberata, non un azzardo. Un workflow leggero ti mantiene focalizzato su guadagni misurabili e previene l'“index sprawl”.
1) Identifica la query reale problematica
Parti dalle evidenze: log di query lente, tracce APM o segnalazioni degli utenti. Scegli una query che sia lenta e frequente—un report raro da 10 secondi conta meno di una lookup comune da 200 ms.
Cattura l'SQL esatto e il pattern di parametri (per esempio: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Piccole differenze cambiano quale indice è utile.
2) Misura una baseline
Registra latenza corrente (p50/p95), righe scandite e impatto CPU/IO. Salva l'output del piano corrente (es. EXPLAIN / EXPLAIN ANALYZE) per confronti.
3) Progetta il più piccolo indice utile
Scegli colonne che rispecchino come la query filtra e ordina. Preferisci l'indice minimo che fa smettere il piano di scansionare grandi porzioni.
Testa in staging con volumi di dati simili alla produzione. Gli indici possono sembrare ottimi su dataset piccoli e deludere a scala.
4) Crealo in sicurezza
Su tabelle grandi, usa opzioni online quando disponibili (per esempio PostgreSQL CREATE INDEX CONCURRENTLY). Pianifica le modifiche in traffico più basso se il DB può bloccare scritture.
5) Convalida con evidenze prima/dopo
Riesegui la stessa query e confronta:
- la forma del piano (è cambiata da full scan a accesso tramite indice?)
- tempo di esecuzione e righe scandite
- impatto sulle scritture (latenza insert/update)
6) Hai un piano di rollback
Se l'indice aumenta il costo delle scritture o satura la memoria, rimuovilo pulitamente (es. DROP INDEX CONCURRENTLY dove disponibile). Mantieni la migrazione reversibile.
7) Documenta il “perché”
Nella migrazione o nelle note di schema, scrivi quale query serve l'indice e quale metrica è migliorata. Il te futuro (o un collega) saprà perché esiste e quando è sicuro eliminarlo.
Dove si inserisce Koder.ai in questo workflow
Se stai costruendo un nuovo servizio e vuoi evitare l’“index sprawl” fin dall'inizio, Koder.ai ti aiuta a iterare velocemente sull'intero loop sopra: genera un'app React + Go + PostgreSQL dalla chat, aggiusta schemi e migrazioni man mano che cambiano i requisiti, e poi esporta il codice quando sei pronto a prenderne il controllo manuale. In pratica, rende più semplice passare da “questo endpoint è lento” a “ecco il piano EXPLAIN, l'indice minimo e una migrazione reversibile” senza aspettare una pipeline tradizionale completa.
Quando l'indicizzazione non basta (e cosa fare dopo)
Gli indici sono una leva enorme, ma non sono un pulsante magico per velocizzare tutto. A volte la parte lenta di una richiesta avviene dopo che il database trova le righe giuste—oppure il pattern di query rende l'indicizzazione una mossa sbagliata.
Casi in cui l'indicizzazione non è la soluzione principale
Se la query già usa un buon indice ma è comunque lenta, cerca questi colpevoli comuni:
- Paginazione mancante o inadeguata: recuperare la pagina 1.000 con
OFFSET 999000 può essere lento anche con indici. Preferisci la paginazione keyset (es.: “dammi le righe dopo l'ultimo id/timestamp visto”).
- Si restituisce troppa roba: selezionare righe molto ampie (
SELECT *) o restituire decine di migliaia di record può diventare un collo di bottiglia su rete, serializzazione JSON o elaborazione applicativa.
- Mismatch di schema: join eccessivi, valori ricercabili salvati in JSON/blob di testo, o tipi dati sbagliati possono costringere operazioni pesanti che gli indici non mascherano completamente.
Ottimizzazioni complementari spesso più importanti
- Riscrivi la query: rimuovi join non necessari, evita funzioni su colonne indicizzate nelle WHERE, semplifica predicati con molti OR.
- Limita colonne e righe: seleziona solo ciò che serve, aggiungi LIMIT sensati e pagina i risultati intenzionalmente.
- Caching: memorizza le letture calde a livello applicazione o usa un read-through cache per query costose ripetute.
- Partizionamento: se la maggior parte delle query riguarda dati recenti, partiziona per tempo (o altro confine naturale) per ridurre lo spazio di ricerca.
Se vuoi una diagnostica più profonda dei colli di bottiglia, abbina questo approccio con il workflow "Come dimostrare che un indice aiuta".
Priorità: risolvi il collo di bottiglia più grande prima
Non indovinare. Misura dove si spende il tempo (esecuzione DB vs righe restituite vs codice app). Se il database è veloce ma l'API è lenta, più indici non aiutano.
Checklist rapida